Análisis de Sonetos de Francisco de Quevedo
Índice
Información General
| Título: | Sonetos |
|---|
| Autor: | Francisco de Quevedo |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 9011 |
|---|
| #Palabras distintas: | 2796 |
|---|
| Type-Token ratio: | 31.03% |
|---|
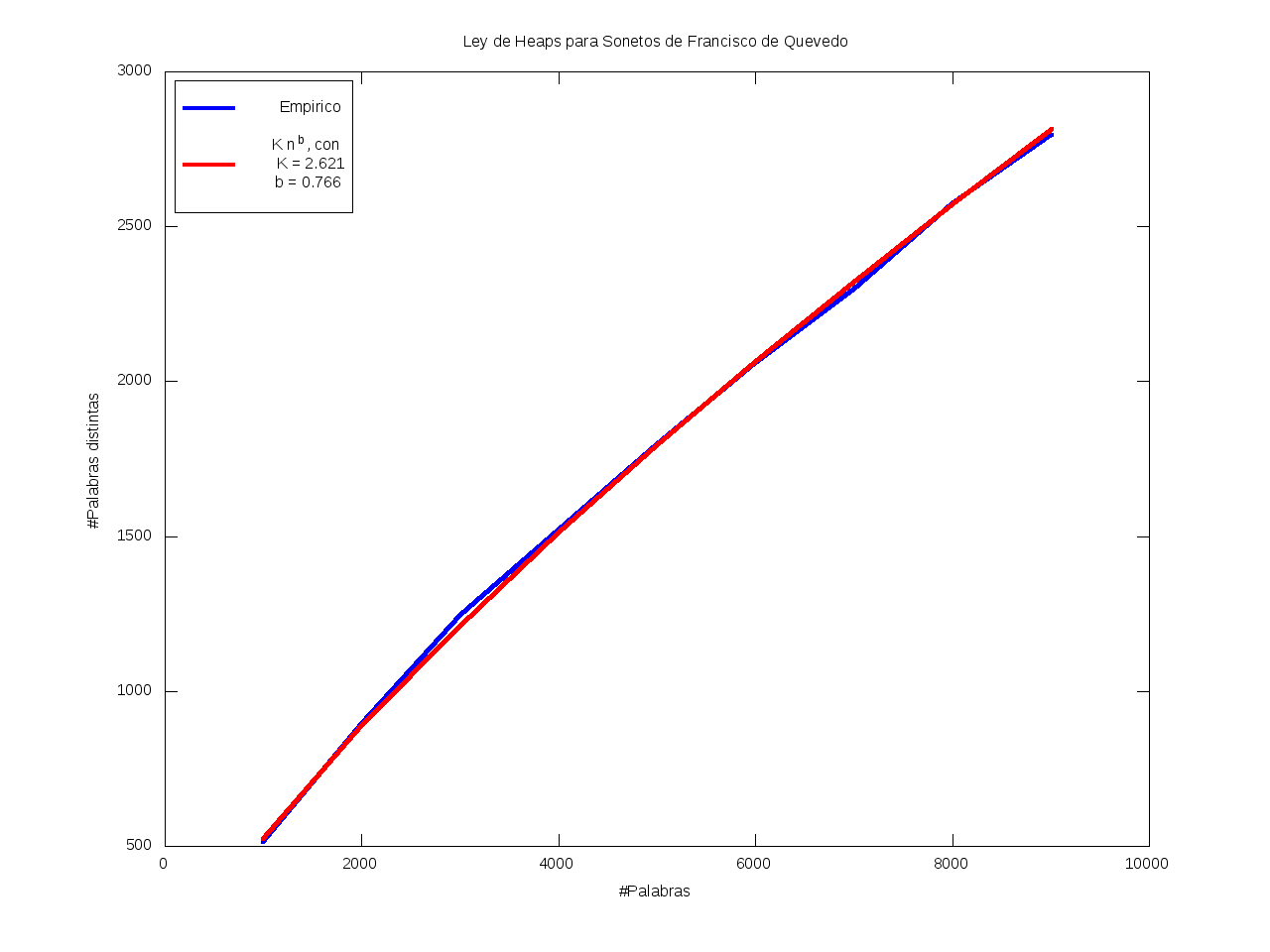
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| #Palabras: | #Palabras distintas: |
|---|
| 1000 | 512 |
| 2000 | 893 |
| 3000 | 1245 |
| 4000 | 1522 |
| 5000 | 1796 |
| 6000 | 2058 |
| 7000 | 2297 |
| 8000 | 2574 |
| 9000 | 2794 |
| 9011 | 2796 |
|
Ajuste por mínimos cuadrados de los datos a K*n^b:
|
| K = 2.621 |
|
b = 0.766 |
|
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Rank | Palabra | Frec |
|---|
| 1 | y | 419 |
| 2 | de | 360 |
| 3 | que | 309 |
| 4 | la | 287 |
| 5 | en | 261 |
| 6 | el | 255 |
| 7 | a | 161 |
| 8 | con | 120 |
| 9 | no | 119 |
| 10 | del | 105 |
| 11 | su | 104 |
| 12 | los | 91 |
| 13 | al | 87 |
| 14 | mi | 82 |
| 15 | las | 81 |
| 16 | es | 69 |
| 17 | si | 67 |
| 18 | tu | 64 |
| 19 | por | 58 |
| 20 | lo | 50 |
| 21 | un | 48 |
| 22 | se | 47 |
| 23 | muerte | 44 |
| 24 | me | 43 |
| 25 | amor | 42 |
| 26 | más | 38 |
| 27 | vida | 36 |
| 28 | te | 36 |
| 29 | pues | 36 |
| 30 | mis | 36 |
| 31 | le | 32 |
| 32 | son | 28 |
| 33 | día | 28 |
| 34 | sus | 27 |
| 35 | sin | 26 |
| 36 | fuego | 26 |
| 37 | ya | 25 |
| 38 | una | 25 |
| 39 | qué | 25 |
| 40 | sol | 22 |
| 41 | tus | 21 |
| 42 | quien | 21 |
| 43 | todo | 20 |
| 44 | oro | 20 |
| 45 | ni | 20 |
| 46 | cuando | 20 |
| 47 | ardiente | 20 |
| 48 | ojos | 19 |
| 49 | amante | 19 |
| 50 | yo | 18 |
| 51 | ser | 18 |
| 52 | para | 18 |
| 53 | ha | 18 |
| 54 | corazón | 18 |
| 55 | alma | 18 |
| 56 | mas | 17 |
| 57 | oh | 16 |
| 58 | mí | 16 |
| 59 | luz | 16 |
| 60 | él | 15 |
| 61 | tiempo | 14 |
| 62 | mar | 14 |
| 63 | mal | 14 |
| 64 | llanto | 14 |
| 65 | llama | 14 |
| 66 | fue | 14 |
| 67 | mano | 13 |
| 68 | lisi | 13 |
| 69 | este | 13 |
| 70 | esta | 13 |
| 71 | cielo | 13 |
| 72 | tan | 12 |
| 73 | soy | 12 |
| 74 | nieve | 12 |
| 75 | mía | 12 |
| 76 | como | 12 |
| 77 | tierra | 11 |
| 78 | sombra | 11 |
| 79 | sangre | 11 |
| 80 | hermosura | 11 |
| 81 | fría | 11 |
| 82 | breve | 11 |
| 83 | siempre | 10 |
| 84 | sí | 10 |
| 85 | será | 10 |
| 86 | noche | 10 |
| 87 | he | 10 |
| 88 | edad | 10 |
| 89 | cuidado | 10 |
| 90 | cuán | 10 |
| 91 | contra | 10 |
| 92 | ves | 9 |
| 93 | tiene | 9 |
| 94 | ti | 9 |
| 95 | sueño | 9 |
| 96 | poco | 9 |
| 97 | hoy | 9 |
| 98 | hombre | 9 |
| 99 | hermosa | 9 |
| 100 | está | 9 |
| 101 | entre | 9 |
| 102 | dura | 9 |
| 103 | dolor | 9 |
| 104 | cuanto | 9 |
| 105 | armas | 9 |
| 106 | voz | 8 |
| 107 | vivir | 8 |
| 108 | viento | 8 |
| 109 | venas | 8 |
| 110 | tal | 8 |
| 111 | rey | 8 |
| 112 | prisión | 8 |
| 113 | porque | 8 |
| 114 | pena | 8 |
| 115 | o | 8 |
| 116 | nada | 8 |
| 117 | invierno | 8 |
| 118 | humo | 8 |
| 119 | guerra | 8 |
| 120 | gloria | 8 |
| 121 | dios | 8 |
| 122 | da | 8 |
| 123 | cuerpo | 8 |
| 124 | bien | 8 |
| 125 | amar | 8 |
| 126 | vive | 7 |
| 127 | tú | 7 |
| 128 | tirano | 7 |
| 129 | tanto | 7 |
| 130 | roma | 7 |
| 131 | púrpura | 7 |
| 132 | pudo | 7 |
| 133 | piedad | 7 |
| 134 | mismo | 7 |
| 135 | memoria | 7 |
| 136 | mañana | 7 |
| 137 | hielo | 7 |
| 138 | han | 7 |
| 139 | grande | 7 |
| 140 | fin | 7 |
| 141 | donde | 7 |
| 142 | después | 7 |
| 143 | dentro | 7 |
| 144 | ciego | 7 |
| 145 | ayer | 7 |
| 146 | sólo | 6 |
| 147 | sepulcro | 6 |
| 148 | pero | 6 |
| 149 | paso | 6 |
| 150 | osuna | 6 |
| 151 | nos | 6 |
| 152 | nariz | 6 |
| 153 | mujer | 6 |
| 154 | monte | 6 |
| 155 | luego | 6 |
| 156 | lágrimas | 6 |
| 157 | infierno | 6 |
| 158 | hora | 6 |
| 159 | fuera | 6 |
| 160 | fortuna | 6 |
| 161 | eres | 6 |
| 162 | érase | 6 |
| 163 | entrañas | 6 |
| 164 | dulce | 6 |
| 165 | dos | 6 |
| 166 | boca | 6 |
| 167 | bebe | 6 |
| 168 | vuelve | 5 |
| 169 | vos | 5 |
| 170 | vio | 5 |
| 171 | veo | 5 |
| 172 | valiente | 5 |
| 173 | valentía | 5 |
| 174 | toros | 5 |
| 175 | todas | 5 |
| 176 | tesoro | 5 |
| 177 | sombras | 5 |
| 178 | solamente | 5 |
| 179 | sobre | 5 |
| 180 | señor | 5 |
| 181 | sentidos | 5 |
| 182 | semblante | 5 |
| 183 | rayo | 5 |
| 184 | pura | 5 |
| 185 | puede | 5 |
| 186 | postrer | 5 |
| 187 | pie | 5 |
| 188 | pide | 5 |
| 189 | penas | 5 |
| 190 | paz | 5 |
| 191 | otro | 5 |
| 192 | otra | 5 |
| 193 | oscura | 5 |
| 194 | negro | 5 |
| 195 | morir | 5 |
| 196 | menos | 5 |
| 197 | lleva | 5 |
| 198 | llamas | 5 |
| 199 | libre | 5 |
| 200 | l | 5 |
| 201 | humana | 5 |
| 202 | horas | 5 |
| 203 | hermoso | 5 |
| 204 | gran | 5 |
| 205 | fuese | 5 |
| 206 | frente | 5 |
| 207 | flores | 5 |
| 208 | espada | 5 |
| 209 | era | 5 |
| 210 | envía | 5 |
| 211 | don | 5 |
| 212 | dichoso | 5 |
| 213 | dan | 5 |
| 214 | corriente | 5 |
| 215 | compañía | 5 |
| 216 | cómo | 5 |
| 217 | clavel | 5 |
| 218 | cerco | 5 |
| 219 | campo | 5 |
| 220 | ausente | 5 |
| 221 | arder | 5 |
| 222 | antes | 5 |
| 223 | yace | 4 |
| 224 | vuelo | 4 |
| 225 | viendo | 4 |
| 226 | victoria | 4 |
| 227 | vi | 4 |
| 228 | ve | 4 |
| 229 | va | 4 |
| 230 | treinta | 4 |
| 231 | traigo | 4 |
| 232 | toro | 4 |
| 233 | suerte | 4 |
| 234 | suelo | 4 |
| 235 | sonoro | 4 |
| 236 | soledad | 4 |
| 237 | soberbia | 4 |
| 238 | sino | 4 |
| 239 | siente | 4 |
| 240 | sido | 4 |
| 241 | sentimiento | 4 |
| 242 | salud | 4 |
| 243 | rubio | 4 |
| 244 | rosa | 4 |
| 245 | risa | 4 |
| 246 | rico | 4 |
| 247 | rica | 4 |
| 248 | puro | 4 |
| 249 | propio | 4 |
| 250 | presunción | 4 |
| 251 | polvo | 4 |
| 252 | pobre | 4 |
| 253 | piedra | 4 |
| 254 | perlas | 4 |
| 255 | pasos | 4 |
| 256 | pasa | 4 |
| 257 | padecer | 4 |
| 258 | ostenta | 4 |
| 259 | olvido | 4 |
| 260 | nunca | 4 |
| 261 | nacido | 4 |
| 262 | muestra | 4 |
| 263 | muerto | 4 |
| 264 | mortal | 4 |
| 265 | montañas | 4 |
| 266 | miras | 4 |
| 267 | mira | 4 |
| 268 | metal | 4 |
| 269 | manos | 4 |
| 270 | lozana | 4 |
| 271 | lloro | 4 |
| 272 | labios | 4 |
| 273 | imagen | 4 |
| 274 | huye | 4 |
| 275 | herida | 4 |
| 276 | hay | 4 |
| 277 | hasta | 4 |
| 278 | has | 4 |
| 279 | hace | 4 |
| 280 | gente | 4 |
| 281 | fuerza | 4 |
| 282 | fuerte | 4 |
| 283 | fuente | 4 |
| 284 | flora | 4 |
| 285 | espíritu | 4 |
| 286 | engaños | 4 |
| 287 | dueño | 4 |
| 288 | dio | 4 |
| 289 | deseo | 4 |
| 290 | descanso | 4 |
| 291 | dejas | 4 |
| 292 | dado | 4 |
| 293 | cristo | 4 |
| 294 | creo | 4 |
| 295 | claveles | 4 |
| 296 | cinco | 4 |
| 297 | cierra | 4 |
| 298 | ceniza | 4 |
| 299 | camino | 4 |
| 300 | cabello | 4 |
| 301 | ardor | 4 |
| 302 | años | 4 |
| 303 | ansí | 4 |
| 304 | aminta | 4 |
| 305 | amenaza | 4 |
| 306 | alto | 4 |
| 307 | allá | 4 |
| 308 | zagala | 3 |
| 309 | vuelvo | 3 |
| 310 | vivo | 3 |
| 311 | viva | 3 |
| 312 | viste | 3 |
| 313 | vista | 3 |
| 314 | verdad | 3 |
| 315 | ver | 3 |
| 316 | veneno | 3 |
| 317 | vencido | 3 |
| 318 | vela | 3 |
| 319 | vana | 3 |
| 320 | unos | 3 |
| 321 | tras | 3 |
| 322 | tiro | 3 |
| 323 | tiranos | 3 |
| 324 | tienen | 3 |
| 325 | tenía | 3 |
| 326 | tengo | 3 |
| 327 | tempestad | 3 |
| 328 | temerosa | 3 |
| 329 | teme | 3 |
| 330 | suspiros | 3 |
| 331 | suspiro | 3 |
| 332 | soplo | 3 |
| 333 | solo | 3 |
| 334 | sola | 3 |
| 335 | sigue | 3 |
| 336 | sepultada | 3 |
| 337 | sepoltura | 3 |
| 338 | señas | 3 |
| 339 | séneca | 3 |
| 340 | sed | 3 |
| 341 | secos | 3 |
| 342 | ruinas | 3 |
| 343 | rubíes | 3 |
| 344 | rubí | 3 |
| 345 | riqueza | 3 |
| 346 | rigor | 3 |
| 347 | ríes | 3 |
| 348 | ricas | 3 |
| 349 | retrato | 3 |
| 350 | razón | 3 |
| 351 | quieres | 3 |
| 352 | quieren | 3 |
| 353 | quién | 3 |
| 354 | puedo | 3 |
| 355 | puedes | 3 |
| 356 | pueblo | 3 |
| 357 | propias | 3 |
| 358 | presente | 3 |
| 359 | precio | 3 |
| 360 | podrá | 3 |
| 361 | poderoso | 3 |
| 362 | poder | 3 |
| 363 | piedras | 3 |
| 364 | piadosa | 3 |
| 365 | permite | 3 |
| 366 | perdido | 3 |
| 367 | perdición | 3 |
| 368 | pequeño | 3 |
| 369 | pensamiento | 3 |
| 370 | pecho | 3 |
| 371 | pecado | 3 |
| 372 | patria | 3 |
| 373 | padre | 3 |
| 374 | otros | 3 |
| 375 | oscuro | 3 |
| 376 | orilla | 3 |
| 377 | oriente | 3 |
| 378 | orfeo | 3 |
| 379 | ondas | 3 |
| 380 | ocasión | 3 |
| 381 | nueva | 3 |
| 382 | nuestro | 3 |
| 383 | nuestra | 3 |
| 384 | nubes | 3 |
| 385 | nerón | 3 |
| 386 | nació | 3 |
| 387 | muy | 3 |
| 388 | mundo | 3 |
| 389 | mueve | 3 |
| 390 | muera | 3 |
| 391 | mucho | 3 |
| 392 | movimiento | 3 |
| 393 | mortaja | 3 |
| 394 | monumento | 3 |
| 395 | misma | 3 |
| 396 | miro | 3 |
| 397 | ministro | 3 |
| 398 | miedo | 3 |
| 399 | midas | 3 |
| 400 | mejor | 3 |
| 401 | mayor | 3 |
| 402 | mármol | 3 |
| 403 | majestad | 3 |
| 404 | lumbre | 3 |
| 405 | locura | 3 |
| 406 | llora | 3 |
| 407 | llegado | 3 |
| 408 | llega | 3 |
| 409 | libertad | 3 |
| 410 | ley | 3 |
| 411 | largo | 3 |
| 412 | labio | 3 |
| 413 | jornada | 3 |
| 414 | incendios | 3 |
| 415 | incendio | 3 |
| 416 | imperio | 3 |
| 417 | igual | 3 |
| 418 | hubiera | 3 |
| 419 | hizo | 3 |
| 420 | historia | 3 |
| 421 | hierro | 3 |
| 422 | heridas | 3 |
| 423 | hacen | 3 |
| 424 | haber | 3 |
| 425 | gracias | 3 |
| 426 | goza | 3 |
| 427 | girón | 3 |
| 428 | generosa | 3 |
| 429 | gemidos | 3 |
| 430 | funesto | 3 |
| 431 | fueron | 3 |
| 432 | frágil | 3 |
| 433 | flechas | 3 |
| 434 | familia | 3 |
| 435 | falta | 3 |
| 436 | etna | 3 |
| 437 | eterno | 3 |
| 438 | estrella | 3 |
| 439 | estoy | 3 |
| 440 | españa | 3 |
| 441 | esa | 3 |
| 442 | erase | 3 |
| 443 | enseña | 3 |
| 444 | enojos | 3 |
| 445 | enjuga | 3 |
| 446 | engaño | 3 |
| 447 | encendido | 3 |
| 448 | enamorado | 3 |
| 449 | ella | 3 |
| 450 | dureza | 3 |
| 451 | duque | 3 |
| 452 | doliente | 3 |
| 453 | divertido | 3 |
| 454 | diamante | 3 |
| 455 | despierto | 3 |
| 456 | desdén | 3 |
| 457 | derrama | 3 |
| 458 | dejó | 3 |
| 459 | defensa | 3 |
| 460 | debo | 3 |
| 461 | daños | 3 |
| 462 | cuidados | 3 |
| 463 | cuenta | 3 |
| 464 | cuánto | 3 |
| 465 | cosa | 3 |
| 466 | cortés | 3 |
| 467 | corona | 3 |
| 468 | conoce | 3 |
| 469 | color | 3 |
| 470 | claustro | 3 |
| 471 | ciega | 3 |
| 472 | ceño | 3 |
| 473 | cenizas | 3 |
| 474 | causa | 3 |
| 475 | carmesíes | 3 |
| 476 | cárcel | 3 |
| 477 | caña | 3 |
| 478 | cano | 3 |
| 479 | caminante | 3 |
| 480 | cadáver | 3 |
| 481 | cada | 3 |
| 482 | brevedad | 3 |
| 483 | brazo | 3 |
| 484 | blanco | 3 |
| 485 | ay | 3 |
| 486 | avaro | 3 |
| 487 | aurora | 3 |
| 488 | aura | 3 |
| 489 | aun | 3 |
| 490 | atento | 3 |
| 491 | armonía | 3 |
| 492 | ardía | 3 |
| 493 | aquella | 3 |
| 494 | año | 3 |
| 495 | amoroso | 3 |
| 496 | amigo | 3 |
| 497 | altas | 3 |
| 498 | alta | 3 |
| 499 | almas | 3 |
| 500 | aire | 3 |
| 501 | aguas | 3 |
| 502 | agua | 3 |
| 503 | agradecido | 3 |
| 504 | afecto | 3 |
| 505 | advierte | 3 |
| 506 | adora | 3 |
| 507 | admite | 3 |
| 508 | acerca | 3 |
| 509 | vuestro | 2 |
| 510 | vuestra | 2 |
| 511 | volvió | 2 |
| 512 | voluntad | 2 |
| 513 | volcán | 2 |
| 514 | vivido | 2 |
| 515 | vitoria | 2 |
| 516 | virtud | 2 |
| 517 | vino | 2 |
| 518 | villano | 2 |
| 519 | vieres | 2 |
| 520 | vientos | 2 |
| 521 | viene | 2 |
| 522 | vidas | 2 |
| 523 | vez | 2 |
| 524 | vestido | 2 |
| 525 | verte | 2 |
| 526 | verse | 2 |
| 527 | vergüenza | 2 |
| 528 | verdadero | 2 |
| 529 | ventura | 2 |
| 530 | venido | 2 |
| 531 | venganza | 2 |
| 532 | ven | 2 |
| 533 | veinticinco | 2 |
| 534 | veinte | 2 |
| 535 | vanidad | 2 |
| 536 | unas | 2 |
| 537 | tumba | 2 |
| 538 | triunfante | 2 |
| 539 | tregua | 2 |
| 540 | traje | 2 |
| 541 | trae | 2 |
| 542 | tracia | 2 |
| 543 | tormentos | 2 |
| 544 | todos | 2 |
| 545 | tirio | 2 |
| 546 | tienes | 2 |
| 547 | tendrá | 2 |
| 548 | temor | 2 |
| 549 | temo | 2 |
| 550 | temer | 2 |
| 551 | techo | 2 |
| 552 | tales | 2 |
| 553 | suyo | 2 |
| 554 | supo | 2 |
| 555 | sueños | 2 |
| 556 | suele | 2 |
| 557 | sudor | 2 |
| 558 | sordo | 2 |
| 559 | sonoras | 2 |
| 560 | solitario | 2 |
| 561 | sobró | 2 |
| 562 | sirve | 2 |
| 563 | silencio | 2 |
| 564 | sigo | 2 |
| 565 | sierra | 2 |
| 566 | siento | 2 |
| 567 | siendo | 2 |
| 568 | severa | 2 |
| 569 | serena | 2 |
| 570 | serás | 2 |
| 571 | serán | 2 |
| 572 | sentido | 2 |
| 573 | sentí | 2 |
| 574 | senda | 2 |
| 575 | sembrados | 2 |
| 576 | seguro | 2 |
| 577 | segura | 2 |
| 578 | sediento | 2 |
| 579 | sea | 2 |
| 580 | sañas | 2 |
| 581 | saña | 2 |
| 582 | santera | 2 |
| 583 | sangrienta | 2 |
| 584 | san | 2 |
| 585 | sabe | 2 |
| 586 | ruego | 2 |
| 587 | ríos | 2 |
| 588 | ribera | 2 |
| 589 | reyes | 2 |
| 590 | retiró | 2 |
| 591 | retirado | 2 |
| 592 | resistencia | 2 |
| 593 | resbalas | 2 |
| 594 | representa | 2 |
| 595 | relámpagos | 2 |
| 596 | reino | 2 |
| 597 | quiere | 2 |
| 598 | quiera | 2 |
| 599 | querer | 2 |
| 600 | quedan | 2 |
| 601 | propia | 2 |
| 602 | pronuncian | 2 |
| 603 | prisiones | 2 |
| 604 | principio | 2 |
| 605 | primero | 2 |
| 606 | primavera | 2 |
| 607 | pretensión | 2 |
| 608 | pretende | 2 |
| 609 | presumir | 2 |
| 610 | prestó | 2 |
| 611 | presto | 2 |
| 612 | premio | 2 |
| 613 | precioso | 2 |
| 614 | preciosa | 2 |
| 615 | postrero | 2 |
| 616 | porfía | 2 |
| 617 | pólvora | 2 |
| 618 | pobreza | 2 |
| 619 | pirámide | 2 |
| 620 | pies | 2 |
| 621 | piadoso | 2 |
| 622 | pesado | 2 |
| 623 | peregrino | 2 |
| 624 | peñas | 2 |
| 625 | penar | 2 |
| 626 | pedro | 2 |
| 627 | pasajero | 2 |
| 628 | parto | 2 |
| 629 | parte | 2 |
| 630 | pan | 2 |
| 631 | pálidos | 2 |
| 632 | pálida | 2 |
| 633 | palabras | 2 |
| 634 | padezco | 2 |
| 635 | padece | 2 |
| 636 | osas | 2 |
| 637 | osa | 2 |
| 638 | os | 2 |
| 639 | olvidos | 2 |
| 640 | olvida | 2 |
| 641 | ocaso | 2 |
| 642 | obstinado | 2 |
| 643 | nuevo | 2 |
| 644 | nombre | 2 |
| 645 | niña | 2 |
| 646 | negra | 2 |
| 647 | necio | 2 |
| 648 | náufrago | 2 |
| 649 | nacidos | 2 |
| 650 | mustio | 2 |
| 651 | músicos | 2 |
| 652 | músico | 2 |
| 653 | música | 2 |
| 654 | muero | 2 |
| 655 | muere | 2 |
| 656 | mudos | 2 |
| 657 | mudas | 2 |
| 658 | moza | 2 |
| 659 | mostrar | 2 |
| 660 | mordido | 2 |
| 661 | monarquía | 2 |
| 662 | momento | 2 |
| 663 | mirar | 2 |
| 664 | míos | 2 |
| 665 | mientras | 2 |
| 666 | mezclaba | 2 |
| 667 | mentiras | 2 |
| 668 | mente | 2 |
| 669 | medulas | 2 |
| 670 | mata | 2 |
| 671 | martirio | 2 |
| 672 | marte | 2 |
| 673 | marinero | 2 |
| 674 | manera | 2 |
| 675 | luna | 2 |
| 676 | lugar | 2 |
| 677 | luciente | 2 |
| 678 | lluvias | 2 |
| 679 | llueve | 2 |
| 680 | llena | 2 |
| 681 | llanura | 2 |
| 682 | lisonjera | 2 |
| 683 | lisonjas | 2 |
| 684 | lísida | 2 |
| 685 | líquida | 2 |
| 686 | licas | 2 |
| 687 | les | 2 |
| 688 | leño | 2 |
| 689 | lenguaje | 2 |
| 690 | lección | 2 |
| 691 | lástima | 2 |
| 692 | larga | 2 |
| 693 | juventud | 2 |
| 694 | juntos | 2 |
| 695 | junto | 2 |
| 696 | jasón | 2 |
| 697 | jardín | 2 |
| 698 | ir | 2 |
| 699 | invidia | 2 |
| 700 | inútil | 2 |
| 701 | interior | 2 |
| 702 | interés | 2 |
| 703 | intenta | 2 |
| 704 | instante | 2 |
| 705 | inadvertido | 2 |
| 706 | impreso | 2 |
| 707 | imite | 2 |
| 708 | imita | 2 |
| 709 | humos | 2 |
| 710 | humilde | 2 |
| 711 | humano | 2 |
| 712 | hospedado | 2 |
| 713 | horror | 2 |
| 714 | honra | 2 |
| 715 | honesto | 2 |
| 716 | hidrópica | 2 |
| 717 | hidropesía | 2 |
| 718 | hazañas | 2 |
| 719 | hados | 2 |
| 720 | haces | 2 |
| 721 | hablan | 2 |
| 722 | gusanos | 2 |
| 723 | gusano | 2 |
| 724 | guido | 2 |
| 725 | granizos | 2 |
| 726 | grandeza | 2 |
| 727 | golfo | 2 |
| 728 | gobierno | 2 |
| 729 | glorioso | 2 |
| 730 | gime | 2 |
| 731 | gemido | 2 |
| 732 | furias | 2 |
| 733 | fulminar | 2 |
| 734 | fugitivas | 2 |
| 735 | fugitiva | 2 |
| 736 | fuertes | 2 |
| 737 | floralva | 2 |
| 738 | flor | 2 |
| 739 | flandes | 2 |
| 740 | flagrante | 2 |
| 741 | firmamento | 2 |
| 742 | felipe | 2 |
| 743 | fatiga | 2 |
| 744 | fantasma | 2 |
| 745 | fábricas | 2 |
| 746 | exequias | 2 |
| 747 | eterna | 2 |
| 748 | estudios | 2 |
| 749 | estrellas | 2 |
| 750 | estos | 2 |
| 751 | esto | 2 |
| 752 | esquivo | 2 |
| 753 | espléndidas | 2 |
| 754 | espero | 2 |
| 755 | esotra | 2 |
| 756 | esforzado | 2 |
| 757 | ese | 2 |
| 758 | esconde | 2 |
| 759 | esclava | 2 |
| 760 | esas | 2 |
| 761 | errado | 2 |
| 762 | epitafio | 2 |
| 763 | entendimiento | 2 |
| 764 | entendidos | 2 |
| 765 | enseñanza | 2 |
| 766 | ennegreció | 2 |
| 767 | enemigos | 2 |
| 768 | encendió | 2 |
| 769 | encendidas | 2 |
| 770 | encendida | 2 |
| 771 | encender | 2 |
| 772 | encarnado | 2 |
| 773 | encarcelado | 2 |
| 774 | elocuente | 2 |
| 775 | ejemplo | 2 |
| 776 | egipto | 2 |
| 777 | duerme | 2 |
| 778 | dudoso | 2 |
| 779 | doy | 2 |
| 780 | doctos | 2 |
| 781 | docta | 2 |
| 782 | diste | 2 |
| 783 | difunto | 2 |
| 784 | diferentes | 2 |
| 785 | dice | 2 |
| 786 | di | 2 |
| 787 | destino | 2 |
| 788 | despreciada | 2 |
| 789 | desprecia | 2 |
| 790 | despojos | 2 |
| 791 | despeñado | 2 |
| 792 | desnudez | 2 |
| 793 | desierto | 2 |
| 794 | desdichado | 2 |
| 795 | desdeñosa | 2 |
| 796 | desdeña | 2 |
| 797 | descuido | 2 |
| 798 | descubre | 2 |
| 799 | desconcierto | 2 |
| 800 | descansar | 2 |
| 801 | delito | 2 |
| 802 | delante | 2 |
| 803 | dejáis | 2 |
| 804 | deja | 2 |
| 805 | deidad | 2 |
| 806 | dedos | 2 |
| 807 | débil | 2 |
| 808 | deba | 2 |
| 809 | dé | 2 |
| 810 | danubio | 2 |
| 811 | cuyas | 2 |
| 812 | cuna | 2 |
| 813 | culpa | 2 |
| 814 | cuello | 2 |
| 815 | cuarenta | 2 |
| 816 | cualquiera | 2 |
| 817 | cual | 2 |
| 818 | crecer | 2 |
| 819 | crece | 2 |
| 820 | cosas | 2 |
| 821 | correr | 2 |
| 822 | coroza | 2 |
| 823 | consuelo | 2 |
| 824 | constante | 2 |
| 825 | confiado | 2 |
| 826 | concede | 2 |
| 827 | compara | 2 |
| 828 | colores | 2 |
| 829 | cohete | 2 |
| 830 | codicia | 2 |
| 831 | ciudad | 2 |
| 832 | cincuenta | 2 |
| 833 | cerca | 2 |
| 834 | cayó | 2 |
| 835 | caudal | 2 |
| 836 | castigo | 2 |
| 837 | cañas | 2 |
| 838 | cáñamo | 2 |
| 839 | canto | 2 |
| 840 | cansado | 2 |
| 841 | campana | 2 |
| 842 | calores | 2 |
| 843 | callado | 2 |
| 844 | callada | 2 |
| 845 | calamidad | 2 |
| 846 | buscas | 2 |
| 847 | busca | 2 |
| 848 | borrasca | 2 |
| 849 | blasones | 2 |
| 850 | blasonar | 2 |
| 851 | blasona | 2 |
| 852 | blasón | 2 |
| 853 | blancura | 2 |
| 854 | avisan | 2 |
| 855 | ausenta | 2 |
| 856 | aunque | 2 |
| 857 | atropella | 2 |
| 858 | arroyos | 2 |
| 859 | arroyo | 2 |
| 860 | armado | 2 |
| 861 | armada | 2 |
| 862 | ardiendo | 2 |
| 863 | arden | 2 |
| 864 | arde | 2 |
| 865 | aquí | 2 |
| 866 | aquellos | 2 |
| 867 | aquel | 2 |
| 868 | apura | 2 |
| 869 | aprisionado | 2 |
| 870 | aprender | 2 |
| 871 | aprende | 2 |
| 872 | anudado | 2 |
| 873 | andar | 2 |
| 874 | anciana | 2 |
| 875 | ancha | 2 |
| 876 | amo | 2 |
| 877 | amenazas | 2 |
| 878 | ambiciosa | 2 |
| 879 | ambición | 2 |
| 880 | amantes | 2 |
| 881 | amando | 2 |
| 882 | amada | 2 |
| 883 | almendro | 2 |
| 884 | aljaba | 2 |
| 885 | alivio | 2 |
| 886 | alimento | 2 |
| 887 | alexi | 2 |
| 888 | aleve | 2 |
| 889 | alegría | 2 |
| 890 | alegre | 2 |
| 891 | alas | 2 |
| 892 | airado | 2 |
| 893 | afectos | 2 |
| 894 | adonde | 2 |
| 895 | admiten | 2 |
| 896 | ademán | 2 |
| 897 | adán | 2 |
| 898 | acero | 2 |
| 899 | acabe | 2 |
| 900 | acabar | 2 |
| 901 | abreviado | 2 |
| 902 | abraso | 2 |
| 903 | abismo | 2 |
| 904 | yerta | 1 |
| 905 | yerra | 1 |
| 906 | yendo | 1 |
| 907 | yelos | 1 |
| 908 | yelo | 1 |
| 909 | vulcano | 1 |
| 910 | vuélvete | 1 |
| 911 | vuelva | 1 |
| 912 | vuela | 1 |
| 913 | voyme | 1 |
| 914 | voy | 1 |
| 915 | voraz | 1 |
| 916 | volvía | 1 |
| 917 | volverte | 1 |
| 918 | volvérmelo | 1 |
| 919 | volverlo | 1 |
| 920 | volverle | 1 |
| 921 | volador | 1 |
| 922 | voces | 1 |
| 923 | vocablo | 1 |
| 924 | vivirán | 1 |
| 925 | vivió | 1 |
| 926 | viviendo | 1 |
| 927 | vives | 1 |
| 928 | viudas | 1 |
| 929 | vistiendo | 1 |
| 930 | visten | 1 |
| 931 | vísperas | 1 |
| 932 | visión | 1 |
| 933 | violenta | 1 |
| 934 | violencia | 1 |
| 935 | vinosas | 1 |
| 936 | vinos | 1 |
| 937 | vine | 1 |
| 938 | vil | 1 |
| 939 | vierte | 1 |
| 940 | vientre | 1 |
| 941 | viéneslo | 1 |
| 942 | viejo | 1 |
| 943 | viejas | 1 |
| 944 | vieja | 1 |
| 945 | vidro | 1 |
| 946 | vid | 1 |
| 947 | victoriosa | 1 |
| 948 | vicios | 1 |
| 949 | víbora | 1 |
| 950 | viaje | 1 |
| 951 | vete | 1 |
| 952 | vesubio | 1 |
| 953 | vestidos | 1 |
| 954 | vestida | 1 |
| 955 | vestía | 1 |
| 956 | veslos | 1 |
| 957 | vertió | 1 |
| 958 | vertido | 1 |
| 959 | veros | 1 |
| 960 | verme | 1 |
| 961 | vergonzosos | 1 |
| 962 | verdadera | 1 |
| 963 | veraste | 1 |
| 964 | verano | 1 |
| 965 | venturoso | 1 |
| 966 | venta | 1 |
| 967 | vengativa | 1 |
| 968 | vengar | 1 |
| 969 | venganzas | 1 |
| 970 | vengadora | 1 |
| 971 | venga | 1 |
| 972 | vendrán | 1 |
| 973 | vendrá | 1 |
| 974 | vendimia | 1 |
| 975 | vendible | 1 |
| 976 | véndanle | 1 |
| 977 | venció | 1 |
| 978 | vencimiento | 1 |
| 979 | vencida | 1 |
| 980 | vencerte | 1 |
| 981 | vencer | 1 |
| 982 | vencedores | 1 |
| 983 | vence | 1 |
| 984 | vellones | 1 |
| 985 | vella | 1 |
| 986 | velilla | 1 |
| 987 | velas | 1 |
| 988 | velador | 1 |
| 989 | ved | 1 |
| 990 | veces | 1 |
| 991 | vea | 1 |
| 992 | vasallaje | 1 |
| 993 | vas | 1 |
| 994 | varios | 1 |
| 995 | vara | 1 |
| 996 | vapores | 1 |
| 997 | vanos | 1 |
| 998 | vano | 1 |
| 999 | valiera | 1 |
| 1000 | valeroso | 1 |
| 1001 | vacía | 1 |
| 1002 | v | 1 |
| 1003 | útil | 1 |
| 1004 | usurera | 1 |
| 1005 | uno | 1 |
| 1006 | unidas | 1 |
| 1007 | única | 1 |
| 1008 | undoso | 1 |
| 1009 | último | 1 |
| 1010 | últimas | 1 |
| 1011 | última | 1 |
| 1012 | ulises | 1 |
| 1013 | ufanos | 1 |
| 1014 | ufana | 1 |
| 1015 | tuyos | 1 |
| 1016 | tuyo | 1 |
| 1017 | tuvo | 1 |
| 1018 | tuvieron | 1 |
| 1019 | tuvieras | 1 |
| 1020 | tuviera | 1 |
| 1021 | tuve | 1 |
| 1022 | turbio | 1 |
| 1023 | tumultos | 1 |
| 1024 | túmulo | 1 |
| 1025 | tudescos | 1 |
| 1026 | truenos | 1 |
| 1027 | trueno | 1 |
| 1028 | truena | 1 |
| 1029 | tropieza | 1 |
| 1030 | tropezará | 1 |
| 1031 | triunfará | 1 |
| 1032 | triunfadora | 1 |
| 1033 | tristes | 1 |
| 1034 | triste | 1 |
| 1035 | triones | 1 |
| 1036 | trinacria | 1 |
| 1037 | tributo | 1 |
| 1038 | tribus | 1 |
| 1039 | trecho | 1 |
| 1040 | traza | 1 |
| 1041 | travieso | 1 |
| 1042 | trata | 1 |
| 1043 | trasgo | 1 |
| 1044 | trapos | 1 |
| 1045 | transitoria | 1 |
| 1046 | tránsito | 1 |
| 1047 | tranquilidad | 1 |
| 1048 | traía | 1 |
| 1049 | trago | 1 |
| 1050 | traes | 1 |
| 1051 | torva | 1 |
| 1052 | torres | 1 |
| 1053 | torno | 1 |
| 1054 | tormento | 1 |
| 1055 | torcido | 1 |
| 1056 | tomá | 1 |
| 1057 | toda | 1 |
| 1058 | tocolas | 1 |
| 1059 | tocinos | 1 |
| 1060 | tocarse | 1 |
| 1061 | tocan | 1 |
| 1062 | toca | 1 |
| 1063 | tizones | 1 |
| 1064 | titubeando | 1 |
| 1065 | tiria | 1 |
| 1066 | tirana | 1 |
| 1067 | tierno | 1 |
| 1068 | tiempos | 1 |
| 1069 | tíber | 1 |
| 1070 | testimonio | 1 |
| 1071 | tesoros | 1 |
| 1072 | terror | 1 |
| 1073 | términos | 1 |
| 1074 | tentación | 1 |
| 1075 | teniendo | 1 |
| 1076 | tenga | 1 |
| 1077 | tenéis | 1 |
| 1078 | tendrán | 1 |
| 1079 | tenaz | 1 |
| 1080 | templarle | 1 |
| 1081 | templanza | 1 |
| 1082 | templando | 1 |
| 1083 | temido | 1 |
| 1084 | temidas | 1 |
| 1085 | temerosos | 1 |
| 1086 | temen | 1 |
| 1087 | temblor | 1 |
| 1088 | temas | 1 |
| 1089 | telas | 1 |
| 1090 | tasado | 1 |
| 1091 | tasaba | 1 |
| 1092 | tarde | 1 |
| 1093 | tantos | 1 |
| 1094 | tántalo | 1 |
| 1095 | tanta | 1 |
| 1096 | también | 1 |
| 1097 | tajo | 1 |
| 1098 | tacto | 1 |
| 1099 | suya | 1 |
| 1100 | sustenta | 1 |
| 1101 | suspendiera | 1 |
| 1102 | surcos | 1 |
| 1103 | supliendo | 1 |
| 1104 | superlativa | 1 |
| 1105 | superior | 1 |
| 1106 | supe | 1 |
| 1107 | sumo | 1 |
| 1108 | sujeto | 1 |
| 1109 | sujetarlo | 1 |
| 1110 | sujeta | 1 |
| 1111 | sufrimiento | 1 |
| 1112 | sufrido | 1 |
| 1113 | suena | 1 |
| 1114 | sucesiones | 1 |
| 1115 | sube | 1 |
| 1116 | suba | 1 |
| 1117 | sospecha | 1 |
| 1118 | sosiego | 1 |
| 1119 | sosegó | 1 |
| 1120 | sortija | 1 |
| 1121 | sorbos | 1 |
| 1122 | soplando | 1 |
| 1123 | soñolientos | 1 |
| 1124 | soñé | 1 |
| 1125 | soñado | 1 |
| 1126 | soñaba | 1 |
| 1127 | soneto | 1 |
| 1128 | somos | 1 |
| 1129 | soltado | 1 |
| 1130 | sollozos | 1 |
| 1131 | solimán | 1 |
| 1132 | solicitud | 1 |
| 1133 | soldado | 1 |
| 1134 | solas | 1 |
| 1135 | soga | 1 |
| 1136 | socorres | 1 |
| 1137 | soberana | 1 |
| 1138 | sitio | 1 |
| 1139 | sirven | 1 |
| 1140 | sirio | 1 |
| 1141 | sirenas | 1 |
| 1142 | silvio | 1 |
| 1143 | siguieron | 1 |
| 1144 | sigues | 1 |
| 1145 | sígote | 1 |
| 1146 | significase | 1 |
| 1147 | significación | 1 |
| 1148 | sígate | 1 |
| 1149 | sigan | 1 |
| 1150 | siga | 1 |
| 1151 | severo | 1 |
| 1152 | seso | 1 |
| 1153 | serpiente | 1 |
| 1154 | sería | 1 |
| 1155 | serenado | 1 |
| 1156 | séquito | 1 |
| 1157 | sepultado | 1 |
| 1158 | sepa | 1 |
| 1159 | señorío | 1 |
| 1160 | señala | 1 |
| 1161 | seña | 1 |
| 1162 | sensitivo | 1 |
| 1163 | seno | 1 |
| 1164 | semejante | 1 |
| 1165 | semblantes | 1 |
| 1166 | selvas | 1 |
| 1167 | selva | 1 |
| 1168 | seguridad | 1 |
| 1169 | segur | 1 |
| 1170 | segundo | 1 |
| 1171 | seguir | 1 |
| 1172 | sediciosos | 1 |
| 1173 | sedición | 1 |
| 1174 | secundan | 1 |
| 1175 | secreto | 1 |
| 1176 | secreta | 1 |
| 1177 | seco | 1 |
| 1178 | sayón | 1 |
| 1179 | saquearon | 1 |
| 1180 | sangriento | 1 |
| 1181 | sangrientas | 1 |
| 1182 | salteada | 1 |
| 1183 | salió | 1 |
| 1184 | salime | 1 |
| 1185 | salido | 1 |
| 1186 | sal | 1 |
| 1187 | sagrado | 1 |
| 1188 | sacudido | 1 |
| 1189 | sacrificios | 1 |
| 1190 | sacrificio | 1 |
| 1191 | sacramento | 1 |
| 1192 | saca | 1 |
| 1193 | sabroso | 1 |
| 1194 | sabrosas | 1 |
| 1195 | sabios | 1 |
| 1196 | sabio | 1 |
| 1197 | sabidor | 1 |
| 1198 | saber | 1 |
| 1199 | saben | 1 |
| 1200 | rústicos | 1 |
| 1201 | rumor | 1 |
| 1202 | ruiseñores | 1 |
| 1203 | ruïdos | 1 |
| 1204 | rúbricas | 1 |
| 1205 | rubrica | 1 |
| 1206 | rubís | 1 |
| 1207 | rubia | 1 |
| 1208 | rostro | 1 |
| 1209 | ronde | 1 |
| 1210 | rompiera | 1 |
| 1211 | romperse | 1 |
| 1212 | rompe | 1 |
| 1213 | roja | 1 |
| 1214 | rogada | 1 |
| 1215 | rodéanle | 1 |
| 1216 | rodea | 1 |
| 1217 | robusta | 1 |
| 1218 | robado | 1 |
| 1219 | rizos | 1 |
| 1220 | rizas | 1 |
| 1221 | riyendo | 1 |
| 1222 | risueño | 1 |
| 1223 | risco | 1 |
| 1224 | río | 1 |
| 1225 | rin | 1 |
| 1226 | rigurosa | 1 |
| 1227 | rígido | 1 |
| 1228 | rígidas | 1 |
| 1229 | rige | 1 |
| 1230 | riego | 1 |
| 1231 | ricos | 1 |
| 1232 | riberas | 1 |
| 1233 | reviente | 1 |
| 1234 | revés | 1 |
| 1235 | retraída | 1 |
| 1236 | retiro | 1 |
| 1237 | retirada | 1 |
| 1238 | retablo | 1 |
| 1239 | resucitola | 1 |
| 1240 | restituyes | 1 |
| 1241 | restaurado | 1 |
| 1242 | respuesta | 1 |
| 1243 | responder | 1 |
| 1244 | responde | 1 |
| 1245 | resplandor | 1 |
| 1246 | resplandecientes | 1 |
| 1247 | resplandeciente | 1 |
| 1248 | resplandece | 1 |
| 1249 | respiras | 1 |
| 1250 | respeto | 1 |
| 1251 | respetando | 1 |
| 1252 | respetaba | 1 |
| 1253 | respeta | 1 |
| 1254 | resistir | 1 |
| 1255 | resistencias | 1 |
| 1256 | rescate | 1 |
| 1257 | rescatar | 1 |
| 1258 | resbalar | 1 |
| 1259 | represéntase | 1 |
| 1260 | reprensiones | 1 |
| 1261 | reposo | 1 |
| 1262 | repitió | 1 |
| 1263 | repite | 1 |
| 1264 | repente | 1 |
| 1265 | repartido | 1 |
| 1266 | renunció | 1 |
| 1267 | renovado | 1 |
| 1268 | rendido | 1 |
| 1269 | remos | 1 |
| 1270 | remontando | 1 |
| 1271 | remite | 1 |
| 1272 | reloj | 1 |
| 1273 | religión | 1 |
| 1274 | relámpago | 1 |
| 1275 | rejones | 1 |
| 1276 | reinó | 1 |
| 1277 | reinar | 1 |
| 1278 | reinaba | 1 |
| 1279 | reina | 1 |
| 1280 | rehusado | 1 |
| 1281 | regó | 1 |
| 1282 | regís | 1 |
| 1283 | regiones | 1 |
| 1284 | región | 1 |
| 1285 | regalo | 1 |
| 1286 | regala | 1 |
| 1287 | refiere | 1 |
| 1288 | reduciéndole | 1 |
| 1289 | reducido | 1 |
| 1290 | recuerdos | 1 |
| 1291 | recuerdo | 1 |
| 1292 | recocido | 1 |
| 1293 | recién | 1 |
| 1294 | recibirlo | 1 |
| 1295 | recibido | 1 |
| 1296 | recíbelo | 1 |
| 1297 | recela | 1 |
| 1298 | recato | 1 |
| 1299 | recatada | 1 |
| 1300 | recata | 1 |
| 1301 | rebozo | 1 |
| 1302 | razonan | 1 |
| 1303 | razonamiento | 1 |
| 1304 | raudal | 1 |
| 1305 | rato | 1 |
| 1306 | raro | 1 |
| 1307 | rama | 1 |
| 1308 | radïante | 1 |
| 1309 | quites | 1 |
| 1310 | quitar | 1 |
| 1311 | quita | 1 |
| 1312 | quisiese | 1 |
| 1313 | quisiera | 1 |
| 1314 | quince | 1 |
| 1315 | quiero | 1 |
| 1316 | quereros | 1 |
| 1317 | querella | 1 |
| 1318 | queréis | 1 |
| 1319 | quejosos | 1 |
| 1320 | quejado | 1 |
| 1321 | quedó | 1 |
| 1322 | quedarás | 1 |
| 1323 | quedado | 1 |
| 1324 | quebrantan | 1 |
| 1325 | quebranta | 1 |
| 1326 | quebrado | 1 |
| 1327 | purpúrea | 1 |
| 1328 | puras | 1 |
| 1329 | punzón | 1 |
| 1330 | punto | 1 |
| 1331 | puntiaguda | 1 |
| 1332 | puntas | 1 |
| 1333 | puesto | 1 |
| 1334 | puédese | 1 |
| 1335 | puebla | 1 |
| 1336 | pudiera | 1 |
| 1337 | publicando | 1 |
| 1338 | pruebo | 1 |
| 1339 | provecho | 1 |
| 1340 | prosigue | 1 |
| 1341 | proprio | 1 |
| 1342 | propria | 1 |
| 1343 | propios | 1 |
| 1344 | propiedades | 1 |
| 1345 | propicios | 1 |
| 1346 | pronunció | 1 |
| 1347 | promete | 1 |
| 1348 | prolijidades | 1 |
| 1349 | profético | 1 |
| 1350 | prodigios | 1 |
| 1351 | procurar | 1 |
| 1352 | procura | 1 |
| 1353 | proción | 1 |
| 1354 | procesos | 1 |
| 1355 | proceloso | 1 |
| 1356 | procede | 1 |
| 1357 | probar | 1 |
| 1358 | privó | 1 |
| 1359 | prisionero | 1 |
| 1360 | princesa | 1 |
| 1361 | primer | 1 |
| 1362 | primaveras | 1 |
| 1363 | previene | 1 |
| 1364 | prevenido | 1 |
| 1365 | pretensiones | 1 |
| 1366 | pretendido | 1 |
| 1367 | presupuesto | 1 |
| 1368 | presumo | 1 |
| 1369 | presumida | 1 |
| 1370 | preso | 1 |
| 1371 | presentes | 1 |
| 1372 | prescribe | 1 |
| 1373 | premios | 1 |
| 1374 | premiarte | 1 |
| 1375 | prefiero | 1 |
| 1376 | precipicios | 1 |
| 1377 | preciada | 1 |
| 1378 | potencia | 1 |
| 1379 | postrera | 1 |
| 1380 | poseo | 1 |
| 1381 | poseerte | 1 |
| 1382 | posea | 1 |
| 1383 | portento | 1 |
| 1384 | porfiando | 1 |
| 1385 | porfiado | 1 |
| 1386 | popular | 1 |
| 1387 | ponto | 1 |
| 1388 | poniente | 1 |
| 1389 | poner | 1 |
| 1390 | pomona | 1 |
| 1391 | podría | 1 |
| 1392 | podrás | 1 |
| 1393 | podido | 1 |
| 1394 | poderosos | 1 |
| 1395 | pocos | 1 |
| 1396 | poca | 1 |
| 1397 | plectro | 1 |
| 1398 | plazos | 1 |
| 1399 | platónica | 1 |
| 1400 | platicas | 1 |
| 1401 | plata | 1 |
| 1402 | piso | 1 |
| 1403 | pisas | 1 |
| 1404 | pisada | 1 |
| 1405 | pirata | 1 |
| 1406 | piramidal | 1 |
| 1407 | pintora | 1 |
| 1408 | pintada | 1 |
| 1409 | pincel | 1 |
| 1410 | pimienta | 1 |
| 1411 | piloto | 1 |
| 1412 | pierdes | 1 |
| 1413 | piense | 1 |
| 1414 | piélago | 1 |
| 1415 | piel | 1 |
| 1416 | pido | 1 |
| 1417 | pidiéndole | 1 |
| 1418 | pides | 1 |
| 1419 | piadosas | 1 |
| 1420 | pïadosa | 1 |
| 1421 | peso | 1 |
| 1422 | pesar | 1 |
| 1423 | persuadiéndola | 1 |
| 1424 | persuadida | 1 |
| 1425 | persuade | 1 |
| 1426 | persona | 1 |
| 1427 | persevera | 1 |
| 1428 | persecución | 1 |
| 1429 | perpetuamente | 1 |
| 1430 | permites | 1 |
| 1431 | permanece | 1 |
| 1432 | perezosos | 1 |
| 1433 | perezoso | 1 |
| 1434 | perdona | 1 |
| 1435 | perdió | 1 |
| 1436 | perdidos | 1 |
| 1437 | perder | 1 |
| 1438 | percibirse | 1 |
| 1439 | pequeña | 1 |
| 1440 | peonza | 1 |
| 1441 | pensión | 1 |
| 1442 | pensativa | 1 |
| 1443 | pensar | 1 |
| 1444 | pensamientos | 1 |
| 1445 | penitencias | 1 |
| 1446 | penitencia | 1 |
| 1447 | penando | 1 |
| 1448 | pelusas | 1 |
| 1449 | peligro | 1 |
| 1450 | peje | 1 |
| 1451 | pegado | 1 |
| 1452 | pedernal | 1 |
| 1453 | pedazos | 1 |
| 1454 | pecados | 1 |
| 1455 | patrimonio | 1 |
| 1456 | pastora | 1 |
| 1457 | pastor | 1 |
| 1458 | pasto | 1 |
| 1459 | pasas | 1 |
| 1460 | pasará | 1 |
| 1461 | pasados | 1 |
| 1462 | pasado | 1 |
| 1463 | partido | 1 |
| 1464 | partida | 1 |
| 1465 | partes | 1 |
| 1466 | parténope | 1 |
| 1467 | paro | 1 |
| 1468 | parlero | 1 |
| 1469 | pariente | 1 |
| 1470 | parecido | 1 |
| 1471 | parece | 1 |
| 1472 | pardas | 1 |
| 1473 | parasismo | 1 |
| 1474 | parar | 1 |
| 1475 | paraíso | 1 |
| 1476 | parado | 1 |
| 1477 | pañales | 1 |
| 1478 | paloma | 1 |
| 1479 | palinuro | 1 |
| 1480 | palatino | 1 |
| 1481 | palacio | 1 |
| 1482 | pájaros | 1 |
| 1483 | pájaro | 1 |
| 1484 | paja | 1 |
| 1485 | pagase | 1 |
| 1486 | padezca | 1 |
| 1487 | padecida | 1 |
| 1488 | padeces | 1 |
| 1489 | padecerás | 1 |
| 1490 | pacífico | 1 |
| 1491 | paciencia | 1 |
| 1492 | pacen | 1 |
| 1493 | oyen | 1 |
| 1494 | ovidio | 1 |
| 1495 | otras | 1 |
| 1496 | ostentó | 1 |
| 1497 | ostentas | 1 |
| 1498 | ostentación | 1 |
| 1499 | osé | 1 |
| 1500 | oscurecida | 1 |
| 1501 | osadía | 1 |
| 1502 | osada | 1 |
| 1503 | ornamento | 1 |
| 1504 | orión | 1 |
| 1505 | origen | 1 |
| 1506 | orejas | 1 |
| 1507 | ordene | 1 |
| 1508 | ordenas | 1 |
| 1509 | orbe | 1 |
| 1510 | oráis | 1 |
| 1511 | opuestas | 1 |
| 1512 | oprimido | 1 |
| 1513 | onda | 1 |
| 1514 | omnipotente | 1 |
| 1515 | omnipotencia | 1 |
| 1516 | olvidaros | 1 |
| 1517 | olvidado | 1 |
| 1518 | oloroso | 1 |
| 1519 | oirán | 1 |
| 1520 | oír | 1 |
| 1521 | ofreces | 1 |
| 1522 | ofrece | 1 |
| 1523 | ofenderos | 1 |
| 1524 | ofendellas | 1 |
| 1525 | ocupa | 1 |
| 1526 | ocultarle | 1 |
| 1527 | occidente | 1 |
| 1528 | ocasionas | 1 |
| 1529 | obligaros | 1 |
| 1530 | obediente | 1 |
| 1531 | obedeces | 1 |
| 1532 | numerosa | 1 |
| 1533 | nuez | 1 |
| 1534 | nuevos | 1 |
| 1535 | nuestras | 1 |
| 1536 | nubloso | 1 |
| 1537 | nublados | 1 |
| 1538 | nube | 1 |
| 1539 | noruega | 1 |
| 1540 | nocturnas | 1 |
| 1541 | noble | 1 |
| 1542 | niño | 1 |
| 1543 | niñez | 1 |
| 1544 | nieves | 1 |
| 1545 | nieto | 1 |
| 1546 | niego | 1 |
| 1547 | niégale | 1 |
| 1548 | nido | 1 |
| 1549 | nevado | 1 |
| 1550 | negaste | 1 |
| 1551 | necios | 1 |
| 1552 | necesidad | 1 |
| 1553 | navegar | 1 |
| 1554 | navega | 1 |
| 1555 | nave | 1 |
| 1556 | naturaleza | 1 |
| 1557 | natural | 1 |
| 1558 | nasón | 1 |
| 1559 | narizado | 1 |
| 1560 | naricísimo | 1 |
| 1561 | narices | 1 |
| 1562 | nadie | 1 |
| 1563 | nadar | 1 |
| 1564 | naciones | 1 |
| 1565 | naciese | 1 |
| 1566 | naciendo | 1 |
| 1567 | naces | 1 |
| 1568 | nace | 1 |
| 1569 | muros | 1 |
| 1570 | muro | 1 |
| 1571 | murmuran | 1 |
| 1572 | murió | 1 |
| 1573 | murallas | 1 |
| 1574 | multiplicas | 1 |
| 1575 | mujeres | 1 |
| 1576 | muestre | 1 |
| 1577 | muestran | 1 |
| 1578 | muertos | 1 |
| 1579 | muertes | 1 |
| 1580 | mueren | 1 |
| 1581 | muchísimo | 1 |
| 1582 | mucha | 1 |
| 1583 | mozo | 1 |
| 1584 | moverse | 1 |
| 1585 | motril | 1 |
| 1586 | motas | 1 |
| 1587 | mostró | 1 |
| 1588 | mosto | 1 |
| 1589 | mosquitos | 1 |
| 1590 | moscos | 1 |
| 1591 | mosa | 1 |
| 1592 | mordió | 1 |
| 1593 | morderle | 1 |
| 1594 | moralidad | 1 |
| 1595 | monumentos | 1 |
| 1596 | monstruo | 1 |
| 1597 | mongibelo | 1 |
| 1598 | monarca | 1 |
| 1599 | molesta | 1 |
| 1600 | modo | 1 |
| 1601 | modestia | 1 |
| 1602 | mocedad | 1 |
| 1603 | mitigar | 1 |
| 1604 | mísero | 1 |
| 1605 | miserias | 1 |
| 1606 | miseria | 1 |
| 1607 | miserable | 1 |
| 1608 | mísera | 1 |
| 1609 | miré | 1 |
| 1610 | miraron | 1 |
| 1611 | mirando | 1 |
| 1612 | mirad | 1 |
| 1613 | mío | 1 |
| 1614 | minas | 1 |
| 1615 | militar | 1 |
| 1616 | milagrosa | 1 |
| 1617 | milagro | 1 |
| 1618 | mil | 1 |
| 1619 | mieses | 1 |
| 1620 | miente | 1 |
| 1621 | miel | 1 |
| 1622 | mezquinos | 1 |
| 1623 | méritos | 1 |
| 1624 | merézcate | 1 |
| 1625 | mereciéndole | 1 |
| 1626 | merecerlo | 1 |
| 1627 | mentirosas | 1 |
| 1628 | mentirosa | 1 |
| 1629 | menester | 1 |
| 1630 | menea | 1 |
| 1631 | memorias | 1 |
| 1632 | melodía | 1 |
| 1633 | melena | 1 |
| 1634 | melancólico | 1 |
| 1635 | mejorado | 1 |
| 1636 | mejora | 1 |
| 1637 | medrosa | 1 |
| 1638 | medallas | 1 |
| 1639 | mecha | 1 |
| 1640 | mayo | 1 |
| 1641 | matizar | 1 |
| 1642 | matiza | 1 |
| 1643 | marivinos | 1 |
| 1644 | mariposas | 1 |
| 1645 | mares | 1 |
| 1646 | marcos | 1 |
| 1647 | marchitan | 1 |
| 1648 | manto | 1 |
| 1649 | mantiene | 1 |
| 1650 | mantenido | 1 |
| 1651 | mandome | 1 |
| 1652 | mande | 1 |
| 1653 | mandas | 1 |
| 1654 | mandar | 1 |
| 1655 | mancillado | 1 |
| 1656 | mancilla | 1 |
| 1657 | manchó | 1 |
| 1658 | manchado | 1 |
| 1659 | mancha | 1 |
| 1660 | maltrata | 1 |
| 1661 | malograrla | 1 |
| 1662 | maestros | 1 |
| 1663 | madre | 1 |
| 1664 | macilentos | 1 |
| 1665 | macilenta | 1 |
| 1666 | luto | 1 |
| 1667 | lustre | 1 |
| 1668 | luquetes | 1 |
| 1669 | luchando | 1 |
| 1670 | luces | 1 |
| 1671 | lope | 1 |
| 1672 | lodo | 1 |
| 1673 | loca | 1 |
| 1674 | lluvioso | 1 |
| 1675 | llueven | 1 |
| 1676 | lloras | 1 |
| 1677 | lloraron | 1 |
| 1678 | llevo | 1 |
| 1679 | llévate | 1 |
| 1680 | llevaré | 1 |
| 1681 | llevara | 1 |
| 1682 | llevada | 1 |
| 1683 | llegue | 1 |
| 1684 | llegó | 1 |
| 1685 | llego | 1 |
| 1686 | llegase | 1 |
| 1687 | llanos | 1 |
| 1688 | llamo | 1 |
| 1689 | llámente | 1 |
| 1690 | llamé | 1 |
| 1691 | llame | 1 |
| 1692 | llámate | 1 |
| 1693 | llamaste | 1 |
| 1694 | llamar | 1 |
| 1695 | llámanle | 1 |
| 1696 | llamado | 1 |
| 1697 | liviana | 1 |
| 1698 | lisa | 1 |
| 1699 | líquido | 1 |
| 1700 | linsojera | 1 |
| 1701 | lino | 1 |
| 1702 | linaje | 1 |
| 1703 | limadas | 1 |
| 1704 | ligero | 1 |
| 1705 | lienzo | 1 |
| 1706 | liendres | 1 |
| 1707 | lid | 1 |
| 1708 | licor | 1 |
| 1709 | lico | 1 |
| 1710 | licenciosa | 1 |
| 1711 | licencia | 1 |
| 1712 | libros | 1 |
| 1713 | libremente | 1 |
| 1714 | libra | 1 |
| 1715 | leyes | 1 |
| 1716 | levante | 1 |
| 1717 | lete | 1 |
| 1718 | león | 1 |
| 1719 | lento | 1 |
| 1720 | lengua | 1 |
| 1721 | legiones | 1 |
| 1722 | legión | 1 |
| 1723 | leandro | 1 |
| 1724 | lazos | 1 |
| 1725 | lava | 1 |
| 1726 | latino | 1 |
| 1727 | larvas | 1 |
| 1728 | largas | 1 |
| 1729 | lanza | 1 |
| 1730 | lamento | 1 |
| 1731 | lamentación | 1 |
| 1732 | lágrima | 1 |
| 1733 | ladrando | 1 |
| 1734 | labradores | 1 |
| 1735 | labrador | 1 |
| 1736 | labra | 1 |
| 1737 | juzgarán | 1 |
| 1738 | justo | 1 |
| 1739 | júpiter | 1 |
| 1740 | juntara | 1 |
| 1741 | juntados | 1 |
| 1742 | juncos | 1 |
| 1743 | jugar | 1 |
| 1744 | juega | 1 |
| 1745 | judea | 1 |
| 1746 | joyas | 1 |
| 1747 | josef | 1 |
| 1748 | jornalero | 1 |
| 1749 | jornal | 1 |
| 1750 | jaspes | 1 |
| 1751 | jarama | 1 |
| 1752 | jamás | 1 |
| 1753 | iv | 1 |
| 1754 | irrevocable | 1 |
| 1755 | irracionales | 1 |
| 1756 | iré | 1 |
| 1757 | iras | 1 |
| 1758 | invisible | 1 |
| 1759 | invidiosa | 1 |
| 1760 | invidias | 1 |
| 1761 | invidiada | 1 |
| 1762 | inventaran | 1 |
| 1763 | inunda | 1 |
| 1764 | introduciendo | 1 |
| 1765 | interesada | 1 |
| 1766 | intercadencia | 1 |
| 1767 | inteligible | 1 |
| 1768 | intelectual | 1 |
| 1769 | insultos | 1 |
| 1770 | inscripción | 1 |
| 1771 | insano | 1 |
| 1772 | insana | 1 |
| 1773 | inquiriendo | 1 |
| 1774 | inquietud | 1 |
| 1775 | inquieta | 1 |
| 1776 | inobediencia | 1 |
| 1777 | inmortales | 1 |
| 1778 | inmortal | 1 |
| 1779 | injustas | 1 |
| 1780 | injurias | 1 |
| 1781 | injuriar | 1 |
| 1782 | ingrata | 1 |
| 1783 | influyendo | 1 |
| 1784 | influye | 1 |
| 1785 | inflama | 1 |
| 1786 | infinito | 1 |
| 1787 | indultos | 1 |
| 1788 | indignada | 1 |
| 1789 | indias | 1 |
| 1790 | inclina | 1 |
| 1791 | incierto | 1 |
| 1792 | imprenta | 1 |
| 1793 | importuna | 1 |
| 1794 | importa | 1 |
| 1795 | impensada | 1 |
| 1796 | imiten | 1 |
| 1797 | imitación | 1 |
| 1798 | imagina | 1 |
| 1799 | ilustre | 1 |
| 1800 | ilusión | 1 |
| 1801 | iii | 1 |
| 1802 | igualmente | 1 |
| 1803 | igualas | 1 |
| 1804 | ignoras | 1 |
| 1805 | iglesia | 1 |
| 1806 | idolatrando | 1 |
| 1807 | ícaro | 1 |
| 1808 | huyó | 1 |
| 1809 | huyes | 1 |
| 1810 | huyen | 1 |
| 1811 | hurtó | 1 |
| 1812 | hurtando | 1 |
| 1813 | hungría | 1 |
| 1814 | humosa | 1 |
| 1815 | humores | 1 |
| 1816 | humor | 1 |
| 1817 | humildemente | 1 |
| 1818 | humedezco | 1 |
| 1819 | humedecida | 1 |
| 1820 | humanos | 1 |
| 1821 | huido | 1 |
| 1822 | huesos | 1 |
| 1823 | huerto | 1 |
| 1824 | hubieran | 1 |
| 1825 | hospeda | 1 |
| 1826 | horrores | 1 |
| 1827 | honrosa | 1 |
| 1828 | hombres | 1 |
| 1829 | hoja | 1 |
| 1830 | hoguera | 1 |
| 1831 | hipócritas | 1 |
| 1832 | hinchado | 1 |
| 1833 | hile | 1 |
| 1834 | hijuelos | 1 |
| 1835 | hija | 1 |
| 1836 | hierba | 1 |
| 1837 | hielos | 1 |
| 1838 | hibla | 1 |
| 1839 | hervores | 1 |
| 1840 | hermosos | 1 |
| 1841 | herirme | 1 |
| 1842 | herido | 1 |
| 1843 | heredada | 1 |
| 1844 | helarle | 1 |
| 1845 | helado | 1 |
| 1846 | hecho | 1 |
| 1847 | hechicera | 1 |
| 1848 | haz | 1 |
| 1849 | hayan | 1 |
| 1850 | hambrienta | 1 |
| 1851 | hambre | 1 |
| 1852 | hálleme | 1 |
| 1853 | hallé | 1 |
| 1854 | hallas | 1 |
| 1855 | hallaré | 1 |
| 1856 | halla | 1 |
| 1857 | hago | 1 |
| 1858 | hado | 1 |
| 1859 | haciendo | 1 |
| 1860 | hacienda | 1 |
| 1861 | hacia | 1 |
| 1862 | hacerte | 1 |
| 1863 | hacerme | 1 |
| 1864 | habrás | 1 |
| 1865 | habrán | 1 |
| 1866 | habitadas | 1 |
| 1867 | habitación | 1 |
| 1868 | habita | 1 |
| 1869 | habiéndola | 1 |
| 1870 | habiendo | 1 |
| 1871 | había | 1 |
| 1872 | haberte | 1 |
| 1873 | haberse | 1 |
| 1874 | gustoso | 1 |
| 1875 | gula | 1 |
| 1876 | guijas | 1 |
| 1877 | guedejas | 1 |
| 1878 | guardaría | 1 |
| 1879 | guardar | 1 |
| 1880 | guardándole | 1 |
| 1881 | guardan | 1 |
| 1882 | guardado | 1 |
| 1883 | guarda | 1 |
| 1884 | guadañas | 1 |
| 1885 | grosera | 1 |
| 1886 | gravedad | 1 |
| 1887 | granjear | 1 |
| 1888 | granizado | 1 |
| 1889 | grandezas | 1 |
| 1890 | grandes | 1 |
| 1891 | grana | 1 |
| 1892 | grabadas | 1 |
| 1893 | gozoso | 1 |
| 1894 | gozos | 1 |
| 1895 | gozo | 1 |
| 1896 | gozaba | 1 |
| 1897 | golfos | 1 |
| 1898 | gobierna | 1 |
| 1899 | glotón | 1 |
| 1900 | gloriosamente | 1 |
| 1901 | gimió | 1 |
| 1902 | gimes | 1 |
| 1903 | gigante | 1 |
| 1904 | gentil | 1 |
| 1905 | generoso | 1 |
| 1906 | generosas | 1 |
| 1907 | gaznate | 1 |
| 1908 | gasta | 1 |
| 1909 | ganguea | 1 |
| 1910 | ganapán | 1 |
| 1911 | ganados | 1 |
| 1912 | gana | 1 |
| 1913 | gallarda | 1 |
| 1914 | galera | 1 |
| 1915 | galán | 1 |
| 1916 | gala | 1 |
| 1917 | futuro | 1 |
| 1918 | furor | 1 |
| 1919 | furia | 1 |
| 1920 | funesta | 1 |
| 1921 | fundido | 1 |
| 1922 | fulminaron | 1 |
| 1923 | fulminante | 1 |
| 1924 | fulminando | 1 |
| 1925 | fulminan | 1 |
| 1926 | fuí | 1 |
| 1927 | fugitivo | 1 |
| 1928 | fuga | 1 |
| 1929 | fuerzas | 1 |
| 1930 | fueras | 1 |
| 1931 | fuentes | 1 |
| 1932 | fruto | 1 |
| 1933 | frío | 1 |
| 1934 | fresno | 1 |
| 1935 | frenética | 1 |
| 1936 | fragilidad | 1 |
| 1937 | forzosa | 1 |
| 1938 | formidables | 1 |
| 1939 | formidable | 1 |
| 1940 | formaran | 1 |
| 1941 | formar | 1 |
| 1942 | forjó | 1 |
| 1943 | fluctuando | 1 |
| 1944 | flori | 1 |
| 1945 | florecidas | 1 |
| 1946 | flecha | 1 |
| 1947 | flaqueza | 1 |
| 1948 | firme | 1 |
| 1949 | finos | 1 |
| 1950 | fingida | 1 |
| 1951 | finge | 1 |
| 1952 | filosofía | 1 |
| 1953 | figura | 1 |
| 1954 | fiesta | 1 |
| 1955 | fiero | 1 |
| 1956 | fieras | 1 |
| 1957 | fiera | 1 |
| 1958 | fieles | 1 |
| 1959 | fiel | 1 |
| 1960 | fía | 1 |
| 1961 | festivo | 1 |
| 1962 | feroz | 1 |
| 1963 | fénix | 1 |
| 1964 | felicidades | 1 |
| 1965 | fecundo | 1 |
| 1966 | fecunda | 1 |
| 1967 | fe | 1 |
| 1968 | favor | 1 |
| 1969 | fatal | 1 |
| 1970 | farsante | 1 |
| 1971 | fantásticas | 1 |
| 1972 | fantasmas | 1 |
| 1973 | fama | 1 |
| 1974 | faltar | 1 |
| 1975 | fáltanme | 1 |
| 1976 | falsa | 1 |
| 1977 | fallecida | 1 |
| 1978 | faldas | 1 |
| 1979 | fajina | 1 |
| 1980 | faetón | 1 |
| 1981 | facinorosas | 1 |
| 1982 | fácil | 1 |
| 1983 | facción | 1 |
| 1984 | fabricaste | 1 |
| 1985 | fabrican | 1 |
| 1986 | fabricado | 1 |
| 1987 | fabios | 1 |
| 1988 | fabio | 1 |
| 1989 | extrañas | 1 |
| 1990 | exterior | 1 |
| 1991 | extendida | 1 |
| 1992 | éxtasi | 1 |
| 1993 | explayose | 1 |
| 1994 | exhorta | 1 |
| 1995 | exhalando | 1 |
| 1996 | exhalación | 1 |
| 1997 | exentos | 1 |
| 1998 | exclama | 1 |
| 1999 | exceso | 1 |
| 2000 | exceda | 1 |
| 2001 | examinando | 1 |
| 2002 | examina | 1 |
| 2003 | examen | 1 |
| 2004 | exageraciones | 1 |
| 2005 | exageración | 1 |
| 2006 | evasión | 1 |
| 2007 | eternidad | 1 |
| 2008 | eternamente | 1 |
| 2009 | estuve | 1 |
| 2010 | estudien | 1 |
| 2011 | estudiante | 1 |
| 2012 | estudia | 1 |
| 2013 | estuche | 1 |
| 2014 | estremeció | 1 |
| 2015 | estrellado | 1 |
| 2016 | estrecho | 1 |
| 2017 | estrechas | 1 |
| 2018 | estorba | 1 |
| 2019 | estimación | 1 |
| 2020 | estatua | 1 |
| 2021 | estas | 1 |
| 2022 | estaré | 1 |
| 2023 | están | 1 |
| 2024 | estame | 1 |
| 2025 | estado | 1 |
| 2026 | estacada | 1 |
| 2027 | estaba | 1 |
| 2028 | esquiva | 1 |
| 2029 | espumosos | 1 |
| 2030 | espumoso | 1 |
| 2031 | espuma | 1 |
| 2032 | espolón | 1 |
| 2033 | esperanzas | 1 |
| 2034 | esperanza | 1 |
| 2035 | española | 1 |
| 2036 | españas | 1 |
| 2037 | espantoso | 1 |
| 2038 | espanto | 1 |
| 2039 | espadaña | 1 |
| 2040 | espacio | 1 |
| 2041 | esos | 1 |
| 2042 | eso | 1 |
| 2043 | esmeril | 1 |
| 2044 | esfuerzo | 1 |
| 2045 | escuro | 1 |
| 2046 | escuras | 1 |
| 2047 | escupido | 1 |
| 2048 | escucho | 1 |
| 2049 | escucha | 1 |
| 2050 | escuadrón | 1 |
| 2051 | escritor | 1 |
| 2052 | escrito | 1 |
| 2053 | escribió | 1 |
| 2054 | escriba | 1 |
| 2055 | escorias | 1 |
| 2056 | escondido | 1 |
| 2057 | escondidas | 1 |
| 2058 | esconda | 1 |
| 2059 | esclavo | 1 |
| 2060 | esclavitud | 1 |
| 2061 | escasamente | 1 |
| 2062 | escarmientos | 1 |
| 2063 | escándalo | 1 |
| 2064 | escandalizan | 1 |
| 2065 | escalas | 1 |
| 2066 | error | 1 |
| 2067 | errada | 1 |
| 2068 | erizado | 1 |
| 2069 | equivocado | 1 |
| 2070 | equivoca | 1 |
| 2071 | envuelta | 1 |
| 2072 | envío | 1 |
| 2073 | envidioso | 1 |
| 2074 | envidiosas | 1 |
| 2075 | envidien | 1 |
| 2076 | entretenme | 1 |
| 2077 | entretenidos | 1 |
| 2078 | entré | 1 |
| 2079 | entierra | 1 |
| 2080 | entena | 1 |
| 2081 | ensordezca | 1 |
| 2082 | ensordeces | 1 |
| 2083 | ensangrientan | 1 |
| 2084 | enojo | 1 |
| 2085 | ennobleciste | 1 |
| 2086 | ennoblecido | 1 |
| 2087 | ennoblecerte | 1 |
| 2088 | ennegrecida | 1 |
| 2089 | enmiendan | 1 |
| 2090 | enlutada | 1 |
| 2091 | enjuto | 1 |
| 2092 | enhiesto | 1 |
| 2093 | engendre | 1 |
| 2094 | engañoso | 1 |
| 2095 | engañosas | 1 |
| 2096 | engañas | 1 |
| 2097 | engañada | 1 |
| 2098 | enfurece | 1 |
| 2099 | enfermedad | 1 |
| 2100 | enferma | 1 |
| 2101 | enemigo | 1 |
| 2102 | enemiga | 1 |
| 2103 | encogido | 1 |
| 2104 | encina | 1 |
| 2105 | encierra | 1 |
| 2106 | encerramiento | 1 |
| 2107 | encendieron | 1 |
| 2108 | encelado | 1 |
| 2109 | encarcelada | 1 |
| 2110 | encarado | 1 |
| 2111 | encaneces | 1 |
| 2112 | encaminado | 1 |
| 2113 | encajo | 1 |
| 2114 | encájate | 1 |
| 2115 | encadena | 1 |
| 2116 | enajena | 1 |
| 2117 | enaguas | 1 |
| 2118 | empiézola | 1 |
| 2119 | empezar | 1 |
| 2120 | empecé | 1 |
| 2121 | eminentes | 1 |
| 2122 | embudo | 1 |
| 2123 | embates | 1 |
| 2124 | embaraza | 1 |
| 2125 | embajadora | 1 |
| 2126 | ellos | 1 |
| 2127 | ellas | 1 |
| 2128 | elemento | 1 |
| 2129 | elefante | 1 |
| 2130 | elección | 1 |
| 2131 | ejemplos | 1 |
| 2132 | ejecutivo | 1 |
| 2133 | ejecución | 1 |
| 2134 | edades | 1 |
| 2135 | echa | 1 |
| 2136 | e | 1 |
| 2137 | duro | 1 |
| 2138 | durmiese | 1 |
| 2139 | durmiendo | 1 |
| 2140 | duras | 1 |
| 2141 | duración | 1 |
| 2142 | duplicado | 1 |
| 2143 | duermo | 1 |
| 2144 | duerma | 1 |
| 2145 | duele | 1 |
| 2146 | dudosos | 1 |
| 2147 | dudas | 1 |
| 2148 | doseles | 1 |
| 2149 | dormido | 1 |
| 2150 | dormida | 1 |
| 2151 | dorada | 1 |
| 2152 | doña | 1 |
| 2153 | dones | 1 |
| 2154 | dónde | 1 |
| 2155 | doloroso | 1 |
| 2156 | dolencia | 1 |
| 2157 | doctrina | 1 |
| 2158 | doctas | 1 |
| 2159 | doce | 1 |
| 2160 | doblado | 1 |
| 2161 | divina | 1 |
| 2162 | dividido | 1 |
| 2163 | divide | 1 |
| 2164 | divertida | 1 |
| 2165 | diversos | 1 |
| 2166 | diversas | 1 |
| 2167 | distrito | 1 |
| 2168 | dispuesto | 1 |
| 2169 | dispensas | 1 |
| 2170 | dispensan | 1 |
| 2171 | disparado | 1 |
| 2172 | disimulan | 1 |
| 2173 | disimula | 1 |
| 2174 | discurso | 1 |
| 2175 | discurren | 1 |
| 2176 | disculpa | 1 |
| 2177 | discreta | 1 |
| 2178 | disciplinante | 1 |
| 2179 | direlo | 1 |
| 2180 | dirá | 1 |
| 2181 | diole | 1 |
| 2182 | diolas | 1 |
| 2183 | dineros | 1 |
| 2184 | dinero | 1 |
| 2185 | diluvios | 1 |
| 2186 | diluvio | 1 |
| 2187 | diligencia | 1 |
| 2188 | dile | 1 |
| 2189 | dilató | 1 |
| 2190 | dilato | 1 |
| 2191 | dilatas | 1 |
| 2192 | dilata | 1 |
| 2193 | dije | 1 |
| 2194 | digas | 1 |
| 2195 | difuntos | 1 |
| 2196 | difuntas | 1 |
| 2197 | diferiste | 1 |
| 2198 | diferente | 1 |
| 2199 | diferencia | 1 |
| 2200 | diéronle | 1 |
| 2201 | diciendo | 1 |
| 2202 | diciembre | 1 |
| 2203 | dichosa | 1 |
| 2204 | diamantes | 1 |
| 2205 | diablo | 1 |
| 2206 | devana | 1 |
| 2207 | detenido | 1 |
| 2208 | detenida | 1 |
| 2209 | detenga | 1 |
| 2210 | detenerse | 1 |
| 2211 | desvíos | 1 |
| 2212 | desvío | 1 |
| 2213 | desvíes | 1 |
| 2214 | desvía | 1 |
| 2215 | desvelo | 1 |
| 2216 | destrozos | 1 |
| 2217 | destrozo | 1 |
| 2218 | destinado | 1 |
| 2219 | destilando | 1 |
| 2220 | destierra | 1 |
| 2221 | desterrado | 1 |
| 2222 | desquito | 1 |
| 2223 | despuebla | 1 |
| 2224 | desprecios | 1 |
| 2225 | desprecié | 1 |
| 2226 | despreciarlo | 1 |
| 2227 | despreciado | 1 |
| 2228 | despojado | 1 |
| 2229 | despiertos | 1 |
| 2230 | despierte | 1 |
| 2231 | desperté | 1 |
| 2232 | desperdicios | 1 |
| 2233 | despedazada | 1 |
| 2234 | desordenado | 1 |
| 2235 | desorden | 1 |
| 2236 | desnudeces | 1 |
| 2237 | desnudas | 1 |
| 2238 | desnúdame | 1 |
| 2239 | desmoronados | 1 |
| 2240 | desmentirá | 1 |
| 2241 | desmayo | 1 |
| 2242 | deslizas | 1 |
| 2243 | deslazas | 1 |
| 2244 | desigual | 1 |
| 2245 | desiertos | 1 |
| 2246 | deshecho | 1 |
| 2247 | deshabitado | 1 |
| 2248 | desfigura | 1 |
| 2249 | desesperado | 1 |
| 2250 | desesperación | 1 |
| 2251 | deseos | 1 |
| 2252 | desenojada | 1 |
| 2253 | desengaños | 1 |
| 2254 | desengaño | 1 |
| 2255 | desengaña | 1 |
| 2256 | desenfrenado | 1 |
| 2257 | desecha | 1 |
| 2258 | desearla | 1 |
| 2259 | deseando | 1 |
| 2260 | deseado | 1 |
| 2261 | desdiga | 1 |
| 2262 | desdichada | 1 |
| 2263 | desdenes | 1 |
| 2264 | desde | 1 |
| 2265 | descripción | 1 |
| 2266 | descortés | 1 |
| 2267 | desconsuelo | 1 |
| 2268 | desconocida | 1 |
| 2269 | descoloridos | 1 |
| 2270 | descoloridas | 1 |
| 2271 | descolorida | 1 |
| 2272 | descifra | 1 |
| 2273 | descaminar | 1 |
| 2274 | descaminado | 1 |
| 2275 | descaminada | 1 |
| 2276 | desatar | 1 |
| 2277 | desatados | 1 |
| 2278 | desatado | 1 |
| 2279 | desatada | 1 |
| 2280 | desata | 1 |
| 2281 | desangrado | 1 |
| 2282 | desandar | 1 |
| 2283 | desacordado | 1 |
| 2284 | desabrigan | 1 |
| 2285 | derretir | 1 |
| 2286 | derramo | 1 |
| 2287 | derramado | 1 |
| 2288 | derecho | 1 |
| 2289 | demonio | 1 |
| 2290 | demás | 1 |
| 2291 | dellas | 1 |
| 2292 | della | 1 |
| 2293 | delirio | 1 |
| 2294 | delincuente | 1 |
| 2295 | delicioso | 1 |
| 2296 | delgada | 1 |
| 2297 | deleitar | 1 |
| 2298 | déjase | 1 |
| 2299 | dejarle | 1 |
| 2300 | dejarán | 1 |
| 2301 | dejará | 1 |
| 2302 | dejar | 1 |
| 2303 | defuera | 1 |
| 2304 | definiendo | 1 |
| 2305 | defiende | 1 |
| 2306 | decios | 1 |
| 2307 | decente | 1 |
| 2308 | debido | 1 |
| 2309 | debidas | 1 |
| 2310 | deben | 1 |
| 2311 | debe | 1 |
| 2312 | debajo | 1 |
| 2313 | darme | 1 |
| 2314 | darlo | 1 |
| 2315 | dar | 1 |
| 2316 | dando | 1 |
| 2317 | dama | 1 |
| 2318 | dádivas | 1 |
| 2319 | dádiva | 1 |
| 2320 | cuyo | 1 |
| 2321 | cuya | 1 |
| 2322 | curios | 1 |
| 2323 | curada | 1 |
| 2324 | cumplidos | 1 |
| 2325 | culpas | 1 |
| 2326 | cuitado | 1 |
| 2327 | cueva | 1 |
| 2328 | cuerdas | 1 |
| 2329 | cuerda | 1 |
| 2330 | cuentes | 1 |
| 2331 | cuentas | 1 |
| 2332 | cuece | 1 |
| 2333 | cucurucho | 1 |
| 2334 | cubrió | 1 |
| 2335 | cubilete | 1 |
| 2336 | cuantos | 1 |
| 2337 | cuántas | 1 |
| 2338 | cuánta | 1 |
| 2339 | cuanta | 1 |
| 2340 | cualquier | 1 |
| 2341 | cuál | 1 |
| 2342 | cruentos | 1 |
| 2343 | cruenta | 1 |
| 2344 | crueles | 1 |
| 2345 | cruel | 1 |
| 2346 | cristales | 1 |
| 2347 | cristal | 1 |
| 2348 | criaturas | 1 |
| 2349 | criado | 1 |
| 2350 | criada | 1 |
| 2351 | crespa | 1 |
| 2352 | crédito | 1 |
| 2353 | creció | 1 |
| 2354 | creciendo | 1 |
| 2355 | crecerte | 1 |
| 2356 | creas | 1 |
| 2357 | coyuntura | 1 |
| 2358 | costumbres | 1 |
| 2359 | costa | 1 |
| 2360 | cosechas | 1 |
| 2361 | corvo | 1 |
| 2362 | corto | 1 |
| 2363 | cortesía | 1 |
| 2364 | corte | 1 |
| 2365 | cortado | 1 |
| 2366 | corta | 1 |
| 2367 | corsarios | 1 |
| 2368 | corre | 1 |
| 2369 | corpulento | 1 |
| 2370 | coronado | 1 |
| 2371 | coronada | 1 |
| 2372 | corazones | 1 |
| 2373 | coral | 1 |
| 2374 | copia | 1 |
| 2375 | conviene | 1 |
| 2376 | convida | 1 |
| 2377 | conversación | 1 |
| 2378 | convencida | 1 |
| 2379 | contrito | 1 |
| 2380 | contrario | 1 |
| 2381 | contrapuntos | 1 |
| 2382 | continúa | 1 |
| 2383 | contento | 1 |
| 2384 | consumo | 1 |
| 2385 | consumir | 1 |
| 2386 | consumido | 1 |
| 2387 | consume | 1 |
| 2388 | cónsules | 1 |
| 2389 | consuelos | 1 |
| 2390 | constantes | 1 |
| 2391 | considero | 1 |
| 2392 | considerándole | 1 |
| 2393 | conquistada | 1 |
| 2394 | conozco | 1 |
| 2395 | conoces | 1 |
| 2396 | conocerte | 1 |
| 2397 | conoceros | 1 |
| 2398 | conocer | 1 |
| 2399 | conjuro | 1 |
| 2400 | conjetura | 1 |
| 2401 | congojoso | 1 |
| 2402 | congojosa | 1 |
| 2403 | confuso | 1 |
| 2404 | confusión | 1 |
| 2405 | confundirle | 1 |
| 2406 | confines | 1 |
| 2407 | condición | 1 |
| 2408 | concertaste | 1 |
| 2409 | concediste | 1 |
| 2410 | concédele | 1 |
| 2411 | comprar | 1 |
| 2412 | compra | 1 |
| 2413 | compiten | 1 |
| 2414 | compite | 1 |
| 2415 | compita | 1 |
| 2416 | competilla | 1 |
| 2417 | competidor | 1 |
| 2418 | comparación | 1 |
| 2419 | compadecidos | 1 |
| 2420 | cometió | 1 |
| 2421 | cometa | 1 |
| 2422 | comer | 1 |
| 2423 | come | 1 |
| 2424 | combatido | 1 |
| 2425 | combatida | 1 |
| 2426 | combate | 1 |
| 2427 | colora | 1 |
| 2428 | codiciaron | 1 |
| 2429 | cocodrilo | 1 |
| 2430 | cobrador | 1 |
| 2431 | cobardes | 1 |
| 2432 | cobarde | 1 |
| 2433 | clemencia | 1 |
| 2434 | claustros | 1 |
| 2435 | claro | 1 |
| 2436 | clamoreó | 1 |
| 2437 | civil | 1 |
| 2438 | ciudadanos | 1 |
| 2439 | cítaras | 1 |
| 2440 | círculos | 1 |
| 2441 | círculo | 1 |
| 2442 | cipreses | 1 |
| 2443 | cimientos | 1 |
| 2444 | cimiento | 1 |
| 2445 | cierto | 1 |
| 2446 | cierta | 1 |
| 2447 | cierro | 1 |
| 2448 | chicas | 1 |
| 2449 | chapitel | 1 |
| 2450 | cetro | 1 |
| 2451 | césar | 1 |
| 2452 | cerúleos | 1 |
| 2453 | cerrar | 1 |
| 2454 | cerrado | 1 |
| 2455 | ceremonias | 1 |
| 2456 | cercano | 1 |
| 2457 | cercado | 1 |
| 2458 | ceñir | 1 |
| 2459 | ceñido | 1 |
| 2460 | centelleante | 1 |
| 2461 | centellas | 1 |
| 2462 | centella | 1 |
| 2463 | celosos | 1 |
| 2464 | celosa | 1 |
| 2465 | celos | 1 |
| 2466 | celo | 1 |
| 2467 | cedros | 1 |
| 2468 | cede | 1 |
| 2469 | cebo | 1 |
| 2470 | cavan | 1 |
| 2471 | cautelosos | 1 |
| 2472 | cautela | 1 |
| 2473 | castiga | 1 |
| 2474 | caspa | 1 |
| 2475 | casimiro | 1 |
| 2476 | casa | 1 |
| 2477 | carrera | 1 |
| 2478 | carmín | 1 |
| 2479 | carlos | 1 |
| 2480 | caricia | 1 |
| 2481 | cargó | 1 |
| 2482 | cargado | 1 |
| 2483 | cárdenas | 1 |
| 2484 | caracteres | 1 |
| 2485 | cara | 1 |
| 2486 | capaces | 1 |
| 2487 | cantarle | 1 |
| 2488 | cansados | 1 |
| 2489 | cansa | 1 |
| 2490 | canoras | 1 |
| 2491 | canicular | 1 |
| 2492 | canícula | 1 |
| 2493 | can | 1 |
| 2494 | campos | 1 |
| 2495 | campañas | 1 |
| 2496 | caminar | 1 |
| 2497 | caminado | 1 |
| 2498 | camina | 1 |
| 2499 | calor | 1 |
| 2500 | callados | 1 |
| 2501 | calladas | 1 |
| 2502 | cáliz | 1 |
| 2503 | calendario | 1 |
| 2504 | cálculo | 1 |
| 2505 | caimán | 1 |
| 2506 | caerá | 1 |
| 2507 | caducamente | 1 |
| 2508 | caduca | 1 |
| 2509 | cadena | 1 |
| 2510 | cabeza | 1 |
| 2511 | cabellos | 1 |
| 2512 | cabañas | 1 |
| 2513 | cabaña | 1 |
| 2514 | caballo | 1 |
| 2515 | buscado | 1 |
| 2516 | burlarme | 1 |
| 2517 | burlando | 1 |
| 2518 | búrlame | 1 |
| 2519 | burladora | 1 |
| 2520 | burlador | 1 |
| 2521 | burla | 1 |
| 2522 | bultos | 1 |
| 2523 | bulto | 1 |
| 2524 | bujía | 1 |
| 2525 | buida | 1 |
| 2526 | buena | 1 |
| 2527 | buen | 1 |
| 2528 | bruja | 1 |
| 2529 | bríos | 1 |
| 2530 | brío | 1 |
| 2531 | brilla | 1 |
| 2532 | brazos | 1 |
| 2533 | bramidos | 1 |
| 2534 | bosque | 1 |
| 2535 | borres | 1 |
| 2536 | borrachas | 1 |
| 2537 | bóreas | 1 |
| 2538 | boloñés | 1 |
| 2539 | boga | 1 |
| 2540 | blando | 1 |
| 2541 | blandas | 1 |
| 2542 | blanda | 1 |
| 2543 | blancos | 1 |
| 2544 | blancas | 1 |
| 2545 | beso | 1 |
| 2546 | bendito | 1 |
| 2547 | bellísima | 1 |
| 2548 | belleza | 1 |
| 2549 | belicoso | 1 |
| 2550 | beldad | 1 |
| 2551 | bebiste | 1 |
| 2552 | bebiéndoos | 1 |
| 2553 | bebido | 1 |
| 2554 | bebía | 1 |
| 2555 | bébese | 1 |
| 2556 | beberán | 1 |
| 2557 | bebéis | 1 |
| 2558 | bato | 1 |
| 2559 | batallas | 1 |
| 2560 | básteme | 1 |
| 2561 | bastábale | 1 |
| 2562 | barbado | 1 |
| 2563 | bañas | 1 |
| 2564 | baña | 1 |
| 2565 | balcones | 1 |
| 2566 | bajel | 1 |
| 2567 | baje | 1 |
| 2568 | baja | 1 |
| 2569 | bailarán | 1 |
| 2570 | badajo | 1 |
| 2571 | báculo | 1 |
| 2572 | bachillera | 1 |
| 2573 | azumbres | 1 |
| 2574 | azufre | 1 |
| 2575 | azucena | 1 |
| 2576 | azúcar | 1 |
| 2577 | azadas | 1 |
| 2578 | ayuno | 1 |
| 2579 | aviso | 1 |
| 2580 | aves | 1 |
| 2581 | aventino | 1 |
| 2582 | avara | 1 |
| 2583 | autor | 1 |
| 2584 | ausencias | 1 |
| 2585 | ausencia | 1 |
| 2586 | auroras | 1 |
| 2587 | aún | 1 |
| 2588 | augusta | 1 |
| 2589 | atrevimiento | 1 |
| 2590 | atreverte | 1 |
| 2591 | atreverse | 1 |
| 2592 | atreve | 1 |
| 2593 | atrás | 1 |
| 2594 | átomos | 1 |
| 2595 | atienden | 1 |
| 2596 | atiende | 1 |
| 2597 | atienda | 1 |
| 2598 | atesora | 1 |
| 2599 | asustado | 1 |
| 2600 | asuntos | 1 |
| 2601 | astros | 1 |
| 2602 | aspiraste | 1 |
| 2603 | áspid | 1 |
| 2604 | ásperos | 1 |
| 2605 | áspero | 1 |
| 2606 | ásperas | 1 |
| 2607 | aspecto | 1 |
| 2608 | asistió | 1 |
| 2609 | asistidos | 1 |
| 2610 | asiste | 1 |
| 2611 | asiento | 1 |
| 2612 | así | 1 |
| 2613 | asco | 1 |
| 2614 | asaltado | 1 |
| 2615 | arturo | 1 |
| 2616 | artificiosa | 1 |
| 2617 | artificial | 1 |
| 2618 | articulada | 1 |
| 2619 | arte | 1 |
| 2620 | arriba | 1 |
| 2621 | arrepentir | 1 |
| 2622 | arrepentimiento | 1 |
| 2623 | arrendajo | 1 |
| 2624 | arrastro | 1 |
| 2625 | arrastra | 1 |
| 2626 | arma | 1 |
| 2627 | argonauta | 1 |
| 2628 | arena | 1 |
| 2629 | ardo | 1 |
| 2630 | ardientes | 1 |
| 2631 | ardido | 1 |
| 2632 | árbitro | 1 |
| 2633 | aranjuez | 1 |
| 2634 | aragón | 1 |
| 2635 | ara | 1 |
| 2636 | aquesta | 1 |
| 2637 | aprovechas | 1 |
| 2638 | aprisiona | 1 |
| 2639 | apresurado | 1 |
| 2640 | aprendiese | 1 |
| 2641 | aprended | 1 |
| 2642 | aplauso | 1 |
| 2643 | aplaudió | 1 |
| 2644 | apenas | 1 |
| 2645 | aparta | 1 |
| 2646 | apariencia | 1 |
| 2647 | aparentes | 1 |
| 2648 | apago | 1 |
| 2649 | apagar | 1 |
| 2650 | apagada | 1 |
| 2651 | apaga | 1 |
| 2652 | apacibles | 1 |
| 2653 | añudado | 1 |
| 2654 | añadir | 1 |
| 2655 | antonio | 1 |
| 2656 | antiguo | 1 |
| 2657 | anticiparse | 1 |
| 2658 | antaños | 1 |
| 2659 | ansioso | 1 |
| 2660 | ansias | 1 |
| 2661 | animoso | 1 |
| 2662 | animado | 1 |
| 2663 | animada | 1 |
| 2664 | ánima | 1 |
| 2665 | anhélito | 1 |
| 2666 | anhelas | 1 |
| 2667 | anhelar | 1 |
| 2668 | anhelando | 1 |
| 2669 | anhela | 1 |
| 2670 | anegó | 1 |
| 2671 | anega | 1 |
| 2672 | anduvo | 1 |
| 2673 | andante | 1 |
| 2674 | anda | 1 |
| 2675 | anás | 1 |
| 2676 | amortecido | 1 |
| 2677 | amorosa | 1 |
| 2678 | amores | 1 |
| 2679 | amistad | 1 |
| 2680 | ameno | 1 |
| 2681 | amenazados | 1 |
| 2682 | amedrentando | 1 |
| 2683 | ambiciosos | 1 |
| 2684 | ambiciones | 1 |
| 2685 | amase | 1 |
| 2686 | amartelado | 1 |
| 2687 | amarrada | 1 |
| 2688 | amargo | 1 |
| 2689 | amaren | 1 |
| 2690 | amaneciese | 1 |
| 2691 | amanecida | 1 |
| 2692 | amancillada | 1 |
| 2693 | amado | 1 |
| 2694 | ama | 1 |
| 2695 | altura | 1 |
| 2696 | altos | 1 |
| 2697 | altamente | 1 |
| 2698 | alquitara | 1 |
| 2699 | alivian | 1 |
| 2700 | alimenta | 1 |
| 2701 | alienta | 1 |
| 2702 | algunos | 1 |
| 2703 | alguno | 1 |
| 2704 | alentada | 1 |
| 2705 | alegoría | 1 |
| 2706 | alegan | 1 |
| 2707 | alce | 1 |
| 2708 | alcázares | 1 |
| 2709 | alcanzarla | 1 |
| 2710 | alcanzar | 1 |
| 2711 | albricias | 1 |
| 2712 | alboroza | 1 |
| 2713 | alboroto | 1 |
| 2714 | alberga | 1 |
| 2715 | albedrío | 1 |
| 2716 | alba | 1 |
| 2717 | alargar | 1 |
| 2718 | alargan | 1 |
| 2719 | alada | 1 |
| 2720 | alaben | 1 |
| 2721 | alabastrina | 1 |
| 2722 | alabanza | 1 |
| 2723 | ajenas | 1 |
| 2724 | ajena | 1 |
| 2725 | ahoga | 1 |
| 2726 | ah | 1 |
| 2727 | águila | 1 |
| 2728 | aguijo | 1 |
| 2729 | agüero | 1 |
| 2730 | agudo | 1 |
| 2731 | agravios | 1 |
| 2732 | agravio | 1 |
| 2733 | agravia | 1 |
| 2734 | agradecida | 1 |
| 2735 | agradable | 1 |
| 2736 | agonizar | 1 |
| 2737 | agonía | 1 |
| 2738 | áfrica | 1 |
| 2739 | afrenta | 1 |
| 2740 | aflijo | 1 |
| 2741 | aflige | 1 |
| 2742 | afirma | 1 |
| 2743 | afanan | 1 |
| 2744 | afán | 1 |
| 2745 | advertidas | 1 |
| 2746 | advertencia | 1 |
| 2747 | adulador | 1 |
| 2748 | adoro | 1 |
| 2749 | adorno | 1 |
| 2750 | adorne | 1 |
| 2751 | adormecido | 1 |
| 2752 | adónde | 1 |
| 2753 | admito | 1 |
| 2754 | admitirle | 1 |
| 2755 | admitiéndole | 1 |
| 2756 | admitido | 1 |
| 2757 | admires | 1 |
| 2758 | admire | 1 |
| 2759 | admiras | 1 |
| 2760 | admiración | 1 |
| 2761 | adivine | 1 |
| 2762 | acusen | 1 |
| 2763 | acusaban | 1 |
| 2764 | acuerdas | 1 |
| 2765 | acuerda | 1 |
| 2766 | acreditada | 1 |
| 2767 | acortarse | 1 |
| 2768 | acorde | 1 |
| 2769 | aconsejando | 1 |
| 2770 | acompaña | 1 |
| 2771 | acicalado | 1 |
| 2772 | acercarse | 1 |
| 2773 | acentos | 1 |
| 2774 | acento | 1 |
| 2775 | acciones | 1 |
| 2776 | acción | 1 |
| 2777 | acaban | 1 |
| 2778 | acá | 1 |
| 2779 | abundancia | 1 |
| 2780 | abultan | 1 |
| 2781 | absorto | 1 |
| 2782 | absoluto | 1 |
| 2783 | abrojos | 1 |
| 2784 | abril | 1 |
| 2785 | abriga | 1 |
| 2786 | abrieron | 1 |
| 2787 | abres | 1 |
| 2788 | abrazos | 1 |
| 2789 | abrasando | 1 |
| 2790 | abrasados | 1 |
| 2791 | abrasador | 1 |
| 2792 | aborrecer | 1 |
| 2793 | aborrece | 1 |
| 2794 | abiertos | 1 |
| 2795 | abejas | 1 |
| 2796 | abajo | 1 |
|
Ilustración del principio de mínimo esfuerzo: |
|
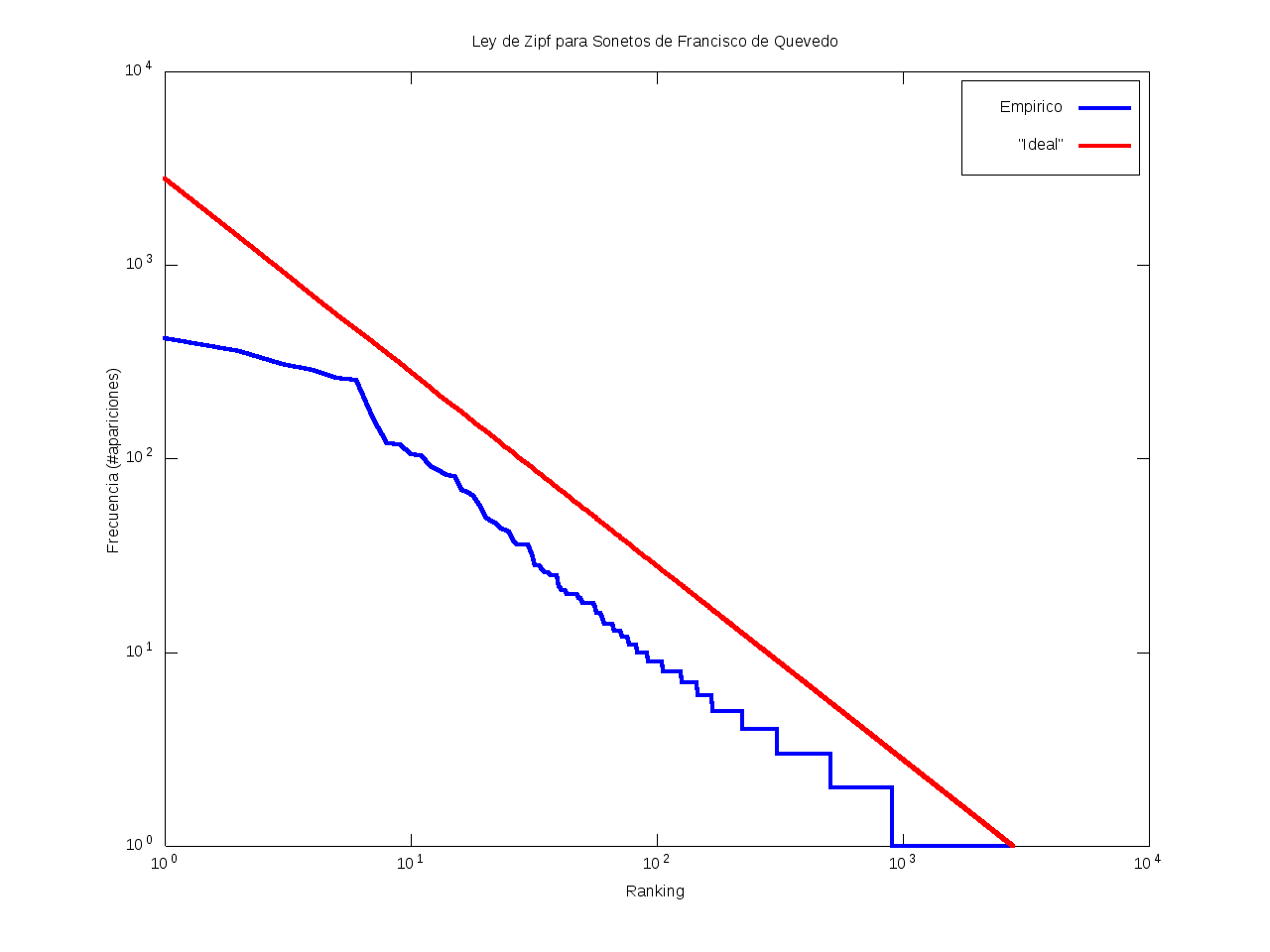
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará el texto actual (Sonetos de Francisco de Quevedo) (conjunto 1)
contra el resto de textos en el mismo idioma (Castellano) (conjunto 2).
A continuación se muestra una lista de las palabras presentes en el texto actual,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
Mostrar todo
Recoger