Análisis de Soledades 1 de Luis de Góngora
Índice
Información General
| Título: | Soledades 1 |
|---|
| Autor: | Luis de Góngora |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 6189 |
|---|
| #Palabras distintas: | 2285 |
|---|
| Type-Token ratio: | 36.92% |
|---|
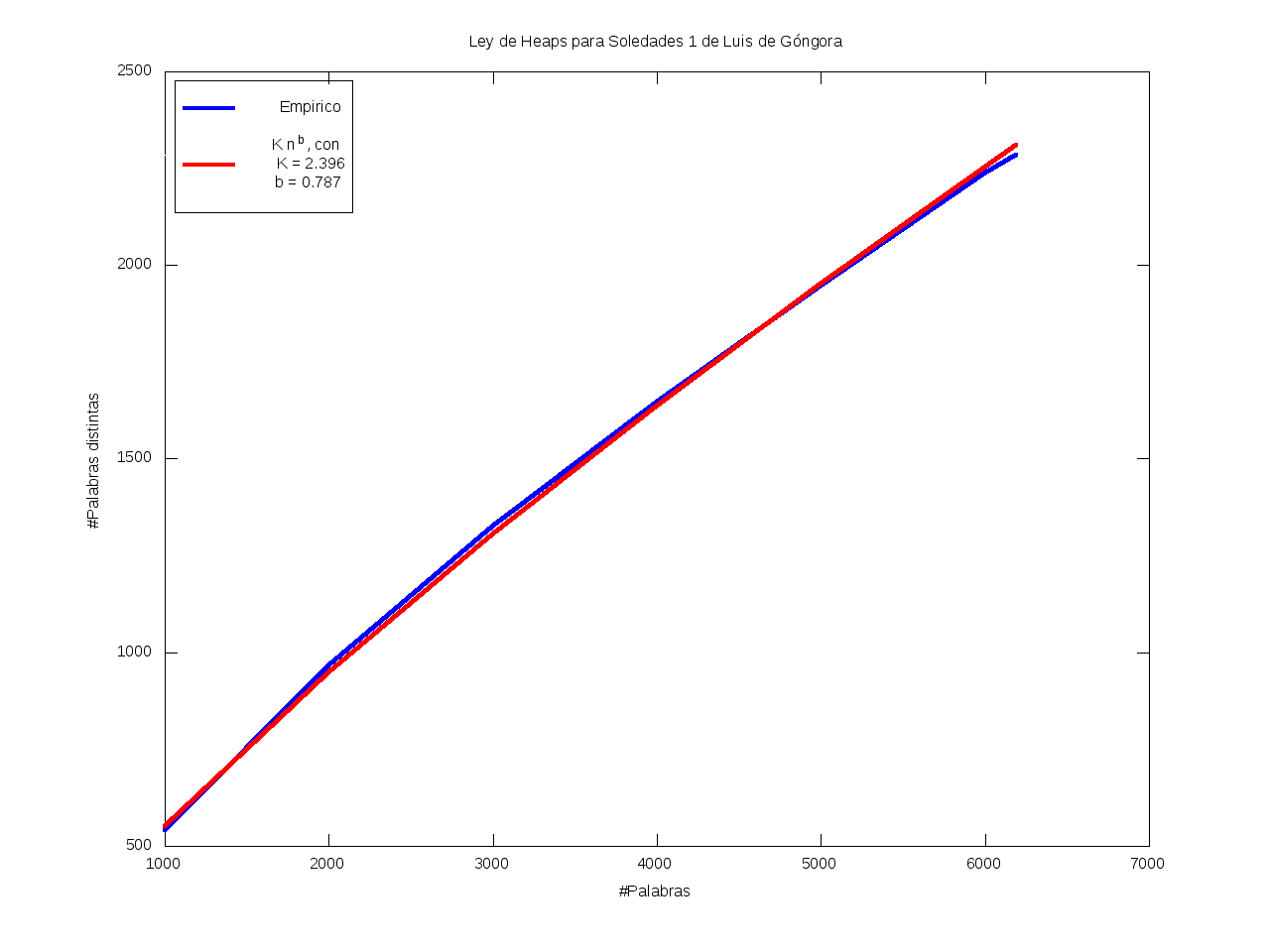
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| #Palabras: | #Palabras distintas: |
|---|
| 1000 | 541 |
| 2000 | 965 |
| 3000 | 1326 |
| 4000 | 1646 |
| 5000 | 1948 |
| 6000 | 2240 |
| 6189 | 2285 |
|
Ajuste por mínimos cuadrados de los datos a K*n^b:
|
| K = 2.396 |
|
b = 0.787 |
|
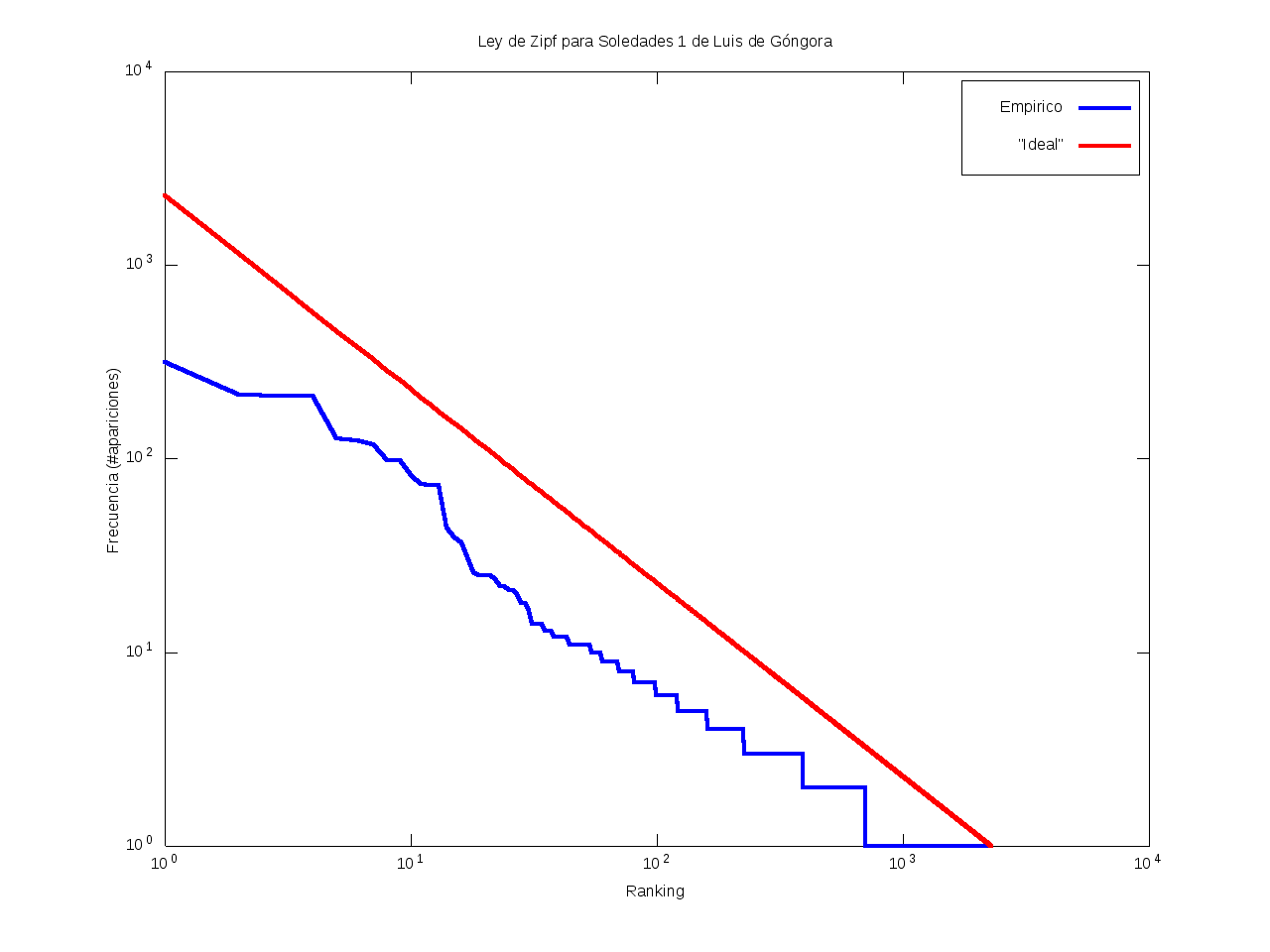
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Rank | Palabra | Frec |
|---|
| 1 | de | 315 |
| 2 | la | 213 |
| 3 | el | 212 |
| 4 | que | 211 |
| 5 | en | 127 |
| 6 | y | 125 |
| 7 | a | 119 |
| 8 | del | 98 |
| 9 | al | 98 |
| 10 | no | 82 |
| 11 | los | 74 |
| 12 | su | 73 |
| 13 | las | 73 |
| 14 | con | 44 |
| 15 | sus | 39 |
| 16 | más | 37 |
| 17 | un | 31 |
| 18 | ya | 26 |
| 19 | ven | 25 |
| 20 | o | 25 |
| 21 | le | 25 |
| 22 | lo | 24 |
| 23 | pues | 22 |
| 24 | himeneo | 22 |
| 25 | sol | 21 |
| 26 | se | 21 |
| 27 | si | 20 |
| 28 | es | 18 |
| 29 | cuando | 18 |
| 30 | por | 17 |
| 31 | fue | 14 |
| 32 | dulce | 14 |
| 33 | cual | 14 |
| 34 | aun | 14 |
| 35 | una | 13 |
| 36 | mar | 13 |
| 37 | donde | 13 |
| 38 | viento | 12 |
| 39 | tu | 12 |
| 40 | sin | 12 |
| 41 | dos | 12 |
| 42 | día | 12 |
| 43 | cuantos | 12 |
| 44 | verde | 11 |
| 45 | tal | 11 |
| 46 | sobre | 11 |
| 47 | siempre | 11 |
| 48 | rayos | 11 |
| 49 | oro | 11 |
| 50 | menos | 11 |
| 51 | entre | 11 |
| 52 | dio | 11 |
| 53 | breve | 11 |
| 54 | plumas | 10 |
| 55 | otro | 10 |
| 56 | ni | 10 |
| 57 | cuanto | 10 |
| 58 | bien | 10 |
| 59 | bella | 10 |
| 60 | tan | 9 |
| 61 | son | 9 |
| 62 | mas | 9 |
| 63 | luego | 9 |
| 64 | joven | 9 |
| 65 | hoy | 9 |
| 66 | frente | 9 |
| 67 | fin | 9 |
| 68 | cuyo | 9 |
| 69 | aquel | 9 |
| 70 | te | 8 |
| 71 | tantas | 8 |
| 72 | señas | 8 |
| 73 | pie | 8 |
| 74 | otra | 8 |
| 75 | ondas | 8 |
| 76 | mal | 8 |
| 77 | aves | 8 |
| 78 | aunque | 8 |
| 79 | ardiente | 8 |
| 80 | ahora | 8 |
| 81 | veces | 7 |
| 82 | todos | 7 |
| 83 | tanto | 7 |
| 84 | pesar | 7 |
| 85 | pasos | 7 |
| 86 | ojos | 7 |
| 87 | montes | 7 |
| 88 | flores | 7 |
| 89 | espuma | 7 |
| 90 | ella | 7 |
| 91 | dulces | 7 |
| 92 | da | 7 |
| 93 | coro | 7 |
| 94 | ciento | 7 |
| 95 | camino | 7 |
| 96 | aurora | 7 |
| 97 | apenas | 7 |
| 98 | amor | 7 |
| 99 | verdes | 6 |
| 100 | tiempo | 6 |
| 101 | tanta | 6 |
| 102 | sueño | 6 |
| 103 | sierra | 6 |
| 104 | sí | 6 |
| 105 | para | 6 |
| 106 | oh | 6 |
| 107 | número | 6 |
| 108 | mientras | 6 |
| 109 | les | 6 |
| 110 | hierba | 6 |
| 111 | ha | 6 |
| 112 | fuego | 6 |
| 113 | estrellas | 6 |
| 114 | este | 6 |
| 115 | cuya | 6 |
| 116 | cristal | 6 |
| 117 | cielo | 6 |
| 118 | aún | 6 |
| 119 | arroyo | 6 |
| 120 | albergue | 6 |
| 121 | uno | 5 |
| 122 | tus | 5 |
| 123 | tierra | 5 |
| 124 | ser | 5 |
| 125 | rosas | 5 |
| 126 | pudo | 5 |
| 127 | prolijo | 5 |
| 128 | pluma | 5 |
| 129 | pino | 5 |
| 130 | otros | 5 |
| 131 | os | 5 |
| 132 | océano | 5 |
| 133 | nieve | 5 |
| 134 | montañés | 5 |
| 135 | montaña | 5 |
| 136 | menor | 5 |
| 137 | mayor | 5 |
| 138 | luz | 5 |
| 139 | luciente | 5 |
| 140 | llano | 5 |
| 141 | lino | 5 |
| 142 | lento | 5 |
| 143 | igual | 5 |
| 144 | hora | 5 |
| 145 | hizo | 5 |
| 146 | hace | 5 |
| 147 | errantes | 5 |
| 148 | era | 5 |
| 149 | deja | 5 |
| 150 | cuantas | 5 |
| 151 | canoro | 5 |
| 152 | campo | 5 |
| 153 | cabello | 5 |
| 154 | blancas | 5 |
| 155 | bello | 5 |
| 156 | árboles | 5 |
| 157 | antes | 5 |
| 158 | alcides | 5 |
| 159 | aire | 5 |
| 160 | vuelo | 4 |
| 161 | voz | 4 |
| 162 | vez | 4 |
| 163 | vestida | 4 |
| 164 | tú | 4 |
| 165 | tres | 4 |
| 166 | términos | 4 |
| 167 | término | 4 |
| 168 | templo | 4 |
| 169 | tarde | 4 |
| 170 | sombra | 4 |
| 171 | solicita | 4 |
| 172 | sino | 4 |
| 173 | sigue | 4 |
| 174 | serrano | 4 |
| 175 | sea | 4 |
| 176 | quien | 4 |
| 177 | pudiera | 4 |
| 178 | primero | 4 |
| 179 | plata | 4 |
| 180 | peregrino | 4 |
| 181 | paso | 4 |
| 182 | olmos | 4 |
| 183 | negras | 4 |
| 184 | néctar | 4 |
| 185 | muro | 4 |
| 186 | muda | 4 |
| 187 | miembros | 4 |
| 188 | memoria | 4 |
| 189 | llegó | 4 |
| 190 | líquido | 4 |
| 191 | leño | 4 |
| 192 | lascivo | 4 |
| 193 | labradores | 4 |
| 194 | júpiter | 4 |
| 195 | instrumento | 4 |
| 196 | impedido | 4 |
| 197 | hecho | 4 |
| 198 | fortuna | 4 |
| 199 | florida | 4 |
| 200 | estrella | 4 |
| 201 | esposa | 4 |
| 202 | esplendor | 4 |
| 203 | escollo | 4 |
| 204 | encina | 4 |
| 205 | ellas | 4 |
| 206 | él | 4 |
| 207 | duro | 4 |
| 208 | discurso | 4 |
| 209 | desnudo | 4 |
| 210 | cuyas | 4 |
| 211 | cualquier | 4 |
| 212 | cristales | 4 |
| 213 | corona | 4 |
| 214 | cenizas | 4 |
| 215 | casi | 4 |
| 216 | carrera | 4 |
| 217 | blanco | 4 |
| 218 | blanca | 4 |
| 219 | bienaventurado | 4 |
| 220 | bellas | 4 |
| 221 | aquella | 4 |
| 222 | ambos | 4 |
| 223 | alta | 4 |
| 224 | alas | 4 |
| 225 | acero | 4 |
| 226 | zafiro | 3 |
| 227 | vuestros | 3 |
| 228 | vuestras | 3 |
| 229 | volantes | 3 |
| 230 | viste | 3 |
| 231 | vista | 3 |
| 232 | virgen | 3 |
| 233 | villano | 3 |
| 234 | vides | 3 |
| 235 | vestido | 3 |
| 236 | vello | 3 |
| 237 | vecina | 3 |
| 238 | vaquero | 3 |
| 239 | umbrales | 3 |
| 240 | tronco | 3 |
| 241 | torpe | 3 |
| 242 | torcido | 3 |
| 243 | tierno | 3 |
| 244 | tercio | 3 |
| 245 | templado | 3 |
| 246 | teatro | 3 |
| 247 | tantos | 3 |
| 248 | tálamo | 3 |
| 249 | suelo | 3 |
| 250 | süaves | 3 |
| 251 | süave | 3 |
| 252 | sombras | 3 |
| 253 | sólo | 3 |
| 254 | sitio | 3 |
| 255 | silencio | 3 |
| 256 | serranos | 3 |
| 257 | serranas | 3 |
| 258 | segundo | 3 |
| 259 | salto | 3 |
| 260 | sale | 3 |
| 261 | rubíes | 3 |
| 262 | rocas | 3 |
| 263 | robusto | 3 |
| 264 | robre | 3 |
| 265 | río | 3 |
| 266 | región | 3 |
| 267 | quién | 3 |
| 268 | purpúreos | 3 |
| 269 | púrpura | 3 |
| 270 | primer | 3 |
| 271 | primavera | 3 |
| 272 | pompa | 3 |
| 273 | poca | 3 |
| 274 | plantas | 3 |
| 275 | pisan | 3 |
| 276 | piedras | 3 |
| 277 | peñas | 3 |
| 278 | ofrece | 3 |
| 279 | occidente | 3 |
| 280 | nunca | 3 |
| 281 | nuestra | 3 |
| 282 | nudos | 3 |
| 283 | novios | 3 |
| 284 | novio | 3 |
| 285 | norte | 3 |
| 286 | nocturno | 3 |
| 287 | noche | 3 |
| 288 | ninfas | 3 |
| 289 | niega | 3 |
| 290 | neptuno | 3 |
| 291 | mudo | 3 |
| 292 | movimiento | 3 |
| 293 | misma | 3 |
| 294 | mi | 3 |
| 295 | mesas | 3 |
| 296 | menuda | 3 |
| 297 | me | 3 |
| 298 | mármol | 3 |
| 299 | mano | 3 |
| 300 | madre | 3 |
| 301 | lugar | 3 |
| 302 | lucha | 3 |
| 303 | luces | 3 |
| 304 | limpio | 3 |
| 305 | lilios | 3 |
| 306 | ligero | 3 |
| 307 | lecho | 3 |
| 308 | labradora | 3 |
| 309 | islas | 3 |
| 310 | inmortal | 3 |
| 311 | ii | 3 |
| 312 | i | 3 |
| 313 | hijo | 3 |
| 314 | hermosura | 3 |
| 315 | hermosa | 3 |
| 316 | halló | 3 |
| 317 | hacer | 3 |
| 318 | graves | 3 |
| 319 | gloria | 3 |
| 320 | gime | 3 |
| 321 | fuente | 3 |
| 322 | fría | 3 |
| 323 | fresco | 3 |
| 324 | forastero | 3 |
| 325 | floresta | 3 |
| 326 | floreciente | 3 |
| 327 | fiero | 3 |
| 328 | extranjero | 3 |
| 329 | esta | 3 |
| 330 | espumas | 3 |
| 331 | esfera | 3 |
| 332 | errante | 3 |
| 333 | ellos | 3 |
| 334 | edad | 3 |
| 335 | duras | 3 |
| 336 | dura | 3 |
| 337 | dulcemente | 3 |
| 338 | distante | 3 |
| 339 | dijo | 3 |
| 340 | diez | 3 |
| 341 | deste | 3 |
| 342 | después | 3 |
| 343 | desata | 3 |
| 344 | dejó | 3 |
| 345 | deidad | 3 |
| 346 | dan | 3 |
| 347 | curso | 3 |
| 348 | culto | 3 |
| 349 | cuerno | 3 |
| 350 | cuatro | 3 |
| 351 | cuál | 3 |
| 352 | coronada | 3 |
| 353 | copia | 3 |
| 354 | concento | 3 |
| 355 | compañía | 3 |
| 356 | cien | 3 |
| 357 | ceres | 3 |
| 358 | cela | 3 |
| 359 | casta | 3 |
| 360 | carroza | 3 |
| 361 | carro | 3 |
| 362 | canas | 3 |
| 363 | campaña | 3 |
| 364 | cabras | 3 |
| 365 | cabo | 3 |
| 366 | bosque | 3 |
| 367 | bodas | 3 |
| 368 | blando | 3 |
| 369 | blancos | 3 |
| 370 | bellos | 3 |
| 371 | bárbara | 3 |
| 372 | austro | 3 |
| 373 | arroyuelo | 3 |
| 374 | armonía | 3 |
| 375 | armas | 3 |
| 376 | arena | 3 |
| 377 | arboleda | 3 |
| 378 | aquellos | 3 |
| 379 | apacible | 3 |
| 380 | años | 3 |
| 381 | alma | 3 |
| 382 | alimento | 3 |
| 383 | alguna | 3 |
| 384 | aldea | 3 |
| 385 | alba | 3 |
| 386 | alado | 3 |
| 387 | aguas | 3 |
| 388 | agradecido | 3 |
| 389 | adusto | 3 |
| 390 | acompañada | 3 |
| 391 | zagala | 2 |
| 392 | yugo | 2 |
| 393 | yedra | 2 |
| 394 | vulto | 2 |
| 395 | vuela | 2 |
| 396 | voces | 2 |
| 397 | vivid | 2 |
| 398 | virginal | 2 |
| 399 | vio | 2 |
| 400 | villanas | 2 |
| 401 | villana | 2 |
| 402 | vigilante | 2 |
| 403 | viejo | 2 |
| 404 | veneno | 2 |
| 405 | veloces | 2 |
| 406 | vecino | 2 |
| 407 | ve | 2 |
| 408 | vana | 2 |
| 409 | vago | 2 |
| 410 | undoso | 2 |
| 411 | unas | 2 |
| 412 | último | 2 |
| 413 | turba | 2 |
| 414 | troncos | 2 |
| 415 | trompa | 2 |
| 416 | trofeos | 2 |
| 417 | trofeo | 2 |
| 418 | traslada | 2 |
| 419 | traía | 2 |
| 420 | topacios | 2 |
| 421 | todo | 2 |
| 422 | todas | 2 |
| 423 | telas | 2 |
| 424 | tardó | 2 |
| 425 | tardo | 2 |
| 426 | surcar | 2 |
| 427 | sublime | 2 |
| 428 | sonoroso | 2 |
| 429 | silbo | 2 |
| 430 | senos | 2 |
| 431 | selvas | 2 |
| 432 | seis | 2 |
| 433 | seguro | 2 |
| 434 | segunda | 2 |
| 435 | según | 2 |
| 436 | sayal | 2 |
| 437 | sañudo | 2 |
| 438 | sagrado | 2 |
| 439 | saetas | 2 |
| 440 | saca | 2 |
| 441 | rústica | 2 |
| 442 | rüina | 2 |
| 443 | rüido | 2 |
| 444 | rudo | 2 |
| 445 | rubio | 2 |
| 446 | rosa | 2 |
| 447 | ronco | 2 |
| 448 | robustos | 2 |
| 449 | robusta | 2 |
| 450 | roble | 2 |
| 451 | riscos | 2 |
| 452 | ribera | 2 |
| 453 | repetido | 2 |
| 454 | regalado | 2 |
| 455 | redimió | 2 |
| 456 | razón | 2 |
| 457 | rato | 2 |
| 458 | ramo | 2 |
| 459 | quiso | 2 |
| 460 | quiere | 2 |
| 461 | quedó | 2 |
| 462 | purpúrea | 2 |
| 463 | prolija | 2 |
| 464 | previno | 2 |
| 465 | pólvora | 2 |
| 466 | polvo | 2 |
| 467 | polo | 2 |
| 468 | podía | 2 |
| 469 | pocas | 2 |
| 470 | planta | 2 |
| 471 | pisó | 2 |
| 472 | pisar | 2 |
| 473 | pisa | 2 |
| 474 | pintadas | 2 |
| 475 | piélagos | 2 |
| 476 | piedra | 2 |
| 477 | piedad | 2 |
| 478 | perlas | 2 |
| 479 | perdonó | 2 |
| 480 | pequeño | 2 |
| 481 | pequeña | 2 |
| 482 | pensamiento | 2 |
| 483 | pende | 2 |
| 484 | papel | 2 |
| 485 | palios | 2 |
| 486 | pales | 2 |
| 487 | pájaro | 2 |
| 488 | padre | 2 |
| 489 | otras | 2 |
| 490 | ostenta | 2 |
| 491 | onda | 2 |
| 492 | olvido | 2 |
| 493 | oído | 2 |
| 494 | nuevo | 2 |
| 495 | nuestros | 2 |
| 496 | nudo | 2 |
| 497 | noble | 2 |
| 498 | ninfa | 2 |
| 499 | nido | 2 |
| 500 | nave | 2 |
| 501 | náutica | 2 |
| 502 | nácar | 2 |
| 503 | musa | 2 |
| 504 | muros | 2 |
| 505 | mundo | 2 |
| 506 | muchos | 2 |
| 507 | mucho | 2 |
| 508 | montañeses | 2 |
| 509 | monarquía | 2 |
| 510 | mísero | 2 |
| 511 | mil | 2 |
| 512 | mieses | 2 |
| 513 | miente | 2 |
| 514 | meta | 2 |
| 515 | membrudo | 2 |
| 516 | mejor | 2 |
| 517 | marte | 2 |
| 518 | marfil | 2 |
| 519 | mañana | 2 |
| 520 | manos | 2 |
| 521 | mancebo | 2 |
| 522 | lunas | 2 |
| 523 | luminoso | 2 |
| 524 | lisonjear | 2 |
| 525 | líquidos | 2 |
| 526 | libia | 2 |
| 527 | levantado | 2 |
| 528 | lejos | 2 |
| 529 | leche | 2 |
| 530 | lava | 2 |
| 531 | lastimosas | 2 |
| 532 | lasciva | 2 |
| 533 | lágrimas | 2 |
| 534 | juventud | 2 |
| 535 | istmo | 2 |
| 536 | inmóvil | 2 |
| 537 | inciertos | 2 |
| 538 | impide | 2 |
| 539 | imitar | 2 |
| 540 | ilustra | 2 |
| 541 | igualmente | 2 |
| 542 | iguales | 2 |
| 543 | iguala | 2 |
| 544 | humo | 2 |
| 545 | humano | 2 |
| 546 | huésped | 2 |
| 547 | horas | 2 |
| 548 | hombros | 2 |
| 549 | hombro | 2 |
| 550 | hojas | 2 |
| 551 | hoja | 2 |
| 552 | hijos | 2 |
| 553 | hija | 2 |
| 554 | hicieron | 2 |
| 555 | hay | 2 |
| 556 | hasta | 2 |
| 557 | haciendo | 2 |
| 558 | hacía | 2 |
| 559 | gusto | 2 |
| 560 | guijas | 2 |
| 561 | guarda | 2 |
| 562 | grutas | 2 |
| 563 | grave | 2 |
| 564 | grana | 2 |
| 565 | glorïosa | 2 |
| 566 | gente | 2 |
| 567 | garzón | 2 |
| 568 | gallardo | 2 |
| 569 | galán | 2 |
| 570 | fugitivos | 2 |
| 571 | fugitiva | 2 |
| 572 | fuertes | 2 |
| 573 | fuentes | 2 |
| 574 | fuegos | 2 |
| 575 | fresno | 2 |
| 576 | fresca | 2 |
| 577 | freno | 2 |
| 578 | fragoso | 2 |
| 579 | fragosa | 2 |
| 580 | formando | 2 |
| 581 | fina | 2 |
| 582 | fijo | 2 |
| 583 | fieras | 2 |
| 584 | fiera | 2 |
| 585 | felices | 2 |
| 586 | fecundo | 2 |
| 587 | fatiga | 2 |
| 588 | fábrica | 2 |
| 589 | estambre | 2 |
| 590 | está | 2 |
| 591 | ésta | 2 |
| 592 | esposo | 2 |
| 593 | espera | 2 |
| 594 | escuadrón | 2 |
| 595 | escuadra | 2 |
| 596 | esconde | 2 |
| 597 | esclarecido | 2 |
| 598 | eran | 2 |
| 599 | émulo | 2 |
| 600 | emulación | 2 |
| 601 | elemento | 2 |
| 602 | ejido | 2 |
| 603 | eco | 2 |
| 604 | dudo | 2 |
| 605 | dosel | 2 |
| 606 | divide | 2 |
| 607 | distancia | 2 |
| 608 | diente | 2 |
| 609 | días | 2 |
| 610 | diamante | 2 |
| 611 | desnuda | 2 |
| 612 | desiguales | 2 |
| 613 | deseo | 2 |
| 614 | desatada | 2 |
| 615 | dejar | 2 |
| 616 | dejan | 2 |
| 617 | dará | 2 |
| 618 | cumbre | 2 |
| 619 | cuello | 2 |
| 620 | cristalino | 2 |
| 621 | crepúsculos | 2 |
| 622 | corvo | 2 |
| 623 | coros | 2 |
| 624 | coronado | 2 |
| 625 | corchos | 2 |
| 626 | coral | 2 |
| 627 | convoca | 2 |
| 628 | convida | 2 |
| 629 | confuso | 2 |
| 630 | confusión | 2 |
| 631 | concurso | 2 |
| 632 | cóncavo | 2 |
| 633 | color | 2 |
| 634 | codicia | 2 |
| 635 | cisne | 2 |
| 636 | ciñe | 2 |
| 637 | chupa | 2 |
| 638 | choza | 2 |
| 639 | chopo | 2 |
| 640 | cerúlea | 2 |
| 641 | cera | 2 |
| 642 | centro | 2 |
| 643 | céfiros | 2 |
| 644 | caudal | 2 |
| 645 | caso | 2 |
| 646 | carmesíes | 2 |
| 647 | cargas | 2 |
| 648 | cansado | 2 |
| 649 | canora | 2 |
| 650 | cano | 2 |
| 651 | candor | 2 |
| 652 | can | 2 |
| 653 | campos | 2 |
| 654 | caminante | 2 |
| 655 | calzada | 2 |
| 656 | cada | 2 |
| 657 | cabrero | 2 |
| 658 | cabeza | 2 |
| 659 | breves | 2 |
| 660 | bocas | 2 |
| 661 | besó | 2 |
| 662 | besa | 2 |
| 663 | bárbaros | 2 |
| 664 | banderas | 2 |
| 665 | balcón | 2 |
| 666 | baja | 2 |
| 667 | baile | 2 |
| 668 | bailando | 2 |
| 669 | baco | 2 |
| 670 | ave | 2 |
| 671 | augusto | 2 |
| 672 | atención | 2 |
| 673 | áspides | 2 |
| 674 | arrogante | 2 |
| 675 | arenas | 2 |
| 676 | arcos | 2 |
| 677 | arco | 2 |
| 678 | árbitro | 2 |
| 679 | arabia | 2 |
| 680 | apetito | 2 |
| 681 | animoso | 2 |
| 682 | animal | 2 |
| 683 | ambición | 2 |
| 684 | amante | 2 |
| 685 | almenas | 2 |
| 686 | allí | 2 |
| 687 | algunas | 2 |
| 688 | aldehuela | 2 |
| 689 | álamos | 2 |
| 690 | alados | 2 |
| 691 | agudo | 2 |
| 692 | agua | 2 |
| 693 | agricultura | 2 |
| 694 | agradable | 2 |
| 695 | ágil | 2 |
| 696 | adora | 2 |
| 697 | admiración | 2 |
| 698 | acento | 2 |
| 699 | acaba | 2 |
| 700 | abraza | 2 |
| 701 | abeja | 2 |
| 702 | abaten | 2 |
| 703 | zona | 1 |
| 704 | zodíaco | 1 |
| 705 | zampoñas | 1 |
| 706 | zampoña | 1 |
| 707 | zagales | 1 |
| 708 | zagalejas | 1 |
| 709 | yedras | 1 |
| 710 | yacen | 1 |
| 711 | yace | 1 |
| 712 | vulgo | 1 |
| 713 | vulgares | 1 |
| 714 | vulcano | 1 |
| 715 | vuestra | 1 |
| 716 | vuelven | 1 |
| 717 | voto | 1 |
| 718 | votado | 1 |
| 719 | vomitado | 1 |
| 720 | volcán | 1 |
| 721 | volante | 1 |
| 722 | volando | 1 |
| 723 | vividores | 1 |
| 724 | vital | 1 |
| 725 | vistió | 1 |
| 726 | visten | 1 |
| 727 | vistan | 1 |
| 728 | virtud | 1 |
| 729 | vírgenes | 1 |
| 730 | violentando | 1 |
| 731 | víolas | 1 |
| 732 | violaron | 1 |
| 733 | vïolar | 1 |
| 734 | vinos | 1 |
| 735 | vinculen | 1 |
| 736 | vincule | 1 |
| 737 | vinculados | 1 |
| 738 | vigilantes | 1 |
| 739 | vientos | 1 |
| 740 | viendo | 1 |
| 741 | vidrio | 1 |
| 742 | vidrïera | 1 |
| 743 | vida | 1 |
| 744 | victoria | 1 |
| 745 | víbora | 1 |
| 746 | viales | 1 |
| 747 | vestidas | 1 |
| 748 | ves | 1 |
| 749 | versos | 1 |
| 750 | vergonzosas | 1 |
| 751 | vergonzosa | 1 |
| 752 | verdugo | 1 |
| 753 | verás | 1 |
| 754 | ver | 1 |
| 755 | venza | 1 |
| 756 | venus | 1 |
| 757 | venerables | 1 |
| 758 | venerable | 1 |
| 759 | vencido | 1 |
| 760 | vencidas | 1 |
| 761 | vencida | 1 |
| 762 | vencedores | 1 |
| 763 | vence | 1 |
| 764 | venatorio | 1 |
| 765 | venas | 1 |
| 766 | venablos | 1 |
| 767 | vemos | 1 |
| 768 | veloz | 1 |
| 769 | vellones | 1 |
| 770 | veleras | 1 |
| 771 | vecinos | 1 |
| 772 | vario | 1 |
| 773 | varada | 1 |
| 774 | vara | 1 |
| 775 | vaquera | 1 |
| 776 | vanos | 1 |
| 777 | valientes | 1 |
| 778 | vaga | 1 |
| 779 | vadeando | 1 |
| 780 | vacíos | 1 |
| 781 | vacilante | 1 |
| 782 | vacas | 1 |
| 783 | va | 1 |
| 784 | útilmente | 1 |
| 785 | urbana | 1 |
| 786 | unos | 1 |
| 787 | undosa | 1 |
| 788 | umbroso | 1 |
| 789 | umbrosa | 1 |
| 790 | turquesco | 1 |
| 791 | turquesadas | 1 |
| 792 | turno | 1 |
| 793 | turbante | 1 |
| 794 | tumba | 1 |
| 795 | tropa | 1 |
| 796 | triunfador | 1 |
| 797 | triunfa | 1 |
| 798 | triplicado | 1 |
| 799 | trïón | 1 |
| 800 | trillado | 1 |
| 801 | tridente | 1 |
| 802 | trepa | 1 |
| 803 | trenzándose | 1 |
| 804 | trémulos | 1 |
| 805 | tremolantes | 1 |
| 806 | tremola | 1 |
| 807 | treguas | 1 |
| 808 | travieso | 1 |
| 809 | tras | 1 |
| 810 | tranquilidad | 1 |
| 811 | traducido | 1 |
| 812 | tradición | 1 |
| 813 | trabajo | 1 |
| 814 | tostada | 1 |
| 815 | tósigo | 1 |
| 816 | tórrida | 1 |
| 817 | torres | 1 |
| 818 | torrente | 1 |
| 819 | torre | 1 |
| 820 | toros | 1 |
| 821 | torno | 1 |
| 822 | tormes | 1 |
| 823 | tormentoso | 1 |
| 824 | torcidos | 1 |
| 825 | toda | 1 |
| 826 | tiro | 1 |
| 827 | tiria | 1 |
| 828 | tiraniza | 1 |
| 829 | tinieblas | 1 |
| 830 | tiniebla | 1 |
| 831 | tímido | 1 |
| 832 | tijera | 1 |
| 833 | tigre | 1 |
| 834 | tifis | 1 |
| 835 | tiernos | 1 |
| 836 | tierna | 1 |
| 837 | tienda | 1 |
| 838 | tïara | 1 |
| 839 | ti | 1 |
| 840 | testigo | 1 |
| 841 | terso | 1 |
| 842 | terno | 1 |
| 843 | ternezuelo | 1 |
| 844 | terneruela | 1 |
| 845 | termodonte | 1 |
| 846 | teñido | 1 |
| 847 | tenían | 1 |
| 848 | tenebroso | 1 |
| 849 | tendido | 1 |
| 850 | tenaz | 1 |
| 851 | tempranos | 1 |
| 852 | templarse | 1 |
| 853 | templar | 1 |
| 854 | templa | 1 |
| 855 | temeroso | 1 |
| 856 | temeridades | 1 |
| 857 | temer | 1 |
| 858 | teme | 1 |
| 859 | telar | 1 |
| 860 | tela | 1 |
| 861 | tejió | 1 |
| 862 | tejiendo | 1 |
| 863 | tejido | 1 |
| 864 | tea | 1 |
| 865 | tapiz | 1 |
| 866 | tapete | 1 |
| 867 | taladro | 1 |
| 868 | tafiletes | 1 |
| 869 | tabla | 1 |
| 870 | suyos | 1 |
| 871 | suyas | 1 |
| 872 | sutil | 1 |
| 873 | suspiros | 1 |
| 874 | surcó | 1 |
| 875 | surcado | 1 |
| 876 | surca | 1 |
| 877 | sur | 1 |
| 878 | supo | 1 |
| 879 | supla | 1 |
| 880 | sumas | 1 |
| 881 | sufre | 1 |
| 882 | sueltos | 1 |
| 883 | suelto | 1 |
| 884 | suele | 1 |
| 885 | suegro | 1 |
| 886 | sudor | 1 |
| 887 | sudar | 1 |
| 888 | sudando | 1 |
| 889 | suda | 1 |
| 890 | sucede | 1 |
| 891 | sordo | 1 |
| 892 | sorbido | 1 |
| 893 | sonoros | 1 |
| 894 | sonora | 1 |
| 895 | sonante | 1 |
| 896 | solo | 1 |
| 897 | solícito | 1 |
| 898 | solicitar | 1 |
| 899 | solicitan | 1 |
| 900 | solícita | 1 |
| 901 | soles | 1 |
| 902 | solemniza | 1 |
| 903 | soledad | 1 |
| 904 | sobran | 1 |
| 905 | soberbios | 1 |
| 906 | soberbia | 1 |
| 907 | soberanos | 1 |
| 908 | soberano | 1 |
| 909 | sitïal | 1 |
| 910 | sísifo | 1 |
| 911 | sirvieron | 1 |
| 912 | sirenas | 1 |
| 913 | sirena | 1 |
| 914 | sincopan | 1 |
| 915 | sinceridad | 1 |
| 916 | simples | 1 |
| 917 | sileno | 1 |
| 918 | siguiendo | 1 |
| 919 | sierpes | 1 |
| 920 | sierpe | 1 |
| 921 | siente | 1 |
| 922 | sienes | 1 |
| 923 | siendo | 1 |
| 924 | sidón | 1 |
| 925 | sido | 1 |
| 926 | sexos | 1 |
| 927 | servido | 1 |
| 928 | serrana | 1 |
| 929 | serenara | 1 |
| 930 | serenaba | 1 |
| 931 | sepultura | 1 |
| 932 | sepultados | 1 |
| 933 | sepulcros | 1 |
| 934 | seña | 1 |
| 935 | seno | 1 |
| 936 | senectud | 1 |
| 937 | semicapro | 1 |
| 938 | selva | 1 |
| 939 | sellar | 1 |
| 940 | sella | 1 |
| 941 | segundos | 1 |
| 942 | segundas | 1 |
| 943 | seguida | 1 |
| 944 | sedientas | 1 |
| 945 | seda | 1 |
| 946 | sed | 1 |
| 947 | secretos | 1 |
| 948 | secretas | 1 |
| 949 | secos | 1 |
| 950 | seca | 1 |
| 951 | sean | 1 |
| 952 | sátiros | 1 |
| 953 | sarmiento | 1 |
| 954 | sardo | 1 |
| 955 | santo | 1 |
| 956 | sangre | 1 |
| 957 | salvas | 1 |
| 958 | saludolos | 1 |
| 959 | saludado | 1 |
| 960 | saluda | 1 |
| 961 | salterio | 1 |
| 962 | salen | 1 |
| 963 | sacudido | 1 |
| 964 | sacros | 1 |
| 965 | sacro | 1 |
| 966 | sabrosa | 1 |
| 967 | sabio | 1 |
| 968 | sabido | 1 |
| 969 | saber | 1 |
| 970 | sabe | 1 |
| 971 | rumor | 1 |
| 972 | ruiseñores | 1 |
| 973 | rüinas | 1 |
| 974 | rugoso | 1 |
| 975 | rueca | 1 |
| 976 | ruda | 1 |
| 977 | roto | 1 |
| 978 | rota | 1 |
| 979 | rosicler | 1 |
| 980 | rosado | 1 |
| 981 | rompieron | 1 |
| 982 | roma | 1 |
| 983 | rocío | 1 |
| 984 | roca | 1 |
| 985 | robustas | 1 |
| 986 | robador | 1 |
| 987 | rizado | 1 |
| 988 | rival | 1 |
| 989 | risco | 1 |
| 990 | ríos | 1 |
| 991 | rindió | 1 |
| 992 | rinda | 1 |
| 993 | riberas | 1 |
| 994 | rey | 1 |
| 995 | revocó | 1 |
| 996 | revoca | 1 |
| 997 | revelar | 1 |
| 998 | retozadores | 1 |
| 999 | retamas | 1 |
| 1000 | resuelven | 1 |
| 1001 | resto | 1 |
| 1002 | restituyen | 1 |
| 1003 | restituir | 1 |
| 1004 | respuesta | 1 |
| 1005 | responda | 1 |
| 1006 | resistir | 1 |
| 1007 | resistencia | 1 |
| 1008 | reposo | 1 |
| 1009 | repita | 1 |
| 1010 | repeló | 1 |
| 1011 | renunciar | 1 |
| 1012 | rémora | 1 |
| 1013 | remiso | 1 |
| 1014 | reja | 1 |
| 1015 | reinos | 1 |
| 1016 | regulados | 1 |
| 1017 | regocijo | 1 |
| 1018 | reflejo | 1 |
| 1019 | reduciendo | 1 |
| 1020 | rediman | 1 |
| 1021 | recuerda | 1 |
| 1022 | recordó | 1 |
| 1023 | reconociendo | 1 |
| 1024 | reclinarse | 1 |
| 1025 | reclinaron | 1 |
| 1026 | reclamo | 1 |
| 1027 | recíprocos | 1 |
| 1028 | reciente | 1 |
| 1029 | recelar | 1 |
| 1030 | recelando | 1 |
| 1031 | rebelde | 1 |
| 1032 | reales | 1 |
| 1033 | real | 1 |
| 1034 | rayó | 1 |
| 1035 | rayo | 1 |
| 1036 | rayando | 1 |
| 1037 | rayaba | 1 |
| 1038 | raya | 1 |
| 1039 | raso | 1 |
| 1040 | rara | 1 |
| 1041 | ramas | 1 |
| 1042 | rama | 1 |
| 1043 | racimo | 1 |
| 1044 | quieren | 1 |
| 1045 | quesillo | 1 |
| 1046 | quería | 1 |
| 1047 | querellas | 1 |
| 1048 | quejarse | 1 |
| 1049 | quedos | 1 |
| 1050 | quédese | 1 |
| 1051 | quedaba | 1 |
| 1052 | puso | 1 |
| 1053 | purpúreo | 1 |
| 1054 | purpurear | 1 |
| 1055 | pululante | 1 |
| 1056 | pulsado | 1 |
| 1057 | puerto | 1 |
| 1058 | puede | 1 |
| 1059 | pueblos | 1 |
| 1060 | pueblo | 1 |
| 1061 | pudieron | 1 |
| 1062 | pudieran | 1 |
| 1063 | ptolomeos | 1 |
| 1064 | psiques | 1 |
| 1065 | próvidas | 1 |
| 1066 | próspera | 1 |
| 1067 | propia | 1 |
| 1068 | pronto | 1 |
| 1069 | promontorio | 1 |
| 1070 | progenie | 1 |
| 1071 | profundos | 1 |
| 1072 | profundas | 1 |
| 1073 | profana | 1 |
| 1074 | productor | 1 |
| 1075 | procuran | 1 |
| 1076 | procura | 1 |
| 1077 | privilegió | 1 |
| 1078 | principio | 1 |
| 1079 | príncipe | 1 |
| 1080 | primaveras | 1 |
| 1081 | previniendo | 1 |
| 1082 | previene | 1 |
| 1083 | prevenido | 1 |
| 1084 | prevenidas | 1 |
| 1085 | presentes | 1 |
| 1086 | presenta | 1 |
| 1087 | presagios | 1 |
| 1088 | prendas | 1 |
| 1089 | prenda | 1 |
| 1090 | premios | 1 |
| 1091 | premio | 1 |
| 1092 | premïados | 1 |
| 1093 | preciso | 1 |
| 1094 | precisa | 1 |
| 1095 | precipitados | 1 |
| 1096 | precipita | 1 |
| 1097 | precioso | 1 |
| 1098 | precedente | 1 |
| 1099 | prado | 1 |
| 1100 | postrimera | 1 |
| 1101 | poro | 1 |
| 1102 | populoso | 1 |
| 1103 | populosa | 1 |
| 1104 | ponto | 1 |
| 1105 | ponen | 1 |
| 1106 | ponderosa | 1 |
| 1107 | pondera | 1 |
| 1108 | pomos | 1 |
| 1109 | polvorosa | 1 |
| 1110 | político | 1 |
| 1111 | política | 1 |
| 1112 | podría | 1 |
| 1113 | pocos | 1 |
| 1114 | poco | 1 |
| 1115 | pobre | 1 |
| 1116 | pobos | 1 |
| 1117 | pluvia | 1 |
| 1118 | playas | 1 |
| 1119 | playa | 1 |
| 1120 | pizarras | 1 |
| 1121 | pisando | 1 |
| 1122 | pira | 1 |
| 1123 | pinos | 1 |
| 1124 | piloto | 1 |
| 1125 | pies | 1 |
| 1126 | pierde | 1 |
| 1127 | pieles | 1 |
| 1128 | piélago | 1 |
| 1129 | pidiendo | 1 |
| 1130 | picos | 1 |
| 1131 | pías | 1 |
| 1132 | piadoso | 1 |
| 1133 | piadosas | 1 |
| 1134 | pestañas | 1 |
| 1135 | peso | 1 |
| 1136 | pesares | 1 |
| 1137 | pesadumbre | 1 |
| 1138 | personas | 1 |
| 1139 | perseguida | 1 |
| 1140 | perros | 1 |
| 1141 | pero | 1 |
| 1142 | perezoso | 1 |
| 1143 | perezosas | 1 |
| 1144 | peregrina | 1 |
| 1145 | perdona | 1 |
| 1146 | perdidos | 1 |
| 1147 | perdían | 1 |
| 1148 | perderse | 1 |
| 1149 | pequeños | 1 |
| 1150 | peñascos | 1 |
| 1151 | pénsiles | 1 |
| 1152 | penetraste | 1 |
| 1153 | peneida | 1 |
| 1154 | pendientes | 1 |
| 1155 | pendiente | 1 |
| 1156 | penda | 1 |
| 1157 | pena | 1 |
| 1158 | pelo | 1 |
| 1159 | peinar | 1 |
| 1160 | peina | 1 |
| 1161 | pedernal | 1 |
| 1162 | pedazos | 1 |
| 1163 | pecho | 1 |
| 1164 | paz | 1 |
| 1165 | pastores | 1 |
| 1166 | pastorales | 1 |
| 1167 | pastoral | 1 |
| 1168 | pastor | 1 |
| 1169 | pasaron | 1 |
| 1170 | partes | 1 |
| 1171 | parte | 1 |
| 1172 | parnaso | 1 |
| 1173 | parlera | 1 |
| 1174 | pario | 1 |
| 1175 | parientas | 1 |
| 1176 | pareció | 1 |
| 1177 | parecía | 1 |
| 1178 | pardo | 1 |
| 1179 | paños | 1 |
| 1180 | panales | 1 |
| 1181 | pan | 1 |
| 1182 | pámpanos | 1 |
| 1183 | palizada | 1 |
| 1184 | palio | 1 |
| 1185 | palinuro | 1 |
| 1186 | pálidos | 1 |
| 1187 | palestra | 1 |
| 1188 | palas | 1 |
| 1189 | palacios | 1 |
| 1190 | palabras | 1 |
| 1191 | pajizo | 1 |
| 1192 | padrino | 1 |
| 1193 | pacíficas | 1 |
| 1194 | pace | 1 |
| 1195 | pabellón | 1 |
| 1196 | ovejas | 1 |
| 1197 | ostente | 1 |
| 1198 | oso | 1 |
| 1199 | oscura | 1 |
| 1200 | orza | 1 |
| 1201 | orlado | 1 |
| 1202 | orladas | 1 |
| 1203 | orillas | 1 |
| 1204 | orilla | 1 |
| 1205 | orientales | 1 |
| 1206 | orgullo | 1 |
| 1207 | orejas | 1 |
| 1208 | oreja | 1 |
| 1209 | orcas | 1 |
| 1210 | opulencias | 1 |
| 1211 | opuesto | 1 |
| 1212 | oprime | 1 |
| 1213 | omiso | 1 |
| 1214 | oliva | 1 |
| 1215 | olímpica | 1 |
| 1216 | ojo | 1 |
| 1217 | oílla | 1 |
| 1218 | oía | 1 |
| 1219 | ofrecen | 1 |
| 1220 | ofendido | 1 |
| 1221 | ocupar | 1 |
| 1222 | ocho | 1 |
| 1223 | ocëano | 1 |
| 1224 | ocaso | 1 |
| 1225 | ocasión | 1 |
| 1226 | obstinada | 1 |
| 1227 | obscuro | 1 |
| 1228 | obligación | 1 |
| 1229 | oblicuos | 1 |
| 1230 | obeliscos | 1 |
| 1231 | obelisco | 1 |
| 1232 | obedeciendo | 1 |
| 1233 | nuncio | 1 |
| 1234 | numeroso | 1 |
| 1235 | numerosamente | 1 |
| 1236 | nuez | 1 |
| 1237 | nuevos | 1 |
| 1238 | nuevas | 1 |
| 1239 | nueva | 1 |
| 1240 | nuestro | 1 |
| 1241 | nubes | 1 |
| 1242 | novillos | 1 |
| 1243 | novia | 1 |
| 1244 | noto | 1 |
| 1245 | nos | 1 |
| 1246 | noruega | 1 |
| 1247 | nombre | 1 |
| 1248 | nogal | 1 |
| 1249 | nocturnas | 1 |
| 1250 | nocturna | 1 |
| 1251 | níobe | 1 |
| 1252 | niño | 1 |
| 1253 | ninguno | 1 |
| 1254 | nilo | 1 |
| 1255 | nieven | 1 |
| 1256 | nieblas | 1 |
| 1257 | niebla | 1 |
| 1258 | neutro | 1 |
| 1259 | neutralidad | 1 |
| 1260 | netas | 1 |
| 1261 | nervïosos | 1 |
| 1262 | nervios | 1 |
| 1263 | negó | 1 |
| 1264 | negar | 1 |
| 1265 | necesidades | 1 |
| 1266 | náufrago | 1 |
| 1267 | naufragios | 1 |
| 1268 | naufragante | 1 |
| 1269 | narcisos | 1 |
| 1270 | narciso | 1 |
| 1271 | nacido | 1 |
| 1272 | nace | 1 |
| 1273 | muy | 1 |
| 1274 | músicas | 1 |
| 1275 | músculos | 1 |
| 1276 | muró | 1 |
| 1277 | murieron | 1 |
| 1278 | murarse | 1 |
| 1279 | multiplica | 1 |
| 1280 | muflón | 1 |
| 1281 | muestras | 1 |
| 1282 | muestra | 1 |
| 1283 | muerte | 1 |
| 1284 | muertas | 1 |
| 1285 | muere | 1 |
| 1286 | mudos | 1 |
| 1287 | mucha | 1 |
| 1288 | mozo | 1 |
| 1289 | mosquetas | 1 |
| 1290 | mortal | 1 |
| 1291 | moren | 1 |
| 1292 | mordiendo | 1 |
| 1293 | morados | 1 |
| 1294 | moradoras | 1 |
| 1295 | mora | 1 |
| 1296 | montero | 1 |
| 1297 | montería | 1 |
| 1298 | monte | 1 |
| 1299 | montaraz | 1 |
| 1300 | montañesas | 1 |
| 1301 | montañesa | 1 |
| 1302 | montañas | 1 |
| 1303 | monstruo | 1 |
| 1304 | molesta | 1 |
| 1305 | modestas | 1 |
| 1306 | moderno | 1 |
| 1307 | modelos | 1 |
| 1308 | mismos | 1 |
| 1309 | mismo | 1 |
| 1310 | miserablemente | 1 |
| 1311 | mira | 1 |
| 1312 | ministrar | 1 |
| 1313 | minerva | 1 |
| 1314 | minas | 1 |
| 1315 | minador | 1 |
| 1316 | milla | 1 |
| 1317 | militar | 1 |
| 1318 | milanés | 1 |
| 1319 | mies | 1 |
| 1320 | miembro | 1 |
| 1321 | midiendo | 1 |
| 1322 | midas | 1 |
| 1323 | mezcladas | 1 |
| 1324 | métrica | 1 |
| 1325 | metas | 1 |
| 1326 | metales | 1 |
| 1327 | metal | 1 |
| 1328 | merced | 1 |
| 1329 | mentira | 1 |
| 1330 | mentir | 1 |
| 1331 | mentidos | 1 |
| 1332 | mentido | 1 |
| 1333 | menosprecia | 1 |
| 1334 | menguando | 1 |
| 1335 | membrillo | 1 |
| 1336 | mejores | 1 |
| 1337 | mejillas | 1 |
| 1338 | medianías | 1 |
| 1339 | media | 1 |
| 1340 | mayos | 1 |
| 1341 | mayores | 1 |
| 1342 | matutinos | 1 |
| 1343 | matizado | 1 |
| 1344 | matiza | 1 |
| 1345 | mariposa | 1 |
| 1346 | marino | 1 |
| 1347 | marinero | 1 |
| 1348 | marinas | 1 |
| 1349 | marina | 1 |
| 1350 | márgenes | 1 |
| 1351 | margen | 1 |
| 1352 | mares | 1 |
| 1353 | mapa | 1 |
| 1354 | mañosos | 1 |
| 1355 | mantenía | 1 |
| 1356 | manteles | 1 |
| 1357 | manso | 1 |
| 1358 | manjares | 1 |
| 1359 | manera | 1 |
| 1360 | manchada | 1 |
| 1361 | mancebos | 1 |
| 1362 | majestüoso | 1 |
| 1363 | magnificencia | 1 |
| 1364 | madruga | 1 |
| 1365 | lustro | 1 |
| 1366 | luna | 1 |
| 1367 | luminosas | 1 |
| 1368 | luminarias | 1 |
| 1369 | lumbre | 1 |
| 1370 | lugarillo | 1 |
| 1371 | lucrecia | 1 |
| 1372 | lucina | 1 |
| 1373 | lucientes | 1 |
| 1374 | lucidos | 1 |
| 1375 | luchadores | 1 |
| 1376 | luce | 1 |
| 1377 | lograr | 1 |
| 1378 | lóbrego | 1 |
| 1379 | lobo | 1 |
| 1380 | lloró | 1 |
| 1381 | llora | 1 |
| 1382 | llevó | 1 |
| 1383 | llevar | 1 |
| 1384 | lleva | 1 |
| 1385 | llenos | 1 |
| 1386 | llegaron | 1 |
| 1387 | llegaran | 1 |
| 1388 | llegan | 1 |
| 1389 | llave | 1 |
| 1390 | llanto | 1 |
| 1391 | llama | 1 |
| 1392 | lisonjera | 1 |
| 1393 | lisonja | 1 |
| 1394 | liso | 1 |
| 1395 | lince | 1 |
| 1396 | límites | 1 |
| 1397 | liëo | 1 |
| 1398 | lides | 1 |
| 1399 | libre | 1 |
| 1400 | libra | 1 |
| 1401 | libertad | 1 |
| 1402 | liberal | 1 |
| 1403 | libar | 1 |
| 1404 | leves | 1 |
| 1405 | levantando | 1 |
| 1406 | levantan | 1 |
| 1407 | levantadas | 1 |
| 1408 | letras | 1 |
| 1409 | leteo | 1 |
| 1410 | lestrigones | 1 |
| 1411 | leopardo | 1 |
| 1412 | leños | 1 |
| 1413 | lentisco | 1 |
| 1414 | lenguas | 1 |
| 1415 | lengua | 1 |
| 1416 | leda | 1 |
| 1417 | lean | 1 |
| 1418 | lea | 1 |
| 1419 | lazo | 1 |
| 1420 | laurel | 1 |
| 1421 | lascivos | 1 |
| 1422 | largo | 1 |
| 1423 | largas | 1 |
| 1424 | larga | 1 |
| 1425 | lana | 1 |
| 1426 | lámina | 1 |
| 1427 | lamiéndolo | 1 |
| 1428 | lagrimosas | 1 |
| 1429 | labradoras | 1 |
| 1430 | labrador | 1 |
| 1431 | labios | 1 |
| 1432 | juzga | 1 |
| 1433 | junto | 1 |
| 1434 | juntar | 1 |
| 1435 | juntaba | 1 |
| 1436 | junón | 1 |
| 1437 | juno | 1 |
| 1438 | juncos | 1 |
| 1439 | jüicio | 1 |
| 1440 | judiciosa | 1 |
| 1441 | jóvenes | 1 |
| 1442 | jazmines | 1 |
| 1443 | jaspes | 1 |
| 1444 | jardines | 1 |
| 1445 | jabalina | 1 |
| 1446 | isla | 1 |
| 1447 | invocan | 1 |
| 1448 | invidiosas | 1 |
| 1449 | invidïosa | 1 |
| 1450 | invidia | 1 |
| 1451 | investigó | 1 |
| 1452 | invención | 1 |
| 1453 | inunde | 1 |
| 1454 | inundación | 1 |
| 1455 | introdujo | 1 |
| 1456 | intrépida | 1 |
| 1457 | intonso | 1 |
| 1458 | interrumpido | 1 |
| 1459 | interposición | 1 |
| 1460 | instrumentos | 1 |
| 1461 | instante | 1 |
| 1462 | inspirados | 1 |
| 1463 | inocencia | 1 |
| 1464 | ingrato | 1 |
| 1465 | ingenïosa | 1 |
| 1466 | infelizmente | 1 |
| 1467 | infausto | 1 |
| 1468 | infamó | 1 |
| 1469 | infamar | 1 |
| 1470 | inexpugnable | 1 |
| 1471 | industria | 1 |
| 1472 | indigna | 1 |
| 1473 | indeciso | 1 |
| 1474 | inculta | 1 |
| 1475 | inculcar | 1 |
| 1476 | inconstantes | 1 |
| 1477 | inconsiderado | 1 |
| 1478 | inclinar | 1 |
| 1479 | inclina | 1 |
| 1480 | incierto | 1 |
| 1481 | impulso | 1 |
| 1482 | importuna | 1 |
| 1483 | implicantes | 1 |
| 1484 | impertinentes | 1 |
| 1485 | imperïoso | 1 |
| 1486 | impenetrable | 1 |
| 1487 | impedidos | 1 |
| 1488 | impacïente | 1 |
| 1489 | imitador | 1 |
| 1490 | ilustren | 1 |
| 1491 | igualara | 1 |
| 1492 | ignoran | 1 |
| 1493 | ignora | 1 |
| 1494 | ida | 1 |
| 1495 | ícaro | 1 |
| 1496 | iba | 1 |
| 1497 | huye | 1 |
| 1498 | huso | 1 |
| 1499 | hurtos | 1 |
| 1500 | hurta | 1 |
| 1501 | humosos | 1 |
| 1502 | humor | 1 |
| 1503 | húmido | 1 |
| 1504 | humeros | 1 |
| 1505 | huesos | 1 |
| 1506 | huellas | 1 |
| 1507 | hospitalidad | 1 |
| 1508 | hospedó | 1 |
| 1509 | hospedaje | 1 |
| 1510 | hospedado | 1 |
| 1511 | hospeda | 1 |
| 1512 | hormigas | 1 |
| 1513 | horizontes | 1 |
| 1514 | honre | 1 |
| 1515 | honrarás | 1 |
| 1516 | honra | 1 |
| 1517 | honor | 1 |
| 1518 | honesto | 1 |
| 1519 | honesta | 1 |
| 1520 | hondas | 1 |
| 1521 | homicidas | 1 |
| 1522 | holandas | 1 |
| 1523 | historias | 1 |
| 1524 | hircano | 1 |
| 1525 | himno | 1 |
| 1526 | hilos | 1 |
| 1527 | hilo | 1 |
| 1528 | hijuelos | 1 |
| 1529 | hijas | 1 |
| 1530 | hierro | 1 |
| 1531 | hiere | 1 |
| 1532 | hielo | 1 |
| 1533 | hidrópica | 1 |
| 1534 | hiciera | 1 |
| 1535 | hibleo | 1 |
| 1536 | herradas | 1 |
| 1537 | héroe | 1 |
| 1538 | hermoso | 1 |
| 1539 | herida | 1 |
| 1540 | hereda | 1 |
| 1541 | hercúleos | 1 |
| 1542 | heno | 1 |
| 1543 | hemisferio | 1 |
| 1544 | hechas | 1 |
| 1545 | hayas | 1 |
| 1546 | hará | 1 |
| 1547 | han | 1 |
| 1548 | hamadrías | 1 |
| 1549 | halle | 1 |
| 1550 | hallar | 1 |
| 1551 | halagos | 1 |
| 1552 | hagan | 1 |
| 1553 | haciéndole | 1 |
| 1554 | hacienda | 1 |
| 1555 | hacían | 1 |
| 1556 | hacen | 1 |
| 1557 | habló | 1 |
| 1558 | habla | 1 |
| 1559 | habían | 1 |
| 1560 | habian | 1 |
| 1561 | había | 1 |
| 1562 | gusano | 1 |
| 1563 | gulosos | 1 |
| 1564 | gulosa | 1 |
| 1565 | guirnalda | 1 |
| 1566 | guía | 1 |
| 1567 | guerra | 1 |
| 1568 | guardó | 1 |
| 1569 | guardan | 1 |
| 1570 | gruta | 1 |
| 1571 | grullas | 1 |
| 1572 | grueso | 1 |
| 1573 | gruesa | 1 |
| 1574 | griego | 1 |
| 1575 | grecia | 1 |
| 1576 | granjerías | 1 |
| 1577 | grandes | 1 |
| 1578 | grama | 1 |
| 1579 | gradüadamente | 1 |
| 1580 | gracias | 1 |
| 1581 | gracia | 1 |
| 1582 | gozar | 1 |
| 1583 | gomas | 1 |
| 1584 | golpe | 1 |
| 1585 | golosos | 1 |
| 1586 | golfo | 1 |
| 1587 | glorïoso | 1 |
| 1588 | gloriosas | 1 |
| 1589 | gitano | 1 |
| 1590 | gira | 1 |
| 1591 | gigantes | 1 |
| 1592 | gentil | 1 |
| 1593 | generoso | 1 |
| 1594 | gemido | 1 |
| 1595 | gasta | 1 |
| 1596 | garzones | 1 |
| 1597 | garganta | 1 |
| 1598 | ganges | 1 |
| 1599 | ganado | 1 |
| 1600 | gamo | 1 |
| 1601 | gallardas | 1 |
| 1602 | gallarda | 1 |
| 1603 | galería | 1 |
| 1604 | galeras | 1 |
| 1605 | gaita | 1 |
| 1606 | gabán | 1 |
| 1607 | furor | 1 |
| 1608 | funerales | 1 |
| 1609 | fulminante | 1 |
| 1610 | fulminando | 1 |
| 1611 | fuerzas | 1 |
| 1612 | fuerza | 1 |
| 1613 | fuerte | 1 |
| 1614 | fueran | 1 |
| 1615 | fuera | 1 |
| 1616 | frutales | 1 |
| 1617 | frustrados | 1 |
| 1618 | frondoso | 1 |
| 1619 | frondosas | 1 |
| 1620 | frondosa | 1 |
| 1621 | frío | 1 |
| 1622 | frigio | 1 |
| 1623 | fresnos | 1 |
| 1624 | fragantes | 1 |
| 1625 | fragante | 1 |
| 1626 | fracaso | 1 |
| 1627 | formidables | 1 |
| 1628 | formidable | 1 |
| 1629 | forma | 1 |
| 1630 | flota | 1 |
| 1631 | florestas | 1 |
| 1632 | flora | 1 |
| 1633 | flor | 1 |
| 1634 | flechen | 1 |
| 1635 | flechados | 1 |
| 1636 | flandes | 1 |
| 1637 | flamantes | 1 |
| 1638 | firmes | 1 |
| 1639 | firme | 1 |
| 1640 | fió | 1 |
| 1641 | fino | 1 |
| 1642 | fingieron | 1 |
| 1643 | fingido | 1 |
| 1644 | fijas | 1 |
| 1645 | fierezas | 1 |
| 1646 | fíe | 1 |
| 1647 | fiándose | 1 |
| 1648 | festivos | 1 |
| 1649 | festivo | 1 |
| 1650 | ferro | 1 |
| 1651 | feroz | 1 |
| 1652 | fénix | 1 |
| 1653 | femenil | 1 |
| 1654 | felicidad | 1 |
| 1655 | febo | 1 |
| 1656 | febeo | 1 |
| 1657 | favor | 1 |
| 1658 | faunos | 1 |
| 1659 | fatigado | 1 |
| 1660 | fatal | 1 |
| 1661 | farol | 1 |
| 1662 | fanal | 1 |
| 1663 | famoso | 1 |
| 1664 | fama | 1 |
| 1665 | falta | 1 |
| 1666 | falda | 1 |
| 1667 | faetón | 1 |
| 1668 | fácil | 1 |
| 1669 | fabrican | 1 |
| 1670 | extremos | 1 |
| 1671 | extraordinarias | 1 |
| 1672 | extiende | 1 |
| 1673 | expuso | 1 |
| 1674 | expuesta | 1 |
| 1675 | exprimir | 1 |
| 1676 | exprimido | 1 |
| 1677 | expriman | 1 |
| 1678 | expone | 1 |
| 1679 | expedido | 1 |
| 1680 | exhalada | 1 |
| 1681 | excedía | 1 |
| 1682 | excede | 1 |
| 1683 | exceda | 1 |
| 1684 | euterpe | 1 |
| 1685 | eurota | 1 |
| 1686 | europa | 1 |
| 1687 | euro | 1 |
| 1688 | etïopia | 1 |
| 1689 | estruendo | 1 |
| 1690 | estremeciéndose | 1 |
| 1691 | estrecho | 1 |
| 1692 | estrechamente | 1 |
| 1693 | estrecha | 1 |
| 1694 | estragos | 1 |
| 1695 | éstos | 1 |
| 1696 | estos | 1 |
| 1697 | estómagos | 1 |
| 1698 | esto | 1 |
| 1699 | estilo | 1 |
| 1700 | estigias | 1 |
| 1701 | estéril | 1 |
| 1702 | estas | 1 |
| 1703 | estanques | 1 |
| 1704 | estanque | 1 |
| 1705 | estación | 1 |
| 1706 | estacada | 1 |
| 1707 | estaban | 1 |
| 1708 | esquiva | 1 |
| 1709 | esquilas | 1 |
| 1710 | espumoso | 1 |
| 1711 | espumosas | 1 |
| 1712 | espumosa | 1 |
| 1713 | espuela | 1 |
| 1714 | esposos | 1 |
| 1715 | espirante | 1 |
| 1716 | espinas | 1 |
| 1717 | espigas | 1 |
| 1718 | espigada | 1 |
| 1719 | espiga | 1 |
| 1720 | espesura | 1 |
| 1721 | esperanza | 1 |
| 1722 | espejos | 1 |
| 1723 | espaldas | 1 |
| 1724 | espacïoso | 1 |
| 1725 | espacioso | 1 |
| 1726 | espaciosas | 1 |
| 1727 | espacio | 1 |
| 1728 | esos | 1 |
| 1729 | esfinge | 1 |
| 1730 | esculturas | 1 |
| 1731 | escudo | 1 |
| 1732 | escucharan | 1 |
| 1733 | escucha | 1 |
| 1734 | esconder | 1 |
| 1735 | escollos | 1 |
| 1736 | escena | 1 |
| 1737 | escasa | 1 |
| 1738 | escarlata | 1 |
| 1739 | escamado | 1 |
| 1740 | escamada | 1 |
| 1741 | escala | 1 |
| 1742 | erraba | 1 |
| 1743 | erigió | 1 |
| 1744 | erige | 1 |
| 1745 | equinocios | 1 |
| 1746 | éolo | 1 |
| 1747 | entró | 1 |
| 1748 | entregados | 1 |
| 1749 | entregado | 1 |
| 1750 | entra | 1 |
| 1751 | entera | 1 |
| 1752 | entena | 1 |
| 1753 | enramada | 1 |
| 1754 | enjutas | 1 |
| 1755 | enjugó | 1 |
| 1756 | enjuga | 1 |
| 1757 | enjambre | 1 |
| 1758 | engendran | 1 |
| 1759 | engendradora | 1 |
| 1760 | engazando | 1 |
| 1761 | engaste | 1 |
| 1762 | engasta | 1 |
| 1763 | engarza | 1 |
| 1764 | enfrenar | 1 |
| 1765 | enfrenado | 1 |
| 1766 | enemigo | 1 |
| 1767 | encomendó | 1 |
| 1768 | encinas | 1 |
| 1769 | encarcelada | 1 |
| 1770 | émulos | 1 |
| 1771 | emular | 1 |
| 1772 | empuñe | 1 |
| 1773 | embravecido | 1 |
| 1774 | embiste | 1 |
| 1775 | embebido | 1 |
| 1776 | elevada | 1 |
| 1777 | elegante | 1 |
| 1778 | egito | 1 |
| 1779 | egipto | 1 |
| 1780 | efectos | 1 |
| 1781 | edificios | 1 |
| 1782 | edificio | 1 |
| 1783 | edades | 1 |
| 1784 | ecos | 1 |
| 1785 | eclíptico | 1 |
| 1786 | e | 1 |
| 1787 | duros | 1 |
| 1788 | durmió | 1 |
| 1789 | duque | 1 |
| 1790 | dudosos | 1 |
| 1791 | dudosa | 1 |
| 1792 | duda | 1 |
| 1793 | dorándole | 1 |
| 1794 | dorado | 1 |
| 1795 | dora | 1 |
| 1796 | doméstico | 1 |
| 1797 | dome | 1 |
| 1798 | domadas | 1 |
| 1799 | dolor | 1 |
| 1800 | doctrina | 1 |
| 1801 | doce | 1 |
| 1802 | doble | 1 |
| 1803 | doblaste | 1 |
| 1804 | dobladuras | 1 |
| 1805 | do | 1 |
| 1806 | divisa | 1 |
| 1807 | dividido | 1 |
| 1808 | disuelvan | 1 |
| 1809 | distinta | 1 |
| 1810 | distinguieron | 1 |
| 1811 | distantes | 1 |
| 1812 | dispensadora | 1 |
| 1813 | disolviendo | 1 |
| 1814 | disformes | 1 |
| 1815 | dirigidos | 1 |
| 1816 | dirías | 1 |
| 1817 | diosa | 1 |
| 1818 | dios | 1 |
| 1819 | diluvio | 1 |
| 1820 | diligente | 1 |
| 1821 | digna | 1 |
| 1822 | dieron | 1 |
| 1823 | diera | 1 |
| 1824 | dictó | 1 |
| 1825 | dichosa | 1 |
| 1826 | dice | 1 |
| 1827 | diáfanos | 1 |
| 1828 | dïáfano | 1 |
| 1829 | desvïada | 1 |
| 1830 | desvanece | 1 |
| 1831 | destina | 1 |
| 1832 | desterrado | 1 |
| 1833 | destemplado | 1 |
| 1834 | desta | 1 |
| 1835 | desposados | 1 |
| 1836 | desposada | 1 |
| 1837 | despliega | 1 |
| 1838 | despierto | 1 |
| 1839 | despidiendo | 1 |
| 1840 | despejan | 1 |
| 1841 | despedido | 1 |
| 1842 | despecho | 1 |
| 1843 | desparece | 1 |
| 1844 | desnudos | 1 |
| 1845 | desnudas | 1 |
| 1846 | desmintieron | 1 |
| 1847 | desmentido | 1 |
| 1848 | desigual | 1 |
| 1849 | designios | 1 |
| 1850 | desfloren | 1 |
| 1851 | desengaños | 1 |
| 1852 | desdorados | 1 |
| 1853 | desdeñosa | 1 |
| 1854 | desdeñas | 1 |
| 1855 | desdeñar | 1 |
| 1856 | desdeñado | 1 |
| 1857 | desdeña | 1 |
| 1858 | desde | 1 |
| 1859 | describo | 1 |
| 1860 | desciende | 1 |
| 1861 | descendientes | 1 |
| 1862 | descanso | 1 |
| 1863 | desaten | 1 |
| 1864 | desatando | 1 |
| 1865 | desatados | 1 |
| 1866 | desatado | 1 |
| 1867 | desarmado | 1 |
| 1868 | desafío | 1 |
| 1869 | desafía | 1 |
| 1870 | derribarse | 1 |
| 1871 | derribados | 1 |
| 1872 | deponiendo | 1 |
| 1873 | denso | 1 |
| 1874 | den | 1 |
| 1875 | dellos | 1 |
| 1876 | delicioso | 1 |
| 1877 | delfín | 1 |
| 1878 | deje | 1 |
| 1879 | déjate | 1 |
| 1880 | defendidos | 1 |
| 1881 | dedos | 1 |
| 1882 | declina | 1 |
| 1883 | decidiera | 1 |
| 1884 | debido | 1 |
| 1885 | debajo | 1 |
| 1886 | deba | 1 |
| 1887 | dé | 1 |
| 1888 | dardo | 1 |
| 1889 | dar | 1 |
| 1890 | daños | 1 |
| 1891 | danza | 1 |
| 1892 | dando | 1 |
| 1893 | damascó | 1 |
| 1894 | cuyos | 1 |
| 1895 | curioso | 1 |
| 1896 | cupido | 1 |
| 1897 | cuidado | 1 |
| 1898 | cuesta | 1 |
| 1899 | cuerdas | 1 |
| 1900 | cuerda | 1 |
| 1901 | cuenta | 1 |
| 1902 | cuellos | 1 |
| 1903 | cuchillos | 1 |
| 1904 | cuchara | 1 |
| 1905 | cubrió | 1 |
| 1906 | cubren | 1 |
| 1907 | cubran | 1 |
| 1908 | cuanta | 1 |
| 1909 | cuajada | 1 |
| 1910 | cuadrado | 1 |
| 1911 | cruza | 1 |
| 1912 | cruja | 1 |
| 1913 | crestadas | 1 |
| 1914 | crespo | 1 |
| 1915 | crespas | 1 |
| 1916 | creo | 1 |
| 1917 | creciendo | 1 |
| 1918 | crece | 1 |
| 1919 | coyunda | 1 |
| 1920 | coturno | 1 |
| 1921 | coscoja | 1 |
| 1922 | corvos | 1 |
| 1923 | cortinas | 1 |
| 1924 | corteza | 1 |
| 1925 | cortésmente | 1 |
| 1926 | cortesía | 1 |
| 1927 | cortesano | 1 |
| 1928 | corta | 1 |
| 1929 | correspondido | 1 |
| 1930 | corre | 1 |
| 1931 | corpulento | 1 |
| 1932 | coronó | 1 |
| 1933 | coronen | 1 |
| 1934 | coronan | 1 |
| 1935 | coronaban | 1 |
| 1936 | corderos | 1 |
| 1937 | corderillos | 1 |
| 1938 | corcillo | 1 |
| 1939 | copadas | 1 |
| 1940 | copa | 1 |
| 1941 | conyugal | 1 |
| 1942 | convecino | 1 |
| 1943 | contra | 1 |
| 1944 | contento | 1 |
| 1945 | contenía | 1 |
| 1946 | contar | 1 |
| 1947 | construye | 1 |
| 1948 | consolalle | 1 |
| 1949 | consignados | 1 |
| 1950 | consiente | 1 |
| 1951 | consejo | 1 |
| 1952 | consagrando | 1 |
| 1953 | conmigo | 1 |
| 1954 | conjuración | 1 |
| 1955 | confusamente | 1 |
| 1956 | confusa | 1 |
| 1957 | confunden | 1 |
| 1958 | confunde | 1 |
| 1959 | conejuelo | 1 |
| 1960 | conduzgan | 1 |
| 1961 | condujo | 1 |
| 1962 | conducir | 1 |
| 1963 | conducidos | 1 |
| 1964 | conducidores | 1 |
| 1965 | conducida | 1 |
| 1966 | conduce | 1 |
| 1967 | condolido | 1 |
| 1968 | condenó | 1 |
| 1969 | condena | 1 |
| 1970 | concurría | 1 |
| 1971 | concurren | 1 |
| 1972 | conculcado | 1 |
| 1973 | concordia | 1 |
| 1974 | concocelle | 1 |
| 1975 | conchas | 1 |
| 1976 | concede | 1 |
| 1977 | compulsen | 1 |
| 1978 | competidoras | 1 |
| 1979 | competentes | 1 |
| 1980 | como | 1 |
| 1981 | comida | 1 |
| 1982 | cometas | 1 |
| 1983 | comenzaran | 1 |
| 1984 | comenzando | 1 |
| 1985 | comarcanos | 1 |
| 1986 | coluna | 1 |
| 1987 | columnas | 1 |
| 1988 | colorido | 1 |
| 1989 | colores | 1 |
| 1990 | coliseo | 1 |
| 1991 | cola | 1 |
| 1992 | cojea | 1 |
| 1993 | codornices | 1 |
| 1994 | coche | 1 |
| 1995 | coces | 1 |
| 1996 | cloto | 1 |
| 1997 | clima | 1 |
| 1998 | clicie | 1 |
| 1999 | clavo | 1 |
| 2000 | clavijas | 1 |
| 2001 | claveles | 1 |
| 2002 | clavel | 1 |
| 2003 | clava | 1 |
| 2004 | clara | 1 |
| 2005 | civil | 1 |
| 2006 | ciudades | 1 |
| 2007 | cítaras | 1 |
| 2008 | cisuras | 1 |
| 2009 | cisnes | 1 |
| 2010 | círculo | 1 |
| 2011 | cifre | 1 |
| 2012 | cierzos | 1 |
| 2013 | cierzo | 1 |
| 2014 | cierva | 1 |
| 2015 | cierra | 1 |
| 2016 | cielos | 1 |
| 2017 | ciega | 1 |
| 2018 | chupar | 1 |
| 2019 | chopos | 1 |
| 2020 | césped | 1 |
| 2021 | cerviz | 1 |
| 2022 | cervices | 1 |
| 2023 | cerúleas | 1 |
| 2024 | cerros | 1 |
| 2025 | ceremonia | 1 |
| 2026 | cercanas | 1 |
| 2027 | cercado | 1 |
| 2028 | ceño | 1 |
| 2029 | centellas | 1 |
| 2030 | ceniza | 1 |
| 2031 | cenefa | 1 |
| 2032 | celosas | 1 |
| 2033 | celosa | 1 |
| 2034 | celdas | 1 |
| 2035 | celaje | 1 |
| 2036 | cejas | 1 |
| 2037 | cedió | 1 |
| 2038 | cecina | 1 |
| 2039 | cayado | 1 |
| 2040 | cautelas | 1 |
| 2041 | catón | 1 |
| 2042 | casero | 1 |
| 2043 | casando | 1 |
| 2044 | casa | 1 |
| 2045 | caribes | 1 |
| 2046 | carga | 1 |
| 2047 | cardada | 1 |
| 2048 | carcajes | 1 |
| 2049 | carbunclo | 1 |
| 2050 | caracteres | 1 |
| 2051 | capilla | 1 |
| 2052 | capa | 1 |
| 2053 | caña | 1 |
| 2054 | cantuesos | 1 |
| 2055 | canto | 1 |
| 2056 | cansancio | 1 |
| 2057 | cansada | 1 |
| 2058 | cándidas | 1 |
| 2059 | candados | 1 |
| 2060 | cana | 1 |
| 2061 | caminos | 1 |
| 2062 | calzadas | 1 |
| 2063 | calor | 1 |
| 2064 | caló | 1 |
| 2065 | calmas | 1 |
| 2066 | calles | 1 |
| 2067 | calle | 1 |
| 2068 | callando | 1 |
| 2069 | calientes | 1 |
| 2070 | calidad | 1 |
| 2071 | calarse | 1 |
| 2072 | cajas | 1 |
| 2073 | cairela | 1 |
| 2074 | caducar | 1 |
| 2075 | cadenas | 1 |
| 2076 | cadena | 1 |
| 2077 | cabritos | 1 |
| 2078 | cabaña | 1 |
| 2079 | buscó | 1 |
| 2080 | buscaba | 1 |
| 2081 | burlado | 1 |
| 2082 | burla | 1 |
| 2083 | buitres | 1 |
| 2084 | buitre | 1 |
| 2085 | buena | 1 |
| 2086 | bruñida | 1 |
| 2087 | brújula | 1 |
| 2088 | brote | 1 |
| 2089 | brocado | 1 |
| 2090 | brillante | 1 |
| 2091 | brilla | 1 |
| 2092 | brazos | 1 |
| 2093 | brame | 1 |
| 2094 | bóvedas | 1 |
| 2095 | botón | 1 |
| 2096 | bosquejó | 1 |
| 2097 | borró | 1 |
| 2098 | boj | 1 |
| 2099 | blanqueando | 1 |
| 2100 | blandas | 1 |
| 2101 | bisagra | 1 |
| 2102 | bipartida | 1 |
| 2103 | bese | 1 |
| 2104 | besaste | 1 |
| 2105 | besando | 1 |
| 2106 | besaba | 1 |
| 2107 | berberiscos | 1 |
| 2108 | bengala | 1 |
| 2109 | belleza | 1 |
| 2110 | beldad | 1 |
| 2111 | bebido | 1 |
| 2112 | beberse | 1 |
| 2113 | beber | 1 |
| 2114 | batía | 1 |
| 2115 | bates | 1 |
| 2116 | baten | 1 |
| 2117 | batallas | 1 |
| 2118 | bastó | 1 |
| 2119 | basas | 1 |
| 2120 | basa | 1 |
| 2121 | bárbaras | 1 |
| 2122 | barbado | 1 |
| 2123 | barba | 1 |
| 2124 | ballenas | 1 |
| 2125 | bajaba | 1 |
| 2126 | bachillera | 1 |
| 2127 | bacantes | 1 |
| 2128 | bacanal | 1 |
| 2129 | azules | 1 |
| 2130 | azul | 1 |
| 2131 | azucena | 1 |
| 2132 | azahares | 1 |
| 2133 | azada | 1 |
| 2134 | ayuno | 1 |
| 2135 | austros | 1 |
| 2136 | ausente | 1 |
| 2137 | atribuye | 1 |
| 2138 | atrevimiento | 1 |
| 2139 | atravesado | 1 |
| 2140 | atractiva | 1 |
| 2141 | atento | 1 |
| 2142 | atalayas | 1 |
| 2143 | atalanta | 1 |
| 2144 | atajo | 1 |
| 2145 | astros | 1 |
| 2146 | astronómicos | 1 |
| 2147 | asta | 1 |
| 2148 | áspid | 1 |
| 2149 | asombro | 1 |
| 2150 | así | 1 |
| 2151 | ascálafo | 1 |
| 2152 | artificiosamente | 1 |
| 2153 | artificio | 1 |
| 2154 | artífice | 1 |
| 2155 | arte | 1 |
| 2156 | arrogancia | 1 |
| 2157 | arrogan | 1 |
| 2158 | arrima | 1 |
| 2159 | arreboles | 1 |
| 2160 | arrebatamiento | 1 |
| 2161 | arrebatado | 1 |
| 2162 | arrebata | 1 |
| 2163 | arras | 1 |
| 2164 | arraigados | 1 |
| 2165 | arraiga | 1 |
| 2166 | arquear | 1 |
| 2167 | aromática | 1 |
| 2168 | aromas | 1 |
| 2169 | aroma | 1 |
| 2170 | armó | 1 |
| 2171 | armaron | 1 |
| 2172 | armados | 1 |
| 2173 | armado | 1 |
| 2174 | arïón | 1 |
| 2175 | argentados | 1 |
| 2176 | argenta | 1 |
| 2177 | arcaduz | 1 |
| 2178 | arador | 1 |
| 2179 | arado | 1 |
| 2180 | aracnes | 1 |
| 2181 | aquí | 1 |
| 2182 | aquéllos | 1 |
| 2183 | aquéllas | 1 |
| 2184 | aquellas | 1 |
| 2185 | aprisiona | 1 |
| 2186 | apresura | 1 |
| 2187 | apremïado | 1 |
| 2188 | apolo | 1 |
| 2189 | apócrifa | 1 |
| 2190 | aplausos | 1 |
| 2191 | añudando | 1 |
| 2192 | año | 1 |
| 2193 | anunciando | 1 |
| 2194 | anudado | 1 |
| 2195 | antípodas | 1 |
| 2196 | antigua | 1 |
| 2197 | anticipa | 1 |
| 2198 | antárticas | 1 |
| 2199 | anocheció | 1 |
| 2200 | anhelando | 1 |
| 2201 | anegó | 1 |
| 2202 | anciano | 1 |
| 2203 | amorosos | 1 |
| 2204 | amores | 1 |
| 2205 | amó | 1 |
| 2206 | amigo | 1 |
| 2207 | amigas | 1 |
| 2208 | ameno | 1 |
| 2209 | amazonas | 1 |
| 2210 | amanezca | 1 |
| 2211 | amaltea | 1 |
| 2212 | amada | 1 |
| 2213 | alto | 1 |
| 2214 | alterno | 1 |
| 2215 | alternando | 1 |
| 2216 | alterna | 1 |
| 2217 | altera | 1 |
| 2218 | alquería | 1 |
| 2219 | aljófar | 1 |
| 2220 | aljaba | 1 |
| 2221 | alistar | 1 |
| 2222 | alisos | 1 |
| 2223 | aliso | 1 |
| 2224 | alimenten | 1 |
| 2225 | algún | 1 |
| 2226 | alga | 1 |
| 2227 | alfombras | 1 |
| 2228 | alegres | 1 |
| 2229 | alegre | 1 |
| 2230 | aldeas | 1 |
| 2231 | aldabas | 1 |
| 2232 | alcimedón | 1 |
| 2233 | alcanzan | 1 |
| 2234 | albogues | 1 |
| 2235 | albergues | 1 |
| 2236 | álamo | 1 |
| 2237 | alameda | 1 |
| 2238 | aladas | 1 |
| 2239 | alada | 1 |
| 2240 | ala | 1 |
| 2241 | ajustando | 1 |
| 2242 | airoso | 1 |
| 2243 | aires | 1 |
| 2244 | aguja | 1 |
| 2245 | aguarda | 1 |
| 2246 | agravado | 1 |
| 2247 | agradecidas | 1 |
| 2248 | agradecida | 1 |
| 2249 | agilidad | 1 |
| 2250 | afrenta | 1 |
| 2251 | afable | 1 |
| 2252 | advocaron | 1 |
| 2253 | adulación | 1 |
| 2254 | adorno | 1 |
| 2255 | adonde | 1 |
| 2256 | adolescente | 1 |
| 2257 | admitir | 1 |
| 2258 | admire | 1 |
| 2259 | admirando | 1 |
| 2260 | admirado | 1 |
| 2261 | admira | 1 |
| 2262 | acusando | 1 |
| 2263 | acusa | 1 |
| 2264 | acteón | 1 |
| 2265 | acompañado | 1 |
| 2266 | acertado | 1 |
| 2267 | acerados | 1 |
| 2268 | acequia | 1 |
| 2269 | acelerado | 1 |
| 2270 | acanto | 1 |
| 2271 | absolvello | 1 |
| 2272 | abriles | 1 |
| 2273 | abril | 1 |
| 2274 | abrevïara | 1 |
| 2275 | abrevia | 1 |
| 2276 | abre | 1 |
| 2277 | abrazó | 1 |
| 2278 | abrazáronse | 1 |
| 2279 | abrazaron | 1 |
| 2280 | abrazados | 1 |
| 2281 | abrazadora | 1 |
| 2282 | abortaron | 1 |
| 2283 | abetos | 1 |
| 2284 | abeto | 1 |
| 2285 | abejas | 1 |
|
Ilustración del principio de mínimo esfuerzo: |
|
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará el texto actual (Soledades 1 de Luis de Góngora) (conjunto 1)
contra el resto de textos en el mismo idioma (Castellano) (conjunto 2).
A continuación se muestra una lista de las palabras presentes en el texto actual,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
Mostrar todo
Recoger