Análisis de El Lazarillo de Tormes de Anónimo
Índice
Información General
| Título: | El Lazarillo de Tormes |
|---|
| Autor: | Anónimo |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 20073 |
|---|
| #Palabras distintas: | 3718 |
|---|
| Type-Token ratio: | 18.52% |
|---|
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| #Palabras: | #Palabras distintas: |
|---|
| 1000 | 468 |
| 2000 | 788 |
| 3000 | 1062 |
| 4000 | 1292 |
| 5000 | 1505 |
| 6000 | 1712 |
| 7000 | 1896 |
| 8000 | 2084 |
| 9000 | 2225 |
| 10000 | 2370 |
| 11000 | 2537 |
| 12000 | 2690 |
| 13000 | 2824 |
| 14000 | 2930 |
| 15000 | 3085 |
| 16000 | 3226 |
| 17000 | 3357 |
| 18000 | 3495 |
| 19000 | 3603 |
| 20000 | 3710 |
| 20073 | 3718 |
|
Ajuste por mínimos cuadrados de los datos a K*n^b:
|
| K = 4.539 |
|
b = 0.679 |

|
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Rank | Palabra | Frec |
|---|
| 1 | y | 1144 |
| 2 | que | 901 |
| 3 | de | 753 |
| 4 | la | 527 |
| 5 | a | 484 |
| 6 | el | 463 |
| 7 | en | 429 |
| 8 | no | 343 |
| 9 | por | 283 |
| 10 | con | 281 |
| 11 | me | 258 |
| 12 | lo | 214 |
| 13 | yo | 211 |
| 14 | mi | 198 |
| 15 | un | 164 |
| 16 | se | 160 |
| 17 | los | 158 |
| 18 | le | 147 |
| 19 | como | 146 |
| 20 | las | 139 |
| 21 | del | 129 |
| 22 | él | 123 |
| 23 | más | 117 |
| 24 | su | 114 |
| 25 | al | 98 |
| 26 | mas | 92 |
| 27 | porque | 89 |
| 28 | había | 89 |
| 29 | para | 83 |
| 30 | si | 80 |
| 31 | bien | 79 |
| 32 | amo | 77 |
| 33 | dios | 76 |
| 34 | mí | 71 |
| 35 | muy | 69 |
| 36 | una | 67 |
| 37 | señor | 67 |
| 38 | es | 67 |
| 39 | cual | 59 |
| 40 | pues | 58 |
| 41 | ni | 58 |
| 42 | era | 58 |
| 43 | ser | 55 |
| 44 | casa | 55 |
| 45 | tan | 54 |
| 46 | fue | 54 |
| 47 | tenía | 52 |
| 48 | día | 52 |
| 49 | sin | 49 |
| 50 | qué | 49 |
| 51 | esto | 49 |
| 52 | todo | 47 |
| 53 | estaba | 47 |
| 54 | este | 45 |
| 55 | aunque | 45 |
| 56 | aquel | 44 |
| 57 | dije | 43 |
| 58 | ansí | 42 |
| 59 | allí | 41 |
| 60 | ella | 39 |
| 61 | tal | 38 |
| 62 | o | 37 |
| 63 | mis | 37 |
| 64 | dijo | 37 |
| 65 | cuando | 37 |
| 66 | ciego | 37 |
| 67 | poco | 36 |
| 68 | manera | 36 |
| 69 | gran | 35 |
| 70 | comer | 35 |
| 71 | te | 34 |
| 72 | mal | 34 |
| 73 | hacer | 34 |
| 74 | ya | 33 |
| 75 | vino | 33 |
| 76 | noche | 33 |
| 77 | así | 33 |
| 78 | otro | 32 |
| 79 | dos | 32 |
| 80 | todos | 31 |
| 81 | mejor | 31 |
| 82 | entre | 30 |
| 83 | veces | 29 |
| 84 | tiempo | 29 |
| 85 | sus | 29 |
| 86 | pan | 29 |
| 87 | luego | 29 |
| 88 | decir | 29 |
| 89 | puerta | 28 |
| 90 | nos | 28 |
| 91 | mucho | 27 |
| 92 | mano | 27 |
| 93 | tres | 26 |
| 94 | sobre | 26 |
| 95 | lázaro | 26 |
| 96 | hombre | 26 |
| 97 | hecho | 26 |
| 98 | esta | 26 |
| 99 | después | 26 |
| 100 | vi | 25 |
| 101 | diciendo | 25 |
| 102 | decía | 25 |
| 103 | sino | 24 |
| 104 | otra | 24 |
| 105 | nunca | 24 |
| 106 | he | 24 |
| 107 | hasta | 24 |
| 108 | cosas | 24 |
| 109 | buen | 24 |
| 110 | vida | 23 |
| 111 | manos | 23 |
| 112 | ha | 23 |
| 113 | aun | 23 |
| 114 | ellos | 22 |
| 115 | días | 22 |
| 116 | antes | 22 |
| 117 | tanto | 21 |
| 118 | quien | 21 |
| 119 | hambre | 21 |
| 120 | está | 21 |
| 121 | digo | 21 |
| 122 | cosa | 21 |
| 123 | alguacil | 21 |
| 124 | también | 20 |
| 125 | otras | 20 |
| 126 | mundo | 20 |
| 127 | lugar | 20 |
| 128 | llave | 20 |
| 129 | hacía | 20 |
| 130 | dél | 20 |
| 131 | buena | 20 |
| 132 | boca | 20 |
| 133 | aquí | 20 |
| 134 | aquella | 20 |
| 135 | verdad | 19 |
| 136 | cabo | 19 |
| 137 | toda | 18 |
| 138 | sí | 18 |
| 139 | según | 18 |
| 140 | nada | 18 |
| 141 | muchas | 18 |
| 142 | eso | 18 |
| 143 | della | 18 |
| 144 | vuestra | 17 |
| 145 | otros | 17 |
| 146 | jarro | 17 |
| 147 | iba | 17 |
| 148 | hay | 17 |
| 149 | fuese | 17 |
| 150 | éste | 17 |
| 151 | donde | 17 |
| 152 | dio | 17 |
| 153 | bula | 17 |
| 154 | arca | 17 |
| 155 | agora | 17 |
| 156 | paso | 16 |
| 157 | parte | 16 |
| 158 | mozo | 16 |
| 159 | merced | 16 |
| 160 | haber | 16 |
| 161 | algo | 16 |
| 162 | tomar | 15 |
| 163 | pobre | 15 |
| 164 | mil | 15 |
| 165 | hoy | 15 |
| 166 | gente | 15 |
| 167 | daba | 15 |
| 168 | cuenta | 15 |
| 169 | cómo | 15 |
| 170 | calle | 15 |
| 171 | ver | 14 |
| 172 | os | 14 |
| 173 | les | 14 |
| 174 | iglesia | 14 |
| 175 | hizo | 14 |
| 176 | habían | 14 |
| 177 | do | 14 |
| 178 | alguna | 14 |
| 179 | tú | 13 |
| 180 | triste | 13 |
| 181 | traía | 13 |
| 182 | tierra | 13 |
| 183 | tener | 13 |
| 184 | pienso | 13 |
| 185 | menos | 13 |
| 186 | fuera | 13 |
| 187 | estaban | 13 |
| 188 | díjome | 13 |
| 189 | cuales | 13 |
| 190 | cabeza | 13 |
| 191 | adelante | 13 |
| 192 | todas | 12 |
| 193 | tiene | 12 |
| 194 | tanta | 12 |
| 195 | siempre | 12 |
| 196 | saber | 12 |
| 197 | puesto | 12 |
| 198 | pensando | 12 |
| 199 | nadie | 12 |
| 200 | madre | 12 |
| 201 | ir | 12 |
| 202 | estar | 12 |
| 203 | ello | 12 |
| 204 | ellas | 12 |
| 205 | dicen | 12 |
| 206 | desta | 12 |
| 207 | desde | 12 |
| 208 | dar | 12 |
| 209 | cruz | 12 |
| 210 | ciudad | 12 |
| 211 | cada | 12 |
| 212 | voces | 11 |
| 213 | vieja | 11 |
| 214 | ventura | 11 |
| 215 | unos | 11 |
| 216 | tengo | 11 |
| 217 | remedio | 11 |
| 218 | pecador | 11 |
| 219 | muerto | 11 |
| 220 | muchos | 11 |
| 221 | mucha | 11 |
| 222 | mañana | 11 |
| 223 | m | 11 |
| 224 | longaniza | 11 |
| 225 | hace | 11 |
| 226 | finalmente | 11 |
| 227 | estando | 11 |
| 228 | eran | 11 |
| 229 | e | 11 |
| 230 | dentro | 11 |
| 231 | cuatro | 11 |
| 232 | aquél | 11 |
| 233 | algún | 11 |
| 234 | agua | 11 |
| 235 | vivir | 10 |
| 236 | visto | 10 |
| 237 | viendo | 10 |
| 238 | v | 10 |
| 239 | uno | 10 |
| 240 | sé | 10 |
| 241 | santa | 10 |
| 242 | par | 10 |
| 243 | mujer | 10 |
| 244 | menester | 10 |
| 245 | hombres | 10 |
| 246 | estuve | 10 |
| 247 | diablo | 10 |
| 248 | comido | 10 |
| 249 | comenzó | 10 |
| 250 | cama | 10 |
| 251 | bulas | 10 |
| 252 | arcaz | 10 |
| 253 | aquello | 10 |
| 254 | vio | 9 |
| 255 | venida | 9 |
| 256 | sentido | 9 |
| 257 | respondió | 9 |
| 258 | quiso | 9 |
| 259 | quiero | 9 |
| 260 | quería | 9 |
| 261 | pueblo | 9 |
| 262 | pie | 9 |
| 263 | parecía | 9 |
| 264 | oración | 9 |
| 265 | ojos | 9 |
| 266 | ninguna | 9 |
| 267 | miedo | 9 |
| 268 | medio | 9 |
| 269 | hice | 9 |
| 270 | grandes | 9 |
| 271 | fortuna | 9 |
| 272 | escribano | 9 |
| 273 | dicho | 9 |
| 274 | decían | 9 |
| 275 | debía | 9 |
| 276 | daño | 9 |
| 277 | culebra | 9 |
| 278 | cuanto | 9 |
| 279 | casi | 9 |
| 280 | cara | 9 |
| 281 | aquellos | 9 |
| 282 | año | 9 |
| 283 | alguno | 9 |
| 284 | viejo | 8 |
| 285 | vecinos | 8 |
| 286 | tu | 8 |
| 287 | tras | 8 |
| 288 | todavía | 8 |
| 289 | suelen | 8 |
| 290 | soy | 8 |
| 291 | son | 8 |
| 292 | siendo | 8 |
| 293 | quién | 8 |
| 294 | púlpito | 8 |
| 295 | priesa | 8 |
| 296 | presto | 8 |
| 297 | poner | 8 |
| 298 | podía | 8 |
| 299 | persona | 8 |
| 300 | pasaba | 8 |
| 301 | parece | 8 |
| 302 | oficio | 8 |
| 303 | negocio | 8 |
| 304 | milagro | 8 |
| 305 | honra | 8 |
| 306 | fe | 8 |
| 307 | ésta | 8 |
| 308 | echar | 8 |
| 309 | di | 8 |
| 310 | carne | 8 |
| 311 | capa | 8 |
| 312 | camino | 8 |
| 313 | andaba | 8 |
| 314 | algunos | 8 |
| 315 | acabado | 8 |
| 316 | vos | 7 |
| 317 | vez | 7 |
| 318 | venir | 7 |
| 319 | venía | 7 |
| 320 | tratado | 7 |
| 321 | tomó | 7 |
| 322 | toledo | 7 |
| 323 | tantas | 7 |
| 324 | suyo | 7 |
| 325 | solo | 7 |
| 326 | sermón | 7 |
| 327 | sayo | 7 |
| 328 | ratones | 7 |
| 329 | puso | 7 |
| 330 | primero | 7 |
| 331 | posada | 7 |
| 332 | podría | 7 |
| 333 | poder | 7 |
| 334 | pocos | 7 |
| 335 | parecióme | 7 |
| 336 | oh | 7 |
| 337 | nuevo | 7 |
| 338 | nuestro | 7 |
| 339 | negra | 7 |
| 340 | muerte | 7 |
| 341 | mochacho | 7 |
| 342 | mío | 7 |
| 343 | memoria | 7 |
| 344 | mayormente | 7 |
| 345 | mayor | 7 |
| 346 | malas | 7 |
| 347 | mala | 7 |
| 348 | llevar | 7 |
| 349 | laceria | 7 |
| 350 | hora | 7 |
| 351 | grande | 7 |
| 352 | fui | 7 |
| 353 | falta | 7 |
| 354 | eres | 7 |
| 355 | entonces | 7 |
| 356 | dice | 7 |
| 357 | desque | 7 |
| 358 | deseo | 7 |
| 359 | demonio | 7 |
| 360 | debe | 7 |
| 361 | debajo | 7 |
| 362 | contento | 7 |
| 363 | comigo | 7 |
| 364 | clérigos | 7 |
| 365 | clérigo | 7 |
| 366 | cierto | 7 |
| 367 | cielo | 7 |
| 368 | casas | 7 |
| 369 | caridad | 7 |
| 370 | buenos | 7 |
| 371 | bueno | 7 |
| 372 | buenas | 7 |
| 373 | blanca | 7 |
| 374 | altar | 7 |
| 375 | algunas | 7 |
| 376 | adonde | 7 |
| 377 | venido | 6 |
| 378 | torné | 6 |
| 379 | tercero | 6 |
| 380 | suya | 6 |
| 381 | sueño | 6 |
| 382 | servir | 6 |
| 383 | sería | 6 |
| 384 | sepa | 6 |
| 385 | señores | 6 |
| 386 | sentía | 6 |
| 387 | sea | 6 |
| 388 | sabía | 6 |
| 389 | ruido | 6 |
| 390 | razón | 6 |
| 391 | ratón | 6 |
| 392 | quisiera | 6 |
| 393 | pude | 6 |
| 394 | presente | 6 |
| 395 | ponía | 6 |
| 396 | poca | 6 |
| 397 | pies | 6 |
| 398 | perdone | 6 |
| 399 | peor | 6 |
| 400 | pensaba | 6 |
| 401 | pedazos | 6 |
| 402 | pasó | 6 |
| 403 | pajas | 6 |
| 404 | padre | 6 |
| 405 | ocho | 6 |
| 406 | mujeres | 6 |
| 407 | misa | 6 |
| 408 | mesón | 6 |
| 409 | mesmo | 6 |
| 410 | maldito | 6 |
| 411 | maldita | 6 |
| 412 | llevaba | 6 |
| 413 | llaman | 6 |
| 414 | jubón | 6 |
| 415 | hijo | 6 |
| 416 | hallé | 6 |
| 417 | fuerza | 6 |
| 418 | estos | 6 |
| 419 | estómago | 6 |
| 420 | entró | 6 |
| 421 | diez | 6 |
| 422 | deseaba | 6 |
| 423 | desdicha | 6 |
| 424 | dejó | 6 |
| 425 | dándome | 6 |
| 426 | dando | 6 |
| 427 | da | 6 |
| 428 | criado | 6 |
| 429 | comía | 6 |
| 430 | caso | 6 |
| 431 | blancas | 6 |
| 432 | asentó | 6 |
| 433 | aparejo | 6 |
| 434 | alegre | 6 |
| 435 | adónde | 6 |
| 436 | acaeció | 6 |
| 437 | abajo | 6 |
| 438 | vista | 5 |
| 439 | vine | 5 |
| 440 | vía | 5 |
| 441 | venían | 5 |
| 442 | va | 5 |
| 443 | trabajos | 5 |
| 444 | trabajo | 5 |
| 445 | tiento | 5 |
| 446 | tienen | 5 |
| 447 | ti | 5 |
| 448 | tenido | 5 |
| 449 | tenían | 5 |
| 450 | temor | 5 |
| 451 | suelo | 5 |
| 452 | sintió | 5 |
| 453 | señal | 5 |
| 454 | salir | 5 |
| 455 | salió | 5 |
| 456 | sacar | 5 |
| 457 | río | 5 |
| 458 | rezar | 5 |
| 459 | respondí | 5 |
| 460 | racimo | 5 |
| 461 | quitaba | 5 |
| 462 | quince | 5 |
| 463 | queso | 5 |
| 464 | provecho | 5 |
| 465 | propósito | 5 |
| 466 | plaza | 5 |
| 467 | piernas | 5 |
| 468 | pensé | 5 |
| 469 | pensar | 5 |
| 470 | pasar | 5 |
| 471 | palabra | 5 |
| 472 | ojo | 5 |
| 473 | oí | 5 |
| 474 | nuestra | 5 |
| 475 | niño | 5 |
| 476 | ninguno | 5 |
| 477 | mitad | 5 |
| 478 | mira | 5 |
| 479 | meter | 5 |
| 480 | maravedís | 5 |
| 481 | mandó | 5 |
| 482 | limosna | 5 |
| 483 | larga | 5 |
| 484 | lacerado | 5 |
| 485 | justicia | 5 |
| 486 | hecha | 5 |
| 487 | has | 5 |
| 488 | harto | 5 |
| 489 | haría | 5 |
| 490 | han | 5 |
| 491 | hallar | 5 |
| 492 | hacienda | 5 |
| 493 | hacen | 5 |
| 494 | hábito | 5 |
| 495 | gracias | 5 |
| 496 | frío | 5 |
| 497 | favor | 5 |
| 498 | estuvimos | 5 |
| 499 | escudero | 5 |
| 500 | esa | 5 |
| 501 | entrar | 5 |
| 502 | encima | 5 |
| 503 | dubda | 5 |
| 504 | doy | 5 |
| 505 | díjele | 5 |
| 506 | dientes | 5 |
| 507 | dicha | 5 |
| 508 | deste | 5 |
| 509 | derecho | 5 |
| 510 | dende | 5 |
| 511 | demás | 5 |
| 512 | dellas | 5 |
| 513 | dado | 5 |
| 514 | daban | 5 |
| 515 | cuerpo | 5 |
| 516 | creo | 5 |
| 517 | costa | 5 |
| 518 | contar | 5 |
| 519 | contando | 5 |
| 520 | contado | 5 |
| 521 | contaba | 5 |
| 522 | considerando | 5 |
| 523 | comisario | 5 |
| 524 | comienzo | 5 |
| 525 | bocado | 5 |
| 526 | aún | 5 |
| 527 | astuto | 5 |
| 528 | arroyo | 5 |
| 529 | años | 5 |
| 530 | andar | 5 |
| 531 | amos | 5 |
| 532 | alto | 5 |
| 533 | allá | 5 |
| 534 | vuelto | 4 |
| 535 | viniese | 4 |
| 536 | viéndome | 4 |
| 537 | veo | 4 |
| 538 | ve | 4 |
| 539 | unas | 4 |
| 540 | tuve | 4 |
| 541 | toro | 4 |
| 542 | tornando | 4 |
| 543 | tormes | 4 |
| 544 | tomo | 4 |
| 545 | tomé | 4 |
| 546 | tomad | 4 |
| 547 | toma | 4 |
| 548 | toca | 4 |
| 549 | tío | 4 |
| 550 | tienes | 4 |
| 551 | tenga | 4 |
| 552 | tarde | 4 |
| 553 | supe | 4 |
| 554 | solía | 4 |
| 555 | sido | 4 |
| 556 | seguro | 4 |
| 557 | sazón | 4 |
| 558 | sano | 4 |
| 559 | salvo | 4 |
| 560 | salimos | 4 |
| 561 | salamanca | 4 |
| 562 | sacó | 4 |
| 563 | sabe | 4 |
| 564 | ruin | 4 |
| 565 | rezaba | 4 |
| 566 | remediar | 4 |
| 567 | recio | 4 |
| 568 | quitar | 4 |
| 569 | quise | 4 |
| 570 | quieren | 4 |
| 571 | punto | 4 |
| 572 | primer | 4 |
| 573 | poyo | 4 |
| 574 | poste | 4 |
| 575 | piedra | 4 |
| 576 | pequeño | 4 |
| 577 | pena | 4 |
| 578 | peligro | 4 |
| 579 | pedazo | 4 |
| 580 | pecados | 4 |
| 581 | parecer | 4 |
| 582 | panes | 4 |
| 583 | pago | 4 |
| 584 | oyó | 4 |
| 585 | obscura | 4 |
| 586 | noches | 4 |
| 587 | nabo | 4 |
| 588 | miró | 4 |
| 589 | mes | 4 |
| 590 | marido | 4 |
| 591 | mañas | 4 |
| 592 | maltratado | 4 |
| 593 | malo | 4 |
| 594 | maldad | 4 |
| 595 | lumbre | 4 |
| 596 | lugares | 4 |
| 597 | lóbrega | 4 |
| 598 | llorando | 4 |
| 599 | llegó | 4 |
| 600 | llegando | 4 |
| 601 | lengua | 4 |
| 602 | lástima | 4 |
| 603 | jamás | 4 |
| 604 | ido | 4 |
| 605 | hubo | 4 |
| 606 | hubiera | 4 |
| 607 | hube | 4 |
| 608 | hiciera | 4 |
| 609 | hemos | 4 |
| 610 | hallaba | 4 |
| 611 | habrá | 4 |
| 612 | hablaba | 4 |
| 613 | gesto | 4 |
| 614 | ganancia | 4 |
| 615 | fuimos | 4 |
| 616 | fueron | 4 |
| 617 | fin | 4 |
| 618 | fardel | 4 |
| 619 | falsas | 4 |
| 620 | estuvo | 4 |
| 621 | éstos | 4 |
| 622 | estas | 4 |
| 623 | están | 4 |
| 624 | estado | 4 |
| 625 | escalona | 4 |
| 626 | entrando | 4 |
| 627 | entrada | 4 |
| 628 | echado | 4 |
| 629 | echaba | 4 |
| 630 | dormir | 4 |
| 631 | dónde | 4 |
| 632 | dinero | 4 |
| 633 | dijeron | 4 |
| 634 | diese | 4 |
| 635 | dichos | 4 |
| 636 | desto | 4 |
| 637 | destas | 4 |
| 638 | descanso | 4 |
| 639 | dellos | 4 |
| 640 | dello | 4 |
| 641 | delante | 4 |
| 642 | dejo | 4 |
| 643 | dejado | 4 |
| 644 | dejaba | 4 |
| 645 | decís | 4 |
| 646 | debió | 4 |
| 647 | darme | 4 |
| 648 | cuánto | 4 |
| 649 | cuán | 4 |
| 650 | cruel | 4 |
| 651 | corazón | 4 |
| 652 | continente | 4 |
| 653 | conmigo | 4 |
| 654 | comienza | 4 |
| 655 | color | 4 |
| 656 | cinco | 4 |
| 657 | ciertos | 4 |
| 658 | cierra | 4 |
| 659 | cerrar | 4 |
| 660 | cerca | 4 |
| 661 | cargo | 4 |
| 662 | cámara | 4 |
| 663 | calzas | 4 |
| 664 | calor | 4 |
| 665 | buscar | 4 |
| 666 | buscaba | 4 |
| 667 | bolsa | 4 |
| 668 | bodigo | 4 |
| 669 | bestias | 4 |
| 670 | beber | 4 |
| 671 | bajo | 4 |
| 672 | ayuda | 4 |
| 673 | arriba | 4 |
| 674 | aquellas | 4 |
| 675 | aprovechaba | 4 |
| 676 | amor | 4 |
| 677 | agujeros | 4 |
| 678 | agujero | 4 |
| 679 | acuerdo | 4 |
| 680 | acá | 4 |
| 681 | abro | 4 |
| 682 | yendo | 3 |
| 683 | vuestras | 3 |
| 684 | voz | 3 |
| 685 | voluntad | 3 |
| 686 | vinieron | 3 |
| 687 | viniendo | 3 |
| 688 | villa | 3 |
| 689 | viejas | 3 |
| 690 | verá | 3 |
| 691 | venganza | 3 |
| 692 | venga | 3 |
| 693 | ven | 3 |
| 694 | veinte | 3 |
| 695 | vecino | 3 |
| 696 | vaca | 3 |
| 697 | uvas | 3 |
| 698 | uña | 3 |
| 699 | tuvo | 3 |
| 700 | tuviese | 3 |
| 701 | tuvieron | 3 |
| 702 | tuviera | 3 |
| 703 | trueco | 3 |
| 704 | tripas | 3 |
| 705 | treinta | 3 |
| 706 | traidor | 3 |
| 707 | traído | 3 |
| 708 | tomado | 3 |
| 709 | tomaban | 3 |
| 710 | tomaba | 3 |
| 711 | testigos | 3 |
| 712 | teniendo | 3 |
| 713 | tablillas | 3 |
| 714 | suplico | 3 |
| 715 | suerte | 3 |
| 716 | suele | 3 |
| 717 | subió | 3 |
| 718 | sotil | 3 |
| 719 | sólo | 3 |
| 720 | solar | 3 |
| 721 | solamente | 3 |
| 722 | sois | 3 |
| 723 | servicio | 3 |
| 724 | será | 3 |
| 725 | sepultura | 3 |
| 726 | sentí | 3 |
| 727 | saqué | 3 |
| 728 | santo | 3 |
| 729 | sant | 3 |
| 730 | salud | 3 |
| 731 | salto | 3 |
| 732 | sacaba | 3 |
| 733 | sabes | 3 |
| 734 | ropa | 3 |
| 735 | rogado | 3 |
| 736 | rogaba | 3 |
| 737 | rodillas | 3 |
| 738 | risueño | 3 |
| 739 | rey | 3 |
| 740 | reverencia | 3 |
| 741 | reñir | 3 |
| 742 | real | 3 |
| 743 | ratonera | 3 |
| 744 | rato | 3 |
| 745 | quisiese | 3 |
| 746 | quinto | 3 |
| 747 | quedó | 3 |
| 748 | quedar | 3 |
| 749 | quedado | 3 |
| 750 | púseme | 3 |
| 751 | puestas | 3 |
| 752 | principal | 3 |
| 753 | predica | 3 |
| 754 | posible | 3 |
| 755 | portal | 3 |
| 756 | poniendo | 3 |
| 757 | pobres | 3 |
| 758 | plega | 3 |
| 759 | pieza | 3 |
| 760 | pesar | 3 |
| 761 | persecución | 3 |
| 762 | perdido | 3 |
| 763 | pensó | 3 |
| 764 | pensara | 3 |
| 765 | pedir | 3 |
| 766 | pedía | 3 |
| 767 | pecado | 3 |
| 768 | paz | 3 |
| 769 | pasión | 3 |
| 770 | pasan | 3 |
| 771 | pasado | 3 |
| 772 | pasada | 3 |
| 773 | partes | 3 |
| 774 | paredes | 3 |
| 775 | pared | 3 |
| 776 | palabras | 3 |
| 777 | paja | 3 |
| 778 | osaba | 3 |
| 779 | oro | 3 |
| 780 | oraciones | 3 |
| 781 | oír | 3 |
| 782 | obras | 3 |
| 783 | noticia | 3 |
| 784 | nombre | 3 |
| 785 | negocios | 3 |
| 786 | necesidad | 3 |
| 787 | necesario | 3 |
| 788 | nariz | 3 |
| 789 | mujercillas | 3 |
| 790 | mozuelo | 3 |
| 791 | mozos | 3 |
| 792 | mostró | 3 |
| 793 | moría | 3 |
| 794 | mirase | 3 |
| 795 | mirando | 3 |
| 796 | mientras | 3 |
| 797 | mezquino | 3 |
| 798 | meses | 3 |
| 799 | mesa | 3 |
| 800 | medias | 3 |
| 801 | manda | 3 |
| 802 | males | 3 |
| 803 | llorar | 3 |
| 804 | llevan | 3 |
| 805 | llevado | 3 |
| 806 | llegóse | 3 |
| 807 | libras | 3 |
| 808 | levantóse | 3 |
| 809 | letras | 3 |
| 810 | lenguas | 3 |
| 811 | largo | 3 |
| 812 | lado | 3 |
| 813 | justo | 3 |
| 814 | irse | 3 |
| 815 | inventario | 3 |
| 816 | inocente | 3 |
| 817 | ingenio | 3 |
| 818 | huéspedes | 3 |
| 819 | holgaba | 3 |
| 820 | hijos | 3 |
| 821 | hicieron | 3 |
| 822 | hermanico | 3 |
| 823 | hechas | 3 |
| 824 | hayas | 3 |
| 825 | hallo | 3 |
| 826 | hallase | 3 |
| 827 | hago | 3 |
| 828 | haciendo | 3 |
| 829 | hacia | 3 |
| 830 | hablar | 3 |
| 831 | hablando | 3 |
| 832 | habíamos | 3 |
| 833 | gusto | 3 |
| 834 | gracia | 3 |
| 835 | golpe | 3 |
| 836 | gentil | 3 |
| 837 | gentes | 3 |
| 838 | garganta | 3 |
| 839 | gana | 3 |
| 840 | fuime | 3 |
| 841 | fuesen | 3 |
| 842 | fraile | 3 |
| 843 | forma | 3 |
| 844 | flaqueza | 3 |
| 845 | fatigas | 3 |
| 846 | falsedad | 3 |
| 847 | extenso | 3 |
| 848 | evitar | 3 |
| 849 | estuviese | 3 |
| 850 | estoy | 3 |
| 851 | estotro | 3 |
| 852 | estábamos | 3 |
| 853 | espero | 3 |
| 854 | espantado | 3 |
| 855 | espada | 3 |
| 856 | entrase | 3 |
| 857 | enojo | 3 |
| 858 | echando | 3 |
| 859 | durmiendo | 3 |
| 860 | duda | 3 |
| 861 | dormido | 3 |
| 862 | dormía | 3 |
| 863 | dormí | 3 |
| 864 | donaires | 3 |
| 865 | doce | 3 |
| 866 | dineros | 3 |
| 867 | diligente | 3 |
| 868 | diligencias | 3 |
| 869 | diligencia | 3 |
| 870 | devoto | 3 |
| 871 | deuda | 3 |
| 872 | desastre | 3 |
| 873 | derecha | 3 |
| 874 | dedos | 3 |
| 875 | decirle | 3 |
| 876 | dé | 3 |
| 877 | cuidado | 3 |
| 878 | cuchillo | 3 |
| 879 | cuántos | 3 |
| 880 | cuantos | 3 |
| 881 | cuantas | 3 |
| 882 | creyó | 3 |
| 883 | conveniente | 3 |
| 884 | conocimiento | 3 |
| 885 | conocí | 3 |
| 886 | comida | 3 |
| 887 | comíamos | 3 |
| 888 | comí | 3 |
| 889 | comenzamos | 3 |
| 890 | comencé | 3 |
| 891 | come | 3 |
| 892 | clavos | 3 |
| 893 | ciertas | 3 |
| 894 | cenar | 3 |
| 895 | cayese | 3 |
| 896 | causa | 3 |
| 897 | capellán | 3 |
| 898 | caer | 3 |
| 899 | caballero | 3 |
| 900 | buscando | 3 |
| 901 | busca | 3 |
| 902 | burlas | 3 |
| 903 | burla | 3 |
| 904 | bonete | 3 |
| 905 | bondad | 3 |
| 906 | blanco | 3 |
| 907 | bebo | 3 |
| 908 | bastaban | 3 |
| 909 | avariento | 3 |
| 910 | asiento | 3 |
| 911 | asido | 3 |
| 912 | asenté | 3 |
| 913 | artes | 3 |
| 914 | aquéllos | 3 |
| 915 | aprovecha | 3 |
| 916 | apenas | 3 |
| 917 | ante | 3 |
| 918 | amigos | 3 |
| 919 | amigo | 3 |
| 920 | ambos | 3 |
| 921 | allende | 3 |
| 922 | alforjas | 3 |
| 923 | alfamar | 3 |
| 924 | alcanzar | 3 |
| 925 | ahí | 3 |
| 926 | acordaron | 3 |
| 927 | abre | 3 |
| 928 | zapatos | 2 |
| 929 | zaide | 2 |
| 930 | yéndose | 2 |
| 931 | vuelven | 2 |
| 932 | vueltas | 2 |
| 933 | voy | 2 |
| 934 | vosotros | 2 |
| 935 | vivo | 2 |
| 936 | vivienda | 2 |
| 937 | vivían | 2 |
| 938 | viví | 2 |
| 939 | vives | 2 |
| 940 | vive | 2 |
| 941 | viuda | 2 |
| 942 | visajes | 2 |
| 943 | virtud | 2 |
| 944 | vínose | 2 |
| 945 | vinos | 2 |
| 946 | vime | 2 |
| 947 | viese | 2 |
| 948 | vientre | 2 |
| 949 | vestir | 2 |
| 950 | verás | 2 |
| 951 | vengan | 2 |
| 952 | vendía | 2 |
| 953 | veis | 2 |
| 954 | vecinas | 2 |
| 955 | vean | 2 |
| 956 | van | 2 |
| 957 | valga | 2 |
| 958 | valer | 2 |
| 959 | uva | 2 |
| 960 | uso | 2 |
| 961 | usé | 2 |
| 962 | usar | 2 |
| 963 | usan | 2 |
| 964 | usaba | 2 |
| 965 | uñas | 2 |
| 966 | trujo | 2 |
| 967 | trote | 2 |
| 968 | trocar | 2 |
| 969 | tristeza | 2 |
| 970 | trato | 2 |
| 971 | trampilla | 2 |
| 972 | trajese | 2 |
| 973 | traían | 2 |
| 974 | tragos | 2 |
| 975 | traer | 2 |
| 976 | traen | 2 |
| 977 | trabajosa | 2 |
| 978 | tórnase | 2 |
| 979 | tornaba | 2 |
| 980 | topo | 2 |
| 981 | topé | 2 |
| 982 | topase | 2 |
| 983 | topar | 2 |
| 984 | tomóle | 2 |
| 985 | tomase | 2 |
| 986 | tocaba | 2 |
| 987 | tirase | 2 |
| 988 | tio | 2 |
| 989 | tenéis | 2 |
| 990 | tendido | 2 |
| 991 | tasa | 2 |
| 992 | tantos | 2 |
| 993 | tampoco | 2 |
| 994 | talabarte | 2 |
| 995 | taberna | 2 |
| 996 | supo | 2 |
| 997 | sufrir | 2 |
| 998 | suficiencia | 2 |
| 999 | sucedido | 2 |
| 1000 | subir | 2 |
| 1001 | subía | 2 |
| 1002 | spíritu | 2 |
| 1003 | sospecha | 2 |
| 1004 | solícito | 2 |
| 1005 | sogas | 2 |
| 1006 | soga | 2 |
| 1007 | socorrer | 2 |
| 1008 | sobrino | 2 |
| 1009 | sobredicho | 2 |
| 1010 | so | 2 |
| 1011 | sintieron | 2 |
| 1012 | singular | 2 |
| 1013 | silencio | 2 |
| 1014 | silbaba | 2 |
| 1015 | siete | 2 |
| 1016 | servidor | 2 |
| 1017 | servido | 2 |
| 1018 | servía | 2 |
| 1019 | sermones | 2 |
| 1020 | sentóse | 2 |
| 1021 | sentir | 2 |
| 1022 | sentencia | 2 |
| 1023 | sentéme | 2 |
| 1024 | senos | 2 |
| 1025 | seno | 2 |
| 1026 | semblante | 2 |
| 1027 | semana | 2 |
| 1028 | seis | 2 |
| 1029 | segundo | 2 |
| 1030 | seáis | 2 |
| 1031 | sartal | 2 |
| 1032 | santiguándose | 2 |
| 1033 | salieron | 2 |
| 1034 | salía | 2 |
| 1035 | salí | 2 |
| 1036 | saldría | 2 |
| 1037 | sacudir | 2 |
| 1038 | sacarlo | 2 |
| 1039 | sabroso | 2 |
| 1040 | sabrosísimo | 2 |
| 1041 | sabor | 2 |
| 1042 | sábados | 2 |
| 1043 | ruines | 2 |
| 1044 | rompía | 2 |
| 1045 | romper | 2 |
| 1046 | romance | 2 |
| 1047 | risa | 2 |
| 1048 | respondióme | 2 |
| 1049 | resonar | 2 |
| 1050 | reloj | 2 |
| 1051 | relación | 2 |
| 1052 | reír | 2 |
| 1053 | reían | 2 |
| 1054 | regla | 2 |
| 1055 | recuesta | 2 |
| 1056 | recibió | 2 |
| 1057 | recibía | 2 |
| 1058 | recaudo | 2 |
| 1059 | rebanadas | 2 |
| 1060 | reales | 2 |
| 1061 | razonable | 2 |
| 1062 | ratonado | 2 |
| 1063 | ración | 2 |
| 1064 | quitárselo | 2 |
| 1065 | quita | 2 |
| 1066 | quisieron | 2 |
| 1067 | quiere | 2 |
| 1068 | queriendo | 2 |
| 1069 | queréis | 2 |
| 1070 | quedé | 2 |
| 1071 | quebrar | 2 |
| 1072 | púsome | 2 |
| 1073 | pura | 2 |
| 1074 | puestos | 2 |
| 1075 | puesta | 2 |
| 1076 | puertas | 2 |
| 1077 | puedo | 2 |
| 1078 | puede | 2 |
| 1079 | pudiera | 2 |
| 1080 | proveer | 2 |
| 1081 | prometo | 2 |
| 1082 | procuró | 2 |
| 1083 | principio | 2 |
| 1084 | primeros | 2 |
| 1085 | primera | 2 |
| 1086 | preso | 2 |
| 1087 | presentes | 2 |
| 1088 | preguntóme | 2 |
| 1089 | preguntó | 2 |
| 1090 | preguntándome | 2 |
| 1091 | preguntaban | 2 |
| 1092 | preguntaba | 2 |
| 1093 | pregón | 2 |
| 1094 | predicar | 2 |
| 1095 | postura | 2 |
| 1096 | portales | 2 |
| 1097 | ponerme | 2 |
| 1098 | pocas | 2 |
| 1099 | pluguiera | 2 |
| 1100 | plato | 2 |
| 1101 | plata | 2 |
| 1102 | pilar | 2 |
| 1103 | pidió | 2 |
| 1104 | pesa | 2 |
| 1105 | persuadido | 2 |
| 1106 | personas | 2 |
| 1107 | persecuciones | 2 |
| 1108 | pero | 2 |
| 1109 | permitido | 2 |
| 1110 | perjuicio | 2 |
| 1111 | perdones | 2 |
| 1112 | perdonar | 2 |
| 1113 | perdidas | 2 |
| 1114 | peras | 2 |
| 1115 | pensado | 2 |
| 1116 | pedí | 2 |
| 1117 | patio | 2 |
| 1118 | pasos | 2 |
| 1119 | pasé | 2 |
| 1120 | pasamos | 2 |
| 1121 | pasados | 2 |
| 1122 | parto | 2 |
| 1123 | partir | 2 |
| 1124 | partimos | 2 |
| 1125 | partido | 2 |
| 1126 | partía | 2 |
| 1127 | paró | 2 |
| 1128 | pariente | 2 |
| 1129 | pareció | 2 |
| 1130 | pareciéndome | 2 |
| 1131 | pareciéndole | 2 |
| 1132 | palomar | 2 |
| 1133 | palmo | 2 |
| 1134 | pagados | 2 |
| 1135 | padecía | 2 |
| 1136 | padecer | 2 |
| 1137 | padecen | 2 |
| 1138 | orden | 2 |
| 1139 | olla | 2 |
| 1140 | olé | 2 |
| 1141 | oído | 2 |
| 1142 | oían | 2 |
| 1143 | obra | 2 |
| 1144 | noté | 2 |
| 1145 | nosotros | 2 |
| 1146 | niños | 2 |
| 1147 | ningún | 2 |
| 1148 | negro | 2 |
| 1149 | naturales | 2 |
| 1150 | mudó | 2 |
| 1151 | mostréle | 2 |
| 1152 | mortuorios | 2 |
| 1153 | moros | 2 |
| 1154 | mismo | 2 |
| 1155 | mísero | 2 |
| 1156 | mires | 2 |
| 1157 | miré | 2 |
| 1158 | mirá | 2 |
| 1159 | mía | 2 |
| 1160 | metía | 2 |
| 1161 | mesonera | 2 |
| 1162 | mejores | 2 |
| 1163 | mediodía | 2 |
| 1164 | medicina | 2 |
| 1165 | media | 2 |
| 1166 | matase | 2 |
| 1167 | matar | 2 |
| 1168 | mataba | 2 |
| 1169 | maravedí | 2 |
| 1170 | maña | 2 |
| 1171 | manténgaos | 2 |
| 1172 | mantenga | 2 |
| 1173 | manjar | 2 |
| 1174 | manga | 2 |
| 1175 | maneras | 2 |
| 1176 | mandóme | 2 |
| 1177 | mandaban | 2 |
| 1178 | malos | 2 |
| 1179 | malicia | 2 |
| 1180 | maldecía | 2 |
| 1181 | majestad | 2 |
| 1182 | maestro | 2 |
| 1183 | madera | 2 |
| 1184 | lobo | 2 |
| 1185 | llovía | 2 |
| 1186 | lleva | 2 |
| 1187 | llenas | 2 |
| 1188 | llena | 2 |
| 1189 | llegué | 2 |
| 1190 | llegaron | 2 |
| 1191 | llegar | 2 |
| 1192 | llegamos | 2 |
| 1193 | llegaba | 2 |
| 1194 | llega | 2 |
| 1195 | llamó | 2 |
| 1196 | limpias | 2 |
| 1197 | libre | 2 |
| 1198 | levantado | 2 |
| 1199 | latín | 2 |
| 1200 | lastimado | 2 |
| 1201 | lana | 2 |
| 1202 | lamentaba | 2 |
| 1203 | ladrón | 2 |
| 1204 | juraré | 2 |
| 1205 | juramento | 2 |
| 1206 | junto | 2 |
| 1207 | juego | 2 |
| 1208 | juan | 2 |
| 1209 | jarrazo | 2 |
| 1210 | invierno | 2 |
| 1211 | intención | 2 |
| 1212 | insigne | 2 |
| 1213 | infinitas | 2 |
| 1214 | indulgencia | 2 |
| 1215 | imposible | 2 |
| 1216 | íbamos | 2 |
| 1217 | huesos | 2 |
| 1218 | huelgo | 2 |
| 1219 | hombro | 2 |
| 1220 | hobiese | 2 |
| 1221 | hobiera | 2 |
| 1222 | hízonos | 2 |
| 1223 | hija | 2 |
| 1224 | hiciese | 2 |
| 1225 | hermanos | 2 |
| 1226 | haya | 2 |
| 1227 | hartura | 2 |
| 1228 | hartas | 2 |
| 1229 | hará | 2 |
| 1230 | hallóse | 2 |
| 1231 | halle | 2 |
| 1232 | halda | 2 |
| 1233 | hacían | 2 |
| 1234 | hacerle | 2 |
| 1235 | habilidad | 2 |
| 1236 | habido | 2 |
| 1237 | habéis | 2 |
| 1238 | gozoso | 2 |
| 1239 | gozar | 2 |
| 1240 | gota | 2 |
| 1241 | golpes | 2 |
| 1242 | gato | 2 |
| 1243 | garrote | 2 |
| 1244 | garrotazo | 2 |
| 1245 | ganaba | 2 |
| 1246 | galgo | 2 |
| 1247 | fueran | 2 |
| 1248 | fuentecilla | 2 |
| 1249 | fuego | 2 |
| 1250 | fingiendo | 2 |
| 1251 | fiestas | 2 |
| 1252 | feneció | 2 |
| 1253 | faltaba | 2 |
| 1254 | falsario | 2 |
| 1255 | estuviera | 2 |
| 1256 | estruendo | 2 |
| 1257 | estorbasen | 2 |
| 1258 | estilo | 2 |
| 1259 | estados | 2 |
| 1260 | especialmente | 2 |
| 1261 | esparto | 2 |
| 1262 | ese | 2 |
| 1263 | escalón | 2 |
| 1264 | enviado | 2 |
| 1265 | entré | 2 |
| 1266 | entra | 2 |
| 1267 | entera | 2 |
| 1268 | entendimiento | 2 |
| 1269 | enjuto | 2 |
| 1270 | enfermedad | 2 |
| 1271 | enemigo | 2 |
| 1272 | encontré | 2 |
| 1273 | encomendó | 2 |
| 1274 | echó | 2 |
| 1275 | echada | 2 |
| 1276 | duro | 2 |
| 1277 | durase | 2 |
| 1278 | dulce | 2 |
| 1279 | don | 2 |
| 1280 | divina | 2 |
| 1281 | disposición | 2 |
| 1282 | disimules | 2 |
| 1283 | diome | 2 |
| 1284 | dimos | 2 |
| 1285 | dígote | 2 |
| 1286 | diéronme | 2 |
| 1287 | dieron | 2 |
| 1288 | devotamente | 2 |
| 1289 | detrás | 2 |
| 1290 | determinó | 2 |
| 1291 | determiné | 2 |
| 1292 | desventurado | 2 |
| 1293 | despedir | 2 |
| 1294 | despedido | 2 |
| 1295 | deso | 2 |
| 1296 | deshora | 2 |
| 1297 | desdichada | 2 |
| 1298 | descuidado | 2 |
| 1299 | descalabrado | 2 |
| 1300 | desastres | 2 |
| 1301 | derribado | 2 |
| 1302 | delicadamente | 2 |
| 1303 | dejase | 2 |
| 1304 | dejará | 2 |
| 1305 | dejan | 2 |
| 1306 | dejalle | 2 |
| 1307 | defuntos | 2 |
| 1308 | defensa | 2 |
| 1309 | dedo | 2 |
| 1310 | declaro | 2 |
| 1311 | decíame | 2 |
| 1312 | debría | 2 |
| 1313 | debían | 2 |
| 1314 | deben | 2 |
| 1315 | dará | 2 |
| 1316 | dadas | 2 |
| 1317 | curas | 2 |
| 1318 | cumplir | 2 |
| 1319 | cumplió | 2 |
| 1320 | culpado | 2 |
| 1321 | culebras | 2 |
| 1322 | cuerno | 2 |
| 1323 | cuasi | 2 |
| 1324 | cuarto | 2 |
| 1325 | cuántas | 2 |
| 1326 | cuánta | 2 |
| 1327 | cristianos | 2 |
| 1328 | crió | 2 |
| 1329 | criaturas | 2 |
| 1330 | criar | 2 |
| 1331 | costura | 2 |
| 1332 | costumbre | 2 |
| 1333 | costado | 2 |
| 1334 | cosillas | 2 |
| 1335 | cortezas | 2 |
| 1336 | coro | 2 |
| 1337 | conversación | 2 |
| 1338 | convento | 2 |
| 1339 | contrario | 2 |
| 1340 | contra | 2 |
| 1341 | contaré | 2 |
| 1342 | consideración | 2 |
| 1343 | consideraba | 2 |
| 1344 | consejo | 2 |
| 1345 | conocido | 2 |
| 1346 | conocía | 2 |
| 1347 | conocer | 2 |
| 1348 | confianza | 2 |
| 1349 | confesó | 2 |
| 1350 | conde | 2 |
| 1351 | conciencia | 2 |
| 1352 | concejo | 2 |
| 1353 | comes | 2 |
| 1354 | comendador | 2 |
| 1355 | comen | 2 |
| 1356 | comamos | 2 |
| 1357 | collar | 2 |
| 1358 | colchón | 2 |
| 1359 | claramente | 2 |
| 1360 | cierro | 2 |
| 1361 | cien | 2 |
| 1362 | cerró | 2 |
| 1363 | cerraba | 2 |
| 1364 | cera | 2 |
| 1365 | cebollas | 2 |
| 1366 | cayó | 2 |
| 1367 | castilla | 2 |
| 1368 | castigo | 2 |
| 1369 | castigaldo | 2 |
| 1370 | castigado | 2 |
| 1371 | casilla | 2 |
| 1372 | cargado | 2 |
| 1373 | carga | 2 |
| 1374 | cañizo | 2 |
| 1375 | cañas | 2 |
| 1376 | candado | 2 |
| 1377 | cambio | 2 |
| 1378 | calles | 2 |
| 1379 | calla | 2 |
| 1380 | calabazada | 2 |
| 1381 | caído | 2 |
| 1382 | caía | 2 |
| 1383 | cabía | 2 |
| 1384 | cabecera | 2 |
| 1385 | cabe | 2 |
| 1386 | caballos | 2 |
| 1387 | buldero | 2 |
| 1388 | bocados | 2 |
| 1389 | bienes | 2 |
| 1390 | besos | 2 |
| 1391 | besar | 2 |
| 1392 | bendito | 2 |
| 1393 | bendición | 2 |
| 1394 | bebimos | 2 |
| 1395 | bebía | 2 |
| 1396 | beben | 2 |
| 1397 | barrer | 2 |
| 1398 | balde | 2 |
| 1399 | bajó | 2 |
| 1400 | baja | 2 |
| 1401 | azote | 2 |
| 1402 | ayude | 2 |
| 1403 | ayudar | 2 |
| 1404 | ayudaba | 2 |
| 1405 | auxilio | 2 |
| 1406 | atrás | 2 |
| 1407 | asno | 2 |
| 1408 | asador | 2 |
| 1409 | arrojar | 2 |
| 1410 | arrepentido | 2 |
| 1411 | armas | 2 |
| 1412 | aquesta | 2 |
| 1413 | aquélla | 2 |
| 1414 | aprovechar | 2 |
| 1415 | animal | 2 |
| 1416 | ángel | 2 |
| 1417 | anduve | 2 |
| 1418 | alzando | 2 |
| 1419 | altos | 2 |
| 1420 | alteración | 2 |
| 1421 | almorzar | 2 |
| 1422 | almorzado | 2 |
| 1423 | alegres | 2 |
| 1424 | alcanzaron | 2 |
| 1425 | alcaldes | 2 |
| 1426 | alcalde | 2 |
| 1427 | ajena | 2 |
| 1428 | aire | 2 |
| 1429 | adversa | 2 |
| 1430 | adorar | 2 |
| 1431 | acuérdome | 2 |
| 1432 | acostumbrado | 2 |
| 1433 | acordó | 2 |
| 1434 | acordé | 2 |
| 1435 | aceña | 2 |
| 1436 | acaecieron | 2 |
| 1437 | acaecido | 2 |
| 1438 | acabó | 2 |
| 1439 | acabamos | 2 |
| 1440 | acababa | 2 |
| 1441 | abriese | 2 |
| 1442 | abierta | 2 |
| 1443 | abajar | 2 |
| 1444 | zozobra | 1 |
| 1445 | zapatero | 1 |
| 1446 | yerba | 1 |
| 1447 | vuestros | 1 |
| 1448 | vuelvo | 1 |
| 1449 | vuélvela | 1 |
| 1450 | vuelta | 1 |
| 1451 | voyme | 1 |
| 1452 | vótote | 1 |
| 1453 | volvíme | 1 |
| 1454 | volviese | 1 |
| 1455 | volvieron | 1 |
| 1456 | volviendo | 1 |
| 1457 | volví | 1 |
| 1458 | volverle | 1 |
| 1459 | volvamos | 1 |
| 1460 | vivirás | 1 |
| 1461 | viviente | 1 |
| 1462 | vivía | 1 |
| 1463 | viven | 1 |
| 1464 | viva | 1 |
| 1465 | vístese | 1 |
| 1466 | vistas | 1 |
| 1467 | visitar | 1 |
| 1468 | virtuosos | 1 |
| 1469 | viole | 1 |
| 1470 | viniesen | 1 |
| 1471 | viniere | 1 |
| 1472 | vímonos | 1 |
| 1473 | villanos | 1 |
| 1474 | villano | 1 |
| 1475 | vigilancia | 1 |
| 1476 | viera | 1 |
| 1477 | viéndose | 1 |
| 1478 | viejos | 1 |
| 1479 | vido | 1 |
| 1480 | vidas | 1 |
| 1481 | victorioso | 1 |
| 1482 | vicio | 1 |
| 1483 | vianda | 1 |
| 1484 | vezado | 1 |
| 1485 | veví | 1 |
| 1486 | vete | 1 |
| 1487 | vestido | 1 |
| 1488 | vesla | 1 |
| 1489 | ves | 1 |
| 1490 | verlo | 1 |
| 1491 | verle | 1 |
| 1492 | vergüenza | 1 |
| 1493 | vergonzosa | 1 |
| 1494 | veremos | 1 |
| 1495 | veréis | 1 |
| 1496 | veré | 1 |
| 1497 | verdiniales | 1 |
| 1498 | verdadero | 1 |
| 1499 | verdaderamente | 1 |
| 1500 | verdadera | 1 |
| 1501 | verano | 1 |
| 1502 | vente | 1 |
| 1503 | veniste | 1 |
| 1504 | venimos | 1 |
| 1505 | venidera | 1 |
| 1506 | vengo | 1 |
| 1507 | vengarse | 1 |
| 1508 | venecia | 1 |
| 1509 | vendimiador | 1 |
| 1510 | vendí | 1 |
| 1511 | vender | 1 |
| 1512 | venden | 1 |
| 1513 | vemos | 1 |
| 1514 | vello | 1 |
| 1515 | velle | 1 |
| 1516 | vejez | 1 |
| 1517 | veían | 1 |
| 1518 | veía | 1 |
| 1519 | vees | 1 |
| 1520 | veen | 1 |
| 1521 | vee | 1 |
| 1522 | vecindad | 1 |
| 1523 | veáis | 1 |
| 1524 | vea | 1 |
| 1525 | vayan | 1 |
| 1526 | vasija | 1 |
| 1527 | vara | 1 |
| 1528 | vano | 1 |
| 1529 | vamos | 1 |
| 1530 | valor | 1 |
| 1531 | valladolid | 1 |
| 1532 | valladar | 1 |
| 1533 | validas | 1 |
| 1534 | valía | 1 |
| 1535 | válete | 1 |
| 1536 | valerosa | 1 |
| 1537 | valencia | 1 |
| 1538 | vale | 1 |
| 1539 | valdrían | 1 |
| 1540 | vaina | 1 |
| 1541 | usaría | 1 |
| 1542 | usado | 1 |
| 1543 | usada | 1 |
| 1544 | usa | 1 |
| 1545 | ungüentos | 1 |
| 1546 | unción | 1 |
| 1547 | ufano | 1 |
| 1548 | tuyo | 1 |
| 1549 | tuviste | 1 |
| 1550 | turroneras | 1 |
| 1551 | turóme | 1 |
| 1552 | turbarse | 1 |
| 1553 | turan | 1 |
| 1554 | turaba | 1 |
| 1555 | tulio | 1 |
| 1556 | truhán | 1 |
| 1557 | trueque | 1 |
| 1558 | trueno | 1 |
| 1559 | tropezón | 1 |
| 1560 | tronchos | 1 |
| 1561 | trompa | 1 |
| 1562 | triunfa | 1 |
| 1563 | tripería | 1 |
| 1564 | trigo | 1 |
| 1565 | trepa | 1 |
| 1566 | trecho | 1 |
| 1567 | trece | 1 |
| 1568 | trebejando | 1 |
| 1569 | travesemos | 1 |
| 1570 | tratase | 1 |
| 1571 | trataron | 1 |
| 1572 | trataba | 1 |
| 1573 | trastornábalas | 1 |
| 1574 | traspuso | 1 |
| 1575 | trasponer | 1 |
| 1576 | trasgo | 1 |
| 1577 | trapos | 1 |
| 1578 | tranzada | 1 |
| 1579 | transportado | 1 |
| 1580 | transido | 1 |
| 1581 | traje | 1 |
| 1582 | traigo | 1 |
| 1583 | traidores | 1 |
| 1584 | traíame | 1 |
| 1585 | traéis | 1 |
| 1586 | trae | 1 |
| 1587 | trabaron | 1 |
| 1588 | trabajada | 1 |
| 1589 | trabado | 1 |
| 1590 | tortilla | 1 |
| 1591 | torrijos | 1 |
| 1592 | torreznos | 1 |
| 1593 | tornóse | 1 |
| 1594 | tórnome | 1 |
| 1595 | tornóla | 1 |
| 1596 | torno | 1 |
| 1597 | tornéme | 1 |
| 1598 | tornaron | 1 |
| 1599 | tornar | 1 |
| 1600 | tornado | 1 |
| 1601 | tornada | 1 |
| 1602 | tornábase | 1 |
| 1603 | tornábale | 1 |
| 1604 | torna | 1 |
| 1605 | torcella | 1 |
| 1606 | toqué | 1 |
| 1607 | topóme | 1 |
| 1608 | tope | 1 |
| 1609 | topasen | 1 |
| 1610 | toparon | 1 |
| 1611 | toparía | 1 |
| 1612 | topamos | 1 |
| 1613 | topaba | 1 |
| 1614 | tono | 1 |
| 1615 | tomóse | 1 |
| 1616 | tomóme | 1 |
| 1617 | tomóla | 1 |
| 1618 | toméis | 1 |
| 1619 | tomasen | 1 |
| 1620 | tomás | 1 |
| 1621 | tomaron | 1 |
| 1622 | tomarla | 1 |
| 1623 | tomando | 1 |
| 1624 | toman | 1 |
| 1625 | tomalle | 1 |
| 1626 | tomalla | 1 |
| 1627 | tolondrones | 1 |
| 1628 | tocó | 1 |
| 1629 | tocino | 1 |
| 1630 | tocase | 1 |
| 1631 | tocar | 1 |
| 1632 | tocantes | 1 |
| 1633 | tocándolos | 1 |
| 1634 | título | 1 |
| 1635 | tiraban | 1 |
| 1636 | testimonio | 1 |
| 1637 | testigo | 1 |
| 1638 | tesoro | 1 |
| 1639 | ternía | 1 |
| 1640 | terciopelo | 1 |
| 1641 | terciana | 1 |
| 1642 | tentóla | 1 |
| 1643 | tentó | 1 |
| 1644 | tentando | 1 |
| 1645 | tentado | 1 |
| 1646 | teniente | 1 |
| 1647 | tenidas | 1 |
| 1648 | teníamos | 1 |
| 1649 | teníades | 1 |
| 1650 | tenerte | 1 |
| 1651 | tenerlos | 1 |
| 1652 | tenerla | 1 |
| 1653 | tenella | 1 |
| 1654 | tendimos | 1 |
| 1655 | tendida | 1 |
| 1656 | templados | 1 |
| 1657 | temo | 1 |
| 1658 | temía | 1 |
| 1659 | temerosos | 1 |
| 1660 | temer | 1 |
| 1661 | tela | 1 |
| 1662 | tejía | 1 |
| 1663 | tejares | 1 |
| 1664 | teja | 1 |
| 1665 | tardé | 1 |
| 1666 | tardanza | 1 |
| 1667 | taparlo | 1 |
| 1668 | tapaba | 1 |
| 1669 | tañer | 1 |
| 1670 | talla | 1 |
| 1671 | tales | 1 |
| 1672 | tajo | 1 |
| 1673 | tachuelas | 1 |
| 1674 | tabla | 1 |
| 1675 | sustentar | 1 |
| 1676 | susodicho | 1 |
| 1677 | suplicasen | 1 |
| 1678 | suplicaron | 1 |
| 1679 | suplicarle | 1 |
| 1680 | suplicando | 1 |
| 1681 | suplicalle | 1 |
| 1682 | supieses | 1 |
| 1683 | supiese | 1 |
| 1684 | supiera | 1 |
| 1685 | sufrirían | 1 |
| 1686 | sufriría | 1 |
| 1687 | sufriré | 1 |
| 1688 | sufrí | 1 |
| 1689 | sufres | 1 |
| 1690 | sufre | 1 |
| 1691 | suficiente | 1 |
| 1692 | suelto | 1 |
| 1693 | suelta | 1 |
| 1694 | sudores | 1 |
| 1695 | sudado | 1 |
| 1696 | sucedió | 1 |
| 1697 | sucediere | 1 |
| 1698 | sucedía | 1 |
| 1699 | suceder | 1 |
| 1700 | substancia | 1 |
| 1701 | subióse | 1 |
| 1702 | subí | 1 |
| 1703 | súbese | 1 |
| 1704 | sotileza | 1 |
| 1705 | sotiles | 1 |
| 1706 | sospiro | 1 |
| 1707 | sospechuela | 1 |
| 1708 | sospeché | 1 |
| 1709 | sospechara | 1 |
| 1710 | sospecháis | 1 |
| 1711 | sospechaba | 1 |
| 1712 | sosegado | 1 |
| 1713 | soportales | 1 |
| 1714 | soplando | 1 |
| 1715 | sonriéndose | 1 |
| 1716 | sonó | 1 |
| 1717 | sonido | 1 |
| 1718 | sonase | 1 |
| 1719 | sonara | 1 |
| 1720 | sonable | 1 |
| 1721 | somos | 1 |
| 1722 | soltado | 1 |
| 1723 | solos | 1 |
| 1724 | soldado | 1 |
| 1725 | solas | 1 |
| 1726 | solana | 1 |
| 1727 | socorre | 1 |
| 1728 | socorra | 1 |
| 1729 | sobresalto | 1 |
| 1730 | sobresaltado | 1 |
| 1731 | sobrenombre | 1 |
| 1732 | sobran | 1 |
| 1733 | sobrado | 1 |
| 1734 | sisar | 1 |
| 1735 | sirvas | 1 |
| 1736 | siquiera | 1 |
| 1737 | sintiéndose | 1 |
| 1738 | sinsabores | 1 |
| 1739 | sinjusticia | 1 |
| 1740 | simpleza | 1 |
| 1741 | simplemente | 1 |
| 1742 | silleta | 1 |
| 1743 | silbo | 1 |
| 1744 | siguientes | 1 |
| 1745 | siguiente | 1 |
| 1746 | siento | 1 |
| 1747 | sientes | 1 |
| 1748 | siéndoles | 1 |
| 1749 | sexto | 1 |
| 1750 | sesos | 1 |
| 1751 | servicios | 1 |
| 1752 | servicial | 1 |
| 1753 | servían | 1 |
| 1754 | serme | 1 |
| 1755 | serás | 1 |
| 1756 | sepultado | 1 |
| 1757 | séptimo | 1 |
| 1758 | sepas | 1 |
| 1759 | sepan | 1 |
| 1760 | señalándose | 1 |
| 1761 | señalando | 1 |
| 1762 | señalado | 1 |
| 1763 | señaladas | 1 |
| 1764 | señaladamente | 1 |
| 1765 | señalaban | 1 |
| 1766 | sentiste | 1 |
| 1767 | sentimiento | 1 |
| 1768 | sentida | 1 |
| 1769 | sentámonos | 1 |
| 1770 | sendas | 1 |
| 1771 | semejantes | 1 |
| 1772 | semanas | 1 |
| 1773 | seguir | 1 |
| 1774 | seguíle | 1 |
| 1775 | seglares | 1 |
| 1776 | sed | 1 |
| 1777 | secretos | 1 |
| 1778 | secreto | 1 |
| 1779 | secreta | 1 |
| 1780 | sazonada | 1 |
| 1781 | sayete | 1 |
| 1782 | satisfice | 1 |
| 1783 | satisfecha | 1 |
| 1784 | satisfacerse | 1 |
| 1785 | satisfaceros | 1 |
| 1786 | saquen | 1 |
| 1787 | saquéle | 1 |
| 1788 | sangrías | 1 |
| 1789 | sangre | 1 |
| 1790 | sangraba | 1 |
| 1791 | sanaba | 1 |
| 1792 | sana | 1 |
| 1793 | salvar | 1 |
| 1794 | salvados | 1 |
| 1795 | salvador | 1 |
| 1796 | saludar | 1 |
| 1797 | saludador | 1 |
| 1798 | saltos | 1 |
| 1799 | saltando | 1 |
| 1800 | saltá | 1 |
| 1801 | salta | 1 |
| 1802 | salsas | 1 |
| 1803 | salsa | 1 |
| 1804 | salirme | 1 |
| 1805 | saliese | 1 |
| 1806 | saliendo | 1 |
| 1807 | salidos | 1 |
| 1808 | salida | 1 |
| 1809 | salgan | 1 |
| 1810 | salgamos | 1 |
| 1811 | saledizos | 1 |
| 1812 | sagra | 1 |
| 1813 | sagaz | 1 |
| 1814 | sagacísimo | 1 |
| 1815 | saeta | 1 |
| 1816 | sacudimos | 1 |
| 1817 | sacristanes | 1 |
| 1818 | sacramento | 1 |
| 1819 | sacóme | 1 |
| 1820 | sacóla | 1 |
| 1821 | sacerdotes | 1 |
| 1822 | sacerdote | 1 |
| 1823 | sacase | 1 |
| 1824 | sacáronme | 1 |
| 1825 | sacaran | 1 |
| 1826 | sacándomela | 1 |
| 1827 | sacando | 1 |
| 1828 | sacallas | 1 |
| 1829 | sabría | 1 |
| 1830 | sabrás | 1 |
| 1831 | sabiendo | 1 |
| 1832 | sabido | 1 |
| 1833 | sábanas | 1 |
| 1834 | ruinoso | 1 |
| 1835 | ruinmente | 1 |
| 1836 | ruindad | 1 |
| 1837 | ruegue | 1 |
| 1838 | ruegan | 1 |
| 1839 | royendo | 1 |
| 1840 | roturas | 1 |
| 1841 | roto | 1 |
| 1842 | rostros | 1 |
| 1843 | rostro | 1 |
| 1844 | rostriquemados | 1 |
| 1845 | roncar | 1 |
| 1846 | rompiéndomela | 1 |
| 1847 | rompí | 1 |
| 1848 | roídos | 1 |
| 1849 | roía | 1 |
| 1850 | rogar | 1 |
| 1851 | roer | 1 |
| 1852 | rodillazos | 1 |
| 1853 | robó | 1 |
| 1854 | rió | 1 |
| 1855 | rio | 1 |
| 1856 | riñese | 1 |
| 1857 | riñendo | 1 |
| 1858 | rindió | 1 |
| 1859 | rifar | 1 |
| 1860 | riéronse | 1 |
| 1861 | riendo | 1 |
| 1862 | rico | 1 |
| 1863 | rica | 1 |
| 1864 | riberas | 1 |
| 1865 | ribera | 1 |
| 1866 | rezumando | 1 |
| 1867 | rezaste | 1 |
| 1868 | rezando | 1 |
| 1869 | rezamos | 1 |
| 1870 | revolviéndose | 1 |
| 1871 | revolviendo | 1 |
| 1872 | revolver | 1 |
| 1873 | revés | 1 |
| 1874 | reverendos | 1 |
| 1875 | reverendas | 1 |
| 1876 | retuvo | 1 |
| 1877 | retuviera | 1 |
| 1878 | retraídos | 1 |
| 1879 | respuesta | 1 |
| 1880 | respondía | 1 |
| 1881 | responden | 1 |
| 1882 | resoplo | 1 |
| 1883 | resoplidos | 1 |
| 1884 | resido | 1 |
| 1885 | reservar | 1 |
| 1886 | representaron | 1 |
| 1887 | represa | 1 |
| 1888 | reposo | 1 |
| 1889 | reposé | 1 |
| 1890 | reposar | 1 |
| 1891 | reposado | 1 |
| 1892 | repelándome | 1 |
| 1893 | renieguen | 1 |
| 1894 | renegué | 1 |
| 1895 | renegaba | 1 |
| 1896 | remiendo | 1 |
| 1897 | remedios | 1 |
| 1898 | remedie | 1 |
| 1899 | remediásedes | 1 |
| 1900 | remediaran | 1 |
| 1901 | remando | 1 |
| 1902 | relate | 1 |
| 1903 | relámpago | 1 |
| 1904 | reírlas | 1 |
| 1905 | reino | 1 |
| 1906 | reíme | 1 |
| 1907 | reílle | 1 |
| 1908 | rehacer | 1 |
| 1909 | regocijos | 1 |
| 1910 | regladamente | 1 |
| 1911 | registrada | 1 |
| 1912 | regidores | 1 |
| 1913 | regalaba | 1 |
| 1914 | refrescar | 1 |
| 1915 | refrán | 1 |
| 1916 | reformar | 1 |
| 1917 | redención | 1 |
| 1918 | recueros | 1 |
| 1919 | recordarme | 1 |
| 1920 | recontaba | 1 |
| 1921 | recompensados | 1 |
| 1922 | recibiendo | 1 |
| 1923 | reciba | 1 |
| 1924 | recias | 1 |
| 1925 | reciamente | 1 |
| 1926 | recia | 1 |
| 1927 | recelo | 1 |
| 1928 | recelaba | 1 |
| 1929 | recebillo | 1 |
| 1930 | recámara | 1 |
| 1931 | rebozadas | 1 |
| 1932 | rebeldes | 1 |
| 1933 | razonamiento | 1 |
| 1934 | razonables | 1 |
| 1935 | razonablemente | 1 |
| 1936 | rayó | 1 |
| 1937 | ratopes | 1 |
| 1938 | ratonar | 1 |
| 1939 | ratonados | 1 |
| 1940 | raso | 1 |
| 1941 | rascuñado | 1 |
| 1942 | rameras | 1 |
| 1943 | raíz | 1 |
| 1944 | raído | 1 |
| 1945 | raída | 1 |
| 1946 | raciones | 1 |
| 1947 | rabiosa | 1 |
| 1948 | rabiaba | 1 |
| 1949 | quitó | 1 |
| 1950 | quitarse | 1 |
| 1951 | quitando | 1 |
| 1952 | quitáis | 1 |
| 1953 | quitado | 1 |
| 1954 | quisiesen | 1 |
| 1955 | quisiéredes | 1 |
| 1956 | quijadas | 1 |
| 1957 | quietud | 1 |
| 1958 | quienquiera | 1 |
| 1959 | quicio | 1 |
| 1960 | querré | 1 |
| 1961 | querrá | 1 |
| 1962 | quejándose | 1 |
| 1963 | quejando | 1 |
| 1964 | quejábaseme | 1 |
| 1965 | quedo | 1 |
| 1966 | quedito | 1 |
| 1967 | quede | 1 |
| 1968 | quedasen | 1 |
| 1969 | quedase | 1 |
| 1970 | quedaran | 1 |
| 1971 | quedan | 1 |
| 1972 | quedamos | 1 |
| 1973 | quedaban | 1 |
| 1974 | quebró | 1 |
| 1975 | quebremos | 1 |
| 1976 | quebraba | 1 |
| 1977 | púsosela | 1 |
| 1978 | púsose | 1 |
| 1979 | púsole | 1 |
| 1980 | púsolas | 1 |
| 1981 | pusimos | 1 |
| 1982 | pusímonos | 1 |
| 1983 | pusiéronse | 1 |
| 1984 | pusieron | 1 |
| 1985 | puse | 1 |
| 1986 | purgatorio | 1 |
| 1987 | puñadas | 1 |
| 1988 | puntillos | 1 |
| 1989 | punido | 1 |
| 1990 | puerto | 1 |
| 1991 | puercos | 1 |
| 1992 | puerco | 1 |
| 1993 | puente | 1 |
| 1994 | puédese | 1 |
| 1995 | puedes | 1 |
| 1996 | pueden | 1 |
| 1997 | pueda | 1 |
| 1998 | pudiese | 1 |
| 1999 | pudieron | 1 |
| 2000 | pudieres | 1 |
| 2001 | pudiendo | 1 |
| 2002 | pruebe | 1 |
| 2003 | provisiones | 1 |
| 2004 | proveído | 1 |
| 2005 | proveía | 1 |
| 2006 | provechosamente | 1 |
| 2007 | provechosa | 1 |
| 2008 | provechos | 1 |
| 2009 | prosperidad | 1 |
| 2010 | proprio | 1 |
| 2011 | propria | 1 |
| 2012 | propio | 1 |
| 2013 | propicios | 1 |
| 2014 | propiamente | 1 |
| 2015 | pronósticos | 1 |
| 2016 | pronóstico | 1 |
| 2017 | prometíle | 1 |
| 2018 | prometido | 1 |
| 2019 | prometas | 1 |
| 2020 | prólogo | 1 |
| 2021 | prolijo | 1 |
| 2022 | prolijidad | 1 |
| 2023 | prójimo | 1 |
| 2024 | profecía | 1 |
| 2025 | procuré | 1 |
| 2026 | procurar | 1 |
| 2027 | procurándose | 1 |
| 2028 | procuraba | 1 |
| 2029 | procura | 1 |
| 2030 | procesión | 1 |
| 2031 | probósele | 1 |
| 2032 | probó | 1 |
| 2033 | probaré | 1 |
| 2034 | probar | 1 |
| 2035 | proballa | 1 |
| 2036 | privilegiada | 1 |
| 2037 | privar | 1 |
| 2038 | privado | 1 |
| 2039 | prisa | 1 |
| 2040 | pringaron | 1 |
| 2041 | pringado | 1 |
| 2042 | pringadas | 1 |
| 2043 | primeras | 1 |
| 2044 | presunción | 1 |
| 2045 | prestos | 1 |
| 2046 | prestada | 1 |
| 2047 | presentar | 1 |
| 2048 | presentado | 1 |
| 2049 | presentaba | 1 |
| 2050 | preñadas | 1 |
| 2051 | preñada | 1 |
| 2052 | prended | 1 |
| 2053 | pregunten | 1 |
| 2054 | préguntaron | 1 |
| 2055 | preguntaron | 1 |
| 2056 | preguntar | 1 |
| 2057 | preguntándole | 1 |
| 2058 | preguntando | 1 |
| 2059 | preguntan | 1 |
| 2060 | preguntado | 1 |
| 2061 | pregonero | 1 |
| 2062 | pregonar | 1 |
| 2063 | pregonaba | 1 |
| 2064 | predicó | 1 |
| 2065 | predicador | 1 |
| 2066 | predicado | 1 |
| 2067 | predicaba | 1 |
| 2068 | precio | 1 |
| 2069 | preciado | 1 |
| 2070 | postrero | 1 |
| 2071 | postrera | 1 |
| 2072 | postrer | 1 |
| 2073 | pospuesto | 1 |
| 2074 | posar | 1 |
| 2075 | porquerón | 1 |
| 2076 | pormandado | 1 |
| 2077 | porfiada | 1 |
| 2078 | ponme | 1 |
| 2079 | ponla | 1 |
| 2080 | poniéndole | 1 |
| 2081 | póngome | 1 |
| 2082 | póngole | 1 |
| 2083 | pongo | 1 |
| 2084 | pongas | 1 |
| 2085 | ponerse | 1 |
| 2086 | ponerle | 1 |
| 2087 | ponellos | 1 |
| 2088 | ponello | 1 |
| 2089 | ponelle | 1 |
| 2090 | ponéis | 1 |
| 2091 | pone | 1 |
| 2092 | pondrá | 1 |
| 2093 | pompa | 1 |
| 2094 | podrían | 1 |
| 2095 | podremos | 1 |
| 2096 | podré | 1 |
| 2097 | podrá | 1 |
| 2098 | podían | 1 |
| 2099 | podia | 1 |
| 2100 | podenco | 1 |
| 2101 | podemos | 1 |
| 2102 | podamos | 1 |
| 2103 | podáis | 1 |
| 2104 | pobreza | 1 |
| 2105 | pobreto | 1 |
| 2106 | pobrecilla | 1 |
| 2107 | pluguiere | 1 |
| 2108 | plinio | 1 |
| 2109 | plegarias | 1 |
| 2110 | plazos | 1 |
| 2111 | plazas | 1 |
| 2112 | plática | 1 |
| 2113 | planto | 1 |
| 2114 | placeres | 1 |
| 2115 | placerá | 1 |
| 2116 | placer | 1 |
| 2117 | place | 1 |
| 2118 | pintar | 1 |
| 2119 | pierde | 1 |
| 2120 | pierda | 1 |
| 2121 | piense | 1 |
| 2122 | piensan | 1 |
| 2123 | piensa | 1 |
| 2124 | piedras | 1 |
| 2125 | pido | 1 |
| 2126 | pidióme | 1 |
| 2127 | piden | 1 |
| 2128 | pide | 1 |
| 2129 | pico | 1 |
| 2130 | picarás | 1 |
| 2131 | pía | 1 |
| 2132 | petición | 1 |
| 2133 | pesquisar | 1 |
| 2134 | pesquisa | 1 |
| 2135 | pese | 1 |
| 2136 | pescuezo | 1 |
| 2137 | pesase | 1 |
| 2138 | pesará | 1 |
| 2139 | pesábame | 1 |
| 2140 | perverso | 1 |
| 2141 | perseguirme | 1 |
| 2142 | perjurar | 1 |
| 2143 | pérez | 1 |
| 2144 | perdonó | 1 |
| 2145 | perdono | 1 |
| 2146 | perdonemos | 1 |
| 2147 | perdonalle | 1 |
| 2148 | perdonaba | 1 |
| 2149 | perdón | 1 |
| 2150 | perdiese | 1 |
| 2151 | perdición | 1 |
| 2152 | perdía | 1 |
| 2153 | pequeños | 1 |
| 2154 | peores | 1 |
| 2155 | pensaste | 1 |
| 2156 | pensaréis | 1 |
| 2157 | pensamiento | 1 |
| 2158 | penélope | 1 |
| 2159 | penas | 1 |
| 2160 | pelo | 1 |
| 2161 | pelillo | 1 |
| 2162 | peligroso | 1 |
| 2163 | peligros | 1 |
| 2164 | peligrar | 1 |
| 2165 | pelado | 1 |
| 2166 | peinóse | 1 |
| 2167 | peinado | 1 |
| 2168 | pegar | 1 |
| 2169 | pegan | 1 |
| 2170 | pedradas | 1 |
| 2171 | pedirme | 1 |
| 2172 | pedirle | 1 |
| 2173 | pedillo | 1 |
| 2174 | pechos | 1 |
| 2175 | pecadorcico | 1 |
| 2176 | pecadora | 1 |
| 2177 | pausadamente | 1 |
| 2178 | pausada | 1 |
| 2179 | patrimos | 1 |
| 2180 | paternostres | 1 |
| 2181 | pasemos | 1 |
| 2182 | paseándose | 1 |
| 2183 | paseando | 1 |
| 2184 | pascuas | 1 |
| 2185 | pascasio | 1 |
| 2186 | pásate | 1 |
| 2187 | pasase | 1 |
| 2188 | pasarme | 1 |
| 2189 | pasaremos | 1 |
| 2190 | pasando | 1 |
| 2191 | pasadas | 1 |
| 2192 | pasábamos | 1 |
| 2193 | pasa | 1 |
| 2194 | partiríamos | 1 |
| 2195 | partillo | 1 |
| 2196 | partiésemos | 1 |
| 2197 | partí | 1 |
| 2198 | parióme | 1 |
| 2199 | parido | 1 |
| 2200 | parían | 1 |
| 2201 | parezcamos | 1 |
| 2202 | parecióle | 1 |
| 2203 | pareciesen | 1 |
| 2204 | pareciese | 1 |
| 2205 | pareciendo | 1 |
| 2206 | parecían | 1 |
| 2207 | parecíamos | 1 |
| 2208 | parecerme | 1 |
| 2209 | parecen | 1 |
| 2210 | paréceme | 1 |
| 2211 | parcial | 1 |
| 2212 | párate | 1 |
| 2213 | paraíso | 1 |
| 2214 | papar | 1 |
| 2215 | papa | 1 |
| 2216 | paños | 1 |
| 2217 | paño | 1 |
| 2218 | pañizuelo | 1 |
| 2219 | panderos | 1 |
| 2220 | panal | 1 |
| 2221 | palos | 1 |
| 2222 | palominos | 1 |
| 2223 | palo | 1 |
| 2224 | paletoque | 1 |
| 2225 | palacio | 1 |
| 2226 | pagué | 1 |
| 2227 | pague | 1 |
| 2228 | pagaré | 1 |
| 2229 | pagara | 1 |
| 2230 | pagar | 1 |
| 2231 | pagamentos | 1 |
| 2232 | pagaban | 1 |
| 2233 | padres | 1 |
| 2234 | padrastro | 1 |
| 2235 | padeció | 1 |
| 2236 | padeciendo | 1 |
| 2237 | padece | 1 |
| 2238 | oyese | 1 |
| 2239 | oyeron | 1 |
| 2240 | oyera | 1 |
| 2241 | ovidio | 1 |
| 2242 | otorgamos | 1 |
| 2243 | osé | 1 |
| 2244 | osándome | 1 |
| 2245 | osando | 1 |
| 2246 | ordinario | 1 |
| 2247 | ordena | 1 |
| 2248 | oracion | 1 |
| 2249 | once | 1 |
| 2250 | olvido | 1 |
| 2251 | olvidando | 1 |
| 2252 | olor | 1 |
| 2253 | olistes | 1 |
| 2254 | olerme | 1 |
| 2255 | oiréis | 1 |
| 2256 | oirás | 1 |
| 2257 | oirá | 1 |
| 2258 | oídos | 1 |
| 2259 | oídme | 1 |
| 2260 | oídas | 1 |
| 2261 | oíd | 1 |
| 2262 | ofrenda | 1 |
| 2263 | ofreciéndosele | 1 |
| 2264 | ofrecían | 1 |
| 2265 | ofrecer | 1 |
| 2266 | oficios | 1 |
| 2267 | oficial | 1 |
| 2268 | ofertorio | 1 |
| 2269 | ofendió | 1 |
| 2270 | ocupado | 1 |
| 2271 | ocultar | 1 |
| 2272 | obtinados | 1 |
| 2273 | obstáculo | 1 |
| 2274 | obscuridad | 1 |
| 2275 | obligo | 1 |
| 2276 | obligados | 1 |
| 2277 | oblada | 1 |
| 2278 | obispado | 1 |
| 2279 | nueve | 1 |
| 2280 | nuevas | 1 |
| 2281 | nueva | 1 |
| 2282 | nuestras | 1 |
| 2283 | notar | 1 |
| 2284 | nonada | 1 |
| 2285 | nombrar | 1 |
| 2286 | nobles | 1 |
| 2287 | niñerías | 1 |
| 2288 | negros | 1 |
| 2289 | negrito | 1 |
| 2290 | negociado | 1 |
| 2291 | negó | 1 |
| 2292 | negar | 1 |
| 2293 | necios | 1 |
| 2294 | necio | 1 |
| 2295 | naturaleza | 1 |
| 2296 | narices | 1 |
| 2297 | naranjas | 1 |
| 2298 | nacimiento | 1 |
| 2299 | nacidos | 1 |
| 2300 | nacido | 1 |
| 2301 | nací | 1 |
| 2302 | murmurando | 1 |
| 2303 | murieron | 1 |
| 2304 | muriendo | 1 |
| 2305 | murciana | 1 |
| 2306 | mula | 1 |
| 2307 | muestra | 1 |
| 2308 | muerda | 1 |
| 2309 | muela | 1 |
| 2310 | mudar | 1 |
| 2311 | muchacho | 1 |
| 2312 | mozas | 1 |
| 2313 | moxquito | 1 |
| 2314 | motivo | 1 |
| 2315 | mostrase | 1 |
| 2316 | mostraré | 1 |
| 2317 | mostrar | 1 |
| 2318 | mostraba | 1 |
| 2319 | mosto | 1 |
| 2320 | moriré | 1 |
| 2321 | morir | 1 |
| 2322 | morí | 1 |
| 2323 | moreno | 1 |
| 2324 | mordiese | 1 |
| 2325 | morder | 1 |
| 2326 | mordellas | 1 |
| 2327 | morar | 1 |
| 2328 | moradores | 1 |
| 2329 | montero | 1 |
| 2330 | molinero | 1 |
| 2331 | molienda | 1 |
| 2332 | molestias | 1 |
| 2333 | moler | 1 |
| 2334 | molelle | 1 |
| 2335 | mojar | 1 |
| 2336 | mojamos | 1 |
| 2337 | mojados | 1 |
| 2338 | mojaba | 1 |
| 2339 | mofador | 1 |
| 2340 | modos | 1 |
| 2341 | modo | 1 |
| 2342 | míseros | 1 |
| 2343 | miseria | 1 |
| 2344 | misal | 1 |
| 2345 | miróme | 1 |
| 2346 | miróla | 1 |
| 2347 | mirara | 1 |
| 2348 | mirar | 1 |
| 2349 | mirado | 1 |
| 2350 | miraba | 1 |
| 2351 | míos | 1 |
| 2352 | mio | 1 |
| 2353 | migajas | 1 |
| 2354 | migaja | 1 |
| 2355 | mientra | 1 |
| 2356 | mezquindad | 1 |
| 2357 | metióse | 1 |
| 2358 | metióme | 1 |
| 2359 | metieron | 1 |
| 2360 | metiéndola | 1 |
| 2361 | metido | 1 |
| 2362 | metí | 1 |
| 2363 | métense | 1 |
| 2364 | metella | 1 |
| 2365 | meta | 1 |
| 2366 | mesoneras | 1 |
| 2367 | mesmos | 1 |
| 2368 | mesma | 1 |
| 2369 | merienda | 1 |
| 2370 | merezco | 1 |
| 2371 | merecía | 1 |
| 2372 | merecedes | 1 |
| 2373 | mercedes | 1 |
| 2374 | merca | 1 |
| 2375 | menudo | 1 |
| 2376 | menudas | 1 |
| 2377 | mentiroso | 1 |
| 2378 | mentir | 1 |
| 2379 | mentille | 1 |
| 2380 | mentía | 1 |
| 2381 | mentalle | 1 |
| 2382 | menor | 1 |
| 2383 | menesteres | 1 |
| 2384 | meneos | 1 |
| 2385 | menear | 1 |
| 2386 | meneando | 1 |
| 2387 | mendrugo | 1 |
| 2388 | melocotón | 1 |
| 2389 | mejoría | 1 |
| 2390 | mejoraba | 1 |
| 2391 | meitad | 1 |
| 2392 | medre | 1 |
| 2393 | medrará | 1 |
| 2394 | medra | 1 |
| 2395 | medida | 1 |
| 2396 | mayores | 1 |
| 2397 | mayordomo | 1 |
| 2398 | maté | 1 |
| 2399 | matarlos | 1 |
| 2400 | mataré | 1 |
| 2401 | matador | 1 |
| 2402 | mataban | 1 |
| 2403 | marras | 1 |
| 2404 | maridos | 1 |
| 2405 | marco | 1 |
| 2406 | maravillosas | 1 |
| 2407 | maravillosamente | 1 |
| 2408 | maravillemos | 1 |
| 2409 | maravillas | 1 |
| 2410 | maravillaría | 1 |
| 2411 | maravillado | 1 |
| 2412 | maqueda | 1 |
| 2413 | mañosos | 1 |
| 2414 | mañanicas | 1 |
| 2415 | mantuviese | 1 |
| 2416 | mantenimiento | 1 |
| 2417 | mantenerte | 1 |
| 2418 | mantener | 1 |
| 2419 | manteles | 1 |
| 2420 | mantas | 1 |
| 2421 | mansamente | 1 |
| 2422 | manifiestas | 1 |
| 2423 | manifestase | 1 |
| 2424 | mangas | 1 |
| 2425 | mandiles | 1 |
| 2426 | mandasen | 1 |
| 2427 | mandar | 1 |
| 2428 | mandan | 1 |
| 2429 | mandamiento | 1 |
| 2430 | mandado | 1 |
| 2431 | mandaba | 1 |
| 2432 | mancilla | 1 |
| 2433 | mancha | 1 |
| 2434 | mamado | 1 |
| 2435 | malvado | 1 |
| 2436 | maltratamiento | 1 |
| 2437 | maltratados | 1 |
| 2438 | malsinar | 1 |
| 2439 | malmaxcada | 1 |
| 2440 | malilla | 1 |
| 2441 | malicioso | 1 |
| 2442 | maleficio | 1 |
| 2443 | malditos | 1 |
| 2444 | maldíjeme | 1 |
| 2445 | maldiciones | 1 |
| 2446 | malcasado | 1 |
| 2447 | malcasadas | 1 |
| 2448 | malaventurado | 1 |
| 2449 | magno | 1 |
| 2450 | magdalena | 1 |
| 2451 | maestra | 1 |
| 2452 | madura | 1 |
| 2453 | madres | 1 |
| 2454 | macías | 1 |
| 2455 | luz | 1 |
| 2456 | luto | 1 |
| 2457 | luenga | 1 |
| 2458 | lodo | 1 |
| 2459 | loado | 1 |
| 2460 | loaba | 1 |
| 2461 | llovido | 1 |
| 2462 | llover | 1 |
| 2463 | lloré | 1 |
| 2464 | llorarlas | 1 |
| 2465 | llevóme | 1 |
| 2466 | llevélo | 1 |
| 2467 | llevase | 1 |
| 2468 | llevas | 1 |
| 2469 | llevándolo | 1 |
| 2470 | llévame | 1 |
| 2471 | llevada | 1 |
| 2472 | llevaban | 1 |
| 2473 | llevábamos | 1 |
| 2474 | lleno | 1 |
| 2475 | lleguéme | 1 |
| 2476 | llegue | 1 |
| 2477 | llegase | 1 |
| 2478 | llegáramos | 1 |
| 2479 | llegado | 1 |
| 2480 | llegábamos | 1 |
| 2481 | llanto | 1 |
| 2482 | llamóme | 1 |
| 2483 | llamasen | 1 |
| 2484 | llamara | 1 |
| 2485 | llámanme | 1 |
| 2486 | llamándome | 1 |
| 2487 | llamaban | 1 |
| 2488 | llamaba | 1 |
| 2489 | llama | 1 |
| 2490 | llagada | 1 |
| 2491 | limpieza | 1 |
| 2492 | limpiar | 1 |
| 2493 | limpiamente | 1 |
| 2494 | limpia | 1 |
| 2495 | limosnera | 1 |
| 2496 | limitada | 1 |
| 2497 | limas | 1 |
| 2498 | ligeramente | 1 |
| 2499 | lienzo | 1 |
| 2500 | licor | 1 |
| 2501 | licenciado | 1 |
| 2502 | libro | 1 |
| 2503 | librarle | 1 |
| 2504 | librar | 1 |
| 2505 | librados | 1 |
| 2506 | libra | 1 |
| 2507 | liberalidad | 1 |
| 2508 | ley | 1 |
| 2509 | levantéme | 1 |
| 2510 | levanté | 1 |
| 2511 | levantasen | 1 |
| 2512 | levantarse | 1 |
| 2513 | levantar | 1 |
| 2514 | levantándose | 1 |
| 2515 | levantando | 1 |
| 2516 | levantámonos | 1 |
| 2517 | levantaba | 1 |
| 2518 | letanía | 1 |
| 2519 | leños | 1 |
| 2520 | leña | 1 |
| 2521 | leguas | 1 |
| 2522 | lechuga | 1 |
| 2523 | lecho | 1 |
| 2524 | leche | 1 |
| 2525 | lean | 1 |
| 2526 | leal | 1 |
| 2527 | lea | 1 |
| 2528 | lazarillo | 1 |
| 2529 | lavóme | 1 |
| 2530 | lavatorios | 1 |
| 2531 | lavarse | 1 |
| 2532 | laváronme | 1 |
| 2533 | lavándose | 1 |
| 2534 | lavaban | 1 |
| 2535 | lavaba | 1 |
| 2536 | laudes | 1 |
| 2537 | larguillo | 1 |
| 2538 | largos | 1 |
| 2539 | lanzón | 1 |
| 2540 | lanzas | 1 |
| 2541 | lanzar | 1 |
| 2542 | lanzado | 1 |
| 2543 | lanzada | 1 |
| 2544 | lance | 1 |
| 2545 | ladrones | 1 |
| 2546 | labradas | 1 |
| 2547 | justó | 1 |
| 2548 | justamente | 1 |
| 2549 | jurar | 1 |
| 2550 | juramentos | 1 |
| 2551 | juraba | 1 |
| 2552 | juntóseme | 1 |
| 2553 | juntó | 1 |
| 2554 | juntaron | 1 |
| 2555 | juicio | 1 |
| 2556 | jugar | 1 |
| 2557 | jugaban | 1 |
| 2558 | jerigonza | 1 |
| 2559 | jarrillo | 1 |
| 2560 | jaez | 1 |
| 2561 | izquierdo | 1 |
| 2562 | irme | 1 |
| 2563 | irle | 1 |
| 2564 | ira | 1 |
| 2565 | invocando | 1 |
| 2566 | invisible | 1 |
| 2567 | inventivo | 1 |
| 2568 | invenciones | 1 |
| 2569 | instituídas | 1 |
| 2570 | instante | 1 |
| 2571 | inocencia | 1 |
| 2572 | injustamente | 1 |
| 2573 | injuriosas | 1 |
| 2574 | injurias | 1 |
| 2575 | injuria | 1 |
| 2576 | informábase | 1 |
| 2577 | infierno | 1 |
| 2578 | industrioso | 1 |
| 2579 | industriado | 1 |
| 2580 | industria | 1 |
| 2581 | indirecte | 1 |
| 2582 | inclinadas | 1 |
| 2583 | importunidades | 1 |
| 2584 | importaba | 1 |
| 2585 | imán | 1 |
| 2586 | iguales | 1 |
| 2587 | ignoran | 1 |
| 2588 | ida | 1 |
| 2589 | huyese | 1 |
| 2590 | huyen | 1 |
| 2591 | hurto | 1 |
| 2592 | hurten | 1 |
| 2593 | hurtar | 1 |
| 2594 | hurtallo | 1 |
| 2595 | hurtaba | 1 |
| 2596 | hurta | 1 |
| 2597 | hundiera | 1 |
| 2598 | hunda | 1 |
| 2599 | humilde | 1 |
| 2600 | humero | 1 |
| 2601 | humana | 1 |
| 2602 | huía | 1 |
| 2603 | huevos | 1 |
| 2604 | huesecillo | 1 |
| 2605 | huerta | 1 |
| 2606 | huérfano | 1 |
| 2607 | huelgues | 1 |
| 2608 | huelguen | 1 |
| 2609 | hueco | 1 |
| 2610 | hubiste | 1 |
| 2611 | hubimos | 1 |
| 2612 | hubiese | 1 |
| 2613 | hubieron | 1 |
| 2614 | hostia | 1 |
| 2615 | horca | 1 |
| 2616 | horas | 1 |
| 2617 | honrados | 1 |
| 2618 | honradamente | 1 |
| 2619 | holgáronse | 1 |
| 2620 | holgaría | 1 |
| 2621 | holgado | 1 |
| 2622 | holgábase | 1 |
| 2623 | holgábame | 1 |
| 2624 | hocicos | 1 |
| 2625 | hincó | 1 |
| 2626 | hincaron | 1 |
| 2627 | hilanderas | 1 |
| 2628 | hijas | 1 |
| 2629 | hierro | 1 |
| 2630 | hideputa | 1 |
| 2631 | hidalgos | 1 |
| 2632 | hidalgo | 1 |
| 2633 | hiciéronnos | 1 |
| 2634 | híceme | 1 |
| 2635 | herrero | 1 |
| 2636 | herraduras | 1 |
| 2637 | hermosa | 1 |
| 2638 | herida | 1 |
| 2639 | hería | 1 |
| 2640 | heredaron | 1 |
| 2641 | hendida | 1 |
| 2642 | hendí | 1 |
| 2643 | heme | 1 |
| 2644 | helos | 1 |
| 2645 | hecimos | 1 |
| 2646 | hechura | 1 |
| 2647 | hazer | 1 |
| 2648 | hazañas | 1 |
| 2649 | hazaña | 1 |
| 2650 | haz | 1 |
| 2651 | hayan | 1 |
| 2652 | hartar | 1 |
| 2653 | hartaban | 1 |
| 2654 | harta | 1 |
| 2655 | harpado | 1 |
| 2656 | haríades | 1 |
| 2657 | hareís | 1 |
| 2658 | haré | 1 |
| 2659 | hanme | 1 |
| 2660 | hame | 1 |
| 2661 | hambriento | 1 |
| 2662 | hambrienta | 1 |
| 2663 | hallóme | 1 |
| 2664 | halló | 1 |
| 2665 | halláronla | 1 |
| 2666 | hallaron | 1 |
| 2667 | hallaría | 1 |
| 2668 | hallaren | 1 |
| 2669 | hallará | 1 |
| 2670 | hallan | 1 |
| 2671 | hallado | 1 |
| 2672 | hágote | 1 |
| 2673 | hagáis | 1 |
| 2674 | haga | 1 |
| 2675 | hados | 1 |
| 2676 | haciéndome | 1 |
| 2677 | haciendas | 1 |
| 2678 | hacíase | 1 |
| 2679 | hacíamos | 1 |
| 2680 | haces | 1 |
| 2681 | hacerme | 1 |
| 2682 | hacerlo | 1 |
| 2683 | hacerles | 1 |
| 2684 | hacemos | 1 |
| 2685 | hacello | 1 |
| 2686 | hacéis | 1 |
| 2687 | haced | 1 |
| 2688 | habréis | 1 |
| 2689 | habló | 1 |
| 2690 | habla | 1 |
| 2691 | habiéndome | 1 |
| 2692 | habiendo | 1 |
| 2693 | habíale | 1 |
| 2694 | habíades | 1 |
| 2695 | gustos | 1 |
| 2696 | gustar | 1 |
| 2697 | gusano | 1 |
| 2698 | gulilla | 1 |
| 2699 | guisar | 1 |
| 2700 | guisalle | 1 |
| 2701 | guíe | 1 |
| 2702 | guerra | 1 |
| 2703 | guardas | 1 |
| 2704 | guardado | 1 |
| 2705 | guardada | 1 |
| 2706 | guardaba | 1 |
| 2707 | guarda | 1 |
| 2708 | gruesas | 1 |
| 2709 | grosero | 1 |
| 2710 | grandísimo | 1 |
| 2711 | gragea | 1 |
| 2712 | grados | 1 |
| 2713 | grada | 1 |
| 2714 | graciosas | 1 |
| 2715 | gozo | 1 |
| 2716 | gonzález | 1 |
| 2717 | gómez | 1 |
| 2718 | golpecillo | 1 |
| 2719 | goloso | 1 |
| 2720 | golosinar | 1 |
| 2721 | golosina | 1 |
| 2722 | glotón | 1 |
| 2723 | gloria | 1 |
| 2724 | gestos | 1 |
| 2725 | gentiles | 1 |
| 2726 | gelves | 1 |
| 2727 | gastarlo | 1 |
| 2728 | gastado | 1 |
| 2729 | gasta | 1 |
| 2730 | garrotazos | 1 |
| 2731 | ganarme | 1 |
| 2732 | ganar | 1 |
| 2733 | ganados | 1 |
| 2734 | gallofero | 1 |
| 2735 | galeno | 1 |
| 2736 | galas | 1 |
| 2737 | fustán | 1 |
| 2738 | furia | 1 |
| 2739 | fulano | 1 |
| 2740 | fuile | 1 |
| 2741 | fuerzas | 1 |
| 2742 | fuertes | 1 |
| 2743 | fuere | 1 |
| 2744 | fuente | 1 |
| 2745 | fueme | 1 |
| 2746 | fué | 1 |
| 2747 | fruto | 1 |
| 2748 | frisada | 1 |
| 2749 | frías | 1 |
| 2750 | frescas | 1 |
| 2751 | frecuentando | 1 |
| 2752 | francia | 1 |
| 2753 | forzado | 1 |
| 2754 | fortunas | 1 |
| 2755 | formó | 1 |
| 2756 | formas | 1 |
| 2757 | flojedad | 1 |
| 2758 | flaquísimo | 1 |
| 2759 | flacas | 1 |
| 2760 | flaca | 1 |
| 2761 | finara | 1 |
| 2762 | finaba | 1 |
| 2763 | figura | 1 |
| 2764 | fiesta | 1 |
| 2765 | fieros | 1 |
| 2766 | fiero | 1 |
| 2767 | fiel | 1 |
| 2768 | fiaban | 1 |
| 2769 | fenecer | 1 |
| 2770 | feligreses | 1 |
| 2771 | favoreciesen | 1 |
| 2772 | favoreciese | 1 |
| 2773 | fatigo | 1 |
| 2774 | fasta | 1 |
| 2775 | fantasía | 1 |
| 2776 | faltaron | 1 |
| 2777 | faltarán | 1 |
| 2778 | faltar | 1 |
| 2779 | faltando | 1 |
| 2780 | faltalle | 1 |
| 2781 | falsopecto | 1 |
| 2782 | falso | 1 |
| 2783 | falsamente | 1 |
| 2784 | falsa | 1 |
| 2785 | fallecieron | 1 |
| 2786 | faldas | 1 |
| 2787 | faisán | 1 |
| 2788 | fácilmente | 1 |
| 2789 | extrema | 1 |
| 2790 | experiencia | 1 |
| 2791 | excusas | 1 |
| 2792 | excomunión | 1 |
| 2793 | evangelio | 1 |
| 2794 | estuviéremos | 1 |
| 2795 | estuvieran | 1 |
| 2796 | estudiantes | 1 |
| 2797 | estudiado | 1 |
| 2798 | estrecho | 1 |
| 2799 | estrecha | 1 |
| 2800 | estranjeros | 1 |
| 2801 | estranjero | 1 |
| 2802 | estotra | 1 |
| 2803 | estó | 1 |
| 2804 | estirado | 1 |
| 2805 | estéril | 1 |
| 2806 | estendía | 1 |
| 2807 | estás | 1 |
| 2808 | éstas | 1 |
| 2809 | estaría | 1 |
| 2810 | estamos | 1 |
| 2811 | estada | 1 |
| 2812 | espumajos | 1 |
| 2813 | esperó | 1 |
| 2814 | esperar | 1 |
| 2815 | esperanza | 1 |
| 2816 | esperándome | 1 |
| 2817 | esperalla | 1 |
| 2818 | esperado | 1 |
| 2819 | espera | 1 |
| 2820 | espanto | 1 |
| 2821 | espantar | 1 |
| 2822 | espantados | 1 |
| 2823 | espantábase | 1 |
| 2824 | espacio | 1 |
| 2825 | esgremidor | 1 |
| 2826 | esforzó | 1 |
| 2827 | esforzándome | 1 |
| 2828 | esencia | 1 |
| 2829 | ése | 1 |
| 2830 | escudillar | 1 |
| 2831 | escrito | 1 |
| 2832 | escribo | 1 |
| 2833 | escribirían | 1 |
| 2834 | escribir | 1 |
| 2835 | escribió | 1 |
| 2836 | escribiesen | 1 |
| 2837 | escribe | 1 |
| 2838 | escribanos | 1 |
| 2839 | escriba | 1 |
| 2840 | escrebir | 1 |
| 2841 | escondida | 1 |
| 2842 | escondía | 1 |
| 2843 | escobajo | 1 |
| 2844 | esclavo | 1 |
| 2845 | escarbar | 1 |
| 2846 | escarbando | 1 |
| 2847 | escapé | 1 |
| 2848 | escapando | 1 |
| 2849 | escapado | 1 |
| 2850 | escapaba | 1 |
| 2851 | escándalo | 1 |
| 2852 | escala | 1 |
| 2853 | ésas | 1 |
| 2854 | ésa | 1 |
| 2855 | errara | 1 |
| 2856 | errábades | 1 |
| 2857 | envuelta | 1 |
| 2858 | envolvía | 1 |
| 2859 | enviábame | 1 |
| 2860 | envía | 1 |
| 2861 | entro | 1 |
| 2862 | entregar | 1 |
| 2863 | entrecuesto | 1 |
| 2864 | entran | 1 |
| 2865 | entramos | 1 |
| 2866 | entrados | 1 |
| 2867 | entrado | 1 |
| 2868 | entrábase | 1 |
| 2869 | entraban | 1 |
| 2870 | entrábame | 1 |
| 2871 | entraba | 1 |
| 2872 | entierren | 1 |
| 2873 | entiende | 1 |
| 2874 | enterrábamos | 1 |
| 2875 | entero | 1 |
| 2876 | enternecido | 1 |
| 2877 | entendiendo | 1 |
| 2878 | entendido | 1 |
| 2879 | entendían | 1 |
| 2880 | entender | 1 |
| 2881 | ensiladas | 1 |
| 2882 | enseñó | 1 |
| 2883 | ensayo | 1 |
| 2884 | ensayara | 1 |
| 2885 | ensangosta | 1 |
| 2886 | ensalzar | 1 |
| 2887 | ensalmaba | 1 |
| 2888 | enojados | 1 |
| 2889 | enojado | 1 |
| 2890 | enjalma | 1 |
| 2891 | enhoramala | 1 |
| 2892 | engendró | 1 |
| 2893 | engastonar | 1 |
| 2894 | engañó | 1 |
| 2895 | engaño | 1 |
| 2896 | engañara | 1 |
| 2897 | engañado | 1 |
| 2898 | enfrente | 1 |
| 2899 | enfermos | 1 |
| 2900 | enfermó | 1 |
| 2901 | enferma | 1 |
| 2902 | enemistad | 1 |
| 2903 | endiabladas | 1 |
| 2904 | endiablada | 1 |
| 2905 | endemoniado | 1 |
| 2906 | encuentro | 1 |
| 2907 | encontrara | 1 |
| 2908 | encomiendo | 1 |
| 2909 | encomendarme | 1 |
| 2910 | encerrada | 1 |
| 2911 | encenderse | 1 |
| 2912 | encender | 1 |
| 2913 | encantada | 1 |
| 2914 | encaminaron | 1 |
| 2915 | encaminar | 1 |
| 2916 | encaminando | 1 |
| 2917 | encaminado | 1 |
| 2918 | emplearía | 1 |
| 2919 | empleaba | 1 |
| 2920 | emplea | 1 |
| 2921 | emplastada | 1 |
| 2922 | empezaba | 1 |
| 2923 | emperador | 1 |
| 2924 | emparedada | 1 |
| 2925 | embargo | 1 |
| 2926 | embargar | 1 |
| 2927 | elevado | 1 |
| 2928 | ejecutando | 1 |
| 2929 | efectos | 1 |
| 2930 | echóse | 1 |
| 2931 | echóme | 1 |
| 2932 | echéle | 1 |
| 2933 | echase | 1 |
| 2934 | echarlo | 1 |
| 2935 | échar | 1 |
| 2936 | echamos | 1 |
| 2937 | echallo | 1 |
| 2938 | echador | 1 |
| 2939 | echacuervo | 1 |
| 2940 | echábalo | 1 |
| 2941 | êbase | 1 |
| 2942 | duró | 1 |
| 2943 | duraznos | 1 |
| 2944 | duraron | 1 |
| 2945 | durar | 1 |
| 2946 | dura | 1 |
| 2947 | duque | 1 |
| 2948 | dulzuras | 1 |
| 2949 | dulces | 1 |
| 2950 | dueño | 1 |
| 2951 | duela | 1 |
| 2952 | doscientos | 1 |
| 2953 | doscientas | 1 |
| 2954 | donoso | 1 |
| 2955 | donos | 1 |
| 2956 | donaire | 1 |
| 2957 | domingos | 1 |
| 2958 | dolor | 1 |
| 2959 | doctores | 1 |
| 2960 | dobleces | 1 |
| 2961 | doblamos | 1 |
| 2962 | doblada | 1 |
| 2963 | dó | 1 |
| 2964 | divulgóse | 1 |
| 2965 | divinos | 1 |
| 2966 | diversos | 1 |
| 2967 | disimuló | 1 |
| 2968 | disimulando | 1 |
| 2969 | disimuladamente | 1 |
| 2970 | disimulaba | 1 |
| 2971 | díselo | 1 |
| 2972 | discurriendo | 1 |
| 2973 | discreto | 1 |
| 2974 | discreta | 1 |
| 2975 | discípulo | 1 |
| 2976 | discantaba | 1 |
| 2977 | diremos | 1 |
| 2978 | diréis | 1 |
| 2979 | directe | 1 |
| 2980 | diré | 1 |
| 2981 | dióme | 1 |
| 2982 | dime | 1 |
| 2983 | dijóme | 1 |
| 2984 | díjole | 1 |
| 2985 | dijimos | 1 |
| 2986 | dijese | 1 |
| 2987 | dijere | 1 |
| 2988 | dijera | 1 |
| 2989 | dija | 1 |
| 2990 | dígole | 1 |
| 2991 | digáis | 1 |
| 2992 | diga | 1 |
| 2993 | difunto | 1 |
| 2994 | diferenciaba | 1 |
| 2995 | dieta | 1 |
| 2996 | diestro | 1 |
| 2997 | dieran | 1 |
| 2998 | diera | 1 |
| 2999 | diciéndoles | 1 |
| 3000 | diciéndole | 1 |
| 3001 | dichas | 1 |
| 3002 | dícenme | 1 |
| 3003 | diablos | 1 |
| 3004 | deyuso | 1 |
| 3005 | devuelto | 1 |
| 3006 | devotas | 1 |
| 3007 | devota | 1 |
| 3008 | devociones | 1 |
| 3009 | deudos | 1 |
| 3010 | detestable | 1 |
| 3011 | deteníamonos | 1 |
| 3012 | desvengonzado | 1 |
| 3013 | desvelado | 1 |
| 3014 | destruían | 1 |
| 3015 | destillarme | 1 |
| 3016 | destiento | 1 |
| 3017 | desterrado | 1 |
| 3018 | destapaba | 1 |
| 3019 | destajo | 1 |
| 3020 | despierta | 1 |
| 3021 | despidiente | 1 |
| 3022 | desperté | 1 |
| 3023 | despertaron | 1 |
| 3024 | despertando | 1 |
| 3025 | despertalle | 1 |
| 3026 | despertaba | 1 |
| 3027 | despensa | 1 |
| 3028 | despender | 1 |
| 3029 | despedirse | 1 |
| 3030 | despedió | 1 |
| 3031 | despachar | 1 |
| 3032 | despachada | 1 |
| 3033 | desnudo | 1 |
| 3034 | desmigajé | 1 |
| 3035 | desmigajar | 1 |
| 3036 | desmayos | 1 |
| 3037 | desmando | 1 |
| 3038 | desmandarme | 1 |
| 3039 | desmandara | 1 |
| 3040 | desisto | 1 |
| 3041 | deshonré | 1 |
| 3042 | desherraba | 1 |
| 3043 | desgranábasele | 1 |
| 3044 | desesperado | 1 |
| 3045 | desenvuelto | 1 |
| 3046 | desenvolvíle | 1 |
| 3047 | desenvoltísima | 1 |
| 3048 | desengaño | 1 |
| 3049 | desembarazar | 1 |
| 3050 | desembarazada | 1 |
| 3051 | deseando | 1 |
| 3052 | deseado | 1 |
| 3053 | desea | 1 |
| 3054 | desdichado | 1 |
| 3055 | desdichadas | 1 |
| 3056 | descuide | 1 |
| 3057 | descuidar | 1 |
| 3058 | descuidaban | 1 |
| 3059 | descuidaba | 1 |
| 3060 | descubriese | 1 |
| 3061 | descubría | 1 |
| 3062 | descubres | 1 |
| 3063 | descubierto | 1 |
| 3064 | descosía | 1 |
| 3065 | descontento | 1 |
| 3066 | descargó | 1 |
| 3067 | descansar | 1 |
| 3068 | desbocado | 1 |
| 3069 | desayuné | 1 |
| 3070 | desayunase | 1 |
| 3071 | desatinó | 1 |
| 3072 | desatentadamente | 1 |
| 3073 | desataba | 1 |
| 3074 | desastrada | 1 |
| 3075 | desaprovechada | 1 |
| 3076 | desamparé | 1 |
| 3077 | desamparaba | 1 |
| 3078 | desamar | 1 |
| 3079 | derribando | 1 |
| 3080 | derretida | 1 |
| 3081 | derramados | 1 |
| 3082 | derechos | 1 |
| 3083 | den | 1 |
| 3084 | deméritos | 1 |
| 3085 | demediase | 1 |
| 3086 | demediara | 1 |
| 3087 | demediaba | 1 |
| 3088 | demandóle | 1 |
| 3089 | demandar | 1 |
| 3090 | demanda | 1 |
| 3091 | delitos | 1 |
| 3092 | delincuente | 1 |
| 3093 | delicado | 1 |
| 3094 | delgada | 1 |
| 3095 | deleite | 1 |
| 3096 | dejéle | 1 |
| 3097 | dejé | 1 |
| 3098 | dejasen | 1 |
| 3099 | dejarse | 1 |
| 3100 | dejáronme | 1 |
| 3101 | dejáronle | 1 |
| 3102 | dejaron | 1 |
| 3103 | dejara | 1 |
| 3104 | dejándoselas | 1 |
| 3105 | dejándome | 1 |
| 3106 | dejándole | 1 |
| 3107 | dejando | 1 |
| 3108 | dejálos | 1 |
| 3109 | dejados | 1 |
| 3110 | deja | 1 |
| 3111 | deis | 1 |
| 3112 | defienda | 1 |
| 3113 | defender | 1 |
| 3114 | declarar | 1 |
| 3115 | decíanse | 1 |
| 3116 | decíanle | 1 |
| 3117 | decíamos | 1 |
| 3118 | decia | 1 |
| 3119 | debéis | 1 |
| 3120 | das | 1 |
| 3121 | dárselo | 1 |
| 3122 | darles | 1 |
| 3123 | darle | 1 |
| 3124 | daría | 1 |
| 3125 | daré | 1 |
| 3126 | daños | 1 |
| 3127 | dándoles | 1 |
| 3128 | dan | 1 |
| 3129 | damos | 1 |
| 3130 | dalle | 1 |
| 3131 | dalla | 1 |
| 3132 | dais | 1 |
| 3133 | dábase | 1 |
| 3134 | dábamos | 1 |
| 3135 | dábamelos | 1 |
| 3136 | dábame | 1 |
| 3137 | dábales | 1 |
| 3138 | cuyo | 1 |
| 3139 | curé | 1 |
| 3140 | curar | 1 |
| 3141 | curaban | 1 |
| 3142 | curaba | 1 |
| 3143 | cura | 1 |
| 3144 | cupo | 1 |
| 3145 | cuotidiana | 1 |
| 3146 | cunas | 1 |
| 3147 | cuna | 1 |
| 3148 | cumplirá | 1 |
| 3149 | cumplimiento | 1 |
| 3150 | cumpliese | 1 |
| 3151 | cumplidísima | 1 |
| 3152 | cumplía | 1 |
| 3153 | cumple | 1 |
| 3154 | cumpla | 1 |
| 3155 | cumbre | 1 |
| 3156 | culpa | 1 |
| 3157 | culebro | 1 |
| 3158 | cuitas | 1 |
| 3159 | cuitado | 1 |
| 3160 | cuidados | 1 |
| 3161 | cuernos | 1 |
| 3162 | cuerdamente | 1 |
| 3163 | cuento | 1 |
| 3164 | cuenten | 1 |
| 3165 | cuentas | 1 |
| 3166 | cuéllar | 1 |
| 3167 | cualquier | 1 |
| 3168 | cuadró | 1 |
| 3169 | cristiano | 1 |
| 3170 | criase | 1 |
| 3171 | criados | 1 |
| 3172 | criada | 1 |
| 3173 | cría | 1 |
| 3174 | creyóse | 1 |
| 3175 | creyendo | 1 |
| 3176 | creían | 1 |
| 3177 | creía | 1 |
| 3178 | creí | 1 |
| 3179 | credos | 1 |
| 3180 | credo | 1 |
| 3181 | crédito | 1 |
| 3182 | creciese | 1 |
| 3183 | creáis | 1 |
| 3184 | crea | 1 |
| 3185 | coxqueaba | 1 |
| 3186 | coxcorrones | 1 |
| 3187 | costumbres | 1 |
| 3188 | costosos | 1 |
| 3189 | costara | 1 |
| 3190 | costanilla | 1 |
| 3191 | costales | 1 |
| 3192 | costaba | 1 |
| 3193 | cosilla | 1 |
| 3194 | cosideración | 1 |
| 3195 | coser | 1 |
| 3196 | cosed | 1 |
| 3197 | cosecha | 1 |
| 3198 | cortes | 1 |
| 3199 | cortado | 1 |
| 3200 | corrieron | 1 |
| 3201 | corrida | 1 |
| 3202 | correr | 1 |
| 3203 | cornado | 1 |
| 3204 | cornada | 1 |
| 3205 | corazas | 1 |
| 3206 | coraje | 1 |
| 3207 | copo | 1 |
| 3208 | convite | 1 |
| 3209 | conviéneos | 1 |
| 3210 | convidóme | 1 |
| 3211 | convide | 1 |
| 3212 | convidar | 1 |
| 3213 | convidalle | 1 |
| 3214 | convertir | 1 |
| 3215 | contraria | 1 |
| 3216 | contrahecho | 1 |
| 3217 | contóme | 1 |
| 3218 | continuando | 1 |
| 3219 | continuada | 1 |
| 3220 | continua | 1 |
| 3221 | contino | 1 |
| 3222 | continencia | 1 |
| 3223 | contigo | 1 |
| 3224 | contienda | 1 |
| 3225 | contestar | 1 |
| 3226 | contentos | 1 |
| 3227 | contenté | 1 |
| 3228 | contentarme | 1 |
| 3229 | contemplar | 1 |
| 3230 | contemplación | 1 |
| 3231 | contemplaba | 1 |
| 3232 | contélos | 1 |
| 3233 | contéles | 1 |
| 3234 | contárselas | 1 |
| 3235 | contándolos | 1 |
| 3236 | contaminaba | 1 |
| 3237 | contadero | 1 |
| 3238 | consuelo | 1 |
| 3239 | constituido | 1 |
| 3240 | consolé | 1 |
| 3241 | consolarme | 1 |
| 3242 | consolara | 1 |
| 3243 | consolado | 1 |
| 3244 | consintió | 1 |
| 3245 | consigo | 1 |
| 3246 | consideren | 1 |
| 3247 | consideré | 1 |
| 3248 | conservas | 1 |
| 3249 | consagrada | 1 |
| 3250 | conoció | 1 |
| 3251 | conociera | 1 |
| 3252 | conocida | 1 |
| 3253 | congoja | 1 |
| 3254 | conformes | 1 |
| 3255 | conformaran | 1 |
| 3256 | confieso | 1 |
| 3257 | confiaba | 1 |
| 3258 | confesase | 1 |
| 3259 | confesando | 1 |
| 3260 | condes | 1 |
| 3261 | concierto | 1 |
| 3262 | concheta | 1 |
| 3263 | concha | 1 |
| 3264 | comunicase | 1 |
| 3265 | comunicar | 1 |
| 3266 | compremos | 1 |
| 3267 | compré | 1 |
| 3268 | comprar | 1 |
| 3269 | compasaba | 1 |
| 3270 | compás | 1 |
| 3271 | compañía | 1 |
| 3272 | comiste | 1 |
| 3273 | comió | 1 |
| 3274 | comimos | 1 |
| 3275 | comiésemos | 1 |
| 3276 | comiénzanme | 1 |
| 3277 | comiendo | 1 |
| 3278 | comídose | 1 |
| 3279 | comían | 1 |
| 3280 | cómete | 1 |
| 3281 | comerlo | 1 |
| 3282 | comeré | 1 |
| 3283 | comenzóme | 1 |
| 3284 | comenzados | 1 |
| 3285 | comenzaban | 1 |
| 3286 | comenzaba | 1 |
| 3287 | cómense | 1 |
| 3288 | comencélo | 1 |
| 3289 | comedirse | 1 |
| 3290 | comedirme | 1 |
| 3291 | comediría | 1 |
| 3292 | comarcanos | 1 |
| 3293 | colores | 1 |
| 3294 | colodrillo | 1 |
| 3295 | colgado | 1 |
| 3296 | colgadas | 1 |
| 3297 | colación | 1 |
| 3298 | coja | 1 |
| 3299 | cogote | 1 |
| 3300 | cogían | 1 |
| 3301 | cofradías | 1 |
| 3302 | coco | 1 |
| 3303 | cocido | 1 |
| 3304 | cocidas | 1 |
| 3305 | cocida | 1 |
| 3306 | cocía | 1 |
| 3307 | coces | 1 |
| 3308 | cobro | 1 |
| 3309 | cobrar | 1 |
| 3310 | cobardía | 1 |
| 3311 | clerecía | 1 |
| 3312 | clavó | 1 |
| 3313 | clavo | 1 |
| 3314 | clavazón | 1 |
| 3315 | clara | 1 |
| 3316 | ciñósela | 1 |
| 3317 | cinta | 1 |
| 3318 | cinchas | 1 |
| 3319 | ciertamente | 1 |
| 3320 | cierta | 1 |
| 3321 | cierrase | 1 |
| 3322 | cierras | 1 |
| 3323 | ciento | 1 |
| 3324 | ciegos | 1 |
| 3325 | ciégale | 1 |
| 3326 | cibdad | 1 |
| 3327 | chupando | 1 |
| 3328 | chaza | 1 |
| 3329 | cestos | 1 |
| 3330 | cesó | 1 |
| 3331 | cesaba | 1 |
| 3332 | certifico | 1 |
| 3333 | certificado | 1 |
| 3334 | cerrando | 1 |
| 3335 | cerrados | 1 |
| 3336 | cerrado | 1 |
| 3337 | cerrada | 1 |
| 3338 | cercenar | 1 |
| 3339 | cercano | 1 |
| 3340 | cercana | 1 |
| 3341 | centeno | 1 |
| 3342 | centenario | 1 |
| 3343 | cenas | 1 |
| 3344 | cenaremos | 1 |
| 3345 | cenado | 1 |
| 3346 | cena | 1 |
| 3347 | cegó | 1 |
| 3348 | cegalle | 1 |
| 3349 | cebo | 1 |
| 3350 | cebada | 1 |
| 3351 | cazador | 1 |
| 3352 | cazado | 1 |
| 3353 | cayóme | 1 |
| 3354 | caxco | 1 |
| 3355 | cautivos | 1 |
| 3356 | cautiverio | 1 |
| 3357 | caudal | 1 |
| 3358 | cato | 1 |
| 3359 | casta | 1 |
| 3360 | casé | 1 |
| 3361 | casase | 1 |
| 3362 | casarme | 1 |
| 3363 | casado | 1 |
| 3364 | carrera | 1 |
| 3365 | carpintero | 1 |
| 3366 | caro | 1 |
| 3367 | carnero | 1 |
| 3368 | cargase | 1 |
| 3369 | cargar | 1 |
| 3370 | cargada | 1 |
| 3371 | cargaban | 1 |
| 3372 | carecía | 1 |
| 3373 | carecen | 1 |
| 3374 | cardenales | 1 |
| 3375 | carcomida | 1 |
| 3376 | capuz | 1 |
| 3377 | captivos | 1 |
| 3378 | capean | 1 |
| 3379 | cañuto | 1 |
| 3380 | cántaros | 1 |
| 3381 | cantar | 1 |
| 3382 | cantado | 1 |
| 3383 | canónigos | 1 |
| 3384 | candelas | 1 |
| 3385 | canastillo | 1 |
| 3386 | campanas | 1 |
| 3387 | camisa | 1 |
| 3388 | caminos | 1 |
| 3389 | camareta | 1 |
| 3390 | camarero | 1 |
| 3391 | cámaras | 1 |
| 3392 | calofrío | 1 |
| 3393 | calló | 1 |
| 3394 | callo | 1 |
| 3395 | callé | 1 |
| 3396 | callase | 1 |
| 3397 | callando | 1 |
| 3398 | callados | 1 |
| 3399 | callabas | 1 |
| 3400 | caliente | 1 |
| 3401 | calidad | 1 |
| 3402 | calentarse | 1 |
| 3403 | calentarme | 1 |
| 3404 | calentar | 1 |
| 3405 | calentábamos | 1 |
| 3406 | caldo | 1 |
| 3407 | caldero | 1 |
| 3408 | calderero | 1 |
| 3409 | caldedero | 1 |
| 3410 | calabaza | 1 |
| 3411 | caída | 1 |
| 3412 | caí | 1 |
| 3413 | cae | 1 |
| 3414 | cabrón | 1 |
| 3415 | cabezas | 1 |
| 3416 | cabellos | 1 |
| 3417 | caballeros | 1 |
| 3418 | caballerizas | 1 |
| 3419 | cabacera | 1 |
| 3420 | ca | 1 |
| 3421 | buscó | 1 |
| 3422 | buscas | 1 |
| 3423 | buscan | 1 |
| 3424 | burlar | 1 |
| 3425 | burladores | 1 |
| 3426 | burlaba | 1 |
| 3427 | brujo | 1 |
| 3428 | brincaba | 1 |
| 3429 | brevedad | 1 |
| 3430 | brazos | 1 |
| 3431 | brazo | 1 |
| 3432 | brasero | 1 |
| 3433 | bramar | 1 |
| 3434 | bonito | 1 |
| 3435 | bonetes | 1 |
| 3436 | bolsilla | 1 |
| 3437 | bodigos | 1 |
| 3438 | bodegoneras | 1 |
| 3439 | blando | 1 |
| 3440 | blanda | 1 |
| 3441 | blancos | 1 |
| 3442 | birrete | 1 |
| 3443 | bienaventurados | 1 |
| 3444 | bienaventurado | 1 |
| 3445 | bésoos | 1 |
| 3446 | beso | 1 |
| 3447 | besada | 1 |
| 3448 | besaba | 1 |
| 3449 | berzas | 1 |
| 3450 | bendita | 1 |
| 3451 | bendiciones | 1 |
| 3452 | bellaco | 1 |
| 3453 | bebido | 1 |
| 3454 | bebí | 1 |
| 3455 | bastante | 1 |
| 3456 | bastaba | 1 |
| 3457 | basta | 1 |
| 3458 | barreno | 1 |
| 3459 | banquete | 1 |
| 3460 | bancos | 1 |
| 3461 | banco | 1 |
| 3462 | ballena | 1 |
| 3463 | bajos | 1 |
| 3464 | bajar | 1 |
| 3465 | bailábanle | 1 |
| 3466 | azotes | 1 |
| 3467 | azotaron | 1 |
| 3468 | azotando | 1 |
| 3469 | azogue | 1 |
| 3470 | ayuntamiento | 1 |
| 3471 | ayudase | 1 |
| 3472 | ayudarme | 1 |
| 3473 | ayudarle | 1 |
| 3474 | ayudándose | 1 |
| 3475 | ayudalle | 1 |
| 3476 | ayudadles | 1 |
| 3477 | ayer | 1 |
| 3478 | avivar | 1 |
| 3479 | avisos | 1 |
| 3480 | aviso | 1 |
| 3481 | avisaré | 1 |
| 3482 | avisar | 1 |
| 3483 | avisa | 1 |
| 3484 | avemarías | 1 |
| 3485 | avaricia | 1 |
| 3486 | autoridad | 1 |
| 3487 | augmentado | 1 |
| 3488 | auditorio | 1 |
| 3489 | atrever | 1 |
| 3490 | atravesar | 1 |
| 3491 | atestaba | 1 |
| 3492 | atentaba | 1 |
| 3493 | atapárselos | 1 |
| 3494 | atapábale | 1 |
| 3495 | atajo | 1 |
| 3496 | atada | 1 |
| 3497 | ataban | 1 |
| 3498 | asunto | 1 |
| 3499 | astutos | 1 |
| 3500 | astucias | 1 |
| 3501 | astucia | 1 |
| 3502 | asirle | 1 |
| 3503 | asióme | 1 |
| 3504 | asió | 1 |
| 3505 | asienta | 1 |
| 3506 | asiéndome | 1 |
| 3507 | asía | 1 |
| 3508 | asentóseme | 1 |
| 3509 | asentar | 1 |
| 3510 | asentaba | 1 |
| 3511 | asco | 1 |
| 3512 | asaz | 1 |
| 3513 | asase | 1 |
| 3514 | asar | 1 |
| 3515 | asa | 1 |
| 3516 | artificios | 1 |
| 3517 | artificio | 1 |
| 3518 | artífice | 1 |
| 3519 | arte | 1 |
| 3520 | arriméme | 1 |
| 3521 | arrimarse | 1 |
| 3522 | arrimarme | 1 |
| 3523 | arrimábase | 1 |
| 3524 | arrepintiese | 1 |
| 3525 | arrepentimiento | 1 |
| 3526 | arrepentí | 1 |
| 3527 | arremete | 1 |
| 3528 | arquetón | 1 |
| 3529 | armario | 1 |
| 3530 | armaré | 1 |
| 3531 | armado | 1 |
| 3532 | armada | 1 |
| 3533 | argolla | 1 |
| 3534 | ardideza | 1 |
| 3535 | ardía | 1 |
| 3536 | arcos | 1 |
| 3537 | arcipreste | 1 |
| 3538 | arcas | 1 |
| 3539 | arañada | 1 |
| 3540 | aquéstos | 1 |
| 3541 | aquestos | 1 |
| 3542 | aquéste | 1 |
| 3543 | aqueste | 1 |
| 3544 | aquejaba | 1 |
| 3545 | aprovechó | 1 |
| 3546 | aprovecharme | 1 |
| 3547 | aprovechara | 1 |
| 3548 | aprovechan | 1 |
| 3549 | aprovechábase | 1 |
| 3550 | apretar | 1 |
| 3551 | apretado | 1 |
| 3552 | aprendí | 1 |
| 3553 | aprende | 1 |
| 3554 | apetito | 1 |
| 3555 | apartalle | 1 |
| 3556 | aparejado | 1 |
| 3557 | aparejada | 1 |
| 3558 | apañador | 1 |
| 3559 | añadiendo | 1 |
| 3560 | antonio | 1 |
| 3561 | antona | 1 |
| 3562 | antiquísima | 1 |
| 3563 | antiguos | 1 |
| 3564 | antigua | 1 |
| 3565 | anoche | 1 |
| 3566 | aniquilada | 1 |
| 3567 | ánimas | 1 |
| 3568 | animar | 1 |
| 3569 | animales | 1 |
| 3570 | animaba | 1 |
| 3571 | ánima | 1 |
| 3572 | angosto | 1 |
| 3573 | angosta | 1 |
| 3574 | angélico | 1 |
| 3575 | anexado | 1 |
| 3576 | anduvimos | 1 |
| 3577 | anduvieron | 1 |
| 3578 | andas | 1 |
| 3579 | andando | 1 |
| 3580 | andan | 1 |
| 3581 | andamos | 1 |
| 3582 | andado | 1 |
| 3583 | andábase | 1 |
| 3584 | andá | 1 |
| 3585 | anda | 1 |
| 3586 | ancianos | 1 |
| 3587 | ancho | 1 |
| 3588 | ampollas | 1 |
| 3589 | amistades | 1 |
| 3590 | amistad | 1 |
| 3591 | amicísimo | 1 |
| 3592 | amenazas | 1 |
| 3593 | amasado | 1 |
| 3594 | amargo | 1 |
| 3595 | amagado | 1 |
| 3596 | alzado | 1 |
| 3597 | alumbró | 1 |
| 3598 | alumbrarme | 1 |
| 3599 | alumbrado | 1 |
| 3600 | alteróse | 1 |
| 3601 | alteró | 1 |
| 3602 | alterado | 1 |
| 3603 | alta | 1 |
| 3604 | alquiló | 1 |
| 3605 | alquiler | 1 |
| 3606 | alquilar | 1 |
| 3607 | alquilando | 1 |
| 3608 | alquilado | 1 |
| 3609 | almorox | 1 |
| 3610 | almonedas | 1 |
| 3611 | almohazas | 1 |
| 3612 | almodrote | 1 |
| 3613 | allegar | 1 |
| 3614 | allegaban | 1 |
| 3615 | aliento | 1 |
| 3616 | alhajas | 1 |
| 3617 | algodón | 1 |
| 3618 | alejandro | 1 |
| 3619 | alegría | 1 |
| 3620 | alegaron | 1 |
| 3621 | alderredores | 1 |
| 3622 | alderredor | 1 |
| 3623 | aldea | 1 |
| 3624 | aldaba | 1 |
| 3625 | alcanzara | 1 |
| 3626 | alargó | 1 |
| 3627 | alaben | 1 |
| 3628 | alabar | 1 |
| 3629 | alabanza | 1 |
| 3630 | ajenas | 1 |
| 3631 | aínas | 1 |
| 3632 | aína | 1 |
| 3633 | ahorré | 1 |
| 3634 | ahorraría | 1 |
| 3635 | ahorrar | 1 |
| 3636 | ahorcábamos | 1 |
| 3637 | ahora | 1 |
| 3638 | ahondaren | 1 |
| 3639 | ahogándome | 1 |
| 3640 | ahoga | 1 |
| 3641 | agujeta | 1 |
| 3642 | águila | 1 |
| 3643 | agudos | 1 |
| 3644 | aguda | 1 |
| 3645 | aguamanos | 1 |
| 3646 | aguacil | 1 |
| 3647 | agrade | 1 |
| 3648 | agradalle | 1 |
| 3649 | agonía | 1 |
| 3650 | afuera | 1 |
| 3651 | afrentarse | 1 |
| 3652 | afrentado | 1 |
| 3653 | afligidos | 1 |
| 3654 | afligida | 1 |
| 3655 | aflición | 1 |
| 3656 | afirmó | 1 |
| 3657 | afirmélo | 1 |
| 3658 | afilada | 1 |
| 3659 | adversidades | 1 |
| 3660 | adrede | 1 |
| 3661 | adquiría | 1 |
| 3662 | adobar | 1 |
| 3663 | adestró | 1 |
| 3664 | adestrar | 1 |
| 3665 | adestralle | 1 |
| 3666 | acullá | 1 |
| 3667 | acudieran | 1 |
| 3668 | acudía | 1 |
| 3669 | acuden | 1 |
| 3670 | acuda | 1 |
| 3671 | acreedores | 1 |
| 3672 | acostumbradas | 1 |
| 3673 | acostóse | 1 |
| 3674 | acordaba | 1 |
| 3675 | acompañar | 1 |
| 3676 | acometí | 1 |
| 3677 | acojámonos | 1 |
| 3678 | acogiese | 1 |
| 3679 | acogida | 1 |
| 3680 | acipreste | 1 |
| 3681 | achaque | 1 |
| 3682 | achacaron | 1 |
| 3683 | acertó | 1 |
| 3684 | aceros | 1 |
| 3685 | acero | 1 |
| 3686 | aceptaría | 1 |
| 3687 | acemilero | 1 |
| 3688 | aceites | 1 |
| 3689 | acaso | 1 |
| 3690 | acaeciónos | 1 |
| 3691 | acaecía | 1 |
| 3692 | acaben | 1 |
| 3693 | acabemos | 1 |
| 3694 | acabé | 1 |
| 3695 | acabe | 1 |
| 3696 | acabaran | 1 |
| 3697 | acabar | 1 |
| 3698 | acabados | 1 |
| 3699 | abundante | 1 |
| 3700 | abstinencia | 1 |
| 3701 | abrir | 1 |
| 3702 | abrió | 1 |
| 3703 | abrigo | 1 |
| 3704 | abriendo | 1 |
| 3705 | abríame | 1 |
| 3706 | abría | 1 |
| 3707 | abreviaba | 1 |
| 3708 | abren | 1 |
| 3709 | ábrela | 1 |
| 3710 | abrazándome | 1 |
| 3711 | abrasó | 1 |
| 3712 | aborrecieron | 1 |
| 3713 | aborrecido | 1 |
| 3714 | aborrecen | 1 |
| 3715 | ablandalle | 1 |
| 3716 | abierto | 1 |
| 3717 | abalanza | 1 |
| 3718 | abajara | 1 |
|
Ilustración del principio de mínimo esfuerzo: |
|
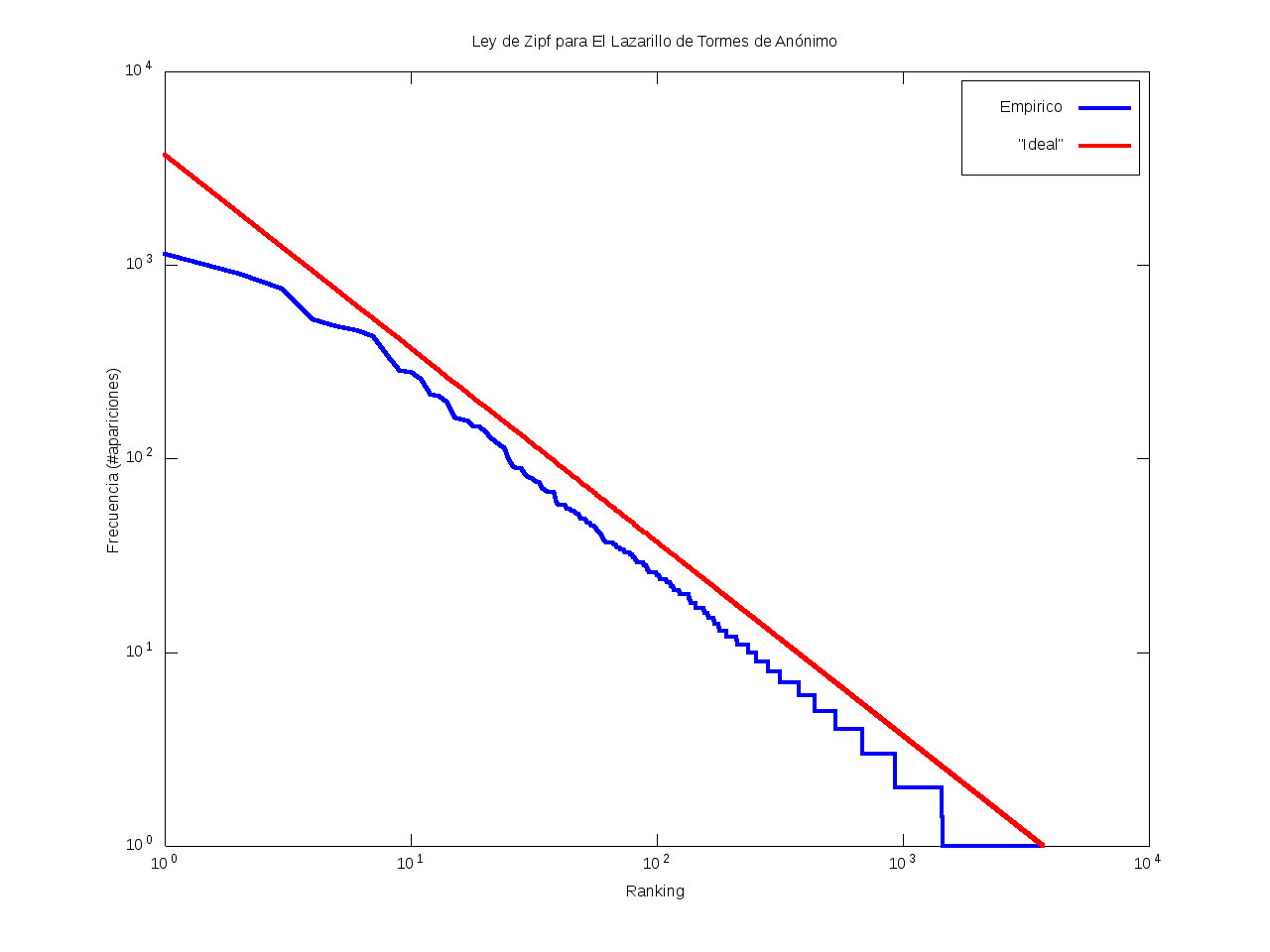
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará el texto actual (El Lazarillo de Tormes de Anónimo) (conjunto 1)
contra el resto de textos en el mismo idioma (Castellano) (conjunto 2).
A continuación se muestra una lista de las palabras presentes en el texto actual,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
Mostrar todo
Recoger