Análisis de Romances de Francisco de Quevedo
Índice
Información General
| Título: | Romances |
|---|
| Autor: | Francisco de Quevedo |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 12700 |
|---|
| #Palabras distintas: | 3713 |
|---|
| Type-Token ratio: | 29.24% |
|---|
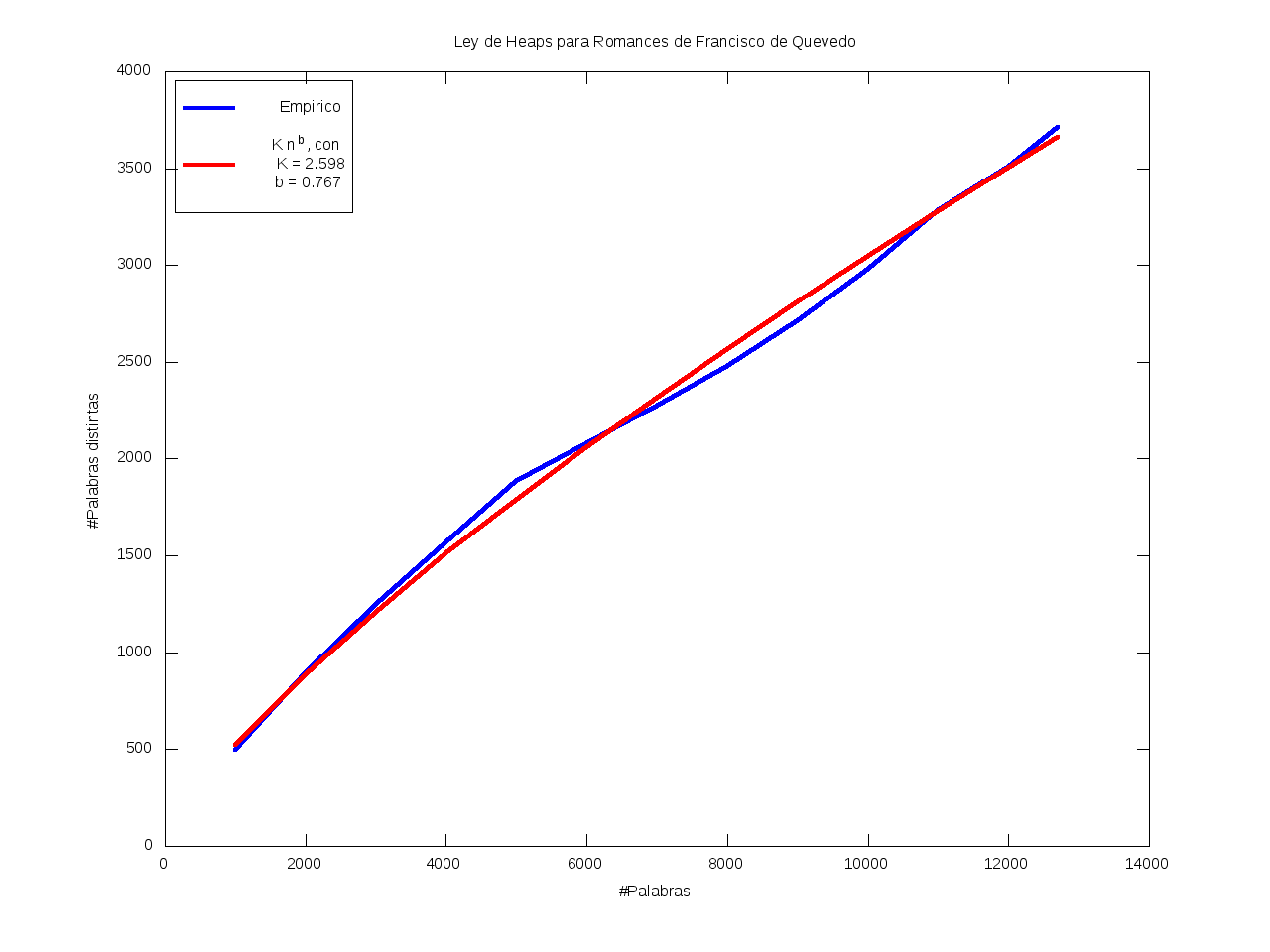
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| #Palabras: | #Palabras distintas: |
|---|
| 1000 | 497 |
| 2000 | 895 |
| 3000 | 1248 |
| 4000 | 1568 |
| 5000 | 1883 |
| 6000 | 2079 |
| 7000 | 2275 |
| 8000 | 2477 |
| 9000 | 2712 |
| 10000 | 2980 |
| 11000 | 3284 |
| 12000 | 3510 |
| 12700 | 3713 |
|
Ajuste por mínimos cuadrados de los datos a K*n^b:
|
| K = 2.598 |
|
b = 0.767 |
|
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Rank | Palabra | Frec |
|---|
| 1 | que | 546 |
| 2 | y | 537 |
| 3 | de | 500 |
| 4 | la | 363 |
| 5 | el | 334 |
| 6 | en | 316 |
| 7 | a | 229 |
| 8 | no | 185 |
| 9 | los | 182 |
| 10 | las | 174 |
| 11 | con | 159 |
| 12 | por | 137 |
| 13 | su | 111 |
| 14 | al | 108 |
| 15 | se | 99 |
| 16 | es | 99 |
| 17 | si | 85 |
| 18 | del | 83 |
| 19 | lo | 75 |
| 20 | me | 73 |
| 21 | más | 73 |
| 22 | qué | 72 |
| 23 | un | 69 |
| 24 | pues | 67 |
| 25 | mi | 62 |
| 26 | le | 57 |
| 27 | yo | 53 |
| 28 | para | 49 |
| 29 | sus | 48 |
| 30 | ya | 46 |
| 31 | tan | 46 |
| 32 | te | 41 |
| 33 | sin | 39 |
| 34 | ser | 39 |
| 35 | son | 38 |
| 36 | tu | 36 |
| 37 | una | 35 |
| 38 | ni | 35 |
| 39 | quien | 34 |
| 40 | como | 34 |
| 41 | porque | 32 |
| 42 | dar | 30 |
| 43 | bien | 30 |
| 44 | ha | 29 |
| 45 | dinero | 28 |
| 46 | amor | 27 |
| 47 | sol | 26 |
| 48 | mis | 26 |
| 49 | os | 25 |
| 50 | o | 25 |
| 51 | dios | 25 |
| 52 | vida | 24 |
| 53 | hay | 23 |
| 54 | don | 23 |
| 55 | luz | 22 |
| 56 | he | 22 |
| 57 | todos | 21 |
| 58 | soy | 21 |
| 59 | muy | 21 |
| 60 | muerte | 21 |
| 61 | hace | 21 |
| 62 | fue | 21 |
| 63 | alma | 21 |
| 64 | sólo | 20 |
| 65 | mí | 20 |
| 66 | mas | 20 |
| 67 | donde | 20 |
| 68 | cuando | 20 |
| 69 | cielo | 20 |
| 70 | pero | 19 |
| 71 | dos | 19 |
| 72 | aunque | 19 |
| 73 | todo | 18 |
| 74 | galán | 18 |
| 75 | dama | 18 |
| 76 | quiero | 17 |
| 77 | entre | 17 |
| 78 | él | 17 |
| 79 | vos | 16 |
| 80 | tus | 16 |
| 81 | tú | 16 |
| 82 | tiempo | 16 |
| 83 | quién | 16 |
| 84 | ojos | 16 |
| 85 | noche | 16 |
| 86 | mal | 16 |
| 87 | este | 16 |
| 88 | verdad | 15 |
| 89 | día | 15 |
| 90 | tener | 14 |
| 91 | siendo | 14 |
| 92 | siempre | 14 |
| 93 | ver | 13 |
| 94 | tierra | 13 |
| 95 | nada | 13 |
| 96 | mundo | 13 |
| 97 | menos | 13 |
| 98 | gran | 13 |
| 99 | fortuna | 13 |
| 100 | cuanto | 13 |
| 101 | tiene | 12 |
| 102 | tanto | 12 |
| 103 | morir | 12 |
| 104 | horas | 12 |
| 105 | consiente | 12 |
| 106 | sueño | 11 |
| 107 | sino | 11 |
| 108 | puro | 11 |
| 109 | puede | 11 |
| 110 | poderoso | 11 |
| 111 | oro | 11 |
| 112 | negra | 11 |
| 113 | mujer | 11 |
| 114 | estrellas | 11 |
| 115 | está | 11 |
| 116 | caballero | 11 |
| 117 | boca | 11 |
| 118 | voz | 10 |
| 119 | ti | 10 |
| 120 | sombra | 10 |
| 121 | sois | 10 |
| 122 | será | 10 |
| 123 | señor | 10 |
| 124 | sé | 10 |
| 125 | miedo | 10 |
| 126 | malhaya | 10 |
| 127 | letrilla | 10 |
| 128 | les | 10 |
| 129 | hombre | 10 |
| 130 | han | 10 |
| 131 | fuego | 10 |
| 132 | flor | 10 |
| 133 | ella | 10 |
| 134 | dulce | 10 |
| 135 | da | 10 |
| 136 | camino | 10 |
| 137 | algún | 10 |
| 138 | agua | 10 |
| 139 | vino | 9 |
| 140 | toda | 9 |
| 141 | sola | 9 |
| 142 | sobre | 9 |
| 143 | silencio | 9 |
| 144 | nunca | 9 |
| 145 | negro | 9 |
| 146 | muerto | 9 |
| 147 | mejor | 9 |
| 148 | gente | 9 |
| 149 | flores | 9 |
| 150 | esta | 9 |
| 151 | dio | 9 |
| 152 | cosa | 9 |
| 153 | cara | 9 |
| 154 | aun | 9 |
| 155 | tienes | 8 |
| 156 | tengo | 8 |
| 157 | tenga | 8 |
| 158 | también | 8 |
| 159 | sí | 8 |
| 160 | satírica | 8 |
| 161 | rosas | 8 |
| 162 | podido | 8 |
| 163 | pena | 8 |
| 164 | luna | 8 |
| 165 | llanto | 8 |
| 166 | llama | 8 |
| 167 | hermosa | 8 |
| 168 | hecho | 8 |
| 169 | hasta | 8 |
| 170 | era | 8 |
| 171 | corazón | 8 |
| 172 | casa | 8 |
| 173 | boda | 8 |
| 174 | ardiente | 8 |
| 175 | suerte | 7 |
| 176 | solamente | 7 |
| 177 | señora | 7 |
| 178 | rico | 7 |
| 179 | quiere | 7 |
| 180 | querido | 7 |
| 181 | punto | 7 |
| 182 | pluma | 7 |
| 183 | otro | 7 |
| 184 | nombre | 7 |
| 185 | mucho | 7 |
| 186 | mil | 7 |
| 187 | mayor | 7 |
| 188 | manos | 7 |
| 189 | luego | 7 |
| 190 | gusto | 7 |
| 191 | guerra | 7 |
| 192 | están | 7 |
| 193 | edad | 7 |
| 194 | doña | 7 |
| 195 | buen | 7 |
| 196 | aún | 7 |
| 197 | vuestra | 6 |
| 198 | vosotras | 6 |
| 199 | vivir | 6 |
| 200 | viendo | 6 |
| 201 | veces | 6 |
| 202 | valiente | 6 |
| 203 | triste | 6 |
| 204 | tal | 6 |
| 205 | suelo | 6 |
| 206 | sosiego | 6 |
| 207 | sombras | 6 |
| 208 | serán | 6 |
| 209 | santo | 6 |
| 210 | quiso | 6 |
| 211 | primero | 6 |
| 212 | pies | 6 |
| 213 | persona | 6 |
| 214 | pensamiento | 6 |
| 215 | paso | 6 |
| 216 | pasión | 6 |
| 217 | parte | 6 |
| 218 | oriente | 6 |
| 219 | nos | 6 |
| 220 | negros | 6 |
| 221 | mar | 6 |
| 222 | mañana | 6 |
| 223 | mano | 6 |
| 224 | ley | 6 |
| 225 | hoy | 6 |
| 226 | grande | 6 |
| 227 | gloria | 6 |
| 228 | fuera | 6 |
| 229 | entonces | 6 |
| 230 | dolor | 6 |
| 231 | después | 6 |
| 232 | desde | 6 |
| 233 | cuidado | 6 |
| 234 | cualquier | 6 |
| 235 | ciego | 6 |
| 236 | caras | 6 |
| 237 | aquella | 6 |
| 238 | antigua | 6 |
| 239 | amante | 6 |
| 240 | alto | 6 |
| 241 | yace | 5 |
| 242 | vuestro | 5 |
| 243 | vio | 5 |
| 244 | ven | 5 |
| 245 | va | 5 |
| 246 | tuvo | 5 |
| 247 | tristeza | 5 |
| 248 | tres | 5 |
| 249 | todas | 5 |
| 250 | toca | 5 |
| 251 | sonoras | 5 |
| 252 | soberbia | 5 |
| 253 | rostro | 5 |
| 254 | rey | 5 |
| 255 | reloj | 5 |
| 256 | razón | 5 |
| 257 | pueden | 5 |
| 258 | pudo | 5 |
| 259 | presunción | 5 |
| 260 | poco | 5 |
| 261 | plata | 5 |
| 262 | oficio | 5 |
| 263 | mía | 5 |
| 264 | mentiroso | 5 |
| 265 | lugar | 5 |
| 266 | llaman | 5 |
| 267 | libertad | 5 |
| 268 | lágrimas | 5 |
| 269 | hora | 5 |
| 270 | hermosura | 5 |
| 271 | estilo | 5 |
| 272 | espaldas | 5 |
| 273 | eso | 5 |
| 274 | escudos | 5 |
| 275 | esa | 5 |
| 276 | enamorado | 5 |
| 277 | días | 5 |
| 278 | decir | 5 |
| 279 | debajo | 5 |
| 280 | cuerpo | 5 |
| 281 | cuenta | 5 |
| 282 | cómo | 5 |
| 283 | ceniza | 5 |
| 284 | cantas | 5 |
| 285 | buena | 5 |
| 286 | blanca | 5 |
| 287 | basta | 5 |
| 288 | ausente | 5 |
| 289 | armas | 5 |
| 290 | antes | 5 |
| 291 | anda | 5 |
| 292 | amores | 5 |
| 293 | aliento | 5 |
| 294 | alguno | 5 |
| 295 | algo | 5 |
| 296 | alas | 5 |
| 297 | aire | 5 |
| 298 | agrada | 5 |
| 299 | agora | 5 |
| 300 | vuelas | 4 |
| 301 | vuela | 4 |
| 302 | virtud | 4 |
| 303 | viento | 4 |
| 304 | vi | 4 |
| 305 | vez | 4 |
| 306 | vergüenza | 4 |
| 307 | verde | 4 |
| 308 | verdadero | 4 |
| 309 | vencer | 4 |
| 310 | van | 4 |
| 311 | tras | 4 |
| 312 | severo | 4 |
| 313 | sed | 4 |
| 314 | santa | 4 |
| 315 | rosal | 4 |
| 316 | río | 4 |
| 317 | rigor | 4 |
| 318 | ricos | 4 |
| 319 | reales | 4 |
| 320 | rayos | 4 |
| 321 | pura | 4 |
| 322 | puertas | 4 |
| 323 | puerta | 4 |
| 324 | prado | 4 |
| 325 | pobreza | 4 |
| 326 | pobres | 4 |
| 327 | pobre | 4 |
| 328 | pide | 4 |
| 329 | peregrino | 4 |
| 330 | penas | 4 |
| 331 | pecado | 4 |
| 332 | paz | 4 |
| 333 | pasos | 4 |
| 334 | otros | 4 |
| 335 | otra | 4 |
| 336 | olvido | 4 |
| 337 | nadadores | 4 |
| 338 | muerta | 4 |
| 339 | mudo | 4 |
| 340 | muda | 4 |
| 341 | muchos | 4 |
| 342 | muchas | 4 |
| 343 | mostró | 4 |
| 344 | mortaja | 4 |
| 345 | misma | 4 |
| 346 | mío | 4 |
| 347 | mala | 4 |
| 348 | madrugas | 4 |
| 349 | madre | 4 |
| 350 | luces | 4 |
| 351 | llorar | 4 |
| 352 | llora | 4 |
| 353 | llegó | 4 |
| 354 | llamas | 4 |
| 355 | laurel | 4 |
| 356 | ladrón | 4 |
| 357 | joyas | 4 |
| 358 | jilguero | 4 |
| 359 | invidia | 4 |
| 360 | humildad | 4 |
| 361 | hubo | 4 |
| 362 | honor | 4 |
| 363 | hombres | 4 |
| 364 | hazañas | 4 |
| 365 | hacer | 4 |
| 366 | grandes | 4 |
| 367 | gracia | 4 |
| 368 | garganta | 4 |
| 369 | galas | 4 |
| 370 | fuí | 4 |
| 371 | firme | 4 |
| 372 | fama | 4 |
| 373 | facistol | 4 |
| 374 | estrella | 4 |
| 375 | esto | 4 |
| 376 | estas | 4 |
| 377 | estaba | 4 |
| 378 | espíritu | 4 |
| 379 | espinas | 4 |
| 380 | españa | 4 |
| 381 | eres | 4 |
| 382 | ellas | 4 |
| 383 | diles | 4 |
| 384 | dijo | 4 |
| 385 | digo | 4 |
| 386 | digasmé | 4 |
| 387 | dicho | 4 |
| 388 | dicen | 4 |
| 389 | diablo | 4 |
| 390 | desvelas | 4 |
| 391 | cuyos | 4 |
| 392 | culpa | 4 |
| 393 | cuidados | 4 |
| 394 | cristo | 4 |
| 395 | corona | 4 |
| 396 | cielos | 4 |
| 397 | cautelas | 4 |
| 398 | carne | 4 |
| 399 | cantar | 4 |
| 400 | campo | 4 |
| 401 | cama | 4 |
| 402 | cada | 4 |
| 403 | cabeza | 4 |
| 404 | breve | 4 |
| 405 | brazos | 4 |
| 406 | belleza | 4 |
| 407 | bella | 4 |
| 408 | aves | 4 |
| 409 | aurora | 4 |
| 410 | atento | 4 |
| 411 | así | 4 |
| 412 | aquel | 4 |
| 413 | años | 4 |
| 414 | almas | 4 |
| 415 | alcanza | 4 |
| 416 | vuelta | 3 |
| 417 | voces | 3 |
| 418 | vivo | 3 |
| 419 | viven | 3 |
| 420 | vista | 3 |
| 421 | vientos | 3 |
| 422 | viene | 3 |
| 423 | vestido | 3 |
| 424 | ves | 3 |
| 425 | verdes | 3 |
| 426 | verano | 3 |
| 427 | venas | 3 |
| 428 | ve | 3 |
| 429 | vana | 3 |
| 430 | valor | 3 |
| 431 | uno | 3 |
| 432 | unas | 3 |
| 433 | tuve | 3 |
| 434 | trabajo | 3 |
| 435 | torpe | 3 |
| 436 | toro | 3 |
| 437 | tormento | 3 |
| 438 | tonos | 3 |
| 439 | tomar | 3 |
| 440 | tirana | 3 |
| 441 | tinta | 3 |
| 442 | tengan | 3 |
| 443 | temor | 3 |
| 444 | tela | 3 |
| 445 | sutil | 3 |
| 446 | suma | 3 |
| 447 | sufrir | 3 |
| 448 | solo | 3 |
| 449 | soldado | 3 |
| 450 | solas | 3 |
| 451 | sirve | 3 |
| 452 | siquiera | 3 |
| 453 | silla | 3 |
| 454 | semejante | 3 |
| 455 | según | 3 |
| 456 | sangre | 3 |
| 457 | san | 3 |
| 458 | sacan | 3 |
| 459 | saber | 3 |
| 460 | sabe | 3 |
| 461 | risa | 3 |
| 462 | revés | 3 |
| 463 | reino | 3 |
| 464 | rayo | 3 |
| 465 | quiera | 3 |
| 466 | puedo | 3 |
| 467 | prosa | 3 |
| 468 | propia | 3 |
| 469 | principio | 3 |
| 470 | primera | 3 |
| 471 | primer | 3 |
| 472 | primaveras | 3 |
| 473 | presumir | 3 |
| 474 | poder | 3 |
| 475 | plumas | 3 |
| 476 | pienso | 3 |
| 477 | piedras | 3 |
| 478 | pie | 3 |
| 479 | pez | 3 |
| 480 | personas | 3 |
| 481 | peor | 3 |
| 482 | pecho | 3 |
| 483 | pasiones | 3 |
| 484 | pasados | 3 |
| 485 | parto | 3 |
| 486 | parecer | 3 |
| 487 | paga | 3 |
| 488 | orejas | 3 |
| 489 | oído | 3 |
| 490 | ofende | 3 |
| 491 | nuevo | 3 |
| 492 | nuevas | 3 |
| 493 | nuestras | 3 |
| 494 | niña | 3 |
| 495 | negras | 3 |
| 496 | necios | 3 |
| 497 | nadie | 3 |
| 498 | nacimiento | 3 |
| 499 | nací | 3 |
| 500 | murió | 3 |
| 501 | mudas | 3 |
| 502 | mudanza | 3 |
| 503 | mortales | 3 |
| 504 | moro | 3 |
| 505 | montes | 3 |
| 506 | molesto | 3 |
| 507 | modos | 3 |
| 508 | mira | 3 |
| 509 | mesa | 3 |
| 510 | merece | 3 |
| 511 | mejores | 3 |
| 512 | medio | 3 |
| 513 | matar | 3 |
| 514 | marido | 3 |
| 515 | máquina | 3 |
| 516 | manera | 3 |
| 517 | majestad | 3 |
| 518 | llueva | 3 |
| 519 | llorando | 3 |
| 520 | llevas | 3 |
| 521 | llena | 3 |
| 522 | llano | 3 |
| 523 | limpieza | 3 |
| 524 | ligera | 3 |
| 525 | leyes | 3 |
| 526 | lenguaje | 3 |
| 527 | lengua | 3 |
| 528 | lado | 3 |
| 529 | juicio | 3 |
| 530 | jornada | 3 |
| 531 | jesús | 3 |
| 532 | jardín | 3 |
| 533 | hijos | 3 |
| 534 | hechos | 3 |
| 535 | haya | 3 |
| 536 | has | 3 |
| 537 | hambre | 3 |
| 538 | hallar | 3 |
| 539 | hacen | 3 |
| 540 | hacéis | 3 |
| 541 | había | 3 |
| 542 | haber | 3 |
| 543 | guardar | 3 |
| 544 | gracias | 3 |
| 545 | goza | 3 |
| 546 | gala | 3 |
| 547 | fuerzas | 3 |
| 548 | fuerza | 3 |
| 549 | frío | 3 |
| 550 | frente | 3 |
| 551 | firmamento | 3 |
| 552 | fin | 3 |
| 553 | feas | 3 |
| 554 | fea | 3 |
| 555 | estoy | 3 |
| 556 | estos | 3 |
| 557 | estando | 3 |
| 558 | esposo | 3 |
| 559 | espero | 3 |
| 560 | escuadras | 3 |
| 561 | eran | 3 |
| 562 | envidiosos | 3 |
| 563 | enferma | 3 |
| 564 | ellos | 3 |
| 565 | elementos | 3 |
| 566 | elegante | 3 |
| 567 | ejército | 3 |
| 568 | duros | 3 |
| 569 | duro | 3 |
| 570 | duras | 3 |
| 571 | dulces | 3 |
| 572 | dote | 3 |
| 573 | dormir | 3 |
| 574 | docta | 3 |
| 575 | diome | 3 |
| 576 | dineros | 3 |
| 577 | dichosas | 3 |
| 578 | di | 3 |
| 579 | desvarío | 3 |
| 580 | desprecia | 3 |
| 581 | desnudo | 3 |
| 582 | deseos | 3 |
| 583 | deseo | 3 |
| 584 | desdichado | 3 |
| 585 | descanso | 3 |
| 586 | delgada | 3 |
| 587 | dejan | 3 |
| 588 | deja | 3 |
| 589 | dedo | 3 |
| 590 | daros | 3 |
| 591 | daré | 3 |
| 592 | dando | 3 |
| 593 | dan | 3 |
| 594 | dame | 3 |
| 595 | damas | 3 |
| 596 | cuya | 3 |
| 597 | culto | 3 |
| 598 | cuerpos | 3 |
| 599 | cuello | 3 |
| 600 | cruz | 3 |
| 601 | coro | 3 |
| 602 | contra | 3 |
| 603 | confío | 3 |
| 604 | conde | 3 |
| 605 | comer | 3 |
| 606 | color | 3 |
| 607 | coche | 3 |
| 608 | clavellinas | 3 |
| 609 | cierto | 3 |
| 610 | ciento | 3 |
| 611 | ciega | 3 |
| 612 | chica | 3 |
| 613 | ceño | 3 |
| 614 | cárcel | 3 |
| 615 | canto | 3 |
| 616 | campos | 3 |
| 617 | calidad | 3 |
| 618 | busca | 3 |
| 619 | buenos | 3 |
| 620 | bueno | 3 |
| 621 | blando | 3 |
| 622 | blanco | 3 |
| 623 | bienes | 3 |
| 624 | baja | 3 |
| 625 | ave | 3 |
| 626 | avaro | 3 |
| 627 | auroras | 3 |
| 628 | armado | 3 |
| 629 | aquí | 3 |
| 630 | año | 3 |
| 631 | aminta | 3 |
| 632 | amar | 3 |
| 633 | altas | 3 |
| 634 | algunos | 3 |
| 635 | alguna | 3 |
| 636 | alegre | 3 |
| 637 | acredita | 3 |
| 638 | vuelve | 2 |
| 639 | vuelvan | 2 |
| 640 | vuelo | 2 |
| 641 | voluntad | 2 |
| 642 | vivos | 2 |
| 643 | vivas | 2 |
| 644 | viuda | 2 |
| 645 | visto | 2 |
| 646 | vistió | 2 |
| 647 | viste | 2 |
| 648 | villa | 2 |
| 649 | vierte | 2 |
| 650 | vieron | 2 |
| 651 | viere | 2 |
| 652 | vientre | 2 |
| 653 | viéndote | 2 |
| 654 | vid | 2 |
| 655 | vicio | 2 |
| 656 | vestidas | 2 |
| 657 | verte | 2 |
| 658 | versos | 2 |
| 659 | verse | 2 |
| 660 | verme | 2 |
| 661 | verdadera | 2 |
| 662 | veras | 2 |
| 663 | ventura | 2 |
| 664 | venir | 2 |
| 665 | veladores | 2 |
| 666 | vejez | 2 |
| 667 | vaya | 2 |
| 668 | vara | 2 |
| 669 | vano | 2 |
| 670 | vanidad | 2 |
| 671 | valle | 2 |
| 672 | vale | 2 |
| 673 | vaca | 2 |
| 674 | unos | 2 |
| 675 | umbral | 2 |
| 676 | tumba | 2 |
| 677 | trujo | 2 |
| 678 | truhán | 2 |
| 679 | traidora | 2 |
| 680 | trae | 2 |
| 681 | trabajos | 2 |
| 682 | tortilla | 2 |
| 683 | torpes | 2 |
| 684 | tormentos | 2 |
| 685 | tomara | 2 |
| 686 | tocas | 2 |
| 687 | tirsi | 2 |
| 688 | tinieblas | 2 |
| 689 | tiernos | 2 |
| 690 | tienen | 2 |
| 691 | términos | 2 |
| 692 | templo | 2 |
| 693 | temerosa | 2 |
| 694 | teme | 2 |
| 695 | tarde | 2 |
| 696 | tantas | 2 |
| 697 | tanta | 2 |
| 698 | talegos | 2 |
| 699 | tabernas | 2 |
| 700 | suspiros | 2 |
| 701 | supo | 2 |
| 702 | suceda | 2 |
| 703 | subiste | 2 |
| 704 | sospecho | 2 |
| 705 | somos | 2 |
| 706 | solimán | 2 |
| 707 | solares | 2 |
| 708 | soga | 2 |
| 709 | soberbios | 2 |
| 710 | sirenas | 2 |
| 711 | siguió | 2 |
| 712 | siguieron | 2 |
| 713 | siglos | 2 |
| 714 | siglo | 2 |
| 715 | siento | 2 |
| 716 | siente | 2 |
| 717 | servicios | 2 |
| 718 | sepa | 2 |
| 719 | sentir | 2 |
| 720 | sentaron | 2 |
| 721 | semejantes | 2 |
| 722 | seguros | 2 |
| 723 | secreto | 2 |
| 724 | sean | 2 |
| 725 | sea | 2 |
| 726 | satisfacción | 2 |
| 727 | sano | 2 |
| 728 | salas | 2 |
| 729 | sagrado | 2 |
| 730 | sacrosanta | 2 |
| 731 | sacar | 2 |
| 732 | ruido | 2 |
| 733 | romano | 2 |
| 734 | romance | 2 |
| 735 | robar | 2 |
| 736 | rigurosas | 2 |
| 737 | rica | 2 |
| 738 | reyes | 2 |
| 739 | revueltos | 2 |
| 740 | respeto | 2 |
| 741 | refrán | 2 |
| 742 | refiere | 2 |
| 743 | redentor | 2 |
| 744 | recién | 2 |
| 745 | ramas | 2 |
| 746 | quita | 2 |
| 747 | quise | 2 |
| 748 | quieres | 2 |
| 749 | quiebra | 2 |
| 750 | queréis | 2 |
| 751 | quejas | 2 |
| 752 | queja | 2 |
| 753 | quedó | 2 |
| 754 | quede | 2 |
| 755 | puros | 2 |
| 756 | puente | 2 |
| 757 | pudiera | 2 |
| 758 | pudiendo | 2 |
| 759 | prudente | 2 |
| 760 | prometo | 2 |
| 761 | pródiga | 2 |
| 762 | privanza | 2 |
| 763 | prisiones | 2 |
| 764 | prisa | 2 |
| 765 | principales | 2 |
| 766 | primavera | 2 |
| 767 | presumida | 2 |
| 768 | presto | 2 |
| 769 | prestado | 2 |
| 770 | presente | 2 |
| 771 | premio | 2 |
| 772 | precioso | 2 |
| 773 | preciosas | 2 |
| 774 | postrero | 2 |
| 775 | porfía | 2 |
| 776 | podrá | 2 |
| 777 | pocas | 2 |
| 778 | poca | 2 |
| 779 | plantas | 2 |
| 780 | planta | 2 |
| 781 | pizorra | 2 |
| 782 | pisas | 2 |
| 783 | pintado | 2 |
| 784 | pimiento | 2 |
| 785 | piernas | 2 |
| 786 | pierde | 2 |
| 787 | piense | 2 |
| 788 | piensa | 2 |
| 789 | pidan | 2 |
| 790 | pida | 2 |
| 791 | picado | 2 |
| 792 | peso | 2 |
| 793 | pesares | 2 |
| 794 | persuadieron | 2 |
| 795 | perros | 2 |
| 796 | perlas | 2 |
| 797 | perdidos | 2 |
| 798 | perderás | 2 |
| 799 | pensando | 2 |
| 800 | pecados | 2 |
| 801 | patria | 2 |
| 802 | pase | 2 |
| 803 | pasar | 2 |
| 804 | pasado | 2 |
| 805 | pasa | 2 |
| 806 | parecido | 2 |
| 807 | parecen | 2 |
| 808 | panza | 2 |
| 809 | pan | 2 |
| 810 | palma | 2 |
| 811 | pájaro | 2 |
| 812 | pago | 2 |
| 813 | pagados | 2 |
| 814 | padres | 2 |
| 815 | padece | 2 |
| 816 | paciencia | 2 |
| 817 | oyó | 2 |
| 818 | otras | 2 |
| 819 | oscura | 2 |
| 820 | orilla | 2 |
| 821 | olmo | 2 |
| 822 | ollas | 2 |
| 823 | olas | 2 |
| 824 | oigas | 2 |
| 825 | ofenden | 2 |
| 826 | obras | 2 |
| 827 | número | 2 |
| 828 | nueva | 2 |
| 829 | nuestros | 2 |
| 830 | nuestro | 2 |
| 831 | nuestra | 2 |
| 832 | novia | 2 |
| 833 | nobles | 2 |
| 834 | ninguno | 2 |
| 835 | nieves | 2 |
| 836 | necio | 2 |
| 837 | naturaleza | 2 |
| 838 | narciso | 2 |
| 839 | nadar | 2 |
| 840 | nadando | 2 |
| 841 | nacido | 2 |
| 842 | nace | 2 |
| 843 | mulato | 2 |
| 844 | muestre | 2 |
| 845 | muertas | 2 |
| 846 | muero | 2 |
| 847 | movimientos | 2 |
| 848 | movimiento | 2 |
| 849 | mostrando | 2 |
| 850 | mostaza | 2 |
| 851 | mosca | 2 |
| 852 | montaña | 2 |
| 853 | mondada | 2 |
| 854 | modo | 2 |
| 855 | mismos | 2 |
| 856 | miráis | 2 |
| 857 | ministro | 2 |
| 858 | minas | 2 |
| 859 | milagro | 2 |
| 860 | mieses | 2 |
| 861 | miércoles | 2 |
| 862 | miente | 2 |
| 863 | metal | 2 |
| 864 | mesmas | 2 |
| 865 | mercader | 2 |
| 866 | mentira | 2 |
| 867 | mente | 2 |
| 868 | menester | 2 |
| 869 | memoria | 2 |
| 870 | mejillas | 2 |
| 871 | médicos | 2 |
| 872 | médico | 2 |
| 873 | medicina | 2 |
| 874 | mata | 2 |
| 875 | martirio | 2 |
| 876 | martes | 2 |
| 877 | mariposa | 2 |
| 878 | mari | 2 |
| 879 | manso | 2 |
| 880 | mancebo | 2 |
| 881 | malos | 2 |
| 882 | malas | 2 |
| 883 | madrugan | 2 |
| 884 | madrigal | 2 |
| 885 | madres | 2 |
| 886 | llenos | 2 |
| 887 | lírica | 2 |
| 888 | lira | 2 |
| 889 | líquidas | 2 |
| 890 | lindas | 2 |
| 891 | limpio | 2 |
| 892 | libre | 2 |
| 893 | levantan | 2 |
| 894 | levanta | 2 |
| 895 | letras | 2 |
| 896 | leonor | 2 |
| 897 | lecho | 2 |
| 898 | leandro | 2 |
| 899 | lastimoso | 2 |
| 900 | largo | 2 |
| 901 | larga | 2 |
| 902 | lanza | 2 |
| 903 | labios | 2 |
| 904 | justo | 2 |
| 905 | justicia | 2 |
| 906 | juez | 2 |
| 907 | juego | 2 |
| 908 | juan | 2 |
| 909 | joya | 2 |
| 910 | jove | 2 |
| 911 | jordán | 2 |
| 912 | jineta | 2 |
| 913 | jamás | 2 |
| 914 | intento | 2 |
| 915 | intenté | 2 |
| 916 | instrumento | 2 |
| 917 | inobedientes | 2 |
| 918 | ingrato | 2 |
| 919 | infinitos | 2 |
| 920 | infanzón | 2 |
| 921 | inclinación | 2 |
| 922 | importuna | 2 |
| 923 | imagen | 2 |
| 924 | igual | 2 |
| 925 | humos | 2 |
| 926 | humano | 2 |
| 927 | hubiera | 2 |
| 928 | honroso | 2 |
| 929 | honras | 2 |
| 930 | honrado | 2 |
| 931 | honra | 2 |
| 932 | hongos | 2 |
| 933 | hombro | 2 |
| 934 | hizo | 2 |
| 935 | hielo | 2 |
| 936 | hicieron | 2 |
| 937 | hero | 2 |
| 938 | hermoso | 2 |
| 939 | hereje | 2 |
| 940 | harto | 2 |
| 941 | haré | 2 |
| 942 | hanme | 2 |
| 943 | hallan | 2 |
| 944 | halla | 2 |
| 945 | hago | 2 |
| 946 | hagas | 2 |
| 947 | hagan | 2 |
| 948 | haga | 2 |
| 949 | haciendo | 2 |
| 950 | hacienda | 2 |
| 951 | hable | 2 |
| 952 | hablar | 2 |
| 953 | habitación | 2 |
| 954 | gustas | 2 |
| 955 | güevos | 2 |
| 956 | güeros | 2 |
| 957 | güeco | 2 |
| 958 | guarda | 2 |
| 959 | guadaña | 2 |
| 960 | grandeza | 2 |
| 961 | grajos | 2 |
| 962 | gozar | 2 |
| 963 | glorioso | 2 |
| 964 | gesto | 2 |
| 965 | gentes | 2 |
| 966 | gemido | 2 |
| 967 | gatos | 2 |
| 968 | gastar | 2 |
| 969 | gasta | 2 |
| 970 | gana | 2 |
| 971 | fuisteis | 2 |
| 972 | fuerte | 2 |
| 973 | fueron | 2 |
| 974 | fuente | 2 |
| 975 | fritos | 2 |
| 976 | fría | 2 |
| 977 | frentes | 2 |
| 978 | fregona | 2 |
| 979 | forzosos | 2 |
| 980 | flaca | 2 |
| 981 | firmeza | 2 |
| 982 | fiestas | 2 |
| 983 | fiesta | 2 |
| 984 | fiero | 2 |
| 985 | feo | 2 |
| 986 | fe | 2 |
| 987 | favor | 2 |
| 988 | famoso | 2 |
| 989 | exprimida | 2 |
| 990 | europa | 2 |
| 991 | eterno | 2 |
| 992 | estrellada | 2 |
| 993 | estrecha | 2 |
| 994 | esté | 2 |
| 995 | estás | 2 |
| 996 | estarán | 2 |
| 997 | estar | 2 |
| 998 | estaban | 2 |
| 999 | espuma | 2 |
| 1000 | espera | 2 |
| 1001 | español | 2 |
| 1002 | espanta | 2 |
| 1003 | esfuerzo | 2 |
| 1004 | escuadra | 2 |
| 1005 | escribo | 2 |
| 1006 | escribe | 2 |
| 1007 | esclavo | 2 |
| 1008 | envidia | 2 |
| 1009 | envejecen | 2 |
| 1010 | entrañas | 2 |
| 1011 | entiendes | 2 |
| 1012 | engendró | 2 |
| 1013 | engaños | 2 |
| 1014 | enemigos | 2 |
| 1015 | enemigo | 2 |
| 1016 | enciende | 2 |
| 1017 | encendió | 2 |
| 1018 | empiezas | 2 |
| 1019 | ejecutoria | 2 |
| 1020 | echen | 2 |
| 1021 | e | 2 |
| 1022 | duerme | 2 |
| 1023 | dueños | 2 |
| 1024 | doy | 2 |
| 1025 | dones | 2 |
| 1026 | dolores | 2 |
| 1027 | doctor | 2 |
| 1028 | doblones | 2 |
| 1029 | doblón | 2 |
| 1030 | divino | 2 |
| 1031 | divina | 2 |
| 1032 | discreto | 2 |
| 1033 | dije | 2 |
| 1034 | dieron | 2 |
| 1035 | diciendo | 2 |
| 1036 | dichosos | 2 |
| 1037 | dice | 2 |
| 1038 | desventuras | 2 |
| 1039 | destierro | 2 |
| 1040 | desprecio | 2 |
| 1041 | despide | 2 |
| 1042 | desnudar | 2 |
| 1043 | desmayada | 2 |
| 1044 | desiguales | 2 |
| 1045 | desesperada | 2 |
| 1046 | desdicha | 2 |
| 1047 | descubierta | 2 |
| 1048 | descendiente | 2 |
| 1049 | desatina | 2 |
| 1050 | depare | 2 |
| 1051 | della | 2 |
| 1052 | delincuente | 2 |
| 1053 | delicada | 2 |
| 1054 | deje | 2 |
| 1055 | dejaron | 2 |
| 1056 | deis | 2 |
| 1057 | decoro | 2 |
| 1058 | décimas | 2 |
| 1059 | debe | 2 |
| 1060 | dé | 2 |
| 1061 | das | 2 |
| 1062 | darán | 2 |
| 1063 | dais | 2 |
| 1064 | dado | 2 |
| 1065 | daba | 2 |
| 1066 | curioso | 2 |
| 1067 | cura | 2 |
| 1068 | cuitado | 2 |
| 1069 | cubiertos | 2 |
| 1070 | cuatro | 2 |
| 1071 | cuartos | 2 |
| 1072 | cuántas | 2 |
| 1073 | cuánta | 2 |
| 1074 | cualquiera | 2 |
| 1075 | cuál | 2 |
| 1076 | criada | 2 |
| 1077 | crecida | 2 |
| 1078 | costumbres | 2 |
| 1079 | costa | 2 |
| 1080 | cosas | 2 |
| 1081 | cortés | 2 |
| 1082 | corta | 2 |
| 1083 | corrido | 2 |
| 1084 | corra | 2 |
| 1085 | coronas | 2 |
| 1086 | coronado | 2 |
| 1087 | contigo | 2 |
| 1088 | contar | 2 |
| 1089 | contagio | 2 |
| 1090 | contaba | 2 |
| 1091 | consejo | 2 |
| 1092 | conozca | 2 |
| 1093 | conoce | 2 |
| 1094 | conduce | 2 |
| 1095 | condestable | 2 |
| 1096 | competencia | 2 |
| 1097 | comieron | 2 |
| 1098 | come | 2 |
| 1099 | cobarde | 2 |
| 1100 | clementes | 2 |
| 1101 | cierta | 2 |
| 1102 | ciegos | 2 |
| 1103 | chismes | 2 |
| 1104 | cerros | 2 |
| 1105 | cerrado | 2 |
| 1106 | celosos | 2 |
| 1107 | celos | 2 |
| 1108 | cayó | 2 |
| 1109 | cautiverio | 2 |
| 1110 | casta | 2 |
| 1111 | caso | 2 |
| 1112 | casi | 2 |
| 1113 | carnes | 2 |
| 1114 | carnero | 2 |
| 1115 | caña | 2 |
| 1116 | cantaron | 2 |
| 1117 | canciones | 2 |
| 1118 | canas | 2 |
| 1119 | camina | 2 |
| 1120 | calle | 2 |
| 1121 | cadena | 2 |
| 1122 | busque | 2 |
| 1123 | burlas | 2 |
| 1124 | burla | 2 |
| 1125 | bulto | 2 |
| 1126 | bruto | 2 |
| 1127 | bravatas | 2 |
| 1128 | bolsón | 2 |
| 1129 | bolsa | 2 |
| 1130 | blasones | 2 |
| 1131 | bienaventuranza | 2 |
| 1132 | bendición | 2 |
| 1133 | basquiñas | 2 |
| 1134 | bajo | 2 |
| 1135 | azotaron | 2 |
| 1136 | ay | 2 |
| 1137 | avariento | 2 |
| 1138 | atrevida | 2 |
| 1139 | atreven | 2 |
| 1140 | atiende | 2 |
| 1141 | asiste | 2 |
| 1142 | asientos | 2 |
| 1143 | asados | 2 |
| 1144 | arroyuelos | 2 |
| 1145 | arriba | 2 |
| 1146 | arma | 2 |
| 1147 | arena | 2 |
| 1148 | arde | 2 |
| 1149 | aquesto | 2 |
| 1150 | aposento | 2 |
| 1151 | aplauso | 2 |
| 1152 | apenas | 2 |
| 1153 | ansias | 2 |
| 1154 | amarillo | 2 |
| 1155 | amarillez | 2 |
| 1156 | amanecer | 2 |
| 1157 | amada | 2 |
| 1158 | alumbra | 2 |
| 1159 | alimento | 2 |
| 1160 | aleje | 2 |
| 1161 | alcance | 2 |
| 1162 | alado | 2 |
| 1163 | ahorrar | 2 |
| 1164 | aguarda | 2 |
| 1165 | agria | 2 |
| 1166 | agravios | 2 |
| 1167 | agradable | 2 |
| 1168 | afligido | 2 |
| 1169 | advierte | 2 |
| 1170 | adán | 2 |
| 1171 | acompañamiento | 2 |
| 1172 | acero | 2 |
| 1173 | acentos | 2 |
| 1174 | acaso | 2 |
| 1175 | acá | 2 |
| 1176 | abrazos | 2 |
| 1177 | abrazado | 2 |
| 1178 | ablanda | 2 |
| 1179 | zorras | 1 |
| 1180 | zenón | 1 |
| 1181 | zapatero | 1 |
| 1182 | zafir | 1 |
| 1183 | zabúllete | 1 |
| 1184 | yerto | 1 |
| 1185 | yerre | 1 |
| 1186 | yerran | 1 |
| 1187 | yema | 1 |
| 1188 | vuestros | 1 |
| 1189 | vuestras | 1 |
| 1190 | vuelves | 1 |
| 1191 | vuelvas | 1 |
| 1192 | vuélvanse | 1 |
| 1193 | vuelto | 1 |
| 1194 | vueltas | 1 |
| 1195 | voto | 1 |
| 1196 | vosotros | 1 |
| 1197 | vomita | 1 |
| 1198 | volvieron | 1 |
| 1199 | volvieran | 1 |
| 1200 | volverán | 1 |
| 1201 | volver | 1 |
| 1202 | voló | 1 |
| 1203 | volcanes | 1 |
| 1204 | volante | 1 |
| 1205 | volando | 1 |
| 1206 | vocean | 1 |
| 1207 | vizcaya | 1 |
| 1208 | vivirá | 1 |
| 1209 | viviente | 1 |
| 1210 | vivido | 1 |
| 1211 | vivía | 1 |
| 1212 | vives | 1 |
| 1213 | vive | 1 |
| 1214 | viudo | 1 |
| 1215 | viudas | 1 |
| 1216 | vituperios | 1 |
| 1217 | vitorioso | 1 |
| 1218 | vistiese | 1 |
| 1219 | virtudes | 1 |
| 1220 | virgo | 1 |
| 1221 | virgen | 1 |
| 1222 | violento | 1 |
| 1223 | viole | 1 |
| 1224 | vine | 1 |
| 1225 | vimos | 1 |
| 1226 | villanos | 1 |
| 1227 | vil | 1 |
| 1228 | vigüelas | 1 |
| 1229 | vieran | 1 |
| 1230 | vienen | 1 |
| 1231 | viéndose | 1 |
| 1232 | viéndonos | 1 |
| 1233 | viéndome | 1 |
| 1234 | viéndole | 1 |
| 1235 | viejos | 1 |
| 1236 | viejo | 1 |
| 1237 | vieja | 1 |
| 1238 | vidrio | 1 |
| 1239 | vidas | 1 |
| 1240 | víctima | 1 |
| 1241 | vestidos | 1 |
| 1242 | vestidito | 1 |
| 1243 | vestí | 1 |
| 1244 | veros | 1 |
| 1245 | veréis | 1 |
| 1246 | verdura | 1 |
| 1247 | verdugos | 1 |
| 1248 | verdugo | 1 |
| 1249 | verdugado | 1 |
| 1250 | verdades | 1 |
| 1251 | verbo | 1 |
| 1252 | veraste | 1 |
| 1253 | verás | 1 |
| 1254 | verá | 1 |
| 1255 | venzo | 1 |
| 1256 | venturosa | 1 |
| 1257 | ventana | 1 |
| 1258 | ventaja | 1 |
| 1259 | venido | 1 |
| 1260 | venidero | 1 |
| 1261 | venideras | 1 |
| 1262 | venida | 1 |
| 1263 | venïales | 1 |
| 1264 | vengole | 1 |
| 1265 | vengativos | 1 |
| 1266 | vengarse | 1 |
| 1267 | vengar | 1 |
| 1268 | venganza | 1 |
| 1269 | venga | 1 |
| 1270 | venerable | 1 |
| 1271 | vendré | 1 |
| 1272 | vendrá | 1 |
| 1273 | vendiendo | 1 |
| 1274 | vendido | 1 |
| 1275 | vendederas | 1 |
| 1276 | venda | 1 |
| 1277 | vencido | 1 |
| 1278 | vencedora | 1 |
| 1279 | venado | 1 |
| 1280 | vemos | 1 |
| 1281 | velocísima | 1 |
| 1282 | velloso | 1 |
| 1283 | velillos | 1 |
| 1284 | veleta | 1 |
| 1285 | vela | 1 |
| 1286 | vejigas | 1 |
| 1287 | veintidoseno | 1 |
| 1288 | vecindad | 1 |
| 1289 | vean | 1 |
| 1290 | vea | 1 |
| 1291 | vaso | 1 |
| 1292 | vasallos | 1 |
| 1293 | varia | 1 |
| 1294 | vanos | 1 |
| 1295 | valonas | 1 |
| 1296 | valimiento | 1 |
| 1297 | valentía | 1 |
| 1298 | valen | 1 |
| 1299 | valdrá | 1 |
| 1300 | vais | 1 |
| 1301 | vainicas | 1 |
| 1302 | vacío | 1 |
| 1303 | vaciaba | 1 |
| 1304 | vacado | 1 |
| 1305 | vacada | 1 |
| 1306 | útil | 1 |
| 1307 | usurparon | 1 |
| 1308 | usura | 1 |
| 1309 | urnas | 1 |
| 1310 | uña | 1 |
| 1311 | untándolos | 1 |
| 1312 | unida | 1 |
| 1313 | ungüento | 1 |
| 1314 | umbrales | 1 |
| 1315 | tuyos | 1 |
| 1316 | tuviste | 1 |
| 1317 | tuvieron | 1 |
| 1318 | tuviera | 1 |
| 1319 | tutelares | 1 |
| 1320 | turquíes | 1 |
| 1321 | turco | 1 |
| 1322 | turbantes | 1 |
| 1323 | túmulo | 1 |
| 1324 | tuerces | 1 |
| 1325 | tudescos | 1 |
| 1326 | trujeron | 1 |
| 1327 | trueco | 1 |
| 1328 | trueca | 1 |
| 1329 | truchas | 1 |
| 1330 | trucha | 1 |
| 1331 | trote | 1 |
| 1332 | troquéis | 1 |
| 1333 | trono | 1 |
| 1334 | trongas | 1 |
| 1335 | troncos | 1 |
| 1336 | trompeta | 1 |
| 1337 | trofeos | 1 |
| 1338 | trocarme | 1 |
| 1339 | triunfante | 1 |
| 1340 | tristes | 1 |
| 1341 | tributo | 1 |
| 1342 | tretas | 1 |
| 1343 | trémulos | 1 |
| 1344 | treinta | 1 |
| 1345 | trazas | 1 |
| 1346 | tratos | 1 |
| 1347 | trato | 1 |
| 1348 | tratable | 1 |
| 1349 | trata | 1 |
| 1350 | trastes | 1 |
| 1351 | traspasos | 1 |
| 1352 | traseros | 1 |
| 1353 | transformadas | 1 |
| 1354 | tramposo | 1 |
| 1355 | traje | 1 |
| 1356 | traiga | 1 |
| 1357 | traidores | 1 |
| 1358 | traidor | 1 |
| 1359 | traiciones | 1 |
| 1360 | trágica | 1 |
| 1361 | tragar | 1 |
| 1362 | tragan | 1 |
| 1363 | traga | 1 |
| 1364 | traer | 1 |
| 1365 | trabaja | 1 |
| 1366 | total | 1 |
| 1367 | tórtolas | 1 |
| 1368 | torno | 1 |
| 1369 | torneos | 1 |
| 1370 | tormenta | 1 |
| 1371 | toque | 1 |
| 1372 | tontas | 1 |
| 1373 | tómeme | 1 |
| 1374 | tomé | 1 |
| 1375 | tómate | 1 |
| 1376 | tomando | 1 |
| 1377 | toma | 1 |
| 1378 | tocino | 1 |
| 1379 | tocando | 1 |
| 1380 | tócame | 1 |
| 1381 | toalla | 1 |
| 1382 | tizones | 1 |
| 1383 | tirano | 1 |
| 1384 | tiraniza | 1 |
| 1385 | tique | 1 |
| 1386 | tiña | 1 |
| 1387 | tinto | 1 |
| 1388 | tinteros | 1 |
| 1389 | tintero | 1 |
| 1390 | tiniebla | 1 |
| 1391 | timbre | 1 |
| 1392 | tiesa | 1 |
| 1393 | tiernas | 1 |
| 1394 | tiernamente | 1 |
| 1395 | tierna | 1 |
| 1396 | tiembla | 1 |
| 1397 | tiburón | 1 |
| 1398 | tesoros | 1 |
| 1399 | tesoro | 1 |
| 1400 | terrón | 1 |
| 1401 | ternezas | 1 |
| 1402 | terneza | 1 |
| 1403 | terciopelo | 1 |
| 1404 | tercianas | 1 |
| 1405 | tercero | 1 |
| 1406 | teñido | 1 |
| 1407 | tenerla | 1 |
| 1408 | tenella | 1 |
| 1409 | tenéis | 1 |
| 1410 | tenebrosas | 1 |
| 1411 | tenebrosa | 1 |
| 1412 | tendría | 1 |
| 1413 | tendremos | 1 |
| 1414 | tendréis | 1 |
| 1415 | tendero | 1 |
| 1416 | tenca | 1 |
| 1417 | temprano | 1 |
| 1418 | temprana | 1 |
| 1419 | templado | 1 |
| 1420 | templada | 1 |
| 1421 | temo | 1 |
| 1422 | temiéndole | 1 |
| 1423 | temida | 1 |
| 1424 | temeroso | 1 |
| 1425 | temerarios | 1 |
| 1426 | temer | 1 |
| 1427 | temen | 1 |
| 1428 | temblaron | 1 |
| 1429 | tejieron | 1 |
| 1430 | teja | 1 |
| 1431 | taza | 1 |
| 1432 | tasa | 1 |
| 1433 | tapetado | 1 |
| 1434 | tapadas | 1 |
| 1435 | tantos | 1 |
| 1436 | tamaño | 1 |
| 1437 | talle | 1 |
| 1438 | tajo | 1 |
| 1439 | tachas | 1 |
| 1440 | tablados | 1 |
| 1441 | taberna | 1 |
| 1442 | t | 1 |
| 1443 | suyos | 1 |
| 1444 | suyo | 1 |
| 1445 | suya | 1 |
| 1446 | sustento | 1 |
| 1447 | sustentarme | 1 |
| 1448 | sustentar | 1 |
| 1449 | sustentan | 1 |
| 1450 | suspirando | 1 |
| 1451 | suspiráis | 1 |
| 1452 | suspensión | 1 |
| 1453 | suspenda | 1 |
| 1454 | surcos | 1 |
| 1455 | supremo | 1 |
| 1456 | sumo | 1 |
| 1457 | sumergirse | 1 |
| 1458 | sumas | 1 |
| 1459 | sujetas | 1 |
| 1460 | sufridos | 1 |
| 1461 | sueños | 1 |
| 1462 | suenas | 1 |
| 1463 | sueltos | 1 |
| 1464 | suelta | 1 |
| 1465 | suelos | 1 |
| 1466 | suelen | 1 |
| 1467 | sucesores | 1 |
| 1468 | sucedido | 1 |
| 1469 | subir | 1 |
| 1470 | subió | 1 |
| 1471 | subiéronse | 1 |
| 1472 | süave | 1 |
| 1473 | suave | 1 |
| 1474 | sospechas | 1 |
| 1475 | sosegar | 1 |
| 1476 | soria | 1 |
| 1477 | sorben | 1 |
| 1478 | soplón | 1 |
| 1479 | soplo | 1 |
| 1480 | soplillo | 1 |
| 1481 | sopas | 1 |
| 1482 | sopa | 1 |
| 1483 | sonoro | 1 |
| 1484 | sonora | 1 |
| 1485 | sonido | 1 |
| 1486 | sombreros | 1 |
| 1487 | solos | 1 |
| 1488 | soledades | 1 |
| 1489 | soledad | 1 |
| 1490 | socorro | 1 |
| 1491 | socorrida | 1 |
| 1492 | sobresaltos | 1 |
| 1493 | sobran | 1 |
| 1494 | sobra | 1 |
| 1495 | sitio | 1 |
| 1496 | sírvole | 1 |
| 1497 | sirena | 1 |
| 1498 | sincero | 1 |
| 1499 | simples | 1 |
| 1500 | símbolo | 1 |
| 1501 | silvas | 1 |
| 1502 | sillas | 1 |
| 1503 | silbo | 1 |
| 1504 | signo | 1 |
| 1505 | sierpe | 1 |
| 1506 | sienes | 1 |
| 1507 | sido | 1 |
| 1508 | siciliana | 1 |
| 1509 | servís | 1 |
| 1510 | servir | 1 |
| 1511 | servicio | 1 |
| 1512 | servía | 1 |
| 1513 | serví | 1 |
| 1514 | sermones | 1 |
| 1515 | serenos | 1 |
| 1516 | serás | 1 |
| 1517 | seráficas | 1 |
| 1518 | sequen | 1 |
| 1519 | sepultura | 1 |
| 1520 | sepultadas | 1 |
| 1521 | sepultada | 1 |
| 1522 | sépase | 1 |
| 1523 | separa | 1 |
| 1524 | sepan | 1 |
| 1525 | seoto | 1 |
| 1526 | señas | 1 |
| 1527 | señal | 1 |
| 1528 | sentirlas | 1 |
| 1529 | sentimientos | 1 |
| 1530 | sentidos | 1 |
| 1531 | senos | 1 |
| 1532 | sencillo | 1 |
| 1533 | sencilla | 1 |
| 1534 | sembrar | 1 |
| 1535 | sembrados | 1 |
| 1536 | semblantes | 1 |
| 1537 | semblante | 1 |
| 1538 | sellaría | 1 |
| 1539 | seguro | 1 |
| 1540 | seguridad | 1 |
| 1541 | segundo | 1 |
| 1542 | seguidme | 1 |
| 1543 | segadores | 1 |
| 1544 | seda | 1 |
| 1545 | secretamente | 1 |
| 1546 | secas | 1 |
| 1547 | seas | 1 |
| 1548 | sazonado | 1 |
| 1549 | sayas | 1 |
| 1550 | saturno | 1 |
| 1551 | satisfecha | 1 |
| 1552 | satisfacer | 1 |
| 1553 | satírico | 1 |
| 1554 | sastre | 1 |
| 1555 | sarna | 1 |
| 1556 | sardinas | 1 |
| 1557 | saque | 1 |
| 1558 | sangres | 1 |
| 1559 | salvaréis | 1 |
| 1560 | saludó | 1 |
| 1561 | saludaron | 1 |
| 1562 | saluda | 1 |
| 1563 | salud | 1 |
| 1564 | salsa | 1 |
| 1565 | salmón | 1 |
| 1566 | salístele | 1 |
| 1567 | saliese | 1 |
| 1568 | salen | 1 |
| 1569 | salamandras | 1 |
| 1570 | salamandra | 1 |
| 1571 | salamanca | 1 |
| 1572 | salada | 1 |
| 1573 | sahagún | 1 |
| 1574 | sagrada | 1 |
| 1575 | sagaz | 1 |
| 1576 | saco | 1 |
| 1577 | sacarles | 1 |
| 1578 | sabor | 1 |
| 1579 | sabios | 1 |
| 1580 | sabias | 1 |
| 1581 | sabia | 1 |
| 1582 | rumia | 1 |
| 1583 | ruiseñores | 1 |
| 1584 | ruegos | 1 |
| 1585 | ruego | 1 |
| 1586 | ruedas | 1 |
| 1587 | rueda | 1 |
| 1588 | rudo | 1 |
| 1589 | rubíes | 1 |
| 1590 | rubias | 1 |
| 1591 | roto | 1 |
| 1592 | roque | 1 |
| 1593 | ropa | 1 |
| 1594 | ronda | 1 |
| 1595 | roncos | 1 |
| 1596 | roncha | 1 |
| 1597 | rompida | 1 |
| 1598 | romper | 1 |
| 1599 | rompe | 1 |
| 1600 | rompa | 1 |
| 1601 | rojos | 1 |
| 1602 | roída | 1 |
| 1603 | rodelas | 1 |
| 1604 | rocas | 1 |
| 1605 | roca | 1 |
| 1606 | robusta | 1 |
| 1607 | robles | 1 |
| 1608 | roballas | 1 |
| 1609 | rizado | 1 |
| 1610 | riyendo | 1 |
| 1611 | risueño | 1 |
| 1612 | riscos | 1 |
| 1613 | risada | 1 |
| 1614 | riqueza | 1 |
| 1615 | ríos | 1 |
| 1616 | rincón | 1 |
| 1617 | riguroso | 1 |
| 1618 | riéronse | 1 |
| 1619 | riendo | 1 |
| 1620 | riega | 1 |
| 1621 | ricas | 1 |
| 1622 | riberas | 1 |
| 1623 | ría | 1 |
| 1624 | revuelta | 1 |
| 1625 | revoca | 1 |
| 1626 | reverberan | 1 |
| 1627 | retruécano | 1 |
| 1628 | retrato | 1 |
| 1629 | retratada | 1 |
| 1630 | resucitó | 1 |
| 1631 | resucitado | 1 |
| 1632 | restituye | 1 |
| 1633 | restitúyanse | 1 |
| 1634 | restaurar | 1 |
| 1635 | resquicios | 1 |
| 1636 | respuestas | 1 |
| 1637 | respondió | 1 |
| 1638 | responde | 1 |
| 1639 | resplandeciente | 1 |
| 1640 | respiró | 1 |
| 1641 | resonaron | 1 |
| 1642 | resistir | 1 |
| 1643 | resistencia | 1 |
| 1644 | residencia | 1 |
| 1645 | resbalando | 1 |
| 1646 | resabios | 1 |
| 1647 | requiebros | 1 |
| 1648 | requiebro | 1 |
| 1649 | requebrare | 1 |
| 1650 | reputación | 1 |
| 1651 | reputaban | 1 |
| 1652 | república | 1 |
| 1653 | reprender | 1 |
| 1654 | reposo | 1 |
| 1655 | repollo | 1 |
| 1656 | repetir | 1 |
| 1657 | repetidas | 1 |
| 1658 | repetían | 1 |
| 1659 | repente | 1 |
| 1660 | repartidas | 1 |
| 1661 | reparas | 1 |
| 1662 | reñido | 1 |
| 1663 | renglones | 1 |
| 1664 | renacer | 1 |
| 1665 | remozar | 1 |
| 1666 | remos | 1 |
| 1667 | remolino | 1 |
| 1668 | remiendo | 1 |
| 1669 | remedio | 1 |
| 1670 | remaba | 1 |
| 1671 | relumbrante | 1 |
| 1672 | rejas | 1 |
| 1673 | rejalgar | 1 |
| 1674 | reír | 1 |
| 1675 | reinos | 1 |
| 1676 | reina | 1 |
| 1677 | regoldaba | 1 |
| 1678 | regó | 1 |
| 1679 | regís | 1 |
| 1680 | regiones | 1 |
| 1681 | regidas | 1 |
| 1682 | reforzoles | 1 |
| 1683 | redondillas | 1 |
| 1684 | recuerdos | 1 |
| 1685 | recuerdo | 1 |
| 1686 | rectos | 1 |
| 1687 | recostados | 1 |
| 1688 | recordada | 1 |
| 1689 | reconocimiento | 1 |
| 1690 | recibirle | 1 |
| 1691 | recibió | 1 |
| 1692 | recibille | 1 |
| 1693 | recibes | 1 |
| 1694 | recíbeme | 1 |
| 1695 | recelo | 1 |
| 1696 | recatos | 1 |
| 1697 | recataré | 1 |
| 1698 | recatado | 1 |
| 1699 | recata | 1 |
| 1700 | recancanilla | 1 |
| 1701 | rebelde | 1 |
| 1702 | realzar | 1 |
| 1703 | razones | 1 |
| 1704 | razonamientos | 1 |
| 1705 | rato | 1 |
| 1706 | rastillo | 1 |
| 1707 | rapiñas | 1 |
| 1708 | rapiña | 1 |
| 1709 | ranas | 1 |
| 1710 | rana | 1 |
| 1711 | ramplón | 1 |
| 1712 | ramos | 1 |
| 1713 | ramo | 1 |
| 1714 | ramillete | 1 |
| 1715 | raíz | 1 |
| 1716 | rábano | 1 |
| 1717 | quitóseme | 1 |
| 1718 | quitas | 1 |
| 1719 | quitarme | 1 |
| 1720 | quítame | 1 |
| 1721 | quisiere | 1 |
| 1722 | quietud | 1 |
| 1723 | quieren | 1 |
| 1724 | quieras | 1 |
| 1725 | querrá | 1 |
| 1726 | quererte | 1 |
| 1727 | querer | 1 |
| 1728 | querellas | 1 |
| 1729 | queredme | 1 |
| 1730 | quejosos | 1 |
| 1731 | quedas | 1 |
| 1732 | quedaron | 1 |
| 1733 | quedar | 1 |
| 1734 | queda | 1 |
| 1735 | quebranta | 1 |
| 1736 | quebrado | 1 |
| 1737 | pusieron | 1 |
| 1738 | púrpura | 1 |
| 1739 | punzón | 1 |
| 1740 | puntas | 1 |
| 1741 | punta | 1 |
| 1742 | pulpos | 1 |
| 1743 | pulgas | 1 |
| 1744 | pulga | 1 |
| 1745 | puja | 1 |
| 1746 | puesto | 1 |
| 1747 | puerto | 1 |
| 1748 | puerco | 1 |
| 1749 | pueda | 1 |
| 1750 | pueblos | 1 |
| 1751 | pueblo | 1 |
| 1752 | pudieran | 1 |
| 1753 | pude | 1 |
| 1754 | providencia | 1 |
| 1755 | provecho | 1 |
| 1756 | prosigue | 1 |
| 1757 | proseguir | 1 |
| 1758 | proprio | 1 |
| 1759 | proponga | 1 |
| 1760 | propio | 1 |
| 1761 | propiedades | 1 |
| 1762 | pronostican | 1 |
| 1763 | pronostica | 1 |
| 1764 | prometerme | 1 |
| 1765 | prolongadas | 1 |
| 1766 | profeta | 1 |
| 1767 | profeso | 1 |
| 1768 | produzca | 1 |
| 1769 | procura | 1 |
| 1770 | probado | 1 |
| 1771 | privar | 1 |
| 1772 | privado | 1 |
| 1773 | prisión | 1 |
| 1774 | pringados | 1 |
| 1775 | pringadas | 1 |
| 1776 | príncipes | 1 |
| 1777 | primogénita | 1 |
| 1778 | primeras | 1 |
| 1779 | prieto | 1 |
| 1780 | previene | 1 |
| 1781 | prevenir | 1 |
| 1782 | prevenida | 1 |
| 1783 | prevén | 1 |
| 1784 | pretenmuela | 1 |
| 1785 | pretendiente | 1 |
| 1786 | pretende | 1 |
| 1787 | pretenda | 1 |
| 1788 | presumiendo | 1 |
| 1789 | presumidas | 1 |
| 1790 | presuma | 1 |
| 1791 | prestarme | 1 |
| 1792 | prestar | 1 |
| 1793 | prestando | 1 |
| 1794 | prestadas | 1 |
| 1795 | preso | 1 |
| 1796 | presintiendo | 1 |
| 1797 | presentes | 1 |
| 1798 | presencia | 1 |
| 1799 | preparen | 1 |
| 1800 | preñado | 1 |
| 1801 | prender | 1 |
| 1802 | prendas | 1 |
| 1803 | premió | 1 |
| 1804 | predicaré | 1 |
| 1805 | predicador | 1 |
| 1806 | precursor | 1 |
| 1807 | preciosa | 1 |
| 1808 | precias | 1 |
| 1809 | preciado | 1 |
| 1810 | precia | 1 |
| 1811 | prados | 1 |
| 1812 | potente | 1 |
| 1813 | postre | 1 |
| 1814 | postigo | 1 |
| 1815 | posible | 1 |
| 1816 | poseer | 1 |
| 1817 | portugal | 1 |
| 1818 | porfiado | 1 |
| 1819 | pordiosero | 1 |
| 1820 | popa | 1 |
| 1821 | ponzoña | 1 |
| 1822 | poniente | 1 |
| 1823 | pónganme | 1 |
| 1824 | pomposa | 1 |
| 1825 | pompa | 1 |
| 1826 | pólvora | 1 |
| 1827 | polvo | 1 |
| 1828 | polo | 1 |
| 1829 | poeta | 1 |
| 1830 | poemas | 1 |
| 1831 | poema | 1 |
| 1832 | podré | 1 |
| 1833 | poderte | 1 |
| 1834 | pobláronse | 1 |
| 1835 | poblaréis | 1 |
| 1836 | plumaje | 1 |
| 1837 | plazos | 1 |
| 1838 | plazas | 1 |
| 1839 | plaza | 1 |
| 1840 | platos | 1 |
| 1841 | platón | 1 |
| 1842 | platicantes | 1 |
| 1843 | platería | 1 |
| 1844 | planetas | 1 |
| 1845 | plaga | 1 |
| 1846 | placeres | 1 |
| 1847 | placer | 1 |
| 1848 | pitágoras | 1 |
| 1849 | pisó | 1 |
| 1850 | pisé | 1 |
| 1851 | pisar | 1 |
| 1852 | piropos | 1 |
| 1853 | piras | 1 |
| 1854 | pintó | 1 |
| 1855 | pintando | 1 |
| 1856 | pintada | 1 |
| 1857 | pimientos | 1 |
| 1858 | pimienta | 1 |
| 1859 | piezas | 1 |
| 1860 | pierden | 1 |
| 1861 | pierda | 1 |
| 1862 | piénsanse | 1 |
| 1863 | piensan | 1 |
| 1864 | pieles | 1 |
| 1865 | piélago | 1 |
| 1866 | pido | 1 |
| 1867 | pidió | 1 |
| 1868 | pidiere | 1 |
| 1869 | pidiendo | 1 |
| 1870 | picos | 1 |
| 1871 | picar | 1 |
| 1872 | picantes | 1 |
| 1873 | picados | 1 |
| 1874 | pica | 1 |
| 1875 | piadosa | 1 |
| 1876 | peto | 1 |
| 1877 | pestilencia | 1 |
| 1878 | peste | 1 |
| 1879 | pesco | 1 |
| 1880 | pescados | 1 |
| 1881 | pescada | 1 |
| 1882 | pesas | 1 |
| 1883 | pesar | 1 |
| 1884 | persuadir | 1 |
| 1885 | persuadida | 1 |
| 1886 | persuade | 1 |
| 1887 | perseverad | 1 |
| 1888 | persecución | 1 |
| 1889 | perrengues | 1 |
| 1890 | permitía | 1 |
| 1891 | perfumadas | 1 |
| 1892 | perfeta | 1 |
| 1893 | perfecto | 1 |
| 1894 | perfección | 1 |
| 1895 | perezosa | 1 |
| 1896 | pereza | 1 |
| 1897 | peregrinas | 1 |
| 1898 | peregrinando | 1 |
| 1899 | peregrinaciones | 1 |
| 1900 | perdone | 1 |
| 1901 | perdonaron | 1 |
| 1902 | perdiendo | 1 |
| 1903 | perdido | 1 |
| 1904 | pérdida | 1 |
| 1905 | perdición | 1 |
| 1906 | pepita | 1 |
| 1907 | pepino | 1 |
| 1908 | peñas | 1 |
| 1909 | pensión | 1 |
| 1910 | penséis | 1 |
| 1911 | pensamientos | 1 |
| 1912 | penoso | 1 |
| 1913 | pelones | 1 |
| 1914 | peligroso | 1 |
| 1915 | peligran | 1 |
| 1916 | pelayo | 1 |
| 1917 | peje | 1 |
| 1918 | pegan | 1 |
| 1919 | pedro | 1 |
| 1920 | pedradas | 1 |
| 1921 | pedidla | 1 |
| 1922 | pedí | 1 |
| 1923 | pechos | 1 |
| 1924 | pe | 1 |
| 1925 | pausa | 1 |
| 1926 | patio | 1 |
| 1927 | pasto | 1 |
| 1928 | pasó | 1 |
| 1929 | paseo | 1 |
| 1930 | pasarás | 1 |
| 1931 | pasajero | 1 |
| 1932 | pasadnos | 1 |
| 1933 | pasada | 1 |
| 1934 | partir | 1 |
| 1935 | partes | 1 |
| 1936 | parlera | 1 |
| 1937 | parlen | 1 |
| 1938 | pariome | 1 |
| 1939 | pariera | 1 |
| 1940 | parezca | 1 |
| 1941 | pareciendo | 1 |
| 1942 | parecida | 1 |
| 1943 | parecía | 1 |
| 1944 | pareceres | 1 |
| 1945 | parecerán | 1 |
| 1946 | pardos | 1 |
| 1947 | pardas | 1 |
| 1948 | paraíso | 1 |
| 1949 | par | 1 |
| 1950 | papel | 1 |
| 1951 | pápate | 1 |
| 1952 | panzudo | 1 |
| 1953 | pantanos | 1 |
| 1954 | pancaya | 1 |
| 1955 | palustre | 1 |
| 1956 | palpe | 1 |
| 1957 | palos | 1 |
| 1958 | palor | 1 |
| 1959 | palmas | 1 |
| 1960 | pálido | 1 |
| 1961 | paletilla | 1 |
| 1962 | palacio | 1 |
| 1963 | palabras | 1 |
| 1964 | palabra | 1 |
| 1965 | paje | 1 |
| 1966 | pagan | 1 |
| 1967 | padre | 1 |
| 1968 | paces | 1 |
| 1969 | pablillos | 1 |
| 1970 | pa | 1 |
| 1971 | oyere | 1 |
| 1972 | oyente | 1 |
| 1973 | óyeme | 1 |
| 1974 | oye | 1 |
| 1975 | ovidio | 1 |
| 1976 | ovas | 1 |
| 1977 | osorio | 1 |
| 1978 | ose | 1 |
| 1979 | oscuros | 1 |
| 1980 | oscuras | 1 |
| 1981 | osadía | 1 |
| 1982 | osa | 1 |
| 1983 | oropel | 1 |
| 1984 | ornamento | 1 |
| 1985 | orillas | 1 |
| 1986 | originales | 1 |
| 1987 | orgullo | 1 |
| 1988 | organizando | 1 |
| 1989 | orfeos | 1 |
| 1990 | oreja | 1 |
| 1991 | ordenad | 1 |
| 1992 | ordena | 1 |
| 1993 | orbe | 1 |
| 1994 | oprime | 1 |
| 1995 | opilación | 1 |
| 1996 | onzas | 1 |
| 1997 | ondas | 1 |
| 1998 | omnipotente | 1 |
| 1999 | olvide | 1 |
| 2000 | olvidarle | 1 |
| 2001 | olvidares | 1 |
| 2002 | olvidadas | 1 |
| 2003 | olvida | 1 |
| 2004 | olorosas | 1 |
| 2005 | olor | 1 |
| 2006 | olla | 1 |
| 2007 | olivares | 1 |
| 2008 | oliendo | 1 |
| 2009 | ojo | 1 |
| 2010 | ojalá | 1 |
| 2011 | oirás | 1 |
| 2012 | oirán | 1 |
| 2013 | oídos | 1 |
| 2014 | oía | 1 |
| 2015 | oí | 1 |
| 2016 | oh | 1 |
| 2017 | ofrezca | 1 |
| 2018 | ofrecido | 1 |
| 2019 | ofrece | 1 |
| 2020 | ofensas | 1 |
| 2021 | ofensa | 1 |
| 2022 | ofender | 1 |
| 2023 | ofenda | 1 |
| 2024 | ocioso | 1 |
| 2025 | ocio | 1 |
| 2026 | océano | 1 |
| 2027 | ocasos | 1 |
| 2028 | ocaso | 1 |
| 2029 | obstinación | 1 |
| 2030 | observante | 1 |
| 2031 | obra | 1 |
| 2032 | obligar | 1 |
| 2033 | obligación | 1 |
| 2034 | objeciones | 1 |
| 2035 | obediente | 1 |
| 2036 | números | 1 |
| 2037 | nubes | 1 |
| 2038 | nube | 1 |
| 2039 | noviembre | 1 |
| 2040 | notomía | 1 |
| 2041 | notifiques | 1 |
| 2042 | nota | 1 |
| 2043 | nombro | 1 |
| 2044 | nombres | 1 |
| 2045 | nombrara | 1 |
| 2046 | nocturno | 1 |
| 2047 | noches | 1 |
| 2048 | nobleza | 1 |
| 2049 | noble | 1 |
| 2050 | niños | 1 |
| 2051 | niñez | 1 |
| 2052 | niñerías | 1 |
| 2053 | ninguna | 1 |
| 2054 | ningún | 1 |
| 2055 | ninfas | 1 |
| 2056 | ninfa | 1 |
| 2057 | nieve | 1 |
| 2058 | niega | 1 |
| 2059 | negociados | 1 |
| 2060 | negáis | 1 |
| 2061 | necias | 1 |
| 2062 | necesidad | 1 |
| 2063 | necedad | 1 |
| 2064 | navega | 1 |
| 2065 | naranja | 1 |
| 2066 | nadará | 1 |
| 2067 | nadan | 1 |
| 2068 | nadador | 1 |
| 2069 | nación | 1 |
| 2070 | nacieron | 1 |
| 2071 | naciera | 1 |
| 2072 | nacida | 1 |
| 2073 | nacía | 1 |
| 2074 | nacer | 1 |
| 2075 | nabo | 1 |
| 2076 | muzas | 1 |
| 2077 | mustias | 1 |
| 2078 | músicos | 1 |
| 2079 | músicas | 1 |
| 2080 | musas | 1 |
| 2081 | murmurando | 1 |
| 2082 | murieron | 1 |
| 2083 | muriendo | 1 |
| 2084 | múrice | 1 |
| 2085 | murciélagos | 1 |
| 2086 | munición | 1 |
| 2087 | multiplique | 1 |
| 2088 | multiplicó | 1 |
| 2089 | mula | 1 |
| 2090 | mujeres | 1 |
| 2091 | mueves | 1 |
| 2092 | muestra | 1 |
| 2093 | mueres | 1 |
| 2094 | mueran | 1 |
| 2095 | muera | 1 |
| 2096 | mudos | 1 |
| 2097 | mudarme | 1 |
| 2098 | mudando | 1 |
| 2099 | mudado | 1 |
| 2100 | muchachuelos | 1 |
| 2101 | muchacha | 1 |
| 2102 | moza | 1 |
| 2103 | mote | 1 |
| 2104 | mostraron | 1 |
| 2105 | mostrarme | 1 |
| 2106 | mostraba | 1 |
| 2107 | mosquito | 1 |
| 2108 | mosquetes | 1 |
| 2109 | mosquete | 1 |
| 2110 | mortal | 1 |
| 2111 | morirse | 1 |
| 2112 | morirme | 1 |
| 2113 | moreno | 1 |
| 2114 | morder | 1 |
| 2115 | morcillas | 1 |
| 2116 | morado | 1 |
| 2117 | morada | 1 |
| 2118 | monte | 1 |
| 2119 | monjas | 1 |
| 2120 | mondragón | 1 |
| 2121 | mondongo | 1 |
| 2122 | monda | 1 |
| 2123 | monarcas | 1 |
| 2124 | molestan | 1 |
| 2125 | molerlos | 1 |
| 2126 | mojarrilla | 1 |
| 2127 | mofen | 1 |
| 2128 | mitad | 1 |
| 2129 | misterios | 1 |
| 2130 | mísero | 1 |
| 2131 | misericordia | 1 |
| 2132 | misas | 1 |
| 2133 | miró | 1 |
| 2134 | miro | 1 |
| 2135 | mirlados | 1 |
| 2136 | mirasen | 1 |
| 2137 | miraron | 1 |
| 2138 | mirares | 1 |
| 2139 | mirándoos | 1 |
| 2140 | mirallos | 1 |
| 2141 | mirad | 1 |
| 2142 | miraba | 1 |
| 2143 | mique | 1 |
| 2144 | míos | 1 |
| 2145 | mintió | 1 |
| 2146 | minero | 1 |
| 2147 | mimosas | 1 |
| 2148 | millares | 1 |
| 2149 | militar | 1 |
| 2150 | militando | 1 |
| 2151 | milagros | 1 |
| 2152 | mientras | 1 |
| 2153 | miembros | 1 |
| 2154 | mielgas | 1 |
| 2155 | mide | 1 |
| 2156 | mesurado | 1 |
| 2157 | mesmos | 1 |
| 2158 | mesma | 1 |
| 2159 | mero | 1 |
| 2160 | merluzas | 1 |
| 2161 | méritos | 1 |
| 2162 | meridiano | 1 |
| 2163 | merezco | 1 |
| 2164 | merecimiento | 1 |
| 2165 | merecidos | 1 |
| 2166 | merecido | 1 |
| 2167 | merecerte | 1 |
| 2168 | merecer | 1 |
| 2169 | merecen | 1 |
| 2170 | merced | 1 |
| 2171 | menuda | 1 |
| 2172 | mendigando | 1 |
| 2173 | memorias | 1 |
| 2174 | melón | 1 |
| 2175 | mejora | 1 |
| 2176 | medrosos | 1 |
| 2177 | medirlas | 1 |
| 2178 | medida | 1 |
| 2179 | medias | 1 |
| 2180 | media | 1 |
| 2181 | mayores | 1 |
| 2182 | maullar | 1 |
| 2183 | matronas | 1 |
| 2184 | matrimonio | 1 |
| 2185 | mató | 1 |
| 2186 | materia | 1 |
| 2187 | matéis | 1 |
| 2188 | matarme | 1 |
| 2189 | matanza | 1 |
| 2190 | matando | 1 |
| 2191 | mataduras | 1 |
| 2192 | matada | 1 |
| 2193 | martos | 1 |
| 2194 | martín | 1 |
| 2195 | marte | 1 |
| 2196 | marta | 1 |
| 2197 | marlota | 1 |
| 2198 | márgenes | 1 |
| 2199 | margarita | 1 |
| 2200 | mares | 1 |
| 2201 | marchando | 1 |
| 2202 | maravillas | 1 |
| 2203 | maravilla | 1 |
| 2204 | maravedís | 1 |
| 2205 | mantos | 1 |
| 2206 | manto | 1 |
| 2207 | mantilla | 1 |
| 2208 | manteles | 1 |
| 2209 | manjar | 1 |
| 2210 | mandarme | 1 |
| 2211 | mandar | 1 |
| 2212 | mandallo | 1 |
| 2213 | manchó | 1 |
| 2214 | mancebito | 1 |
| 2215 | malva | 1 |
| 2216 | malo | 1 |
| 2217 | malicias | 1 |
| 2218 | males | 1 |
| 2219 | maldice | 1 |
| 2220 | magra | 1 |
| 2221 | madurando | 1 |
| 2222 | madura | 1 |
| 2223 | macilento | 1 |
| 2224 | luzbel | 1 |
| 2225 | luto | 1 |
| 2226 | lumbres | 1 |
| 2227 | lumbre | 1 |
| 2228 | lujuria | 1 |
| 2229 | luisa | 1 |
| 2230 | lugares | 1 |
| 2231 | lucientes | 1 |
| 2232 | luciano | 1 |
| 2233 | lúbricos | 1 |
| 2234 | lógrelas | 1 |
| 2235 | lógrala | 1 |
| 2236 | lograd | 1 |
| 2237 | lograba | 1 |
| 2238 | loco | 1 |
| 2239 | locas | 1 |
| 2240 | loca | 1 |
| 2241 | loa | 1 |
| 2242 | lloroso | 1 |
| 2243 | lloro | 1 |
| 2244 | llore | 1 |
| 2245 | llevó | 1 |
| 2246 | llévenme | 1 |
| 2247 | llevéis | 1 |
| 2248 | llevaste | 1 |
| 2249 | llevarse | 1 |
| 2250 | llevarás | 1 |
| 2251 | llevara | 1 |
| 2252 | llevar | 1 |
| 2253 | llevando | 1 |
| 2254 | lleva | 1 |
| 2255 | llenas | 1 |
| 2256 | llegases | 1 |
| 2257 | llegaron | 1 |
| 2258 | llegar | 1 |
| 2259 | llegan | 1 |
| 2260 | llegado | 1 |
| 2261 | llega | 1 |
| 2262 | llantos | 1 |
| 2263 | llanos | 1 |
| 2264 | llame | 1 |
| 2265 | llamáronme | 1 |
| 2266 | llamará | 1 |
| 2267 | llamar | 1 |
| 2268 | llamaba | 1 |
| 2269 | llagas | 1 |
| 2270 | liviana | 1 |
| 2271 | litera | 1 |
| 2272 | lisonjera | 1 |
| 2273 | lísida | 1 |
| 2274 | lisa | 1 |
| 2275 | líquido | 1 |
| 2276 | linsojera | 1 |
| 2277 | líneas | 1 |
| 2278 | línea | 1 |
| 2279 | linda | 1 |
| 2280 | linaje | 1 |
| 2281 | limpia | 1 |
| 2282 | limón | 1 |
| 2283 | límites | 1 |
| 2284 | limitados | 1 |
| 2285 | limbo | 1 |
| 2286 | limado | 1 |
| 2287 | lima | 1 |
| 2288 | ligustre | 1 |
| 2289 | liguria | 1 |
| 2290 | ligero | 1 |
| 2291 | ligas | 1 |
| 2292 | lidora | 1 |
| 2293 | licencia | 1 |
| 2294 | libró | 1 |
| 2295 | libra | 1 |
| 2296 | levantó | 1 |
| 2297 | levantar | 1 |
| 2298 | letrillas | 1 |
| 2299 | letrado | 1 |
| 2300 | lesna | 1 |
| 2301 | león | 1 |
| 2302 | lenguas | 1 |
| 2303 | legítimos | 1 |
| 2304 | legiones | 1 |
| 2305 | lector | 1 |
| 2306 | lechuga | 1 |
| 2307 | lazos | 1 |
| 2308 | lazo | 1 |
| 2309 | laváronse | 1 |
| 2310 | laureles | 1 |
| 2311 | latinosa | 1 |
| 2312 | lanzada | 1 |
| 2313 | langosta | 1 |
| 2314 | lance | 1 |
| 2315 | lana | 1 |
| 2316 | lampreas | 1 |
| 2317 | lamentos | 1 |
| 2318 | ladridos | 1 |
| 2319 | ladrido | 1 |
| 2320 | laderas | 1 |
| 2321 | lacayos | 1 |
| 2322 | labrador | 1 |
| 2323 | labrada | 1 |
| 2324 | labores | 1 |
| 2325 | labor | 1 |
| 2326 | justas | 1 |
| 2327 | justamente | 1 |
| 2328 | jure | 1 |
| 2329 | juraste | 1 |
| 2330 | juntos | 1 |
| 2331 | junto | 1 |
| 2332 | juglar | 1 |
| 2333 | juegos | 1 |
| 2334 | jueces | 1 |
| 2335 | jubón | 1 |
| 2336 | joven | 1 |
| 2337 | jetas | 1 |
| 2338 | jerez | 1 |
| 2339 | jardineros | 1 |
| 2340 | jara | 1 |
| 2341 | jaque | 1 |
| 2342 | jácaras | 1 |
| 2343 | jácara | 1 |
| 2344 | italia | 1 |
| 2345 | irrevocable | 1 |
| 2346 | iris | 1 |
| 2347 | ir | 1 |
| 2348 | invoca | 1 |
| 2349 | invierno | 1 |
| 2350 | invidioso | 1 |
| 2351 | invidiosas | 1 |
| 2352 | inundación | 1 |
| 2353 | intercediendo | 1 |
| 2354 | intentara | 1 |
| 2355 | intención | 1 |
| 2356 | instante | 1 |
| 2357 | insolente | 1 |
| 2358 | inquietos | 1 |
| 2359 | inocente | 1 |
| 2360 | inobediencia | 1 |
| 2361 | inmenso | 1 |
| 2362 | inmensidad | 1 |
| 2363 | inmensas | 1 |
| 2364 | injuria | 1 |
| 2365 | inhibitoria | 1 |
| 2366 | ingratas | 1 |
| 2367 | ingenio | 1 |
| 2368 | información | 1 |
| 2369 | infinita | 1 |
| 2370 | infierno | 1 |
| 2371 | infiel | 1 |
| 2372 | inexorable | 1 |
| 2373 | industriosa | 1 |
| 2374 | indicios | 1 |
| 2375 | indicio | 1 |
| 2376 | indias | 1 |
| 2377 | inclinó | 1 |
| 2378 | incline | 1 |
| 2379 | inclinar | 1 |
| 2380 | inclinado | 1 |
| 2381 | inclina | 1 |
| 2382 | inclemente | 1 |
| 2383 | incendios | 1 |
| 2384 | imposible | 1 |
| 2385 | importunan | 1 |
| 2386 | importar | 1 |
| 2387 | importantes | 1 |
| 2388 | importa | 1 |
| 2389 | implicación | 1 |
| 2390 | impida | 1 |
| 2391 | impedida | 1 |
| 2392 | imitarán | 1 |
| 2393 | imitación | 1 |
| 2394 | imita | 1 |
| 2395 | ilustre | 1 |
| 2396 | illana | 1 |
| 2397 | iguales | 1 |
| 2398 | igualase | 1 |
| 2399 | ignorantes | 1 |
| 2400 | idolatre | 1 |
| 2401 | idólatra | 1 |
| 2402 | iban | 1 |
| 2403 | iba | 1 |
| 2404 | huyeron | 1 |
| 2405 | huye | 1 |
| 2406 | hurte | 1 |
| 2407 | hurtar | 1 |
| 2408 | hundíase | 1 |
| 2409 | humor | 1 |
| 2410 | humo | 1 |
| 2411 | humillo | 1 |
| 2412 | humildes | 1 |
| 2413 | humanos | 1 |
| 2414 | humanidad | 1 |
| 2415 | huevo | 1 |
| 2416 | huestes | 1 |
| 2417 | hueste | 1 |
| 2418 | huésped | 1 |
| 2419 | huérfano | 1 |
| 2420 | hospedaron | 1 |
| 2421 | hosanna | 1 |
| 2422 | horror | 1 |
| 2423 | horrendo | 1 |
| 2424 | horrenda | 1 |
| 2425 | horca | 1 |
| 2426 | honrosos | 1 |
| 2427 | honrados | 1 |
| 2428 | honradas | 1 |
| 2429 | honrada | 1 |
| 2430 | honores | 1 |
| 2431 | honestidad | 1 |
| 2432 | honesta | 1 |
| 2433 | hondos | 1 |
| 2434 | homero | 1 |
| 2435 | hollín | 1 |
| 2436 | hollé | 1 |
| 2437 | holandés | 1 |
| 2438 | holanda | 1 |
| 2439 | historias | 1 |
| 2440 | hiriendo | 1 |
| 2441 | hinchados | 1 |
| 2442 | hincársele | 1 |
| 2443 | himnos | 1 |
| 2444 | himno | 1 |
| 2445 | hilaba | 1 |
| 2446 | hijas | 1 |
| 2447 | hijadas | 1 |
| 2448 | hierros | 1 |
| 2449 | hierro | 1 |
| 2450 | hiere | 1 |
| 2451 | hiel | 1 |
| 2452 | hervores | 1 |
| 2453 | herreros | 1 |
| 2454 | herradores | 1 |
| 2455 | heroico | 1 |
| 2456 | hermosuras | 1 |
| 2457 | hermosísima | 1 |
| 2458 | hermosas | 1 |
| 2459 | herido | 1 |
| 2460 | herida | 1 |
| 2461 | herencias | 1 |
| 2462 | herejes | 1 |
| 2463 | heredero | 1 |
| 2464 | heredad | 1 |
| 2465 | helado | 1 |
| 2466 | helada | 1 |
| 2467 | hechicera | 1 |
| 2468 | hechas | 1 |
| 2469 | hebras | 1 |
| 2470 | hebra | 1 |
| 2471 | hazaña | 1 |
| 2472 | hayas | 1 |
| 2473 | hartura | 1 |
| 2474 | hartos | 1 |
| 2475 | hartaba | 1 |
| 2476 | haremos | 1 |
| 2477 | hará | 1 |
| 2478 | hallo | 1 |
| 2479 | halle | 1 |
| 2480 | hállate | 1 |
| 2481 | hallarte | 1 |
| 2482 | hallarle | 1 |
| 2483 | halláramos | 1 |
| 2484 | halago | 1 |
| 2485 | hacerme | 1 |
| 2486 | haced | 1 |
| 2487 | hablo | 1 |
| 2488 | hablen | 1 |
| 2489 | hablemos | 1 |
| 2490 | habláis | 1 |
| 2491 | hablado | 1 |
| 2492 | hablada | 1 |
| 2493 | habla | 1 |
| 2494 | hábito | 1 |
| 2495 | habita | 1 |
| 2496 | haberte | 1 |
| 2497 | haberlo | 1 |
| 2498 | haberle | 1 |
| 2499 | habéis | 1 |
| 2500 | habas | 1 |
| 2501 | guzmanes | 1 |
| 2502 | guzmán | 1 |
| 2503 | gustos | 1 |
| 2504 | gusano | 1 |
| 2505 | gula | 1 |
| 2506 | guirnalda | 1 |
| 2507 | guineo | 1 |
| 2508 | guinda | 1 |
| 2509 | guijas | 1 |
| 2510 | guerrero | 1 |
| 2511 | guedejas | 1 |
| 2512 | guareció | 1 |
| 2513 | guárdese | 1 |
| 2514 | guarde | 1 |
| 2515 | guardasol | 1 |
| 2516 | guardas | 1 |
| 2517 | guardan | 1 |
| 2518 | guardáis | 1 |
| 2519 | grosero | 1 |
| 2520 | grito | 1 |
| 2521 | grillos | 1 |
| 2522 | greña | 1 |
| 2523 | grecizante | 1 |
| 2524 | graves | 1 |
| 2525 | grave | 1 |
| 2526 | grandezas | 1 |
| 2527 | granada | 1 |
| 2528 | graduó | 1 |
| 2529 | grados | 1 |
| 2530 | gradas | 1 |
| 2531 | gozo | 1 |
| 2532 | gózante | 1 |
| 2533 | gozan | 1 |
| 2534 | gorrón | 1 |
| 2535 | gorja | 1 |
| 2536 | gordiviejas | 1 |
| 2537 | gonces | 1 |
| 2538 | golpes | 1 |
| 2539 | golondrina | 1 |
| 2540 | golfos | 1 |
| 2541 | golfo | 1 |
| 2542 | godos | 1 |
| 2543 | godo | 1 |
| 2544 | gocéis | 1 |
| 2545 | glosado | 1 |
| 2546 | glorïoso | 1 |
| 2547 | gloriosas | 1 |
| 2548 | gloriosa | 1 |
| 2549 | glorias | 1 |
| 2550 | gimió | 1 |
| 2551 | gimieron | 1 |
| 2552 | geometría | 1 |
| 2553 | gentil | 1 |
| 2554 | génova | 1 |
| 2555 | generoso | 1 |
| 2556 | género | 1 |
| 2557 | gaznate | 1 |
| 2558 | gasté | 1 |
| 2559 | gaste | 1 |
| 2560 | gastáramos | 1 |
| 2561 | gastan | 1 |
| 2562 | gaspar | 1 |
| 2563 | garzota | 1 |
| 2564 | garras | 1 |
| 2565 | gargantas | 1 |
| 2566 | ganados | 1 |
| 2567 | ganado | 1 |
| 2568 | ganadero | 1 |
| 2569 | gallo | 1 |
| 2570 | gallarda | 1 |
| 2571 | galeras | 1 |
| 2572 | galardón | 1 |
| 2573 | furiosa | 1 |
| 2574 | furia | 1 |
| 2575 | fundo | 1 |
| 2576 | fundas | 1 |
| 2577 | fulmina | 1 |
| 2578 | fuiste | 1 |
| 2579 | fui | 1 |
| 2580 | fugitivo | 1 |
| 2581 | fueses | 1 |
| 2582 | fuese | 1 |
| 2583 | fuero | 1 |
| 2584 | fueres | 1 |
| 2585 | fuereis | 1 |
| 2586 | fuere | 1 |
| 2587 | fuéramos | 1 |
| 2588 | fuentes | 1 |
| 2589 | fruto | 1 |
| 2590 | frías | 1 |
| 2591 | frescona | 1 |
| 2592 | francisca | 1 |
| 2593 | fraile | 1 |
| 2594 | fragmentos | 1 |
| 2595 | fragante | 1 |
| 2596 | fortalezas | 1 |
| 2597 | formidable | 1 |
| 2598 | forastero | 1 |
| 2599 | forastera | 1 |
| 2600 | fondos | 1 |
| 2601 | floro | 1 |
| 2602 | florecilla | 1 |
| 2603 | flora | 1 |
| 2604 | flechas | 1 |
| 2605 | flaquezas | 1 |
| 2606 | flaqueza | 1 |
| 2607 | flaco | 1 |
| 2608 | flacas | 1 |
| 2609 | firmada | 1 |
| 2610 | fío | 1 |
| 2611 | fingiendo | 1 |
| 2612 | fineza | 1 |
| 2613 | finas | 1 |
| 2614 | fina | 1 |
| 2615 | filósofos | 1 |
| 2616 | filos | 1 |
| 2617 | fijas | 1 |
| 2618 | fijada | 1 |
| 2619 | fíes | 1 |
| 2620 | fiereza | 1 |
| 2621 | fiera | 1 |
| 2622 | fieltro | 1 |
| 2623 | fidalgos | 1 |
| 2624 | fez | 1 |
| 2625 | fénix | 1 |
| 2626 | fembras | 1 |
| 2627 | feliz | 1 |
| 2628 | fanfarrones | 1 |
| 2629 | fanfarria | 1 |
| 2630 | familia | 1 |
| 2631 | faltas | 1 |
| 2632 | faltan | 1 |
| 2633 | falta | 1 |
| 2634 | falsete | 1 |
| 2635 | falsa | 1 |
| 2636 | faldas | 1 |
| 2637 | falda | 1 |
| 2638 | faetón | 1 |
| 2639 | fabricando | 1 |
| 2640 | fabio | 1 |
| 2641 | extraños | 1 |
| 2642 | explayábase | 1 |
| 2643 | expiraba | 1 |
| 2644 | expira | 1 |
| 2645 | exequias | 1 |
| 2646 | exenta | 1 |
| 2647 | excelso | 1 |
| 2648 | excelentísimo | 1 |
| 2649 | excede | 1 |
| 2650 | examina | 1 |
| 2651 | exagere | 1 |
| 2652 | eternidad | 1 |
| 2653 | eternas | 1 |
| 2654 | eternamente | 1 |
| 2655 | eterna | 1 |
| 2656 | estudioso | 1 |
| 2657 | estudio | 1 |
| 2658 | estudiaron | 1 |
| 2659 | estudiara | 1 |
| 2660 | estrujada | 1 |
| 2661 | estrenad | 1 |
| 2662 | estrechamente | 1 |
| 2663 | estraza | 1 |
| 2664 | estraga | 1 |
| 2665 | estrado | 1 |
| 2666 | estotro | 1 |
| 2667 | estornudos | 1 |
| 2668 | estornudaba | 1 |
| 2669 | estornuda | 1 |
| 2670 | estorbo | 1 |
| 2671 | estorba | 1 |
| 2672 | estimalde | 1 |
| 2673 | estimación | 1 |
| 2674 | estima | 1 |
| 2675 | estilos | 1 |
| 2676 | estériles | 1 |
| 2677 | estén | 1 |
| 2678 | estéis | 1 |
| 2679 | estáis | 1 |
| 2680 | estado | 1 |
| 2681 | estables | 1 |
| 2682 | esquivos | 1 |
| 2683 | esquivas | 1 |
| 2684 | esqueleto | 1 |
| 2685 | esposa | 1 |
| 2686 | esponja | 1 |
| 2687 | esplendores | 1 |
| 2688 | espléndidas | 1 |
| 2689 | espina | 1 |
| 2690 | espigas | 1 |
| 2691 | espías | 1 |
| 2692 | espiada | 1 |
| 2693 | espía | 1 |
| 2694 | espeso | 1 |
| 2695 | espere | 1 |
| 2696 | esperanzas | 1 |
| 2697 | esperanza | 1 |
| 2698 | esperan | 1 |
| 2699 | espejo | 1 |
| 2700 | esparto | 1 |
| 2701 | españolas | 1 |
| 2702 | espantéis | 1 |
| 2703 | esmeralda | 1 |
| 2704 | esmaltada | 1 |
| 2705 | esforzaban | 1 |
| 2706 | esfera | 1 |
| 2707 | ese | 1 |
| 2708 | escudo | 1 |
| 2709 | escuche | 1 |
| 2710 | escuchad | 1 |
| 2711 | escuadrones | 1 |
| 2712 | escuadrón | 1 |
| 2713 | escrita | 1 |
| 2714 | escribiré | 1 |
| 2715 | escribir | 1 |
| 2716 | escribió | 1 |
| 2717 | escribiendo | 1 |
| 2718 | escríbase | 1 |
| 2719 | escribano | 1 |
| 2720 | escorpión | 1 |
| 2721 | escondieron | 1 |
| 2722 | escondido | 1 |
| 2723 | escondida | 1 |
| 2724 | escondían | 1 |
| 2725 | esconderla | 1 |
| 2726 | esconde | 1 |
| 2727 | esclava | 1 |
| 2728 | esclarecido | 1 |
| 2729 | esclarecidas | 1 |
| 2730 | esclarecida | 1 |
| 2731 | escapó | 1 |
| 2732 | escandalice | 1 |
| 2733 | escamas | 1 |
| 2734 | esas | 1 |
| 2735 | eruditos | 1 |
| 2736 | errante | 1 |
| 2737 | erizo | 1 |
| 2738 | equívocos | 1 |
| 2739 | epíteto | 1 |
| 2740 | epístolas | 1 |
| 2741 | epístola | 1 |
| 2742 | enzarza | 1 |
| 2743 | envuelto | 1 |
| 2744 | envuelta | 1 |
| 2745 | envidiados | 1 |
| 2746 | envía | 1 |
| 2747 | envejecer | 1 |
| 2748 | entró | 1 |
| 2749 | entretener | 1 |
| 2750 | entresuelos | 1 |
| 2751 | entregué | 1 |
| 2752 | entregó | 1 |
| 2753 | entrare | 1 |
| 2754 | entrar | 1 |
| 2755 | entrando | 1 |
| 2756 | entráis | 1 |
| 2757 | entrada | 1 |
| 2758 | entierro | 1 |
| 2759 | entierra | 1 |
| 2760 | entiendo | 1 |
| 2761 | entiendas | 1 |
| 2762 | enterrado | 1 |
| 2763 | enternecieron | 1 |
| 2764 | entera | 1 |
| 2765 | entendimiento | 1 |
| 2766 | entendí | 1 |
| 2767 | entender | 1 |
| 2768 | entablo | 1 |
| 2769 | ensuciar | 1 |
| 2770 | ensangrentado | 1 |
| 2771 | ensalzar | 1 |
| 2772 | ensaladas | 1 |
| 2773 | ensalada | 1 |
| 2774 | enriquezco | 1 |
| 2775 | enriquecelde | 1 |
| 2776 | enredos | 1 |
| 2777 | enojos | 1 |
| 2778 | enojadas | 1 |
| 2779 | enmudeció | 1 |
| 2780 | enmudecido | 1 |
| 2781 | enmendastes | 1 |
| 2782 | enmendar | 1 |
| 2783 | enlutaron | 1 |
| 2784 | enlutada | 1 |
| 2785 | enjuto | 1 |
| 2786 | enjuta | 1 |
| 2787 | engordar | 1 |
| 2788 | engendrar | 1 |
| 2789 | engendrado | 1 |
| 2790 | engaño | 1 |
| 2791 | engañe | 1 |
| 2792 | engaña | 1 |
| 2793 | enfermedad | 1 |
| 2794 | enfado | 1 |
| 2795 | enemistad | 1 |
| 2796 | enemiga | 1 |
| 2797 | endureció | 1 |
| 2798 | encuentros | 1 |
| 2799 | encuentre | 1 |
| 2800 | encuéntrate | 1 |
| 2801 | encubrirnos | 1 |
| 2802 | encomienda | 1 |
| 2803 | encierra | 1 |
| 2804 | encerrar | 1 |
| 2805 | encendidos | 1 |
| 2806 | encargó | 1 |
| 2807 | encarece | 1 |
| 2808 | encaje | 1 |
| 2809 | enamoran | 1 |
| 2810 | enamorada | 1 |
| 2811 | enamora | 1 |
| 2812 | enaguas | 1 |
| 2813 | empréndenlos | 1 |
| 2814 | empobreces | 1 |
| 2815 | empleado | 1 |
| 2816 | empezará | 1 |
| 2817 | empero | 1 |
| 2818 | embelequen | 1 |
| 2819 | embeleco | 1 |
| 2820 | embarazan | 1 |
| 2821 | elocuentes | 1 |
| 2822 | elocuente | 1 |
| 2823 | ello | 1 |
| 2824 | elegantes | 1 |
| 2825 | elección | 1 |
| 2826 | ejércitos | 1 |
| 2827 | ejercite | 1 |
| 2828 | ejercitar | 1 |
| 2829 | ejemplo | 1 |
| 2830 | ejecutar | 1 |
| 2831 | ejecuta | 1 |
| 2832 | efecto | 1 |
| 2833 | edades | 1 |
| 2834 | eco | 1 |
| 2835 | echolos | 1 |
| 2836 | echó | 1 |
| 2837 | échese | 1 |
| 2838 | echarla | 1 |
| 2839 | echaba | 1 |
| 2840 | ébano | 1 |
| 2841 | duró | 1 |
| 2842 | durazno | 1 |
| 2843 | dura | 1 |
| 2844 | duque | 1 |
| 2845 | duplicado | 1 |
| 2846 | duermen | 1 |
| 2847 | dueño | 1 |
| 2848 | duende | 1 |
| 2849 | duelos | 1 |
| 2850 | dudoso | 1 |
| 2851 | duda | 1 |
| 2852 | dotrinada | 1 |
| 2853 | dormida | 1 |
| 2854 | dorados | 1 |
| 2855 | dorado | 1 |
| 2856 | dónde | 1 |
| 2857 | doncellez | 1 |
| 2858 | doncella | 1 |
| 2859 | dominaba | 1 |
| 2860 | doloroso | 1 |
| 2861 | dolorosas | 1 |
| 2862 | dolorosa | 1 |
| 2863 | doliente | 1 |
| 2864 | doctrina | 1 |
| 2865 | doctos | 1 |
| 2866 | doctores | 1 |
| 2867 | docto | 1 |
| 2868 | dobló | 1 |
| 2869 | dobles | 1 |
| 2870 | do | 1 |
| 2871 | dixo | 1 |
| 2872 | divorcio | 1 |
| 2873 | divine | 1 |
| 2874 | dividido | 1 |
| 2875 | divertido | 1 |
| 2876 | diversas | 1 |
| 2877 | distes | 1 |
| 2878 | diste | 1 |
| 2879 | dispensando | 1 |
| 2880 | dispensadores | 1 |
| 2881 | disimulan | 1 |
| 2882 | disimuladas | 1 |
| 2883 | disfraz | 1 |
| 2884 | disfavor | 1 |
| 2885 | discursos | 1 |
| 2886 | discurrían | 1 |
| 2887 | discretas | 1 |
| 2888 | discreta | 1 |
| 2889 | discordia | 1 |
| 2890 | disciplinado | 1 |
| 2891 | disciplina | 1 |
| 2892 | dirás | 1 |
| 2893 | dirá | 1 |
| 2894 | dineras | 1 |
| 2895 | dime | 1 |
| 2896 | diligente | 1 |
| 2897 | diligencias | 1 |
| 2898 | dile | 1 |
| 2899 | dijeron | 1 |
| 2900 | digno | 1 |
| 2901 | digan | 1 |
| 2902 | diga | 1 |
| 2903 | difunto | 1 |
| 2904 | dificultosos | 1 |
| 2905 | diferentes | 1 |
| 2906 | diferente | 1 |
| 2907 | diferencias | 1 |
| 2908 | diferenciaban | 1 |
| 2909 | diez | 1 |
| 2910 | diéronles | 1 |
| 2911 | diere | 1 |
| 2912 | diera | 1 |
| 2913 | diente | 1 |
| 2914 | dichas | 1 |
| 2915 | devotos | 1 |
| 2916 | devoción | 1 |
| 2917 | devaneos | 1 |
| 2918 | devanadera | 1 |
| 2919 | detúvose | 1 |
| 2920 | detrás | 1 |
| 2921 | detiene | 1 |
| 2922 | desvío | 1 |
| 2923 | desventura | 1 |
| 2924 | desvelo | 1 |
| 2925 | desvelarme | 1 |
| 2926 | desvelan | 1 |
| 2927 | desvelado | 1 |
| 2928 | desvelada | 1 |
| 2929 | desvanece | 1 |
| 2930 | desvaído | 1 |
| 2931 | destierros | 1 |
| 2932 | desta | 1 |
| 2933 | despreció | 1 |
| 2934 | desposados | 1 |
| 2935 | despojos | 1 |
| 2936 | despoblado | 1 |
| 2937 | desperdicios | 1 |
| 2938 | despeñadero | 1 |
| 2939 | despeñada | 1 |
| 2940 | despedirme | 1 |
| 2941 | desollada | 1 |
| 2942 | desnudos | 1 |
| 2943 | desnudando | 1 |
| 2944 | desnudador | 1 |
| 2945 | desnuda | 1 |
| 2946 | desmienten | 1 |
| 2947 | desmiente | 1 |
| 2948 | desmienta | 1 |
| 2949 | desiertos | 1 |
| 2950 | desiertas | 1 |
| 2951 | deshonesta | 1 |
| 2952 | deshojar | 1 |
| 2953 | deshace | 1 |
| 2954 | desgreñado | 1 |
| 2955 | desgracias | 1 |
| 2956 | desgraciado | 1 |
| 2957 | desgracia | 1 |
| 2958 | desfallece | 1 |
| 2959 | desesperados | 1 |
| 2960 | desenvaina | 1 |
| 2961 | desengaños | 1 |
| 2962 | desembozo | 1 |
| 2963 | desembarazarnos | 1 |
| 2964 | desecha | 1 |
| 2965 | desdichada | 1 |
| 2966 | desdeñosa | 1 |
| 2967 | desdenes | 1 |
| 2968 | desdén | 1 |
| 2969 | descuídate | 1 |
| 2970 | descuidado | 1 |
| 2971 | descubriendo | 1 |
| 2972 | desconsuelo | 1 |
| 2973 | desconsuelas | 1 |
| 2974 | desconsoladas | 1 |
| 2975 | desconocido | 1 |
| 2976 | desconocida | 1 |
| 2977 | desconfiar | 1 |
| 2978 | desconfianza | 1 |
| 2979 | descendencias | 1 |
| 2980 | descaramiento | 1 |
| 2981 | descansen | 1 |
| 2982 | descanse | 1 |
| 2983 | descansarás | 1 |
| 2984 | descansar | 1 |
| 2985 | descansaba | 1 |
| 2986 | desatado | 1 |
| 2987 | desatadas | 1 |
| 2988 | desataba | 1 |
| 2989 | desangradas | 1 |
| 2990 | desamparada | 1 |
| 2991 | desamor | 1 |
| 2992 | desaliñada | 1 |
| 2993 | desafío | 1 |
| 2994 | desacredito | 1 |
| 2995 | desabrimientos | 1 |
| 2996 | derriba | 1 |
| 2997 | derramaron | 1 |
| 2998 | derramado | 1 |
| 2999 | derramada | 1 |
| 3000 | derecho | 1 |
| 3001 | dependió | 1 |
| 3002 | deo | 1 |
| 3003 | denegridos | 1 |
| 3004 | den | 1 |
| 3005 | demudado | 1 |
| 3006 | demonio | 1 |
| 3007 | demanda | 1 |
| 3008 | dellos | 1 |
| 3009 | dellas | 1 |
| 3010 | delgado | 1 |
| 3011 | delfín | 1 |
| 3012 | delata | 1 |
| 3013 | delante | 1 |
| 3014 | dejó | 1 |
| 3015 | dejo | 1 |
| 3016 | dejes | 1 |
| 3017 | déjate | 1 |
| 3018 | dejara | 1 |
| 3019 | dejar | 1 |
| 3020 | dejándola | 1 |
| 3021 | déjame | 1 |
| 3022 | dejad | 1 |
| 3023 | deidad | 1 |
| 3024 | degollado | 1 |
| 3025 | defiéndaos | 1 |
| 3026 | dedos | 1 |
| 3027 | decrépito | 1 |
| 3028 | decirte | 1 |
| 3029 | decilla | 1 |
| 3030 | decente | 1 |
| 3031 | débil | 1 |
| 3032 | debidas | 1 |
| 3033 | debía | 1 |
| 3034 | débate | 1 |
| 3035 | dátil | 1 |
| 3036 | date | 1 |
| 3037 | dase | 1 |
| 3038 | darme | 1 |
| 3039 | darles | 1 |
| 3040 | dareos | 1 |
| 3041 | dará | 1 |
| 3042 | daños | 1 |
| 3043 | danzas | 1 |
| 3044 | dallos | 1 |
| 3045 | dad | 1 |
| 3046 | dábanme | 1 |
| 3047 | cuyo | 1 |
| 3048 | cuyas | 1 |
| 3049 | custodia | 1 |
| 3050 | curiosidad | 1 |
| 3051 | curas | 1 |
| 3052 | curara | 1 |
| 3053 | curando | 1 |
| 3054 | cuna | 1 |
| 3055 | cumbres | 1 |
| 3056 | cumbre | 1 |
| 3057 | cultos | 1 |
| 3058 | culterana | 1 |
| 3059 | cultas | 1 |
| 3060 | culpada | 1 |
| 3061 | cuestas | 1 |
| 3062 | cuesta | 1 |
| 3063 | cuervos | 1 |
| 3064 | cueros | 1 |
| 3065 | cuero | 1 |
| 3066 | cuerdos | 1 |
| 3067 | cuerdas | 1 |
| 3068 | cuerda | 1 |
| 3069 | cuento | 1 |
| 3070 | cuentes | 1 |
| 3071 | cuentas | 1 |
| 3072 | cubrió | 1 |
| 3073 | cuba | 1 |
| 3074 | cuarto | 1 |
| 3075 | cuartana | 1 |
| 3076 | cuarta | 1 |
| 3077 | cuaresma | 1 |
| 3078 | cuantos | 1 |
| 3079 | cuan | 1 |
| 3080 | cual | 1 |
| 3081 | cruel | 1 |
| 3082 | crucifijo | 1 |
| 3083 | cristianos | 1 |
| 3084 | cristiano | 1 |
| 3085 | cristïana | 1 |
| 3086 | cristalinas | 1 |
| 3087 | cristal | 1 |
| 3088 | crin | 1 |
| 3089 | cribas | 1 |
| 3090 | criara | 1 |
| 3091 | criado | 1 |
| 3092 | creo | 1 |
| 3093 | creídas | 1 |
| 3094 | creer | 1 |
| 3095 | crédito | 1 |
| 3096 | creces | 1 |
| 3097 | crece | 1 |
| 3098 | creación | 1 |
| 3099 | corvillo | 1 |
| 3100 | corva | 1 |
| 3101 | corto | 1 |
| 3102 | cortinas | 1 |
| 3103 | cortezas | 1 |
| 3104 | corteses | 1 |
| 3105 | cortesano | 1 |
| 3106 | cortesana | 1 |
| 3107 | corte | 1 |
| 3108 | cortan | 1 |
| 3109 | cortad | 1 |
| 3110 | corrió | 1 |
| 3111 | corrientes | 1 |
| 3112 | corriente | 1 |
| 3113 | corres | 1 |
| 3114 | corregidor | 1 |
| 3115 | corpus | 1 |
| 3116 | coroza | 1 |
| 3117 | cornudo | 1 |
| 3118 | cornado | 1 |
| 3119 | cordón | 1 |
| 3120 | cordero | 1 |
| 3121 | corcova | 1 |
| 3122 | corchete | 1 |
| 3123 | corazones | 1 |
| 3124 | coraza | 1 |
| 3125 | coral | 1 |
| 3126 | copias | 1 |
| 3127 | copete | 1 |
| 3128 | convida | 1 |
| 3129 | convenía | 1 |
| 3130 | convaleciente | 1 |
| 3131 | contrarios | 1 |
| 3132 | contrario | 1 |
| 3133 | contrapunto | 1 |
| 3134 | contino | 1 |
| 3135 | contera | 1 |
| 3136 | contentos | 1 |
| 3137 | contento | 1 |
| 3138 | contarme | 1 |
| 3139 | contador | 1 |
| 3140 | contadas | 1 |
| 3141 | consumida | 1 |
| 3142 | cónsules | 1 |
| 3143 | construye | 1 |
| 3144 | constelaciones | 1 |
| 3145 | consortes | 1 |
| 3146 | consolarme | 1 |
| 3147 | considera | 1 |
| 3148 | consejos | 1 |
| 3149 | consejera | 1 |
| 3150 | conozco | 1 |
| 3151 | conocimiento | 1 |
| 3152 | conocí | 1 |
| 3153 | conocer | 1 |
| 3154 | congrio | 1 |
| 3155 | confusos | 1 |
| 3156 | confundiendo | 1 |
| 3157 | conformes | 1 |
| 3158 | confieso | 1 |
| 3159 | confiese | 1 |
| 3160 | confianza | 1 |
| 3161 | confiado | 1 |
| 3162 | confesión | 1 |
| 3163 | confesarse | 1 |
| 3164 | condición | 1 |
| 3165 | condeno | 1 |
| 3166 | condenada | 1 |
| 3167 | condena | 1 |
| 3168 | conciencia | 1 |
| 3169 | conciba | 1 |
| 3170 | conchas | 1 |
| 3171 | conceto | 1 |
| 3172 | concertando | 1 |
| 3173 | conceptos | 1 |
| 3174 | concento | 1 |
| 3175 | cóncavos | 1 |
| 3176 | cóncavas | 1 |
| 3177 | comunico | 1 |
| 3178 | comunera | 1 |
| 3179 | común | 1 |
| 3180 | compuesta | 1 |
| 3181 | compró | 1 |
| 3182 | comparados | 1 |
| 3183 | compañías | 1 |
| 3184 | compadre | 1 |
| 3185 | comió | 1 |
| 3186 | comiendo | 1 |
| 3187 | comían | 1 |
| 3188 | comercio | 1 |
| 3189 | comenzolos | 1 |
| 3190 | comen | 1 |
| 3191 | comedla | 1 |
| 3192 | colores | 1 |
| 3193 | colmados | 1 |
| 3194 | colegiales | 1 |
| 3195 | cola | 1 |
| 3196 | cohombro | 1 |
| 3197 | cohete | 1 |
| 3198 | cofrades | 1 |
| 3199 | codicioso | 1 |
| 3200 | codiciaba | 1 |
| 3201 | codicia | 1 |
| 3202 | coco | 1 |
| 3203 | coces | 1 |
| 3204 | coca | 1 |
| 3205 | cobra | 1 |
| 3206 | cobardes | 1 |
| 3207 | cleantes | 1 |
| 3208 | clavos | 1 |
| 3209 | clavo | 1 |
| 3210 | clavado | 1 |
| 3211 | clavadas | 1 |
| 3212 | clava | 1 |
| 3213 | cláusulas | 1 |
| 3214 | claustro | 1 |
| 3215 | claros | 1 |
| 3216 | claro | 1 |
| 3217 | claras | 1 |
| 3218 | clara | 1 |
| 3219 | clamor | 1 |
| 3220 | circunloquio | 1 |
| 3221 | ciñe | 1 |
| 3222 | cintas | 1 |
| 3223 | cinco | 1 |
| 3224 | cierra | 1 |
| 3225 | ciencia | 1 |
| 3226 | cieguen | 1 |
| 3227 | ciegan | 1 |
| 3228 | cid | 1 |
| 3229 | chiste | 1 |
| 3230 | chiquilla | 1 |
| 3231 | chipre | 1 |
| 3232 | chillón | 1 |
| 3233 | chapuzan | 1 |
| 3234 | chanzas | 1 |
| 3235 | cetro | 1 |
| 3236 | certeza | 1 |
| 3237 | cerriles | 1 |
| 3238 | cerrallos | 1 |
| 3239 | cerrada | 1 |
| 3240 | ceros | 1 |
| 3241 | cereza | 1 |
| 3242 | ceres | 1 |
| 3243 | cercos | 1 |
| 3244 | cercan | 1 |
| 3245 | cerbero | 1 |
| 3246 | ceñido | 1 |
| 3247 | centellas | 1 |
| 3248 | centellante | 1 |
| 3249 | censoria | 1 |
| 3250 | censo | 1 |
| 3251 | celoso | 1 |
| 3252 | celo | 1 |
| 3253 | celestiales | 1 |
| 3254 | celebrarte | 1 |
| 3255 | celebralde | 1 |
| 3256 | céfiro | 1 |
| 3257 | cédula | 1 |
| 3258 | cebolla | 1 |
| 3259 | caza | 1 |
| 3260 | cavernas | 1 |
| 3261 | cautivo | 1 |
| 3262 | causa | 1 |
| 3263 | catedrático | 1 |
| 3264 | cátedra | 1 |
| 3265 | cátate | 1 |
| 3266 | castillos | 1 |
| 3267 | castillas | 1 |
| 3268 | castilla | 1 |
| 3269 | castigas | 1 |
| 3270 | castigar | 1 |
| 3271 | castidad | 1 |
| 3272 | castellanos | 1 |
| 3273 | castellano | 1 |
| 3274 | castañeta | 1 |
| 3275 | castaña | 1 |
| 3276 | casos | 1 |
| 3277 | caseme | 1 |
| 3278 | casas | 1 |
| 3279 | casáronse | 1 |
| 3280 | casaron | 1 |
| 3281 | casarme | 1 |
| 3282 | casaos | 1 |
| 3283 | casan | 1 |
| 3284 | casamentero | 1 |
| 3285 | casados | 1 |
| 3286 | casado | 1 |
| 3287 | cartilla | 1 |
| 3288 | carriles | 1 |
| 3289 | carrera | 1 |
| 3290 | carquesio | 1 |
| 3291 | carpas | 1 |
| 3292 | caro | 1 |
| 3293 | carmesíes | 1 |
| 3294 | carininfos | 1 |
| 3295 | cargado | 1 |
| 3296 | cargadas | 1 |
| 3297 | carga | 1 |
| 3298 | careciendo | 1 |
| 3299 | cárdeno | 1 |
| 3300 | carcomida | 1 |
| 3301 | carbones | 1 |
| 3302 | carbonada | 1 |
| 3303 | carbón | 1 |
| 3304 | capaz | 1 |
| 3305 | capas | 1 |
| 3306 | caos | 1 |
| 3307 | cañuto | 1 |
| 3308 | cañones | 1 |
| 3309 | cañas | 1 |
| 3310 | cantor | 1 |
| 3311 | cantares | 1 |
| 3312 | cantanos | 1 |
| 3313 | cantándome | 1 |
| 3314 | cantando | 1 |
| 3315 | cántabro | 1 |
| 3316 | cantaba | 1 |
| 3317 | canta | 1 |
| 3318 | cansaré | 1 |
| 3319 | canos | 1 |
| 3320 | canonice | 1 |
| 3321 | cano | 1 |
| 3322 | candores | 1 |
| 3323 | canción | 1 |
| 3324 | cana | 1 |
| 3325 | can | 1 |
| 3326 | campeador | 1 |
| 3327 | campañas | 1 |
| 3328 | campanilla | 1 |
| 3329 | caminos | 1 |
| 3330 | caminar | 1 |
| 3331 | caminante | 1 |
| 3332 | cambio | 1 |
| 3333 | calzas | 1 |
| 3334 | calvas | 1 |
| 3335 | calores | 1 |
| 3336 | callar | 1 |
| 3337 | callado | 1 |
| 3338 | calentura | 1 |
| 3339 | caldero | 1 |
| 3340 | calcetero | 1 |
| 3341 | calavera | 1 |
| 3342 | calabazas | 1 |
| 3343 | calabaza | 1 |
| 3344 | cajas | 1 |
| 3345 | caerse | 1 |
| 3346 | caer | 1 |
| 3347 | caducan | 1 |
| 3348 | caducaban | 1 |
| 3349 | cadáver | 1 |
| 3350 | cabo | 1 |
| 3351 | cabezas | 1 |
| 3352 | cabe | 1 |
| 3353 | cabañas | 1 |
| 3354 | caballo | 1 |
| 3355 | caballeros | 1 |
| 3356 | caballeriza | 1 |
| 3357 | caballerías | 1 |
| 3358 | caballera | 1 |
| 3359 | buzano | 1 |
| 3360 | buscó | 1 |
| 3361 | busco | 1 |
| 3362 | buscarlos | 1 |
| 3363 | buscaré | 1 |
| 3364 | buscar | 1 |
| 3365 | buscaba | 1 |
| 3366 | burlesca | 1 |
| 3367 | burlándose | 1 |
| 3368 | buriel | 1 |
| 3369 | bula | 1 |
| 3370 | buida | 1 |
| 3371 | buenas | 1 |
| 3372 | briosa | 1 |
| 3373 | bríos | 1 |
| 3374 | brindis | 1 |
| 3375 | brilla | 1 |
| 3376 | breves | 1 |
| 3377 | brevemente | 1 |
| 3378 | brazo | 1 |
| 3379 | brava | 1 |
| 3380 | bracete | 1 |
| 3381 | botarga | 1 |
| 3382 | bota | 1 |
| 3383 | bostezo | 1 |
| 3384 | borrascas | 1 |
| 3385 | bonito | 1 |
| 3386 | bonanza | 1 |
| 3387 | bombardas | 1 |
| 3388 | bolsas | 1 |
| 3389 | bocas | 1 |
| 3390 | blasonan | 1 |
| 3391 | blasón | 1 |
| 3392 | blandos | 1 |
| 3393 | blandamente | 1 |
| 3394 | blanda | 1 |
| 3395 | blancas | 1 |
| 3396 | bizarría | 1 |
| 3397 | bizarra | 1 |
| 3398 | betún | 1 |
| 3399 | bestia | 1 |
| 3400 | besar | 1 |
| 3401 | besamanos | 1 |
| 3402 | berza | 1 |
| 3403 | berenjena | 1 |
| 3404 | benignas | 1 |
| 3405 | beneficios | 1 |
| 3406 | benavente | 1 |
| 3407 | bellas | 1 |
| 3408 | belisa | 1 |
| 3409 | belicosa | 1 |
| 3410 | bebió | 1 |
| 3411 | bebida | 1 |
| 3412 | bebería | 1 |
| 3413 | bebe | 1 |
| 3414 | baza | 1 |
| 3415 | bayetas | 1 |
| 3416 | bayeta | 1 |
| 3417 | baste | 1 |
| 3418 | bártulos | 1 |
| 3419 | barbo | 1 |
| 3420 | barbas | 1 |
| 3421 | barbado | 1 |
| 3422 | barba | 1 |
| 3423 | baratas | 1 |
| 3424 | barata | 1 |
| 3425 | bañado | 1 |
| 3426 | banquetes | 1 |
| 3427 | banderas | 1 |
| 3428 | bandera | 1 |
| 3429 | ballenas | 1 |
| 3430 | ballena | 1 |
| 3431 | balcones | 1 |
| 3432 | balas | 1 |
| 3433 | bajeles | 1 |
| 3434 | bajas | 1 |
| 3435 | bailes | 1 |
| 3436 | baile | 1 |
| 3437 | bailarín | 1 |
| 3438 | baco | 1 |
| 3439 | bacanales | 1 |
| 3440 | azufrados | 1 |
| 3441 | azotes | 1 |
| 3442 | azotan | 1 |
| 3443 | azabache | 1 |
| 3444 | ayo | 1 |
| 3445 | avises | 1 |
| 3446 | aventuró | 1 |
| 3447 | aventajarse | 1 |
| 3448 | avaros | 1 |
| 3449 | avaricia | 1 |
| 3450 | autoridad | 1 |
| 3451 | ausentas | 1 |
| 3452 | ausenta | 1 |
| 3453 | ausencia | 1 |
| 3454 | aumento | 1 |
| 3455 | aumenta | 1 |
| 3456 | atusada | 1 |
| 3457 | atunes | 1 |
| 3458 | atrevieron | 1 |
| 3459 | atrevidos | 1 |
| 3460 | atreve | 1 |
| 3461 | atreva | 1 |
| 3462 | átomo | 1 |
| 3463 | atiendes | 1 |
| 3464 | atiéndele | 1 |
| 3465 | atención | 1 |
| 3466 | atemorice | 1 |
| 3467 | atascan | 1 |
| 3468 | atarazaba | 1 |
| 3469 | astrología | 1 |
| 3470 | asta | 1 |
| 3471 | ásperos | 1 |
| 3472 | áspero | 1 |
| 3473 | áspera | 1 |
| 3474 | asombro | 1 |
| 3475 | asirte | 1 |
| 3476 | aseo | 1 |
| 3477 | aseguro | 1 |
| 3478 | aseguraros | 1 |
| 3479 | asegurado | 1 |
| 3480 | asco | 1 |
| 3481 | asciendes | 1 |
| 3482 | ascendiente | 1 |
| 3483 | asaltos | 1 |
| 3484 | artífice | 1 |
| 3485 | arrugada | 1 |
| 3486 | arrobas | 1 |
| 3487 | arrepentimiento | 1 |
| 3488 | arremendando | 1 |
| 3489 | arrebol | 1 |
| 3490 | arrebata | 1 |
| 3491 | arrastran | 1 |
| 3492 | arracadas | 1 |
| 3493 | arpías | 1 |
| 3494 | aroma | 1 |
| 3495 | armonía | 1 |
| 3496 | armadura | 1 |
| 3497 | aritmética | 1 |
| 3498 | argumentillo | 1 |
| 3499 | argumentaren | 1 |
| 3500 | argos | 1 |
| 3501 | arenas | 1 |
| 3502 | ardió | 1 |
| 3503 | ardiendo | 1 |
| 3504 | árboles | 1 |
| 3505 | árbitros | 1 |
| 3506 | aras | 1 |
| 3507 | araña | 1 |
| 3508 | aqueste | 1 |
| 3509 | aquesta | 1 |
| 3510 | aqueje | 1 |
| 3511 | apurar | 1 |
| 3512 | apurado | 1 |
| 3513 | apruebo | 1 |
| 3514 | aprisionada | 1 |
| 3515 | aprietes | 1 |
| 3516 | apretada | 1 |
| 3517 | apresura | 1 |
| 3518 | aprendiz | 1 |
| 3519 | aprenderemos | 1 |
| 3520 | aprenderán | 1 |
| 3521 | aprendan | 1 |
| 3522 | apodos | 1 |
| 3523 | apocamiento | 1 |
| 3524 | aplique | 1 |
| 3525 | apetecidos | 1 |
| 3526 | apetecido | 1 |
| 3527 | apetecer | 1 |
| 3528 | apasionáis | 1 |
| 3529 | aparte | 1 |
| 3530 | apartan | 1 |
| 3531 | apariencia | 1 |
| 3532 | aparente | 1 |
| 3533 | apareció | 1 |
| 3534 | apacibles | 1 |
| 3535 | antiguo | 1 |
| 3536 | ante | 1 |
| 3537 | antaños | 1 |
| 3538 | ansí | 1 |
| 3539 | anonadada | 1 |
| 3540 | ánimo | 1 |
| 3541 | animar | 1 |
| 3542 | animal | 1 |
| 3543 | animado | 1 |
| 3544 | anhelas | 1 |
| 3545 | angosto | 1 |
| 3546 | angosta | 1 |
| 3547 | ángeles | 1 |
| 3548 | ángela | 1 |
| 3549 | ángel | 1 |
| 3550 | anegadas | 1 |
| 3551 | andarán | 1 |
| 3552 | andan | 1 |
| 3553 | andaban | 1 |
| 3554 | andaba | 1 |
| 3555 | anchoba | 1 |
| 3556 | amortajado | 1 |
| 3557 | amoroso | 1 |
| 3558 | amolada | 1 |
| 3559 | amistad | 1 |
| 3560 | amigos | 1 |
| 3561 | amigo | 1 |
| 3562 | amenazas | 1 |
| 3563 | amenaces | 1 |
| 3564 | ambos | 1 |
| 3565 | amasteis | 1 |
| 3566 | amas | 1 |
| 3567 | amartelar | 1 |
| 3568 | amarillos | 1 |
| 3569 | amarillas | 1 |
| 3570 | amarilis | 1 |
| 3571 | amarga | 1 |
| 3572 | amara | 1 |
| 3573 | amaneciendo | 1 |
| 3574 | amanecerá | 1 |
| 3575 | amanece | 1 |
| 3576 | amando | 1 |
| 3577 | amados | 1 |
| 3578 | amado | 1 |
| 3579 | alza | 1 |
| 3580 | álvaro | 1 |
| 3581 | alumbraban | 1 |
| 3582 | altura | 1 |
| 3583 | altos | 1 |
| 3584 | altiva | 1 |
| 3585 | alteza | 1 |
| 3586 | alquimista | 1 |
| 3587 | allá | 1 |
| 3588 | aliño | 1 |
| 3589 | alindado | 1 |
| 3590 | alimente | 1 |
| 3591 | alimenta | 1 |
| 3592 | alientos | 1 |
| 3593 | alhajas | 1 |
| 3594 | algunas | 1 |
| 3595 | alguaciles | 1 |
| 3596 | algodones | 1 |
| 3597 | alfombra | 1 |
| 3598 | alevoso | 1 |
| 3599 | aleve | 1 |
| 3600 | alentado | 1 |
| 3601 | alegrías | 1 |
| 3602 | alegría | 1 |
| 3603 | aldeas | 1 |
| 3604 | alcázar | 1 |
| 3605 | alcanzaras | 1 |
| 3606 | alcachofa | 1 |
| 3607 | albedrío | 1 |
| 3608 | alba | 1 |
| 3609 | alanos | 1 |
| 3610 | alano | 1 |
| 3611 | alabanzas | 1 |
| 3612 | alabanza | 1 |
| 3613 | ajusticiar | 1 |
| 3614 | ajos | 1 |
| 3615 | ajenos | 1 |
| 3616 | aires | 1 |
| 3617 | airada | 1 |
| 3618 | ahorro | 1 |
| 3619 | ahorcaron | 1 |
| 3620 | ahorcados | 1 |
| 3621 | ahogose | 1 |
| 3622 | ahogaron | 1 |
| 3623 | ahoga | 1 |
| 3624 | aguja | 1 |
| 3625 | agüeros | 1 |
| 3626 | agudo | 1 |
| 3627 | aguas | 1 |
| 3628 | aguardan | 1 |
| 3629 | aguados | 1 |
| 3630 | agrado | 1 |
| 3631 | agradezca | 1 |
| 3632 | agradecido | 1 |
| 3633 | agradeces | 1 |
| 3634 | agradar | 1 |
| 3635 | afrentarlos | 1 |
| 3636 | afrenta | 1 |
| 3637 | aflige | 1 |
| 3638 | afición | 1 |
| 3639 | afeitado | 1 |
| 3640 | afeitada | 1 |
| 3641 | afectado | 1 |
| 3642 | afán | 1 |
| 3643 | advertencias | 1 |
| 3644 | adversidad | 1 |
| 3645 | adular | 1 |
| 3646 | adulación | 1 |
| 3647 | adrede | 1 |
| 3648 | adornome | 1 |
| 3649 | adormecen | 1 |
| 3650 | adoren | 1 |
| 3651 | adore | 1 |
| 3652 | adorase | 1 |
| 3653 | adorándote | 1 |
| 3654 | adorando | 1 |
| 3655 | adoran | 1 |
| 3656 | adorado | 1 |
| 3657 | adoración | 1 |
| 3658 | admitió | 1 |
| 3659 | admitidos | 1 |
| 3660 | admirada | 1 |
| 3661 | admira | 1 |
| 3662 | administrar | 1 |
| 3663 | adelgaza | 1 |
| 3664 | adelantara | 1 |
| 3665 | acusar | 1 |
| 3666 | acuéstanse | 1 |
| 3667 | acuerda | 1 |
| 3668 | acrisolaron | 1 |
| 3669 | acrecentaban | 1 |
| 3670 | acostarse | 1 |
| 3671 | acostados | 1 |
| 3672 | acontece | 1 |
| 3673 | acondicionados | 1 |
| 3674 | acompañada | 1 |
| 3675 | acompañaba | 1 |
| 3676 | acompaña | 1 |
| 3677 | acometa | 1 |
| 3678 | acogimiento | 1 |
| 3679 | acobardar | 1 |
| 3680 | aciértanme | 1 |
| 3681 | acercáis | 1 |
| 3682 | acento | 1 |
| 3683 | aceite | 1 |
| 3684 | acebo | 1 |
| 3685 | acción | 1 |
| 3686 | acariciarme | 1 |
| 3687 | acabas | 1 |
| 3688 | acabaron | 1 |
| 3689 | acábanlos | 1 |
| 3690 | acabado | 1 |
| 3691 | abuelo | 1 |
| 3692 | abrió | 1 |
| 3693 | abril | 1 |
| 3694 | abrigado | 1 |
| 3695 | abriéronse | 1 |
| 3696 | abreviar | 1 |
| 3697 | abréviame | 1 |
| 3698 | abreviado | 1 |
| 3699 | abre | 1 |
| 3700 | abrazada | 1 |
| 3701 | abrasar | 1 |
| 3702 | abrasándote | 1 |
| 3703 | abrasado | 1 |
| 3704 | abrasadas | 1 |
| 3705 | abrasaban | 1 |
| 3706 | abrasa | 1 |
| 3707 | aborta | 1 |
| 3708 | aborrecidos | 1 |
| 3709 | abiertas | 1 |
| 3710 | abalanzan | 1 |
| 3711 | abajo | 1 |
| 3712 | abades | 1 |
| 3713 | abadejos | 1 |
|
Ilustración del principio de mínimo esfuerzo: |
|
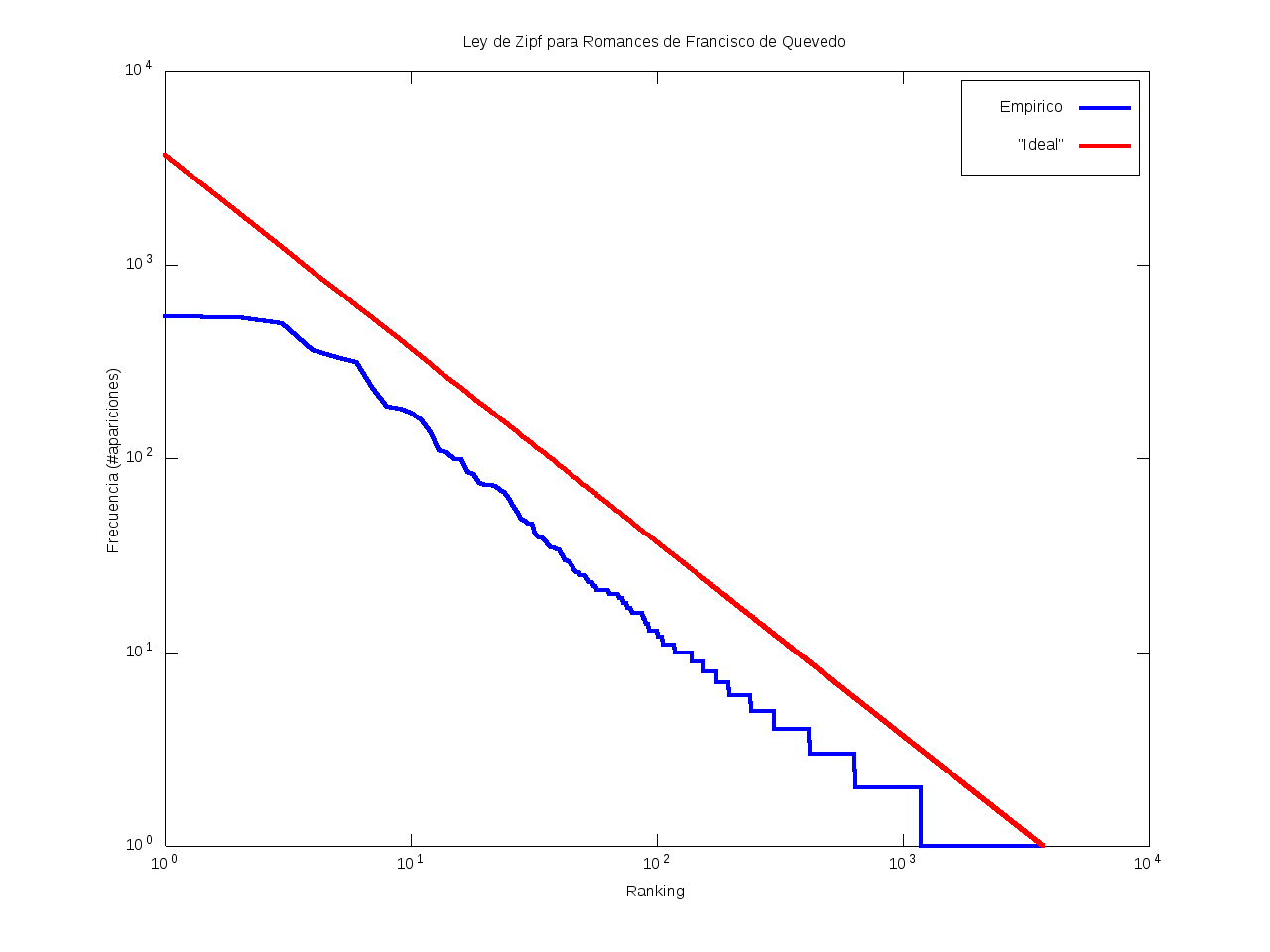
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará el texto actual (Romances de Francisco de Quevedo) (conjunto 1)
contra el resto de textos en el mismo idioma (Castellano) (conjunto 2).
A continuación se muestra una lista de las palabras presentes en el texto actual,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
Mostrar todo
Recoger