Análisis de Las firmezas de Isabela de Luis de Góngora
Índice
Información General
| Título: | Las firmezas de Isabela |
|---|
| Autor: | Luis de Góngora |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 5334 |
|---|
| #Palabras distintas: | 1733 |
|---|
| Type-Token ratio: | 32.49% |
|---|
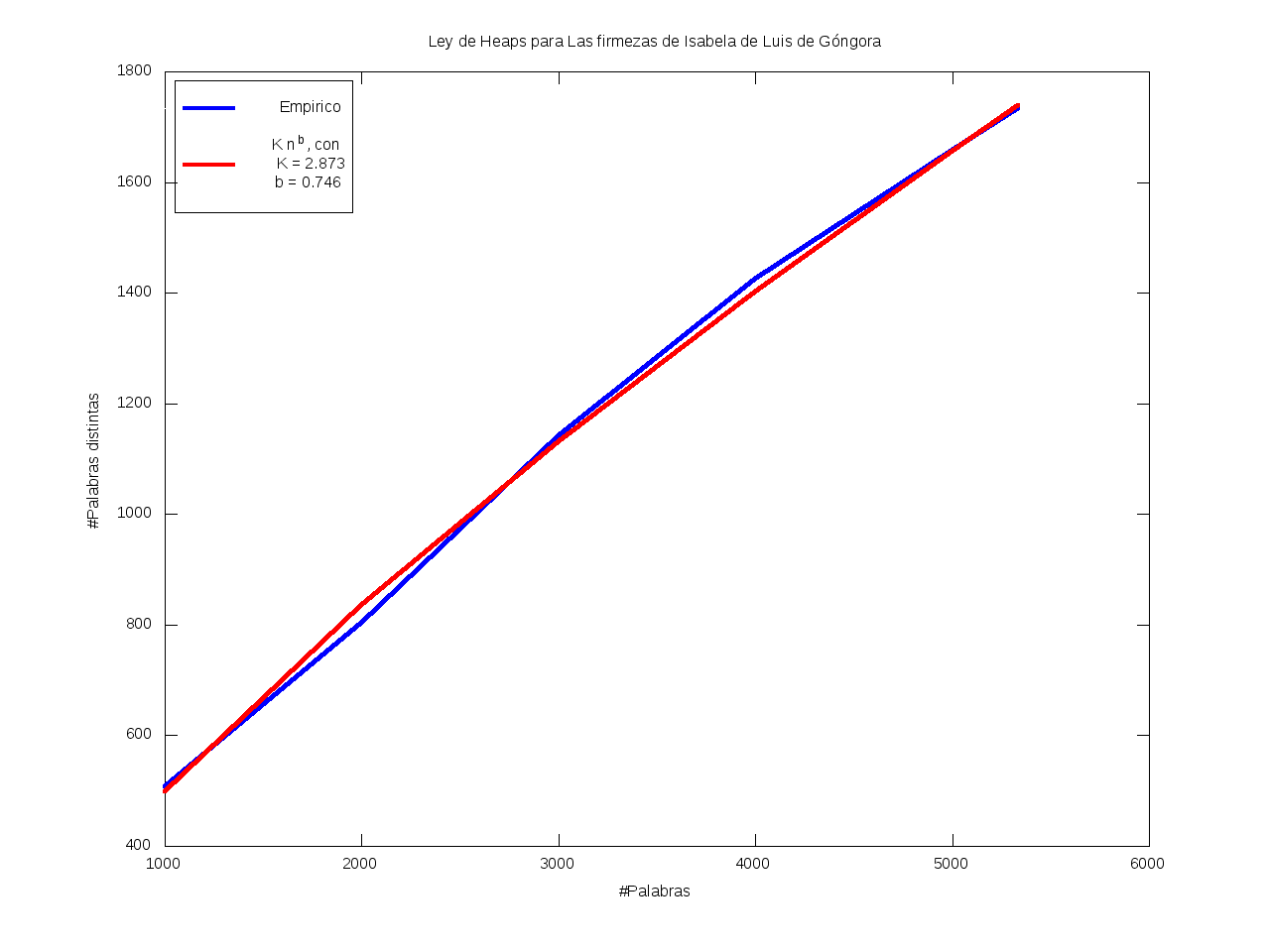
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| #Palabras: | #Palabras distintas: |
|---|
| 1000 | 507 |
| 2000 | 804 |
| 3000 | 1142 |
| 4000 | 1425 |
| 5000 | 1658 |
| 5334 | 1733 |
|
Ajuste por mínimos cuadrados de los datos a K*n^b:
|
| K = 2.873 |
|
b = 0.746 |
|
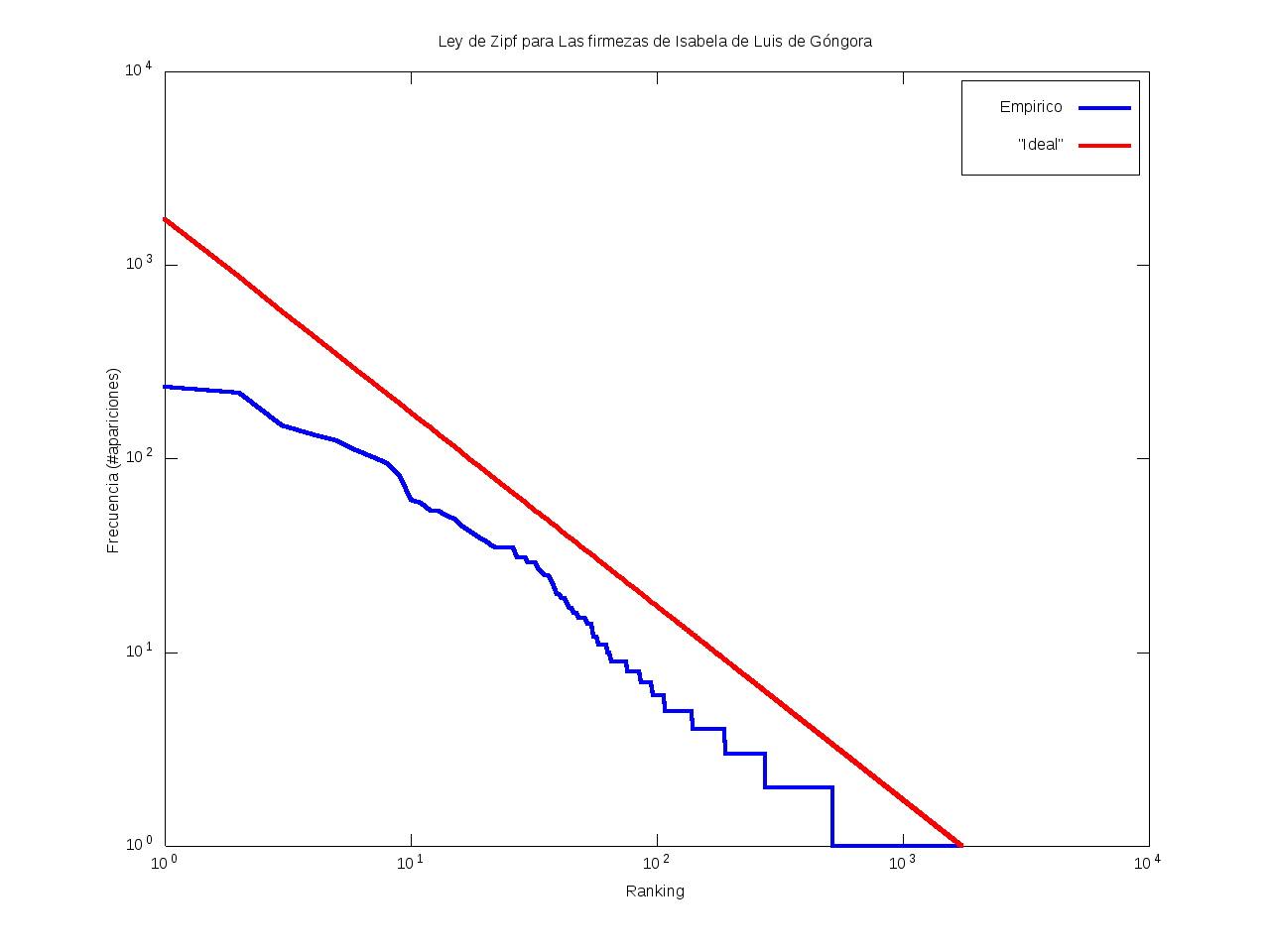
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Rank | Palabra | Frec |
|---|
| 1 | de | 234 |
| 2 | que | 219 |
| 3 | y | 149 |
| 4 | a | 133 |
| 5 | la | 124 |
| 6 | en | 111 |
| 7 | el | 102 |
| 8 | no | 95 |
| 9 | tadeo | 81 |
| 10 | es | 61 |
| 11 | con | 59 |
| 12 | los | 54 |
| 13 | fabio | 54 |
| 14 | camilo | 51 |
| 15 | al | 49 |
| 16 | más | 45 |
| 17 | las | 43 |
| 18 | su | 41 |
| 19 | lo | 39 |
| 20 | se | 38 |
| 21 | mi | 36 |
| 22 | un | 35 |
| 23 | si | 35 |
| 24 | por | 35 |
| 25 | marcelo | 35 |
| 26 | del | 35 |
| 27 | yo | 31 |
| 28 | me | 31 |
| 29 | le | 31 |
| 30 | tu | 29 |
| 31 | sus | 29 |
| 32 | aparte | 29 |
| 33 | qué | 27 |
| 34 | para | 26 |
| 35 | violante | 25 |
| 36 | tan | 25 |
| 37 | ya | 24 |
| 38 | o | 22 |
| 39 | porque | 20 |
| 40 | bien | 20 |
| 41 | pues | 19 |
| 42 | dos | 19 |
| 43 | como | 18 |
| 44 | una | 17 |
| 45 | octavio | 17 |
| 46 | te | 16 |
| 47 | oh | 16 |
| 48 | son | 15 |
| 49 | muy | 15 |
| 50 | este | 15 |
| 51 | él | 15 |
| 52 | tiene | 14 |
| 53 | quien | 14 |
| 54 | ha | 14 |
| 55 | lelio | 12 |
| 56 | hoy | 12 |
| 57 | casa | 12 |
| 58 | mí | 11 |
| 59 | mas | 11 |
| 60 | he | 11 |
| 61 | esta | 11 |
| 62 | amor | 11 |
| 63 | otro | 10 |
| 64 | fe | 10 |
| 65 | tus | 9 |
| 66 | secreto | 9 |
| 67 | quiero | 9 |
| 68 | os | 9 |
| 69 | mal | 9 |
| 70 | isabela | 9 |
| 71 | hacer | 9 |
| 72 | ella | 9 |
| 73 | donde | 9 |
| 74 | dios | 9 |
| 75 | ahora | 9 |
| 76 | toledo | 8 |
| 77 | ti | 8 |
| 78 | ser | 8 |
| 79 | saber | 8 |
| 80 | ni | 8 |
| 81 | hijo | 8 |
| 82 | has | 8 |
| 83 | gran | 8 |
| 84 | entre | 8 |
| 85 | años | 8 |
| 86 | viejo | 7 |
| 87 | señor | 7 |
| 88 | padre | 7 |
| 89 | nombre | 7 |
| 90 | hay | 7 |
| 91 | está | 7 |
| 92 | día | 7 |
| 93 | cielo | 7 |
| 94 | aunque | 7 |
| 95 | amigo | 7 |
| 96 | tanto | 6 |
| 97 | sin | 6 |
| 98 | quiere | 6 |
| 99 | mis | 6 |
| 100 | mercader | 6 |
| 101 | mejor | 6 |
| 102 | huésped | 6 |
| 103 | gente | 6 |
| 104 | galeazo | 6 |
| 105 | experiencia | 6 |
| 106 | esto | 6 |
| 107 | digo | 6 |
| 108 | voy | 5 |
| 109 | verdad | 5 |
| 110 | va | 5 |
| 111 | tú | 5 |
| 112 | todo | 5 |
| 113 | tajo | 5 |
| 114 | sólo | 5 |
| 115 | sino | 5 |
| 116 | siempre | 5 |
| 117 | plumas | 5 |
| 118 | pie | 5 |
| 119 | oro | 5 |
| 120 | ojos | 5 |
| 121 | mío | 5 |
| 122 | hermana | 5 |
| 123 | hablar | 5 |
| 124 | fuera | 5 |
| 125 | fue | 5 |
| 126 | fin | 5 |
| 127 | estoy | 5 |
| 128 | emilio | 5 |
| 129 | dices | 5 |
| 130 | días | 5 |
| 131 | di | 5 |
| 132 | después | 5 |
| 133 | cuanto | 5 |
| 134 | cuando | 5 |
| 135 | criado | 5 |
| 136 | cosas | 5 |
| 137 | cosa | 5 |
| 138 | callar | 5 |
| 139 | aun | 5 |
| 140 | viento | 4 |
| 141 | vi | 4 |
| 142 | ver | 4 |
| 143 | vase | 4 |
| 144 | tras | 4 |
| 145 | tal | 4 |
| 146 | sol | 4 |
| 147 | sí | 4 |
| 148 | señora | 4 |
| 149 | sea | 4 |
| 150 | sé | 4 |
| 151 | rico | 4 |
| 152 | quién | 4 |
| 153 | puedo | 4 |
| 154 | plata | 4 |
| 155 | pero | 4 |
| 156 | peor | 4 |
| 157 | otra | 4 |
| 158 | nos | 4 |
| 159 | noble | 4 |
| 160 | muchos | 4 |
| 161 | mozo | 4 |
| 162 | mil | 4 |
| 163 | mayor | 4 |
| 164 | mano | 4 |
| 165 | luego | 4 |
| 166 | lengua | 4 |
| 167 | hombre | 4 |
| 168 | fuego | 4 |
| 169 | eso | 4 |
| 170 | entra | 4 |
| 171 | dulce | 4 |
| 172 | dar | 4 |
| 173 | da | 4 |
| 174 | corte | 4 |
| 175 | contra | 4 |
| 176 | consejo | 4 |
| 177 | conmigo | 4 |
| 178 | celo | 4 |
| 179 | causa | 4 |
| 180 | cajero | 4 |
| 181 | boca | 4 |
| 182 | así | 4 |
| 183 | antes | 4 |
| 184 | amo | 4 |
| 185 | amistad | 4 |
| 186 | alma | 4 |
| 187 | alas | 4 |
| 188 | agravio | 4 |
| 189 | zaguán | 3 |
| 190 | vuélvese | 3 |
| 191 | venido | 3 |
| 192 | ve | 3 |
| 193 | vano | 3 |
| 194 | uso | 3 |
| 195 | trato | 3 |
| 196 | todas | 3 |
| 197 | tiempo | 3 |
| 198 | tengo | 3 |
| 199 | tener | 3 |
| 200 | templo | 3 |
| 201 | singularidades | 3 |
| 202 | sevilla | 3 |
| 203 | será | 3 |
| 204 | santa | 3 |
| 205 | salud | 3 |
| 206 | riquezas | 3 |
| 207 | rayos | 3 |
| 208 | primero | 3 |
| 209 | persona | 3 |
| 210 | perdona | 3 |
| 211 | patriota | 3 |
| 212 | pasa | 3 |
| 213 | palma | 3 |
| 214 | nunca | 3 |
| 215 | nada | 3 |
| 216 | mujer | 3 |
| 217 | muerte | 3 |
| 218 | monte | 3 |
| 219 | mía | 3 |
| 220 | menos | 3 |
| 221 | manos | 3 |
| 222 | mancebo | 3 |
| 223 | malicia | 3 |
| 224 | mala | 3 |
| 225 | luces | 3 |
| 226 | llama | 3 |
| 227 | licencia | 3 |
| 228 | les | 3 |
| 229 | iglesia | 3 |
| 230 | honra | 3 |
| 231 | hoja | 3 |
| 232 | hizo | 3 |
| 233 | hija | 3 |
| 234 | hermano | 3 |
| 235 | hecho | 3 |
| 236 | harto | 3 |
| 237 | haré | 3 |
| 238 | gusto | 3 |
| 239 | granada | 3 |
| 240 | gracias | 3 |
| 241 | fïel | 3 |
| 242 | experiencias | 3 |
| 243 | examina | 3 |
| 244 | estilo | 3 |
| 245 | estas | 3 |
| 246 | esquina | 3 |
| 247 | escondido | 3 |
| 248 | enseña | 3 |
| 249 | ello | 3 |
| 250 | ducados | 3 |
| 251 | dónde | 3 |
| 252 | dicho | 3 |
| 253 | dice | 3 |
| 254 | deseo | 3 |
| 255 | desengaño | 3 |
| 256 | dejo | 3 |
| 257 | deja | 3 |
| 258 | decir | 3 |
| 259 | daño | 3 |
| 260 | damas | 3 |
| 261 | cuyo | 3 |
| 262 | cuyas | 3 |
| 263 | cual | 3 |
| 264 | cruel | 3 |
| 265 | cristal | 3 |
| 266 | condición | 3 |
| 267 | campo | 3 |
| 268 | camino | 3 |
| 269 | buena | 3 |
| 270 | blancas | 3 |
| 271 | bella | 3 |
| 272 | amores | 3 |
| 273 | ama | 3 |
| 274 | acá | 3 |
| 275 | yerro | 2 |
| 276 | vuela | 2 |
| 277 | voyme | 2 |
| 278 | vos | 2 |
| 279 | voces | 2 |
| 280 | violín | 2 |
| 281 | vihuela | 2 |
| 282 | viene | 2 |
| 283 | vida | 2 |
| 284 | vez | 2 |
| 285 | vete | 2 |
| 286 | venir | 2 |
| 287 | venga | 2 |
| 288 | vecina | 2 |
| 289 | veces | 2 |
| 290 | vacas | 2 |
| 291 | vaca | 2 |
| 292 | uno | 2 |
| 293 | único | 2 |
| 294 | tres | 2 |
| 295 | treinta | 2 |
| 296 | traidor | 2 |
| 297 | torpes | 2 |
| 298 | todos | 2 |
| 299 | toda | 2 |
| 300 | tocas | 2 |
| 301 | tienda | 2 |
| 302 | tejía | 2 |
| 303 | tejado | 2 |
| 304 | tanta | 2 |
| 305 | tales | 2 |
| 306 | suyo | 2 |
| 307 | sujeto | 2 |
| 308 | sufrir | 2 |
| 309 | sufre | 2 |
| 310 | suele | 2 |
| 311 | sospecha | 2 |
| 312 | solo | 2 |
| 313 | solicita | 2 |
| 314 | sobre | 2 |
| 315 | sobra | 2 |
| 316 | sirve | 2 |
| 317 | sido | 2 |
| 318 | servirte | 2 |
| 319 | sepa | 2 |
| 320 | salimos | 2 |
| 321 | sabe | 2 |
| 322 | ruin | 2 |
| 323 | rompen | 2 |
| 324 | reyes | 2 |
| 325 | retórica | 2 |
| 326 | regalo | 2 |
| 327 | reales | 2 |
| 328 | real | 2 |
| 329 | rato | 2 |
| 330 | rabiar | 2 |
| 331 | punto | 2 |
| 332 | puertas | 2 |
| 333 | puente | 2 |
| 334 | pueblo | 2 |
| 335 | propia | 2 |
| 336 | prolijo | 2 |
| 337 | pretendida | 2 |
| 338 | policena | 2 |
| 339 | podías | 2 |
| 340 | pocos | 2 |
| 341 | poca | 2 |
| 342 | pobre | 2 |
| 343 | pluma | 2 |
| 344 | pisa | 2 |
| 345 | pies | 2 |
| 346 | pido | 2 |
| 347 | pidió | 2 |
| 348 | pesquisidor | 2 |
| 349 | perdida | 2 |
| 350 | penas | 2 |
| 351 | pelota | 2 |
| 352 | peligrosas | 2 |
| 353 | pecho | 2 |
| 354 | partí | 2 |
| 355 | paredes | 2 |
| 356 | paces | 2 |
| 357 | otros | 2 |
| 358 | oreja | 2 |
| 359 | ocasiones | 2 |
| 360 | nuevo | 2 |
| 361 | noruega | 2 |
| 362 | norte | 2 |
| 363 | nieve | 2 |
| 364 | niega | 2 |
| 365 | nacido | 2 |
| 366 | mucho | 2 |
| 367 | moro | 2 |
| 368 | morder | 2 |
| 369 | mohína | 2 |
| 370 | mitad | 2 |
| 371 | misa | 2 |
| 372 | miente | 2 |
| 373 | mías | 2 |
| 374 | memorias | 2 |
| 375 | memoria | 2 |
| 376 | malo | 2 |
| 377 | malicias | 2 |
| 378 | madre | 2 |
| 379 | lugar | 2 |
| 380 | loco | 2 |
| 381 | llevas | 2 |
| 382 | lleva | 2 |
| 383 | llamo | 2 |
| 384 | llamas | 2 |
| 385 | llamarme | 2 |
| 386 | llamar | 2 |
| 387 | livia | 2 |
| 388 | libia | 2 |
| 389 | juntos | 2 |
| 390 | intención | 2 |
| 391 | importa | 2 |
| 392 | igual | 2 |
| 393 | hospedaje | 2 |
| 394 | hora | 2 |
| 395 | honrado | 2 |
| 396 | honor | 2 |
| 397 | hombres | 2 |
| 398 | hojas | 2 |
| 399 | historia | 2 |
| 400 | hermosura | 2 |
| 401 | hermanos | 2 |
| 402 | hércules | 2 |
| 403 | hará | 2 |
| 404 | halla | 2 |
| 405 | haga | 2 |
| 406 | haciendo | 2 |
| 407 | hablan | 2 |
| 408 | había | 2 |
| 409 | grillos | 2 |
| 410 | griego | 2 |
| 411 | graves | 2 |
| 412 | grandezas | 2 |
| 413 | grande | 2 |
| 414 | gloria | 2 |
| 415 | fuerzas | 2 |
| 416 | fuerza | 2 |
| 417 | fuerte | 2 |
| 418 | fueran | 2 |
| 419 | flores | 2 |
| 420 | flamenco | 2 |
| 421 | finos | 2 |
| 422 | finezas | 2 |
| 423 | fénix | 2 |
| 424 | favores | 2 |
| 425 | extranjeros | 2 |
| 426 | experimentar | 2 |
| 427 | estrellas | 2 |
| 428 | estás | 2 |
| 429 | estaba | 2 |
| 430 | espuela | 2 |
| 431 | españa | 2 |
| 432 | escudero | 2 |
| 433 | escariote | 2 |
| 434 | esas | 2 |
| 435 | esa | 2 |
| 436 | era | 2 |
| 437 | entrara | 2 |
| 438 | entraos | 2 |
| 439 | ellos | 2 |
| 440 | efecto | 2 |
| 441 | dueña | 2 |
| 442 | duda | 2 |
| 443 | doy | 2 |
| 444 | dote | 2 |
| 445 | dilo | 2 |
| 446 | diligencia | 2 |
| 447 | digas | 2 |
| 448 | diera | 2 |
| 449 | dicha | 2 |
| 450 | dicen | 2 |
| 451 | desvarío | 2 |
| 452 | desengaños | 2 |
| 453 | deseando | 2 |
| 454 | desdén | 2 |
| 455 | dejó | 2 |
| 456 | dejar | 2 |
| 457 | decoro | 2 |
| 458 | decillo | 2 |
| 459 | debo | 2 |
| 460 | debe | 2 |
| 461 | dará | 2 |
| 462 | dando | 2 |
| 463 | dado | 2 |
| 464 | cuyos | 2 |
| 465 | culpas | 2 |
| 466 | cuerdas | 2 |
| 467 | cuenta | 2 |
| 468 | cuál | 2 |
| 469 | creo | 2 |
| 470 | corre | 2 |
| 471 | corona | 2 |
| 472 | corazón | 2 |
| 473 | contado | 2 |
| 474 | conoce | 2 |
| 475 | confío | 2 |
| 476 | cómo | 2 |
| 477 | clava | 2 |
| 478 | ciudad | 2 |
| 479 | cintia | 2 |
| 480 | cierta | 2 |
| 481 | cien | 2 |
| 482 | ciego | 2 |
| 483 | cerro | 2 |
| 484 | cebarse | 2 |
| 485 | caudal | 2 |
| 486 | casamentero | 2 |
| 487 | cartas | 2 |
| 488 | candil | 2 |
| 489 | canales | 2 |
| 490 | camina | 2 |
| 491 | calle | 2 |
| 492 | cadenas | 2 |
| 493 | caballo | 2 |
| 494 | buscar | 2 |
| 495 | bronce | 2 |
| 496 | breves | 2 |
| 497 | breve | 2 |
| 498 | beldad | 2 |
| 499 | basta | 2 |
| 500 | ay | 2 |
| 501 | aún | 2 |
| 502 | astrólogo | 2 |
| 503 | arte | 2 |
| 504 | armas | 2 |
| 505 | aquí | 2 |
| 506 | aqueste | 2 |
| 507 | aquel | 2 |
| 508 | anotomía | 2 |
| 509 | andas | 2 |
| 510 | anda | 2 |
| 511 | amiga | 2 |
| 512 | alguna | 2 |
| 513 | alcalde | 2 |
| 514 | alcabala | 2 |
| 515 | aire | 2 |
| 516 | afición | 2 |
| 517 | adonde | 2 |
| 518 | zaragoza | 1 |
| 519 | vuestras | 1 |
| 520 | vuélvete | 1 |
| 521 | vuelven | 1 |
| 522 | vuelo | 1 |
| 523 | vuelas | 1 |
| 524 | vosotras | 1 |
| 525 | volverme | 1 |
| 526 | voluntad | 1 |
| 527 | vivo | 1 |
| 528 | vive | 1 |
| 529 | viva | 1 |
| 530 | vistió | 1 |
| 531 | visten | 1 |
| 532 | viste | 1 |
| 533 | virotes | 1 |
| 534 | violantes | 1 |
| 535 | violada | 1 |
| 536 | vio | 1 |
| 537 | vínose | 1 |
| 538 | vinos | 1 |
| 539 | vino | 1 |
| 540 | viniera | 1 |
| 541 | vincular | 1 |
| 542 | vimos | 1 |
| 543 | vil | 1 |
| 544 | vigilantes | 1 |
| 545 | viendo | 1 |
| 546 | viejos | 1 |
| 547 | vicio | 1 |
| 548 | vestir | 1 |
| 549 | vestido | 1 |
| 550 | versos | 1 |
| 551 | verso | 1 |
| 552 | vernos | 1 |
| 553 | verdura | 1 |
| 554 | verdugo | 1 |
| 555 | verde | 1 |
| 556 | verdadera | 1 |
| 557 | veras | 1 |
| 558 | veo | 1 |
| 559 | venus | 1 |
| 560 | venta | 1 |
| 561 | venirse | 1 |
| 562 | venida | 1 |
| 563 | venerable | 1 |
| 564 | venenos | 1 |
| 565 | vendimias | 1 |
| 566 | vende | 1 |
| 567 | vendado | 1 |
| 568 | venció | 1 |
| 569 | ven | 1 |
| 570 | veloces | 1 |
| 571 | velas | 1 |
| 572 | veis | 1 |
| 573 | veinte | 1 |
| 574 | ved | 1 |
| 575 | vecinos | 1 |
| 576 | vaya | 1 |
| 577 | vas | 1 |
| 578 | varia | 1 |
| 579 | varas | 1 |
| 580 | vara | 1 |
| 581 | vanse | 1 |
| 582 | valor | 1 |
| 583 | valenzuela | 1 |
| 584 | valentía | 1 |
| 585 | valen | 1 |
| 586 | valdrá | 1 |
| 587 | vais | 1 |
| 588 | vaina | 1 |
| 589 | vagando | 1 |
| 590 | usan | 1 |
| 591 | usa | 1 |
| 592 | urna | 1 |
| 593 | urganda | 1 |
| 594 | untándoles | 1 |
| 595 | ultraje | 1 |
| 596 | último | 1 |
| 597 | tuyo | 1 |
| 598 | tuvo | 1 |
| 599 | tuviera | 1 |
| 600 | turco | 1 |
| 601 | turbóse | 1 |
| 602 | troyano | 1 |
| 603 | troya | 1 |
| 604 | trompeta | 1 |
| 605 | trocó | 1 |
| 606 | trochas | 1 |
| 607 | trocha | 1 |
| 608 | trocara | 1 |
| 609 | trocar | 1 |
| 610 | trocalle | 1 |
| 611 | trïones | 1 |
| 612 | tributaban | 1 |
| 613 | tribunal | 1 |
| 614 | triaca | 1 |
| 615 | traza | 1 |
| 616 | tratos | 1 |
| 617 | tratando | 1 |
| 618 | tratamos | 1 |
| 619 | trata | 1 |
| 620 | traición | 1 |
| 621 | totalmente | 1 |
| 622 | torres | 1 |
| 623 | tormento | 1 |
| 624 | torció | 1 |
| 625 | topar | 1 |
| 626 | tomo | 1 |
| 627 | tomistas | 1 |
| 628 | toledano | 1 |
| 629 | tocaban | 1 |
| 630 | tizona | 1 |
| 631 | tirano | 1 |
| 632 | tiranía | 1 |
| 633 | tinta | 1 |
| 634 | tinieblas | 1 |
| 635 | tierra | 1 |
| 636 | tierno | 1 |
| 637 | tiento | 1 |
| 638 | tienen | 1 |
| 639 | tibia | 1 |
| 640 | testigo | 1 |
| 641 | testamento | 1 |
| 642 | ternísimamente | 1 |
| 643 | términos | 1 |
| 644 | tercio | 1 |
| 645 | tentarlo | 1 |
| 646 | tenido | 1 |
| 647 | tenía | 1 |
| 648 | tengáis | 1 |
| 649 | tenéis | 1 |
| 650 | tendré | 1 |
| 651 | tendrán | 1 |
| 652 | tendido | 1 |
| 653 | templos | 1 |
| 654 | temes | 1 |
| 655 | temer | 1 |
| 656 | temblando | 1 |
| 657 | telas | 1 |
| 658 | tejas | 1 |
| 659 | teatro | 1 |
| 660 | tarde | 1 |
| 661 | tapices | 1 |
| 662 | tantos | 1 |
| 663 | tantas | 1 |
| 664 | también | 1 |
| 665 | talle | 1 |
| 666 | suyos | 1 |
| 667 | suya | 1 |
| 668 | sur | 1 |
| 669 | sufrirá | 1 |
| 670 | sufrimiento | 1 |
| 671 | sufren | 1 |
| 672 | súfrala | 1 |
| 673 | sueño | 1 |
| 674 | suene | 1 |
| 675 | suelo | 1 |
| 676 | suelas | 1 |
| 677 | suegro | 1 |
| 678 | suceso | 1 |
| 679 | subjeto | 1 |
| 680 | soy | 1 |
| 681 | sostuvo | 1 |
| 682 | sosiego | 1 |
| 683 | sombras | 1 |
| 684 | sombra | 1 |
| 685 | soles | 1 |
| 686 | solas | 1 |
| 687 | sola | 1 |
| 688 | sois | 1 |
| 689 | sobrará | 1 |
| 690 | sirviendo | 1 |
| 691 | sirven | 1 |
| 692 | símil | 1 |
| 693 | silla | 1 |
| 694 | siguiendo | 1 |
| 695 | sigue | 1 |
| 696 | sigo | 1 |
| 697 | siento | 1 |
| 698 | sientes | 1 |
| 699 | sienes | 1 |
| 700 | sevillanos | 1 |
| 701 | seteno | 1 |
| 702 | servir | 1 |
| 703 | servidor | 1 |
| 704 | servido | 1 |
| 705 | serte | 1 |
| 706 | seréis | 1 |
| 707 | serafín | 1 |
| 708 | sepulcro | 1 |
| 709 | señores | 1 |
| 710 | señas | 1 |
| 711 | seno | 1 |
| 712 | selvas | 1 |
| 713 | sellos | 1 |
| 714 | segura | 1 |
| 715 | segundo | 1 |
| 716 | seguirás | 1 |
| 717 | sed | 1 |
| 718 | saturno | 1 |
| 719 | sátiros | 1 |
| 720 | satanás | 1 |
| 721 | santos | 1 |
| 722 | santo | 1 |
| 723 | sangre | 1 |
| 724 | sanear | 1 |
| 725 | salvados | 1 |
| 726 | salió | 1 |
| 727 | saliere | 1 |
| 728 | salía | 1 |
| 729 | sale | 1 |
| 730 | sala | 1 |
| 731 | sagrada | 1 |
| 732 | sagitario | 1 |
| 733 | saetas | 1 |
| 734 | sacrificios | 1 |
| 735 | sacar | 1 |
| 736 | sabio | 1 |
| 737 | sabes | 1 |
| 738 | sabandijas | 1 |
| 739 | rumbo | 1 |
| 740 | ruinas | 1 |
| 741 | ruego | 1 |
| 742 | roe | 1 |
| 743 | rocín | 1 |
| 744 | robusto | 1 |
| 745 | robres | 1 |
| 746 | rival | 1 |
| 747 | riqueza | 1 |
| 748 | ríos | 1 |
| 749 | río | 1 |
| 750 | rindió | 1 |
| 751 | rigores | 1 |
| 752 | rigor | 1 |
| 753 | ricos | 1 |
| 754 | ricas | 1 |
| 755 | revocaban | 1 |
| 756 | resuelven | 1 |
| 757 | resuelto | 1 |
| 758 | respondón | 1 |
| 759 | respondiste | 1 |
| 760 | respondí | 1 |
| 761 | respeto | 1 |
| 762 | replicáis | 1 |
| 763 | reñir | 1 |
| 764 | reniego | 1 |
| 765 | renglones | 1 |
| 766 | remozado | 1 |
| 767 | remotas | 1 |
| 768 | remitió | 1 |
| 769 | remitiera | 1 |
| 770 | religión | 1 |
| 771 | registró | 1 |
| 772 | regiones | 1 |
| 773 | regalarte | 1 |
| 774 | redujo | 1 |
| 775 | reducido | 1 |
| 776 | redomas | 1 |
| 777 | redomado | 1 |
| 778 | recoge | 1 |
| 779 | recobrarle | 1 |
| 780 | reclamo | 1 |
| 781 | recato | 1 |
| 782 | razones | 1 |
| 783 | razón | 1 |
| 784 | raro | 1 |
| 785 | quitaste | 1 |
| 786 | quitan | 1 |
| 787 | quitalla | 1 |
| 788 | quiso | 1 |
| 789 | quisiera | 1 |
| 790 | quintas | 1 |
| 791 | quiés | 1 |
| 792 | quieres | 1 |
| 793 | quicios | 1 |
| 794 | querría | 1 |
| 795 | quería | 1 |
| 796 | quema | 1 |
| 797 | queje | 1 |
| 798 | quedo | 1 |
| 799 | quédese | 1 |
| 800 | quedara | 1 |
| 801 | púrpura | 1 |
| 802 | purísima | 1 |
| 803 | purificación | 1 |
| 804 | puridad | 1 |
| 805 | purgarse | 1 |
| 806 | puntualidad | 1 |
| 807 | puntas | 1 |
| 808 | puesto | 1 |
| 809 | puesta | 1 |
| 810 | puerto | 1 |
| 811 | puede | 1 |
| 812 | pueda | 1 |
| 813 | publicara | 1 |
| 814 | publicando | 1 |
| 815 | prueba | 1 |
| 816 | prudentes | 1 |
| 817 | prudencia | 1 |
| 818 | provisiones | 1 |
| 819 | provecho | 1 |
| 820 | propio | 1 |
| 821 | propiedad | 1 |
| 822 | prometo | 1 |
| 823 | procura | 1 |
| 824 | procede | 1 |
| 825 | privilegios | 1 |
| 826 | privilegie | 1 |
| 827 | primores | 1 |
| 828 | primeros | 1 |
| 829 | pretende | 1 |
| 830 | presuponiendo | 1 |
| 831 | presto | 1 |
| 832 | presta | 1 |
| 833 | preso | 1 |
| 834 | preguntas | 1 |
| 835 | pregonero | 1 |
| 836 | prado | 1 |
| 837 | potro | 1 |
| 838 | postigo | 1 |
| 839 | porfía | 1 |
| 840 | ponzoñosa | 1 |
| 841 | ponzoña | 1 |
| 842 | poniéndole | 1 |
| 843 | ponga | 1 |
| 844 | poner | 1 |
| 845 | pone | 1 |
| 846 | pondero | 1 |
| 847 | ponderé | 1 |
| 848 | poltronería | 1 |
| 849 | polo | 1 |
| 850 | poetas | 1 |
| 851 | podéis | 1 |
| 852 | poco | 1 |
| 853 | po | 1 |
| 854 | plugo | 1 |
| 855 | plega | 1 |
| 856 | plaza | 1 |
| 857 | platería | 1 |
| 858 | planeta | 1 |
| 859 | pisó | 1 |
| 860 | pisase | 1 |
| 861 | pisaba | 1 |
| 862 | pipotes | 1 |
| 863 | pierna | 1 |
| 864 | piedra | 1 |
| 865 | pide | 1 |
| 866 | pestilencia | 1 |
| 867 | pesadumbres | 1 |
| 868 | pesado | 1 |
| 869 | pesada | 1 |
| 870 | personas | 1 |
| 871 | personajes | 1 |
| 872 | permitió | 1 |
| 873 | perlas | 1 |
| 874 | peregrinos | 1 |
| 875 | peregrino | 1 |
| 876 | peregrina | 1 |
| 877 | perdonen | 1 |
| 878 | perdone | 1 |
| 879 | perdonaba | 1 |
| 880 | perdón | 1 |
| 881 | perdido | 1 |
| 882 | perdí | 1 |
| 883 | perder | 1 |
| 884 | pequeña | 1 |
| 885 | penséis | 1 |
| 886 | pensé | 1 |
| 887 | pensar | 1 |
| 888 | pensamiento | 1 |
| 889 | penetra | 1 |
| 890 | pendientes | 1 |
| 891 | penado | 1 |
| 892 | pena | 1 |
| 893 | peligroso | 1 |
| 894 | peligro | 1 |
| 895 | peinados | 1 |
| 896 | pegadlo | 1 |
| 897 | pedir | 1 |
| 898 | pedí | 1 |
| 899 | pecadores | 1 |
| 900 | patrio | 1 |
| 901 | patria | 1 |
| 902 | pasos | 1 |
| 903 | pasiones | 1 |
| 904 | pasear | 1 |
| 905 | pasas | 1 |
| 906 | pasar | 1 |
| 907 | partiré | 1 |
| 908 | partimos | 1 |
| 909 | partíme | 1 |
| 910 | partes | 1 |
| 911 | parir | 1 |
| 912 | parecerse | 1 |
| 913 | parecen | 1 |
| 914 | papel | 1 |
| 915 | pan | 1 |
| 916 | pámpanos | 1 |
| 917 | palacios | 1 |
| 918 | palabras | 1 |
| 919 | palabra | 1 |
| 920 | pajes | 1 |
| 921 | paje | 1 |
| 922 | pagando | 1 |
| 923 | pagada | 1 |
| 924 | paga | 1 |
| 925 | padezco | 1 |
| 926 | pacientes | 1 |
| 927 | paciencia | 1 |
| 928 | pabellones | 1 |
| 929 | oyes | 1 |
| 930 | oyendo | 1 |
| 931 | oya | 1 |
| 932 | otorgue | 1 |
| 933 | otorga | 1 |
| 934 | otoño | 1 |
| 935 | orinales | 1 |
| 936 | orejas | 1 |
| 937 | orden | 1 |
| 938 | orbe | 1 |
| 939 | oraciones | 1 |
| 940 | onceno | 1 |
| 941 | omnium | 1 |
| 942 | olas | 1 |
| 943 | oíste | 1 |
| 944 | oigo | 1 |
| 945 | oído | 1 |
| 946 | ofrecerle | 1 |
| 947 | ofrecerá | 1 |
| 948 | ofenda | 1 |
| 949 | ocupando | 1 |
| 950 | ocupa | 1 |
| 951 | octava | 1 |
| 952 | ocasión | 1 |
| 953 | obras | 1 |
| 954 | obligará | 1 |
| 955 | nuevas | 1 |
| 956 | nueva | 1 |
| 957 | nuestras | 1 |
| 958 | nuestra | 1 |
| 959 | nuero | 1 |
| 960 | novelas | 1 |
| 961 | novedades | 1 |
| 962 | nota | 1 |
| 963 | nombran | 1 |
| 964 | noche | 1 |
| 965 | niño | 1 |
| 966 | ningún | 1 |
| 967 | nilo | 1 |
| 968 | nido | 1 |
| 969 | negóme | 1 |
| 970 | negocio | 1 |
| 971 | negándose | 1 |
| 972 | negallo | 1 |
| 973 | néctar | 1 |
| 974 | necedad | 1 |
| 975 | navíos | 1 |
| 976 | navaja | 1 |
| 977 | natural | 1 |
| 978 | naciones | 1 |
| 979 | nació | 1 |
| 980 | muros | 1 |
| 981 | murmurara | 1 |
| 982 | murió | 1 |
| 983 | mundo | 1 |
| 984 | mula | 1 |
| 985 | mujeres | 1 |
| 986 | mueve | 1 |
| 987 | muevas | 1 |
| 988 | muerde | 1 |
| 989 | muera | 1 |
| 990 | muela | 1 |
| 991 | muebles | 1 |
| 992 | mudo | 1 |
| 993 | muchas | 1 |
| 994 | moza | 1 |
| 995 | motejóme | 1 |
| 996 | mote | 1 |
| 997 | mostrar | 1 |
| 998 | mostrando | 1 |
| 999 | mosto | 1 |
| 1000 | mortaja | 1 |
| 1001 | mordió | 1 |
| 1002 | monjes | 1 |
| 1003 | monja | 1 |
| 1004 | moja | 1 |
| 1005 | modo | 1 |
| 1006 | mírate | 1 |
| 1007 | mírasla | 1 |
| 1008 | mirarlo | 1 |
| 1009 | ministril | 1 |
| 1010 | milagros | 1 |
| 1011 | mientras | 1 |
| 1012 | miento | 1 |
| 1013 | miedo | 1 |
| 1014 | mezquina | 1 |
| 1015 | metal | 1 |
| 1016 | meses | 1 |
| 1017 | mesa | 1 |
| 1018 | mes | 1 |
| 1019 | merece | 1 |
| 1020 | mercedes | 1 |
| 1021 | merced | 1 |
| 1022 | menudos | 1 |
| 1023 | menores | 1 |
| 1024 | mengua | 1 |
| 1025 | menester | 1 |
| 1026 | melancólico | 1 |
| 1027 | melancolías | 1 |
| 1028 | mejores | 1 |
| 1029 | medina | 1 |
| 1030 | médico | 1 |
| 1031 | mazmorra | 1 |
| 1032 | maullando | 1 |
| 1033 | matrimonio | 1 |
| 1034 | matadora | 1 |
| 1035 | máscara | 1 |
| 1036 | mascado | 1 |
| 1037 | maravilla | 1 |
| 1038 | máquina | 1 |
| 1039 | mapa | 1 |
| 1040 | mande | 1 |
| 1041 | mandaron | 1 |
| 1042 | mandáisle | 1 |
| 1043 | mandado | 1 |
| 1044 | malsano | 1 |
| 1045 | maliciosa | 1 |
| 1046 | maestra | 1 |
| 1047 | luz | 1 |
| 1048 | luna | 1 |
| 1049 | luis | 1 |
| 1050 | lucientes | 1 |
| 1051 | lonja | 1 |
| 1052 | londres | 1 |
| 1053 | llora | 1 |
| 1054 | llevó | 1 |
| 1055 | llevarte | 1 |
| 1056 | lleno | 1 |
| 1057 | llegué | 1 |
| 1058 | llegó | 1 |
| 1059 | llégase | 1 |
| 1060 | llegarme | 1 |
| 1061 | llegará | 1 |
| 1062 | llegamos | 1 |
| 1063 | llave | 1 |
| 1064 | llano | 1 |
| 1065 | llana | 1 |
| 1066 | llaman | 1 |
| 1067 | llámame | 1 |
| 1068 | liviandad | 1 |
| 1069 | liviana | 1 |
| 1070 | lisonjas | 1 |
| 1071 | lisonja | 1 |
| 1072 | ligeros | 1 |
| 1073 | ligero | 1 |
| 1074 | libro | 1 |
| 1075 | libre | 1 |
| 1076 | libertad | 1 |
| 1077 | leyes | 1 |
| 1078 | letra | 1 |
| 1079 | leones | 1 |
| 1080 | leños | 1 |
| 1081 | leño | 1 |
| 1082 | lenguaje | 1 |
| 1083 | leí | 1 |
| 1084 | legal | 1 |
| 1085 | lee | 1 |
| 1086 | lechos | 1 |
| 1087 | lección | 1 |
| 1088 | leal | 1 |
| 1089 | laureta | 1 |
| 1090 | largos | 1 |
| 1091 | lambicando | 1 |
| 1092 | lágrimas | 1 |
| 1093 | labradores | 1 |
| 1094 | labio | 1 |
| 1095 | justiciero | 1 |
| 1096 | justicia | 1 |
| 1097 | juré | 1 |
| 1098 | juraré | 1 |
| 1099 | junto | 1 |
| 1100 | juicio | 1 |
| 1101 | jugar | 1 |
| 1102 | juez | 1 |
| 1103 | juega | 1 |
| 1104 | jubileo | 1 |
| 1105 | joyas | 1 |
| 1106 | joven | 1 |
| 1107 | jazmines | 1 |
| 1108 | jarro | 1 |
| 1109 | jardín | 1 |
| 1110 | jamás | 1 |
| 1111 | jabalí | 1 |
| 1112 | islas | 1 |
| 1113 | invidioso | 1 |
| 1114 | invidiado | 1 |
| 1115 | invencibles | 1 |
| 1116 | introducirme | 1 |
| 1117 | interés | 1 |
| 1118 | intentan | 1 |
| 1119 | intempestiva | 1 |
| 1120 | instinto | 1 |
| 1121 | instante | 1 |
| 1122 | instancia | 1 |
| 1123 | insignias | 1 |
| 1124 | injusto | 1 |
| 1125 | ingratitud | 1 |
| 1126 | inglés | 1 |
| 1127 | información | 1 |
| 1128 | informa | 1 |
| 1129 | infernal | 1 |
| 1130 | infamen | 1 |
| 1131 | indiscreto | 1 |
| 1132 | incluís | 1 |
| 1133 | inclinado | 1 |
| 1134 | inclinación | 1 |
| 1135 | incierto | 1 |
| 1136 | importuno | 1 |
| 1137 | impertinencias | 1 |
| 1138 | impertinencia | 1 |
| 1139 | imperio | 1 |
| 1140 | imito | 1 |
| 1141 | imaginaciones | 1 |
| 1142 | imaginación | 1 |
| 1143 | ilustrar | 1 |
| 1144 | ilustra | 1 |
| 1145 | iba | 1 |
| 1146 | huye | 1 |
| 1147 | huso | 1 |
| 1148 | hurto | 1 |
| 1149 | hurtan | 1 |
| 1150 | huevo | 1 |
| 1151 | hueso | 1 |
| 1152 | hospedajes | 1 |
| 1153 | hospedador | 1 |
| 1154 | hospedado | 1 |
| 1155 | horca | 1 |
| 1156 | honrados | 1 |
| 1157 | hondas | 1 |
| 1158 | hombros | 1 |
| 1159 | hombro | 1 |
| 1160 | holanda | 1 |
| 1161 | hojaldrado | 1 |
| 1162 | hogaño | 1 |
| 1163 | hízote | 1 |
| 1164 | hilos | 1 |
| 1165 | hilo | 1 |
| 1166 | hijas | 1 |
| 1167 | hierros | 1 |
| 1168 | hermosas | 1 |
| 1169 | hartas | 1 |
| 1170 | harpía | 1 |
| 1171 | han | 1 |
| 1172 | hambre | 1 |
| 1173 | hallas | 1 |
| 1174 | hallamos | 1 |
| 1175 | halcones | 1 |
| 1176 | halcón | 1 |
| 1177 | hago | 1 |
| 1178 | hacienda | 1 |
| 1179 | haces | 1 |
| 1180 | hacerlo | 1 |
| 1181 | hacerle | 1 |
| 1182 | hacello | 1 |
| 1183 | hace | 1 |
| 1184 | hablo | 1 |
| 1185 | hable | 1 |
| 1186 | hablaba | 1 |
| 1187 | habiendo | 1 |
| 1188 | haberle | 1 |
| 1189 | habéis | 1 |
| 1190 | gustos | 1 |
| 1191 | gusano | 1 |
| 1192 | guido | 1 |
| 1193 | guerra | 1 |
| 1194 | guardarle | 1 |
| 1195 | guardaré | 1 |
| 1196 | guardaos | 1 |
| 1197 | guardan | 1 |
| 1198 | guadaña | 1 |
| 1199 | granos | 1 |
| 1200 | granjeé | 1 |
| 1201 | grandísima | 1 |
| 1202 | granates | 1 |
| 1203 | granadino | 1 |
| 1204 | gradas | 1 |
| 1205 | gozóla | 1 |
| 1206 | gozando | 1 |
| 1207 | goza | 1 |
| 1208 | góngora | 1 |
| 1209 | golpes | 1 |
| 1210 | glorioso | 1 |
| 1211 | gloriosas | 1 |
| 1212 | gentilhombre | 1 |
| 1213 | gentes | 1 |
| 1214 | genil | 1 |
| 1215 | generosos | 1 |
| 1216 | gemido | 1 |
| 1217 | gatos | 1 |
| 1218 | gastó | 1 |
| 1219 | gastalle | 1 |
| 1220 | garrote | 1 |
| 1221 | garras | 1 |
| 1222 | gante | 1 |
| 1223 | ganado | 1 |
| 1224 | gallardo | 1 |
| 1225 | galeote | 1 |
| 1226 | galante | 1 |
| 1227 | gala | 1 |
| 1228 | fundimos | 1 |
| 1229 | fuéramos | 1 |
| 1230 | fruta | 1 |
| 1231 | fría | 1 |
| 1232 | freno | 1 |
| 1233 | francolín | 1 |
| 1234 | frágil | 1 |
| 1235 | forzarle | 1 |
| 1236 | forzado | 1 |
| 1237 | fortaleza | 1 |
| 1238 | flacos | 1 |
| 1239 | flaco | 1 |
| 1240 | firmezas | 1 |
| 1241 | firmé | 1 |
| 1242 | firmas | 1 |
| 1243 | firma | 1 |
| 1244 | final | 1 |
| 1245 | fiera | 1 |
| 1246 | fïeles | 1 |
| 1247 | fiel | 1 |
| 1248 | fidelium | 1 |
| 1249 | feria | 1 |
| 1250 | fatigas | 1 |
| 1251 | faroles | 1 |
| 1252 | famulorum | 1 |
| 1253 | famularum | 1 |
| 1254 | famular | 1 |
| 1255 | fama | 1 |
| 1256 | faltas | 1 |
| 1257 | falta | 1 |
| 1258 | faisán | 1 |
| 1259 | facilidades | 1 |
| 1260 | fácil | 1 |
| 1261 | fábula | 1 |
| 1262 | extremo | 1 |
| 1263 | extraño | 1 |
| 1264 | examinan | 1 |
| 1265 | evangelio | 1 |
| 1266 | europa | 1 |
| 1267 | estuve | 1 |
| 1268 | estribos | 1 |
| 1269 | estrecha | 1 |
| 1270 | estrago | 1 |
| 1271 | estos | 1 |
| 1272 | estoque | 1 |
| 1273 | estómago | 1 |
| 1274 | están | 1 |
| 1275 | estáis | 1 |
| 1276 | estaciones | 1 |
| 1277 | ésta | 1 |
| 1278 | esposas | 1 |
| 1279 | esplendores | 1 |
| 1280 | espíritu | 1 |
| 1281 | espía | 1 |
| 1282 | espesura | 1 |
| 1283 | esperándoos | 1 |
| 1284 | esparcido | 1 |
| 1285 | española | 1 |
| 1286 | espaldas | 1 |
| 1287 | espada | 1 |
| 1288 | esfera | 1 |
| 1289 | esencias | 1 |
| 1290 | ese | 1 |
| 1291 | escudos | 1 |
| 1292 | escuderazo | 1 |
| 1293 | escuchar | 1 |
| 1294 | escuchad | 1 |
| 1295 | escucha | 1 |
| 1296 | escrita | 1 |
| 1297 | esconde | 1 |
| 1298 | escollos | 1 |
| 1299 | escalones | 1 |
| 1300 | escala | 1 |
| 1301 | erranti | 1 |
| 1302 | eres | 1 |
| 1303 | entré | 1 |
| 1304 | entrará | 1 |
| 1305 | entran | 1 |
| 1306 | entrado | 1 |
| 1307 | entonces | 1 |
| 1308 | entienda | 1 |
| 1309 | entendiste | 1 |
| 1310 | enojos | 1 |
| 1311 | enladrillados | 1 |
| 1312 | enhorabuena | 1 |
| 1313 | engendradora | 1 |
| 1314 | engastados | 1 |
| 1315 | engañen | 1 |
| 1316 | enfermera | 1 |
| 1317 | enfermedad | 1 |
| 1318 | encomendarme | 1 |
| 1319 | enamoróse | 1 |
| 1320 | enamora | 1 |
| 1321 | empreña | 1 |
| 1322 | empolla | 1 |
| 1323 | empleé | 1 |
| 1324 | embestille | 1 |
| 1325 | embaraza | 1 |
| 1326 | ellas | 1 |
| 1327 | ejemplo | 1 |
| 1328 | egipto | 1 |
| 1329 | efemérides | 1 |
| 1330 | edificios | 1 |
| 1331 | edificio | 1 |
| 1332 | edad | 1 |
| 1333 | echó | 1 |
| 1334 | dura | 1 |
| 1335 | duque | 1 |
| 1336 | dulcísimos | 1 |
| 1337 | dulces | 1 |
| 1338 | drogas | 1 |
| 1339 | dorado | 1 |
| 1340 | dorada | 1 |
| 1341 | dones | 1 |
| 1342 | doncella | 1 |
| 1343 | donato | 1 |
| 1344 | donaires | 1 |
| 1345 | dolores | 1 |
| 1346 | dolor | 1 |
| 1347 | doctrina | 1 |
| 1348 | doctores | 1 |
| 1349 | docta | 1 |
| 1350 | doce | 1 |
| 1351 | doblones | 1 |
| 1352 | doblón | 1 |
| 1353 | dobles | 1 |
| 1354 | doble | 1 |
| 1355 | do | 1 |
| 1356 | dividido | 1 |
| 1357 | dispones | 1 |
| 1358 | disolviéronse | 1 |
| 1359 | disimules | 1 |
| 1360 | disformes | 1 |
| 1361 | discreto | 1 |
| 1362 | discreta | 1 |
| 1363 | diréoslo | 1 |
| 1364 | diré | 1 |
| 1365 | dirá | 1 |
| 1366 | dioses | 1 |
| 1367 | diomedes | 1 |
| 1368 | dio | 1 |
| 1369 | dineros | 1 |
| 1370 | dímela | 1 |
| 1371 | dijera | 1 |
| 1372 | digerida | 1 |
| 1373 | diga | 1 |
| 1374 | diez | 1 |
| 1375 | diciendo | 1 |
| 1376 | dichosa | 1 |
| 1377 | dichas | 1 |
| 1378 | diamante | 1 |
| 1379 | devotos | 1 |
| 1380 | devoto | 1 |
| 1381 | deudo | 1 |
| 1382 | detenéis | 1 |
| 1383 | destierros | 1 |
| 1384 | destierro | 1 |
| 1385 | destierra | 1 |
| 1386 | desposado | 1 |
| 1387 | desplegó | 1 |
| 1388 | despierto | 1 |
| 1389 | despaché | 1 |
| 1390 | despachando | 1 |
| 1391 | despacha | 1 |
| 1392 | despabilado | 1 |
| 1393 | desnudó | 1 |
| 1394 | deseó | 1 |
| 1395 | desear | 1 |
| 1396 | desea | 1 |
| 1397 | desdichas | 1 |
| 1398 | desdeña | 1 |
| 1399 | desde | 1 |
| 1400 | descargada | 1 |
| 1401 | descansa | 1 |
| 1402 | desatado | 1 |
| 1403 | derecho | 1 |
| 1404 | delicias | 1 |
| 1405 | déjese | 1 |
| 1406 | déjate | 1 |
| 1407 | dejaréte | 1 |
| 1408 | dejándote | 1 |
| 1409 | dejámosla | 1 |
| 1410 | deidad | 1 |
| 1411 | decid | 1 |
| 1412 | debía | 1 |
| 1413 | debajo | 1 |
| 1414 | deba | 1 |
| 1415 | dé | 1 |
| 1416 | dátil | 1 |
| 1417 | das | 1 |
| 1418 | darme | 1 |
| 1419 | darle | 1 |
| 1420 | darás | 1 |
| 1421 | dan | 1 |
| 1422 | dales | 1 |
| 1423 | dais | 1 |
| 1424 | dados | 1 |
| 1425 | daba | 1 |
| 1426 | cuya | 1 |
| 1427 | curiosidad | 1 |
| 1428 | curiosa | 1 |
| 1429 | cupido | 1 |
| 1430 | cuidados | 1 |
| 1431 | cuidado | 1 |
| 1432 | cueva | 1 |
| 1433 | cuestiones | 1 |
| 1434 | cuerpo | 1 |
| 1435 | cuerno | 1 |
| 1436 | cuentas | 1 |
| 1437 | cuchillo | 1 |
| 1438 | cúbrome | 1 |
| 1439 | cúbrete | 1 |
| 1440 | cuatriduano | 1 |
| 1441 | cuartos | 1 |
| 1442 | cuantía | 1 |
| 1443 | cuan | 1 |
| 1444 | cualquier | 1 |
| 1445 | cruces | 1 |
| 1446 | cristales | 1 |
| 1447 | crisoles | 1 |
| 1448 | crisol | 1 |
| 1449 | criados | 1 |
| 1450 | crïado | 1 |
| 1451 | criadas | 1 |
| 1452 | criada | 1 |
| 1453 | creía | 1 |
| 1454 | creí | 1 |
| 1455 | crédito | 1 |
| 1456 | creciente | 1 |
| 1457 | costumbres | 1 |
| 1458 | costado | 1 |
| 1459 | corzo | 1 |
| 1460 | cortes | 1 |
| 1461 | corta | 1 |
| 1462 | corrompe | 1 |
| 1463 | corrido | 1 |
| 1464 | correspondencias | 1 |
| 1465 | correr | 1 |
| 1466 | corren | 1 |
| 1467 | coros | 1 |
| 1468 | corone | 1 |
| 1469 | coronado | 1 |
| 1470 | corazones | 1 |
| 1471 | copia | 1 |
| 1472 | copa | 1 |
| 1473 | convinieron | 1 |
| 1474 | convierte | 1 |
| 1475 | conviene | 1 |
| 1476 | convecinó | 1 |
| 1477 | convalecí | 1 |
| 1478 | contina | 1 |
| 1479 | contera | 1 |
| 1480 | contento | 1 |
| 1481 | consuela | 1 |
| 1482 | consiente | 1 |
| 1483 | conquistóle | 1 |
| 1484 | conoces | 1 |
| 1485 | conocer | 1 |
| 1486 | conocella | 1 |
| 1487 | conjunción | 1 |
| 1488 | conformes | 1 |
| 1489 | confieso | 1 |
| 1490 | confiar | 1 |
| 1491 | condes | 1 |
| 1492 | concluya | 1 |
| 1493 | conciencia | 1 |
| 1494 | concha | 1 |
| 1495 | concertada | 1 |
| 1496 | concepto | 1 |
| 1497 | competidor | 1 |
| 1498 | comience | 1 |
| 1499 | comido | 1 |
| 1500 | comadreja | 1 |
| 1501 | comadre | 1 |
| 1502 | columnas | 1 |
| 1503 | colijo | 1 |
| 1504 | colgaré | 1 |
| 1505 | cola | 1 |
| 1506 | coja | 1 |
| 1507 | cofre | 1 |
| 1508 | cofrade | 1 |
| 1509 | coches | 1 |
| 1510 | cobre | 1 |
| 1511 | clausura | 1 |
| 1512 | claro | 1 |
| 1513 | clarísimos | 1 |
| 1514 | clara | 1 |
| 1515 | ciudades | 1 |
| 1516 | ciudadano | 1 |
| 1517 | ciudadana | 1 |
| 1518 | cierto | 1 |
| 1519 | ciento | 1 |
| 1520 | ciencia | 1 |
| 1521 | ciegas | 1 |
| 1522 | certifico | 1 |
| 1523 | ceremonia | 1 |
| 1524 | cerdas | 1 |
| 1525 | cera | 1 |
| 1526 | centinela | 1 |
| 1527 | cenizas | 1 |
| 1528 | celos | 1 |
| 1529 | celebraban | 1 |
| 1530 | celebraba | 1 |
| 1531 | celdas | 1 |
| 1532 | cédula | 1 |
| 1533 | cavalcanti | 1 |
| 1534 | cavaglieri | 1 |
| 1535 | cautelas | 1 |
| 1536 | cautela | 1 |
| 1537 | cause | 1 |
| 1538 | caudaloso | 1 |
| 1539 | caudalosa | 1 |
| 1540 | caudales | 1 |
| 1541 | católico | 1 |
| 1542 | cátedras | 1 |
| 1543 | castillo | 1 |
| 1544 | castigo | 1 |
| 1545 | casas | 1 |
| 1546 | casarse | 1 |
| 1547 | casar | 1 |
| 1548 | cartujo | 1 |
| 1549 | cartago | 1 |
| 1550 | carrera | 1 |
| 1551 | caro | 1 |
| 1552 | carga | 1 |
| 1553 | caracoles | 1 |
| 1554 | cara | 1 |
| 1555 | capotes | 1 |
| 1556 | cano | 1 |
| 1557 | canicular | 1 |
| 1558 | canas | 1 |
| 1559 | canarias | 1 |
| 1560 | campanilla | 1 |
| 1561 | calzan | 1 |
| 1562 | callo | 1 |
| 1563 | callen | 1 |
| 1564 | callaron | 1 |
| 1565 | callaré | 1 |
| 1566 | callado | 1 |
| 1567 | califican | 1 |
| 1568 | calidad | 1 |
| 1569 | cajas | 1 |
| 1570 | cairás | 1 |
| 1571 | cadena | 1 |
| 1572 | cada | 1 |
| 1573 | caco | 1 |
| 1574 | cabo | 1 |
| 1575 | cabellos | 1 |
| 1576 | caballos | 1 |
| 1577 | busiris | 1 |
| 1578 | buscarle | 1 |
| 1579 | burlas | 1 |
| 1580 | buril | 1 |
| 1581 | bueno | 1 |
| 1582 | buen | 1 |
| 1583 | brocados | 1 |
| 1584 | brazo | 1 |
| 1585 | bravo | 1 |
| 1586 | brava | 1 |
| 1587 | bozo | 1 |
| 1588 | botica | 1 |
| 1589 | bosques | 1 |
| 1590 | borde | 1 |
| 1591 | bontà | 1 |
| 1592 | bondad | 1 |
| 1593 | blancos | 1 |
| 1594 | bicorne | 1 |
| 1595 | beso | 1 |
| 1596 | besar | 1 |
| 1597 | besa | 1 |
| 1598 | benditísimo | 1 |
| 1599 | bendigo | 1 |
| 1600 | bellas | 1 |
| 1601 | bebo | 1 |
| 1602 | bebió | 1 |
| 1603 | baste | 1 |
| 1604 | basiliscos | 1 |
| 1605 | bárbaros | 1 |
| 1606 | barato | 1 |
| 1607 | bailes | 1 |
| 1608 | bailar | 1 |
| 1609 | babilonia | 1 |
| 1610 | azulísima | 1 |
| 1611 | azules | 1 |
| 1612 | azores | 1 |
| 1613 | azogue | 1 |
| 1614 | ayude | 1 |
| 1615 | ayuda | 1 |
| 1616 | ayer | 1 |
| 1617 | aviso | 1 |
| 1618 | autor | 1 |
| 1619 | ausente | 1 |
| 1620 | ausentarse | 1 |
| 1621 | ausencia | 1 |
| 1622 | atrás | 1 |
| 1623 | atlante | 1 |
| 1624 | atenta | 1 |
| 1625 | ataúd | 1 |
| 1626 | astrología | 1 |
| 1627 | aspiran | 1 |
| 1628 | áspid | 1 |
| 1629 | aspecto | 1 |
| 1630 | asombro | 1 |
| 1631 | asido | 1 |
| 1632 | aseo | 1 |
| 1633 | artificio | 1 |
| 1634 | artículos | 1 |
| 1635 | artesón | 1 |
| 1636 | artesa | 1 |
| 1637 | arrimarle | 1 |
| 1638 | arrendara | 1 |
| 1639 | arreboza | 1 |
| 1640 | armonía | 1 |
| 1641 | armar | 1 |
| 1642 | arman | 1 |
| 1643 | armados | 1 |
| 1644 | ariosto | 1 |
| 1645 | argote | 1 |
| 1646 | argos | 1 |
| 1647 | argenta | 1 |
| 1648 | argel | 1 |
| 1649 | arenas | 1 |
| 1650 | arena | 1 |
| 1651 | ardiente | 1 |
| 1652 | árboles | 1 |
| 1653 | aquellos | 1 |
| 1654 | aquello | 1 |
| 1655 | aquella | 1 |
| 1656 | apurando | 1 |
| 1657 | apuntó | 1 |
| 1658 | aprisionado | 1 |
| 1659 | aprisa | 1 |
| 1660 | aprender | 1 |
| 1661 | aprehender | 1 |
| 1662 | aplica | 1 |
| 1663 | apelación | 1 |
| 1664 | apeado | 1 |
| 1665 | aparta | 1 |
| 1666 | año | 1 |
| 1667 | añado | 1 |
| 1668 | antoja | 1 |
| 1669 | antiguos | 1 |
| 1670 | antiguo | 1 |
| 1671 | ánimo | 1 |
| 1672 | ángel | 1 |
| 1673 | andalucía | 1 |
| 1674 | amenazas | 1 |
| 1675 | ambas | 1 |
| 1676 | amas | 1 |
| 1677 | amante | 1 |
| 1678 | alto | 1 |
| 1679 | alterada | 1 |
| 1680 | altera | 1 |
| 1681 | alquerías | 1 |
| 1682 | almalafas | 1 |
| 1683 | allí | 1 |
| 1684 | allana | 1 |
| 1685 | aliéntate | 1 |
| 1686 | alhambra | 1 |
| 1687 | algo | 1 |
| 1688 | alfombras | 1 |
| 1689 | alevosías | 1 |
| 1690 | alegre | 1 |
| 1691 | aldeas | 1 |
| 1692 | alcohole | 1 |
| 1693 | alcohola | 1 |
| 1694 | alcance | 1 |
| 1695 | albornoces | 1 |
| 1696 | albores | 1 |
| 1697 | alados | 1 |
| 1698 | alaba | 1 |
| 1699 | ajeno | 1 |
| 1700 | aguijón | 1 |
| 1701 | aguda | 1 |
| 1702 | aguardo | 1 |
| 1703 | aguarda | 1 |
| 1704 | agradecimiento | 1 |
| 1705 | africano | 1 |
| 1706 | aflijo | 1 |
| 1707 | aflija | 1 |
| 1708 | afirmar | 1 |
| 1709 | afínese | 1 |
| 1710 | afecto | 1 |
| 1711 | adversidades | 1 |
| 1712 | adulteraste | 1 |
| 1713 | aduana | 1 |
| 1714 | adonis | 1 |
| 1715 | adónde | 1 |
| 1716 | admiraciones | 1 |
| 1717 | admiración | 1 |
| 1718 | adivino | 1 |
| 1719 | adentro | 1 |
| 1720 | acusándole | 1 |
| 1721 | acuñados | 1 |
| 1722 | acude | 1 |
| 1723 | acrisola | 1 |
| 1724 | acompañando | 1 |
| 1725 | acomodó | 1 |
| 1726 | acabe | 1 |
| 1727 | acabarán | 1 |
| 1728 | acaba | 1 |
| 1729 | abrevia | 1 |
| 1730 | abrazo | 1 |
| 1731 | abra | 1 |
| 1732 | abogue | 1 |
| 1733 | abades | 1 |
|
Ilustración del principio de mínimo esfuerzo: |
|
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará el texto actual (Las firmezas de Isabela de Luis de Góngora) (conjunto 1)
contra el resto de textos en el mismo idioma (Castellano) (conjunto 2).
A continuación se muestra una lista de las palabras presentes en el texto actual,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
Mostrar todo
Recoger