Comparativa: La Regenta contra La Regenta lematizada
Índice
Información General
| Título: | La Regenta |
|---|
| Autor: | Leopoldo Alas Clarín |
|---|
| Idioma: | Castellano |
|---|
| #Palabras total: | 308254 |
|---|
| #Palabras distintas: | 22907 |
|---|
| Type-Token ratio: | 7.43% |
|---|
|
| Título: | La Regenta (lematizado) |
|---|
| Autor: | Leopoldo Alas Clarín (lematizado) |
|---|
| Idioma: | Castellano (lematizado) |
|---|
| #Palabras total: | 308922 |
|---|
| #Palabras distintas: | 11595 |
|---|
| Type-Token ratio: | 3.75% |
|---|
|
Ley de Heaps - Saturación léxica
La Ley de Heaps es una ley empírica que predice el tamaño del vocabulario dado un texto.
Esto es, nos da una estimación del número de palabras distintas (v) dado el número total de palabras (n) de que consta el texto,
según la fórmula
v = K*n^b
donde b está entre 0 y 1 (habitualmente entre 0.4 y 0.6)
y K es una cierta constante, habitualmente entre 10 y 100.
En particular, mayores valores de b se corresponden con vocabularios más grandes,
en el sentido de que aumentan rápidamente;
mientras que se tienen valores menores de b cuando casi todo el vocabulario aparece al principio
y luego se van añadiendo muy pocos términos nuevos (el vocabulario se satura rápidamente).
| Regenta | Regenta_lemat |
|---|
| #Palabras: | #Palabras distintas: |
|---|
| 6165 | 2271 |
| 12330 | 3791 |
| 18495 | 4953 |
| 24660 | 5904 |
| 30825 | 6760 |
| 36990 | 7547 |
| 43155 | 8247 |
| 49320 | 8872 |
| 55485 | 9606 |
| 61650 | 10139 |
| 67815 | 10711 |
| 73980 | 11235 |
| 80145 | 11782 |
| 86310 | 12283 |
| 92475 | 12770 |
| 98640 | 13211 |
| 104805 | 13627 |
| 110970 | 14110 |
| 117135 | 14532 |
| 123300 | 14951 |
| 129465 | 15322 |
| 135630 | 15644 |
| 141795 | 15987 |
| 147960 | 16358 |
| 154125 | 16712 |
| 160290 | 17052 |
| 166455 | 17290 |
| 172620 | 17613 |
| 178785 | 17904 |
| 184950 | 18254 |
| 191115 | 18547 |
| 197280 | 18859 |
| 203445 | 19141 |
| 209610 | 19458 |
| 215775 | 19748 |
| 221940 | 19993 |
| 228105 | 20309 |
| 234270 | 20503 |
| 240435 | 20676 |
| 246600 | 20921 |
| 252765 | 21135 |
| 258930 | 21405 |
| 265095 | 21645 |
| 271260 | 21842 |
| 277425 | 22023 |
| 283590 | 22213 |
| 289755 | 22389 |
| 295920 | 22595 |
| 302085 | 22760 |
| 308250 | 22907 |
| 308254 | 22907 |
|
| #Palabras: | #Palabras distintas: |
|---|
| 6178 | 1747 |
| 12356 | 2775 |
| 18534 | 3494 |
| 24712 | 4048 |
| 30890 | 4515 |
| 37068 | 4931 |
| 43246 | 5286 |
| 49424 | 5581 |
| 55602 | 5962 |
| 61780 | 6210 |
| 67958 | 6492 |
| 74136 | 6739 |
| 80314 | 6963 |
| 86492 | 7199 |
| 92670 | 7426 |
| 98848 | 7629 |
| 105026 | 7847 |
| 111204 | 8069 |
| 117382 | 8260 |
| 123560 | 8429 |
| 129738 | 8588 |
| 135916 | 8723 |
| 142094 | 8860 |
| 148272 | 9028 |
| 154450 | 9169 |
| 160628 | 9310 |
| 166806 | 9392 |
| 172984 | 9533 |
| 179162 | 9645 |
| 185340 | 9797 |
| 191518 | 9922 |
| 197696 | 10067 |
| 203874 | 10173 |
| 210052 | 10285 |
| 216230 | 10397 |
| 222408 | 10487 |
| 228586 | 10622 |
| 234764 | 10697 |
| 240942 | 10756 |
| 247120 | 10858 |
| 253298 | 10945 |
| 259476 | 11053 |
| 265654 | 11159 |
| 271832 | 11223 |
| 278010 | 11294 |
| 284188 | 11353 |
| 290366 | 11429 |
| 296544 | 11490 |
| 302722 | 11534 |
| 308900 | 11595 |
| 308922 | 11595 |
|
|
Ajuste por mínimos cuadrados de los datos a K*n^b: |
| Regenta |
|
Regenta_lemat |
| K = 20.142 |
|
K = 43.718 |
| b = 0.561 |
|
b = 0.446 |

|
Ley de Zipf
La ley de Zipf es una ley empírica que se basa en el principio de mínimos esfuerzo.
Esto es, supone que existe un pequeño número de palabras, las más "conocidas", que son utilizadas con mucha frecuencia,
mientras que hay un gran número de palabras son poco empleadas.
Matemáticamente esto quiere decir que la frecuencia (número de apariciones) de una palabra cualquiera
es inversamente proporcional a su ranking,
entendido como su posición en una lista de las palabras presentes en el texto ordenada descendentemente en función de su frecuencia.
Así, la palabra más frecuente aparecerá aproximadamente dos veces más que la segunda palabra más frecuente,
unas tres veces más que la tercera palabra más frecuente, etc.
Gráficamente, cuando una curva se encuentra por encima de la recta "ideal"
quiere decir que el texto emplea recurrentemente un número de palabras muy reducido,
habiendo muy pocas que aparezcan con poca frecuencia.
Por el contrario, cuando la curva se encuentra por debajo de la "ideal",
el texto contiene un vocabulario más amplio, con muchas palabras que aparecen relativamente pocas veces.
| Regenta | Regenta_lemat |
Ilustración del principio de mínimo esfuerzo: |
| Rank | Palabra | Frec |
|---|
| 1 | de | 16580 |
| 2 | la | 11489 |
| 3 | que | 9901 |
| 4 | y | 9457 |
| 5 | el | 8268 |
| 6 | a | 7535 |
| 7 | en | 7137 |
| 8 | no | 4999 |
| 9 | se | 4779 |
| 10 | los | 4033 |
| 11 | con | 3202 |
| 12 | un | 3121 |
| 13 | su | 3084 |
| 14 | del | 3016 |
| 15 | las | 2939 |
| 16 | por | 2879 |
| 17 | le | 2436 |
| 18 | lo | 2335 |
| 19 | era | 2301 |
| 20 | había | 2212 |
| 21 | una | 2206 |
| 22 | al | 2168 |
| 23 | pero | 1914 |
| 24 | como | 1866 |
| 25 | don | 1798 |
| 26 | más | 1733 |
| 27 | para | 1377 |
| 28 | él | 1208 |
| 29 | es | 1193 |
| 30 | si | 1173 |
| 31 | sin | 1097 |
| 32 | qué | 1097 |
| 33 | ella | 1021 |
| 34 | sus | 1018 |
| 35 | todo | 917 |
| 36 | ya | 906 |
| 37 | ana | 898 |
| 38 | usted | 822 |
| 39 | magistral | 769 |
| 40 | aquella | 764 |
| 41 | aquel | 735 |
| 42 | estaba | 731 |
| 43 | yo | 712 |
| 44 | sí | 677 |
| 45 | ni | 672 |
| 46 | me | 638 |
| 47 | o | 635 |
| 48 | tenía | 610 |
| 49 | muy | 555 |
| 50 | sobre | 508 |
| 51 | cuando | 494 |
| 52 | víctor | 490 |
| 53 | álvaro | 490 |
| 54 | casa | 487 |
| 55 | regenta | 478 |
| 56 | vetusta | 471 |
| 57 | esto | 468 |
| 58 | señor | 460 |
| 59 | poco | 459 |
| 60 | allí | 450 |
| 61 | ser | 437 |
| 62 | nada | 434 |
| 63 | todos | 427 |
| 64 | después | 418 |
| 65 | doña | 414 |
| 66 | decía | 414 |
| 67 | porque | 401 |
| 68 | eso | 400 |
| 69 | vez | 392 |
| 70 | también | 378 |
| 71 | mesía | 373 |
| 72 | entre | 372 |
| 73 | podía | 369 |
| 74 | ahora | 364 |
| 75 | bien | 355 |
| 76 | hasta | 352 |
| 77 | esta | 351 |
| 78 | fermín | 350 |
| 79 | ojos | 347 |
| 80 | así | 347 |
| 81 | ha | 343 |
| 82 | mucho | 342 |
| 83 | dos | 334 |
| 84 | iba | 333 |
| 85 | eran | 333 |
| 86 | siempre | 332 |
| 87 | tan | 328 |
| 88 | quería | 328 |
| 89 | menos | 328 |
| 90 | vida | 326 |
| 91 | dijo | 326 |
| 92 | otra | 324 |
| 93 | algo | 321 |
| 94 | mismo | 320 |
| 95 | hombre | 318 |
| 96 | este | 314 |
| 97 | dios | 311 |
| 98 | veces | 307 |
| 99 | quintanar | 306 |
| 100 | otro | 303 |
| 101 | mundo | 303 |
| 102 | habían | 302 |
| 103 | mi | 291 |
| 104 | mujer | 286 |
| 105 | alma | 285 |
| 106 | todas | 284 |
| 107 | tiempo | 284 |
| 108 | ver | 280 |
| 109 | sabía | 279 |
| 110 | día | 272 |
| 111 | amor | 268 |
| 112 | parecía | 267 |
| 113 | madre | 267 |
| 114 | aquello | 266 |
| 115 | decir | 259 |
| 116 | mal | 252 |
| 117 | desde | 251 |
| 118 | tal | 249 |
| 119 | pues | 249 |
| 120 | cabeza | 247 |
| 121 | hay | 245 |
| 122 | petra | 241 |
| 123 | fue | 237 |
| 124 | voz | 235 |
| 125 | hacía | 234 |
| 126 | aquellos | 232 |
| 127 | mejor | 231 |
| 128 | cosa | 231 |
| 129 | noche | 230 |
| 130 | está | 230 |
| 131 | señora | 229 |
| 132 | quien | 229 |
| 133 | te | 225 |
| 134 | antes | 223 |
| 135 | toda | 221 |
| 136 | aunque | 219 |
| 137 | gran | 216 |
| 138 | sido | 214 |
| 139 | frígilis | 211 |
| 140 | tarde | 208 |
| 141 | además | 206 |
| 142 | buen | 205 |
| 143 | pensaba | 203 |
| 144 | nadie | 202 |
| 145 | creía | 200 |
| 146 | obdulia | 195 |
| 147 | según | 194 |
| 148 | entonces | 194 |
| 149 | otros | 192 |
| 150 | casi | 192 |
| 151 | aquellas | 190 |
| 152 | anita | 190 |
| 153 | hacer | 187 |
| 154 | cuanto | 187 |
| 155 | hubiera | 186 |
| 156 | donde | 186 |
| 157 | cómo | 186 |
| 158 | años | 186 |
| 159 | fuera | 185 |
| 160 | quién | 183 |
| 161 | tiene | 182 |
| 162 | mientras | 182 |
| 163 | días | 179 |
| 164 | hecho | 178 |
| 165 | aquí | 178 |
| 166 | sentía | 176 |
| 167 | dicho | 175 |
| 168 | daba | 175 |
| 169 | cada | 175 |
| 170 | cuerpo | 174 |
| 171 | paula | 173 |
| 172 | sólo | 172 |
| 173 | mano | 172 |
| 174 | pas | 171 |
| 175 | paco | 171 |
| 176 | dentro | 170 |
| 177 | allá | 167 |
| 178 | tanto | 166 |
| 179 | nunca | 165 |
| 180 | ese | 165 |
| 181 | visto | 163 |
| 182 | verdad | 162 |
| 183 | otras | 162 |
| 184 | hora | 162 |
| 185 | fin | 162 |
| 186 | hablaba | 161 |
| 187 | visita | 159 |
| 188 | marquesa | 159 |
| 189 | cosas | 159 |
| 190 | vio | 157 |
| 191 | veía | 156 |
| 192 | les | 156 |
| 193 | provisor | 155 |
| 194 | estas | 155 |
| 195 | volvió | 154 |
| 196 | debía | 152 |
| 197 | demás | 150 |
| 198 | sé | 147 |
| 199 | modo | 147 |
| 200 | luz | 147 |
| 201 | amigo | 147 |
| 202 | son | 145 |
| 203 | sintió | 145 |
| 204 | hija | 144 |
| 205 | puerta | 143 |
| 206 | tú | 141 |
| 207 | parte | 139 |
| 208 | padre | 138 |
| 209 | hijo | 138 |
| 210 | momento | 137 |
| 211 | misma | 137 |
| 212 | ellos | 137 |
| 213 | he | 135 |
| 214 | iglesia | 134 |
| 215 | muchos | 133 |
| 216 | miedo | 133 |
| 217 | hablar | 133 |
| 218 | vegallana | 132 |
| 219 | fuerza | 132 |
| 220 | sino | 131 |
| 221 | santos | 131 |
| 222 | tres | 130 |
| 223 | ronzal | 130 |
| 224 | oh | 130 |
| 225 | lado | 129 |
| 226 | obispo | 128 |
| 227 | manos | 128 |
| 228 | pobre | 127 |
| 229 | muchas | 127 |
| 230 | mayor | 127 |
| 231 | pensar | 126 |
| 232 | horas | 126 |
| 233 | esa | 126 |
| 234 | pompeyo | 125 |
| 235 | ozores | 124 |
| 236 | saber | 123 |
| 237 | sabe | 123 |
| 238 | marqués | 123 |
| 239 | algunos | 123 |
| 240 | medio | 122 |
| 241 | haber | 122 |
| 242 | dar | 121 |
| 243 | catedral | 121 |
| 244 | pie | 120 |
| 245 | mí | 120 |
| 246 | marido | 120 |
| 247 | espíritu | 118 |
| 248 | casino | 118 |
| 249 | buena | 118 |
| 250 | palabras | 117 |
| 251 | llamaba | 117 |
| 252 | lejos | 117 |
| 253 | estaban | 117 |
| 254 | pronto | 116 |
| 255 | cerca | 115 |
| 256 | calle | 115 |
| 257 | tuvo | 113 |
| 258 | puede | 113 |
| 259 | pies | 113 |
| 260 | silencio | 112 |
| 261 | señores | 112 |
| 262 | sería | 111 |
| 263 | corazón | 111 |
| 264 | uno | 110 |
| 265 | soy | 110 |
| 266 | paso | 109 |
| 267 | aire | 109 |
| 268 | pudo | 108 |
| 269 | cual | 108 |
| 270 | santa | 107 |
| 271 | san | 107 |
| 272 | hizo | 107 |
| 273 | pueblo | 106 |
| 274 | mañana | 106 |
| 275 | llegó | 106 |
| 276 | fuerte | 106 |
| 277 | parece | 105 |
| 278 | idea | 104 |
| 279 | estos | 104 |
| 280 | contra | 104 |
| 281 | agua | 104 |
| 282 | salió | 103 |
| 283 | ir | 103 |
| 284 | visitación | 102 |
| 285 | nos | 102 |
| 286 | grandes | 102 |
| 287 | cielo | 102 |
| 288 | volvía | 101 |
| 289 | pasión | 101 |
| 290 | media | 101 |
| 291 | rostro | 100 |
| 292 | quiere | 100 |
| 293 | cura | 100 |
| 294 | tener | 98 |
| 295 | pensó | 98 |
| 296 | sol | 97 |
| 297 | salón | 97 |
| 298 | ripamilán | 97 |
| 299 | dio | 97 |
| 300 | creo | 97 |
| 301 | bueno | 97 |
| 302 | quiero | 96 |
| 303 | pasar | 96 |
| 304 | cierto | 96 |
| 305 | venía | 95 |
| 306 | triste | 95 |
| 307 | poder | 95 |
| 308 | unos | 94 |
| 309 | tales | 94 |
| 310 | mesa | 94 |
| 311 | hacia | 94 |
| 312 | gritó | 94 |
| 313 | estoy | 94 |
| 314 | detrás | 94 |
| 315 | salir | 93 |
| 316 | foja | 93 |
| 317 | claro | 93 |
| 318 | caso | 93 |
| 319 | boca | 93 |
| 320 | todavía | 92 |
| 321 | ruido | 92 |
| 322 | pesar | 92 |
| 323 | balcón | 92 |
| 324 | nuevo | 91 |
| 325 | nueva | 91 |
| 326 | fe | 91 |
| 327 | camino | 91 |
| 328 | piedad | 90 |
| 329 | oía | 90 |
| 330 | jamás | 90 |
| 331 | ideas | 90 |
| 332 | glocester | 90 |
| 333 | entró | 90 |
| 334 | brazos | 90 |
| 335 | alegría | 90 |
| 336 | tenían | 89 |
| 337 | teatro | 89 |
| 338 | seguro | 89 |
| 339 | frío | 89 |
| 340 | delante | 89 |
| 341 | virtud | 88 |
| 342 | solo | 88 |
| 343 | placer | 87 |
| 344 | palabra | 87 |
| 345 | niña | 87 |
| 346 | grande | 87 |
| 347 | ello | 87 |
| 348 | dice | 87 |
| 349 | tierra | 86 |
| 350 | tengo | 86 |
| 351 | sea | 86 |
| 352 | religión | 86 |
| 353 | razón | 86 |
| 354 | va | 85 |
| 355 | puso | 85 |
| 356 | dejaba | 85 |
| 357 | cara | 84 |
| 358 | ustedes | 83 |
| 359 | solía | 83 |
| 360 | seguía | 83 |
| 361 | orgaz | 83 |
| 362 | general | 83 |
| 363 | canónigo | 83 |
| 364 | algunas | 83 |
| 365 | señoras | 82 |
| 366 | negro | 82 |
| 367 | llegaba | 82 |
| 368 | guimarán | 82 |
| 369 | alto | 82 |
| 370 | pasaba | 81 |
| 371 | mía | 81 |
| 372 | conciencia | 81 |
| 373 | siquiera | 80 |
| 374 | parecían | 80 |
| 375 | frente | 80 |
| 376 | libre | 79 |
| 377 | lecho | 79 |
| 378 | dulce | 79 |
| 379 | dónde | 79 |
| 380 | algún | 79 |
| 381 | paseo | 78 |
| 382 | miraba | 78 |
| 383 | joven | 78 |
| 384 | gabinete | 78 |
| 385 | ellas | 78 |
| 386 | ante | 78 |
| 387 | vivero | 77 |
| 388 | tu | 77 |
| 389 | oído | 77 |
| 390 | muerte | 77 |
| 391 | hace | 77 |
| 392 | pasado | 76 |
| 393 | fuese | 76 |
| 394 | estar | 76 |
| 395 | carne | 76 |
| 396 | arte | 76 |
| 397 | unas | 75 |
| 398 | debajo | 75 |
| 399 | bajo | 75 |
| 400 | amigos | 75 |
| 401 | pocas | 74 |
| 402 | cuatro | 74 |
| 403 | caer | 74 |
| 404 | bermúdez | 74 |
| 405 | arriba | 74 |
| 406 | alguna | 74 |
| 407 | volver | 73 |
| 408 | sola | 73 |
| 409 | mujeres | 73 |
| 410 | médico | 73 |
| 411 | madrid | 73 |
| 412 | despacho | 73 |
| 413 | abajo | 73 |
| 414 | repente | 72 |
| 415 | primero | 71 |
| 416 | falta | 71 |
| 417 | efecto | 71 |
| 418 | dejó | 71 |
| 419 | amiga | 71 |
| 420 | ahí | 71 |
| 421 | querido | 70 |
| 422 | preguntó | 70 |
| 423 | mil | 70 |
| 424 | entrar | 70 |
| 425 | trataba | 69 |
| 426 | puesto | 69 |
| 427 | miró | 69 |
| 428 | hoy | 69 |
| 429 | cuarto | 69 |
| 430 | único | 68 |
| 431 | recordaba | 68 |
| 432 | oír | 68 |
| 433 | mío | 68 |
| 434 | llegar | 68 |
| 435 | hombres | 68 |
| 436 | han | 68 |
| 437 | vetustenses | 67 |
| 438 | tampoco | 67 |
| 439 | sombra | 67 |
| 440 | salía | 67 |
| 441 | punto | 67 |
| 442 | pensando | 67 |
| 443 | obra | 67 |
| 444 | jesús | 67 |
| 445 | fuego | 67 |
| 446 | campo | 67 |
| 447 | cama | 67 |
| 448 | brazo | 67 |
| 449 | tono | 66 |
| 450 | santo | 66 |
| 451 | salud | 66 |
| 452 | petronila | 66 |
| 453 | estado | 66 |
| 454 | demasiado | 66 |
| 455 | cruz | 66 |
| 456 | cerebro | 66 |
| 457 | capilla | 66 |
| 458 | adelante | 66 |
| 459 | mala | 65 |
| 460 | honor | 65 |
| 461 | gracia | 65 |
| 462 | vetustense | 64 |
| 463 | ridículo | 64 |
| 464 | presencia | 64 |
| 465 | oro | 64 |
| 466 | ocasión | 64 |
| 467 | mucha | 64 |
| 468 | lágrimas | 64 |
| 469 | culpa | 64 |
| 470 | comer | 64 |
| 471 | vivir | 63 |
| 472 | sangre | 63 |
| 473 | mis | 63 |
| 474 | hubo | 63 |
| 475 | historia | 63 |
| 476 | fondo | 63 |
| 477 | vuelta | 62 |
| 478 | primera | 62 |
| 479 | manera | 62 |
| 480 | libros | 62 |
| 481 | clérigo | 62 |
| 482 | carlos | 62 |
| 483 | atrás | 62 |
| 484 | vamos | 61 |
| 485 | sentir | 61 |
| 486 | peor | 61 |
| 487 | pasó | 61 |
| 488 | ocho | 61 |
| 489 | natural | 61 |
| 490 | llegado | 61 |
| 491 | junto | 61 |
| 492 | duda | 61 |
| 493 | dejar | 61 |
| 494 | cuenta | 61 |
| 495 | conversación | 61 |
| 496 | arcipreste | 61 |
| 497 | vergüenza | 60 |
| 498 | quiso | 59 |
| 499 | peligro | 59 |
| 500 | parque | 59 |
| 501 | nombre | 59 |
| 502 | iban | 59 |
| 503 | espolón | 59 |
| 504 | esperaba | 59 |
| 505 | encontraba | 59 |
| 506 | dolor | 59 |
| 507 | cualquier | 59 |
| 508 | conocía | 59 |
| 509 | caserón | 59 |
| 510 | sentido | 58 |
| 511 | pudiera | 58 |
| 512 | primer | 58 |
| 513 | papel | 58 |
| 514 | miserable | 58 |
| 515 | diciendo | 58 |
| 516 | amo | 58 |
| 517 | alcoba | 58 |
| 518 | viejo | 57 |
| 519 | sueño | 57 |
| 520 | pensamiento | 57 |
| 521 | gritaba | 57 |
| 522 | enemigo | 57 |
| 523 | embargo | 57 |
| 524 | barinaga | 57 |
| 525 | suya | 56 |
| 526 | quedaba | 56 |
| 527 | puedo | 56 |
| 528 | pasos | 56 |
| 529 | leer | 56 |
| 530 | labios | 56 |
| 531 | decían | 56 |
| 532 | damas | 56 |
| 533 | calor | 56 |
| 534 | año | 56 |
| 535 | amores | 56 |
| 536 | ama | 56 |
| 537 | valor | 55 |
| 538 | teresina | 55 |
| 539 | temía | 55 |
| 540 | tantas | 55 |
| 541 | será | 55 |
| 542 | plaza | 55 |
| 543 | joaquín | 55 |
| 544 | confesonario | 55 |
| 545 | voluntad | 54 |
| 546 | vino | 54 |
| 547 | querer | 54 |
| 548 | quedó | 54 |
| 549 | mirada | 54 |
| 550 | juventud | 54 |
| 551 | frutos | 54 |
| 552 | espiritual | 54 |
| 553 | coro | 54 |
| 554 | confesión | 54 |
| 555 | carta | 54 |
| 556 | buscar | 54 |
| 557 | bastante | 54 |
| 558 | apenas | 54 |
| 559 | podían | 53 |
| 560 | noches | 53 |
| 561 | llevaba | 53 |
| 562 | juan | 53 |
| 563 | gusto | 53 |
| 564 | escándalo | 53 |
| 565 | entraba | 53 |
| 566 | edelmira | 53 |
| 567 | contestó | 53 |
| 568 | color | 53 |
| 569 | alegre | 53 |
| 570 | voy | 52 |
| 571 | versos | 52 |
| 572 | teresa | 52 |
| 573 | necesitaba | 52 |
| 574 | mar | 52 |
| 575 | luna | 52 |
| 576 | loca | 52 |
| 577 | hablaban | 52 |
| 578 | dado | 52 |
| 579 | blanco | 52 |
| 580 | traje | 51 |
| 581 | secreto | 51 |
| 582 | público | 51 |
| 583 | noble | 51 |
| 584 | libro | 51 |
| 585 | hombros | 51 |
| 586 | hermosa | 51 |
| 587 | hablado | 51 |
| 588 | d | 51 |
| 589 | buenas | 51 |
| 590 | anuncia | 51 |
| 591 | suelo | 50 |
| 592 | somoza | 50 |
| 593 | principal | 50 |
| 594 | ponía | 50 |
| 595 | niño | 50 |
| 596 | moral | 50 |
| 597 | exclamó | 50 |
| 598 | ex | 50 |
| 599 | esposa | 50 |
| 600 | esas | 50 |
| 601 | dedos | 50 |
| 602 | banco | 50 |
| 603 | tristeza | 49 |
| 604 | sabes | 49 |
| 605 | pocos | 49 |
| 606 | pedro | 49 |
| 607 | oyó | 49 |
| 608 | muerto | 49 |
| 609 | loco | 49 |
| 610 | ido | 49 |
| 611 | hacían | 49 |
| 612 | etc | 49 |
| 613 | digo | 49 |
| 614 | custodio | 49 |
| 615 | confianza | 49 |
| 616 | confesar | 49 |
| 617 | coche | 49 |
| 618 | clase | 49 |
| 619 | tomar | 48 |
| 620 | perder | 48 |
| 621 | pecado | 48 |
| 622 | naturaleza | 48 |
| 623 | música | 48 |
| 624 | humor | 48 |
| 625 | especie | 48 |
| 626 | dinero | 48 |
| 627 | curas | 48 |
| 628 | cuestión | 48 |
| 629 | creyó | 48 |
| 630 | clero | 48 |
| 631 | cayetano | 48 |
| 632 | atención | 48 |
| 633 | arcediano | 48 |
| 634 | ánimo | 48 |
| 635 | alta | 48 |
| 636 | acababa | 48 |
| 637 | templo | 47 |
| 638 | podría | 47 |
| 639 | persona | 47 |
| 640 | mozo | 47 |
| 641 | largo | 47 |
| 642 | huerta | 47 |
| 643 | hermosura | 47 |
| 644 | gritos | 47 |
| 645 | figuraba | 47 |
| 646 | figura | 47 |
| 647 | estilo | 47 |
| 648 | enfrente | 47 |
| 649 | doncella | 47 |
| 650 | digno | 47 |
| 651 | dama | 47 |
| 652 | ciertas | 47 |
| 653 | atrevió | 47 |
| 654 | pura | 46 |
| 655 | polvo | 46 |
| 656 | piedra | 46 |
| 657 | páez | 46 |
| 658 | morir | 46 |
| 659 | e | 46 |
| 660 | deseo | 46 |
| 661 | derecho | 46 |
| 662 | cierta | 46 |
| 663 | carraspique | 46 |
| 664 | amistad | 46 |
| 665 | verde | 45 |
| 666 | verano | 45 |
| 667 | sotana | 45 |
| 668 | solas | 45 |
| 669 | señorito | 45 |
| 670 | seguida | 45 |
| 671 | nubes | 45 |
| 672 | motivo | 45 |
| 673 | materia | 45 |
| 674 | influencia | 45 |
| 675 | importaba | 45 |
| 676 | habló | 45 |
| 677 | diez | 45 |
| 678 | cinco | 45 |
| 679 | ciencia | 45 |
| 680 | caridad | 45 |
| 681 | añadió | 45 |
| 682 | trabajo | 44 |
| 683 | tías | 44 |
| 684 | tenido | 44 |
| 685 | tantos | 44 |
| 686 | quiera | 44 |
| 687 | puro | 44 |
| 688 | personas | 44 |
| 689 | palacio | 44 |
| 690 | mejillas | 44 |
| 691 | marquesito | 44 |
| 692 | hierro | 44 |
| 693 | gesto | 44 |
| 694 | están | 44 |
| 695 | encontró | 44 |
| 696 | enamorado | 44 |
| 697 | daban | 44 |
| 698 | ciudad | 44 |
| 699 | benítez | 44 |
| 700 | aldea | 44 |
| 701 | acaso | 44 |
| 702 | última | 43 |
| 703 | segura | 43 |
| 704 | saturnino | 43 |
| 705 | sala | 43 |
| 706 | remedio | 43 |
| 707 | perdido | 43 |
| 708 | partido | 43 |
| 709 | llama | 43 |
| 710 | lástima | 43 |
| 711 | eres | 43 |
| 712 | entero | 43 |
| 713 | entendía | 43 |
| 714 | dando | 43 |
| 715 | culto | 43 |
| 716 | comedor | 43 |
| 717 | absurdo | 43 |
| 718 | pálido | 42 |
| 719 | nosotros | 42 |
| 720 | ningún | 42 |
| 721 | miradas | 42 |
| 722 | haciendo | 42 |
| 723 | entender | 42 |
| 724 | energía | 42 |
| 725 | debe | 42 |
| 726 | crimen | 42 |
| 727 | costumbre | 42 |
| 728 | blanca | 42 |
| 729 | aún | 42 |
| 730 | vista | 41 |
| 731 | último | 41 |
| 732 | tentación | 41 |
| 733 | sociedad | 41 |
| 734 | siguió | 41 |
| 735 | siguiente | 41 |
| 736 | monte | 41 |
| 737 | liberal | 41 |
| 738 | juntos | 41 |
| 739 | hijas | 41 |
| 740 | hablando | 41 |
| 741 | fueron | 41 |
| 742 | expresión | 41 |
| 743 | entrañas | 41 |
| 744 | empezaba | 41 |
| 745 | ejemplo | 41 |
| 746 | da | 41 |
| 747 | crespo | 41 |
| 748 | confesor | 41 |
| 749 | asunto | 41 |
| 750 | vivía | 40 |
| 751 | virgen | 40 |
| 752 | verle | 40 |
| 753 | trabuco | 40 |
| 754 | tomó | 40 |
| 755 | tienen | 40 |
| 756 | siendo | 40 |
| 757 | propósito | 40 |
| 758 | orgullo | 40 |
| 759 | luego | 40 |
| 760 | llena | 40 |
| 761 | hambre | 40 |
| 762 | faltaba | 40 |
| 763 | espalda | 40 |
| 764 | enfermo | 40 |
| 765 | enferma | 40 |
| 766 | dicen | 40 |
| 767 | cocina | 40 |
| 768 | cabo | 40 |
| 769 | baile | 40 |
| 770 | árboles | 40 |
| 771 | tienes | 39 |
| 772 | subía | 39 |
| 773 | sonreía | 39 |
| 774 | respeto | 39 |
| 775 | propia | 39 |
| 776 | principio | 39 |
| 777 | podido | 39 |
| 778 | partes | 39 |
| 779 | obscuro | 39 |
| 780 | obscuridad | 39 |
| 781 | ira | 39 |
| 782 | importa | 39 |
| 783 | imaginación | 39 |
| 784 | frase | 39 |
| 785 | esposo | 39 |
| 786 | esos | 39 |
| 787 | escena | 39 |
| 788 | enfermedad | 39 |
| 789 | enemigos | 39 |
| 790 | criada | 39 |
| 791 | correr | 39 |
| 792 | carcajadas | 39 |
| 793 | buenos | 39 |
| 794 | ve | 38 |
| 795 | soledad | 38 |
| 796 | serio | 38 |
| 797 | saturno | 38 |
| 798 | regente | 38 |
| 799 | realidad | 38 |
| 800 | pedía | 38 |
| 801 | pecho | 38 |
| 802 | paz | 38 |
| 803 | pasaban | 38 |
| 804 | orden | 38 |
| 805 | necesidad | 38 |
| 806 | levantó | 38 |
| 807 | leía | 38 |
| 808 | invierno | 38 |
| 809 | honra | 38 |
| 810 | esperanza | 38 |
| 811 | desgracia | 38 |
| 812 | debo | 38 |
| 813 | camila | 38 |
| 814 | café | 38 |
| 815 | basta | 38 |
| 816 | amante | 38 |
| 817 | vuelto | 37 |
| 818 | venir | 37 |
| 819 | ropa | 37 |
| 820 | rincón | 37 |
| 821 | procuraba | 37 |
| 822 | poner | 37 |
| 823 | meses | 37 |
| 824 | lleno | 37 |
| 825 | hojas | 37 |
| 826 | hermano | 37 |
| 827 | envidia | 37 |
| 828 | elegante | 37 |
| 829 | criados | 37 |
| 830 | causa | 37 |
| 831 | caballo | 37 |
| 832 | bosque | 37 |
| 833 | aventuras | 37 |
| 834 | acercó | 37 |
| 835 | viuda | 36 |
| 836 | vanidad | 36 |
| 837 | ti | 36 |
| 838 | temprano | 36 |
| 839 | tanta | 36 |
| 840 | supuesto | 36 |
| 841 | subir | 36 |
| 842 | propio | 36 |
| 843 | pobres | 36 |
| 844 | opinión | 36 |
| 845 | mirar | 36 |
| 846 | locura | 36 |
| 847 | habla | 36 |
| 848 | gracias | 36 |
| 849 | feliz | 36 |
| 850 | familia | 36 |
| 851 | entusiasmo | 36 |
| 852 | encima | 36 |
| 853 | cuello | 36 |
| 854 | creer | 36 |
| 855 | comprendió | 36 |
| 856 | colores | 36 |
| 857 | ay | 36 |
| 858 | anselmo | 36 |
| 859 | venganza | 35 |
| 860 | valía | 35 |
| 861 | tomaba | 35 |
| 862 | terreno | 35 |
| 863 | suyo | 35 |
| 864 | solemne | 35 |
| 865 | servía | 35 |
| 866 | recuerdos | 35 |
| 867 | recuerdo | 35 |
| 868 | provincia | 35 |
| 869 | presidente | 35 |
| 870 | piso | 35 |
| 871 | perro | 35 |
| 872 | paseos | 35 |
| 873 | niñas | 35 |
| 874 | minutos | 35 |
| 875 | memoria | 35 |
| 876 | malo | 35 |
| 877 | madera | 35 |
| 878 | lengua | 35 |
| 879 | imposible | 35 |
| 880 | ideal | 35 |
| 881 | hermoso | 35 |
| 882 | fría | 35 |
| 883 | fijo | 35 |
| 884 | escalera | 35 |
| 885 | encimada | 35 |
| 886 | duelo | 35 |
| 887 | darle | 35 |
| 888 | calles | 35 |
| 889 | aun | 35 |
| 890 | ateo | 35 |
| 891 | alas | 35 |
| 892 | abrió | 35 |
| 893 | torre | 34 |
| 894 | tomás | 34 |
| 895 | sonrisa | 34 |
| 896 | solos | 34 |
| 897 | señoritas | 34 |
| 898 | sabio | 34 |
| 899 | sabían | 34 |
| 900 | rodillas | 34 |
| 901 | robustiano | 34 |
| 902 | repetía | 34 |
| 903 | prefería | 34 |
| 904 | pepe | 34 |
| 905 | palomares | 34 |
| 906 | nuestro | 34 |
| 907 | nervios | 34 |
| 908 | necesario | 34 |
| 909 | llamaban | 34 |
| 910 | leído | 34 |
| 911 | joaquinito | 34 |
| 912 | infame | 34 |
| 913 | estrépito | 34 |
| 914 | cualquiera | 34 |
| 915 | cien | 34 |
| 916 | buscaba | 34 |
| 917 | baja | 34 |
| 918 | atrevía | 34 |
| 919 | voces | 33 |
| 920 | ventana | 33 |
| 921 | triunfo | 33 |
| 922 | suerte | 33 |
| 923 | sombrero | 33 |
| 924 | sentó | 33 |
| 925 | satisfecho | 33 |
| 926 | sacerdote | 33 |
| 927 | río | 33 |
| 928 | reloj | 33 |
| 929 | preciso | 33 |
| 930 | piernas | 33 |
| 931 | pensamientos | 33 |
| 932 | pedir | 33 |
| 933 | nuestra | 33 |
| 934 | misa | 33 |
| 935 | maría | 33 |
| 936 | hubiese | 33 |
| 937 | hogar | 33 |
| 938 | has | 33 |
| 939 | estuvo | 33 |
| 940 | edad | 33 |
| 941 | dormir | 33 |
| 942 | diría | 33 |
| 943 | dejado | 33 |
| 944 | deber | 33 |
| 945 | caballero | 33 |
| 946 | ataque | 33 |
| 947 | anda | 33 |
| 948 | visitas | 32 |
| 949 | viene | 32 |
| 950 | veras | 32 |
| 951 | supo | 32 |
| 952 | suave | 32 |
| 953 | religioso | 32 |
| 954 | pareció | 32 |
| 955 | negra | 32 |
| 956 | movía | 32 |
| 957 | menudo | 32 |
| 958 | lugar | 32 |
| 959 | llevar | 32 |
| 960 | levita | 32 |
| 961 | larga | 32 |
| 962 | inútil | 32 |
| 963 | instante | 32 |
| 964 | gozaba | 32 |
| 965 | gloria | 32 |
| 966 | género | 32 |
| 967 | fermo | 32 |
| 968 | esperar | 32 |
| 969 | durante | 32 |
| 970 | detuvo | 32 |
| 971 | derecha | 32 |
| 972 | cristales | 32 |
| 973 | corría | 32 |
| 974 | comprendía | 32 |
| 975 | compañía | 32 |
| 976 | celos | 32 |
| 977 | caza | 32 |
| 978 | calumnia | 32 |
| 979 | caía | 32 |
| 980 | abierto | 32 |
| 981 | terror | 31 |
| 982 | tenorio | 31 |
| 983 | sonrió | 31 |
| 984 | silla | 31 |
| 985 | salían | 31 |
| 986 | querida | 31 |
| 987 | querían | 31 |
| 988 | preguntaba | 31 |
| 989 | plata | 31 |
| 990 | patio | 31 |
| 991 | notó | 31 |
| 992 | nobleza | 31 |
| 993 | mire | 31 |
| 994 | libertad | 31 |
| 995 | juego | 31 |
| 996 | gato | 31 |
| 997 | fiebre | 31 |
| 998 | fama | 31 |
| 999 | deseos | 31 |
| 1000 | darse | 31 |
| 1001 | cariño | 31 |
| 1002 | capaz | 31 |
| 1003 | viento | 30 |
| 1004 | venido | 30 |
| 1005 | venían | 30 |
| 1006 | veían | 30 |
| 1007 | varias | 30 |
| 1008 | van | 30 |
| 1009 | traía | 30 |
| 1010 | socios | 30 |
| 1011 | segundo | 30 |
| 1012 | roja | 30 |
| 1013 | relaciones | 30 |
| 1014 | presente | 30 |
| 1015 | posible | 30 |
| 1016 | poesía | 30 |
| 1017 | piel | 30 |
| 1018 | pasa | 30 |
| 1019 | pan | 30 |
| 1020 | nobles | 30 |
| 1021 | negros | 30 |
| 1022 | mayores | 30 |
| 1023 | marqueses | 30 |
| 1024 | leyó | 30 |
| 1025 | jefe | 30 |
| 1026 | humilde | 30 |
| 1027 | hemos | 30 |
| 1028 | fortunato | 30 |
| 1029 | flores | 30 |
| 1030 | cristo | 30 |
| 1031 | cree | 30 |
| 1032 | corriente | 30 |
| 1033 | consuelo | 30 |
| 1034 | comía | 30 |
| 1035 | ayer | 30 |
| 1036 | anterior | 30 |
| 1037 | adiós | 30 |
| 1038 | viaje | 29 |
| 1039 | vestido | 29 |
| 1040 | talento | 29 |
| 1041 | sonriendo | 29 |
| 1042 | siglo | 29 |
| 1043 | servicio | 29 |
| 1044 | señorita | 29 |
| 1045 | seguir | 29 |
| 1046 | rufina | 29 |
| 1047 | remordimiento | 29 |
| 1048 | religiosa | 29 |
| 1049 | portal | 29 |
| 1050 | periódicos | 29 |
| 1051 | paredes | 29 |
| 1052 | pared | 29 |
| 1053 | olor | 29 |
| 1054 | nuevas | 29 |
| 1055 | necesito | 29 |
| 1056 | manteo | 29 |
| 1057 | letras | 29 |
| 1058 | huir | 29 |
| 1059 | habría | 29 |
| 1060 | gustaba | 29 |
| 1061 | grave | 29 |
| 1062 | gente | 29 |
| 1063 | fortuna | 29 |
| 1064 | formas | 29 |
| 1065 | forma | 29 |
| 1066 | echar | 29 |
| 1067 | dormía | 29 |
| 1068 | desprecio | 29 |
| 1069 | delicia | 29 |
| 1070 | decirle | 29 |
| 1071 | corrió | 29 |
| 1072 | contestaba | 29 |
| 1073 | broma | 29 |
| 1074 | almas | 29 |
| 1075 | alcalde | 29 |
| 1076 | vicio | 28 |
| 1077 | tertulia | 28 |
| 1078 | supiera | 28 |
| 1079 | sentidos | 28 |
| 1080 | semejante | 28 |
| 1081 | romántico | 28 |
| 1082 | quisiera | 28 |
| 1083 | prueba | 28 |
| 1084 | pecados | 28 |
| 1085 | oye | 28 |
| 1086 | olvido | 28 |
| 1087 | malicia | 28 |
| 1088 | llamó | 28 |
| 1089 | infierno | 28 |
| 1090 | humedad | 28 |
| 1091 | hacen | 28 |
| 1092 | habrá | 28 |
| 1093 | gobierno | 28 |
| 1094 | furioso | 28 |
| 1095 | extremo | 28 |
| 1096 | devoción | 28 |
| 1097 | cristiano | 28 |
| 1098 | costumbres | 28 |
| 1099 | costa | 28 |
| 1100 | contento | 28 |
| 1101 | comercio | 28 |
| 1102 | callaba | 28 |
| 1103 | balcones | 28 |
| 1104 | azul | 28 |
| 1105 | altar | 28 |
| 1106 | águeda | 28 |
| 1107 | abría | 28 |
| 1108 | aborrecía | 28 |
| 1109 | veinte | 27 |
| 1110 | vaya | 27 |
| 1111 | vano | 27 |
| 1112 | salido | 27 |
| 1113 | quedaban | 27 |
| 1114 | perfectamente | 27 |
| 1115 | olvidado | 27 |
| 1116 | obras | 27 |
| 1117 | ninguna | 27 |
| 1118 | mourelo | 27 |
| 1119 | máquina | 27 |
| 1120 | loreto | 27 |
| 1121 | llamar | 27 |
| 1122 | lábaro | 27 |
| 1123 | justicia | 27 |
| 1124 | jóvenes | 27 |
| 1125 | interés | 27 |
| 1126 | imagen | 27 |
| 1127 | hubieran | 27 |
| 1128 | haría | 27 |
| 1129 | francisco | 27 |
| 1130 | escribir | 27 |
| 1131 | elocuencia | 27 |
| 1132 | doce | 27 |
| 1133 | dejaban | 27 |
| 1134 | deja | 27 |
| 1135 | cuándo | 27 |
| 1136 | convento | 27 |
| 1137 | comprender | 27 |
| 1138 | casas | 27 |
| 1139 | buscó | 27 |
| 1140 | aya | 27 |
| 1141 | aventura | 27 |
| 1142 | añadía | 27 |
| 1143 | antojaba | 27 |
| 1144 | ambición | 27 |
| 1145 | alguno | 27 |
| 1146 | alegres | 27 |
| 1147 | vulgar | 26 |
| 1148 | vueltas | 26 |
| 1149 | trato | 26 |
| 1150 | trata | 26 |
| 1151 | tranquilo | 26 |
| 1152 | terrible | 26 |
| 1153 | tendría | 26 |
| 1154 | techo | 26 |
| 1155 | superior | 26 |
| 1156 | sueños | 26 |
| 1157 | seis | 26 |
| 1158 | sacristía | 26 |
| 1159 | recordó | 26 |
| 1160 | rayos | 26 |
| 1161 | ramas | 26 |
| 1162 | púlpito | 26 |
| 1163 | primavera | 26 |
| 1164 | prados | 26 |
| 1165 | objeto | 26 |
| 1166 | mejores | 26 |
| 1167 | maneras | 26 |
| 1168 | junta | 26 |
| 1169 | hacerse | 26 |
| 1170 | fuerzas | 26 |
| 1171 | fueran | 26 |
| 1172 | fantasía | 26 |
| 1173 | exigía | 26 |
| 1174 | eterna | 26 |
| 1175 | dulces | 26 |
| 1176 | digna | 26 |
| 1177 | dientes | 26 |
| 1178 | cuidado | 26 |
| 1179 | creído | 26 |
| 1180 | cenar | 26 |
| 1181 | celedonio | 26 |
| 1182 | carretera | 26 |
| 1183 | cármenes | 26 |
| 1184 | cansado | 26 |
| 1185 | borracho | 26 |
| 1186 | barón | 26 |
| 1187 | asuntos | 26 |
| 1188 | andar | 26 |
| 1189 | ambiente | 26 |
| 1190 | víctima | 25 |
| 1191 | verdadero | 25 |
| 1192 | ven | 25 |
| 1193 | tranquila | 25 |
| 1194 | tormento | 25 |
| 1195 | tiempos | 25 |
| 1196 | suyos | 25 |
| 1197 | sublime | 25 |
| 1198 | situación | 25 |
| 1199 | sitio | 25 |
| 1200 | siglos | 25 |
| 1201 | remordimientos | 25 |
| 1202 | presentó | 25 |
| 1203 | piedras | 25 |
| 1204 | pereza | 25 |
| 1205 | novelas | 25 |
| 1206 | niños | 25 |
| 1207 | necesita | 25 |
| 1208 | moría | 25 |
| 1209 | miserables | 25 |
| 1210 | marcha | 25 |
| 1211 | llave | 25 |
| 1212 | idiota | 25 |
| 1213 | hombro | 25 |
| 1214 | filósofo | 25 |
| 1215 | falda | 25 |
| 1216 | fácil | 25 |
| 1217 | emoción | 25 |
| 1218 | diablo | 25 |
| 1219 | despreciaba | 25 |
| 1220 | cuánto | 25 |
| 1221 | cuadros | 25 |
| 1222 | cuadro | 25 |
| 1223 | contrario | 25 |
| 1224 | continuó | 25 |
| 1225 | contar | 25 |
| 1226 | confesaba | 25 |
| 1227 | cólera | 25 |
| 1228 | cambio | 25 |
| 1229 | bedoya | 25 |
| 1230 | barca | 25 |
| 1231 | antiguo | 25 |
| 1232 | ah | 25 |
| 1233 | adentros | 25 |
| 1234 | vieja | 24 |
| 1235 | verse | 24 |
| 1236 | verdadera | 24 |
| 1237 | tinieblas | 24 |
| 1238 | siete | 24 |
| 1239 | sereno | 24 |
| 1240 | seda | 24 |
| 1241 | resolución | 24 |
| 1242 | parecer | 24 |
| 1243 | pálida | 24 |
| 1244 | pájaros | 24 |
| 1245 | oficio | 24 |
| 1246 | obscuras | 24 |
| 1247 | notar | 24 |
| 1248 | muerta | 24 |
| 1249 | malos | 24 |
| 1250 | maestro | 24 |
| 1251 | lodo | 24 |
| 1252 | llorar | 24 |
| 1253 | llenos | 24 |
| 1254 | ley | 24 |
| 1255 | fresco | 24 |
| 1256 | filosofía | 24 |
| 1257 | estrecha | 24 |
| 1258 | echaba | 24 |
| 1259 | dispuesto | 24 |
| 1260 | cuya | 24 |
| 1261 | comenzó | 24 |
| 1262 | chispas | 24 |
| 1263 | cera | 24 |
| 1264 | capa | 24 |
| 1265 | bah | 24 |
| 1266 | asco | 24 |
| 1267 | admiración | 24 |
| 1268 | yerba | 23 |
| 1269 | volvían | 23 |
| 1270 | ves | 23 |
| 1271 | vencer | 23 |
| 1272 | usaba | 23 |
| 1273 | tren | 23 |
| 1274 | tras | 23 |
| 1275 | tocador | 23 |
| 1276 | temblaba | 23 |
| 1277 | subió | 23 |
| 1278 | sonaba | 23 |
| 1279 | solían | 23 |
| 1280 | seria | 23 |
| 1281 | resistir | 23 |
| 1282 | quedado | 23 |
| 1283 | profunda | 23 |
| 1284 | poeta | 23 |
| 1285 | ojo | 23 |
| 1286 | oídos | 23 |
| 1287 | mística | 23 |
| 1288 | mirando | 23 |
| 1289 | ilustre | 23 |
| 1290 | hijos | 23 |
| 1291 | felicidad | 23 |
| 1292 | explicaba | 23 |
| 1293 | evitar | 23 |
| 1294 | estaría | 23 |
| 1295 | esfuerzo | 23 |
| 1296 | escrito | 23 |
| 1297 | elegantes | 23 |
| 1298 | dogma | 23 |
| 1299 | devota | 23 |
| 1300 | debilidad | 23 |
| 1301 | débil | 23 |
| 1302 | curiosidad | 23 |
| 1303 | conocido | 23 |
| 1304 | compasión | 23 |
| 1305 | colonia | 23 |
| 1306 | circunstancias | 23 |
| 1307 | carácter | 23 |
| 1308 | calma | 23 |
| 1309 | calló | 23 |
| 1310 | callar | 23 |
| 1311 | caballeros | 23 |
| 1312 | acto | 23 |
| 1313 | acordaba | 23 |
| 1314 | vulgares | 22 |
| 1315 | verla | 22 |
| 1316 | tuviera | 22 |
| 1317 | tristes | 22 |
| 1318 | trifón | 22 |
| 1319 | treinta | 22 |
| 1320 | tienda | 22 |
| 1321 | susto | 22 |
| 1322 | sombras | 22 |
| 1323 | serían | 22 |
| 1324 | salvación | 22 |
| 1325 | sacrificio | 22 |
| 1326 | saberlo | 22 |
| 1327 | saben | 22 |
| 1328 | risa | 22 |
| 1329 | ridícula | 22 |
| 1330 | respetable | 22 |
| 1331 | redondo | 22 |
| 1332 | rato | 22 |
| 1333 | pueden | 22 |
| 1334 | presentaba | 22 |
| 1335 | pormenores | 22 |
| 1336 | perdía | 22 |
| 1337 | pena | 22 |
| 1338 | pañuelo | 22 |
| 1339 | miseria | 22 |
| 1340 | metido | 22 |
| 1341 | mandaba | 22 |
| 1342 | llegaban | 22 |
| 1343 | leyes | 22 |
| 1344 | lectura | 22 |
| 1345 | galería | 22 |
| 1346 | firme | 22 |
| 1347 | fandiño | 22 |
| 1348 | familiar | 22 |
| 1349 | experiencia | 22 |
| 1350 | estrecho | 22 |
| 1351 | estás | 22 |
| 1352 | entierro | 22 |
| 1353 | encontrar | 22 |
| 1354 | encogió | 22 |
| 1355 | educación | 22 |
| 1356 | contacto | 22 |
| 1357 | contaba | 22 |
| 1358 | comedias | 22 |
| 1359 | cena | 22 |
| 1360 | cazador | 22 |
| 1361 | cantaba | 22 |
| 1362 | cabildo | 22 |
| 1363 | belleza | 22 |
| 1364 | beatas | 22 |
| 1365 | beata | 22 |
| 1366 | autoridad | 22 |
| 1367 | aprensiones | 22 |
| 1368 | afición | 22 |
| 1369 | acercaba | 22 |
| 1370 | acabó | 22 |
| 1371 | viva | 21 |
| 1372 | vinagre | 21 |
| 1373 | traición | 21 |
| 1374 | seno | 21 |
| 1375 | saludó | 21 |
| 1376 | rumor | 21 |
| 1377 | rubia | 21 |
| 1378 | rojo | 21 |
| 1379 | rival | 21 |
| 1380 | recordar | 21 |
| 1381 | quieren | 21 |
| 1382 | prisa | 21 |
| 1383 | primeras | 21 |
| 1384 | política | 21 |
| 1385 | perdón | 21 |
| 1386 | paquito | 21 |
| 1387 | papá | 21 |
| 1388 | paciencia | 21 |
| 1389 | oyendo | 21 |
| 1390 | oreja | 21 |
| 1391 | nerviosa | 21 |
| 1392 | movimiento | 21 |
| 1393 | momentos | 21 |
| 1394 | mitad | 21 |
| 1395 | mismos | 21 |
| 1396 | material | 21 |
| 1397 | luchar | 21 |
| 1398 | llevaban | 21 |
| 1399 | llegaron | 21 |
| 1400 | levantaba | 21 |
| 1401 | ja | 21 |
| 1402 | interior | 21 |
| 1403 | intención | 21 |
| 1404 | hola | 21 |
| 1405 | haya | 21 |
| 1406 | gozar | 21 |
| 1407 | fuertes | 21 |
| 1408 | fresca | 21 |
| 1409 | extraño | 21 |
| 1410 | esquina | 21 |
| 1411 | esfuerzos | 21 |
| 1412 | enamorada | 21 |
| 1413 | dormido | 21 |
| 1414 | dolores | 21 |
| 1415 | criadas | 21 |
| 1416 | copa | 21 |
| 1417 | convenía | 21 |
| 1418 | comedia | 21 |
| 1419 | cobarde | 21 |
| 1420 | civil | 21 |
| 1421 | ciertos | 21 |
| 1422 | cerró | 21 |
| 1423 | casos | 21 |
| 1424 | casada | 21 |
| 1425 | cantar | 21 |
| 1426 | camisa | 21 |
| 1427 | beneficiado | 21 |
| 1428 | aprensión | 21 |
| 1429 | antigua | 21 |
| 1430 | animal | 21 |
| 1431 | anchas | 21 |
| 1432 | amaba | 21 |
| 1433 | admiraba | 21 |
| 1434 | actividad | 21 |
| 1435 | victoria | 20 |
| 1436 | vestidos | 20 |
| 1437 | vestía | 20 |
| 1438 | venga | 20 |
| 1439 | tristezas | 20 |
| 1440 | tresillo | 20 |
| 1441 | tocaba | 20 |
| 1442 | suficiente | 20 |
| 1443 | sonreír | 20 |
| 1444 | siento | 20 |
| 1445 | servir | 20 |
| 1446 | secretos | 20 |
| 1447 | sacar | 20 |
| 1448 | respondía | 20 |
| 1449 | respecto | 20 |
| 1450 | reía | 20 |
| 1451 | protesta | 20 |
| 1452 | profundo | 20 |
| 1453 | perales | 20 |
| 1454 | pensado | 20 |
| 1455 | ocultar | 20 |
| 1456 | obscura | 20 |
| 1457 | nuevos | 20 |
| 1458 | movimientos | 20 |
| 1459 | mira | 20 |
| 1460 | matar | 20 |
| 1461 | lucha | 20 |
| 1462 | luces | 20 |
| 1463 | locos | 20 |
| 1464 | interrumpió | 20 |
| 1465 | habilidad | 20 |
| 1466 | grandeza | 20 |
| 1467 | germán | 20 |
| 1468 | garganta | 20 |
| 1469 | frases | 20 |
| 1470 | fortaleza | 20 |
| 1471 | fingía | 20 |
| 1472 | fiel | 20 |
| 1473 | faldas | 20 |
| 1474 | esperaban | 20 |
| 1475 | espada | 20 |
| 1476 | época | 20 |
| 1477 | empezó | 20 |
| 1478 | diócesis | 20 |
| 1479 | dignidad | 20 |
| 1480 | despertar | 20 |
| 1481 | dejando | 20 |
| 1482 | daño | 20 |
| 1483 | comida | 20 |
| 1484 | clérigos | 20 |
| 1485 | claridad | 20 |
| 1486 | chica | 20 |
| 1487 | carrera | 20 |
| 1488 | canónigos | 20 |
| 1489 | bromas | 20 |
| 1490 | bismarck | 20 |
| 1491 | asustada | 20 |
| 1492 | aristocracia | 20 |
| 1493 | acercarse | 20 |
| 1494 | voluptuosidad | 19 |
| 1495 | visiones | 19 |
| 1496 | viendo | 19 |
| 1497 | verá | 19 |
| 1498 | varios | 19 |
| 1499 | única | 19 |
| 1500 | soñaba | 19 |
| 1501 | somos | 19 |
| 1502 | sintiendo | 19 |
| 1503 | segunda | 19 |
| 1504 | satisfacer | 19 |
| 1505 | sabido | 19 |
| 1506 | rigor | 19 |
| 1507 | rey | 19 |
| 1508 | quinta | 19 |
| 1509 | quieres | 19 |
| 1510 | propuso | 19 |
| 1511 | primo | 19 |
| 1512 | precisamente | 19 |
| 1513 | político | 19 |
| 1514 | placeres | 19 |
| 1515 | piadosa | 19 |
| 1516 | pasiones | 19 |
| 1517 | pasillos | 19 |
| 1518 | par | 19 |
| 1519 | palco | 19 |
| 1520 | noticia | 19 |
| 1521 | notaba | 19 |
| 1522 | niebla | 19 |
| 1523 | montes | 19 |
| 1524 | moda | 19 |
| 1525 | manda | 19 |
| 1526 | mamá | 19 |
| 1527 | lujo | 19 |
| 1528 | lucía | 19 |
| 1529 | lloró | 19 |
| 1530 | levantarse | 19 |
| 1531 | león | 19 |
| 1532 | iría | 19 |
| 1533 | íntimo | 19 |
| 1534 | instinto | 19 |
| 1535 | impaciencia | 19 |
| 1536 | humo | 19 |
| 1537 | humildad | 19 |
| 1538 | habido | 19 |
| 1539 | guante | 19 |
| 1540 | grado | 19 |
| 1541 | frialdad | 19 |
| 1542 | fonda | 19 |
| 1543 | flor | 19 |
| 1544 | favor | 19 |
| 1545 | existencia | 19 |
| 1546 | espera | 19 |
| 1547 | entraban | 19 |
| 1548 | encontrado | 19 |
| 1549 | eclesiástico | 19 |
| 1550 | dueño | 19 |
| 1551 | drama | 19 |
| 1552 | distraído | 19 |
| 1553 | disgusto | 19 |
| 1554 | desdén | 19 |
| 1555 | cristiana | 19 |
| 1556 | conozco | 19 |
| 1557 | común | 19 |
| 1558 | cita | 19 |
| 1559 | ciego | 19 |
| 1560 | cesar | 19 |
| 1561 | calumnias | 19 |
| 1562 | asustado | 19 |
| 1563 | ambos | 19 |
| 1564 | volvieron | 18 |
| 1565 | verdes | 18 |
| 1566 | veo | 18 |
| 1567 | vejez | 18 |
| 1568 | v | 18 |
| 1569 | ta | 18 |
| 1570 | sonaban | 18 |
| 1571 | social | 18 |
| 1572 | sexo | 18 |
| 1573 | sermones | 18 |
| 1574 | señas | 18 |
| 1575 | sentada | 18 |
| 1576 | sabría | 18 |
| 1577 | rosa | 18 |
| 1578 | romanticismo | 18 |
| 1579 | puertas | 18 |
| 1580 | pueblos | 18 |
| 1581 | pública | 18 |
| 1582 | prudencia | 18 |
| 1583 | propios | 18 |
| 1584 | prohibido | 18 |
| 1585 | presentes | 18 |
| 1586 | poca | 18 |
| 1587 | pidió | 18 |
| 1588 | pasando | 18 |
| 1589 | pagaba | 18 |
| 1590 | orilla | 18 |
| 1591 | obscurecer | 18 |
| 1592 | novio | 18 |
| 1593 | novela | 18 |
| 1594 | noticias | 18 |
| 1595 | notado | 18 |
| 1596 | negaba | 18 |
| 1597 | naturales | 18 |
| 1598 | nacido | 18 |
| 1599 | muere | 18 |
| 1600 | muchacha | 18 |
| 1601 | ministro | 18 |
| 1602 | milagro | 18 |
| 1603 | matrimonio | 18 |
| 1604 | llamado | 18 |
| 1605 | irritaba | 18 |
| 1606 | hermana | 18 |
| 1607 | hastío | 18 |
| 1608 | hago | 18 |
| 1609 | grosero | 18 |
| 1610 | gorro | 18 |
| 1611 | fino | 18 |
| 1612 | fingiendo | 18 |
| 1613 | fanatismo | 18 |
| 1614 | fábrica | 18 |
| 1615 | exaltación | 18 |
| 1616 | estrellas | 18 |
| 1617 | estará | 18 |
| 1618 | espectáculo | 18 |
| 1619 | envidiaba | 18 |
| 1620 | egoísmo | 18 |
| 1621 | ea | 18 |
| 1622 | disimulo | 18 |
| 1623 | deshonra | 18 |
| 1624 | deseaba | 18 |
| 1625 | deje | 18 |
| 1626 | cuerda | 18 |
| 1627 | cristal | 18 |
| 1628 | creían | 18 |
| 1629 | corte | 18 |
| 1630 | convidados | 18 |
| 1631 | continuaba | 18 |
| 1632 | constantino | 18 |
| 1633 | conducta | 18 |
| 1634 | cogió | 18 |
| 1635 | chico | 18 |
| 1636 | cerrado | 18 |
| 1637 | casualidad | 18 |
| 1638 | capital | 18 |
| 1639 | bravo | 18 |
| 1640 | bóveda | 18 |
| 1641 | blancos | 18 |
| 1642 | bastaba | 18 |
| 1643 | barba | 18 |
| 1644 | audiencia | 18 |
| 1645 | antiguas | 18 |
| 1646 | andaba | 18 |
| 1647 | amarillo | 18 |
| 1648 | amable | 18 |
| 1649 | advirtió | 18 |
| 1650 | acordó | 18 |
| 1651 | vivos | 17 |
| 1652 | verja | 17 |
| 1653 | tus | 17 |
| 1654 | tiro | 17 |
| 1655 | tenemos | 17 |
| 1656 | sonriente | 17 |
| 1657 | sofá | 17 |
| 1658 | sistema | 17 |
| 1659 | sentimiento | 17 |
| 1660 | semana | 17 |
| 1661 | santidad | 17 |
| 1662 | rincones | 17 |
| 1663 | rico | 17 |
| 1664 | respondió | 17 |
| 1665 | repugnante | 17 |
| 1666 | reían | 17 |
| 1667 | real | 17 |
| 1668 | quince | 17 |
| 1669 | prima | 17 |
| 1670 | pretexto | 17 |
| 1671 | preparaba | 17 |
| 1672 | pozo | 17 |
| 1673 | ponerse | 17 |
| 1674 | personal | 17 |
| 1675 | personaje | 17 |
| 1676 | permitía | 17 |
| 1677 | paseaba | 17 |
| 1678 | paraguas | 17 |
| 1679 | pagar | 17 |
| 1680 | órgano | 17 |
| 1681 | ninguno | 17 |
| 1682 | montón | 17 |
| 1683 | misticismo | 17 |
| 1684 | miraban | 17 |
| 1685 | menor | 17 |
| 1686 | medias | 17 |
| 1687 | magistrado | 17 |
| 1688 | lujuria | 17 |
| 1689 | lluvia | 17 |
| 1690 | lloraba | 17 |
| 1691 | lleva | 17 |
| 1692 | levantar | 17 |
| 1693 | letra | 17 |
| 1694 | lejanos | 17 |
| 1695 | largos | 17 |
| 1696 | justo | 17 |
| 1697 | íntima | 17 |
| 1698 | inocente | 17 |
| 1699 | indignación | 17 |
| 1700 | in | 17 |
| 1701 | horror | 17 |
| 1702 | hipócrita | 17 |
| 1703 | hipocresía | 17 |
| 1704 | hechos | 17 |
| 1705 | hable | 17 |
| 1706 | gris | 17 |
| 1707 | gestos | 17 |
| 1708 | gas | 17 |
| 1709 | fuesen | 17 |
| 1710 | formidable | 17 |
| 1711 | fina | 17 |
| 1712 | farol | 17 |
| 1713 | estuviera | 17 |
| 1714 | espejo | 17 |
| 1715 | escuela | 17 |
| 1716 | escrúpulos | 17 |
| 1717 | empezado | 17 |
| 1718 | elemento | 17 |
| 1719 | diga | 17 |
| 1720 | difícil | 17 |
| 1721 | diablos | 17 |
| 1722 | descubierto | 17 |
| 1723 | delito | 17 |
| 1724 | creyendo | 17 |
| 1725 | contenerse | 17 |
| 1726 | contemplaba | 17 |
| 1727 | completamente | 17 |
| 1728 | coger | 17 |
| 1729 | caricias | 17 |
| 1730 | capricho | 17 |
| 1731 | caído | 17 |
| 1732 | busca | 17 |
| 1733 | brillaban | 17 |
| 1734 | besos | 17 |
| 1735 | bajaba | 17 |
| 1736 | ancho | 17 |
| 1737 | afán | 17 |
| 1738 | acudía | 17 |
| 1739 | abierta | 17 |
| 1740 | virtuosa | 16 |
| 1741 | vagamente | 16 |
| 1742 | trueno | 16 |
| 1743 | tomado | 16 |
| 1744 | ternura | 16 |
| 1745 | tenga | 16 |
| 1746 | tela | 16 |
| 1747 | tablas | 16 |
| 1748 | suertes | 16 |
| 1749 | subían | 16 |
| 1750 | sermón | 16 |
| 1751 | semejantes | 16 |
| 1752 | saltar | 16 |
| 1753 | sacaba | 16 |
| 1754 | ricos | 16 |
| 1755 | recibía | 16 |
| 1756 | rara | 16 |
| 1757 | quejaba | 16 |
| 1758 | quedarse | 16 |
| 1759 | pulso | 16 |
| 1760 | prudente | 16 |
| 1761 | prosa | 16 |
| 1762 | prometido | 16 |
| 1763 | procuró | 16 |
| 1764 | primeros | 16 |
| 1765 | preocupaciones | 16 |
| 1766 | pone | 16 |
| 1767 | personajes | 16 |
| 1768 | permiso | 16 |
| 1769 | penas | 16 |
| 1770 | pelo | 16 |
| 1771 | patria | 16 |
| 1772 | particular | 16 |
| 1773 | párroco | 16 |
| 1774 | parecido | 16 |
| 1775 | parar | 16 |
| 1776 | país | 16 |
| 1777 | ocasiones | 16 |
| 1778 | observó | 16 |
| 1779 | obligaba | 16 |
| 1780 | norte | 16 |
| 1781 | murmuraba | 16 |
| 1782 | multitud | 16 |
| 1783 | moralidad | 16 |
| 1784 | monjas | 16 |
| 1785 | mes | 16 |
| 1786 | mérito | 16 |
| 1787 | merecía | 16 |
| 1788 | melancolía | 16 |
| 1789 | mata | 16 |
| 1790 | malas | 16 |
| 1791 | llorando | 16 |
| 1792 | ladrón | 16 |
| 1793 | kempis | 16 |
| 1794 | juegos | 16 |
| 1795 | izquierda | 16 |
| 1796 | íntimos | 16 |
| 1797 | intereses | 16 |
| 1798 | infeliz | 16 |
| 1799 | humana | 16 |
| 1800 | fieles | 16 |
| 1801 | falso | 16 |
| 1802 | eterno | 16 |
| 1803 | estudiante | 16 |
| 1804 | especial | 16 |
| 1805 | escenas | 16 |
| 1806 | escalofríos | 16 |
| 1807 | entiende | 16 |
| 1808 | ensueños | 16 |
| 1809 | engañaba | 16 |
| 1810 | empezar | 16 |
| 1811 | emociones | 16 |
| 1812 | ejercicio | 16 |
| 1813 | dirá | 16 |
| 1814 | desierto | 16 |
| 1815 | derechos | 16 |
| 1816 | deleite | 16 |
| 1817 | cuidados | 16 |
| 1818 | cuesta | 16 |
| 1819 | conoce | 16 |
| 1820 | completo | 16 |
| 1821 | cómico | 16 |
| 1822 | colorado | 16 |
| 1823 | círculo | 16 |
| 1824 | cenador | 16 |
| 1825 | cayó | 16 |
| 1826 | cantando | 16 |
| 1827 | buscando | 16 |
| 1828 | bolsa | 16 |
| 1829 | beber | 16 |
| 1830 | asomaba | 16 |
| 1831 | asiento | 16 |
| 1832 | arena | 16 |
| 1833 | ardiente | 16 |
| 1834 | apareció | 16 |
| 1835 | aparecía | 16 |
| 1836 | alcohol | 16 |
| 1837 | agustín | 16 |
| 1838 | abiertos | 16 |
| 1839 | volviéndose | 15 |
| 1840 | volar | 15 |
| 1841 | viera | 15 |
| 1842 | vienen | 15 |
| 1843 | viejos | 15 |
| 1844 | vestida | 15 |
| 1845 | verso | 15 |
| 1846 | ventanas | 15 |
| 1847 | vale | 15 |
| 1848 | universal | 15 |
| 1849 | traído | 15 |
| 1850 | toma | 15 |
| 1851 | temer | 15 |
| 1852 | suspiró | 15 |
| 1853 | suaves | 15 |
| 1854 | solitario | 15 |
| 1855 | sobrina | 15 |
| 1856 | singular | 15 |
| 1857 | simpático | 15 |
| 1858 | sillas | 15 |
| 1859 | servían | 15 |
| 1860 | seco | 15 |
| 1861 | satisfecha | 15 |
| 1862 | satisfacción | 15 |
| 1863 | salieron | 15 |
| 1864 | saliendo | 15 |
| 1865 | ruidos | 15 |
| 1866 | rianzares | 15 |
| 1867 | revolución | 15 |
| 1868 | retórica | 15 |
| 1869 | raza | 15 |
| 1870 | rayo | 15 |
| 1871 | raíces | 15 |
| 1872 | puramente | 15 |
| 1873 | pudor | 15 |
| 1874 | procesión | 15 |
| 1875 | prestigio | 15 |
| 1876 | pluma | 15 |
| 1877 | pistola | 15 |
| 1878 | pierna | 15 |
| 1879 | periódico | 15 |
| 1880 | pensador | 15 |
| 1881 | pasaron | 15 |
| 1882 | pariente | 15 |
| 1883 | papeles | 15 |
| 1884 | oían | 15 |
| 1885 | ofrecía | 15 |
| 1886 | ocurrido | 15 |
| 1887 | nave | 15 |
| 1888 | muchachas | 15 |
| 1889 | moverse | 15 |
| 1890 | místico | 15 |
| 1891 | matarla | 15 |
| 1892 | matalerejo | 15 |
| 1893 | manía | 15 |
| 1894 | llega | 15 |
| 1895 | lenguaje | 15 |
| 1896 | intenso | 15 |
| 1897 | inocencia | 15 |
| 1898 | inmóvil | 15 |
| 1899 | infinito | 15 |
| 1900 | inclinó | 15 |
| 1901 | importante | 15 |
| 1902 | imitar | 15 |
| 1903 | imágenes | 15 |
| 1904 | ilusiones | 15 |
| 1905 | humanidad | 15 |
| 1906 | huesos | 15 |
| 1907 | hacerlo | 15 |
| 1908 | hacerle | 15 |
| 1909 | hablo | 15 |
| 1910 | hablaron | 15 |
| 1911 | fiesta | 15 |
| 1912 | estómago | 15 |
| 1913 | estación | 15 |
| 1914 | espeso | 15 |
| 1915 | españa | 15 |
| 1916 | espaldas | 15 |
| 1917 | escape | 15 |
| 1918 | entera | 15 |
| 1919 | elegancia | 15 |
| 1920 | eh | 15 |
| 1921 | dudaba | 15 |
| 1922 | diputado | 15 |
| 1923 | despidió | 15 |
| 1924 | desaire | 15 |
| 1925 | cuyo | 15 |
| 1926 | cumplido | 15 |
| 1927 | cuentas | 15 |
| 1928 | cubierta | 15 |
| 1929 | costaba | 15 |
| 1930 | conversaciones | 15 |
| 1931 | contenta | 15 |
| 1932 | consistía | 15 |
| 1933 | comían | 15 |
| 1934 | coches | 15 |
| 1935 | clases | 15 |
| 1936 | chato | 15 |
| 1937 | cerrar | 15 |
| 1938 | cementerio | 15 |
| 1939 | celestina | 15 |
| 1940 | cartas | 15 |
| 1941 | camoirán | 15 |
| 1942 | caían | 15 |
| 1943 | bolsillo | 15 |
| 1944 | beso | 15 |
| 1945 | batalla | 15 |
| 1946 | barrio | 15 |
| 1947 | ausencia | 15 |
| 1948 | aseguraba | 15 |
| 1949 | arrogante | 15 |
| 1950 | arqueólogo | 15 |
| 1951 | ángel | 15 |
| 1952 | amigas | 15 |
| 1953 | altas | 15 |
| 1954 | alrededor | 15 |
| 1955 | aires | 15 |
| 1956 | adelantado | 15 |
| 1957 | vulgo | 14 |
| 1958 | vicario | 14 |
| 1959 | vago | 14 |
| 1960 | uso | 14 |
| 1961 | últimos | 14 |
| 1962 | triunfante | 14 |
| 1963 | trabajar | 14 |
| 1964 | tonto | 14 |
| 1965 | tigre | 14 |
| 1966 | terminar | 14 |
| 1967 | terciopelo | 14 |
| 1968 | ten | 14 |
| 1969 | tapia | 14 |
| 1970 | suponía | 14 |
| 1971 | suma | 14 |
| 1972 | sucia | 14 |
| 1973 | sonrisas | 14 |
| 1974 | sincera | 14 |
| 1975 | símbolo | 14 |
| 1976 | seguían | 14 |
| 1977 | seducción | 14 |
| 1978 | sed | 14 |
| 1979 | seca | 14 |
| 1980 | salvaje | 14 |
| 1981 | saludaba | 14 |
| 1982 | salto | 14 |
| 1983 | ronca | 14 |
| 1984 | robado | 14 |
| 1985 | resuelto | 14 |
| 1986 | representaba | 14 |
| 1987 | reina | 14 |
| 1988 | refería | 14 |
| 1989 | recordando | 14 |
| 1990 | recibió | 14 |
| 1991 | raso | 14 |
| 1992 | puños | 14 |
| 1993 | procurar | 14 |
| 1994 | preguntar | 14 |
| 1995 | podrá | 14 |
| 1996 | pliegues | 14 |
| 1997 | planes | 14 |
| 1998 | plan | 14 |
| 1999 | piensa | 14 |
| 2000 | picante | 14 |
| 2001 | piadosas | 14 |
| 2002 | peso | 14 |
| 2003 | perdida | 14 |
| 2004 | pensaban | 14 |
| 2005 | peligros | 14 |
| 2006 | paseaban | 14 |
| 2007 | órdenes | 14 |
| 2008 | oración | 14 |
| 2009 | oportuno | 14 |
| 2010 | olvidó | 14 |
| 2011 | olía | 14 |
| 2012 | oiga | 14 |
| 2013 | objetos | 14 |
| 2014 | modos | 14 |
| 2015 | misteriosa | 14 |
| 2016 | mármol | 14 |
| 2017 | llevado | 14 |
| 2018 | llenas | 14 |
| 2019 | leyendo | 14 |
| 2020 | juraba | 14 |
| 2021 | juicio | 14 |
| 2022 | jesuitas | 14 |
| 2023 | jardín | 14 |
| 2024 | infanzón | 14 |
| 2025 | inefable | 14 |
| 2026 | incienso | 14 |
| 2027 | huía | 14 |
| 2028 | horizonte | 14 |
| 2029 | honrado | 14 |
| 2030 | hermanas | 14 |
| 2031 | hablarle | 14 |
| 2032 | hábito | 14 |
| 2033 | grupo | 14 |
| 2034 | grosera | 14 |
| 2035 | graves | 14 |
| 2036 | gobernador | 14 |
| 2037 | figuró | 14 |
| 2038 | fatiga | 14 |
| 2039 | faroles | 14 |
| 2040 | falsa | 14 |
| 2041 | extraña | 14 |
| 2042 | espinas | 14 |
| 2043 | española | 14 |
| 2044 | escribió | 14 |
| 2045 | entiendo | 14 |
| 2046 | encanto | 14 |
| 2047 | elocuente | 14 |
| 2048 | divertirse | 14 |
| 2049 | disparates | 14 |
| 2050 | disimular | 14 |
| 2051 | discretamente | 14 |
| 2052 | discreta | 14 |
| 2053 | despertó | 14 |
| 2054 | despedirse | 14 |
| 2055 | desnudos | 14 |
| 2056 | desnudo | 14 |
| 2057 | descanso | 14 |
| 2058 | dejarle | 14 |
| 2059 | dedo | 14 |
| 2060 | decírselo | 14 |
| 2061 | debían | 14 |
| 2062 | deben | 14 |
| 2063 | cuantos | 14 |
| 2064 | corrían | 14 |
| 2065 | coronel | 14 |
| 2066 | contraste | 14 |
| 2067 | contemplación | 14 |
| 2068 | constante | 14 |
| 2069 | consejos | 14 |
| 2070 | confidencias | 14 |
| 2071 | confesiones | 14 |
| 2072 | condiciones | 14 |
| 2073 | condición | 14 |
| 2074 | concepto | 14 |
| 2075 | comprar | 14 |
| 2076 | comenzaba | 14 |
| 2077 | columpio | 14 |
| 2078 | cocinero | 14 |
| 2079 | castidad | 14 |
| 2080 | calderón | 14 |
| 2081 | caja | 14 |
| 2082 | cabía | 14 |
| 2083 | baños | 14 |
| 2084 | bailar | 14 |
| 2085 | ayuda | 14 |
| 2086 | auditorio | 14 |
| 2087 | atrevido | 14 |
| 2088 | aspecto | 14 |
| 2089 | árbol | 14 |
| 2090 | apretaba | 14 |
| 2091 | apoyó | 14 |
| 2092 | apariencias | 14 |
| 2093 | ancha | 14 |
| 2094 | americano | 14 |
| 2095 | aliento | 14 |
| 2096 | alfombra | 14 |
| 2097 | agujero | 14 |
| 2098 | agradable | 14 |
| 2099 | acudir | 14 |
| 2100 | acostarse | 14 |
| 2101 | acero | 14 |
| 2102 | vuelo | 13 |
| 2103 | vocación | 13 |
| 2104 | vivían | 13 |
| 2105 | viernes | 13 |
| 2106 | vencido | 13 |
| 2107 | vaga | 13 |
| 2108 | tronco | 13 |
| 2109 | tranquilidad | 13 |
| 2110 | tocar | 13 |
| 2111 | tocado | 13 |
| 2112 | toca | 13 |
| 2113 | tía | 13 |
| 2114 | teología | 13 |
| 2115 | tentaciones | 13 |
| 2116 | temblorosa | 13 |
| 2117 | temblar | 13 |
| 2118 | tejados | 13 |
| 2119 | teatros | 13 |
| 2120 | tardes | 13 |
| 2121 | taberna | 13 |
| 2122 | suspiraba | 13 |
| 2123 | sudor | 13 |
| 2124 | sospechaba | 13 |
| 2125 | sopa | 13 |
| 2126 | sepa | 13 |
| 2127 | sentimientos | 13 |
| 2128 | sentado | 13 |
| 2129 | sentaba | 13 |
| 2130 | sencilla | 13 |
| 2131 | seminario | 13 |
| 2132 | sagrado | 13 |
| 2133 | sacrificios | 13 |
| 2134 | sacerdotes | 13 |
| 2135 | sabiduría | 13 |
| 2136 | rumores | 13 |
| 2137 | rubio | 13 |
| 2138 | rinconada | 13 |
| 2139 | rica | 13 |
| 2140 | repugnancia | 13 |
| 2141 | remediarlo | 13 |
| 2142 | reconocía | 13 |
| 2143 | recinto | 13 |
| 2144 | ratos | 13 |
| 2145 | queda | 13 |
| 2146 | puño | 13 |
| 2147 | puedes | 13 |
| 2148 | próxima | 13 |
| 2149 | probable | 13 |
| 2150 | pregunta | 13 |
| 2151 | porvenir | 13 |
| 2152 | poética | 13 |
| 2153 | poema | 13 |
| 2154 | pico | 13 |
| 2155 | piano | 13 |
| 2156 | perros | 13 |
| 2157 | pernueces | 13 |
| 2158 | pendiente | 13 |
| 2159 | pavimento | 13 |
| 2160 | pausa | 13 |
| 2161 | pasillo | 13 |
| 2162 | parroquia | 13 |
| 2163 | padrinos | 13 |
| 2164 | ofreció | 13 |
| 2165 | obreros | 13 |
| 2166 | nuestras | 13 |
| 2167 | novena | 13 |
| 2168 | negar | 13 |
| 2169 | narices | 13 |
| 2170 | muebles | 13 |
| 2171 | molestaba | 13 |
| 2172 | modista | 13 |
| 2173 | modelo | 13 |
| 2174 | místicas | 13 |
| 2175 | mismas | 13 |
| 2176 | millones | 13 |
| 2177 | medicina | 13 |
| 2178 | mas | 13 |
| 2179 | mártir | 13 |
| 2180 | mangas | 13 |
| 2181 | lugares | 13 |
| 2182 | locuras | 13 |
| 2183 | llevó | 13 |
| 2184 | llaves | 13 |
| 2185 | liberales | 13 |
| 2186 | lejano | 13 |
| 2187 | largas | 13 |
| 2188 | jugar | 13 |
| 2189 | ironía | 13 |
| 2190 | inteligente | 13 |
| 2191 | infancia | 13 |
| 2192 | indispensable | 13 |
| 2193 | inclinaba | 13 |
| 2194 | impulso | 13 |
| 2195 | ignorancia | 13 |
| 2196 | i | 13 |
| 2197 | hermosísima | 13 |
| 2198 | gustos | 13 |
| 2199 | guerra | 13 |
| 2200 | guardaba | 13 |
| 2201 | grupos | 13 |
| 2202 | golpe | 13 |
| 2203 | estimaba | 13 |
| 2204 | esperando | 13 |
| 2205 | escribía | 13 |
| 2206 | escondido | 13 |
| 2207 | escenario | 13 |
| 2208 | entrada | 13 |
| 2209 | engañado | 13 |
| 2210 | encogía | 13 |
| 2211 | encantos | 13 |
| 2212 | egoísta | 13 |
| 2213 | discurso | 13 |
| 2214 | devoto | 13 |
| 2215 | destino | 13 |
| 2216 | desconocido | 13 |
| 2217 | descalza | 13 |
| 2218 | desafío | 13 |
| 2219 | dejaron | 13 |
| 2220 | defendía | 13 |
| 2221 | cumplir | 13 |
| 2222 | cuarenta | 13 |
| 2223 | corro | 13 |
| 2224 | corriendo | 13 |
| 2225 | corre | 13 |
| 2226 | corfín | 13 |
| 2227 | conseguido | 13 |
| 2228 | conoció | 13 |
| 2229 | conocer | 13 |
| 2230 | comulgar | 13 |
| 2231 | comprendido | 13 |
| 2232 | clara | 13 |
| 2233 | chicos | 13 |
| 2234 | cerraba | 13 |
| 2235 | centro | 13 |
| 2236 | castigo | 13 |
| 2237 | casarse | 13 |
| 2238 | carretela | 13 |
| 2239 | carga | 13 |
| 2240 | cantaban | 13 |
| 2241 | calleja | 13 |
| 2242 | caliente | 13 |
| 2243 | cajón | 13 |
| 2244 | bajos | 13 |
| 2245 | azules | 13 |
| 2246 | autor | 13 |
| 2247 | atmósfera | 13 |
| 2248 | arrojaba | 13 |
| 2249 | apoyaba | 13 |
| 2250 | aparte | 13 |
| 2251 | apagados | 13 |
| 2252 | amar | 13 |
| 2253 | amado | 13 |
| 2254 | amabilidad | 13 |
| 2255 | altura | 13 |
| 2256 | algazara | 13 |
| 2257 | aldeana | 13 |
| 2258 | adulterio | 13 |
| 2259 | acompañaba | 13 |
| 2260 | acera | 13 |
| 2261 | acá | 13 |
| 2262 | vuelve | 12 |
| 2263 | volvería | 12 |
| 2264 | vivo | 12 |
| 2265 | visitar | 12 |
| 2266 | últimas | 12 |
| 2267 | tratándose | 12 |
| 2268 | traer | 12 |
| 2269 | tila | 12 |
| 2270 | temperamento | 12 |
| 2271 | tarea | 12 |
| 2272 | sucio | 12 |
| 2273 | sospechas | 12 |
| 2274 | sospechar | 12 |
| 2275 | solemnidad | 12 |
| 2276 | sociales | 12 |
| 2277 | sentarse | 12 |
| 2278 | sana | 12 |
| 2279 | salvo | 12 |
| 2280 | saltaba | 12 |
| 2281 | salida | 12 |
| 2282 | salesas | 12 |
| 2283 | sacó | 12 |
| 2284 | rum | 12 |
| 2285 | roto | 12 |
| 2286 | romántica | 12 |
| 2287 | respirar | 12 |
| 2288 | repitió | 12 |
| 2289 | religiosos | 12 |
| 2290 | religiosidad | 12 |
| 2291 | regiones | 12 |
| 2292 | reflejos | 12 |
| 2293 | razones | 12 |
| 2294 | punta | 12 |
| 2295 | puesta | 12 |
| 2296 | prosiguió | 12 |
| 2297 | propósitos | 12 |
| 2298 | promesa | 12 |
| 2299 | probablemente | 12 |
| 2300 | pretensiones | 12 |
| 2301 | pollos | 12 |
| 2302 | poético | 12 |
| 2303 | poderosa | 12 |
| 2304 | pobreza | 12 |
| 2305 | pobrecita | 12 |
| 2306 | plomo | 12 |
| 2307 | pienso | 12 |
| 2308 | pequeña | 12 |
| 2309 | penitencia | 12 |
| 2310 | parís | 12 |
| 2311 | pareja | 12 |
| 2312 | parecida | 12 |
| 2313 | paraba | 12 |
| 2314 | original | 12 |
| 2315 | oriente | 12 |
| 2316 | orador | 12 |
| 2317 | olvidar | 12 |
| 2318 | odio | 12 |
| 2319 | ocurrió | 12 |
| 2320 | ocupaciones | 12 |
| 2321 | observaba | 12 |
| 2322 | nuestros | 12 |
| 2323 | nervioso | 12 |
| 2324 | necios | 12 |
| 2325 | músculos | 12 |
| 2326 | murió | 12 |
| 2327 | muertos | 12 |
| 2328 | muda | 12 |
| 2329 | muchacho | 12 |
| 2330 | motivos | 12 |
| 2331 | morales | 12 |
| 2332 | mísero | 12 |
| 2333 | mirado | 12 |
| 2334 | miel | 12 |
| 2335 | merienda | 12 |
| 2336 | mentira | 12 |
| 2337 | meditaba | 12 |
| 2338 | materias | 12 |
| 2339 | marismas | 12 |
| 2340 | lontananza | 12 |
| 2341 | llanto | 12 |
| 2342 | literata | 12 |
| 2343 | limpieza | 12 |
| 2344 | liga | 12 |
| 2345 | leguas | 12 |
| 2346 | lecciones | 12 |
| 2347 | latín | 12 |
| 2348 | lascivia | 12 |
| 2349 | lámpara | 12 |
| 2350 | ladrones | 12 |
| 2351 | intimidad | 12 |
| 2352 | instintos | 12 |
| 2353 | indigno | 12 |
| 2354 | indiferencia | 12 |
| 2355 | inconveniente | 12 |
| 2356 | incapaz | 12 |
| 2357 | impulsos | 12 |
| 2358 | importancia | 12 |
| 2359 | húmeda | 12 |
| 2360 | hermandad | 12 |
| 2361 | hecha | 12 |
| 2362 | haga | 12 |
| 2363 | hacerla | 12 |
| 2364 | hablemos | 12 |
| 2365 | habitación | 12 |
| 2366 | gritar | 12 |
| 2367 | graciosa | 12 |
| 2368 | fuentes | 12 |
| 2369 | frescura | 12 |
| 2370 | fervor | 12 |
| 2371 | exige | 12 |
| 2372 | excepción | 12 |
| 2373 | excelente | 12 |
| 2374 | exaltada | 12 |
| 2375 | estrechas | 12 |
| 2376 | estatua | 12 |
| 2377 | espíritus | 12 |
| 2378 | especialmente | 12 |
| 2379 | escopeta | 12 |
| 2380 | entraron | 12 |
| 2381 | entrando | 12 |
| 2382 | entendido | 12 |
| 2383 | engaño | 12 |
| 2384 | engañar | 12 |
| 2385 | enérgico | 12 |
| 2386 | encuentro | 12 |
| 2387 | empleaba | 12 |
| 2388 | echado | 12 |
| 2389 | dulzura | 12 |
| 2390 | dominó | 12 |
| 2391 | dominaba | 12 |
| 2392 | distraída | 12 |
| 2393 | distancia | 12 |
| 2394 | discutía | 12 |
| 2395 | discreción | 12 |
| 2396 | dijera | 12 |
| 2397 | dificultades | 12 |
| 2398 | devoraba | 12 |
| 2399 | despreciar | 12 |
| 2400 | despertaba | 12 |
| 2401 | desgraciado | 12 |
| 2402 | desesperado | 12 |
| 2403 | demonio | 12 |
| 2404 | delirio | 12 |
| 2405 | dejarse | 12 |
| 2406 | declaró | 12 |
| 2407 | decirlo | 12 |
| 2408 | daría | 12 |
| 2409 | dan | 12 |
| 2410 | cuentos | 12 |
| 2411 | cubierto | 12 |
| 2412 | criminal | 12 |
| 2413 | crea | 12 |
| 2414 | corredor | 12 |
| 2415 | contestar | 12 |
| 2416 | contemplar | 12 |
| 2417 | consiguió | 12 |
| 2418 | consideraba | 12 |
| 2419 | conseguir | 12 |
| 2420 | conquista | 12 |
| 2421 | comido | 12 |
| 2422 | columnas | 12 |
| 2423 | codicia | 12 |
| 2424 | claramente | 12 |
| 2425 | cigarro | 12 |
| 2426 | ciega | 12 |
| 2427 | chimenea | 12 |
| 2428 | catecismo | 12 |
| 2429 | casero | 12 |
| 2430 | cargo | 12 |
| 2431 | cargados | 12 |
| 2432 | capitán | 12 |
| 2433 | brillantes | 12 |
| 2434 | boulevard | 12 |
| 2435 | biblioteca | 12 |
| 2436 | berlina | 12 |
| 2437 | bailes | 12 |
| 2438 | ayuntamiento | 12 |
| 2439 | atreverse | 12 |
| 2440 | ataques | 12 |
| 2441 | asesino | 12 |
| 2442 | artista | 12 |
| 2443 | armonía | 12 |
| 2444 | aragonés | 12 |
| 2445 | apretó | 12 |
| 2446 | apetito | 12 |
| 2447 | aparecer | 12 |
| 2448 | altos | 12 |
| 2449 | alimento | 12 |
| 2450 | aguardiente | 12 |
| 2451 | acuerdo | 12 |
| 2452 | actos | 12 |
| 2453 | acercándose | 12 |
| 2454 | acababan | 12 |
| 2455 | aburría | 12 |
| 2456 | abnegación | 12 |
| 2457 | abandono | 12 |
| 2458 | volverse | 11 |
| 2459 | vivido | 11 |
| 2460 | vive | 11 |
| 2461 | vientre | 11 |
| 2462 | vaso | 11 |
| 2463 | vas | 11 |
| 2464 | universo | 11 |
| 2465 | tuviese | 11 |
| 2466 | tratar | 11 |
| 2467 | tonta | 11 |
| 2468 | tirano | 11 |
| 2469 | tierna | 11 |
| 2470 | testigo | 11 |
| 2471 | términos | 11 |
| 2472 | temor | 11 |
| 2473 | temblando | 11 |
| 2474 | sufrir | 11 |
| 2475 | suavidad | 11 |
| 2476 | soñado | 11 |
| 2477 | so | 11 |
| 2478 | sierra | 11 |
| 2479 | siente | 11 |
| 2480 | servidumbre | 11 |
| 2481 | serios | 11 |
| 2482 | seriedad | 11 |
| 2483 | señoritos | 11 |
| 2484 | semanas | 11 |
| 2485 | seductor | 11 |
| 2486 | secas | 11 |
| 2487 | santas | 11 |
| 2488 | rosas | 11 |
| 2489 | rodeada | 11 |
| 2490 | robusto | 11 |
| 2491 | robusta | 11 |
| 2492 | rezaba | 11 |
| 2493 | representa | 11 |
| 2494 | regla | 11 |
| 2495 | recibir | 11 |
| 2496 | recado | 11 |
| 2497 | queriendo | 11 |
| 2498 | quedo | 11 |
| 2499 | puntillas | 11 |
| 2500 | pruebas | 11 |
| 2501 | proyecto | 11 |
| 2502 | proponía | 11 |
| 2503 | propias | 11 |
| 2504 | prójimo | 11 |
| 2505 | profanación | 11 |
| 2506 | presa | 11 |
| 2507 | preocupado | 11 |
| 2508 | prendas | 11 |
| 2509 | preguntas | 11 |
| 2510 | platos | 11 |
| 2511 | perseguía | 11 |
| 2512 | perfección | 11 |
| 2513 | perezosa | 11 |
| 2514 | pensarlo | 11 |
| 2515 | pedazos | 11 |
| 2516 | párpados | 11 |
| 2517 | paraíso | 11 |
| 2518 | palidez | 11 |
| 2519 | p | 11 |
| 2520 | otoño | 11 |
| 2521 | orgullosa | 11 |
| 2522 | oraciones | 11 |
| 2523 | once | 11 |
| 2524 | olas | 11 |
| 2525 | oculto | 11 |
| 2526 | nube | 11 |
| 2527 | novedad | 11 |
| 2528 | nombres | 11 |
| 2529 | negocio | 11 |
| 2530 | necedades | 11 |
| 2531 | náuseas | 11 |
| 2532 | nariz | 11 |
| 2533 | museo | 11 |
| 2534 | murmurar | 11 |
| 2535 | murmullo | 11 |
| 2536 | movían | 11 |
| 2537 | mostraba | 11 |
| 2538 | morada | 11 |
| 2539 | montaña | 11 |
| 2540 | monja | 11 |
| 2541 | mezclado | 11 |
| 2542 | medida | 11 |
| 2543 | mayo | 11 |
| 2544 | mate | 11 |
| 2545 | maridos | 11 |
| 2546 | maíz | 11 |
| 2547 | magnífico | 11 |
| 2548 | llenaban | 11 |
| 2549 | libres | 11 |
| 2550 | libertino | 11 |
| 2551 | leyenda | 11 |
| 2552 | latigazos | 11 |
| 2553 | juró | 11 |
| 2554 | jurado | 11 |
| 2555 | juntas | 11 |
| 2556 | jaqueca | 11 |
| 2557 | italiana | 11 |
| 2558 | irresistible | 11 |
| 2559 | interesante | 11 |
| 2560 | instrumento | 11 |
| 2561 | insignificante | 11 |
| 2562 | inmensa | 11 |
| 2563 | inmediatamente | 11 |
| 2564 | injusticia | 11 |
| 2565 | inglés | 11 |
| 2566 | infames | 11 |
| 2567 | imprudencia | 11 |
| 2568 | impresión | 11 |
| 2569 | iglesias | 11 |
| 2570 | humano | 11 |
| 2571 | higiene | 11 |
| 2572 | gusta | 11 |
| 2573 | guapa | 11 |
| 2574 | grito | 11 |
| 2575 | gracioso | 11 |
| 2576 | gozando | 11 |
| 2577 | golpes | 11 |
| 2578 | ganar | 11 |
| 2579 | gana | 11 |
| 2580 | fuente | 11 |
| 2581 | formalidad | 11 |
| 2582 | flaqueza | 11 |
| 2583 | flamenco | 11 |
| 2584 | filas | 11 |
| 2585 | fijos | 11 |
| 2586 | fija | 11 |
| 2587 | feo | 11 |
| 2588 | farsa | 11 |
| 2589 | faltaban | 11 |
| 2590 | fácilmente | 11 |
| 2591 | extremos | 11 |
| 2592 | extendía | 11 |
| 2593 | exposición | 11 |
| 2594 | explicó | 11 |
| 2595 | excursiones | 11 |
| 2596 | evidente | 11 |
| 2597 | eucaliptus | 11 |
| 2598 | estúpido | 11 |
| 2599 | estridente | 11 |
| 2600 | esté | 11 |
| 2601 | estamos | 11 |
| 2602 | espirituales | 11 |
| 2603 | esperanzas | 11 |
| 2604 | espanto | 11 |
| 2605 | escasa | 11 |
| 2606 | entrado | 11 |
| 2607 | entra | 11 |
| 2608 | enterado | 11 |
| 2609 | enfermedades | 11 |
| 2610 | encontraban | 11 |
| 2611 | empleado | 11 |
| 2612 | empeño | 11 |
| 2613 | eclesiástica | 11 |
| 2614 | echó | 11 |
| 2615 | duro | 11 |
| 2616 | dura | 11 |
| 2617 | dudar | 11 |
| 2618 | doctor | 11 |
| 2619 | discreto | 11 |
| 2620 | disciplina | 11 |
| 2621 | dirigió | 11 |
| 2622 | diré | 11 |
| 2623 | diente | 11 |
| 2624 | dicha | 11 |
| 2625 | diccionario | 11 |
| 2626 | diálogo | 11 |
| 2627 | desnuda | 11 |
| 2628 | desfachatez | 11 |
| 2629 | desaparecía | 11 |
| 2630 | decidió | 11 |
| 2631 | deberes | 11 |
| 2632 | cuyos | 11 |
| 2633 | cubría | 11 |
| 2634 | cubiertos | 11 |
| 2635 | cuartos | 11 |
| 2636 | cuantas | 11 |
| 2637 | creerse | 11 |
| 2638 | coquetería | 11 |
| 2639 | convencido | 11 |
| 2640 | continuar | 11 |
| 2641 | contigua | 11 |
| 2642 | contener | 11 |
| 2643 | contemplando | 11 |
| 2644 | conocían | 11 |
| 2645 | compañero | 11 |
| 2646 | comisión | 11 |
| 2647 | colocaba | 11 |
| 2648 | cogido | 11 |
| 2649 | chistes | 11 |
| 2650 | celosía | 11 |
| 2651 | cayendo | 11 |
| 2652 | católico | 11 |
| 2653 | católica | 11 |
| 2654 | cargado | 11 |
| 2655 | caprichos | 11 |
| 2656 | canciones | 11 |
| 2657 | calidad | 11 |
| 2658 | butacas | 11 |
| 2659 | bosques | 11 |
| 2660 | bondad | 11 |
| 2661 | blancas | 11 |
| 2662 | bajó | 11 |
| 2663 | asustaba | 11 |
| 2664 | arrastraba | 11 |
| 2665 | argumento | 11 |
| 2666 | apóstol | 11 |
| 2667 | antiguos | 11 |
| 2668 | ansias | 11 |
| 2669 | amparo | 11 |
| 2670 | amantes | 11 |
| 2671 | almunia | 11 |
| 2672 | aldeas | 11 |
| 2673 | agradecía | 11 |
| 2674 | acerca | 11 |
| 2675 | aceptó | 11 |
| 2676 | aburrimiento | 11 |
| 2677 | absoluta | 11 |
| 2678 | zorrilla | 10 |
| 2679 | zas | 10 |
| 2680 | zapatos | 10 |
| 2681 | vuelven | 10 |
| 2682 | volviendo | 10 |
| 2683 | voluptuoso | 10 |
| 2684 | voluptuosa | 10 |
| 2685 | volaba | 10 |
| 2686 | vigor | 10 |
| 2687 | vestir | 10 |
| 2688 | vería | 10 |
| 2689 | ventajas | 10 |
| 2690 | vecinos | 10 |
| 2691 | varón | 10 |
| 2692 | varas | 10 |
| 2693 | valiente | 10 |
| 2694 | tuvieron | 10 |
| 2695 | tribunal | 10 |
| 2696 | trébol | 10 |
| 2697 | trazas | 10 |
| 2698 | tomo | 10 |
| 2699 | tipo | 10 |
| 2700 | tersa | 10 |
| 2701 | tercera | 10 |
| 2702 | temo | 10 |
| 2703 | teja | 10 |
| 2704 | tardó | 10 |
| 2705 | tambor | 10 |
| 2706 | tabla | 10 |
| 2707 | suyas | 10 |
| 2708 | supremo | 10 |
| 2709 | supersticioso | 10 |
| 2710 | sujetaba | 10 |
| 2711 | suelta | 10 |
| 2712 | subido | 10 |
| 2713 | sube | 10 |
| 2714 | sospecha | 10 |
| 2715 | sorprendido | 10 |
| 2716 | sor | 10 |
| 2717 | solemnemente | 10 |
| 2718 | sofismas | 10 |
| 2719 | sobrenatural | 10 |
| 2720 | servanda | 10 |
| 2721 | serena | 10 |
| 2722 | sentimental | 10 |
| 2723 | senderos | 10 |
| 2724 | seguido | 10 |
| 2725 | sarcasmo | 10 |
| 2726 | sano | 10 |
| 2727 | salvar | 10 |
| 2728 | saludar | 10 |
| 2729 | sale | 10 |
| 2730 | sábanas | 10 |
| 2731 | s | 10 |
| 2732 | ruina | 10 |
| 2733 | rodeado | 10 |
| 2734 | roce | 10 |
| 2735 | rezar | 10 |
| 2736 | resto | 10 |
| 2737 | resistencia | 10 |
| 2738 | repetir | 10 |
| 2739 | recreo | 10 |
| 2740 | reconoció | 10 |
| 2741 | recoger | 10 |
| 2742 | pupilas | 10 |
| 2743 | propiedad | 10 |
| 2744 | propaganda | 10 |
| 2745 | prometió | 10 |
| 2746 | profanos | 10 |
| 2747 | probar | 10 |
| 2748 | preparar | 10 |
| 2749 | posición | 10 |
| 2750 | plantas | 10 |
| 2751 | pisar | 10 |
| 2752 | pícaro | 10 |
| 2753 | pesaba | 10 |
| 2754 | perfumes | 10 |
| 2755 | perfecta | 10 |
| 2756 | perdonaba | 10 |
| 2757 | percal | 10 |
| 2758 | pechera | 10 |
| 2759 | parientes | 10 |
| 2760 | parecen | 10 |
| 2761 | palomo | 10 |
| 2762 | pálidos | 10 |
| 2763 | padres | 10 |
| 2764 | padecía | 10 |
| 2765 | ordinaria | 10 |
| 2766 | olvidaba | 10 |
| 2767 | oírle | 10 |
| 2768 | obscuros | 10 |
| 2769 | nueve | 10 |
| 2770 | nosotras | 10 |
| 2771 | necedad | 10 |
| 2772 | muro | 10 |
| 2773 | murmuración | 10 |
| 2774 | moribundo | 10 |
| 2775 | mordía | 10 |
| 2776 | molino | 10 |
| 2777 | minuto | 10 |
| 2778 | ministra | 10 |
| 2779 | milagros | 10 |
| 2780 | metió | 10 |
| 2781 | metía | 10 |
| 2782 | mato | 10 |
| 2783 | materialismo | 10 |
| 2784 | masa | 10 |
| 2785 | marchaba | 10 |
| 2786 | mandado | 10 |
| 2787 | maldad | 10 |
| 2788 | majadero | 10 |
| 2789 | luis | 10 |
| 2790 | lógica | 10 |
| 2791 | llovía | 10 |
| 2792 | llenaba | 10 |
| 2793 | llamarse | 10 |
| 2794 | llaman | 10 |
| 2795 | limosna | 10 |
| 2796 | lección | 10 |
| 2797 | jugaba | 10 |
| 2798 | iré | 10 |
| 2799 | invencible | 10 |
| 2800 | insistió | 10 |
| 2801 | inocentes | 10 |
| 2802 | inglesa | 10 |
| 2803 | inés | 10 |
| 2804 | indudablemente | 10 |
| 2805 | importantes | 10 |
| 2806 | iguales | 10 |
| 2807 | igual | 10 |
| 2808 | ignoraba | 10 |
| 2809 | ídolo | 10 |
| 2810 | hueso | 10 |
| 2811 | hueco | 10 |
| 2812 | hondo | 10 |
| 2813 | hoja | 10 |
| 2814 | hierba | 10 |
| 2815 | hicieron | 10 |
| 2816 | hiciera | 10 |
| 2817 | hembra | 10 |
| 2818 | haberlo | 10 |
| 2819 | gritaron | 10 |
| 2820 | gr | 10 |
| 2821 | ganado | 10 |
| 2822 | gallo | 10 |
| 2823 | furor | 10 |
| 2824 | fulgosio | 10 |
| 2825 | frías | 10 |
| 2826 | francés | 10 |
| 2827 | flaca | 10 |
| 2828 | físico | 10 |
| 2829 | finos | 10 |
| 2830 | fingió | 10 |
| 2831 | figuras | 10 |
| 2832 | figurarse | 10 |
| 2833 | fiestas | 10 |
| 2834 | fiera | 10 |
| 2835 | fidelidad | 10 |
| 2836 | familias | 10 |
| 2837 | explicar | 10 |
| 2838 | expedientes | 10 |
| 2839 | expansiva | 10 |
| 2840 | estuviese | 10 |
| 2841 | estancia | 10 |
| 2842 | espesa | 10 |
| 2843 | escandaloso | 10 |
| 2844 | escandalosa | 10 |
| 2845 | entregado | 10 |
| 2846 | entregaba | 10 |
| 2847 | entendían | 10 |
| 2848 | echaban | 10 |
| 2849 | dormirse | 10 |
| 2850 | dorada | 10 |
| 2851 | doloroso | 10 |
| 2852 | dispense | 10 |
| 2853 | dignos | 10 |
| 2854 | despedía | 10 |
| 2855 | desconocida | 10 |
| 2856 | delgada | 10 |
| 2857 | delantero | 10 |
| 2858 | dejo | 10 |
| 2859 | declarar | 10 |
| 2860 | decidido | 10 |
| 2861 | dé | 10 |
| 2862 | cursis | 10 |
| 2863 | cursi | 10 |
| 2864 | curia | 10 |
| 2865 | cuchillo | 10 |
| 2866 | cuántas | 10 |
| 2867 | cuales | 10 |
| 2868 | cruel | 10 |
| 2869 | crucero | 10 |
| 2870 | crítica | 10 |
| 2871 | criterio | 10 |
| 2872 | crisis | 10 |
| 2873 | creí | 10 |
| 2874 | costó | 10 |
| 2875 | cortar | 10 |
| 2876 | convidado | 10 |
| 2877 | convertido | 10 |
| 2878 | conversión | 10 |
| 2879 | convalecencia | 10 |
| 2880 | constancia | 10 |
| 2881 | consiguiente | 10 |
| 2882 | conservar | 10 |
| 2883 | conseguía | 10 |
| 2884 | conmigo | 10 |
| 2885 | conferencia | 10 |
| 2886 | comentarios | 10 |
| 2887 | come | 10 |
| 2888 | columna | 10 |
| 2889 | colorada | 10 |
| 2890 | clarín | 10 |
| 2891 | cintura | 10 |
| 2892 | cincuenta | 10 |
| 2893 | cerrando | 10 |
| 2894 | cerrados | 10 |
| 2895 | célebre | 10 |
| 2896 | castaño | 10 |
| 2897 | casta | 10 |
| 2898 | carcajada | 10 |
| 2899 | capillas | 10 |
| 2900 | cánticos | 10 |
| 2901 | campos | 10 |
| 2902 | cabello | 10 |
| 2903 | caballos | 10 |
| 2904 | burla | 10 |
| 2905 | bronce | 10 |
| 2906 | brillaba | 10 |
| 2907 | botas | 10 |
| 2908 | borrachos | 10 |
| 2909 | bienes | 10 |
| 2910 | baronesa | 10 |
| 2911 | bancos | 10 |
| 2912 | ayudaba | 10 |
| 2913 | aviso | 10 |
| 2914 | atender | 10 |
| 2915 | atado | 10 |
| 2916 | arroyo | 10 |
| 2917 | arma | 10 |
| 2918 | argumentos | 10 |
| 2919 | arco | 10 |
| 2920 | aprovechaba | 10 |
| 2921 | apoyada | 10 |
| 2922 | aparente | 10 |
| 2923 | antigüedades | 10 |
| 2924 | amorosa | 10 |
| 2925 | amargura | 10 |
| 2926 | amanecer | 10 |
| 2927 | almohadas | 10 |
| 2928 | alguien | 10 |
| 2929 | alerta | 10 |
| 2930 | ajedrez | 10 |
| 2931 | afortunadamente | 10 |
| 2932 | aficionado | 10 |
| 2933 | adoraba | 10 |
| 2934 | adivinar | 10 |
| 2935 | acendrada | 10 |
| 2936 | acaba | 10 |
| 2937 | absoluto | 10 |
| 2938 | abrigo | 10 |
| 2939 | abismo | 10 |
| 2940 | volviera | 9 |
| 2941 | vistió | 9 |
| 2942 | visitaba | 9 |
| 2943 | violín | 9 |
| 2944 | violento | 9 |
| 2945 | vete | 9 |
| 2946 | vengo | 9 |
| 2947 | vencedor | 9 |
| 2948 | vela | 9 |
| 2949 | vecino | 9 |
| 2950 | vaciló | 9 |
| 2951 | útil | 9 |
| 2952 | tropezar | 9 |
| 2953 | trecho | 9 |
| 2954 | través | 9 |
| 2955 | trascoro | 9 |
| 2956 | trapo | 9 |
| 2957 | torpe | 9 |
| 2958 | tomaban | 9 |
| 2959 | tolerancia | 9 |
| 2960 | tocaban | 9 |
| 2961 | tesoro | 9 |
| 2962 | término | 9 |
| 2963 | tenerla | 9 |
| 2964 | taza | 9 |
| 2965 | tamaño | 9 |
| 2966 | sur | 9 |
| 2967 | suplicó | 9 |
| 2968 | sujeto | 9 |
| 2969 | sudaba | 9 |
| 2970 | suavemente | 9 |
| 2971 | soslayo | 9 |
| 2972 | sorpresa | 9 |
| 2973 | sonreían | 9 |
| 2974 | soberbia | 9 |
| 2975 | sillón | 9 |
| 2976 | sienes | 9 |
| 2977 | servido | 9 |
| 2978 | serlo | 9 |
| 2979 | seré | 9 |
| 2980 | sequedad | 9 |
| 2981 | separado | 9 |
| 2982 | señales | 9 |
| 2983 | señal | 9 |
| 2984 | sentirse | 9 |
| 2985 | sencillo | 9 |
| 2986 | seguridad | 9 |
| 2987 | salvarse | 9 |
| 2988 | saltaban | 9 |
| 2989 | sacudir | 9 |
| 2990 | sabrá | 9 |
| 2991 | saborear | 9 |
| 2992 | saboreaba | 9 |
| 2993 | rompía | 9 |
| 2994 | romper | 9 |
| 2995 | romería | 9 |
| 2996 | roma | 9 |
| 2997 | rodeaban | 9 |
| 2998 | rodar | 9 |
| 2999 | risas | 9 |
| 3000 | riqueza | 9 |
| 3001 | resultaba | 9 |
| 3002 | respuesta | 9 |
| 3003 | responsabilidad | 9 |
| 3004 | respiró | 9 |
| 3005 | respiraba | 9 |
| 3006 | respetar | 9 |
| 3007 | respetaba | 9 |
| 3008 | reflexiones | 9 |
| 3009 | redonda | 9 |
| 3010 | recursos | 9 |
| 3011 | recogió | 9 |
| 3012 | rebelión | 9 |
| 3013 | reacción | 9 |
| 3014 | rápida | 9 |
| 3015 | raíz | 9 |
| 3016 | quedaron | 9 |
| 3017 | puñetazo | 9 |
| 3018 | pulcritud | 9 |
| 3019 | pueda | 9 |
| 3020 | provecho | 9 |
| 3021 | propuesto | 9 |
| 3022 | proposición | 9 |
| 3023 | promesas | 9 |
| 3024 | programa | 9 |
| 3025 | producía | 9 |
| 3026 | principalmente | 9 |
| 3027 | presentarse | 9 |
| 3028 | prensa | 9 |
| 3029 | prenda | 9 |
| 3030 | preferido | 9 |
| 3031 | precio | 9 |
| 3032 | poniendo | 9 |
| 3033 | polka | 9 |
| 3034 | podemos | 9 |
| 3035 | población | 9 |
| 3036 | plato | 9 |
| 3037 | pierde | 9 |
| 3038 | pide | 9 |
| 3039 | pesimismo | 9 |
| 3040 | perfume | 9 |
| 3041 | perezoso | 9 |
| 3042 | perdió | 9 |
| 3043 | peláez | 9 |
| 3044 | pastor | 9 |
| 3045 | paseando | 9 |
| 3046 | partidario | 9 |
| 3047 | partida | 9 |
| 3048 | palos | 9 |
| 3049 | páginas | 9 |
| 3050 | ostentaba | 9 |
| 3051 | orillas | 9 |
| 3052 | oprimía | 9 |
| 3053 | opinaba | 9 |
| 3054 | ópera | 9 |
| 3055 | ocupaba | 9 |
| 3056 | ocultaba | 9 |
| 3057 | observación | 9 |
| 3058 | obligó | 9 |
| 3059 | nieve | 9 |
| 3060 | negras | 9 |
| 3061 | negó | 9 |
| 3062 | necesaria | 9 |
| 3063 | naves | 9 |
| 3064 | naturalismo | 9 |
| 3065 | nacimiento | 9 |
| 3066 | muralla | 9 |
| 3067 | muera | 9 |
| 3068 | moza | 9 |
| 3069 | morado | 9 |
| 3070 | místicos | 9 |
| 3071 | misterioso | 9 |
| 3072 | mirarle | 9 |
| 3073 | militar | 9 |
| 3074 | mezclaban | 9 |
| 3075 | merece | 9 |
| 3076 | materialista | 9 |
| 3077 | mañanas | 9 |
| 3078 | mandó | 9 |
| 3079 | loma | 9 |
| 3080 | líneas | 9 |
| 3081 | limpia | 9 |
| 3082 | ligero | 9 |
| 3083 | leve | 9 |
| 3084 | lance | 9 |
| 3085 | juez | 9 |
| 3086 | jesuita | 9 |
| 3087 | jesucristo | 9 |
| 3088 | isidro | 9 |
| 3089 | invisibles | 9 |
| 3090 | invisible | 9 |
| 3091 | inteligencia | 9 |
| 3092 | insignificantes | 9 |
| 3093 | ingrata | 9 |
| 3094 | ingleses | 9 |
| 3095 | inferior | 9 |
| 3096 | infalibilidad | 9 |
| 3097 | inclinándose | 9 |
| 3098 | inclinada | 9 |
| 3099 | imprudente | 9 |
| 3100 | impaciente | 9 |
| 3101 | ilustrada | 9 |
| 3102 | idealismo | 9 |
| 3103 | huyendo | 9 |
| 3104 | huérfana | 9 |
| 3105 | honrada | 9 |
| 3106 | hielo | 9 |
| 3107 | gravedad | 9 |
| 3108 | gratitud | 9 |
| 3109 | grandezas | 9 |
| 3110 | granada | 9 |
| 3111 | gordo | 9 |
| 3112 | glorieta | 9 |
| 3113 | froilán | 9 |
| 3114 | fríos | 9 |
| 3115 | frescas | 9 |
| 3116 | frecuentes | 9 |
| 3117 | franqueza | 9 |
| 3118 | frac | 9 |
| 3119 | flaco | 9 |
| 3120 | felices | 9 |
| 3121 | facultades | 9 |
| 3122 | explicaciones | 9 |
| 3123 | examen | 9 |
| 3124 | etiqueta | 9 |
| 3125 | estudio | 9 |
| 3126 | estrechos | 9 |
| 3127 | estrado | 9 |
| 3128 | esperó | 9 |
| 3129 | espacio | 9 |
| 3130 | esclavo | 9 |
| 3131 | enseñaba | 9 |
| 3132 | encerraba | 9 |
| 3133 | encantaba | 9 |
| 3134 | emprender | 9 |
| 3135 | empieza | 9 |
| 3136 | embozo | 9 |
| 3137 | eficaz | 9 |
| 3138 | efectos | 9 |
| 3139 | echando | 9 |
| 3140 | dormían | 9 |
| 3141 | dorado | 9 |
| 3142 | doradas | 9 |
| 3143 | dominio | 9 |
| 3144 | dominar | 9 |
| 3145 | doméstica | 9 |
| 3146 | divina | 9 |
| 3147 | divertido | 9 |
| 3148 | dispuesta | 9 |
| 3149 | disposición | 9 |
| 3150 | disimulada | 9 |
| 3151 | dirán | 9 |
| 3152 | dinástico | 9 |
| 3153 | dificultad | 9 |
| 3154 | desesperación | 9 |
| 3155 | descuido | 9 |
| 3156 | deprisa | 9 |
| 3157 | delicias | 9 |
| 3158 | delicado | 9 |
| 3159 | declaración | 9 |
| 3160 | decirse | 9 |
| 3161 | debió | 9 |
| 3162 | debes | 9 |
| 3163 | deán | 9 |
| 3164 | dándole | 9 |
| 3165 | damasco | 9 |
| 3166 | culpas | 9 |
| 3167 | cuervo | 9 |
| 3168 | cuánta | 9 |
| 3169 | crecía | 9 |
| 3170 | corto | 9 |
| 3171 | corrido | 9 |
| 3172 | convertía | 9 |
| 3173 | conventos | 9 |
| 3174 | contraria | 9 |
| 3175 | continuo | 9 |
| 3176 | contentarse | 9 |
| 3177 | contentaba | 9 |
| 3178 | consultar | 9 |
| 3179 | consigo | 9 |
| 3180 | conserje | 9 |
| 3181 | consentía | 9 |
| 3182 | conquistar | 9 |
| 3183 | conferencias | 9 |
| 3184 | comparación | 9 |
| 3185 | codos | 9 |
| 3186 | codo | 9 |
| 3187 | cochero | 9 |
| 3188 | clavados | 9 |
| 3189 | citas | 9 |
| 3190 | choque | 9 |
| 3191 | chateaubriand | 9 |
| 3192 | cerrada | 9 |
| 3193 | ceñida | 9 |
| 3194 | ceniza | 9 |
| 3195 | celo | 9 |
| 3196 | celebraba | 9 |
| 3197 | causaba | 9 |
| 3198 | católicos | 9 |
| 3199 | catalejo | 9 |
| 3200 | caro | 9 |
| 3201 | cariñosa | 9 |
| 3202 | cargada | 9 |
| 3203 | capellán | 9 |
| 3204 | cantó | 9 |
| 3205 | calvario | 9 |
| 3206 | caída | 9 |
| 3207 | cadáver | 9 |
| 3208 | burlaba | 9 |
| 3209 | brisa | 9 |
| 3210 | bofetadas | 9 |
| 3211 | blanda | 9 |
| 3212 | bendito | 9 |
| 3213 | bajar | 9 |
| 3214 | b | 9 |
| 3215 | autores | 9 |
| 3216 | aureola | 9 |
| 3217 | audacia | 9 |
| 3218 | aturdido | 9 |
| 3219 | atrevían | 9 |
| 3220 | atormentaba | 9 |
| 3221 | atento | 9 |
| 3222 | aspavientos | 9 |
| 3223 | asomó | 9 |
| 3224 | asombro | 9 |
| 3225 | asistir | 9 |
| 3226 | artes | 9 |
| 3227 | arrojó | 9 |
| 3228 | arquitectura | 9 |
| 3229 | armas | 9 |
| 3230 | armario | 9 |
| 3231 | aristócrata | 9 |
| 3232 | aprendido | 9 |
| 3233 | apagado | 9 |
| 3234 | antojaban | 9 |
| 3235 | amenazaba | 9 |
| 3236 | ahogaba | 9 |
| 3237 | agradecimiento | 9 |
| 3238 | admirado | 9 |
| 3239 | ademán | 9 |
| 3240 | acuerdas | 9 |
| 3241 | activa | 9 |
| 3242 | acostumbrado | 9 |
| 3243 | acólito | 9 |
| 3244 | acción | 9 |
| 3245 | abandonado | 9 |
| 3246 | zarzuela | 8 |
| 3247 | zapatillas | 8 |
| 3248 | vigilia | 8 |
| 3249 | viese | 8 |
| 3250 | vieron | 8 |
| 3251 | vicente | 8 |
| 3252 | verdura | 8 |
| 3253 | venerables | 8 |
| 3254 | venerable | 8 |
| 3255 | veneno | 8 |
| 3256 | vencida | 8 |
| 3257 | velas | 8 |
| 3258 | vea | 8 |
| 3259 | utilidad | 8 |
| 3260 | trémula | 8 |
| 3261 | trasnochadores | 8 |
| 3262 | trasaltar | 8 |
| 3263 | trapos | 8 |
| 3264 | trance | 8 |
| 3265 | trabajaba | 8 |
| 3266 | tordo | 8 |
| 3267 | torcido | 8 |
| 3268 | timbre | 8 |
| 3269 | tiendas | 8 |
| 3270 | testigos | 8 |
| 3271 | teoría | 8 |
| 3272 | tenue | 8 |
| 3273 | tendió | 8 |
| 3274 | tendida | 8 |
| 3275 | temible | 8 |
| 3276 | temblor | 8 |
| 3277 | tembló | 8 |
| 3278 | tajada | 8 |
| 3279 | sutiles | 8 |
| 3280 | sutil | 8 |
| 3281 | suprema | 8 |
| 3282 | superioridad | 8 |
| 3283 | sucesos | 8 |
| 3284 | sucedido | 8 |
| 3285 | sordo | 8 |
| 3286 | sorda | 8 |
| 3287 | solución | 8 |
| 3288 | solitaria | 8 |
| 3289 | sirvió | 8 |
| 3290 | sirve | 8 |
| 3291 | siguieron | 8 |
| 3292 | sigue | 8 |
| 3293 | siesta | 8 |
| 3294 | servicios | 8 |
| 3295 | serias | 8 |
| 3296 | señalando | 8 |
| 3297 | seña | 8 |
| 3298 | sensación | 8 |
| 3299 | sendas | 8 |
| 3300 | seducir | 8 |
| 3301 | secular | 8 |
| 3302 | saludo | 8 |
| 3303 | saludable | 8 |
| 3304 | salones | 8 |
| 3305 | sagrada | 8 |
| 3306 | sacudió | 8 |
| 3307 | sacramentos | 8 |
| 3308 | sabemos | 8 |
| 3309 | roquete | 8 |
| 3310 | románticas | 8 |
| 3311 | robles | 8 |
| 3312 | roble | 8 |
| 3313 | ridículas | 8 |
| 3314 | reyes | 8 |
| 3315 | revelaciones | 8 |
| 3316 | retirado | 8 |
| 3317 | resumen | 8 |
| 3318 | relámpago | 8 |
| 3319 | reír | 8 |
| 3320 | reinaba | 8 |
| 3321 | regular | 8 |
| 3322 | reconocer | 8 |
| 3323 | reconciliar | 8 |
| 3324 | recibido | 8 |
| 3325 | reaccionario | 8 |
| 3326 | rama | 8 |
| 3327 | racional | 8 |
| 3328 | rabia | 8 |
| 3329 | quitaba | 8 |
| 3330 | querrá | 8 |
| 3331 | pureza | 8 |
| 3332 | pudiese | 8 |
| 3333 | proyectos | 8 |
| 3334 | prosaica | 8 |
| 3335 | prometía | 8 |
| 3336 | principales | 8 |
| 3337 | preparativos | 8 |
| 3338 | prefiero | 8 |
| 3339 | preferían | 8 |
| 3340 | predicador | 8 |
| 3341 | precauciones | 8 |
| 3342 | prado | 8 |
| 3343 | positiva | 8 |
| 3344 | poniéndose | 8 |
| 3345 | pongo | 8 |
| 3346 | poéticas | 8 |
| 3347 | podrida | 8 |
| 3348 | plumas | 8 |
| 3349 | plazuela | 8 |
| 3350 | platónico | 8 |
| 3351 | pintada | 8 |
| 3352 | pinos | 8 |
| 3353 | pillo | 8 |
| 3354 | piadoso | 8 |
| 3355 | pesadilla | 8 |
| 3356 | perseguir | 8 |
| 3357 | perdiz | 8 |
| 3358 | perdiendo | 8 |
| 3359 | perdices | 8 |
| 3360 | pequeños | 8 |
| 3361 | pepa | 8 |
| 3362 | pasear | 8 |
| 3363 | parches | 8 |
| 3364 | papa | 8 |
| 3365 | pantorrilla | 8 |
| 3366 | pantalones | 8 |
| 3367 | palmo | 8 |
| 3368 | palique | 8 |
| 3369 | palacios | 8 |
| 3370 | pájaro | 8 |
| 3371 | paisano | 8 |
| 3372 | os | 8 |
| 3373 | orejas | 8 |
| 3374 | ordinario | 8 |
| 3375 | oratorio | 8 |
| 3376 | ora | 8 |
| 3377 | oleaje | 8 |
| 3378 | oigo | 8 |
| 3379 | ocurría | 8 |
| 3380 | ocupaban | 8 |
| 3381 | obstáculos | 8 |
| 3382 | obispado | 8 |
| 3383 | novedades | 8 |
| 3384 | niñez | 8 |
| 3385 | niego | 8 |
| 3386 | necesitó | 8 |
| 3387 | nazareno | 8 |
| 3388 | muero | 8 |
| 3389 | mueble | 8 |
| 3390 | mozos | 8 |
| 3391 | movió | 8 |
| 3392 | mortal | 8 |
| 3393 | monedas | 8 |
| 3394 | mitología | 8 |
| 3395 | misterio | 8 |
| 3396 | minas | 8 |
| 3397 | mercado | 8 |
| 3398 | mentir | 8 |
| 3399 | melancólico | 8 |
| 3400 | melancólica | 8 |
| 3401 | mejilla | 8 |
| 3402 | médicos | 8 |
| 3403 | mediante | 8 |
| 3404 | martirio | 8 |
| 3405 | marfil | 8 |
| 3406 | máquinas | 8 |
| 3407 | mantener | 8 |
| 3408 | manejaba | 8 |
| 3409 | mandar | 8 |
| 3410 | maldito | 8 |
| 3411 | majestuoso | 8 |
| 3412 | macho | 8 |
| 3413 | lumbre | 8 |
| 3414 | llegaría | 8 |
| 3415 | llamas | 8 |
| 3416 | literatura | 8 |
| 3417 | licenciado | 8 |
| 3418 | levantado | 8 |
| 3419 | lecturas | 8 |
| 3420 | lazo | 8 |
| 3421 | juramento | 8 |
| 3422 | jugadores | 8 |
| 3423 | jugaban | 8 |
| 3424 | jinete | 8 |
| 3425 | irse | 8 |
| 3426 | inverosímil | 8 |
| 3427 | interrumpía | 8 |
| 3428 | ingrato | 8 |
| 3429 | infinita | 8 |
| 3430 | industria | 8 |
| 3431 | indigna | 8 |
| 3432 | incapaces | 8 |
| 3433 | impertinente | 8 |
| 3434 | imaginar | 8 |
| 3435 | hundida | 8 |
| 3436 | humildes | 8 |
| 3437 | humanas | 8 |
| 3438 | hojarasca | 8 |
| 3439 | hilos | 8 |
| 3440 | halagaba | 8 |
| 3441 | habitaciones | 8 |
| 3442 | hábil | 8 |
| 3443 | gustan | 8 |
| 3444 | guardia | 8 |
| 3445 | guantes | 8 |
| 3446 | groseras | 8 |
| 3447 | grano | 8 |
| 3448 | gotas | 8 |
| 3449 | godino | 8 |
| 3450 | gobernadora | 8 |
| 3451 | gentes | 8 |
| 3452 | galantería | 8 |
| 3453 | galán | 8 |
| 3454 | furiosa | 8 |
| 3455 | funciones | 8 |
| 3456 | fruto | 8 |
| 3457 | fraile | 8 |
| 3458 | forastero | 8 |
| 3459 | flotante | 8 |
| 3460 | flaquezas | 8 |
| 3461 | fingida | 8 |
| 3462 | figuraban | 8 |
| 3463 | favores | 8 |
| 3464 | fantasmas | 8 |
| 3465 | fantasma | 8 |
| 3466 | exterior | 8 |
| 3467 | exigir | 8 |
| 3468 | exigían | 8 |
| 3469 | exigencias | 8 |
| 3470 | exclamaba | 8 |
| 3471 | estupidez | 8 |
| 3472 | estúpida | 8 |
| 3473 | estudios | 8 |
| 3474 | estudiar | 8 |
| 3475 | estudiaba | 8 |
| 3476 | espiaba | 8 |
| 3477 | espere | 8 |
| 3478 | esmero | 8 |
| 3479 | escocesa | 8 |
| 3480 | escapar | 8 |
| 3481 | escapaba | 8 |
| 3482 | escándalos | 8 |
| 3483 | esbelta | 8 |
| 3484 | entregada | 8 |
| 3485 | entiendes | 8 |
| 3486 | enseñanza | 8 |
| 3487 | engaña | 8 |
| 3488 | encuentra | 8 |
| 3489 | encontraron | 8 |
| 3490 | encendido | 8 |
| 3491 | enaguas | 8 |
| 3492 | emplear | 8 |
| 3493 | empleados | 8 |
| 3494 | economía | 8 |
| 3495 | dulcísima | 8 |
| 3496 | duerme | 8 |
| 3497 | dudas | 8 |
| 3498 | dolorosa | 8 |
| 3499 | divinidad | 8 |
| 3500 | distracciones | 8 |
| 3501 | disponía | 8 |
| 3502 | disparate | 8 |
| 3503 | disimulados | 8 |
| 3504 | disimulado | 8 |
| 3505 | disimulaba | 8 |
| 3506 | dirección | 8 |
| 3507 | diligencia | 8 |
| 3508 | dijeron | 8 |
| 3509 | dignas | 8 |
| 3510 | diferente | 8 |
| 3511 | dieron | 8 |
| 3512 | despreciado | 8 |
| 3513 | despierto | 8 |
| 3514 | despertado | 8 |
| 3515 | desgraciada | 8 |
| 3516 | desconfianza | 8 |
| 3517 | desafiar | 8 |
| 3518 | delgado | 8 |
| 3519 | déjame | 8 |
| 3520 | defensa | 8 |
| 3521 | declaraba | 8 |
| 3522 | decentes | 8 |
| 3523 | curvas | 8 |
| 3524 | cuidar | 8 |
| 3525 | cuántos | 8 |
| 3526 | cualidades | 8 |
| 3527 | cuál | 8 |
| 3528 | crianza | 8 |
| 3529 | criado | 8 |
| 3530 | cosquillas | 8 |
| 3531 | cortés | 8 |
| 3532 | correo | 8 |
| 3533 | copas | 8 |
| 3534 | convicción | 8 |
| 3535 | convertir | 8 |
| 3536 | contuvo | 8 |
| 3537 | contracayes | 8 |
| 3538 | continente | 8 |
| 3539 | contentó | 8 |
| 3540 | contado | 8 |
| 3541 | conocimiento | 8 |
| 3542 | conjunto | 8 |
| 3543 | confuso | 8 |
| 3544 | concluía | 8 |
| 3545 | comprende | 8 |
| 3546 | cómplice | 8 |
| 3547 | compañeros | 8 |
| 3548 | comió | 8 |
| 3549 | cómicos | 8 |
| 3550 | comerciante | 8 |
| 3551 | colmo | 8 |
| 3552 | colchón | 8 |
| 3553 | claustro | 8 |
| 3554 | ciento | 8 |
| 3555 | chiquillos | 8 |
| 3556 | charcos | 8 |
| 3557 | champaña | 8 |
| 3558 | ceja | 8 |
| 3559 | catástrofe | 8 |
| 3560 | castilla | 8 |
| 3561 | casado | 8 |
| 3562 | carnaval | 8 |
| 3563 | cárcel | 8 |
| 3564 | carbón | 8 |
| 3565 | canto | 8 |
| 3566 | campaña | 8 |
| 3567 | campanadas | 8 |
| 3568 | cambiar | 8 |
| 3569 | calzado | 8 |
| 3570 | callaban | 8 |
| 3571 | calla | 8 |
| 3572 | cadena | 8 |
| 3573 | cabellos | 8 |
| 3574 | cabaña | 8 |
| 3575 | buscaban | 8 |
| 3576 | bulto | 8 |
| 3577 | bruto | 8 |
| 3578 | brigadiera | 8 |
| 3579 | breve | 8 |
| 3580 | brasas | 8 |
| 3581 | botón | 8 |
| 3582 | billar | 8 |
| 3583 | bigote | 8 |
| 3584 | besó | 8 |
| 3585 | barro | 8 |
| 3586 | barquilla | 8 |
| 3587 | baño | 8 |
| 3588 | bajando | 8 |
| 3589 | azúcar | 8 |
| 3590 | atribuía | 8 |
| 3591 | atrevimiento | 8 |
| 3592 | atravesó | 8 |
| 3593 | atenerse | 8 |
| 3594 | asustó | 8 |
| 3595 | aspiraba | 8 |
| 3596 | asegurar | 8 |
| 3597 | arrojar | 8 |
| 3598 | arrancar | 8 |
| 3599 | aridez | 8 |
| 3600 | aprovechar | 8 |
| 3601 | apreciar | 8 |
| 3602 | antojó | 8 |
| 3603 | animales | 8 |
| 3604 | anhelos | 8 |
| 3605 | anduvo | 8 |
| 3606 | andadas | 8 |
| 3607 | amos | 8 |
| 3608 | américa | 8 |
| 3609 | alumbraba | 8 |
| 3610 | aludía | 8 |
| 3611 | alejaba | 8 |
| 3612 | alegraba | 8 |
| 3613 | agosto | 8 |
| 3614 | adornaban | 8 |
| 3615 | admirar | 8 |
| 3616 | adivinaba | 8 |
| 3617 | actual | 8 |
| 3618 | acostó | 8 |
| 3619 | acabar | 8 |
| 3620 | acabado | 8 |
| 3621 | abrir | 8 |
| 3622 | abrían | 8 |
| 3623 | abandonada | 8 |
| 3624 | zaragoza | 7 |
| 3625 | yeso | 7 |
| 3626 | yacían | 7 |
| 3627 | yacía | 7 |
| 3628 | voltaire | 7 |
| 3629 | viven | 7 |
| 3630 | violencia | 7 |
| 3631 | víctimas | 7 |
| 3632 | vicios | 7 |
| 3633 | vía | 7 |
| 3634 | vi | 7 |
| 3635 | vergonzoso | 7 |
| 3636 | veremos | 7 |
| 3637 | verás | 7 |
| 3638 | venidas | 7 |
| 3639 | vengarse | 7 |
| 3640 | vendría | 7 |
| 3641 | venas | 7 |
| 3642 | velo | 7 |
| 3643 | velaba | 7 |
| 3644 | valle | 7 |
| 3645 | vacío | 7 |
| 3646 | usurero | 7 |
| 3647 | urgente | 7 |
| 3648 | unción | 7 |
| 3649 | umbral | 7 |
| 3650 | tuve | 7 |
| 3651 | tranquilamente | 7 |
| 3652 | trampas | 7 |
| 3653 | trampa | 7 |
| 3654 | trabajos | 7 |
| 3655 | torpeza | 7 |
| 3656 | tormenta | 7 |
| 3657 | torcida | 7 |
| 3658 | tonos | 7 |
| 3659 | tome | 7 |
| 3660 | toldo | 7 |
| 3661 | tocó | 7 |
| 3662 | tocando | 7 |
| 3663 | tibia | 7 |
| 3664 | tertulios | 7 |
| 3665 | teólogo | 7 |
| 3666 | temporada | 7 |
| 3667 | té | 7 |
| 3668 | tapaba | 7 |
| 3669 | sustos | 7 |
| 3670 | suspiros | 7 |
| 3671 | suceder | 7 |
| 3672 | sublevaba | 7 |
| 3673 | sotanas | 7 |
| 3674 | sostener | 7 |
| 3675 | soplo | 7 |
| 3676 | somnolencia | 7 |
| 3677 | soltó | 7 |
| 3678 | socio | 7 |
| 3679 | síntomas | 7 |
| 3680 | silenciosa | 7 |
| 3681 | significaba | 7 |
| 3682 | sigilo | 7 |
| 3683 | severidad | 7 |
| 3684 | severa | 7 |
| 3685 | septiembre | 7 |
| 3686 | separarse | 7 |
| 3687 | separaba | 7 |
| 3688 | señalado | 7 |
| 3689 | semillas | 7 |
| 3690 | secreta | 7 |
| 3691 | sastre | 7 |
| 3692 | saciar | 7 |
| 3693 | sacado | 7 |
| 3694 | sabré | 7 |
| 3695 | sabor | 7 |
| 3696 | ruedas | 7 |
| 3697 | rosita | 7 |
| 3698 | rizos | 7 |
| 3699 | rita | 7 |
| 3700 | ricas | 7 |
| 3701 | revelación | 7 |
| 3702 | retumbaban | 7 |
| 3703 | retiró | 7 |
| 3704 | resultado | 7 |
| 3705 | resuelta | 7 |
| 3706 | restos | 7 |
| 3707 | respetables | 7 |
| 3708 | resolvió | 7 |
| 3709 | resolver | 7 |
| 3710 | resignación | 7 |
| 3711 | replicó | 7 |
| 3712 | repentina | 7 |
| 3713 | repasaba | 7 |
| 3714 | repartía | 7 |
| 3715 | reluciente | 7 |
| 3716 | religiosas | 7 |
| 3717 | región | 7 |
| 3718 | regencia | 7 |
| 3719 | reflexionar | 7 |
| 3720 | recordaban | 7 |
| 3721 | reales | 7 |
| 3722 | rápidas | 7 |
| 3723 | quejas | 7 |
| 3724 | queja | 7 |
| 3725 | puntas | 7 |
| 3726 | pulcro | 7 |
| 3727 | puerto | 7 |
| 3728 | providencia | 7 |
| 3729 | protestas | 7 |
| 3730 | protestaba | 7 |
| 3731 | prohibía | 7 |
| 3732 | progreso | 7 |
| 3733 | procurado | 7 |
| 3734 | proceder | 7 |
| 3735 | principios | 7 |
| 3736 | preparada | 7 |
| 3737 | prelado | 7 |
| 3738 | prefirió | 7 |
| 3739 | precioso | 7 |
| 3740 | posturas | 7 |
| 3741 | postura | 7 |
| 3742 | positivas | 7 |
| 3743 | ponían | 7 |
| 3744 | pollo | 7 |
| 3745 | poetas | 7 |
| 3746 | podrían | 7 |
| 3747 | podredumbre | 7 |
| 3748 | poderosos | 7 |
| 3749 | poderoso | 7 |
| 3750 | plebeyos | 7 |
| 3751 | pisando | 7 |
| 3752 | pintura | 7 |
| 3753 | pesado | 7 |
| 3754 | pesadas | 7 |
| 3755 | persecución | 7 |
| 3756 | perfumado | 7 |
| 3757 | perdonar | 7 |
| 3758 | pequeño | 7 |
| 3759 | pensaría | 7 |
| 3760 | penitentes | 7 |
| 3761 | pellizco | 7 |
| 3762 | peligrosos | 7 |
| 3763 | pedido | 7 |
| 3764 | pedían | 7 |
| 3765 | paulinas | 7 |
| 3766 | paternal | 7 |
| 3767 | patadas | 7 |
| 3768 | parejas | 7 |
| 3769 | pardo | 7 |
| 3770 | pardas | 7 |
| 3771 | parda | 7 |
| 3772 | paraguay | 7 |
| 3773 | paño | 7 |
| 3774 | pantalón | 7 |
| 3775 | pánico | 7 |
| 3776 | palomas | 7 |
| 3777 | palmadas | 7 |
| 3778 | palcos | 7 |
| 3779 | paja | 7 |
| 3780 | paisaje | 7 |
| 3781 | padecer | 7 |
| 3782 | pacífico | 7 |
| 3783 | oyera | 7 |
| 3784 | oposición | 7 |
| 3785 | ondas | 7 |
| 3786 | ofrecer | 7 |
| 3787 | ofrece | 7 |
| 3788 | ocultando | 7 |
| 3789 | oculta | 7 |
| 3790 | octubre | 7 |
| 3791 | obligación | 7 |
| 3792 | notas | 7 |
| 3793 | nerviosas | 7 |
| 3794 | negocios | 7 |
| 3795 | negarse | 7 |
| 3796 | necio | 7 |
| 3797 | necia | 7 |
| 3798 | náufrago | 7 |
| 3799 | nata | 7 |
| 3800 | na | 7 |
| 3801 | murmuraciones | 7 |
| 3802 | mudo | 7 |
| 3803 | muchachos | 7 |
| 3804 | moscas | 7 |
| 3805 | monótono | 7 |
| 3806 | molestar | 7 |
| 3807 | modestia | 7 |
| 3808 | moderna | 7 |
| 3809 | misterios | 7 |
| 3810 | mezclaba | 7 |
| 3811 | merced | 7 |
| 3812 | memorias | 7 |
| 3813 | mecedora | 7 |
| 3814 | mecánica | 7 |
| 3815 | mayoría | 7 |
| 3816 | matarle | 7 |
| 3817 | mareaba | 7 |
| 3818 | marchar | 7 |
| 3819 | maravillas | 7 |
| 3820 | manteos | 7 |
| 3821 | manchas | 7 |
| 3822 | maliciosos | 7 |
| 3823 | maledicencia | 7 |
| 3824 | maestra | 7 |
| 3825 | luto | 7 |
| 3826 | llenó | 7 |
| 3827 | limpias | 7 |
| 3828 | limosnas | 7 |
| 3829 | legua | 7 |
| 3830 | leche | 7 |
| 3831 | lasciva | 7 |
| 3832 | juro | 7 |
| 3833 | junio | 7 |
| 3834 | irritatio | 7 |
| 3835 | irritado | 7 |
| 3836 | intrigas | 7 |
| 3837 | íntimas | 7 |
| 3838 | intentar | 7 |
| 3839 | intensa | 7 |
| 3840 | intelectual | 7 |
| 3841 | insustancial | 7 |
| 3842 | insultos | 7 |
| 3843 | inspiraba | 7 |
| 3844 | insolente | 7 |
| 3845 | inmortal | 7 |
| 3846 | ingenio | 7 |
| 3847 | infalible | 7 |
| 3848 | inclusive | 7 |
| 3849 | inclinación | 7 |
| 3850 | impíos | 7 |
| 3851 | impío | 7 |
| 3852 | imperio | 7 |
| 3853 | imitación | 7 |
| 3854 | imitaban | 7 |
| 3855 | imitaba | 7 |
| 3856 | idolatría | 7 |
| 3857 | ideales | 7 |
| 3858 | idas | 7 |
| 3859 | humillaba | 7 |
| 3860 | hubiesen | 7 |
| 3861 | honradez | 7 |
| 3862 | hilo | 7 |
| 3863 | hermosas | 7 |
| 3864 | hermanos | 7 |
| 3865 | herido | 7 |
| 3866 | herencia | 7 |
| 3867 | haces | 7 |
| 3868 | hablan | 7 |
| 3869 | haberle | 7 |
| 3870 | gritando | 7 |
| 3871 | gozado | 7 |
| 3872 | gloriosa | 7 |
| 3873 | globo | 7 |
| 3874 | gatos | 7 |
| 3875 | ganaba | 7 |
| 3876 | galerías | 7 |
| 3877 | futura | 7 |
| 3878 | fúnebre | 7 |
| 3879 | frecuente | 7 |
| 3880 | frecuencia | 7 |
| 3881 | formal | 7 |
| 3882 | formado | 7 |
| 3883 | fingían | 7 |
| 3884 | figurado | 7 |
| 3885 | fanático | 7 |
| 3886 | facciones | 7 |
| 3887 | éxtasis | 7 |
| 3888 | explicarse | 7 |
| 3889 | exageraciones | 7 |
| 3890 | evidencia | 7 |
| 3891 | evangelio | 7 |
| 3892 | estragos | 7 |
| 3893 | estirar | 7 |
| 3894 | estarían | 7 |
| 3895 | est | 7 |
| 3896 | espuma | 7 |
| 3897 | esbelto | 7 |
| 3898 | errores | 7 |
| 3899 | equivocado | 7 |
| 3900 | equilibrio | 7 |
| 3901 | entregarse | 7 |
| 3902 | entrega | 7 |
| 3903 | encerrado | 7 |
| 3904 | encendidas | 7 |
| 3905 | elogios | 7 |
| 3906 | edificio | 7 |
| 3907 | duros | 7 |
| 3908 | duró | 7 |
| 3909 | dramas | 7 |
| 3910 | dormida | 7 |
| 3911 | dolía | 7 |
| 3912 | doble | 7 |
| 3913 | divino | 7 |
| 3914 | distraídos | 7 |
| 3915 | distinguía | 7 |
| 3916 | distinción | 7 |
| 3917 | discutir | 7 |
| 3918 | discutió | 7 |
| 3919 | discusión | 7 |
| 3920 | disculpa | 7 |
| 3921 | dirigía | 7 |
| 3922 | diestro | 7 |
| 3923 | dices | 7 |
| 3924 | deudas | 7 |
| 3925 | deuda | 7 |
| 3926 | detenerse | 7 |
| 3927 | despedida | 7 |
| 3928 | despacio | 7 |
| 3929 | desorden | 7 |
| 3930 | deseado | 7 |
| 3931 | descubrir | 7 |
| 3932 | descubrimiento | 7 |
| 3933 | describía | 7 |
| 3934 | desapareció | 7 |
| 3935 | desafiando | 7 |
| 3936 | delicioso | 7 |
| 3937 | delicadeza | 7 |
| 3938 | delicada | 7 |
| 3939 | dejarla | 7 |
| 3940 | defender | 7 |
| 3941 | decente | 7 |
| 3942 | datos | 7 |
| 3943 | cuidaba | 7 |
| 3944 | cuento | 7 |
| 3945 | cuaresma | 7 |
| 3946 | cuadrado | 7 |
| 3947 | crueldad | 7 |
| 3948 | crítico | 7 |
| 3949 | cristianos | 7 |
| 3950 | crees | 7 |
| 3951 | creerá | 7 |
| 3952 | cortesía | 7 |
| 3953 | corta | 7 |
| 3954 | cordel | 7 |
| 3955 | corbata | 7 |
| 3956 | corazonada | 7 |
| 3957 | conviene | 7 |
| 3958 | contestaban | 7 |
| 3959 | contenía | 7 |
| 3960 | contando | 7 |
| 3961 | contaban | 7 |
| 3962 | conservador | 7 |
| 3963 | consentido | 7 |
| 3964 | consejo | 7 |
| 3965 | consagrada | 7 |
| 3966 | conforme | 7 |
| 3967 | confiesa | 7 |
| 3968 | confesarse | 7 |
| 3969 | confesarlo | 7 |
| 3970 | confesado | 7 |
| 3971 | comprado | 7 |
| 3972 | complacía | 7 |
| 3973 | comparar | 7 |
| 3974 | comenzaron | 7 |
| 3975 | comenzar | 7 |
| 3976 | comenzado | 7 |
| 3977 | comen | 7 |
| 3978 | colgado | 7 |
| 3979 | colcha | 7 |
| 3980 | cola | 7 |
| 3981 | cofradías | 7 |
| 3982 | clavaba | 7 |
| 3983 | cirios | 7 |
| 3984 | chocolate | 7 |
| 3985 | chiquillo | 7 |
| 3986 | cesaron | 7 |
| 3987 | cereza | 7 |
| 3988 | cazar | 7 |
| 3989 | castigar | 7 |
| 3990 | castaños | 7 |
| 3991 | cascabeles | 7 |
| 3992 | casadas | 7 |
| 3993 | carro | 7 |
| 3994 | carnal | 7 |
| 3995 | cariñoso | 7 |
| 3996 | cargadas | 7 |
| 3997 | cansancio | 7 |
| 3998 | cánones | 7 |
| 3999 | canas | 7 |
| 4000 | campanario | 7 |
| 4001 | campana | 7 |
| 4002 | cambiado | 7 |
| 4003 | calumniado | 7 |
| 4004 | callaron | 7 |
| 4005 | callada | 7 |
| 4006 | caldo | 7 |
| 4007 | cal | 7 |
| 4008 | cajones | 7 |
| 4009 | caería | 7 |
| 4010 | cabecera | 7 |
| 4011 | butaca | 7 |
| 4012 | buscado | 7 |
| 4013 | bultos | 7 |
| 4014 | bulliciosa | 7 |
| 4015 | brutal | 7 |
| 4016 | brillante | 7 |
| 4017 | brecha | 7 |
| 4018 | borbotones | 7 |
| 4019 | bofetada | 7 |
| 4020 | blas | 7 |
| 4021 | blandura | 7 |
| 4022 | bebía | 7 |
| 4023 | batallas | 7 |
| 4024 | bala | 7 |
| 4025 | ayudar | 7 |
| 4026 | avergonzado | 7 |
| 4027 | avergonzada | 7 |
| 4028 | avaricia | 7 |
| 4029 | ausente | 7 |
| 4030 | atraía | 7 |
| 4031 | atractivo | 7 |
| 4032 | artillero | 7 |
| 4033 | artículos | 7 |
| 4034 | arruinado | 7 |
| 4035 | arrojarse | 7 |
| 4036 | arroja | 7 |
| 4037 | arrastrando | 7 |
| 4038 | arranques | 7 |
| 4039 | armarios | 7 |
| 4040 | aristócratas | 7 |
| 4041 | aras | 7 |
| 4042 | apretado | 7 |
| 4043 | apresuró | 7 |
| 4044 | aplicaba | 7 |
| 4045 | apariencia | 7 |
| 4046 | aparición | 7 |
| 4047 | aparecían | 7 |
| 4048 | ansiedad | 7 |
| 4049 | animó | 7 |
| 4050 | ángeles | 7 |
| 4051 | andando | 7 |
| 4052 | americanos | 7 |
| 4053 | amenazó | 7 |
| 4054 | alvarito | 7 |
| 4055 | alborotar | 7 |
| 4056 | alarde | 7 |
| 4057 | álamos | 7 |
| 4058 | ajena | 7 |
| 4059 | airoso | 7 |
| 4060 | agujeros | 7 |
| 4061 | aguda | 7 |
| 4062 | aguas | 7 |
| 4063 | agradar | 7 |
| 4064 | agradaba | 7 |
| 4065 | aficionados | 7 |
| 4066 | admite | 7 |
| 4067 | acordado | 7 |
| 4068 | acontecimientos | 7 |
| 4069 | acompañaban | 7 |
| 4070 | acercaban | 7 |
| 4071 | acciones | 7 |
| 4072 | absurdos | 7 |
| 4073 | abril | 7 |
| 4074 | abrazo | 7 |
| 4075 | abismos | 7 |
| 4076 | abdicación | 7 |
| 4077 | abanico | 7 |
| 4078 | zorros | 6 |
| 4079 | yerbas | 6 |
| 4080 | volviese | 6 |
| 4081 | volaban | 6 |
| 4082 | vistas | 6 |
| 4083 | visitaban | 6 |
| 4084 | virtudes | 6 |
| 4085 | vírgenes | 6 |
| 4086 | vinculete | 6 |
| 4087 | vil | 6 |
| 4088 | vientos | 6 |
| 4089 | viejas | 6 |
| 4090 | vidrieras | 6 |
| 4091 | viajes | 6 |
| 4092 | verlo | 6 |
| 4093 | vendrá | 6 |
| 4094 | vende | 6 |
| 4095 | venció | 6 |
| 4096 | vehemente | 6 |
| 4097 | vecindario | 6 |
| 4098 | vecinas | 6 |
| 4099 | varonil | 6 |
| 4100 | variedad | 6 |
| 4101 | vara | 6 |
| 4102 | vapores | 6 |
| 4103 | valladolid | 6 |
| 4104 | vagos | 6 |
| 4105 | vacía | 6 |
| 4106 | usía | 6 |
| 4107 | urraca | 6 |
| 4108 | ubi | 6 |
| 4109 | turno | 6 |
| 4110 | truenos | 6 |
| 4111 | tropezó | 6 |
| 4112 | tropezando | 6 |
| 4113 | tresillistas | 6 |
| 4114 | tratara | 6 |
| 4115 | trataban | 6 |
| 4116 | traslacerca | 6 |
| 4117 | tranquilos | 6 |
| 4118 | trajes | 6 |
| 4119 | traían | 6 |
| 4120 | torpes | 6 |
| 4121 | tormentos | 6 |
| 4122 | tordos | 6 |
| 4123 | torbellino | 6 |
| 4124 | tonterías | 6 |
| 4125 | tomando | 6 |
| 4126 | tolerar | 6 |
| 4127 | tirar | 6 |
| 4128 | tinte | 6 |
| 4129 | tinta | 6 |
| 4130 | tientas | 6 |
| 4131 | tesis | 6 |
| 4132 | terribles | 6 |
| 4133 | terminó | 6 |
| 4134 | tercer | 6 |
| 4135 | tentador | 6 |
| 4136 | tenerle | 6 |
| 4137 | tendido | 6 |
| 4138 | tendía | 6 |
| 4139 | temiendo | 6 |
| 4140 | telón | 6 |
| 4141 | tejado | 6 |
| 4142 | tardar | 6 |
| 4143 | talle | 6 |
| 4144 | talar | 6 |
| 4145 | tacto | 6 |
| 4146 | suplicaba | 6 |
| 4147 | suceso | 6 |
| 4148 | sucedía | 6 |
| 4149 | subterráneos | 6 |
| 4150 | subiendo | 6 |
| 4151 | sopor | 6 |
| 4152 | soñar | 6 |
| 4153 | soñador | 6 |
| 4154 | solteronas | 6 |
| 4155 | solícita | 6 |
| 4156 | sofocaba | 6 |
| 4157 | sinceramente | 6 |
| 4158 | simpatía | 6 |
| 4159 | silencioso | 6 |
| 4160 | silbidos | 6 |
| 4161 | silbaba | 6 |
| 4162 | sesión | 6 |
| 4163 | sesenta | 6 |
| 4164 | servirle | 6 |
| 4165 | seriamente | 6 |
| 4166 | separar | 6 |
| 4167 | separando | 6 |
| 4168 | señorío | 6 |
| 4169 | señaló | 6 |
| 4170 | señalaba | 6 |
| 4171 | sentían | 6 |
| 4172 | segundos | 6 |
| 4173 | seguirle | 6 |
| 4174 | seglar | 6 |
| 4175 | seductores | 6 |
| 4176 | satisfechos | 6 |
| 4177 | sapo | 6 |
| 4178 | salve | 6 |
| 4179 | saludando | 6 |
| 4180 | saltó | 6 |
| 4181 | saliese | 6 |
| 4182 | saliera | 6 |
| 4183 | salga | 6 |
| 4184 | salas | 6 |
| 4185 | sal | 6 |
| 4186 | sacudiendo | 6 |
| 4187 | sacramento | 6 |
| 4188 | sábana | 6 |
| 4189 | ruegos | 6 |
| 4190 | rubor | 6 |
| 4191 | rosario | 6 |
| 4192 | ronda | 6 |
| 4193 | rompo | 6 |
| 4194 | rodeaba | 6 |
| 4195 | rocío | 6 |
| 4196 | roca | 6 |
| 4197 | rizada | 6 |
| 4198 | rítmico | 6 |
| 4199 | risueña | 6 |
| 4200 | restituto | 6 |
| 4201 | restaurant | 6 |
| 4202 | respirando | 6 |
| 4203 | respiración | 6 |
| 4204 | respectivos | 6 |
| 4205 | resistía | 6 |
| 4206 | reserva | 6 |
| 4207 | repugnantes | 6 |
| 4208 | representar | 6 |
| 4209 | rentas | 6 |
| 4210 | rendida | 6 |
| 4211 | rencores | 6 |
| 4212 | relámpagos | 6 |
| 4213 | rejas | 6 |
| 4214 | reino | 6 |
| 4215 | régimen | 6 |
| 4216 | regalado | 6 |
| 4217 | reflejaban | 6 |
| 4218 | recuerda | 6 |
| 4219 | recobraba | 6 |
| 4220 | recitaba | 6 |
| 4221 | recibieron | 6 |
| 4222 | ras | 6 |
| 4223 | raro | 6 |
| 4224 | rapidez | 6 |
| 4225 | ramos | 6 |
| 4226 | ramona | 6 |
| 4227 | quisieron | 6 |
| 4228 | quisieran | 6 |
| 4229 | queridas | 6 |
| 4230 | quejarse | 6 |
| 4231 | pusieron | 6 |
| 4232 | puros | 6 |
| 4233 | puntos | 6 |
| 4234 | pudieron | 6 |
| 4235 | pudieran | 6 |
| 4236 | pudiendo | 6 |
| 4237 | ps | 6 |
| 4238 | próximo | 6 |
| 4239 | proximidad | 6 |
| 4240 | prosaico | 6 |
| 4241 | proporciones | 6 |
| 4242 | profundamente | 6 |
| 4243 | procurando | 6 |
| 4244 | probaban | 6 |
| 4245 | príncipe | 6 |
| 4246 | pretendiente | 6 |
| 4247 | pretendían | 6 |
| 4248 | pretendía | 6 |
| 4249 | prestado | 6 |
| 4250 | preparándose | 6 |
| 4251 | preparando | 6 |
| 4252 | preparado | 6 |
| 4253 | preferir | 6 |
| 4254 | práctica | 6 |
| 4255 | positivo | 6 |
| 4256 | popular | 6 |
| 4257 | plataforma | 6 |
| 4258 | pizca | 6 |
| 4259 | pinturas | 6 |
| 4260 | pintado | 6 |
| 4261 | pino | 6 |
| 4262 | pinche | 6 |
| 4263 | pimienta | 6 |
| 4264 | pilares | 6 |
| 4265 | pilar | 6 |
| 4266 | picaresca | 6 |
| 4267 | pícara | 6 |
| 4268 | petróleo | 6 |
| 4269 | perversión | 6 |
| 4270 | perspectiva | 6 |
| 4271 | perfumada | 6 |
| 4272 | perfil | 6 |
| 4273 | perdono | 6 |
| 4274 | perdición | 6 |
| 4275 | pequeñas | 6 |
| 4276 | penitente | 6 |
| 4277 | penetraba | 6 |
| 4278 | pegajosa | 6 |
| 4279 | pegado | 6 |
| 4280 | pedazo | 6 |
| 4281 | pécora | 6 |
| 4282 | pecar | 6 |
| 4283 | pavor | 6 |
| 4284 | pataditas | 6 |
| 4285 | pasará | 6 |
| 4286 | pasara | 6 |
| 4287 | pasan | 6 |
| 4288 | pasaje | 6 |
| 4289 | pasada | 6 |
| 4290 | palo | 6 |
| 4291 | padecido | 6 |
| 4292 | pablo | 6 |
| 4293 | oyes | 6 |
| 4294 | oyeran | 6 |
| 4295 | origen | 6 |
| 4296 | orgía | 6 |
| 4297 | oportunidad | 6 |
| 4298 | opina | 6 |
| 4299 | olvidada | 6 |
| 4300 | olores | 6 |
| 4301 | ofrecían | 6 |
| 4302 | oeste | 6 |
| 4303 | ocurrencia | 6 |
| 4304 | ocupada | 6 |
| 4305 | ocultos | 6 |
| 4306 | océano | 6 |
| 4307 | observar | 6 |
| 4308 | obedecía | 6 |
| 4309 | novenas | 6 |
| 4310 | notario | 6 |
| 4311 | muros | 6 |
| 4312 | mundano | 6 |
| 4313 | muchedumbre | 6 |
| 4314 | moviendo | 6 |
| 4315 | morirse | 6 |
| 4316 | morena | 6 |
| 4317 | montañés | 6 |
| 4318 | montañas | 6 |
| 4319 | monotonía | 6 |
| 4320 | monótona | 6 |
| 4321 | monaguillo | 6 |
| 4322 | modernos | 6 |
| 4323 | misión | 6 |
| 4324 | míos | 6 |
| 4325 | mina | 6 |
| 4326 | millonario | 6 |
| 4327 | miedos | 6 |
| 4328 | mia | 6 |
| 4329 | mezcla | 6 |
| 4330 | metida | 6 |
| 4331 | metían | 6 |
| 4332 | meterse | 6 |
| 4333 | metal | 6 |
| 4334 | metáforas | 6 |
| 4335 | mesilla | 6 |
| 4336 | mesas | 6 |
| 4337 | mentía | 6 |
| 4338 | meditando | 6 |
| 4339 | mediquillo | 6 |
| 4340 | medios | 6 |
| 4341 | médica | 6 |
| 4342 | mecánico | 6 |
| 4343 | materiales | 6 |
| 4344 | mataba | 6 |
| 4345 | marinero | 6 |
| 4346 | marina | 6 |
| 4347 | marcharse | 6 |
| 4348 | mantón | 6 |
| 4349 | mantilla | 6 |
| 4350 | mantel | 6 |
| 4351 | manifestación | 6 |
| 4352 | manga | 6 |
| 4353 | malicioso | 6 |
| 4354 | maliciosa | 6 |
| 4355 | males | 6 |
| 4356 | luchas | 6 |
| 4357 | luchaba | 6 |
| 4358 | lúbrica | 6 |
| 4359 | lope | 6 |
| 4360 | lomo | 6 |
| 4361 | llueve | 6 |
| 4362 | llover | 6 |
| 4363 | llevarla | 6 |
| 4364 | llevando | 6 |
| 4365 | llegue | 6 |
| 4366 | llegase | 6 |
| 4367 | llamarle | 6 |
| 4368 | llamarla | 6 |
| 4369 | llamaría | 6 |
| 4370 | limpio | 6 |
| 4371 | límites | 6 |
| 4372 | ligas | 6 |
| 4373 | leña | 6 |
| 4374 | lenta | 6 |
| 4375 | lejana | 6 |
| 4376 | leían | 6 |
| 4377 | lector | 6 |
| 4378 | lana | 6 |
| 4379 | lámparas | 6 |
| 4380 | ladridos | 6 |
| 4381 | lados | 6 |
| 4382 | juanito | 6 |
| 4383 | juana | 6 |
| 4384 | jaula | 6 |
| 4385 | jardines | 6 |
| 4386 | isla | 6 |
| 4387 | inútiles | 6 |
| 4388 | interlocutor | 6 |
| 4389 | interiores | 6 |
| 4390 | interesaba | 6 |
| 4391 | intensidad | 6 |
| 4392 | insultar | 6 |
| 4393 | instituciones | 6 |
| 4394 | insistir | 6 |
| 4395 | insistía | 6 |
| 4396 | iniciativa | 6 |
| 4397 | infidelidad | 6 |
| 4398 | infelices | 6 |
| 4399 | inerte | 6 |
| 4400 | inercia | 6 |
| 4401 | indiferentes | 6 |
| 4402 | indianos | 6 |
| 4403 | indecoroso | 6 |
| 4404 | inclinarse | 6 |
| 4405 | impuso | 6 |
| 4406 | impresiones | 6 |
| 4407 | importuno | 6 |
| 4408 | imponía | 6 |
| 4409 | impone | 6 |
| 4410 | impiedad | 6 |
| 4411 | ilustrísima | 6 |
| 4412 | ilustres | 6 |
| 4413 | ii | 6 |
| 4414 | igualdad | 6 |
| 4415 | ídem | 6 |
| 4416 | idealidad | 6 |
| 4417 | húmedas | 6 |
| 4418 | horrorizaba | 6 |
| 4419 | horrísono | 6 |
| 4420 | horrible | 6 |
| 4421 | hito | 6 |
| 4422 | hipócritas | 6 |
| 4423 | hiciesen | 6 |
| 4424 | héroes | 6 |
| 4425 | héroe | 6 |
| 4426 | hereje | 6 |
| 4427 | heredado | 6 |
| 4428 | haz | 6 |
| 4429 | haré | 6 |
| 4430 | hallazgo | 6 |
| 4431 | halagado | 6 |
| 4432 | h | 6 |
| 4433 | guardaban | 6 |
| 4434 | guapo | 6 |
| 4435 | guapas | 6 |
| 4436 | gritaban | 6 |
| 4437 | grises | 6 |
| 4438 | golosina | 6 |
| 4439 | genio | 6 |
| 4440 | ganancia | 6 |
| 4441 | gallinas | 6 |
| 4442 | gallardo | 6 |
| 4443 | gabán | 6 |
| 4444 | futuro | 6 |
| 4445 | función | 6 |
| 4446 | fray | 6 |
| 4447 | franco | 6 |
| 4448 | francamente | 6 |
| 4449 | follaje | 6 |
| 4450 | flacas | 6 |
| 4451 | filósofos | 6 |
| 4452 | fila | 6 |
| 4453 | fijaba | 6 |
| 4454 | fiaba | 6 |
| 4455 | fantástico | 6 |
| 4456 | fango | 6 |
| 4457 | familiares | 6 |
| 4458 | faltó | 6 |
| 4459 | faltar | 6 |
| 4460 | extravíos | 6 |
| 4461 | expuso | 6 |
| 4462 | exponerse | 6 |
| 4463 | expansión | 6 |
| 4464 | excursión | 6 |
| 4465 | excitada | 6 |
| 4466 | eternamente | 6 |
| 4467 | estuvieran | 6 |
| 4468 | estremeció | 6 |
| 4469 | estorbaba | 6 |
| 4470 | estalló | 6 |
| 4471 | estados | 6 |
| 4472 | espiar | 6 |
| 4473 | espectáculos | 6 |
| 4474 | español | 6 |
| 4475 | esencia | 6 |
| 4476 | escuchar | 6 |
| 4477 | escondida | 6 |
| 4478 | escoger | 6 |
| 4479 | escoba | 6 |
| 4480 | esclava | 6 |
| 4481 | escéptico | 6 |
| 4482 | escalofrío | 6 |
| 4483 | escala | 6 |
| 4484 | error | 6 |
| 4485 | envuelto | 6 |
| 4486 | envolvía | 6 |
| 4487 | enterarse | 6 |
| 4488 | enorme | 6 |
| 4489 | engordar | 6 |
| 4490 | engañó | 6 |
| 4491 | encontrarse | 6 |
| 4492 | encarnado | 6 |
| 4493 | enamorarse | 6 |
| 4494 | enamorar | 6 |
| 4495 | enamora | 6 |
| 4496 | empresas | 6 |
| 4497 | emprendía | 6 |
| 4498 | empeñado | 6 |
| 4499 | elecciones | 6 |
| 4500 | eficacia | 6 |
| 4501 | educado | 6 |
| 4502 | duraba | 6 |
| 4503 | duele | 6 |
| 4504 | dote | 6 |
| 4505 | doncellas | 6 |
| 4506 | dominios | 6 |
| 4507 | doctrina | 6 |
| 4508 | divertía | 6 |
| 4509 | distinguidas | 6 |
| 4510 | disputando | 6 |
| 4511 | disputaba | 6 |
| 4512 | disparar | 6 |
| 4513 | disimulando | 6 |
| 4514 | disgustos | 6 |
| 4515 | disgustaba | 6 |
| 4516 | director | 6 |
| 4517 | diplomacia | 6 |
| 4518 | digámoslo | 6 |
| 4519 | difunto | 6 |
| 4520 | diferentes | 6 |
| 4521 | diferencia | 6 |
| 4522 | devotas | 6 |
| 4523 | despotismo | 6 |
| 4524 | despensa | 6 |
| 4525 | desiertos | 6 |
| 4526 | descalzos | 6 |
| 4527 | desaparecer | 6 |
| 4528 | derrotado | 6 |
| 4529 | delicadas | 6 |
| 4530 | dejasen | 6 |
| 4531 | dejándose | 6 |
| 4532 | defectos | 6 |
| 4533 | defecto | 6 |
| 4534 | decoro | 6 |
| 4535 | decidor | 6 |
| 4536 | débiles | 6 |
| 4537 | debido | 6 |
| 4538 | cutis | 6 |
| 4539 | cuna | 6 |
| 4540 | culta | 6 |
| 4541 | cuartel | 6 |
| 4542 | cruzadas | 6 |
| 4543 | cruzaban | 6 |
| 4544 | crujir | 6 |
| 4545 | crucificado | 6 |
| 4546 | crepúsculo | 6 |
| 4547 | creencias | 6 |
| 4548 | coser | 6 |
| 4549 | corrieron | 6 |
| 4550 | corrección | 6 |
| 4551 | corral | 6 |
| 4552 | cordial | 6 |
| 4553 | conyugal | 6 |
| 4554 | convidaba | 6 |
| 4555 | convicciones | 6 |
| 4556 | convertirse | 6 |
| 4557 | conveniencia | 6 |
| 4558 | convaleciente | 6 |
| 4559 | contó | 6 |
| 4560 | contestado | 6 |
| 4561 | contentos | 6 |
| 4562 | contenida | 6 |
| 4563 | considerar | 6 |
| 4564 | conservaba | 6 |
| 4565 | conserva | 6 |
| 4566 | conocimientos | 6 |
| 4567 | confidente | 6 |
| 4568 | confesó | 6 |
| 4569 | confesaban | 6 |
| 4570 | conducía | 6 |
| 4571 | concluyó | 6 |
| 4572 | comunes | 6 |
| 4573 | comprendían | 6 |
| 4574 | complicada | 6 |
| 4575 | completa | 6 |
| 4576 | compás | 6 |
| 4577 | comparaba | 6 |
| 4578 | compadecía | 6 |
| 4579 | cometido | 6 |
| 4580 | combinaciones | 6 |
| 4581 | colondres | 6 |
| 4582 | colgaduras | 6 |
| 4583 | colecciones | 6 |
| 4584 | cogote | 6 |
| 4585 | cognac | 6 |
| 4586 | clerical | 6 |
| 4587 | clavo | 6 |
| 4588 | claras | 6 |
| 4589 | citaba | 6 |
| 4590 | chusco | 6 |
| 4591 | chocar | 6 |
| 4592 | chiste | 6 |
| 4593 | charco | 6 |
| 4594 | ceremonias | 6 |
| 4595 | ceñido | 6 |
| 4596 | celestial | 6 |
| 4597 | celebrar | 6 |
| 4598 | celda | 6 |
| 4599 | cejas | 6 |
| 4600 | ceguera | 6 |
| 4601 | cavilaciones | 6 |
| 4602 | cautela | 6 |
| 4603 | catorce | 6 |
| 4604 | catequistas | 6 |
| 4605 | cátedra | 6 |
| 4606 | casullas | 6 |
| 4607 | carnes | 6 |
| 4608 | carlistas | 6 |
| 4609 | capítulo | 6 |
| 4610 | capas | 6 |
| 4611 | cañón | 6 |
| 4612 | cansarse | 6 |
| 4613 | cansada | 6 |
| 4614 | canónico | 6 |
| 4615 | campanas | 6 |
| 4616 | caminos | 6 |
| 4617 | callado | 6 |
| 4618 | cadenas | 6 |
| 4619 | cabezas | 6 |
| 4620 | burlado | 6 |
| 4621 | bóvedas | 6 |
| 4622 | bocado | 6 |
| 4623 | blando | 6 |
| 4624 | blancura | 6 |
| 4625 | beneficio | 6 |
| 4626 | bebió | 6 |
| 4627 | bebido | 6 |
| 4628 | bautista | 6 |
| 4629 | batirse | 6 |
| 4630 | bata | 6 |
| 4631 | basílica | 6 |
| 4632 | barquero | 6 |
| 4633 | barco | 6 |
| 4634 | barandilla | 6 |
| 4635 | bando | 6 |
| 4636 | balandrán | 6 |
| 4637 | baba | 6 |
| 4638 | averiguar | 6 |
| 4639 | avena | 6 |
| 4640 | avanzados | 6 |
| 4641 | auxilio | 6 |
| 4642 | auténticos | 6 |
| 4643 | aturdimiento | 6 |
| 4644 | aturdida | 6 |
| 4645 | atrevidos | 6 |
| 4646 | atrevería | 6 |
| 4647 | ateísmo | 6 |
| 4648 | asqueroso | 6 |
| 4649 | asperezas | 6 |
| 4650 | asistía | 6 |
| 4651 | asalto | 6 |
| 4652 | artículo | 6 |
| 4653 | arrugado | 6 |
| 4654 | arrimado | 6 |
| 4655 | arrastrar | 6 |
| 4656 | arranque | 6 |
| 4657 | arrancarle | 6 |
| 4658 | arrancaba | 6 |
| 4659 | aristocrático | 6 |
| 4660 | ardían | 6 |
| 4661 | araña | 6 |
| 4662 | apuntaba | 6 |
| 4663 | aprobaba | 6 |
| 4664 | apretados | 6 |
| 4665 | apretada | 6 |
| 4666 | apetitos | 6 |
| 4667 | apearse | 6 |
| 4668 | anticuario | 6 |
| 4669 | antepecho | 6 |
| 4670 | antaño | 6 |
| 4671 | animado | 6 |
| 4672 | animaba | 6 |
| 4673 | ángulo | 6 |
| 4674 | anciano | 6 |
| 4675 | anchos | 6 |
| 4676 | amorosos | 6 |
| 4677 | amoríos | 6 |
| 4678 | amenaza | 6 |
| 4679 | ambas | 6 |
| 4680 | amargo | 6 |
| 4681 | alzacuello | 6 |
| 4682 | aludiendo | 6 |
| 4683 | alabar | 6 |
| 4684 | alabanzas | 6 |
| 4685 | águila | 6 |
| 4686 | agradeció | 6 |
| 4687 | afirmaba | 6 |
| 4688 | aficiones | 6 |
| 4689 | administración | 6 |
| 4690 | adentro | 6 |
| 4691 | adelantar | 6 |
| 4692 | acudió | 6 |
| 4693 | acudían | 6 |
| 4694 | actitud | 6 |
| 4695 | acordarse | 6 |
| 4696 | acompañado | 6 |
| 4697 | aceptar | 6 |
| 4698 | accidentes | 6 |
| 4699 | aburrido | 6 |
| 4700 | abundante | 6 |
| 4701 | absolutamente | 6 |
| 4702 | abriendo | 6 |
| 4703 | abrazó | 6 |
| 4704 | abonados | 6 |
| 4705 | abiertas | 6 |
| 4706 | zapico | 5 |
| 4707 | zapateros | 5 |
| 4708 | zaguán | 5 |
| 4709 | xv | 5 |
| 4710 | vulgaridades | 5 |
| 4711 | vuelva | 5 |
| 4712 | volando | 5 |
| 4713 | vivió | 5 |
| 4714 | viste | 5 |
| 4715 | vigilancia | 5 |
| 4716 | victorias | 5 |
| 4717 | vibraciones | 5 |
| 4718 | vestirse | 5 |
| 4719 | vestidas | 5 |
| 4720 | vestíbulo | 5 |
| 4721 | vericuetos | 5 |
| 4722 | ventaja | 5 |
| 4723 | vendido | 5 |
| 4724 | vencía | 5 |
| 4725 | veinticinco | 5 |
| 4726 | vegetar | 5 |
| 4727 | vecina | 5 |
| 4728 | valga | 5 |
| 4729 | vaguedad | 5 |
| 4730 | vagas | 5 |
| 4731 | uñas | 5 |
| 4732 | uniforme | 5 |
| 4733 | turbó | 5 |
| 4734 | turbar | 5 |
| 4735 | turbado | 5 |
| 4736 | truchas | 5 |
| 4737 | tropezones | 5 |
| 4738 | tropezaba | 5 |
| 4739 | triunfos | 5 |
| 4740 | tricot | 5 |
| 4741 | trató | 5 |
| 4742 | tratado | 5 |
| 4743 | transigir | 5 |
| 4744 | transeúntes | 5 |
| 4745 | tranquilas | 5 |
| 4746 | traidores | 5 |
| 4747 | tradición | 5 |
| 4748 | total | 5 |
| 4749 | torcía | 5 |
| 4750 | tontos | 5 |
| 4751 | tomate | 5 |
| 4752 | tocarle | 5 |
| 4753 | título | 5 |
| 4754 | tísica | 5 |
| 4755 | tiranía | 5 |
| 4756 | tijeras | 5 |
| 4757 | tierras | 5 |
| 4758 | tierno | 5 |
| 4759 | testamento | 5 |
| 4760 | tesoros | 5 |
| 4761 | tertulias | 5 |
| 4762 | tenerse | 5 |
| 4763 | tendrá | 5 |
| 4764 | temían | 5 |
| 4765 | temblaban | 5 |
| 4766 | telarañas | 5 |
| 4767 | tarima | 5 |
| 4768 | tardaba | 5 |
| 4769 | tapar | 5 |
| 4770 | taciturno | 5 |
| 4771 | tabique | 5 |
| 4772 | suponiendo | 5 |
| 4773 | superstición | 5 |
| 4774 | superficie | 5 |
| 4775 | sumo | 5 |
| 4776 | sumisión | 5 |
| 4777 | sujetó | 5 |
| 4778 | sujeta | 5 |
| 4779 | sufría | 5 |
| 4780 | suena | 5 |
| 4781 | suelto | 5 |
| 4782 | suele | 5 |
| 4783 | sudores | 5 |
| 4784 | sucede | 5 |
| 4785 | subterráneo | 5 |
| 4786 | soto | 5 |
| 4787 | soso | 5 |
| 4788 | sosa | 5 |
| 4789 | sorprendía | 5 |
| 4790 | sorprender | 5 |
| 4791 | soplaba | 5 |
| 4792 | sonó | 5 |
| 4793 | sombrío | 5 |
| 4794 | soltera | 5 |
| 4795 | sollozos | 5 |
| 4796 | solitarios | 5 |
| 4797 | solicitar | 5 |
| 4798 | solemnidades | 5 |
| 4799 | sois | 5 |
| 4800 | sofisma | 5 |
| 4801 | sobrinas | 5 |
| 4802 | sobresaltos | 5 |
| 4803 | sirvo | 5 |
| 4804 | sinceridad | 5 |
| 4805 | siguiendo | 5 |
| 4806 | sesos | 5 |
| 4807 | sesgo | 5 |
| 4808 | serviría | 5 |
| 4809 | servilleta | 5 |
| 4810 | seres | 5 |
| 4811 | señorona | 5 |
| 4812 | señoril | 5 |
| 4813 | sensaciones | 5 |
| 4814 | sendos | 5 |
| 4815 | semi | 5 |
| 4816 | sastres | 5 |
| 4817 | santuario | 5 |
| 4818 | santianes | 5 |
| 4819 | sanar | 5 |
| 4820 | saltos | 5 |
| 4821 | saltando | 5 |
| 4822 | salgo | 5 |
| 4823 | salen | 5 |
| 4824 | saldría | 5 |
| 4825 | sacrificarse | 5 |
| 4826 | sacaban | 5 |
| 4827 | sable | 5 |
| 4828 | rutina | 5 |
| 4829 | ruinas | 5 |
| 4830 | rugió | 5 |
| 4831 | rueda | 5 |
| 4832 | rúa | 5 |
| 4833 | rozagante | 5 |
| 4834 | rompió | 5 |
| 4835 | rojas | 5 |
| 4836 | rodilla | 5 |
| 4837 | robaba | 5 |
| 4838 | ritmo | 5 |
| 4839 | rió | 5 |
| 4840 | rindió | 5 |
| 4841 | rigodón | 5 |
| 4842 | ríe | 5 |
| 4843 | ría | 5 |
| 4844 | retirada | 5 |
| 4845 | restauración | 5 |
| 4846 | responsable | 5 |
| 4847 | responder | 5 |
| 4848 | respetado | 5 |
| 4849 | resortes | 5 |
| 4850 | resorte | 5 |
| 4851 | resistió | 5 |
| 4852 | reputaba | 5 |
| 4853 | repugnaba | 5 |
| 4854 | representando | 5 |
| 4855 | representan | 5 |
| 4856 | reposo | 5 |
| 4857 | repetidas | 5 |
| 4858 | renunciar | 5 |
| 4859 | remordía | 5 |
| 4860 | relucientes | 5 |
| 4861 | relato | 5 |
| 4862 | relación | 5 |
| 4863 | reja | 5 |
| 4864 | regazo | 5 |
| 4865 | regalo | 5 |
| 4866 | refugio | 5 |
| 4867 | refirió | 5 |
| 4868 | redacción | 5 |
| 4869 | rectoral | 5 |
| 4870 | rector | 5 |
| 4871 | recorriendo | 5 |
| 4872 | recorría | 5 |
| 4873 | recomendaciones | 5 |
| 4874 | recogiendo | 5 |
| 4875 | reciente | 5 |
| 4876 | ráfaga | 5 |
| 4877 | quo | 5 |
| 4878 | quita | 5 |
| 4879 | quejó | 5 |
| 4880 | quejidos | 5 |
| 4881 | quedar | 5 |
| 4882 | quedándose | 5 |
| 4883 | puras | 5 |
| 4884 | puñal | 5 |
| 4885 | punzantes | 5 |
| 4886 | pulcra | 5 |
| 4887 | puertos | 5 |
| 4888 | pueril | 5 |
| 4889 | pude | 5 |
| 4890 | próximamente | 5 |
| 4891 | provocativa | 5 |
| 4892 | provincial | 5 |
| 4893 | protectrices | 5 |
| 4894 | prostitución | 5 |
| 4895 | proporción | 5 |
| 4896 | propasaba | 5 |
| 4897 | progresos | 5 |
| 4898 | producido | 5 |
| 4899 | probado | 5 |
| 4900 | prisión | 5 |
| 4901 | presupuesto | 5 |
| 4902 | presta | 5 |
| 4903 | presidio | 5 |
| 4904 | presentimiento | 5 |
| 4905 | presentaban | 5 |
| 4906 | preparó | 5 |
| 4907 | preparaban | 5 |
| 4908 | preocupaba | 5 |
| 4909 | premio | 5 |
| 4910 | preguntaban | 5 |
| 4911 | prefiere | 5 |
| 4912 | predicaba | 5 |
| 4913 | prebendado | 5 |
| 4914 | postigo | 5 |
| 4915 | portado | 5 |
| 4916 | porción | 5 |
| 4917 | policía | 5 |
| 4918 | podré | 5 |
| 4919 | plantar | 5 |
| 4920 | pisaba | 5 |
| 4921 | pillos | 5 |
| 4922 | pilletes | 5 |
| 4923 | pez | 5 |
| 4924 | pesetas | 5 |
| 4925 | peseta | 5 |
| 4926 | perseguido | 5 |
| 4927 | permitido | 5 |
| 4928 | permite | 5 |
| 4929 | perjuicio | 5 |
| 4930 | perdonado | 5 |
| 4931 | perdona | 5 |
| 4932 | perderse | 5 |
| 4933 | perderla | 5 |
| 4934 | pequeñez | 5 |
| 4935 | penetrar | 5 |
| 4936 | pendían | 5 |
| 4937 | peligrosas | 5 |
| 4938 | peinado | 5 |
| 4939 | pegada | 5 |
| 4940 | pedirle | 5 |
| 4941 | pavo | 5 |
| 4942 | patenas | 5 |
| 4943 | patas | 5 |
| 4944 | pastores | 5 |
| 4945 | pasmado | 5 |
| 4946 | pascua | 5 |
| 4947 | parroquias | 5 |
| 4948 | párrafos | 5 |
| 4949 | parentesco | 5 |
| 4950 | pareciera | 5 |
| 4951 | parecidos | 5 |
| 4952 | parajes | 5 |
| 4953 | panza | 5 |
| 4954 | panera | 5 |
| 4955 | palmatoria | 5 |
| 4956 | palma | 5 |
| 4957 | pálidas | 5 |
| 4958 | países | 5 |
| 4959 | pago | 5 |
| 4960 | pagaban | 5 |
| 4961 | paga | 5 |
| 4962 | padrino | 5 |
| 4963 | pa | 5 |
| 4964 | oyese | 5 |
| 4965 | oyeron | 5 |
| 4966 | ostensible | 5 |
| 4967 | oso | 5 |
| 4968 | osado | 5 |
| 4969 | orquesta | 5 |
| 4970 | orgulloso | 5 |
| 4971 | organista | 5 |
| 4972 | ordinariamente | 5 |
| 4973 | opuso | 5 |
| 4974 | oprimían | 5 |
| 4975 | oportuna | 5 |
| 4976 | oponerse | 5 |
| 4977 | opinó | 5 |
| 4978 | óperas | 5 |
| 4979 | olla | 5 |
| 4980 | olías | 5 |
| 4981 | ola | 5 |
| 4982 | oírse | 5 |
| 4983 | oficinas | 5 |
| 4984 | oficina | 5 |
| 4985 | ofendido | 5 |
| 4986 | ofender | 5 |
| 4987 | ocupar | 5 |
| 4988 | ocupación | 5 |
| 4989 | ocultaban | 5 |
| 4990 | ocaso | 5 |
| 4991 | obsesión | 5 |
| 4992 | observado | 5 |
| 4993 | obedecían | 5 |
| 4994 | obedecer | 5 |
| 4995 | obdulita | 5 |
| 4996 | nuca | 5 |
| 4997 | notable | 5 |
| 4998 | notaban | 5 |
| 4999 | noroeste | 5 |
| 5000 | non | 5 |
| 5001 | niega | 5 |
| 5002 | negativa | 5 |
| 5003 | necesitan | 5 |
| 5004 | nauplia | 5 |
| 5005 | naranjas | 5 |
| 5006 | nacía | 5 |
| 5007 | nacer | 5 |
| 5008 | murmurando | 5 |
| 5009 | murmuraban | 5 |
| 5010 | muriendo | 5 |
| 5011 | murciélago | 5 |
| 5012 | mundos | 5 |
| 5013 | mujercita | 5 |
| 5014 | muertas | 5 |
| 5015 | muelle | 5 |
| 5016 | muceta | 5 |
| 5017 | mover | 5 |
| 5018 | mostrando | 5 |
| 5019 | mostraban | 5 |
| 5020 | moros | 5 |
| 5021 | moriría | 5 |
| 5022 | morían | 5 |
| 5023 | moreno | 5 |
| 5024 | mordió | 5 |
| 5025 | mono | 5 |
| 5026 | moneda | 5 |
| 5027 | molesta | 5 |
| 5028 | mojarse | 5 |
| 5029 | mojado | 5 |
| 5030 | modesto | 5 |
| 5031 | misteriosos | 5 |
| 5032 | mismísimo | 5 |
| 5033 | miserias | 5 |
| 5034 | misas | 5 |
| 5035 | miraron | 5 |
| 5036 | mirarla | 5 |
| 5037 | miércoles | 5 |
| 5038 | mientes | 5 |
| 5039 | mezclada | 5 |
| 5040 | metros | 5 |
| 5041 | metafísica | 5 |
| 5042 | merecer | 5 |
| 5043 | mentiras | 5 |
| 5044 | meliflua | 5 |
| 5045 | meditar | 5 |
| 5046 | mediodía | 5 |
| 5047 | medidas | 5 |
| 5048 | matices | 5 |
| 5049 | maternal | 5 |
| 5050 | matando | 5 |
| 5051 | martillo | 5 |
| 5052 | martillazos | 5 |
| 5053 | marquetería | 5 |
| 5054 | mariposas | 5 |
| 5055 | mares | 5 |
| 5056 | mareo | 5 |
| 5057 | marchado | 5 |
| 5058 | manzana | 5 |
| 5059 | manías | 5 |
| 5060 | mandil | 5 |
| 5061 | mandaban | 5 |
| 5062 | mancha | 5 |
| 5063 | manantial | 5 |
| 5064 | maldita | 5 |
| 5065 | maldecir | 5 |
| 5066 | majestad | 5 |
| 5067 | magistrados | 5 |
| 5068 | madrugar | 5 |
| 5069 | lugareño | 5 |
| 5070 | luciendo | 5 |
| 5071 | local | 5 |
| 5072 | llevase | 5 |
| 5073 | llenando | 5 |
| 5074 | llenado | 5 |
| 5075 | llano | 5 |
| 5076 | literarias | 5 |
| 5077 | literaria | 5 |
| 5078 | limpiar | 5 |
| 5079 | lienzo | 5 |
| 5080 | libremente | 5 |
| 5081 | librea | 5 |
| 5082 | librar | 5 |
| 5083 | levemente | 5 |
| 5084 | levantando | 5 |
| 5085 | levantaban | 5 |
| 5086 | leopoldo | 5 |
| 5087 | leñador | 5 |
| 5088 | lentamente | 5 |
| 5089 | lenguas | 5 |
| 5090 | lectores | 5 |
| 5091 | lazos | 5 |
| 5092 | látigo | 5 |
| 5093 | lápiz | 5 |
| 5094 | languidez | 5 |
| 5095 | jugador | 5 |
| 5096 | júbilo | 5 |
| 5097 | jilgueros | 5 |
| 5098 | jergón | 5 |
| 5099 | inveterada | 5 |
| 5100 | inventar | 5 |
| 5101 | invención | 5 |
| 5102 | inundaba | 5 |
| 5103 | interrumpido | 5 |
| 5104 | interesantes | 5 |
| 5105 | interesado | 5 |
| 5106 | insufrible | 5 |
| 5107 | inspiración | 5 |
| 5108 | insoportable | 5 |
| 5109 | insolencia | 5 |
| 5110 | insinuante | 5 |
| 5111 | insinuaciones | 5 |
| 5112 | inmundicias | 5 |
| 5113 | inmaculada | 5 |
| 5114 | injusta | 5 |
| 5115 | ingratitud | 5 |
| 5116 | infiel | 5 |
| 5117 | infantil | 5 |
| 5118 | inexpugnable | 5 |
| 5119 | indiscreta | 5 |
| 5120 | indignado | 5 |
| 5121 | índice | 5 |
| 5122 | inconsciente | 5 |
| 5123 | inclinando | 5 |
| 5124 | incierto | 5 |
| 5125 | incidente | 5 |
| 5126 | inagotable | 5 |
| 5127 | impuesto | 5 |
| 5128 | importaban | 5 |
| 5129 | imaginaba | 5 |
| 5130 | ilustrísimo | 5 |
| 5131 | iconoclasta | 5 |
| 5132 | ibi | 5 |
| 5133 | huido | 5 |
| 5134 | huertas | 5 |
| 5135 | hospital | 5 |
| 5136 | horroroso | 5 |
| 5137 | horrorosa | 5 |
| 5138 | horrorizada | 5 |
| 5139 | histórico | 5 |
| 5140 | himno | 5 |
| 5141 | hermosos | 5 |
| 5142 | heno | 5 |
| 5143 | heladas | 5 |
| 5144 | hechizos | 5 |
| 5145 | hechas | 5 |
| 5146 | hará | 5 |
| 5147 | hacienda | 5 |
| 5148 | hacerme | 5 |
| 5149 | hacemos | 5 |
| 5150 | habrán | 5 |
| 5151 | hablaría | 5 |
| 5152 | hablaremos | 5 |
| 5153 | hablaré | 5 |
| 5154 | gutural | 5 |
| 5155 | guardó | 5 |
| 5156 | guarda | 5 |
| 5157 | groseros | 5 |
| 5158 | groseramente | 5 |
| 5159 | grillos | 5 |
| 5160 | griego | 5 |
| 5161 | granos | 5 |
| 5162 | grabados | 5 |
| 5163 | gota | 5 |
| 5164 | golosinas | 5 |
| 5165 | gentil | 5 |
| 5166 | gastadas | 5 |
| 5167 | ganas | 5 |
| 5168 | ganarse | 5 |
| 5169 | gallos | 5 |
| 5170 | gaita | 5 |
| 5171 | fusil | 5 |
| 5172 | fúnebres | 5 |
| 5173 | fundamento | 5 |
| 5174 | fumaba | 5 |
| 5175 | fuí | 5 |
| 5176 | fragua | 5 |
| 5177 | fornido | 5 |
| 5178 | fórmula | 5 |
| 5179 | fogón | 5 |
| 5180 | fluxus | 5 |
| 5181 | flexible | 5 |
| 5182 | firmemente | 5 |
| 5183 | fingirse | 5 |
| 5184 | fines | 5 |
| 5185 | finas | 5 |
| 5186 | fijarse | 5 |
| 5187 | figurándose | 5 |
| 5188 | fieras | 5 |
| 5189 | ferias | 5 |
| 5190 | favorito | 5 |
| 5191 | fatuos | 5 |
| 5192 | fatal | 5 |
| 5193 | famoso | 5 |
| 5194 | famosa | 5 |
| 5195 | faltan | 5 |
| 5196 | fachada | 5 |
| 5197 | extrañas | 5 |
| 5198 | extendiendo | 5 |
| 5199 | exquisita | 5 |
| 5200 | exponía | 5 |
| 5201 | explicación | 5 |
| 5202 | explica | 5 |
| 5203 | existía | 5 |
| 5204 | exijo | 5 |
| 5205 | excitado | 5 |
| 5206 | excesos | 5 |
| 5207 | excesiva | 5 |
| 5208 | exaltado | 5 |
| 5209 | exagerada | 5 |
| 5210 | exageración | 5 |
| 5211 | exacto | 5 |
| 5212 | exactitud | 5 |
| 5213 | eternas | 5 |
| 5214 | et | 5 |
| 5215 | estuvieron | 5 |
| 5216 | estuco | 5 |
| 5217 | estrella | 5 |
| 5218 | estrechez | 5 |
| 5219 | estiró | 5 |
| 5220 | estéril | 5 |
| 5221 | estatura | 5 |
| 5222 | estantes | 5 |
| 5223 | estante | 5 |
| 5224 | estando | 5 |
| 5225 | estallaban | 5 |
| 5226 | espontánea | 5 |
| 5227 | esplendor | 5 |
| 5228 | esperaría | 5 |
| 5229 | espectadores | 5 |
| 5230 | esparcidos | 5 |
| 5231 | españoles | 5 |
| 5232 | espantada | 5 |
| 5233 | escudo | 5 |
| 5234 | escuchaba | 5 |
| 5235 | escribo | 5 |
| 5236 | escribano | 5 |
| 5237 | escondite | 5 |
| 5238 | escondió | 5 |
| 5239 | esclavitud | 5 |
| 5240 | escandalosas | 5 |
| 5241 | erudito | 5 |
| 5242 | envueltos | 5 |
| 5243 | envuelta | 5 |
| 5244 | envidiaban | 5 |
| 5245 | entusiasmado | 5 |
| 5246 | entrecejo | 5 |
| 5247 | entendió | 5 |
| 5248 | enseñado | 5 |
| 5249 | enfermos | 5 |
| 5250 | énfasis | 5 |
| 5251 | encinas | 5 |
| 5252 | encerró | 5 |
| 5253 | encerrarse | 5 |
| 5254 | encargó | 5 |
| 5255 | empresa | 5 |
| 5256 | empezaron | 5 |
| 5257 | emma | 5 |
| 5258 | embustero | 5 |
| 5259 | elogio | 5 |
| 5260 | elementos | 5 |
| 5261 | elegía | 5 |
| 5262 | eléctrica | 5 |
| 5263 | efectivamente | 5 |
| 5264 | edificios | 5 |
| 5265 | edificante | 5 |
| 5266 | económico | 5 |
| 5267 | eco | 5 |
| 5268 | echarse | 5 |
| 5269 | echarlo | 5 |
| 5270 | echarle | 5 |
| 5271 | echan | 5 |
| 5272 | echada | 5 |
| 5273 | echa | 5 |
| 5274 | durar | 5 |
| 5275 | dulzuras | 5 |
| 5276 | dulcemente | 5 |
| 5277 | dueños | 5 |
| 5278 | dramática | 5 |
| 5279 | doy | 5 |
| 5280 | domingo | 5 |
| 5281 | dominado | 5 |
| 5282 | domésticos | 5 |
| 5283 | doméstico | 5 |
| 5284 | doctora | 5 |
| 5285 | dócil | 5 |
| 5286 | dobló | 5 |
| 5287 | doblar | 5 |
| 5288 | disputar | 5 |
| 5289 | displicente | 5 |
| 5290 | disimulos | 5 |
| 5291 | disimuladamente | 5 |
| 5292 | disfrutaba | 5 |
| 5293 | disfrazado | 5 |
| 5294 | discursos | 5 |
| 5295 | dirían | 5 |
| 5296 | directamente | 5 |
| 5297 | diplomático | 5 |
| 5298 | difuntos | 5 |
| 5299 | difíciles | 5 |
| 5300 | dictador | 5 |
| 5301 | diciéndole | 5 |
| 5302 | dichoso | 5 |
| 5303 | dichosa | 5 |
| 5304 | devorar | 5 |
| 5305 | destrozar | 5 |
| 5306 | despertador | 5 |
| 5307 | desnudez | 5 |
| 5308 | desierta | 5 |
| 5309 | desesperada | 5 |
| 5310 | desengaño | 5 |
| 5311 | deseando | 5 |
| 5312 | descubrió | 5 |
| 5313 | describir | 5 |
| 5314 | descompuesto | 5 |
| 5315 | descargó | 5 |
| 5316 | descansaba | 5 |
| 5317 | desaparecido | 5 |
| 5318 | desabrida | 5 |
| 5319 | demostraba | 5 |
| 5320 | demonios | 5 |
| 5321 | deliciosa | 5 |
| 5322 | dejan | 5 |
| 5323 | debiera | 5 |
| 5324 | darles | 5 |
| 5325 | danza | 5 |
| 5326 | curso | 5 |
| 5327 | curar | 5 |
| 5328 | curaba | 5 |
| 5329 | cumplía | 5 |
| 5330 | cuevas | 5 |
| 5331 | cuestiones | 5 |
| 5332 | cuestas | 5 |
| 5333 | cuervos | 5 |
| 5334 | cuclillas | 5 |
| 5335 | cuchicheos | 5 |
| 5336 | cruzó | 5 |
| 5337 | cruzando | 5 |
| 5338 | cruzados | 5 |
| 5339 | cruzado | 5 |
| 5340 | crujía | 5 |
| 5341 | cristianismo | 5 |
| 5342 | crímenes | 5 |
| 5343 | criaturas | 5 |
| 5344 | criatura | 5 |
| 5345 | creyera | 5 |
| 5346 | cortado | 5 |
| 5347 | cortada | 5 |
| 5348 | corrientes | 5 |
| 5349 | correspondencia | 5 |
| 5350 | corona | 5 |
| 5351 | convite | 5 |
| 5352 | convirtió | 5 |
| 5353 | convertían | 5 |
| 5354 | convenido | 5 |
| 5355 | convencer | 5 |
| 5356 | contornos | 5 |
| 5357 | contiguo | 5 |
| 5358 | contigo | 5 |
| 5359 | contarse | 5 |
| 5360 | consolaba | 5 |
| 5361 | consintió | 5 |
| 5362 | considerando | 5 |
| 5363 | consideraciones | 5 |
| 5364 | consideraban | 5 |
| 5365 | consecuencias | 5 |
| 5366 | consagró | 5 |
| 5367 | conquistador | 5 |
| 5368 | conocerlo | 5 |
| 5369 | confusa | 5 |
| 5370 | confianzas | 5 |
| 5371 | concurso | 5 |
| 5372 | concluido | 5 |
| 5373 | conciencias | 5 |
| 5374 | concepción | 5 |
| 5375 | compró | 5 |
| 5376 | comprendiendo | 5 |
| 5377 | compra | 5 |
| 5378 | complot | 5 |
| 5379 | cómplices | 5 |
| 5380 | comiendo | 5 |
| 5381 | comezón | 5 |
| 5382 | combatir | 5 |
| 5383 | colocar | 5 |
| 5384 | colgando | 5 |
| 5385 | colgada | 5 |
| 5386 | colegas | 5 |
| 5387 | colás | 5 |
| 5388 | cobrar | 5 |
| 5389 | clerigalla | 5 |
| 5390 | claros | 5 |
| 5391 | cigarros | 5 |
| 5392 | ciertamente | 5 |
| 5393 | chocho | 5 |
| 5394 | chin | 5 |
| 5395 | chalequeras | 5 |
| 5396 | cháchara | 5 |
| 5397 | cerraban | 5 |
| 5398 | cerezas | 5 |
| 5399 | ceño | 5 |
| 5400 | ceñía | 5 |
| 5401 | cenceño | 5 |
| 5402 | cenas | 5 |
| 5403 | cedido | 5 |
| 5404 | cazadora | 5 |
| 5405 | caserones | 5 |
| 5406 | cartuchos | 5 |
| 5407 | carruaje | 5 |
| 5408 | carmesí | 5 |
| 5409 | careta | 5 |
| 5410 | caracteres | 5 |
| 5411 | capellanías | 5 |
| 5412 | capaces | 5 |
| 5413 | cantares | 5 |
| 5414 | canción | 5 |
| 5415 | campiña | 5 |
| 5416 | campestres | 5 |
| 5417 | callejón | 5 |
| 5418 | callejas | 5 |
| 5419 | cachet | 5 |
| 5420 | cabe | 5 |
| 5421 | burdeos | 5 |
| 5422 | bruces | 5 |
| 5423 | brinco | 5 |
| 5424 | brillo | 5 |
| 5425 | bordadas | 5 |
| 5426 | bola | 5 |
| 5427 | bocados | 5 |
| 5428 | blasfemias | 5 |
| 5429 | blanquecino | 5 |
| 5430 | bilis | 5 |
| 5431 | biblia | 5 |
| 5432 | besugo | 5 |
| 5433 | bello | 5 |
| 5434 | bellas | 5 |
| 5435 | belén | 5 |
| 5436 | bayeta | 5 |
| 5437 | bastó | 5 |
| 5438 | basilio | 5 |
| 5439 | barcaza | 5 |
| 5440 | balmes | 5 |
| 5441 | bajas | 5 |
| 5442 | bajaban | 5 |
| 5443 | bailarinas | 5 |
| 5444 | bailarina | 5 |
| 5445 | azotar | 5 |
| 5446 | ayudarle | 5 |
| 5447 | ayudado | 5 |
| 5448 | avisar | 5 |
| 5449 | ávila | 5 |
| 5450 | aves | 5 |
| 5451 | ausentes | 5 |
| 5452 | atrocidad | 5 |
| 5453 | atreve | 5 |
| 5454 | astros | 5 |
| 5455 | aspirar | 5 |
| 5456 | asomar | 5 |
| 5457 | asís | 5 |
| 5458 | aseguró | 5 |
| 5459 | artístico | 5 |
| 5460 | artística | 5 |
| 5461 | arrojado | 5 |
| 5462 | arreglar | 5 |
| 5463 | arranca | 5 |
| 5464 | arqueológico | 5 |
| 5465 | armónica | 5 |
| 5466 | armiño | 5 |
| 5467 | ardía | 5 |
| 5468 | arañas | 5 |
| 5469 | apuro | 5 |
| 5470 | apuntando | 5 |
| 5471 | aprobación | 5 |
| 5472 | apretón | 5 |
| 5473 | apretar | 5 |
| 5474 | aprender | 5 |
| 5475 | apoyarse | 5 |
| 5476 | aplicar | 5 |
| 5477 | aplausos | 5 |
| 5478 | aparato | 5 |
| 5479 | anunciación | 5 |
| 5480 | anunciaba | 5 |
| 5481 | antipática | 5 |
| 5482 | antigüedad | 5 |
| 5483 | anteriores | 5 |
| 5484 | anteojo | 5 |
| 5485 | anoche | 5 |
| 5486 | anís | 5 |
| 5487 | anhelo | 5 |
| 5488 | angustia | 5 |
| 5489 | andaban | 5 |
| 5490 | ampuloso | 5 |
| 5491 | amoroso | 5 |
| 5492 | amorosas | 5 |
| 5493 | amistades | 5 |
| 5494 | amarillento | 5 |
| 5495 | amarillenta | 5 |
| 5496 | amarilla | 5 |
| 5497 | amarga | 5 |
| 5498 | amaban | 5 |
| 5499 | alusiones | 5 |
| 5500 | almohada | 5 |
| 5501 | almíbar | 5 |
| 5502 | alias | 5 |
| 5503 | alejó | 5 |
| 5504 | alcanza | 5 |
| 5505 | alcance | 5 |
| 5506 | alba | 5 |
| 5507 | alardes | 5 |
| 5508 | alababan | 5 |
| 5509 | alababa | 5 |
| 5510 | ajo | 5 |
| 5511 | ajenas | 5 |
| 5512 | agujas | 5 |
| 5513 | agradecido | 5 |
| 5514 | afirmación | 5 |
| 5515 | afable | 5 |
| 5516 | adversario | 5 |
| 5517 | adquirido | 5 |
| 5518 | adornos | 5 |
| 5519 | adoración | 5 |
| 5520 | adoraban | 5 |
| 5521 | adónde | 5 |
| 5522 | admitió | 5 |
| 5523 | admitía | 5 |
| 5524 | admiró | 5 |
| 5525 | ademanes | 5 |
| 5526 | activo | 5 |
| 5527 | acostumbrada | 5 |
| 5528 | acordándose | 5 |
| 5529 | acercado | 5 |
| 5530 | aceras | 5 |
| 5531 | aceptaba | 5 |
| 5532 | acento | 5 |
| 5533 | aceite | 5 |
| 5534 | accesos | 5 |
| 5535 | acariciando | 5 |
| 5536 | acacias | 5 |
| 5537 | abusos | 5 |
| 5538 | aburrirse | 5 |
| 5539 | absolución | 5 |
| 5540 | abominable | 5 |
| 5541 | abandonar | 5 |
| 5542 | zarzas | 4 |
| 5543 | zapato | 4 |
| 5544 | wamba | 4 |
| 5545 | wals | 4 |
| 5546 | votos | 4 |
| 5547 | voto | 4 |
| 5548 | volverían | 4 |
| 5549 | vivienda | 4 |
| 5550 | vivas | 4 |
| 5551 | viudita | 4 |
| 5552 | viudedad | 4 |
| 5553 | víspera | 4 |
| 5554 | violines | 4 |
| 5555 | viniese | 4 |
| 5556 | viniera | 4 |
| 5557 | villano | 4 |
| 5558 | vigorosa | 4 |
| 5559 | vigilaba | 4 |
| 5560 | vidrios | 4 |
| 5561 | vestían | 4 |
| 5562 | verosimilitud | 4 |
| 5563 | verosímil | 4 |
| 5564 | verían | 4 |
| 5565 | verán | 4 |
| 5566 | venus | 4 |
| 5567 | ventura | 4 |
| 5568 | vengar | 4 |
| 5569 | vemos | 4 |
| 5570 | veleidades | 4 |
| 5571 | veintisiete | 4 |
| 5572 | vehementes | 4 |
| 5573 | vecindad | 4 |
| 5574 | vean | 4 |
| 5575 | vasos | 4 |
| 5576 | varones | 4 |
| 5577 | valla | 4 |
| 5578 | vacilante | 4 |
| 5579 | vacante | 4 |
| 5580 | vacaciones | 4 |
| 5581 | usar | 4 |
| 5582 | usando | 4 |
| 5583 | universidad | 4 |
| 5584 | unidos | 4 |
| 5585 | únicamente | 4 |
| 5586 | ultrajado | 4 |
| 5587 | últimamente | 4 |
| 5588 | tuya | 4 |
| 5589 | turbaba | 4 |
| 5590 | túnica | 4 |
| 5591 | trovador | 4 |
| 5592 | trote | 4 |
| 5593 | trotaconventos | 4 |
| 5594 | tropezado | 4 |
| 5595 | troncos | 4 |
| 5596 | tripas | 4 |
| 5597 | tributo | 4 |
| 5598 | tributaba | 4 |
| 5599 | trechos | 4 |
| 5600 | traviata | 4 |
| 5601 | tratase | 4 |
| 5602 | trasladó | 4 |
| 5603 | trajo | 4 |
| 5604 | traigo | 4 |
| 5605 | traigan | 4 |
| 5606 | trágico | 4 |
| 5607 | tragar | 4 |
| 5608 | tostada | 4 |
| 5609 | tórtola | 4 |
| 5610 | tornasoles | 4 |
| 5611 | tomillo | 4 |
| 5612 | tolerable | 4 |
| 5613 | toga | 4 |
| 5614 | tocarla | 4 |
| 5615 | títulos | 4 |
| 5616 | tisis | 4 |
| 5617 | tiros | 4 |
| 5618 | timidez | 4 |
| 5619 | tímidamente | 4 |
| 5620 | tímida | 4 |
| 5621 | tibieza | 4 |
| 5622 | tibias | 4 |
| 5623 | testimonio | 4 |
| 5624 | tertulín | 4 |
| 5625 | territorial | 4 |
| 5626 | terrenos | 4 |
| 5627 | terremoto | 4 |
| 5628 | terminante | 4 |
| 5629 | terminada | 4 |
| 5630 | tenor | 4 |
| 5631 | tendidos | 4 |
| 5632 | tenazas | 4 |
| 5633 | tenacidad | 4 |
| 5634 | tempore | 4 |
| 5635 | temporal | 4 |
| 5636 | tempestad | 4 |
| 5637 | temeroso | 4 |
| 5638 | temas | 4 |
| 5639 | tema | 4 |
| 5640 | telégrafo | 4 |
| 5641 | tedio | 4 |
| 5642 | técnicos | 4 |
| 5643 | tarsila | 4 |
| 5644 | tardaría | 4 |
| 5645 | tapices | 4 |
| 5646 | talleres | 4 |
| 5647 | tácito | 4 |
| 5648 | tablado | 4 |
| 5649 | tabaco | 4 |
| 5650 | sustituto | 4 |
| 5651 | suspiro | 4 |
| 5652 | supongo | 4 |
| 5653 | suponer | 4 |
| 5654 | súplicas | 4 |
| 5655 | supina | 4 |
| 5656 | sumido | 4 |
| 5657 | sueltas | 4 |
| 5658 | suela | 4 |
| 5659 | sudando | 4 |
| 5660 | suculento | 4 |
| 5661 | sucias | 4 |
| 5662 | sucesión | 4 |
| 5663 | subo | 4 |
| 5664 | sublimes | 4 |
| 5665 | sótanos | 4 |
| 5666 | sostenía | 4 |
| 5667 | sorpresas | 4 |
| 5668 | sorprendió | 4 |
| 5669 | sórdido | 4 |
| 5670 | soportales | 4 |
| 5671 | soplar | 4 |
| 5672 | soñando | 4 |
| 5673 | sonreído | 4 |
| 5674 | sonoras | 4 |
| 5675 | sonar | 4 |
| 5676 | sombreros | 4 |
| 5677 | sollozando | 4 |
| 5678 | solitarias | 4 |
| 5679 | sólidos | 4 |
| 5680 | sólida | 4 |
| 5681 | solicitud | 4 |
| 5682 | solicitaba | 4 |
| 5683 | sofocada | 4 |
| 5684 | sócrates | 4 |
| 5685 | socarrón | 4 |
| 5686 | sobrinita | 4 |
| 5687 | soberbios | 4 |
| 5688 | soberbio | 4 |
| 5689 | sobado | 4 |
| 5690 | sirven | 4 |
| 5691 | sintiera | 4 |
| 5692 | siniestro | 4 |
| 5693 | singularmente | 4 |
| 5694 | simonía | 4 |
| 5695 | simbólico | 4 |
| 5696 | silenciosos | 4 |
| 5697 | severo | 4 |
| 5698 | seto | 4 |
| 5699 | serán | 4 |
| 5700 | sepultura | 4 |
| 5701 | señalar | 4 |
| 5702 | señalada | 4 |
| 5703 | sentirlo | 4 |
| 5704 | sentimentalismo | 4 |
| 5705 | sentaban | 4 |
| 5706 | sencillez | 4 |
| 5707 | semejanza | 4 |
| 5708 | seguidos | 4 |
| 5709 | seculares | 4 |
| 5710 | secretas | 4 |
| 5711 | secos | 4 |
| 5712 | sebo | 4 |
| 5713 | seas | 4 |
| 5714 | seamos | 4 |
| 5715 | santísima | 4 |
| 5716 | sangrando | 4 |
| 5717 | salvarme | 4 |
| 5718 | salvador | 4 |
| 5719 | salvado | 4 |
| 5720 | salva | 4 |
| 5721 | saludaban | 4 |
| 5722 | saltado | 4 |
| 5723 | salmón | 4 |
| 5724 | saldré | 4 |
| 5725 | sagradas | 4 |
| 5726 | sagaz | 4 |
| 5727 | sacudida | 4 |
| 5728 | sacudía | 4 |
| 5729 | sacrílego | 4 |
| 5730 | saco | 4 |
| 5731 | sacerdocio | 4 |
| 5732 | sacarle | 4 |
| 5733 | saca | 4 |
| 5734 | saboreado | 4 |
| 5735 | sables | 4 |
| 5736 | sabios | 4 |
| 5737 | sabiendo | 4 |
| 5738 | sabiamente | 4 |
| 5739 | sabia | 4 |
| 5740 | ruso | 4 |
| 5741 | run | 4 |
| 5742 | ronco | 4 |
| 5743 | rojos | 4 |
| 5744 | rodeos | 4 |
| 5745 | rodando | 4 |
| 5746 | robo | 4 |
| 5747 | rizado | 4 |
| 5748 | rigores | 4 |
| 5749 | riendo | 4 |
| 5750 | rienda | 4 |
| 5751 | ríen | 4 |
| 5752 | ridículos | 4 |
| 5753 | rezando | 4 |
| 5754 | reyertas | 4 |
| 5755 | revista | 4 |
| 5756 | revela | 4 |
| 5757 | retorcidos | 4 |
| 5758 | retiro | 4 |
| 5759 | retirarse | 4 |
| 5760 | retablo | 4 |
| 5761 | responde | 4 |
| 5762 | resplandor | 4 |
| 5763 | respetaban | 4 |
| 5764 | respeta | 4 |
| 5765 | respectivo | 4 |
| 5766 | respectivas | 4 |
| 5767 | resonancias | 4 |
| 5768 | representación | 4 |
| 5769 | representaban | 4 |
| 5770 | reprensión | 4 |
| 5771 | repetían | 4 |
| 5772 | reparto | 4 |
| 5773 | reparaba | 4 |
| 5774 | renunciaba | 4 |
| 5775 | renta | 4 |
| 5776 | rendido | 4 |
| 5777 | remediar | 4 |
| 5778 | religiones | 4 |
| 5779 | relieves | 4 |
| 5780 | rejuvenecido | 4 |
| 5781 | regaló | 4 |
| 5782 | refresco | 4 |
| 5783 | reflejaba | 4 |
| 5784 | refinada | 4 |
| 5785 | referir | 4 |
| 5786 | reducido | 4 |
| 5787 | recto | 4 |
| 5788 | recorrer | 4 |
| 5789 | reconozco | 4 |
| 5790 | reconoce | 4 |
| 5791 | recomendaba | 4 |
| 5792 | recogido | 4 |
| 5793 | recobrar | 4 |
| 5794 | reclamo | 4 |
| 5795 | reclamaban | 4 |
| 5796 | recitar | 4 |
| 5797 | recitando | 4 |
| 5798 | recargado | 4 |
| 5799 | rebaño | 4 |
| 5800 | raya | 4 |
| 5801 | ratón | 4 |
| 5802 | rasgos | 4 |
| 5803 | rasgo | 4 |
| 5804 | rasgaba | 4 |
| 5805 | rápido | 4 |
| 5806 | rapavelas | 4 |
| 5807 | radical | 4 |
| 5808 | rabillo | 4 |
| 5809 | quizás | 4 |
| 5810 | quitar | 4 |
| 5811 | quitaban | 4 |
| 5812 | quintillas | 4 |
| 5813 | quinqué | 4 |
| 5814 | quieran | 4 |
| 5815 | quiá | 4 |
| 5816 | querría | 4 |
| 5817 | queremos | 4 |
| 5818 | quemaba | 4 |
| 5819 | quema | 4 |
| 5820 | quejido | 4 |
| 5821 | quehaceres | 4 |
| 5822 | quedan | 4 |
| 5823 | quebraderos | 4 |
| 5824 | q | 4 |
| 5825 | púrpura | 4 |
| 5826 | puñaladas | 4 |
| 5827 | punzante | 4 |
| 5828 | pulvisés | 4 |
| 5829 | pulquérrimo | 4 |
| 5830 | pulmonía | 4 |
| 5831 | pulla | 4 |
| 5832 | puente | 4 |
| 5833 | pudiesen | 4 |
| 5834 | publicaba | 4 |
| 5835 | psicología | 4 |
| 5836 | pseudo | 4 |
| 5837 | prurito | 4 |
| 5838 | provisiones | 4 |
| 5839 | provincias | 4 |
| 5840 | protestó | 4 |
| 5841 | protesto | 4 |
| 5842 | protestantes | 4 |
| 5843 | protección | 4 |
| 5844 | prosaicas | 4 |
| 5845 | propinas | 4 |
| 5846 | propina | 4 |
| 5847 | prometiendo | 4 |
| 5848 | prometer | 4 |
| 5849 | prohibidos | 4 |
| 5850 | prohibida | 4 |
| 5851 | prohíbe | 4 |
| 5852 | progresistas | 4 |
| 5853 | profano | 4 |
| 5854 | producto | 4 |
| 5855 | producir | 4 |
| 5856 | prodigaba | 4 |
| 5857 | procuraban | 4 |
| 5858 | problema | 4 |
| 5859 | probables | 4 |
| 5860 | prisiones | 4 |
| 5861 | princesa | 4 |
| 5862 | pretensión | 4 |
| 5863 | pretendiendo | 4 |
| 5864 | presentaron | 4 |
| 5865 | presentar | 4 |
| 5866 | presentado | 4 |
| 5867 | presenta | 4 |
| 5868 | prescindir | 4 |
| 5869 | presbítero | 4 |
| 5870 | preparación | 4 |
| 5871 | preocupación | 4 |
| 5872 | preocupaban | 4 |
| 5873 | premios | 4 |
| 5874 | preguntarle | 4 |
| 5875 | preciosa | 4 |
| 5876 | prácticas | 4 |
| 5877 | pórtico | 4 |
| 5878 | pontífice | 4 |
| 5879 | ponerle | 4 |
| 5880 | ponerla | 4 |
| 5881 | pómulos | 4 |
| 5882 | plebeyo | 4 |
| 5883 | plebe | 4 |
| 5884 | plática | 4 |
| 5885 | platea | 4 |
| 5886 | plásticas | 4 |
| 5887 | planta | 4 |
| 5888 | pistolas | 4 |
| 5889 | pipa | 4 |
| 5890 | pío | 4 |
| 5891 | pintores | 4 |
| 5892 | pintor | 4 |
| 5893 | pintar | 4 |
| 5894 | pinchaban | 4 |
| 5895 | pillastre | 4 |
| 5896 | piden | 4 |
| 5897 | picardías | 4 |
| 5898 | picaba | 4 |
| 5899 | pica | 4 |
| 5900 | piadosos | 4 |
| 5901 | pescuezo | 4 |
| 5902 | pesados | 4 |
| 5903 | pesadillas | 4 |
| 5904 | pesada | 4 |
| 5905 | perseguían | 4 |
| 5906 | perpetua | 4 |
| 5907 | permitían | 4 |
| 5908 | permanente | 4 |
| 5909 | perilla | 4 |
| 5910 | perfecto | 4 |
| 5911 | perdidos | 4 |
| 5912 | perdidas | 4 |
| 5913 | perdería | 4 |
| 5914 | pensadores | 4 |
| 5915 | peligroso | 4 |
| 5916 | peligrosa | 4 |
| 5917 | peguetas | 4 |
| 5918 | pecadora | 4 |
| 5919 | pausadamente | 4 |
| 5920 | pátina | 4 |
| 5921 | paseó | 4 |
| 5922 | pase | 4 |
| 5923 | partidarios | 4 |
| 5924 | particulares | 4 |
| 5925 | parroquial | 4 |
| 5926 | paró | 4 |
| 5927 | parezca | 4 |
| 5928 | pares | 4 |
| 5929 | parecieron | 4 |
| 5930 | parecíale | 4 |
| 5931 | parecerse | 4 |
| 5932 | parecerle | 4 |
| 5933 | parcerisa | 4 |
| 5934 | paños | 4 |
| 5935 | panorama | 4 |
| 5936 | pana | 4 |
| 5937 | palmada | 4 |
| 5938 | pajarillo | 4 |
| 5939 | pajarera | 4 |
| 5940 | página | 4 |
| 5941 | pacto | 4 |
| 5942 | pábulo | 4 |
| 5943 | ostentaban | 4 |
| 5944 | osaba | 4 |
| 5945 | ordinarios | 4 |
| 5946 | optimismo | 4 |
| 5947 | opiniones | 4 |
| 5948 | olvidé | 4 |
| 5949 | ofrecido | 4 |
| 5950 | oficios | 4 |
| 5951 | oficiales | 4 |
| 5952 | oficial | 4 |
| 5953 | ochavo | 4 |
| 5954 | occidente | 4 |
| 5955 | obstáculo | 4 |
| 5956 | observador | 4 |
| 5957 | obscurantista | 4 |
| 5958 | obligado | 4 |
| 5959 | obliga | 4 |
| 5960 | obispos | 4 |
| 5961 | número | 4 |
| 5962 | nudo | 4 |
| 5963 | nublado | 4 |
| 5964 | nubecillas | 4 |
| 5965 | noviembre | 4 |
| 5966 | novicia | 4 |
| 5967 | nostalgia | 4 |
| 5968 | nogal | 4 |
| 5969 | noé | 4 |
| 5970 | niñerías | 4 |
| 5971 | nimiedades | 4 |
| 5972 | nieblas | 4 |
| 5973 | nerviosos | 4 |
| 5974 | negarlo | 4 |
| 5975 | necesarias | 4 |
| 5976 | navidad | 4 |
| 5977 | náufragos | 4 |
| 5978 | naturalista | 4 |
| 5979 | naturalidad | 4 |
| 5980 | napoleón | 4 |
| 5981 | nació | 4 |
| 5982 | nacían | 4 |
| 5983 | nácar | 4 |
| 5984 | mustio | 4 |
| 5985 | murmuró | 4 |
| 5986 | murmuradores | 4 |
| 5987 | muriese | 4 |
| 5988 | murallas | 4 |
| 5989 | municipio | 4 |
| 5990 | mundanas | 4 |
| 5991 | muertes | 4 |
| 5992 | mozas | 4 |
| 5993 | mostrar | 4 |
| 5994 | mostrador | 4 |
| 5995 | mortales | 4 |
| 5996 | morirá | 4 |
| 5997 | moradas | 4 |
| 5998 | montaraz | 4 |
| 5999 | monos | 4 |
| 6000 | molestia | 4 |
| 6001 | molestarle | 4 |
| 6002 | mitra | 4 |
| 6003 | misioneros | 4 |
| 6004 | mísera | 4 |
| 6005 | miramientos | 4 |
| 6006 | mimado | 4 |
| 6007 | militares | 4 |
| 6008 | metiendo | 4 |
| 6009 | meterle | 4 |
| 6010 | metálico | 4 |
| 6011 | metálica | 4 |
| 6012 | meretrices | 4 |
| 6013 | merecido | 4 |
| 6014 | mente | 4 |
| 6015 | meditó | 4 |
| 6016 | meditación | 4 |
| 6017 | medicinas | 4 |
| 6018 | maza | 4 |
| 6019 | mató | 4 |
| 6020 | mataría | 4 |
| 6021 | matan | 4 |
| 6022 | máscara | 4 |
| 6023 | masas | 4 |
| 6024 | marzo | 4 |
| 6025 | margen | 4 |
| 6026 | marea | 4 |
| 6027 | marco | 4 |
| 6028 | marcial | 4 |
| 6029 | maravilla | 4 |
| 6030 | marasmo | 4 |
| 6031 | maquiavelismo | 4 |
| 6032 | manto | 4 |
| 6033 | mantenía | 4 |
| 6034 | mansos | 4 |
| 6035 | manifestó | 4 |
| 6036 | manifestar | 4 |
| 6037 | manifestaba | 4 |
| 6038 | mando | 4 |
| 6039 | mandilón | 4 |
| 6040 | mancebo | 4 |
| 6041 | mamás | 4 |
| 6042 | malvados | 4 |
| 6043 | malva | 4 |
| 6044 | mainate | 4 |
| 6045 | madrugador | 4 |
| 6046 | madrugaba | 4 |
| 6047 | madrileño | 4 |
| 6048 | lugareña | 4 |
| 6049 | lucirse | 4 |
| 6050 | luchó | 4 |
| 6051 | locas | 4 |
| 6052 | llevaron | 4 |
| 6053 | llegara | 4 |
| 6054 | llegando | 4 |
| 6055 | llegan | 4 |
| 6056 | llame | 4 |
| 6057 | llamase | 4 |
| 6058 | llamaradas | 4 |
| 6059 | llamada | 4 |
| 6060 | llagas | 4 |
| 6061 | listo | 4 |
| 6062 | lista | 4 |
| 6063 | líquido | 4 |
| 6064 | linterna | 4 |
| 6065 | limpiando | 4 |
| 6066 | ligeramente | 4 |
| 6067 | ligera | 4 |
| 6068 | licor | 4 |
| 6069 | lícito | 4 |
| 6070 | librarse | 4 |
| 6071 | liberalismo | 4 |
| 6072 | levanto | 4 |
| 6073 | legos | 4 |
| 6074 | lechuguino | 4 |
| 6075 | lavaba | 4 |
| 6076 | laureles | 4 |
| 6077 | latidos | 4 |
| 6078 | laterales | 4 |
| 6079 | larvas | 4 |
| 6080 | lamentaba | 4 |
| 6081 | laico | 4 |
| 6082 | lágrima | 4 |
| 6083 | ladraba | 4 |
| 6084 | lacayos | 4 |
| 6085 | labor | 4 |
| 6086 | labio | 4 |
| 6087 | juzgar | 4 |
| 6088 | juzgaba | 4 |
| 6089 | justa | 4 |
| 6090 | jurar | 4 |
| 6091 | juntar | 4 |
| 6092 | juntando | 4 |
| 6093 | juntaban | 4 |
| 6094 | judío | 4 |
| 6095 | jubilado | 4 |
| 6096 | joya | 4 |
| 6097 | jerarquía | 4 |
| 6098 | je | 4 |
| 6099 | irritada | 4 |
| 6100 | irreverente | 4 |
| 6101 | iriarte | 4 |
| 6102 | irían | 4 |
| 6103 | iremos | 4 |
| 6104 | invocaba | 4 |
| 6105 | invitado | 4 |
| 6106 | inventado | 4 |
| 6107 | intensos | 4 |
| 6108 | intenciones | 4 |
| 6109 | intachable | 4 |
| 6110 | insultaba | 4 |
| 6111 | institución | 4 |
| 6112 | instaló | 4 |
| 6113 | inquietud | 4 |
| 6114 | inofensivo | 4 |
| 6115 | inodoro | 4 |
| 6116 | inmundo | 4 |
| 6117 | inminente | 4 |
| 6118 | injusticias | 4 |
| 6119 | injurias | 4 |
| 6120 | injertaba | 4 |
| 6121 | influjo | 4 |
| 6122 | infernal | 4 |
| 6123 | inefables | 4 |
| 6124 | indumentaria | 4 |
| 6125 | indiscreción | 4 |
| 6126 | indirectas | 4 |
| 6127 | india | 4 |
| 6128 | inconvenientes | 4 |
| 6129 | incluso | 4 |
| 6130 | inclinado | 4 |
| 6131 | incertidumbre | 4 |
| 6132 | incentivo | 4 |
| 6133 | improvisó | 4 |
| 6134 | implacable | 4 |
| 6135 | iluminar | 4 |
| 6136 | iluminada | 4 |
| 6137 | illo | 4 |
| 6138 | il | 4 |
| 6139 | ignorante | 4 |
| 6140 | idealista | 4 |
| 6141 | huyó | 4 |
| 6142 | humillados | 4 |
| 6143 | humillado | 4 |
| 6144 | huevos | 4 |
| 6145 | huerto | 4 |
| 6146 | hortalizas | 4 |
| 6147 | horrores | 4 |
| 6148 | horno | 4 |
| 6149 | honestas | 4 |
| 6150 | hondas | 4 |
| 6151 | homenaje | 4 |
| 6152 | hoguera | 4 |
| 6153 | histórica | 4 |
| 6154 | hipótesis | 4 |
| 6155 | hice | 4 |
| 6156 | heroína | 4 |
| 6157 | heroico | 4 |
| 6158 | heroica | 4 |
| 6159 | hermanitas | 4 |
| 6160 | herida | 4 |
| 6161 | herejía | 4 |
| 6162 | herejes | 4 |
| 6163 | helado | 4 |
| 6164 | hazañas | 4 |
| 6165 | hayan | 4 |
| 6166 | haciéndose | 4 |
| 6167 | hachas | 4 |
| 6168 | hablillas | 4 |
| 6169 | hablé | 4 |
| 6170 | hablase | 4 |
| 6171 | hablas | 4 |
| 6172 | hablara | 4 |
| 6173 | hablador | 4 |
| 6174 | habíamos | 4 |
| 6175 | haberse | 4 |
| 6176 | habéis | 4 |
| 6177 | habana | 4 |
| 6178 | gustado | 4 |
| 6179 | guisa | 4 |
| 6180 | guiñaba | 4 |
| 6181 | gruñido | 4 |
| 6182 | gruesos | 4 |
| 6183 | gruesa | 4 |
| 6184 | grotesca | 4 |
| 6185 | gregorio | 4 |
| 6186 | grandísimo | 4 |
| 6187 | grandísima | 4 |
| 6188 | granate | 4 |
| 6189 | grana | 4 |
| 6190 | grados | 4 |
| 6191 | graciosos | 4 |
| 6192 | grabado | 4 |
| 6193 | gozo | 4 |
| 6194 | gozan | 4 |
| 6195 | gorriones | 4 |
| 6196 | gorra | 4 |
| 6197 | glorias | 4 |
| 6198 | gimnasia | 4 |
| 6199 | generales | 4 |
| 6200 | gemelos | 4 |
| 6201 | gatillo | 4 |
| 6202 | gastado | 4 |
| 6203 | ganancias | 4 |
| 6204 | gala | 4 |
| 6205 | gacetilla | 4 |
| 6206 | fundar | 4 |
| 6207 | fumar | 4 |
| 6208 | fuere | 4 |
| 6209 | fuegos | 4 |
| 6210 | fruta | 4 |
| 6211 | frotaba | 4 |
| 6212 | frescos | 4 |
| 6213 | francisca | 4 |
| 6214 | francia | 4 |
| 6215 | francesa | 4 |
| 6216 | franca | 4 |
| 6217 | fragmentos | 4 |
| 6218 | formada | 4 |
| 6219 | formaban | 4 |
| 6220 | fondos | 4 |
| 6221 | folletines | 4 |
| 6222 | flotaban | 4 |
| 6223 | floridos | 4 |
| 6224 | florida | 4 |
| 6225 | flora | 4 |
| 6226 | física | 4 |
| 6227 | fío | 4 |
| 6228 | finura | 4 |
| 6229 | final | 4 |
| 6230 | filosófico | 4 |
| 6231 | filial | 4 |
| 6232 | fijó | 4 |
| 6233 | figúrate | 4 |
| 6234 | fibras | 4 |
| 6235 | fecha | 4 |
| 6236 | febril | 4 |
| 6237 | fausto | 4 |
| 6238 | fatalidad | 4 |
| 6239 | fantásticos | 4 |
| 6240 | falsedad | 4 |
| 6241 | factor | 4 |
| 6242 | exuberante | 4 |
| 6243 | extraviado | 4 |
| 6244 | extraordinario | 4 |
| 6245 | extranjero | 4 |
| 6246 | externo | 4 |
| 6247 | extendió | 4 |
| 6248 | extendían | 4 |
| 6249 | exquisito | 4 |
| 6250 | expresar | 4 |
| 6251 | explicarlo | 4 |
| 6252 | expedición | 4 |
| 6253 | expansiones | 4 |
| 6254 | éxito | 4 |
| 6255 | excomulgar | 4 |
| 6256 | exclamar | 4 |
| 6257 | excitación | 4 |
| 6258 | excitaba | 4 |
| 6259 | excesivo | 4 |
| 6260 | excepcional | 4 |
| 6261 | evangélica | 4 |
| 6262 | eufemismos | 4 |
| 6263 | estufa | 4 |
| 6264 | estudia | 4 |
| 6265 | estribos | 4 |
| 6266 | estribo | 4 |
| 6267 | estreno | 4 |
| 6268 | estrechar | 4 |
| 6269 | estirado | 4 |
| 6270 | estimaban | 4 |
| 6271 | éste | 4 |
| 6272 | estatuas | 4 |
| 6273 | estameña | 4 |
| 6274 | estallar | 4 |
| 6275 | estallaba | 4 |
| 6276 | estábamos | 4 |
| 6277 | esquivaba | 4 |
| 6278 | espléndida | 4 |
| 6279 | espiando | 4 |
| 6280 | espero | 4 |
| 6281 | esperase | 4 |
| 6282 | espejos | 4 |
| 6283 | espacios | 4 |
| 6284 | eses | 4 |
| 6285 | esencial | 4 |
| 6286 | escuelas | 4 |
| 6287 | escuchó | 4 |
| 6288 | escuchaban | 4 |
| 6289 | escrúpulo | 4 |
| 6290 | escribe | 4 |
| 6291 | escondidas | 4 |
| 6292 | escondía | 4 |
| 6293 | escaso | 4 |
| 6294 | escapó | 4 |
| 6295 | escaparate | 4 |
| 6296 | escapado | 4 |
| 6297 | escandalosos | 4 |
| 6298 | esbeltos | 4 |
| 6299 | eróticas | 4 |
| 6300 | erguía | 4 |
| 6301 | épocas | 4 |
| 6302 | epigramas | 4 |
| 6303 | envidió | 4 |
| 6304 | envidias | 4 |
| 6305 | envidiable | 4 |
| 6306 | entregar | 4 |
| 6307 | enterrar | 4 |
| 6308 | enteros | 4 |
| 6309 | enternecido | 4 |
| 6310 | enternecida | 4 |
| 6311 | enternecía | 4 |
| 6312 | enterase | 4 |
| 6313 | entenderse | 4 |
| 6314 | entendemos | 4 |
| 6315 | entendámonos | 4 |
| 6316 | enseñando | 4 |
| 6317 | enojo | 4 |
| 6318 | engañarse | 4 |
| 6319 | engañada | 4 |
| 6320 | endiablado | 4 |
| 6321 | encontrando | 4 |
| 6322 | encendían | 4 |
| 6323 | encendía | 4 |
| 6324 | encarnada | 4 |
| 6325 | enamorados | 4 |
| 6326 | emprendió | 4 |
| 6327 | empleó | 4 |
| 6328 | empleaban | 4 |
| 6329 | empezaban | 4 |
| 6330 | empeñó | 4 |
| 6331 | empeñaba | 4 |
| 6332 | empeña | 4 |
| 6333 | embriaguez | 4 |
| 6334 | embriagado | 4 |
| 6335 | emanaciones | 4 |
| 6336 | elocuentes | 4 |
| 6337 | elevarse | 4 |
| 6338 | elevar | 4 |
| 6339 | elección | 4 |
| 6340 | ejemplar | 4 |
| 6341 | egipcios | 4 |
| 6342 | efímero | 4 |
| 6343 | duras | 4 |
| 6344 | duran | 4 |
| 6345 | dramático | 4 |
| 6346 | dotes | 4 |
| 6347 | dorados | 4 |
| 6348 | dominicales | 4 |
| 6349 | dominarse | 4 |
| 6350 | documentos | 4 |
| 6351 | docenas | 4 |
| 6352 | docena | 4 |
| 6353 | divertían | 4 |
| 6354 | distracción | 4 |
| 6355 | distinto | 4 |
| 6356 | distinguido | 4 |
| 6357 | distingo | 4 |
| 6358 | disputaban | 4 |
| 6359 | disponer | 4 |
| 6360 | disparatada | 4 |
| 6361 | disparado | 4 |
| 6362 | disimuló | 4 |
| 6363 | disgustado | 4 |
| 6364 | discusiones | 4 |
| 6365 | disculpaba | 4 |
| 6366 | discretos | 4 |
| 6367 | disciplinas | 4 |
| 6368 | dirigiéndose | 4 |
| 6369 | directa | 4 |
| 6370 | dineral | 4 |
| 6371 | dimisión | 4 |
| 6372 | diluvio | 4 |
| 6373 | dije | 4 |
| 6374 | dignísimo | 4 |
| 6375 | digan | 4 |
| 6376 | difunta | 4 |
| 6377 | diera | 4 |
| 6378 | diario | 4 |
| 6379 | diabólica | 4 |
| 6380 | devotos | 4 |
| 6381 | devociones | 4 |
| 6382 | devocionario | 4 |
| 6383 | determinado | 4 |
| 6384 | detenía | 4 |
| 6385 | desvanecerse | 4 |
| 6386 | destacándose | 4 |
| 6387 | despreciaban | 4 |
| 6388 | despedían | 4 |
| 6389 | despecho | 4 |
| 6390 | desmoronaba | 4 |
| 6391 | desmayada | 4 |
| 6392 | deslumbrar | 4 |
| 6393 | desinteresada | 4 |
| 6394 | desigual | 4 |
| 6395 | deshecho | 4 |
| 6396 | deshacía | 4 |
| 6397 | desesperaba | 4 |
| 6398 | desear | 4 |
| 6399 | desdeñar | 4 |
| 6400 | descubierta | 4 |
| 6401 | descrédito | 4 |
| 6402 | desconsuelo | 4 |
| 6403 | descendiente | 4 |
| 6404 | descender | 4 |
| 6405 | descargaba | 4 |
| 6406 | descansar | 4 |
| 6407 | desaires | 4 |
| 6408 | desahogaba | 4 |
| 6409 | desafía | 4 |
| 6410 | depósito | 4 |
| 6411 | depositar | 4 |
| 6412 | demostrar | 4 |
| 6413 | demasías | 4 |
| 6414 | delicados | 4 |
| 6415 | dejes | 4 |
| 6416 | dejen | 4 |
| 6417 | déjate | 4 |
| 6418 | dejaría | 4 |
| 6419 | dejará | 4 |
| 6420 | dejamos | 4 |
| 6421 | degradación | 4 |
| 6422 | defendían | 4 |
| 6423 | decorosa | 4 |
| 6424 | declara | 4 |
| 6425 | decirla | 4 |
| 6426 | decidida | 4 |
| 6427 | decide | 4 |
| 6428 | debilidades | 4 |
| 6429 | debí | 4 |
| 6430 | dandy | 4 |
| 6431 | cuyas | 4 |
| 6432 | cumbre | 4 |
| 6433 | cultos | 4 |
| 6434 | culpable | 4 |
| 6435 | cuerpos | 4 |
| 6436 | cuerno | 4 |
| 6437 | cuchicheo | 4 |
| 6438 | cubiertas | 4 |
| 6439 | cuán | 4 |
| 6440 | cruces | 4 |
| 6441 | crónica | 4 |
| 6442 | crecer | 4 |
| 6443 | creación | 4 |
| 6444 | cráneo | 4 |
| 6445 | corujedo | 4 |
| 6446 | cortina | 4 |
| 6447 | corteses | 4 |
| 6448 | corrillos | 4 |
| 6449 | correcto | 4 |
| 6450 | corporal | 4 |
| 6451 | cordón | 4 |
| 6452 | copia | 4 |
| 6453 | convirtiera | 4 |
| 6454 | convino | 4 |
| 6455 | convierte | 4 |
| 6456 | convidar | 4 |
| 6457 | convertidos | 4 |
| 6458 | convenían | 4 |
| 6459 | convenció | 4 |
| 6460 | convencidos | 4 |
| 6461 | contrarrestar | 4 |
| 6462 | contradicción | 4 |
| 6463 | contorsiones | 4 |
| 6464 | continuaban | 4 |
| 6465 | contestación | 4 |
| 6466 | contenido | 4 |
| 6467 | consunción | 4 |
| 6468 | consumía | 4 |
| 6469 | consuela | 4 |
| 6470 | consolarle | 4 |
| 6471 | consiste | 4 |
| 6472 | consiente | 4 |
| 6473 | considerable | 4 |
| 6474 | conservado | 4 |
| 6475 | consentir | 4 |
| 6476 | conseguirlo | 4 |
| 6477 | consagrar | 4 |
| 6478 | consagraba | 4 |
| 6479 | congojas | 4 |
| 6480 | congoja | 4 |
| 6481 | confusión | 4 |
| 6482 | confundían | 4 |
| 6483 | conflicto | 4 |
| 6484 | confidencial | 4 |
| 6485 | confesárselo | 4 |
| 6486 | confesando | 4 |
| 6487 | condenada | 4 |
| 6488 | condenaba | 4 |
| 6489 | condena | 4 |
| 6490 | cónclave | 4 |
| 6491 | conciudadanos | 4 |
| 6492 | concilio | 4 |
| 6493 | conciertos | 4 |
| 6494 | concejales | 4 |
| 6495 | comunión | 4 |
| 6496 | compuesto | 4 |
| 6497 | comprendo | 4 |
| 6498 | complicados | 4 |
| 6499 | complicaciones | 4 |
| 6500 | complacencia | 4 |
| 6501 | comparando | 4 |
| 6502 | comparado | 4 |
| 6503 | compañera | 4 |
| 6504 | cómodo | 4 |
| 6505 | comodidad | 4 |
| 6506 | cómica | 4 |
| 6507 | cometer | 4 |
| 6508 | comerciantes | 4 |
| 6509 | comenzaban | 4 |
| 6510 | comendador | 4 |
| 6511 | colocada | 4 |
| 6512 | colinas | 4 |
| 6513 | colgar | 4 |
| 6514 | colección | 4 |
| 6515 | colchones | 4 |
| 6516 | coincidiendo | 4 |
| 6517 | coincidía | 4 |
| 6518 | cohetes | 4 |
| 6519 | cogía | 4 |
| 6520 | cocinera | 4 |
| 6521 | cocinas | 4 |
| 6522 | cobre | 4 |
| 6523 | clavado | 4 |
| 6524 | clavaban | 4 |
| 6525 | clava | 4 |
| 6526 | clásicos | 4 |
| 6527 | clásico | 4 |
| 6528 | clásica | 4 |
| 6529 | civiles | 4 |
| 6530 | cieno | 4 |
| 6531 | ciegos | 4 |
| 6532 | chusma | 4 |
| 6533 | churrigueresco | 4 |
| 6534 | chorreando | 4 |
| 6535 | chorizos | 4 |
| 6536 | chimeneas | 4 |
| 6537 | chillona | 4 |
| 6538 | chicas | 4 |
| 6539 | charadas | 4 |
| 6540 | chaqueta | 4 |
| 6541 | chaleco | 4 |
| 6542 | césped | 4 |
| 6543 | cerveza | 4 |
| 6544 | cerero | 4 |
| 6545 | ceder | 4 |
| 6546 | cazadores | 4 |
| 6547 | cayera | 4 |
| 6548 | cavilosa | 4 |
| 6549 | causado | 4 |
| 6550 | catarata | 4 |
| 6551 | catalán | 4 |
| 6552 | casto | 4 |
| 6553 | castillo | 4 |
| 6554 | castellano | 4 |
| 6555 | casó | 4 |
| 6556 | caseros | 4 |
| 6557 | casera | 4 |
| 6558 | cascos | 4 |
| 6559 | cascada | 4 |
| 6560 | casaban | 4 |
| 6561 | casaba | 4 |
| 6562 | cartón | 4 |
| 6563 | carmen | 4 |
| 6564 | carlista | 4 |
| 6565 | cardenal | 4 |
| 6566 | carca | 4 |
| 6567 | característica | 4 |
| 6568 | caracol | 4 |
| 6569 | cañas | 4 |
| 6570 | cantan | 4 |
| 6571 | canta | 4 |
| 6572 | cansó | 4 |
| 6573 | canarios | 4 |
| 6574 | campanero | 4 |
| 6575 | caminar | 4 |
| 6576 | calzaba | 4 |
| 6577 | calvo | 4 |
| 6578 | calorcillo | 4 |
| 6579 | callando | 4 |
| 6580 | calificar | 4 |
| 6581 | calientes | 4 |
| 6582 | calentaba | 4 |
| 6583 | cálculos | 4 |
| 6584 | calculaba | 4 |
| 6585 | calada | 4 |
| 6586 | calabazas | 4 |
| 6587 | cajas | 4 |
| 6588 | caiga | 4 |
| 6589 | caerse | 4 |
| 6590 | busque | 4 |
| 6591 | buscarme | 4 |
| 6592 | burlas | 4 |
| 6593 | burlándose | 4 |
| 6594 | burlaban | 4 |
| 6595 | brutales | 4 |
| 6596 | brotar | 4 |
| 6597 | breves | 4 |
| 6598 | brasero | 4 |
| 6599 | botánico | 4 |
| 6600 | borrachera | 4 |
| 6601 | borla | 4 |
| 6602 | boquirroto | 4 |
| 6603 | bonita | 4 |
| 6604 | bonachón | 4 |
| 6605 | bolas | 4 |
| 6606 | boj | 4 |
| 6607 | besarle | 4 |
| 6608 | besar | 4 |
| 6609 | besaba | 4 |
| 6610 | bendita | 4 |
| 6611 | beltrand | 4 |
| 6612 | basura | 4 |
| 6613 | barría | 4 |
| 6614 | barrer | 4 |
| 6615 | barniz | 4 |
| 6616 | barítono | 4 |
| 6617 | barbero | 4 |
| 6618 | barato | 4 |
| 6619 | bandos | 4 |
| 6620 | bancarrota | 4 |
| 6621 | balde | 4 |
| 6622 | bailado | 4 |
| 6623 | bacantes | 4 |
| 6624 | babilonia | 4 |
| 6625 | azar | 4 |
| 6626 | azafrán | 4 |
| 6627 | ayes | 4 |
| 6628 | aventurado | 4 |
| 6629 | autoridades | 4 |
| 6630 | aurora | 4 |
| 6631 | aumentaba | 4 |
| 6632 | audaz | 4 |
| 6633 | atrocidades | 4 |
| 6634 | atribuían | 4 |
| 6635 | atrevieron | 4 |
| 6636 | atravesaba | 4 |
| 6637 | atrasado | 4 |
| 6638 | atormentaban | 4 |
| 6639 | atleta | 4 |
| 6640 | atacaba | 4 |
| 6641 | asquerosas | 4 |
| 6642 | asomo | 4 |
| 6643 | asistido | 4 |
| 6644 | asistían | 4 |
| 6645 | asfixia | 4 |
| 6646 | artillería | 4 |
| 6647 | arrojaban | 4 |
| 6648 | arrodillada | 4 |
| 6649 | arrepentimiento | 4 |
| 6650 | arrepentida | 4 |
| 6651 | arregla | 4 |
| 6652 | arrastrado | 4 |
| 6653 | arraigadas | 4 |
| 6654 | arqueología | 4 |
| 6655 | ardua | 4 |
| 6656 | ardientes | 4 |
| 6657 | arcas | 4 |
| 6658 | arcángel | 4 |
| 6659 | aquél | 4 |
| 6660 | apuros | 4 |
| 6661 | apurada | 4 |
| 6662 | apuraban | 4 |
| 6663 | apuntó | 4 |
| 6664 | aprovechó | 4 |
| 6665 | aprovechase | 4 |
| 6666 | aprovechan | 4 |
| 6667 | aprobó | 4 |
| 6668 | apretadas | 4 |
| 6669 | apresuraba | 4 |
| 6670 | aprensiva | 4 |
| 6671 | apoyándose | 4 |
| 6672 | apoyando | 4 |
| 6673 | apostólico | 4 |
| 6674 | aplicó | 4 |
| 6675 | aplaudía | 4 |
| 6676 | aplastaba | 4 |
| 6677 | apiñados | 4 |
| 6678 | apetecible | 4 |
| 6679 | apasionado | 4 |
| 6680 | apasionada | 4 |
| 6681 | apagó | 4 |
| 6682 | apagada | 4 |
| 6683 | apagaba | 4 |
| 6684 | apacible | 4 |
| 6685 | anunciar | 4 |
| 6686 | antiquísima | 4 |
| 6687 | antero | 4 |
| 6688 | ansiedades | 4 |
| 6689 | ansia | 4 |
| 6690 | anochecer | 4 |
| 6691 | animación | 4 |
| 6692 | animaban | 4 |
| 6693 | angustias | 4 |
| 6694 | ancianos | 4 |
| 6695 | análisis | 4 |
| 6696 | anales | 4 |
| 6697 | amiguita | 4 |
| 6698 | amapola | 4 |
| 6699 | amaneradas | 4 |
| 6700 | alusión | 4 |
| 6701 | aludir | 4 |
| 6702 | altivo | 4 |
| 6703 | alpaca | 4 |
| 6704 | alimentos | 4 |
| 6705 | alemanes | 4 |
| 6706 | alejaban | 4 |
| 6707 | alegro | 4 |
| 6708 | aldeanos | 4 |
| 6709 | aldeano | 4 |
| 6710 | alabanza | 4 |
| 6711 | ajustado | 4 |
| 6712 | ajustada | 4 |
| 6713 | ajenos | 4 |
| 6714 | airado | 4 |
| 6715 | ahumado | 4 |
| 6716 | ahorros | 4 |
| 6717 | ahínco | 4 |
| 6718 | aguja | 4 |
| 6719 | águilas | 4 |
| 6720 | agudos | 4 |
| 6721 | agrada | 4 |
| 6722 | afectación | 4 |
| 6723 | adolescente | 4 |
| 6724 | adolescencia | 4 |
| 6725 | admirada | 4 |
| 6726 | admiraban | 4 |
| 6727 | adivinó | 4 |
| 6728 | ad | 4 |
| 6729 | acusado | 4 |
| 6730 | acusaba | 4 |
| 6731 | acusa | 4 |
| 6732 | acostaba | 4 |
| 6733 | acompañaron | 4 |
| 6734 | acompañarla | 4 |
| 6735 | acompañar | 4 |
| 6736 | acompañamiento | 4 |
| 6737 | acompañada | 4 |
| 6738 | aceptado | 4 |
| 6739 | acecho | 4 |
| 6740 | acarició | 4 |
| 6741 | acabase | 4 |
| 6742 | abusando | 4 |
| 6743 | aburrida | 4 |
| 6744 | aburren | 4 |
| 6745 | absurdas | 4 |
| 6746 | absurda | 4 |
| 6747 | abstracción | 4 |
| 6748 | abrumaba | 4 |
| 6749 | abrirle | 4 |
| 6750 | abrigado | 4 |
| 6751 | abrazos | 4 |
| 6752 | aborrecido | 4 |
| 6753 | aborrecer | 4 |
| 6754 | aborrece | 4 |
| 6755 | abanicos | 4 |
| 6756 | abandonaba | 4 |
| 6757 | abalorios | 4 |
| 6758 | zurriágame | 3 |
| 6759 | zumbaron | 3 |
| 6760 | xiv | 3 |
| 6761 | vuelvo | 3 |
| 6762 | vuelos | 3 |
| 6763 | votó | 3 |
| 6764 | volverme | 3 |
| 6765 | volveré | 3 |
| 6766 | vocinglero | 3 |
| 6767 | vivimos | 3 |
| 6768 | viviera | 3 |
| 6769 | viudez | 3 |
| 6770 | visitarla | 3 |
| 6771 | visión | 3 |
| 6772 | visible | 3 |
| 6773 | virtuoso | 3 |
| 6774 | vinieron | 3 |
| 6775 | villanía | 3 |
| 6776 | vieran | 3 |
| 6777 | viéndole | 3 |
| 6778 | vidriera | 3 |
| 6779 | vicisitudes | 3 |
| 6780 | viceversa | 3 |
| 6781 | vibrante | 3 |
| 6782 | vibraban | 3 |
| 6783 | vestigios | 3 |
| 6784 | veríamos | 3 |
| 6785 | vergonzosos | 3 |
| 6786 | vergonzosa | 3 |
| 6787 | verdugos | 3 |
| 6788 | verdores | 3 |
| 6789 | verdades | 3 |
| 6790 | verdaderos | 3 |
| 6791 | ventanilla | 3 |
| 6792 | venimos | 3 |
| 6793 | vendía | 3 |
| 6794 | vencerle | 3 |
| 6795 | vencerla | 3 |
| 6796 | velos | 3 |
| 6797 | velar | 3 |
| 6798 | velador | 3 |
| 6799 | vejiga | 3 |
| 6800 | vejete | 3 |
| 6801 | veinticuatro | 3 |
| 6802 | varillas | 3 |
| 6803 | vanos | 3 |
| 6804 | vanidades | 3 |
| 6805 | vanas | 3 |
| 6806 | vana | 3 |
| 6807 | valles | 3 |
| 6808 | valen | 3 |
| 6809 | vacíos | 3 |
| 6810 | vacilaba | 3 |
| 6811 | vacas | 3 |
| 6812 | utilizar | 3 |
| 6813 | usan | 3 |
| 6814 | urna | 3 |
| 6815 | unión | 3 |
| 6816 | unidad | 3 |
| 6817 | unida | 3 |
| 6818 | unanimidad | 3 |
| 6819 | unánime | 3 |
| 6820 | u | 3 |
| 6821 | turgentes | 3 |
| 6822 | turgente | 3 |
| 6823 | turgencias | 3 |
| 6824 | turbarse | 3 |
| 6825 | turbada | 3 |
| 6826 | tupido | 3 |
| 6827 | tubo | 3 |
| 6828 | tronado | 3 |
| 6829 | tronada | 3 |
| 6830 | trompa | 3 |
| 6831 | tristón | 3 |
| 6832 | trigo | 3 |
| 6833 | tremenda | 3 |
| 6834 | trece | 3 |
| 6835 | traza | 3 |
| 6836 | trasladarse | 3 |
| 6837 | trasladar | 3 |
| 6838 | trasladado | 3 |
| 6839 | transtiberina | 3 |
| 6840 | transparentes | 3 |
| 6841 | transformó | 3 |
| 6842 | transformada | 3 |
| 6843 | transformaba | 3 |
| 6844 | tranquilizarse | 3 |
| 6845 | tralla | 3 |
| 6846 | trajeron | 3 |
| 6847 | traidor | 3 |
| 6848 | traiciones | 3 |
| 6849 | tragó | 3 |
| 6850 | trágicas | 3 |
| 6851 | tragaba | 3 |
| 6852 | tráfico | 3 |
| 6853 | traen | 3 |
| 6854 | tradicional | 3 |
| 6855 | trabajando | 3 |
| 6856 | trabajado | 3 |
| 6857 | trabaja | 3 |
| 6858 | tosía | 3 |
| 6859 | toses | 3 |
| 6860 | tosco | 3 |
| 6861 | tos | 3 |
| 6862 | tortura | 3 |
| 6863 | tortuga | 3 |
| 6864 | tórtolas | 3 |
| 6865 | torres | 3 |
| 6866 | torrentes | 3 |
| 6867 | toros | 3 |
| 6868 | torno | 3 |
| 6869 | torneado | 3 |
| 6870 | torcer | 3 |
| 6871 | tomarse | 3 |
| 6872 | tomaron | 3 |
| 6873 | tomaría | 3 |
| 6874 | toman | 3 |
| 6875 | toleraba | 3 |
| 6876 | toledo | 3 |
| 6877 | todd | 3 |
| 6878 | tocante | 3 |
| 6879 | tocan | 3 |
| 6880 | tirso | 3 |
| 6881 | tires | 3 |
| 6882 | tirando | 3 |
| 6883 | tiran | 3 |
| 6884 | tirada | 3 |
| 6885 | tiraba | 3 |
| 6886 | tira | 3 |
| 6887 | tiestos | 3 |
| 6888 | tieso | 3 |
| 6889 | tiernos | 3 |
| 6890 | tibio | 3 |
| 6891 | tiara | 3 |
| 6892 | texto | 3 |
| 6893 | testero | 3 |
| 6894 | tesón | 3 |
| 6895 | terrones | 3 |
| 6896 | terminado | 3 |
| 6897 | termasaltas | 3 |
| 6898 | terco | 3 |
| 6899 | terciando | 3 |
| 6900 | teológico | 3 |
| 6901 | teñía | 3 |
| 6902 | tentativas | 3 |
| 6903 | tensión | 3 |
| 6904 | tenerlo | 3 |
| 6905 | teneatis | 3 |
| 6906 | tendré | 3 |
| 6907 | tendero | 3 |
| 6908 | temperamentos | 3 |
| 6909 | temores | 3 |
| 6910 | teme | 3 |
| 6911 | temblona | 3 |
| 6912 | telar | 3 |
| 6913 | tejas | 3 |
| 6914 | tapada | 3 |
| 6915 | tapabocas | 3 |
| 6916 | tapa | 3 |
| 6917 | tambaleaba | 3 |
| 6918 | taller | 3 |
| 6919 | tálamo | 3 |
| 6920 | tajadas | 3 |
| 6921 | tacos | 3 |
| 6922 | taciturna | 3 |
| 6923 | taburetes | 3 |
| 6924 | taberneros | 3 |
| 6925 | suspirar | 3 |
| 6926 | suspiraban | 3 |
| 6927 | suspira | 3 |
| 6928 | suspendió | 3 |
| 6929 | suspendieron | 3 |
| 6930 | suspender | 3 |
| 6931 | supuestos | 3 |
| 6932 | supremos | 3 |
| 6933 | suplicante | 3 |
| 6934 | supieran | 3 |
| 6935 | supersticiosamente | 3 |
| 6936 | supersticiosa | 3 |
| 6937 | superiores | 3 |
| 6938 | sumida | 3 |
| 6939 | suicidio | 3 |
| 6940 | sugerido | 3 |
| 6941 | suficientes | 3 |
| 6942 | suelas | 3 |
| 6943 | sudaban | 3 |
| 6944 | sucumbir | 3 |
| 6945 | sucios | 3 |
| 6946 | sucesor | 3 |
| 6947 | sucedió | 3 |
| 6948 | subrepticia | 3 |
| 6949 | subieron | 3 |
| 6950 | stabat | 3 |
| 6951 | spirto | 3 |
| 6952 | sostenida | 3 |
| 6953 | sostenían | 3 |
| 6954 | sospechosas | 3 |
| 6955 | sospeche | 3 |
| 6956 | sospechase | 3 |
| 6957 | sospecharlo | 3 |
| 6958 | sospechara | 3 |
| 6959 | sospechaban | 3 |
| 6960 | sosos | 3 |
| 6961 | sordos | 3 |
| 6962 | soporífero | 3 |
| 6963 | soplando | 3 |
| 6964 | soñó | 3 |
| 6965 | soñadora | 3 |
| 6966 | sonrosado | 3 |
| 6967 | sonrosada | 3 |
| 6968 | sonrieron | 3 |
| 6969 | sonríe | 3 |
| 6970 | sonora | 3 |
| 6971 | sonado | 3 |
| 6972 | sombría | 3 |
| 6973 | solidez | 3 |
| 6974 | soles | 3 |
| 6975 | soledades | 3 |
| 6976 | soldados | 3 |
| 6977 | soldado | 3 |
| 6978 | sojuzgada | 3 |
| 6979 | socorro | 3 |
| 6980 | sociedades | 3 |
| 6981 | socialista | 3 |
| 6982 | sobriedad | 3 |
| 6983 | sobra | 3 |
| 6984 | sitios | 3 |
| 6985 | sinodal | 3 |
| 6986 | sine | 3 |
| 6987 | sincero | 3 |
| 6988 | simpática | 3 |
| 6989 | siluetas | 3 |
| 6990 | silueta | 3 |
| 6991 | silbido | 3 |
| 6992 | sílabas | 3 |
| 6993 | sigo | 3 |
| 6994 | sietemesino | 3 |
| 6995 | sidra | 3 |
| 6996 | sexos | 3 |
| 6997 | sevilla | 3 |
| 6998 | setenta | 3 |
| 6999 | serenidad | 3 |
| 7000 | sepulcro | 3 |
| 7001 | separaron | 3 |
| 7002 | separarnos | 3 |
| 7003 | separándose | 3 |
| 7004 | separada | 3 |
| 7005 | separación | 3 |
| 7006 | separa | 3 |
| 7007 | sentiría | 3 |
| 7008 | sentencias | 3 |
| 7009 | sentencia | 3 |
| 7010 | sentaron | 3 |
| 7011 | sentar | 3 |
| 7012 | sentados | 3 |
| 7013 | sensual | 3 |
| 7014 | sensible | 3 |
| 7015 | sencillas | 3 |
| 7016 | seminarista | 3 |
| 7017 | semilla | 3 |
| 7018 | semejaba | 3 |
| 7019 | seguros | 3 |
| 7020 | seguidas | 3 |
| 7021 | segismundo | 3 |
| 7022 | seducirle | 3 |
| 7023 | secularizar | 3 |
| 7024 | sectario | 3 |
| 7025 | sean | 3 |
| 7026 | saya | 3 |
| 7027 | savia | 3 |
| 7028 | satisfechas | 3 |
| 7029 | satisfacía | 3 |
| 7030 | sardinas | 3 |
| 7031 | santiguarse | 3 |
| 7032 | sandio | 3 |
| 7033 | sandeces | 3 |
| 7034 | salvajes | 3 |
| 7035 | saludos | 3 |
| 7036 | salta | 3 |
| 7037 | salpicaba | 3 |
| 7038 | saliva | 3 |
| 7039 | salacia | 3 |
| 7040 | sagrados | 3 |
| 7041 | sagacidad | 3 |
| 7042 | sacrílegos | 3 |
| 7043 | sacrílega | 3 |
| 7044 | sacrificado | 3 |
| 7045 | sacarla | 3 |
| 7046 | sacando | 3 |
| 7047 | sacan | 3 |
| 7048 | sabrosos | 3 |
| 7049 | sabrosa | 3 |
| 7050 | sábado | 3 |
| 7051 | rústica | 3 |
| 7052 | rusia | 3 |
| 7053 | rurales | 3 |
| 7054 | rumbo | 3 |
| 7055 | ruiseñor | 3 |
| 7056 | ruines | 3 |
| 7057 | ruin | 3 |
| 7058 | ruborizó | 3 |
| 7059 | ruborizarse | 3 |
| 7060 | rubios | 3 |
| 7061 | rota | 3 |
| 7062 | rossini | 3 |
| 7063 | rosina | 3 |
| 7064 | rosetones | 3 |
| 7065 | rosada | 3 |
| 7066 | roque | 3 |
| 7067 | rompimiento | 3 |
| 7068 | rompiendo | 3 |
| 7069 | romero | 3 |
| 7070 | románticos | 3 |
| 7071 | romano | 3 |
| 7072 | rodrigo | 3 |
| 7073 | rodearon | 3 |
| 7074 | rodean | 3 |
| 7075 | rodea | 3 |
| 7076 | rocín | 3 |
| 7077 | roba | 3 |
| 7078 | risum | 3 |
| 7079 | risueño | 3 |
| 7080 | ríos | 3 |
| 7081 | riñón | 3 |
| 7082 | riéndose | 3 |
| 7083 | ribeteadoras | 3 |
| 7084 | ríase | 3 |
| 7085 | rezó | 3 |
| 7086 | reyerta | 3 |
| 7087 | revolver | 3 |
| 7088 | revelar | 3 |
| 7089 | revelaban | 3 |
| 7090 | revelaba | 3 |
| 7091 | reunir | 3 |
| 7092 | reuniones | 3 |
| 7093 | reunido | 3 |
| 7094 | retumbar | 3 |
| 7095 | retrocedía | 3 |
| 7096 | retorcía | 3 |
| 7097 | retoños | 3 |
| 7098 | retiraba | 3 |
| 7099 | reticencias | 3 |
| 7100 | resumidas | 3 |
| 7101 | resultó | 3 |
| 7102 | resulta | 3 |
| 7103 | resuelve | 3 |
| 7104 | resucitar | 3 |
| 7105 | resquicios | 3 |
| 7106 | respondo | 3 |
| 7107 | resplandores | 3 |
| 7108 | respiro | 3 |
| 7109 | respetando | 3 |
| 7110 | respetada | 3 |
| 7111 | resonantes | 3 |
| 7112 | resignado | 3 |
| 7113 | resignada | 3 |
| 7114 | reservas | 3 |
| 7115 | reservaba | 3 |
| 7116 | reseco | 3 |
| 7117 | resbalar | 3 |
| 7118 | resbalando | 3 |
| 7119 | reputó | 3 |
| 7120 | repuso | 3 |
| 7121 | republicano | 3 |
| 7122 | reprensible | 3 |
| 7123 | repleto | 3 |
| 7124 | repito | 3 |
| 7125 | repite | 3 |
| 7126 | repetidos | 3 |
| 7127 | repentino | 3 |
| 7128 | repentinas | 3 |
| 7129 | repasando | 3 |
| 7130 | reparte | 3 |
| 7131 | reparo | 3 |
| 7132 | reparado | 3 |
| 7133 | reparación | 3 |
| 7134 | renegaba | 3 |
| 7135 | rendición | 3 |
| 7136 | rendía | 3 |
| 7137 | renan | 3 |
| 7138 | renacía | 3 |
| 7139 | remontaba | 3 |
| 7140 | remolinos | 3 |
| 7141 | remiendos | 3 |
| 7142 | relucir | 3 |
| 7143 | relucía | 3 |
| 7144 | reliquias | 3 |
| 7145 | relieve | 3 |
| 7146 | relativas | 3 |
| 7147 | relativa | 3 |
| 7148 | reído | 3 |
| 7149 | registros | 3 |
| 7150 | regañadientes | 3 |
| 7151 | regalista | 3 |
| 7152 | regalar | 3 |
| 7153 | refuerzo | 3 |
| 7154 | reflejo | 3 |
| 7155 | reflejando | 3 |
| 7156 | refleja | 3 |
| 7157 | refinado | 3 |
| 7158 | referían | 3 |
| 7159 | redomado | 3 |
| 7160 | rediós | 3 |
| 7161 | redes | 3 |
| 7162 | red | 3 |
| 7163 | recurso | 3 |
| 7164 | recurrir | 3 |
| 7165 | recurría | 3 |
| 7166 | recorrido | 3 |
| 7167 | recordándole | 3 |
| 7168 | reconocían | 3 |
| 7169 | reconocerlo | 3 |
| 7170 | recompensa | 3 |
| 7171 | recogerla | 3 |
| 7172 | recobrado | 3 |
| 7173 | recluta | 3 |
| 7174 | reclamar | 3 |
| 7175 | reclamaba | 3 |
| 7176 | recios | 3 |
| 7177 | rechazaba | 3 |
| 7178 | recato | 3 |
| 7179 | reasumiendo | 3 |
| 7180 | realizado | 3 |
| 7181 | rayas | 3 |
| 7182 | ratones | 3 |
| 7183 | rastro | 3 |
| 7184 | rasgó | 3 |
| 7185 | rasgar | 3 |
| 7186 | rasgaban | 3 |
| 7187 | rasero | 3 |
| 7188 | raras | 3 |
| 7189 | ráfagas | 3 |
| 7190 | racimo | 3 |
| 7191 | quitó | 3 |
| 7192 | quitarle | 3 |
| 7193 | quisiese | 3 |
| 7194 | quise | 3 |
| 7195 | quintana | 3 |
| 7196 | quincalla | 3 |
| 7197 | quieras | 3 |
| 7198 | quererla | 3 |
| 7199 | quemar | 3 |
| 7200 | quedaría | 3 |
| 7201 | quedamos | 3 |
| 7202 | quebrantada | 3 |
| 7203 | pusiera | 3 |
| 7204 | purgatorio | 3 |
| 7205 | purga | 3 |
| 7206 | pupitre | 3 |
| 7207 | puñadas | 3 |
| 7208 | punzadas | 3 |
| 7209 | puntería | 3 |
| 7210 | puntapiés | 3 |
| 7211 | pulmones | 3 |
| 7212 | pullas | 3 |
| 7213 | puf | 3 |
| 7214 | puestos | 3 |
| 7215 | puedan | 3 |
| 7216 | publicó | 3 |
| 7217 | públicas | 3 |
| 7218 | prudentes | 3 |
| 7219 | provocada | 3 |
| 7220 | provinciano | 3 |
| 7221 | providencial | 3 |
| 7222 | protestar | 3 |
| 7223 | protectora | 3 |
| 7224 | proscenio | 3 |
| 7225 | propasarse | 3 |
| 7226 | prolongaba | 3 |
| 7227 | prólogo | 3 |
| 7228 | prohibir | 3 |
| 7229 | prohibición | 3 |
| 7230 | progresista | 3 |
| 7231 | profundas | 3 |
| 7232 | profanar | 3 |
| 7233 | profanado | 3 |
| 7234 | profanaciones | 3 |
| 7235 | profana | 3 |
| 7236 | produjo | 3 |
| 7237 | pródigo | 3 |
| 7238 | prodigio | 3 |
| 7239 | prodigar | 3 |
| 7240 | procurase | 3 |
| 7241 | procurador | 3 |
| 7242 | procedía | 3 |
| 7243 | probó | 3 |
| 7244 | probaba | 3 |
| 7245 | privilegio | 3 |
| 7246 | primores | 3 |
| 7247 | primogénito | 3 |
| 7248 | primitivo | 3 |
| 7249 | presumir | 3 |
| 7250 | presumía | 3 |
| 7251 | presidir | 3 |
| 7252 | presidiendo | 3 |
| 7253 | presidida | 3 |
| 7254 | presidía | 3 |
| 7255 | presenciar | 3 |
| 7256 | prepararle | 3 |
| 7257 | preocupados | 3 |
| 7258 | prender | 3 |
| 7259 | prematura | 3 |
| 7260 | preliminares | 3 |
| 7261 | preguntaron | 3 |
| 7262 | preguntado | 3 |
| 7263 | predominaba | 3 |
| 7264 | predilecto | 3 |
| 7265 | predilección | 3 |
| 7266 | predicar | 3 |
| 7267 | precoz | 3 |
| 7268 | praxíteles | 3 |
| 7269 | praderas | 3 |
| 7270 | práctico | 3 |
| 7271 | postres | 3 |
| 7272 | postergado | 3 |
| 7273 | positivismo | 3 |
| 7274 | positivamente | 3 |
| 7275 | posibles | 3 |
| 7276 | posesión | 3 |
| 7277 | pos | 3 |
| 7278 | porteros | 3 |
| 7279 | portero | 3 |
| 7280 | portentos | 3 |
| 7281 | pordiosero | 3 |
| 7282 | poquito | 3 |
| 7283 | poniente | 3 |
| 7284 | pones | 3 |
| 7285 | ponen | 3 |
| 7286 | pondría | 3 |
| 7287 | pompadour | 3 |
| 7288 | pomaradas | 3 |
| 7289 | pólvora | 3 |
| 7290 | pollastres | 3 |
| 7291 | políticos | 3 |
| 7292 | poetisa | 3 |
| 7293 | poesías | 3 |
| 7294 | poemas | 3 |
| 7295 | podremos | 3 |
| 7296 | poderosas | 3 |
| 7297 | poderío | 3 |
| 7298 | pocilga | 3 |
| 7299 | pobrecitos | 3 |
| 7300 | poblados | 3 |
| 7301 | pluviales | 3 |
| 7302 | plumero | 3 |
| 7303 | pliegos | 3 |
| 7304 | pliego | 3 |
| 7305 | plazuelas | 3 |
| 7306 | playa | 3 |
| 7307 | pláticas | 3 |
| 7308 | plateresco | 3 |
| 7309 | plateas | 3 |
| 7310 | plantado | 3 |
| 7311 | planchadora | 3 |
| 7312 | plácida | 3 |
| 7313 | pitillo | 3 |
| 7314 | pisos | 3 |
| 7315 | pisadas | 3 |
| 7316 | pintó | 3 |
| 7317 | pinta | 3 |
| 7318 | piezas | 3 |
| 7319 | pieza | 3 |
| 7320 | pierden | 3 |
| 7321 | piense | 3 |
| 7322 | pidiendo | 3 |
| 7323 | picardía | 3 |
| 7324 | picantes | 3 |
| 7325 | petit | 3 |
| 7326 | petimetre | 3 |
| 7327 | pestillo | 3 |
| 7328 | pestes | 3 |
| 7329 | peste | 3 |
| 7330 | pesebre | 3 |
| 7331 | pese | 3 |
| 7332 | pescar | 3 |
| 7333 | pesca | 3 |
| 7334 | pesadumbre | 3 |
| 7335 | pesa | 3 |
| 7336 | pertenecía | 3 |
| 7337 | perspicacia | 3 |
| 7338 | perseverancia | 3 |
| 7339 | perrero | 3 |
| 7340 | perpendicular | 3 |
| 7341 | perniciosa | 3 |
| 7342 | permitirle | 3 |
| 7343 | permitió | 3 |
| 7344 | permaneció | 3 |
| 7345 | perlas | 3 |
| 7346 | perífrasis | 3 |
| 7347 | perezosos | 3 |
| 7348 | perezosas | 3 |
| 7349 | perenne | 3 |
| 7350 | perdonó | 3 |
| 7351 | perdone | 3 |
| 7352 | perderme | 3 |
| 7353 | pequeñeces | 3 |
| 7354 | pepita | 3 |
| 7355 | pensativo | 3 |
| 7356 | pensará | 3 |
| 7357 | pensara | 3 |
| 7358 | penosa | 3 |
| 7359 | penetraban | 3 |
| 7360 | pelos | 3 |
| 7361 | pellizcos | 3 |
| 7362 | pellizcaba | 3 |
| 7363 | pellejos | 3 |
| 7364 | pelado | 3 |
| 7365 | pegajoso | 3 |
| 7366 | pegaba | 3 |
| 7367 | pedacitos | 3 |
| 7368 | peculiar | 3 |
| 7369 | pecaminosa | 3 |
| 7370 | pecadillos | 3 |
| 7371 | pecaba | 3 |
| 7372 | paúl | 3 |
| 7373 | patriotismo | 3 |
| 7374 | patos | 3 |
| 7375 | patéticos | 3 |
| 7376 | pasta | 3 |
| 7377 | pasmosa | 3 |
| 7378 | pasmados | 3 |
| 7379 | paseándose | 3 |
| 7380 | paseado | 3 |
| 7381 | pasatiempo | 3 |
| 7382 | pasase | 3 |
| 7383 | pasarse | 3 |
| 7384 | pasajera | 3 |
| 7385 | pasados | 3 |
| 7386 | pasadizo | 3 |
| 7387 | pasadas | 3 |
| 7388 | partidos | 3 |
| 7389 | partidas | 3 |
| 7390 | participaban | 3 |
| 7391 | parterres | 3 |
| 7392 | parroquiano | 3 |
| 7393 | parecidas | 3 |
| 7394 | paralelas | 3 |
| 7395 | parada | 3 |
| 7396 | parábolas | 3 |
| 7397 | panurgo | 3 |
| 7398 | panteón | 3 |
| 7399 | panteísmo | 3 |
| 7400 | palpitaba | 3 |
| 7401 | palmas | 3 |
| 7402 | palmaditas | 3 |
| 7403 | palmadita | 3 |
| 7404 | palidecía | 3 |
| 7405 | palabreja | 3 |
| 7406 | pague | 3 |
| 7407 | pagarle | 3 |
| 7408 | pagaría | 3 |
| 7409 | pagano | 3 |
| 7410 | pagana | 3 |
| 7411 | paces | 3 |
| 7412 | paca | 3 |
| 7413 | pabellón | 3 |
| 7414 | otorgó | 3 |
| 7415 | ostentoso | 3 |
| 7416 | ostentosa | 3 |
| 7417 | ostentar | 3 |
| 7418 | ortografía | 3 |
| 7419 | orla | 3 |
| 7420 | originalidad | 3 |
| 7421 | órganos | 3 |
| 7422 | ordalías | 3 |
| 7423 | oratoria | 3 |
| 7424 | oradores | 3 |
| 7425 | oprimió | 3 |
| 7426 | oponía | 3 |
| 7427 | oponer | 3 |
| 7428 | opone | 3 |
| 7429 | opio | 3 |
| 7430 | opinaban | 3 |
| 7431 | operación | 3 |
| 7432 | ondulantes | 3 |
| 7433 | ondulante | 3 |
| 7434 | olvidito | 3 |
| 7435 | olvidando | 3 |
| 7436 | olvidados | 3 |
| 7437 | olvidaban | 3 |
| 7438 | oliendo | 3 |
| 7439 | olfatear | 3 |
| 7440 | olfateaba | 3 |
| 7441 | oler | 3 |
| 7442 | ojuelos | 3 |
| 7443 | ojeriza | 3 |
| 7444 | ojalá | 3 |
| 7445 | oidor | 3 |
| 7446 | ofreciendo | 3 |
| 7447 | odiosos | 3 |
| 7448 | odioso | 3 |
| 7449 | odiosa | 3 |
| 7450 | ocurrían | 3 |
| 7451 | ocurre | 3 |
| 7452 | ocupó | 3 |
| 7453 | ocupado | 3 |
| 7454 | ocultó | 3 |
| 7455 | ocultándose | 3 |
| 7456 | ociosas | 3 |
| 7457 | ocio | 3 |
| 7458 | obstina | 3 |
| 7459 | observaciones | 3 |
| 7460 | obscurecía | 3 |
| 7461 | obrar | 3 |
| 7462 | obligar | 3 |
| 7463 | obligados | 3 |
| 7464 | obligada | 3 |
| 7465 | obligaban | 3 |
| 7466 | objeciones | 3 |
| 7467 | obediencia | 3 |
| 7468 | obedezco | 3 |
| 7469 | numerosos | 3 |
| 7470 | números | 3 |
| 7471 | núcleo | 3 |
| 7472 | notarlo | 3 |
| 7473 | notables | 3 |
| 7474 | nota | 3 |
| 7475 | nono | 3 |
| 7476 | nombraba | 3 |
| 7477 | nocturnos | 3 |
| 7478 | nocturna | 3 |
| 7479 | nilo | 3 |
| 7480 | neutral | 3 |
| 7481 | negaban | 3 |
| 7482 | necesitas | 3 |
| 7483 | necesitar | 3 |
| 7484 | necesitamos | 3 |
| 7485 | necesidades | 3 |
| 7486 | necesarios | 3 |
| 7487 | necesariamente | 3 |
| 7488 | navajas | 3 |
| 7489 | naturalmente | 3 |
| 7490 | narrativa | 3 |
| 7491 | narración | 3 |
| 7492 | narraba | 3 |
| 7493 | nacionales | 3 |
| 7494 | nace | 3 |
| 7495 | mutuamente | 3 |
| 7496 | musical | 3 |
| 7497 | muñecas | 3 |
| 7498 | municipal | 3 |
| 7499 | mundanal | 3 |
| 7500 | multiplicaba | 3 |
| 7501 | mula | 3 |
| 7502 | mueve | 3 |
| 7503 | mueva | 3 |
| 7504 | muestras | 3 |
| 7505 | mudos | 3 |
| 7506 | mortuoria | 3 |
| 7507 | mortificaban | 3 |
| 7508 | mortificaba | 3 |
| 7509 | moribunda | 3 |
| 7510 | mordido | 3 |
| 7511 | morder | 3 |
| 7512 | monumentos | 3 |
| 7513 | monumento | 3 |
| 7514 | monumentales | 3 |
| 7515 | montones | 3 |
| 7516 | montico | 3 |
| 7517 | montera | 3 |
| 7518 | montaraces | 3 |
| 7519 | monstruos | 3 |
| 7520 | monstruo | 3 |
| 7521 | monótonas | 3 |
| 7522 | monosílabos | 3 |
| 7523 | monopolio | 3 |
| 7524 | móndame | 3 |
| 7525 | monaguillos | 3 |
| 7526 | molinero | 3 |
| 7527 | molesto | 3 |
| 7528 | mojada | 3 |
| 7529 | mojaba | 3 |
| 7530 | moderno | 3 |
| 7531 | modas | 3 |
| 7532 | modales | 3 |
| 7533 | mitrado | 3 |
| 7534 | misteriosamente | 3 |
| 7535 | miserere | 3 |
| 7536 | miren | 3 |
| 7537 | mirase | 3 |
| 7538 | miras | 3 |
| 7539 | mirarse | 3 |
| 7540 | miran | 3 |
| 7541 | ministros | 3 |
| 7542 | mineros | 3 |
| 7543 | millares | 3 |
| 7544 | milagroso | 3 |
| 7545 | milagrosa | 3 |
| 7546 | migas | 3 |
| 7547 | miga | 3 |
| 7548 | miembros | 3 |
| 7549 | miembro | 3 |
| 7550 | midió | 3 |
| 7551 | miasmas | 3 |
| 7552 | mezquino | 3 |
| 7553 | mezclando | 3 |
| 7554 | mezcladas | 3 |
| 7555 | metrópoli | 3 |
| 7556 | meter | 3 |
| 7557 | meseta | 3 |
| 7558 | méritos | 3 |
| 7559 | mereciera | 3 |
| 7560 | merecían | 3 |
| 7561 | mercantil | 3 |
| 7562 | mercader | 3 |
| 7563 | menudos | 3 |
| 7564 | mental | 3 |
| 7565 | mensuales | 3 |
| 7566 | menester | 3 |
| 7567 | memorable | 3 |
| 7568 | melunga | 3 |
| 7569 | melancólicos | 3 |
| 7570 | melancólicas | 3 |
| 7571 | mejoría | 3 |
| 7572 | mejía | 3 |
| 7573 | medir | 3 |
| 7574 | mediocritas | 3 |
| 7575 | medían | 3 |
| 7576 | mediaba | 3 |
| 7577 | máxima | 3 |
| 7578 | matorral | 3 |
| 7579 | mater | 3 |
| 7580 | matemáticas | 3 |
| 7581 | masón | 3 |
| 7582 | martínez | 3 |
| 7583 | martín | 3 |
| 7584 | marineros | 3 |
| 7585 | mari | 3 |
| 7586 | marear | 3 |
| 7587 | marcos | 3 |
| 7588 | marchó | 3 |
| 7589 | maña | 3 |
| 7590 | manzanas | 3 |
| 7591 | mantenían | 3 |
| 7592 | mantenerse | 3 |
| 7593 | manta | 3 |
| 7594 | manosear | 3 |
| 7595 | manoseadas | 3 |
| 7596 | manolillo | 3 |
| 7597 | manjares | 3 |
| 7598 | maniquí | 3 |
| 7599 | manejar | 3 |
| 7600 | mande | 3 |
| 7601 | mandarle | 3 |
| 7602 | mandaría | 3 |
| 7603 | manchaba | 3 |
| 7604 | malvado | 3 |
| 7605 | maligna | 3 |
| 7606 | malhaya | 3 |
| 7607 | malagueñas | 3 |
| 7608 | majestuosa | 3 |
| 7609 | majaderos | 3 |
| 7610 | magnate | 3 |
| 7611 | maestros | 3 |
| 7612 | maestría | 3 |
| 7613 | maduro | 3 |
| 7614 | madrugada | 3 |
| 7615 | madreselva | 3 |
| 7616 | madres | 3 |
| 7617 | madero | 3 |
| 7618 | maderas | 3 |
| 7619 | m | 3 |
| 7620 | luminosa | 3 |
| 7621 | lumbrera | 3 |
| 7622 | lujosa | 3 |
| 7623 | lúgubre | 3 |
| 7624 | ludibrio | 3 |
| 7625 | lucir | 3 |
| 7626 | lucido | 3 |
| 7627 | lucían | 3 |
| 7628 | luchando | 3 |
| 7629 | lozana | 3 |
| 7630 | lomas | 3 |
| 7631 | lola | 3 |
| 7632 | logró | 3 |
| 7633 | lodazal | 3 |
| 7634 | locuaz | 3 |
| 7635 | lluvias | 3 |
| 7636 | lloro | 3 |
| 7637 | llorado | 3 |
| 7638 | lloraban | 3 |
| 7639 | lleven | 3 |
| 7640 | llevársela | 3 |
| 7641 | llenarse | 3 |
| 7642 | llenan | 3 |
| 7643 | llegada | 3 |
| 7644 | llamasen | 3 |
| 7645 | llamándole | 3 |
| 7646 | llamando | 3 |
| 7647 | lívido | 3 |
| 7648 | liviandad | 3 |
| 7649 | literario | 3 |
| 7650 | lisonjeras | 3 |
| 7651 | líquidos | 3 |
| 7652 | límite | 3 |
| 7653 | ligeras | 3 |
| 7654 | lid | 3 |
| 7655 | licencias | 3 |
| 7656 | libaciones | 3 |
| 7657 | leyera | 3 |
| 7658 | lejanas | 3 |
| 7659 | lealtad | 3 |
| 7660 | lavar | 3 |
| 7661 | lavándose | 3 |
| 7662 | lavado | 3 |
| 7663 | lavabo | 3 |
| 7664 | latina | 3 |
| 7665 | lascivo | 3 |
| 7666 | lasciami | 3 |
| 7667 | lapsus | 3 |
| 7668 | lanas | 3 |
| 7669 | lamentos | 3 |
| 7670 | laderas | 3 |
| 7671 | l | 3 |
| 7672 | juzga | 3 |
| 7673 | justos | 3 |
| 7674 | justamente | 3 |
| 7675 | jurisconsulto | 3 |
| 7676 | juntarse | 3 |
| 7677 | julio | 3 |
| 7678 | juguetes | 3 |
| 7679 | juguete | 3 |
| 7680 | juega | 3 |
| 7681 | jubilación | 3 |
| 7682 | jovial | 3 |
| 7683 | josé | 3 |
| 7684 | jorge | 3 |
| 7685 | job | 3 |
| 7686 | jipijapa | 3 |
| 7687 | jamona | 3 |
| 7688 | jadeante | 3 |
| 7689 | jactarse | 3 |
| 7690 | irritaban | 3 |
| 7691 | irreverencia | 3 |
| 7692 | irracional | 3 |
| 7693 | irónica | 3 |
| 7694 | irme | 3 |
| 7695 | iris | 3 |
| 7696 | inventos | 3 |
| 7697 | intriga | 3 |
| 7698 | intratable | 3 |
| 7699 | intervenir | 3 |
| 7700 | intervalos | 3 |
| 7701 | intersticio | 3 |
| 7702 | intermitencias | 3 |
| 7703 | interminables | 3 |
| 7704 | interminable | 3 |
| 7705 | interesa | 3 |
| 7706 | intento | 3 |
| 7707 | intemperie | 3 |
| 7708 | instalado | 3 |
| 7709 | inspirado | 3 |
| 7710 | insolentes | 3 |
| 7711 | insisto | 3 |
| 7712 | inquisidor | 3 |
| 7713 | inquietos | 3 |
| 7714 | inquieto | 3 |
| 7715 | inquebrantable | 3 |
| 7716 | inoportuno | 3 |
| 7717 | innominada | 3 |
| 7718 | inmundicia | 3 |
| 7719 | inmortalidad | 3 |
| 7720 | inmoral | 3 |
| 7721 | inmenso | 3 |
| 7722 | inmediata | 3 |
| 7723 | injuria | 3 |
| 7724 | ingeniero | 3 |
| 7725 | infinitamente | 3 |
| 7726 | infamia | 3 |
| 7727 | inexorable | 3 |
| 7728 | inepto | 3 |
| 7729 | indulgente | 3 |
| 7730 | indudable | 3 |
| 7731 | índole | 3 |
| 7732 | indiscreto | 3 |
| 7733 | indignidad | 3 |
| 7734 | indiferente | 3 |
| 7735 | indicar | 3 |
| 7736 | indicaba | 3 |
| 7737 | indias | 3 |
| 7738 | indiano | 3 |
| 7739 | independencia | 3 |
| 7740 | incurable | 3 |
| 7741 | incorporarse | 3 |
| 7742 | incómoda | 3 |
| 7743 | incipiente | 3 |
| 7744 | incidentes | 3 |
| 7745 | incansable | 3 |
| 7746 | impuro | 3 |
| 7747 | imprudentes | 3 |
| 7748 | impropio | 3 |
| 7749 | improper | 3 |
| 7750 | imprenta | 3 |
| 7751 | imposiciones | 3 |
| 7752 | imposibles | 3 |
| 7753 | importunos | 3 |
| 7754 | importuna | 3 |
| 7755 | ímpetu | 3 |
| 7756 | imperiosa | 3 |
| 7757 | imperdonable | 3 |
| 7758 | impasible | 3 |
| 7759 | impacientaba | 3 |
| 7760 | imitando | 3 |
| 7761 | imitaciones | 3 |
| 7762 | imaginaria | 3 |
| 7763 | ilustrado | 3 |
| 7764 | ilustraciones | 3 |
| 7765 | ilustración | 3 |
| 7766 | ilusión | 3 |
| 7767 | ilegítimos | 3 |
| 7768 | ignominioso | 3 |
| 7769 | ignominia | 3 |
| 7770 | ídolos | 3 |
| 7771 | idioma | 3 |
| 7772 | huraña | 3 |
| 7773 | huracanes | 3 |
| 7774 | hundir | 3 |
| 7775 | humorismo | 3 |
| 7776 | humores | 3 |
| 7777 | humillarse | 3 |
| 7778 | humildemente | 3 |
| 7779 | húmedos | 3 |
| 7780 | húmedo | 3 |
| 7781 | huellas | 3 |
| 7782 | hotel | 3 |
| 7783 | horrorizado | 3 |
| 7784 | horca | 3 |
| 7785 | honrados | 3 |
| 7786 | honesta | 3 |
| 7787 | hondonada | 3 |
| 7788 | holocausto | 3 |
| 7789 | hojuelas | 3 |
| 7790 | hipógrifo | 3 |
| 7791 | hipocritona | 3 |
| 7792 | hipócrates | 3 |
| 7793 | hijita | 3 |
| 7794 | higiénico | 3 |
| 7795 | higiénicas | 3 |
| 7796 | hiciese | 3 |
| 7797 | híbrido | 3 |
| 7798 | heroínas | 3 |
| 7799 | herir | 3 |
| 7800 | heredada | 3 |
| 7801 | helechos | 3 |
| 7802 | helada | 3 |
| 7803 | hebilla | 3 |
| 7804 | harían | 3 |
| 7805 | halló | 3 |
| 7806 | halagos | 3 |
| 7807 | hagas | 3 |
| 7808 | hagan | 3 |
| 7809 | hagamos | 3 |
| 7810 | haciéndole | 3 |
| 7811 | hacerles | 3 |
| 7812 | habrían | 3 |
| 7813 | habrás | 3 |
| 7814 | hablarla | 3 |
| 7815 | hablará | 3 |
| 7816 | habituales | 3 |
| 7817 | habitual | 3 |
| 7818 | habitantes | 3 |
| 7819 | habilidades | 3 |
| 7820 | habías | 3 |
| 7821 | habíale | 3 |
| 7822 | gusanos | 3 |
| 7823 | guijarros | 3 |
| 7824 | guiaba | 3 |
| 7825 | guardar | 3 |
| 7826 | guapísima | 3 |
| 7827 | gruñir | 3 |
| 7828 | gruñía | 3 |
| 7829 | grueso | 3 |
| 7830 | grotesco | 3 |
| 7831 | grietas | 3 |
| 7832 | gramática | 3 |
| 7833 | gozoso | 3 |
| 7834 | gótica | 3 |
| 7835 | goteras | 3 |
| 7836 | gorda | 3 |
| 7837 | góndola | 3 |
| 7838 | goma | 3 |
| 7839 | golpecitos | 3 |
| 7840 | goce | 3 |
| 7841 | gobernar | 3 |
| 7842 | goberna | 3 |
| 7843 | glorioso | 3 |
| 7844 | globulus | 3 |
| 7845 | genuflexión | 3 |
| 7846 | géneros | 3 |
| 7847 | generalizada | 3 |
| 7848 | generación | 3 |
| 7849 | gaudeamus | 3 |
| 7850 | gata | 3 |
| 7851 | gastos | 3 |
| 7852 | gárrulo | 3 |
| 7853 | garbo | 3 |
| 7854 | garbanzos | 3 |
| 7855 | garantía | 3 |
| 7856 | ganó | 3 |
| 7857 | gangosa | 3 |
| 7858 | ganando | 3 |
| 7859 | ganan | 3 |
| 7860 | gallina | 3 |
| 7861 | gallarda | 3 |
| 7862 | gafas | 3 |
| 7863 | gacetillero | 3 |
| 7864 | gabinetes | 3 |
| 7865 | fundado | 3 |
| 7866 | funda | 3 |
| 7867 | fulgencia | 3 |
| 7868 | fueras | 3 |
| 7869 | frívolo | 3 |
| 7870 | frenesí | 3 |
| 7871 | frecuentar | 3 |
| 7872 | fraternidad | 3 |
| 7873 | frasco | 3 |
| 7874 | franjas | 3 |
| 7875 | franja | 3 |
| 7876 | franela | 3 |
| 7877 | franceses | 3 |
| 7878 | frágil | 3 |
| 7879 | forzosa | 3 |
| 7880 | formidables | 3 |
| 7881 | formar | 3 |
| 7882 | formalmente | 3 |
| 7883 | forasteros | 3 |
| 7884 | folletín | 3 |
| 7885 | fogoso | 3 |
| 7886 | flotar | 3 |
| 7887 | flotando | 3 |
| 7888 | florido | 3 |
| 7889 | flojedad | 3 |
| 7890 | floja | 3 |
| 7891 | flato | 3 |
| 7892 | fisiológico | 3 |
| 7893 | firmes | 3 |
| 7894 | firmar | 3 |
| 7895 | finge | 3 |
| 7896 | filosóficas | 3 |
| 7897 | filosófica | 3 |
| 7898 | filosofar | 3 |
| 7899 | filo | 3 |
| 7900 | fijaron | 3 |
| 7901 | figurín | 3 |
| 7902 | figúrese | 3 |
| 7903 | fíes | 3 |
| 7904 | fidias | 3 |
| 7905 | fiambres | 3 |
| 7906 | feuillet | 3 |
| 7907 | feudal | 3 |
| 7908 | feria | 3 |
| 7909 | feos | 3 |
| 7910 | femenino | 3 |
| 7911 | femenil | 3 |
| 7912 | favorecer | 3 |
| 7913 | favorable | 3 |
| 7914 | fauna | 3 |
| 7915 | fanatizado | 3 |
| 7916 | fanáticos | 3 |
| 7917 | faltas | 3 |
| 7918 | falsos | 3 |
| 7919 | falsas | 3 |
| 7920 | faena | 3 |
| 7921 | fáciles | 3 |
| 7922 | fabricaba | 3 |
| 7923 | extremosa | 3 |
| 7924 | extravagante | 3 |
| 7925 | extraordinaria | 3 |
| 7926 | extraños | 3 |
| 7927 | extensos | 3 |
| 7928 | expuesto | 3 |
| 7929 | explíquese | 3 |
| 7930 | explique | 3 |
| 7931 | experto | 3 |
| 7932 | expediente | 3 |
| 7933 | expansivo | 3 |
| 7934 | exigido | 3 |
| 7935 | exhibición | 3 |
| 7936 | excomunión | 3 |
| 7937 | exclusivamente | 3 |
| 7938 | excitar | 3 |
| 7939 | excitaban | 3 |
| 7940 | excepciones | 3 |
| 7941 | excelentísimo | 3 |
| 7942 | exaltaba | 3 |
| 7943 | exagerar | 3 |
| 7944 | europeo | 3 |
| 7945 | europa | 3 |
| 7946 | estudiantes | 3 |
| 7947 | estribillo | 3 |
| 7948 | estrepitosos | 3 |
| 7949 | estrepitosas | 3 |
| 7950 | estrechó | 3 |
| 7951 | estrechaba | 3 |
| 7952 | estío | 3 |
| 7953 | estímulos | 3 |
| 7954 | estima | 3 |
| 7955 | estercolero | 3 |
| 7956 | estarán | 3 |
| 7957 | estanquillo | 3 |
| 7958 | estampa | 3 |
| 7959 | estallido | 3 |
| 7960 | estaciones | 3 |
| 7961 | establecimiento | 3 |
| 7962 | establecía | 3 |
| 7963 | esquinas | 3 |
| 7964 | esposas | 3 |
| 7965 | espontáneo | 3 |
| 7966 | espontáneamente | 3 |
| 7967 | esponjas | 3 |
| 7968 | esplendoroso | 3 |
| 7969 | esplendores | 3 |
| 7970 | espiritualidad | 3 |
| 7971 | espiritista | 3 |
| 7972 | espionaje | 3 |
| 7973 | espiga | 3 |
| 7974 | espesas | 3 |
| 7975 | esperma | 3 |
| 7976 | esperado | 3 |
| 7977 | esparcido | 3 |
| 7978 | esparcidas | 3 |
| 7979 | espantaba | 3 |
| 7980 | espaldar | 3 |
| 7981 | espadas | 3 |
| 7982 | esgrima | 3 |
| 7983 | esforzaba | 3 |
| 7984 | esfera | 3 |
| 7985 | escupió | 3 |
| 7986 | escupía | 3 |
| 7987 | escritos | 3 |
| 7988 | escritorio | 3 |
| 7989 | escritores | 3 |
| 7990 | escrita | 3 |
| 7991 | escribirle | 3 |
| 7992 | esconderse | 3 |
| 7993 | escogido | 3 |
| 7994 | escogía | 3 |
| 7995 | esclavina | 3 |
| 7996 | escasas | 3 |
| 7997 | escarlata | 3 |
| 7998 | escarabajos | 3 |
| 7999 | escaleras | 3 |
| 8000 | esbeltez | 3 |
| 8001 | ésa | 3 |
| 8002 | epístola | 3 |
| 8003 | envidiosos | 3 |
| 8004 | envidiada | 3 |
| 8005 | entretenerse | 3 |
| 8006 | entretanto | 3 |
| 8007 | entremeses | 3 |
| 8008 | entregó | 3 |
| 8009 | entregaban | 3 |
| 8010 | entiendan | 3 |
| 8011 | enterrado | 3 |
| 8012 | enternecimientos | 3 |
| 8013 | entendiese | 3 |
| 8014 | entenderlo | 3 |
| 8015 | entablar | 3 |
| 8016 | enseñaban | 3 |
| 8017 | ensalada | 3 |
| 8018 | enrique | 3 |
| 8019 | enredaba | 3 |
| 8020 | enramada | 3 |
| 8021 | enguantada | 3 |
| 8022 | engañarle | 3 |
| 8023 | engañan | 3 |
| 8024 | engañaban | 3 |
| 8025 | enfriaba | 3 |
| 8026 | enérgica | 3 |
| 8027 | encogido | 3 |
| 8028 | encierro | 3 |
| 8029 | encerronas | 3 |
| 8030 | encerrada | 3 |
| 8031 | encendió | 3 |
| 8032 | encendida | 3 |
| 8033 | encarnadas | 3 |
| 8034 | encaramarse | 3 |
| 8035 | encaramado | 3 |
| 8036 | encantado | 3 |
| 8037 | encantada | 3 |
| 8038 | encajes | 3 |
| 8039 | enamoró | 3 |
| 8040 | empuñaba | 3 |
| 8041 | empujaba | 3 |
| 8042 | empleo | 3 |
| 8043 | empeñaban | 3 |
| 8044 | empecatada | 3 |
| 8045 | empapado | 3 |
| 8046 | emigración | 3 |
| 8047 | embozado | 3 |
| 8048 | embalsamado | 3 |
| 8049 | elevación | 3 |
| 8050 | elevaba | 3 |
| 8051 | electricidad | 3 |
| 8052 | electoral | 3 |
| 8053 | ejércitos | 3 |
| 8054 | ejercía | 3 |
| 8055 | efímeras | 3 |
| 8056 | educada | 3 |
| 8057 | edificar | 3 |
| 8058 | edades | 3 |
| 8059 | eclipsado | 3 |
| 8060 | echase | 3 |
| 8061 | durmió | 3 |
| 8062 | duraría | 3 |
| 8063 | durado | 3 |
| 8064 | duradera | 3 |
| 8065 | dudó | 3 |
| 8066 | dogmas | 3 |
| 8067 | dividían | 3 |
| 8068 | dividía | 3 |
| 8069 | divertir | 3 |
| 8070 | diversiones | 3 |
| 8071 | diván | 3 |
| 8072 | diva | 3 |
| 8073 | distrito | 3 |
| 8074 | distraerse | 3 |
| 8075 | distintas | 3 |
| 8076 | distinta | 3 |
| 8077 | distinguían | 3 |
| 8078 | distante | 3 |
| 8079 | disputas | 3 |
| 8080 | disputa | 3 |
| 8081 | dispuestos | 3 |
| 8082 | dispersaron | 3 |
| 8083 | disparó | 3 |
| 8084 | disparatar | 3 |
| 8085 | disparatados | 3 |
| 8086 | disparaba | 3 |
| 8087 | disolvente | 3 |
| 8088 | disimularlo | 3 |
| 8089 | disimulan | 3 |
| 8090 | disimulaban | 3 |
| 8091 | discutían | 3 |
| 8092 | discurría | 3 |
| 8093 | discordia | 3 |
| 8094 | dirigido | 3 |
| 8095 | directiva | 3 |
| 8096 | diputados | 3 |
| 8097 | dioses | 3 |
| 8098 | dinamita | 3 |
| 8099 | dijese | 3 |
| 8100 | dignó | 3 |
| 8101 | digestión | 3 |
| 8102 | dígase | 3 |
| 8103 | diese | 3 |
| 8104 | dieran | 3 |
| 8105 | diciéndose | 3 |
| 8106 | diamantes | 3 |
| 8107 | diálogos | 3 |
| 8108 | diagonales | 3 |
| 8109 | diabólicos | 3 |
| 8110 | diabluras | 3 |
| 8111 | diablura | 3 |
| 8112 | devolver | 3 |
| 8113 | devaneos | 3 |
| 8114 | deteniéndose | 3 |
| 8115 | desvencijada | 3 |
| 8116 | destierro | 3 |
| 8117 | destellos | 3 |
| 8118 | destacaba | 3 |
| 8119 | desprecia | 3 |
| 8120 | déspota | 3 |
| 8121 | despojos | 3 |
| 8122 | desplomado | 3 |
| 8123 | despierta | 3 |
| 8124 | despidieron | 3 |
| 8125 | despertando | 3 |
| 8126 | despedirme | 3 |
| 8127 | despedirla | 3 |
| 8128 | desparpajo | 3 |
| 8129 | desnudas | 3 |
| 8130 | desnudaba | 3 |
| 8131 | desmejorado | 3 |
| 8132 | deslumbrante | 3 |
| 8133 | desigualdad | 3 |
| 8134 | deshonrar | 3 |
| 8135 | deshonrado | 3 |
| 8136 | desgracias | 3 |
| 8137 | desfallecimientos | 3 |
| 8138 | deseó | 3 |
| 8139 | desengañado | 3 |
| 8140 | desencajado | 3 |
| 8141 | desechar | 3 |
| 8142 | deseaban | 3 |
| 8143 | descuide | 3 |
| 8144 | descripción | 3 |
| 8145 | desconfiar | 3 |
| 8146 | desconfiada | 3 |
| 8147 | descargar | 3 |
| 8148 | desaparecían | 3 |
| 8149 | desaliento | 3 |
| 8150 | desairado | 3 |
| 8151 | desahogo | 3 |
| 8152 | desagradable | 3 |
| 8153 | desafíos | 3 |
| 8154 | desafiaba | 3 |
| 8155 | derribo | 3 |
| 8156 | derribar | 3 |
| 8157 | demostró | 3 |
| 8158 | demasiada | 3 |
| 8159 | delirante | 3 |
| 8160 | delgadas | 3 |
| 8161 | deletérea | 3 |
| 8162 | delantal | 3 |
| 8163 | déjeme | 3 |
| 8164 | déjela | 3 |
| 8165 | dejé | 3 |
| 8166 | dejase | 3 |
| 8167 | dejaran | 3 |
| 8168 | dejara | 3 |
| 8169 | déjale | 3 |
| 8170 | dejadme | 3 |
| 8171 | defenderse | 3 |
| 8172 | dedicó | 3 |
| 8173 | dedicaba | 3 |
| 8174 | decoroso | 3 |
| 8175 | decoraciones | 3 |
| 8176 | declarado | 3 |
| 8177 | declamando | 3 |
| 8178 | decisivo | 3 |
| 8179 | decirme | 3 |
| 8180 | decidirse | 3 |
| 8181 | debemos | 3 |
| 8182 | debate | 3 |
| 8183 | darte | 3 |
| 8184 | darme | 3 |
| 8185 | darían | 3 |
| 8186 | dará | 3 |
| 8187 | dándose | 3 |
| 8188 | dame | 3 |
| 8189 | dada | 3 |
| 8190 | curioso | 3 |
| 8191 | curación | 3 |
| 8192 | cumplió | 3 |
| 8193 | cumbres | 3 |
| 8194 | cultivo | 3 |
| 8195 | culinario | 3 |
| 8196 | cuidarse | 3 |
| 8197 | cuidando | 3 |
| 8198 | cuero | 3 |
| 8199 | cuente | 3 |
| 8200 | cubrió | 3 |
| 8201 | cubo | 3 |
| 8202 | cuaderno | 3 |
| 8203 | cruzaba | 3 |
| 8204 | crujientes | 3 |
| 8205 | crónicas | 3 |
| 8206 | crochet | 3 |
| 8207 | cristianas | 3 |
| 8208 | creyese | 3 |
| 8209 | creyentes | 3 |
| 8210 | creyente | 3 |
| 8211 | creyéndose | 3 |
| 8212 | creyéndome | 3 |
| 8213 | creencia | 3 |
| 8214 | creen | 3 |
| 8215 | crédito | 3 |
| 8216 | crecido | 3 |
| 8217 | crear | 3 |
| 8218 | creador | 3 |
| 8219 | costureras | 3 |
| 8220 | costado | 3 |
| 8221 | cortos | 3 |
| 8222 | cortinaje | 3 |
| 8223 | corteza | 3 |
| 8224 | cortesana | 3 |
| 8225 | cortejo | 3 |
| 8226 | cortadas | 3 |
| 8227 | corrupción | 3 |
| 8228 | corrosiva | 3 |
| 8229 | corresponsal | 3 |
| 8230 | correspondía | 3 |
| 8231 | corresponde | 3 |
| 8232 | corregía | 3 |
| 8233 | corredores | 3 |
| 8234 | correctas | 3 |
| 8235 | correcta | 3 |
| 8236 | corralada | 3 |
| 8237 | coronados | 3 |
| 8238 | corazones | 3 |
| 8239 | coraza | 3 |
| 8240 | convirtiendo | 3 |
| 8241 | convinieron | 3 |
| 8242 | convertirlos | 3 |
| 8243 | convertirle | 3 |
| 8244 | conversar | 3 |
| 8245 | conversando | 3 |
| 8246 | conveniente | 3 |
| 8247 | convencida | 3 |
| 8248 | convence | 3 |
| 8249 | controversia | 3 |
| 8250 | contratiempo | 3 |
| 8251 | contrariedades | 3 |
| 8252 | contorno | 3 |
| 8253 | continuando | 3 |
| 8254 | contera | 3 |
| 8255 | contemporáneos | 3 |
| 8256 | contempló | 3 |
| 8257 | contagio | 3 |
| 8258 | consumados | 3 |
| 8259 | construía | 3 |
| 8260 | conste | 3 |
| 8261 | constaba | 3 |
| 8262 | conspirador | 3 |
| 8263 | consolas | 3 |
| 8264 | consolarla | 3 |
| 8265 | consolar | 3 |
| 8266 | consola | 3 |
| 8267 | consienten | 3 |
| 8268 | consideración | 3 |
| 8269 | conservación | 3 |
| 8270 | consecuencia | 3 |
| 8271 | conquistas | 3 |
| 8272 | conquistado | 3 |
| 8273 | conociese | 3 |
| 8274 | conocidos | 3 |
| 8275 | conocida | 3 |
| 8276 | conocerse | 3 |
| 8277 | conocemos | 3 |
| 8278 | conjeturas | 3 |
| 8279 | confusos | 3 |
| 8280 | confusas | 3 |
| 8281 | confundir | 3 |
| 8282 | confundía | 3 |
| 8283 | conformidad | 3 |
| 8284 | conformes | 3 |
| 8285 | confitería | 3 |
| 8286 | confirmó | 3 |
| 8287 | confieso | 3 |
| 8288 | confiese | 3 |
| 8289 | confesonarios | 3 |
| 8290 | conejos | 3 |
| 8291 | conducto | 3 |
| 8292 | condicionales | 3 |
| 8293 | condenaban | 3 |
| 8294 | concluyendo | 3 |
| 8295 | concluían | 3 |
| 8296 | conceptos | 3 |
| 8297 | concentrada | 3 |
| 8298 | conatos | 3 |
| 8299 | comunicaba | 3 |
| 8300 | compungido | 3 |
| 8301 | compromisos | 3 |
| 8302 | compromiso | 3 |
| 8303 | comprometía | 3 |
| 8304 | comprometer | 3 |
| 8305 | compromete | 3 |
| 8306 | comprimidos | 3 |
| 8307 | comprendes | 3 |
| 8308 | compraba | 3 |
| 8309 | composición | 3 |
| 8310 | complicado | 3 |
| 8311 | complicadas | 3 |
| 8312 | complacer | 3 |
| 8313 | competencia | 3 |
| 8314 | compatible | 3 |
| 8315 | compañías | 3 |
| 8316 | compañeras | 3 |
| 8317 | comodidades | 3 |
| 8318 | comitiva | 3 |
| 8319 | comité | 3 |
| 8320 | comidilla | 3 |
| 8321 | cómicas | 3 |
| 8322 | cometía | 3 |
| 8323 | comestibles | 3 |
| 8324 | comería | 3 |
| 8325 | comarca | 3 |
| 8326 | comandante | 3 |
| 8327 | coma | 3 |
| 8328 | colonos | 3 |
| 8329 | colocó | 3 |
| 8330 | colocación | 3 |
| 8331 | colmena | 3 |
| 8332 | colegio | 3 |
| 8333 | colectiva | 3 |
| 8334 | cojo | 3 |
| 8335 | coincidido | 3 |
| 8336 | cogida | 3 |
| 8337 | cogerla | 3 |
| 8338 | coge | 3 |
| 8339 | cofradía | 3 |
| 8340 | código | 3 |
| 8341 | codiciado | 3 |
| 8342 | codiciada | 3 |
| 8343 | cobrando | 3 |
| 8344 | cobardía | 3 |
| 8345 | cobardes | 3 |
| 8346 | club | 3 |
| 8347 | clementina | 3 |
| 8348 | clavos | 3 |
| 8349 | clavó | 3 |
| 8350 | clavar | 3 |
| 8351 | clavando | 3 |
| 8352 | clavadas | 3 |
| 8353 | civilización | 3 |
| 8354 | ciriales | 3 |
| 8355 | circunspecto | 3 |
| 8356 | circunloquios | 3 |
| 8357 | círculos | 3 |
| 8358 | circular | 3 |
| 8359 | circo | 3 |
| 8360 | cintas | 3 |
| 8361 | cilicios | 3 |
| 8362 | científicas | 3 |
| 8363 | cielos | 3 |
| 8364 | cid | 3 |
| 8365 | chuzo | 3 |
| 8366 | churrigueresca | 3 |
| 8367 | chubasco | 3 |
| 8368 | chorros | 3 |
| 8369 | chorro | 3 |
| 8370 | chispa | 3 |
| 8371 | chismes | 3 |
| 8372 | chiquilla | 3 |
| 8373 | china | 3 |
| 8374 | chillones | 3 |
| 8375 | chillidos | 3 |
| 8376 | chillido | 3 |
| 8377 | chiflado | 3 |
| 8378 | chic | 3 |
| 8379 | chasco | 3 |
| 8380 | charol | 3 |
| 8381 | chaparrón | 3 |
| 8382 | chal | 3 |
| 8383 | cesto | 3 |
| 8384 | cesta | 3 |
| 8385 | cerrazón | 3 |
| 8386 | ceremonia | 3 |
| 8387 | cerdos | 3 |
| 8388 | cerco | 3 |
| 8389 | cepillo | 3 |
| 8390 | ceñir | 3 |
| 8391 | centinela | 3 |
| 8392 | censurar | 3 |
| 8393 | censura | 3 |
| 8394 | cenicienta | 3 |
| 8395 | cenaba | 3 |
| 8396 | celosías | 3 |
| 8397 | celebraban | 3 |
| 8398 | cedió | 3 |
| 8399 | cebolletas | 3 |
| 8400 | cazaba | 3 |
| 8401 | cayeron | 3 |
| 8402 | causarle | 3 |
| 8403 | caudillo | 3 |
| 8404 | cauce | 3 |
| 8405 | catedrático | 3 |
| 8406 | castor | 3 |
| 8407 | casillas | 3 |
| 8408 | cascaciruelas | 3 |
| 8409 | casaderas | 3 |
| 8410 | carrillos | 3 |
| 8411 | carreteras | 3 |
| 8412 | carreras | 3 |
| 8413 | caros | 3 |
| 8414 | carneros | 3 |
| 8415 | cargos | 3 |
| 8416 | cargar | 3 |
| 8417 | carbonero | 3 |
| 8418 | caras | 3 |
| 8419 | caramelo | 3 |
| 8420 | caprichosas | 3 |
| 8421 | caprichosa | 3 |
| 8422 | capítulos | 3 |
| 8423 | capitales | 3 |
| 8424 | cañada | 3 |
| 8425 | caña | 3 |
| 8426 | cantidad | 3 |
| 8427 | canteros | 3 |
| 8428 | cantara | 3 |
| 8429 | candoroso | 3 |
| 8430 | candidato | 3 |
| 8431 | candeleros | 3 |
| 8432 | candelas | 3 |
| 8433 | canastillo | 3 |
| 8434 | campillo | 3 |
| 8435 | campanilla | 3 |
| 8436 | campaneros | 3 |
| 8437 | campanarios | 3 |
| 8438 | caminaba | 3 |
| 8439 | calzados | 3 |
| 8440 | calumniar | 3 |
| 8441 | cálices | 3 |
| 8442 | calavera | 3 |
| 8443 | cajero | 3 |
| 8444 | caigo | 3 |
| 8445 | cae | 3 |
| 8446 | cadete | 3 |
| 8447 | cachipote | 3 |
| 8448 | cabizbajo | 3 |
| 8449 | cabían | 3 |
| 8450 | caballerito | 3 |
| 8451 | cábalas | 3 |
| 8452 | busto | 3 |
| 8453 | buscase | 3 |
| 8454 | buscarte | 3 |
| 8455 | buscarlos | 3 |
| 8456 | buscarlo | 3 |
| 8457 | buscarle | 3 |
| 8458 | buscan | 3 |
| 8459 | burlona | 3 |
| 8460 | burlesca | 3 |
| 8461 | burlarse | 3 |
| 8462 | burbujas | 3 |
| 8463 | bulliciosos | 3 |
| 8464 | bucólico | 3 |
| 8465 | bucólica | 3 |
| 8466 | brutalidad | 3 |
| 8467 | bruscos | 3 |
| 8468 | brusco | 3 |
| 8469 | brotaban | 3 |
| 8470 | brotaba | 3 |
| 8471 | bromitas | 3 |
| 8472 | brindando | 3 |
| 8473 | brincos | 3 |
| 8474 | brasa | 3 |
| 8475 | botones | 3 |
| 8476 | botella | 3 |
| 8477 | bostezó | 3 |
| 8478 | borrico | 3 |
| 8479 | borrar | 3 |
| 8480 | bordada | 3 |
| 8481 | bonito | 3 |
| 8482 | bondadosa | 3 |
| 8483 | bonachona | 3 |
| 8484 | bomba | 3 |
| 8485 | bom | 3 |
| 8486 | bolsas | 3 |
| 8487 | bolos | 3 |
| 8488 | bofetón | 3 |
| 8489 | boda | 3 |
| 8490 | bobo | 3 |
| 8491 | bobalicones | 3 |
| 8492 | boba | 3 |
| 8493 | blusa | 3 |
| 8494 | blanquecina | 3 |
| 8495 | bienestar | 3 |
| 8496 | bíblico | 3 |
| 8497 | bestias | 3 |
| 8498 | benevolencia | 3 |
| 8499 | beneficiados | 3 |
| 8500 | bellezas | 3 |
| 8501 | bella | 3 |
| 8502 | belisario | 3 |
| 8503 | bebían | 3 |
| 8504 | be | 3 |
| 8505 | baúl | 3 |
| 8506 | batín | 3 |
| 8507 | batiendo | 3 |
| 8508 | basto | 3 |
| 8509 | barrios | 3 |
| 8510 | barras | 3 |
| 8511 | barragana | 3 |
| 8512 | baroncito | 3 |
| 8513 | barbas | 3 |
| 8514 | bárbaro | 3 |
| 8515 | bárbara | 3 |
| 8516 | bañaba | 3 |
| 8517 | banquete | 3 |
| 8518 | bandadas | 3 |
| 8519 | baladí | 3 |
| 8520 | bajaron | 3 |
| 8521 | bailando | 3 |
| 8522 | bailaba | 3 |
| 8523 | baila | 3 |
| 8524 | badajo | 3 |
| 8525 | bactriana | 3 |
| 8526 | bacante | 3 |
| 8527 | azulada | 3 |
| 8528 | azotó | 3 |
| 8529 | azahar | 3 |
| 8530 | ayudarla | 3 |
| 8531 | ayudara | 3 |
| 8532 | ayudaban | 3 |
| 8533 | avisado | 3 |
| 8534 | avergonzó | 3 |
| 8535 | avergonzaba | 3 |
| 8536 | aventuró | 3 |
| 8537 | aventurar | 3 |
| 8538 | aumentó | 3 |
| 8539 | audaces | 3 |
| 8540 | aturdían | 3 |
| 8541 | aturde | 3 |
| 8542 | atrio | 3 |
| 8543 | atributos | 3 |
| 8544 | atrevo | 3 |
| 8545 | atreviéndose | 3 |
| 8546 | atravesar | 3 |
| 8547 | atravesando | 3 |
| 8548 | atacar | 3 |
| 8549 | asustarle | 3 |
| 8550 | asustan | 3 |
| 8551 | asustados | 3 |
| 8552 | astuta | 3 |
| 8553 | astucia | 3 |
| 8554 | astorga | 3 |
| 8555 | aspiración | 3 |
| 8556 | áspero | 3 |
| 8557 | asomos | 3 |
| 8558 | asistiendo | 3 |
| 8559 | asilo | 3 |
| 8560 | asientos | 3 |
| 8561 | aseguro | 3 |
| 8562 | asegurarse | 3 |
| 8563 | asechanzas | 3 |
| 8564 | ascensión | 3 |
| 8565 | ascender | 3 |
| 8566 | artísticos | 3 |
| 8567 | artistas | 3 |
| 8568 | artesones | 3 |
| 8569 | artefacto | 3 |
| 8570 | arrugada | 3 |
| 8571 | arrugaba | 3 |
| 8572 | arrojase | 3 |
| 8573 | arrodillarse | 3 |
| 8574 | arriesgar | 3 |
| 8575 | arreos | 3 |
| 8576 | arregló | 3 |
| 8577 | arreglado | 3 |
| 8578 | arrebatos | 3 |
| 8579 | arrebato | 3 |
| 8580 | arrastraban | 3 |
| 8581 | arrancando | 3 |
| 8582 | arrancaban | 3 |
| 8583 | aromas | 3 |
| 8584 | armonizar | 3 |
| 8585 | armoniosa | 3 |
| 8586 | armeros | 3 |
| 8587 | armazón | 3 |
| 8588 | aristocrática | 3 |
| 8589 | ardor | 3 |
| 8590 | arca | 3 |
| 8591 | arbustos | 3 |
| 8592 | aragón | 3 |
| 8593 | aquelarre | 3 |
| 8594 | apurado | 3 |
| 8595 | apuntar | 3 |
| 8596 | apuesto | 3 |
| 8597 | apretones | 3 |
| 8598 | apretando | 3 |
| 8599 | aprendiendo | 3 |
| 8600 | aprecio | 3 |
| 8601 | apodo | 3 |
| 8602 | aplazar | 3 |
| 8603 | apasionados | 3 |
| 8604 | apartó | 3 |
| 8605 | apartar | 3 |
| 8606 | aparecido | 3 |
| 8607 | apagar | 3 |
| 8608 | apagaban | 3 |
| 8609 | apaga | 3 |
| 8610 | añadir | 3 |
| 8611 | anunciado | 3 |
| 8612 | antojo | 3 |
| 8613 | antiquísimas | 3 |
| 8614 | antipático | 3 |
| 8615 | antipatía | 3 |
| 8616 | anti | 3 |
| 8617 | antesala | 3 |
| 8618 | ansiaba | 3 |
| 8619 | anguloso | 3 |
| 8620 | angelina | 3 |
| 8621 | anémico | 3 |
| 8622 | anemia | 3 |
| 8623 | anegada | 3 |
| 8624 | andaría | 3 |
| 8625 | andan | 3 |
| 8626 | andaluz | 3 |
| 8627 | andado | 3 |
| 8628 | ancas | 3 |
| 8629 | anarquía | 3 |
| 8630 | anaqueles | 3 |
| 8631 | análogos | 3 |
| 8632 | análogas | 3 |
| 8633 | anacronismos | 3 |
| 8634 | anacleto | 3 |
| 8635 | amontonados | 3 |
| 8636 | amontonada | 3 |
| 8637 | amonestaciones | 3 |
| 8638 | amigotes | 3 |
| 8639 | americana | 3 |
| 8640 | amenazado | 3 |
| 8641 | amena | 3 |
| 8642 | amén | 3 |
| 8643 | ambicioso | 3 |
| 8644 | ambicionar | 3 |
| 8645 | amarle | 3 |
| 8646 | amadeo | 3 |
| 8647 | amada | 3 |
| 8648 | amables | 3 |
| 8649 | altares | 3 |
| 8650 | alrededores | 3 |
| 8651 | almohadones | 3 |
| 8652 | almíbares | 3 |
| 8653 | alfonso | 3 |
| 8654 | aleteo | 3 |
| 8655 | alentar | 3 |
| 8656 | alemana | 3 |
| 8657 | alejado | 3 |
| 8658 | alegró | 3 |
| 8659 | alegrarse | 3 |
| 8660 | alegorías | 3 |
| 8661 | alcázar | 3 |
| 8662 | alcaravanes | 3 |
| 8663 | alcantarillas | 3 |
| 8664 | alborotaba | 3 |
| 8665 | albergue | 3 |
| 8666 | alarmarse | 3 |
| 8667 | alarmante | 3 |
| 8668 | alarma | 3 |
| 8669 | alaridos | 3 |
| 8670 | ajustar | 3 |
| 8671 | ajuar | 3 |
| 8672 | ajeno | 3 |
| 8673 | aguardaba | 3 |
| 8674 | aguantar | 3 |
| 8675 | agria | 3 |
| 8676 | agregada | 3 |
| 8677 | agradecida | 3 |
| 8678 | agolpaban | 3 |
| 8679 | agarrada | 3 |
| 8680 | agapita | 3 |
| 8681 | afirmaciones | 3 |
| 8682 | afilados | 3 |
| 8683 | afeminado | 3 |
| 8684 | afectos | 3 |
| 8685 | afecto | 3 |
| 8686 | afectada | 3 |
| 8687 | afectaba | 3 |
| 8688 | advertir | 3 |
| 8689 | advertido | 3 |
| 8690 | advertía | 3 |
| 8691 | adúltero | 3 |
| 8692 | adulaba | 3 |
| 8693 | adquirir | 3 |
| 8694 | adorno | 3 |
| 8695 | adoradores | 3 |
| 8696 | adorador | 3 |
| 8697 | adorado | 3 |
| 8698 | adora | 3 |
| 8699 | adonde | 3 |
| 8700 | admitir | 3 |
| 8701 | admitido | 3 |
| 8702 | admirable | 3 |
| 8703 | adivinado | 3 |
| 8704 | adelantaba | 3 |
| 8705 | acuérdate | 3 |
| 8706 | acudieron | 3 |
| 8707 | acudido | 3 |
| 8708 | actores | 3 |
| 8709 | acostumbraba | 3 |
| 8710 | acompañara | 3 |
| 8711 | acompañando | 3 |
| 8712 | acólitos | 3 |
| 8713 | acogió | 3 |
| 8714 | aclimatación | 3 |
| 8715 | acierto | 3 |
| 8716 | achaques | 3 |
| 8717 | achacaba | 3 |
| 8718 | acercaron | 3 |
| 8719 | acendrado | 3 |
| 8720 | acechaba | 3 |
| 8721 | accidente | 3 |
| 8722 | acataba | 3 |
| 8723 | acabaron | 3 |
| 8724 | abuso | 3 |
| 8725 | abundantes | 3 |
| 8726 | abundancia | 3 |
| 8727 | abstracto | 3 |
| 8728 | abstracta | 3 |
| 8729 | absorbente | 3 |
| 8730 | ábside | 3 |
| 8731 | abrochó | 3 |
| 8732 | abrasaba | 3 |
| 8733 | abra | 3 |
| 8734 | abono | 3 |
| 8735 | abolengo | 3 |
| 8736 | aberraciones | 3 |
| 8737 | abandonarle | 3 |
| 8738 | abandonaban | 3 |
| 8739 | zurriago | 2 |
| 8740 | zumbido | 2 |
| 8741 | zumbaba | 2 |
| 8742 | zig | 2 |
| 8743 | zarzamora | 2 |
| 8744 | zapatero | 2 |
| 8745 | zánganos | 2 |
| 8746 | zagal | 2 |
| 8747 | yugo | 2 |
| 8748 | york | 2 |
| 8749 | yendo | 2 |
| 8750 | x | 2 |
| 8751 | werther | 2 |
| 8752 | vulgarmente | 2 |
| 8753 | vulgarísima | 2 |
| 8754 | vuelvan | 2 |
| 8755 | vos | 2 |
| 8756 | volviose | 2 |
| 8757 | volví | 2 |
| 8758 | volveremos | 2 |
| 8759 | volverán | 2 |
| 8760 | volverá | 2 |
| 8761 | volvemos | 2 |
| 8762 | voluptuosamente | 2 |
| 8763 | voluntariamente | 2 |
| 8764 | voluntades | 2 |
| 8765 | volaría | 2 |
| 8766 | volado | 2 |
| 8767 | vociferó | 2 |
| 8768 | vocabulario | 2 |
| 8769 | viviese | 2 |
| 8770 | vivieron | 2 |
| 8771 | viviente | 2 |
| 8772 | viviendo | 2 |
| 8773 | viveza | 2 |
| 8774 | vives | 2 |
| 8775 | vivaracho | 2 |
| 8776 | vivaracha | 2 |
| 8777 | visual | 2 |
| 8778 | vistazo | 2 |
| 8779 | vistalegre | 2 |
| 8780 | viso | 2 |
| 8781 | vislumbraba | 2 |
| 8782 | visitó | 2 |
| 8783 | visitado | 2 |
| 8784 | viscoso | 2 |
| 8785 | viscosa | 2 |
| 8786 | virtuosísima | 2 |
| 8787 | viril | 2 |
| 8788 | virginal | 2 |
| 8789 | violeta | 2 |
| 8790 | violentas | 2 |
| 8791 | violentar | 2 |
| 8792 | violenta | 2 |
| 8793 | violencias | 2 |
| 8794 | vinos | 2 |
| 8795 | viniesen | 2 |
| 8796 | vinajeras | 2 |
| 8797 | villegas | 2 |
| 8798 | viles | 2 |
| 8799 | viii | 2 |
| 8800 | vii | 2 |
| 8801 | vigorosas | 2 |
| 8802 | vigilias | 2 |
| 8803 | viga | 2 |
| 8804 | viesen | 2 |
| 8805 | vieras | 2 |
| 8806 | vienes | 2 |
| 8807 | viéndose | 2 |
| 8808 | viejecillo | 2 |
| 8809 | viciosa | 2 |
| 8810 | vibrantes | 2 |
| 8811 | vestiduras | 2 |
| 8812 | vespucios | 2 |
| 8813 | vespucio | 2 |
| 8814 | vertiginosas | 2 |
| 8815 | verticales | 2 |
| 8816 | verme | 2 |
| 8817 | verlos | 2 |
| 8818 | verjas | 2 |
| 8819 | veritas | 2 |
| 8820 | vergonzante | 2 |
| 8821 | veré | 2 |
| 8822 | verdaderas | 2 |
| 8823 | verdaderamente | 2 |
| 8824 | veranos | 2 |
| 8825 | veranillo | 2 |
| 8826 | ventorrillos | 2 |
| 8827 | venirse | 2 |
| 8828 | veniales | 2 |
| 8829 | venganzas | 2 |
| 8830 | vengan | 2 |
| 8831 | vengábase | 2 |
| 8832 | vengaba | 2 |
| 8833 | vendré | 2 |
| 8834 | vendrán | 2 |
| 8835 | vendió | 2 |
| 8836 | vendían | 2 |
| 8837 | vendemos | 2 |
| 8838 | venciste | 2 |
| 8839 | vencieron | 2 |
| 8840 | vencidas | 2 |
| 8841 | vencían | 2 |
| 8842 | vencerían | 2 |
| 8843 | vencerás | 2 |
| 8844 | vence | 2 |
| 8845 | vello | 2 |
| 8846 | veintiséis | 2 |
| 8847 | vega | 2 |
| 8848 | véase | 2 |
| 8849 | vayan | 2 |
| 8850 | vayamos | 2 |
| 8851 | vapor | 2 |
| 8852 | vanamente | 2 |
| 8853 | vanagloria | 2 |
| 8854 | vámonos | 2 |
| 8855 | valientes | 2 |
| 8856 | valido | 2 |
| 8857 | valerse | 2 |
| 8858 | valer | 2 |
| 8859 | valdrá | 2 |
| 8860 | valdés | 2 |
| 8861 | vajilla | 2 |
| 8862 | vagando | 2 |
| 8863 | vade | 2 |
| 8864 | vacilar | 2 |
| 8865 | vacilantes | 2 |
| 8866 | vacilaciones | 2 |
| 8867 | vaca | 2 |
| 8868 | utilitaria | 2 |
| 8869 | usado | 2 |
| 8870 | usaban | 2 |
| 8871 | usa | 2 |
| 8872 | úrsula | 2 |
| 8873 | uña | 2 |
| 8874 | unido | 2 |
| 8875 | ultramontanos | 2 |
| 8876 | ultrajes | 2 |
| 8877 | ultraje | 2 |
| 8878 | ultrajados | 2 |
| 8879 | ultra | 2 |
| 8880 | uf | 2 |
| 8881 | tuviesen | 2 |
| 8882 | tuvieran | 2 |
| 8883 | tutti | 2 |
| 8884 | tuteaba | 2 |
| 8885 | turcos | 2 |
| 8886 | turbas | 2 |
| 8887 | turba | 2 |
| 8888 | tuo | 2 |
| 8889 | tunante | 2 |
| 8890 | tumba | 2 |
| 8891 | tul | 2 |
| 8892 | tubinga | 2 |
| 8893 | truquage | 2 |
| 8894 | trovadores | 2 |
| 8895 | tropezaban | 2 |
| 8896 | tropa | 2 |
| 8897 | trompetas | 2 |
| 8898 | trompeta | 2 |
| 8899 | triunfó | 2 |
| 8900 | triunfador | 2 |
| 8901 | triunfado | 2 |
| 8902 | triunfaba | 2 |
| 8903 | tributando | 2 |
| 8904 | trepar | 2 |
| 8905 | trepaban | 2 |
| 8906 | trenzas | 2 |
| 8907 | tremendos | 2 |
| 8908 | tremendo | 2 |
| 8909 | tregua | 2 |
| 8910 | trayendo | 2 |
| 8911 | traviesa | 2 |
| 8912 | travesaño | 2 |
| 8913 | trataron | 2 |
| 8914 | tratándole | 2 |
| 8915 | tratamos | 2 |
| 8916 | tratamiento | 2 |
| 8917 | trastos | 2 |
| 8918 | trasto | 2 |
| 8919 | trastienda | 2 |
| 8920 | traspasaba | 2 |
| 8921 | trapillo | 2 |
| 8922 | trapicheos | 2 |
| 8923 | transformarse | 2 |
| 8924 | transformaciones | 2 |
| 8925 | transeúnte | 2 |
| 8926 | transacciones | 2 |
| 8927 | tranquilizó | 2 |
| 8928 | tranquilizar | 2 |
| 8929 | tranquilícese | 2 |
| 8930 | tramo | 2 |
| 8931 | trama | 2 |
| 8932 | traidora | 2 |
| 8933 | traídas | 2 |
| 8934 | tragos | 2 |
| 8935 | trágica | 2 |
| 8936 | tragedia | 2 |
| 8937 | tragarse | 2 |
| 8938 | tragando | 2 |
| 8939 | traeré | 2 |
| 8940 | tráeme | 2 |
| 8941 | trae | 2 |
| 8942 | traducir | 2 |
| 8943 | traducción | 2 |
| 8944 | tradiciones | 2 |
| 8945 | tradicionales | 2 |
| 8946 | trabajadores | 2 |
| 8947 | trabajador | 2 |
| 8948 | trabajaban | 2 |
| 8949 | tostados | 2 |
| 8950 | tosió | 2 |
| 8951 | tosca | 2 |
| 8952 | tortuosas | 2 |
| 8953 | torso | 2 |
| 8954 | torrecilla | 2 |
| 8955 | torquemada | 2 |
| 8956 | torpezas | 2 |
| 8957 | tornillo | 2 |
| 8958 | torneados | 2 |
| 8959 | torneada | 2 |
| 8960 | torero | 2 |
| 8961 | torcidas | 2 |
| 8962 | toques | 2 |
| 8963 | topó | 2 |
| 8964 | topo | 2 |
| 8965 | toos | 2 |
| 8966 | tontiloco | 2 |
| 8967 | tontería | 2 |
| 8968 | tonsurado | 2 |
| 8969 | tonel | 2 |
| 8970 | tomillares | 2 |
| 8971 | tomas | 2 |
| 8972 | tomarle | 2 |
| 8973 | tomándola | 2 |
| 8974 | tolerarlas | 2 |
| 8975 | tocadas | 2 |
| 8976 | toalla | 2 |
| 8977 | to | 2 |
| 8978 | titulaba | 2 |
| 8979 | tirón | 2 |
| 8980 | tirarse | 2 |
| 8981 | tirantez | 2 |
| 8982 | tirantes | 2 |
| 8983 | tirador | 2 |
| 8984 | tirado | 2 |
| 8985 | tipos | 2 |
| 8986 | tíos | 2 |
| 8987 | tinto | 2 |
| 8988 | tintas | 2 |
| 8989 | tino | 2 |
| 8990 | timorato | 2 |
| 8991 | times | 2 |
| 8992 | tiesa | 2 |
| 8993 | tiemblo | 2 |
| 8994 | tiemblan | 2 |
| 8995 | tié | 2 |
| 8996 | tic | 2 |
| 8997 | thorum | 2 |
| 8998 | the | 2 |
| 8999 | tez | 2 |
| 9000 | textos | 2 |
| 9001 | testarudo | 2 |
| 9002 | tesorera | 2 |
| 9003 | tertulio | 2 |
| 9004 | terquedad | 2 |
| 9005 | terminaba | 2 |
| 9006 | tercero | 2 |
| 9007 | terca | 2 |
| 9008 | teóricos | 2 |
| 9009 | teológica | 2 |
| 9010 | teologías | 2 |
| 9011 | teñían | 2 |
| 9012 | tente | 2 |
| 9013 | tentada | 2 |
| 9014 | tenorios | 2 |
| 9015 | teníamos | 2 |
| 9016 | tendremos | 2 |
| 9017 | tendrás | 2 |
| 9018 | tendencias | 2 |
| 9019 | temporales | 2 |
| 9020 | templos | 2 |
| 9021 | temple | 2 |
| 9022 | templado | 2 |
| 9023 | templada | 2 |
| 9024 | temperatura | 2 |
| 9025 | temió | 2 |
| 9026 | temibles | 2 |
| 9027 | temerarias | 2 |
| 9028 | temen | 2 |
| 9029 | temblorosas | 2 |
| 9030 | temblores | 2 |
| 9031 | temblonas | 2 |
| 9032 | telas | 2 |
| 9033 | teje | 2 |
| 9034 | técnicas | 2 |
| 9035 | tarsa | 2 |
| 9036 | tarjeta | 2 |
| 9037 | tardía | 2 |
| 9038 | tardase | 2 |
| 9039 | tapiz | 2 |
| 9040 | tapicero | 2 |
| 9041 | tapete | 2 |
| 9042 | tapadillo | 2 |
| 9043 | tañidos | 2 |
| 9044 | tangible | 2 |
| 9045 | tamaza | 2 |
| 9046 | tamañas | 2 |
| 9047 | tamaña | 2 |
| 9048 | talones | 2 |
| 9049 | talón | 2 |
| 9050 | talla | 2 |
| 9051 | talía | 2 |
| 9052 | talante | 2 |
| 9053 | tacones | 2 |
| 9054 | taco | 2 |
| 9055 | tacaño | 2 |
| 9056 | tac | 2 |
| 9057 | tablero | 2 |
| 9058 | tabernas | 2 |
| 9059 | sutilmente | 2 |
| 9060 | susurro | 2 |
| 9061 | sustituir | 2 |
| 9062 | suspirando | 2 |
| 9063 | suspendida | 2 |
| 9064 | susceptibilidad | 2 |
| 9065 | surtidores | 2 |
| 9066 | supongamos | 2 |
| 9067 | supone | 2 |
| 9068 | suplicando | 2 |
| 9069 | suplicado | 2 |
| 9070 | supiese | 2 |
| 9071 | supieron | 2 |
| 9072 | superlativos | 2 |
| 9073 | sumidos | 2 |
| 9074 | sumidas | 2 |
| 9075 | sumía | 2 |
| 9076 | sumergido | 2 |
| 9077 | sujetar | 2 |
| 9078 | sujetaban | 2 |
| 9079 | sugestiones | 2 |
| 9080 | sugería | 2 |
| 9081 | sufrido | 2 |
| 9082 | sufre | 2 |
| 9083 | suficientemente | 2 |
| 9084 | sueña | 2 |
| 9085 | sueltos | 2 |
| 9086 | suelen | 2 |
| 9087 | sueldo | 2 |
| 9088 | sudeste | 2 |
| 9089 | sucumbiría | 2 |
| 9090 | suculentos | 2 |
| 9091 | suciedad | 2 |
| 9092 | sucedáneos | 2 |
| 9093 | subterráneas | 2 |
| 9094 | subterránea | 2 |
| 9095 | subrepticio | 2 |
| 9096 | subrepticiamente | 2 |
| 9097 | submarina | 2 |
| 9098 | subiera | 2 |
| 9099 | subida | 2 |
| 9100 | subasta | 2 |
| 9101 | subamos | 2 |
| 9102 | suavizar | 2 |
| 9103 | suavizaba | 2 |
| 9104 | sr | 2 |
| 9105 | sostuvo | 2 |
| 9106 | sostengo | 2 |
| 9107 | sospechosa | 2 |
| 9108 | sospechando | 2 |
| 9109 | sospechado | 2 |
| 9110 | sortijas | 2 |
| 9111 | sorprendidas | 2 |
| 9112 | sorprendida | 2 |
| 9113 | sordidez | 2 |
| 9114 | soplos | 2 |
| 9115 | soñolienta | 2 |
| 9116 | soñada | 2 |
| 9117 | sonsonete | 2 |
| 9118 | sonrisita | 2 |
| 9119 | sonido | 2 |
| 9120 | sonaron | 2 |
| 9121 | sonámbulo | 2 |
| 9122 | sonajas | 2 |
| 9123 | sombrillas | 2 |
| 9124 | soltura | 2 |
| 9125 | soltando | 2 |
| 9126 | solícito | 2 |
| 9127 | solicitantes | 2 |
| 9128 | solicitante | 2 |
| 9129 | solicitadas | 2 |
| 9130 | soldada | 2 |
| 9131 | solariegas | 2 |
| 9132 | solapada | 2 |
| 9133 | sofocados | 2 |
| 9134 | socorrido | 2 |
| 9135 | socialistas | 2 |
| 9136 | socarronería | 2 |
| 9137 | socarrona | 2 |
| 9138 | sobro | 2 |
| 9139 | sobrinilla | 2 |
| 9140 | sobrenaturales | 2 |
| 9141 | sobrado | 2 |
| 9142 | soberana | 2 |
| 9143 | situado | 2 |
| 9144 | sistemático | 2 |
| 9145 | sistemáticamente | 2 |
| 9146 | sistemas | 2 |
| 9147 | sirviendo | 2 |
| 9148 | sinuosas | 2 |
| 9149 | síntoma | 2 |
| 9150 | síntesis | 2 |
| 9151 | simulacro | 2 |
| 9152 | simoníaco | 2 |
| 9153 | simoniaco | 2 |
| 9154 | simón | 2 |
| 9155 | similor | 2 |
| 9156 | simétricos | 2 |
| 9157 | simétrico | 2 |
| 9158 | sillones | 2 |
| 9159 | silbantes | 2 |
| 9160 | silbaban | 2 |
| 9161 | siguientes | 2 |
| 9162 | siguen | 2 |
| 9163 | signum | 2 |
| 9164 | signos | 2 |
| 9165 | significativa | 2 |
| 9166 | significar | 2 |
| 9167 | significado | 2 |
| 9168 | significaban | 2 |
| 9169 | significa | 2 |
| 9170 | sierva | 2 |
| 9171 | sienta | 2 |
| 9172 | sicilia | 2 |
| 9173 | sexto | 2 |
| 9174 | setos | 2 |
| 9175 | setentón | 2 |
| 9176 | sesudos | 2 |
| 9177 | seso | 2 |
| 9178 | servidor | 2 |
| 9179 | serre | 2 |
| 9180 | serrar | 2 |
| 9181 | seremos | 2 |
| 9182 | serás | 2 |
| 9183 | seráfico | 2 |
| 9184 | sepultados | 2 |
| 9185 | separó | 2 |
| 9186 | seor | 2 |
| 9187 | señuelo | 2 |
| 9188 | señoronas | 2 |
| 9189 | señorial | 2 |
| 9190 | sentirla | 2 |
| 9191 | sentimentales | 2 |
| 9192 | sentí | 2 |
| 9193 | sentarme | 2 |
| 9194 | sentadas | 2 |
| 9195 | sensuales | 2 |
| 9196 | sensibilidad | 2 |
| 9197 | sendero | 2 |
| 9198 | senda | 2 |
| 9199 | seminaristas | 2 |
| 9200 | semejaban | 2 |
| 9201 | sembrado | 2 |
| 9202 | semblante | 2 |
| 9203 | seguras | 2 |
| 9204 | seguramente | 2 |
| 9205 | segundón | 2 |
| 9206 | seguirla | 2 |
| 9207 | seguiría | 2 |
| 9208 | seglares | 2 |
| 9209 | segada | 2 |
| 9210 | seducido | 2 |
| 9211 | seducía | 2 |
| 9212 | secretaría | 2 |
| 9213 | secaba | 2 |
| 9214 | scortum | 2 |
| 9215 | sazón | 2 |
| 9216 | satisface | 2 |
| 9217 | satín | 2 |
| 9218 | sarcasmos | 2 |
| 9219 | saqué | 2 |
| 9220 | saque | 2 |
| 9221 | sapos | 2 |
| 9222 | santísimo | 2 |
| 9223 | santiguó | 2 |
| 9224 | santidades | 2 |
| 9225 | sans | 2 |
| 9226 | sangría | 2 |
| 9227 | sancionado | 2 |
| 9228 | salvedades | 2 |
| 9229 | salvarle | 2 |
| 9230 | salvarla | 2 |
| 9231 | salvaría | 2 |
| 9232 | sálvamelo | 2 |
| 9233 | salvaban | 2 |
| 9234 | saludaron | 2 |
| 9235 | saludarla | 2 |
| 9236 | saltaron | 2 |
| 9237 | saltaría | 2 |
| 9238 | salsa | 2 |
| 9239 | salí | 2 |
| 9240 | salero | 2 |
| 9241 | saldremos | 2 |
| 9242 | saldrá | 2 |
| 9243 | sajón | 2 |
| 9244 | sacudidas | 2 |
| 9245 | sacro | 2 |
| 9246 | sacristanes | 2 |
| 9247 | sacrílegas | 2 |
| 9248 | sacrificarme | 2 |
| 9249 | sacrificaban | 2 |
| 9250 | sacos | 2 |
| 9251 | sacándole | 2 |
| 9252 | sabrían | 2 |
| 9253 | saborearle | 2 |
| 9254 | saborea | 2 |
| 9255 | saborcillo | 2 |
| 9256 | sabías | 2 |
| 9257 | sabias | 2 |
| 9258 | saberse | 2 |
| 9259 | rutinario | 2 |
| 9260 | rumiar | 2 |
| 9261 | ruega | 2 |
| 9262 | ruborosa | 2 |
| 9263 | rubí | 2 |
| 9264 | rozaban | 2 |
| 9265 | rousseau | 2 |
| 9266 | rotas | 2 |
| 9267 | rostros | 2 |
| 9268 | rosal | 2 |
| 9269 | rosadas | 2 |
| 9270 | rondar | 2 |
| 9271 | roncos | 2 |
| 9272 | rompieron | 2 |
| 9273 | rompe | 2 |
| 9274 | románico | 2 |
| 9275 | romana | 2 |
| 9276 | rollo | 2 |
| 9277 | rolliza | 2 |
| 9278 | rojizos | 2 |
| 9279 | rogar | 2 |
| 9280 | rogado | 2 |
| 9281 | roedores | 2 |
| 9282 | rodrigón | 2 |
| 9283 | rodeo | 2 |
| 9284 | rodeando | 2 |
| 9285 | rodeados | 2 |
| 9286 | rodeadas | 2 |
| 9287 | rodamos | 2 |
| 9288 | rodaba | 2 |
| 9289 | roces | 2 |
| 9290 | robustos | 2 |
| 9291 | robustez | 2 |
| 9292 | robar | 2 |
| 9293 | rizoso | 2 |
| 9294 | rito | 2 |
| 9295 | risueños | 2 |
| 9296 | risueñas | 2 |
| 9297 | riquísima | 2 |
| 9298 | riquezas | 2 |
| 9299 | riñe | 2 |
| 9300 | rinden | 2 |
| 9301 | rigoroso | 2 |
| 9302 | rigorosa | 2 |
| 9303 | rige | 2 |
| 9304 | riesgos | 2 |
| 9305 | riesgo | 2 |
| 9306 | rieron | 2 |
| 9307 | riego | 2 |
| 9308 | ribetes | 2 |
| 9309 | rezo | 2 |
| 9310 | rezan | 2 |
| 9311 | reza | 2 |
| 9312 | revueltos | 2 |
| 9313 | revueltas | 2 |
| 9314 | revuelta | 2 |
| 9315 | revolviendo | 2 |
| 9316 | revolvía | 2 |
| 9317 | revolucionaria | 2 |
| 9318 | revoltosos | 2 |
| 9319 | revistas | 2 |
| 9320 | revés | 2 |
| 9321 | revelado | 2 |
| 9322 | reunión | 2 |
| 9323 | reunían | 2 |
| 9324 | retumbó | 2 |
| 9325 | retumbaba | 2 |
| 9326 | retrocedió | 2 |
| 9327 | retrocedido | 2 |
| 9328 | retroceder | 2 |
| 9329 | retro | 2 |
| 9330 | retraso | 2 |
| 9331 | retrasar | 2 |
| 9332 | retraía | 2 |
| 9333 | retozonas | 2 |
| 9334 | retozona | 2 |
| 9335 | retorcían | 2 |
| 9336 | retorcer | 2 |
| 9337 | retoño | 2 |
| 9338 | retirar | 2 |
| 9339 | resultados | 2 |
| 9340 | resuelva | 2 |
| 9341 | resucitado | 2 |
| 9342 | restituyó | 2 |
| 9343 | restituiría | 2 |
| 9344 | restituido | 2 |
| 9345 | respetuoso | 2 |
| 9346 | respete | 2 |
| 9347 | respetabilidad | 2 |
| 9348 | respectiva | 2 |
| 9349 | respaldo | 2 |
| 9350 | resonó | 2 |
| 9351 | resonar | 2 |
| 9352 | resonancia | 2 |
| 9353 | resolverán | 2 |
| 9354 | resignaban | 2 |
| 9355 | reses | 2 |
| 9356 | reservado | 2 |
| 9357 | reservada | 2 |
| 9358 | resbaladizo | 2 |
| 9359 | resbaladiza | 2 |
| 9360 | resaltando | 2 |
| 9361 | resabios | 2 |
| 9362 | rerum | 2 |
| 9363 | requisitos | 2 |
| 9364 | requiescat | 2 |
| 9365 | repugnaban | 2 |
| 9366 | republicanismo | 2 |
| 9367 | reps | 2 |
| 9368 | representada | 2 |
| 9369 | reprendió | 2 |
| 9370 | repitieron | 2 |
| 9371 | repetido | 2 |
| 9372 | repetición | 2 |
| 9373 | repentinos | 2 |
| 9374 | repatriación | 2 |
| 9375 | repasar | 2 |
| 9376 | repartir | 2 |
| 9377 | reparó | 2 |
| 9378 | reñido | 2 |
| 9379 | reñían | 2 |
| 9380 | renunció | 2 |
| 9381 | renunciara | 2 |
| 9382 | renglones | 2 |
| 9383 | renegado | 2 |
| 9384 | renegaban | 2 |
| 9385 | rendir | 2 |
| 9386 | rendijas | 2 |
| 9387 | rencor | 2 |
| 9388 | renacer | 2 |
| 9389 | remotos | 2 |
| 9390 | remotas | 2 |
| 9391 | remota | 2 |
| 9392 | remontarse | 2 |
| 9393 | remontándose | 2 |
| 9394 | remilgos | 2 |
| 9395 | remedios | 2 |
| 9396 | relativo | 2 |
| 9397 | relativamente | 2 |
| 9398 | rejuvenecía | 2 |
| 9399 | reiría | 2 |
| 9400 | regulares | 2 |
| 9401 | regueros | 2 |
| 9402 | regordeta | 2 |
| 9403 | regocijo | 2 |
| 9404 | reglas | 2 |
| 9405 | registró | 2 |
| 9406 | registro | 2 |
| 9407 | regía | 2 |
| 9408 | regatas | 2 |
| 9409 | regalaban | 2 |
| 9410 | reforma | 2 |
| 9411 | reflexión | 2 |
| 9412 | refiriendo | 2 |
| 9413 | referirse | 2 |
| 9414 | referirlos | 2 |
| 9415 | referido | 2 |
| 9416 | reemplazar | 2 |
| 9417 | reducía | 2 |
| 9418 | redondas | 2 |
| 9419 | redil | 2 |
| 9420 | rededor | 2 |
| 9421 | redactores | 2 |
| 9422 | recurrido | 2 |
| 9423 | rectificó | 2 |
| 9424 | rectificar | 2 |
| 9425 | rectificaba | 2 |
| 9426 | recrearse | 2 |
| 9427 | recrear | 2 |
| 9428 | recreaba | 2 |
| 9429 | recortar | 2 |
| 9430 | recorren | 2 |
| 9431 | recordarle | 2 |
| 9432 | recordado | 2 |
| 9433 | reconocido | 2 |
| 9434 | recónditos | 2 |
| 9435 | reconciliarse | 2 |
| 9436 | reconciliación | 2 |
| 9437 | recomienda | 2 |
| 9438 | recomendar | 2 |
| 9439 | recomendado | 2 |
| 9440 | recoletas | 2 |
| 9441 | recolección | 2 |
| 9442 | recogimiento | 2 |
| 9443 | recogidas | 2 |
| 9444 | recogida | 2 |
| 9445 | recogía | 2 |
| 9446 | recodo | 2 |
| 9447 | recobró | 2 |
| 9448 | reclutas | 2 |
| 9449 | recitó | 2 |
| 9450 | recita | 2 |
| 9451 | recipiente | 2 |
| 9452 | recibiendo | 2 |
| 9453 | recibían | 2 |
| 9454 | recibe | 2 |
| 9455 | rechinar | 2 |
| 9456 | recetó | 2 |
| 9457 | recelo | 2 |
| 9458 | recatadas | 2 |
| 9459 | recargada | 2 |
| 9460 | recaída | 2 |
| 9461 | rebeldía | 2 |
| 9462 | rebelde | 2 |
| 9463 | rebelaba | 2 |
| 9464 | rebaños | 2 |
| 9465 | reata | 2 |
| 9466 | realmente | 2 |
| 9467 | realizar | 2 |
| 9468 | realismo | 2 |
| 9469 | razonables | 2 |
| 9470 | rayitas | 2 |
| 9471 | rayaba | 2 |
| 9472 | rasguño | 2 |
| 9473 | rascaba | 2 |
| 9474 | raros | 2 |
| 9475 | raquíticas | 2 |
| 9476 | rápidamente | 2 |
| 9477 | rapé | 2 |
| 9478 | ranas | 2 |
| 9479 | ramitos | 2 |
| 9480 | raído | 2 |
| 9481 | raída | 2 |
| 9482 | radicalmente | 2 |
| 9483 | radiante | 2 |
| 9484 | racionales | 2 |
| 9485 | raciocinio | 2 |
| 9486 | rabo | 2 |
| 9487 | rabió | 2 |
| 9488 | rabiaba | 2 |
| 9489 | quitarse | 2 |
| 9490 | quitará | 2 |
| 9491 | quitan | 2 |
| 9492 | quisiéramos | 2 |
| 9493 | quintas | 2 |
| 9494 | química | 2 |
| 9495 | quimeras | 2 |
| 9496 | quijote | 2 |
| 9497 | quieto | 2 |
| 9498 | quietas | 2 |
| 9499 | quieta | 2 |
| 9500 | quiénes | 2 |
| 9501 | quienes | 2 |
| 9502 | quiebra | 2 |
| 9503 | quevedo | 2 |
| 9504 | queso | 2 |
| 9505 | querrían | 2 |
| 9506 | queridísimo | 2 |
| 9507 | querías | 2 |
| 9508 | quererte | 2 |
| 9509 | quererle | 2 |
| 9510 | quejado | 2 |
| 9511 | quedé | 2 |
| 9512 | quede | 2 |
| 9513 | quedará | 2 |
| 9514 | quedara | 2 |
| 9515 | quedando | 2 |
| 9516 | quebraban | 2 |
| 9517 | pusieran | 2 |
| 9518 | purísimo | 2 |
| 9519 | puñetazos | 2 |
| 9520 | puntiagudos | 2 |
| 9521 | puntiagudo | 2 |
| 9522 | pundonoroso | 2 |
| 9523 | pun | 2 |
| 9524 | púlpitos | 2 |
| 9525 | pulmón | 2 |
| 9526 | pulgar | 2 |
| 9527 | pulgadas | 2 |
| 9528 | pulcras | 2 |
| 9529 | puestas | 2 |
| 9530 | puerco | 2 |
| 9531 | pueblecillo | 2 |
| 9532 | pucheros | 2 |
| 9533 | puchero | 2 |
| 9534 | publicado | 2 |
| 9535 | púas | 2 |
| 9536 | psicológicos | 2 |
| 9537 | prudentísimo | 2 |
| 9538 | próximos | 2 |
| 9539 | provocativos | 2 |
| 9540 | provocase | 2 |
| 9541 | provocar | 2 |
| 9542 | provocaciones | 2 |
| 9543 | provocaba | 2 |
| 9544 | provisorato | 2 |
| 9545 | provisional | 2 |
| 9546 | provincialismo | 2 |
| 9547 | provinciales | 2 |
| 9548 | protestado | 2 |
| 9549 | protestaban | 2 |
| 9550 | protegido | 2 |
| 9551 | proteger | 2 |
| 9552 | protector | 2 |
| 9553 | protagonista | 2 |
| 9554 | prostituida | 2 |
| 9555 | prosaicos | 2 |
| 9556 | prórroga | 2 |
| 9557 | propusieron | 2 |
| 9558 | proporcionada | 2 |
| 9559 | proponerle | 2 |
| 9560 | proponer | 2 |
| 9561 | propone | 2 |
| 9562 | propietario | 2 |
| 9563 | propicia | 2 |
| 9564 | pronunciar | 2 |
| 9565 | pronuncian | 2 |
| 9566 | pronunciado | 2 |
| 9567 | pronunciaba | 2 |
| 9568 | pronta | 2 |
| 9569 | prolongó | 2 |
| 9570 | prohibidas | 2 |
| 9571 | profusión | 2 |
| 9572 | profundos | 2 |
| 9573 | profesión | 2 |
| 9574 | profesado | 2 |
| 9575 | profesaba | 2 |
| 9576 | profesa | 2 |
| 9577 | profanas | 2 |
| 9578 | profanaba | 2 |
| 9579 | producían | 2 |
| 9580 | producen | 2 |
| 9581 | produce | 2 |
| 9582 | prodigarse | 2 |
| 9583 | prodigado | 2 |
| 9584 | procuraría | 2 |
| 9585 | procul | 2 |
| 9586 | proceso | 2 |
| 9587 | procesiones | 2 |
| 9588 | proceden | 2 |
| 9589 | procaz | 2 |
| 9590 | probarle | 2 |
| 9591 | probando | 2 |
| 9592 | probabilidades | 2 |
| 9593 | probabilidad | 2 |
| 9594 | privilegios | 2 |
| 9595 | privada | 2 |
| 9596 | prisioneros | 2 |
| 9597 | prisionera | 2 |
| 9598 | pringue | 2 |
| 9599 | primitiva | 2 |
| 9600 | primaveras | 2 |
| 9601 | previsto | 2 |
| 9602 | pretendida | 2 |
| 9603 | pretende | 2 |
| 9604 | presto | 2 |
| 9605 | préstamo | 2 |
| 9606 | prestados | 2 |
| 9607 | prestaba | 2 |
| 9608 | preso | 2 |
| 9609 | presidenta | 2 |
| 9610 | presentados | 2 |
| 9611 | presenciaban | 2 |
| 9612 | prescripciones | 2 |
| 9613 | prescindía | 2 |
| 9614 | preparase | 2 |
| 9615 | prepararse | 2 |
| 9616 | preparan | 2 |
| 9617 | preparados | 2 |
| 9618 | preocupa | 2 |
| 9619 | premiar | 2 |
| 9620 | pregunto | 2 |
| 9621 | pregunté | 2 |
| 9622 | preguntárselo | 2 |
| 9623 | preguntando | 2 |
| 9624 | pregonando | 2 |
| 9625 | preferencias | 2 |
| 9626 | preferencia | 2 |
| 9627 | predilecta | 2 |
| 9628 | predicando | 2 |
| 9629 | predicadores | 2 |
| 9630 | predica | 2 |
| 9631 | precocidad | 2 |
| 9632 | precoces | 2 |
| 9633 | preclaros | 2 |
| 9634 | precisar | 2 |
| 9635 | precipitar | 2 |
| 9636 | precipitados | 2 |
| 9637 | preciaba | 2 |
| 9638 | preces | 2 |
| 9639 | prebendados | 2 |
| 9640 | pp | 2 |
| 9641 | potencia | 2 |
| 9642 | postrada | 2 |
| 9643 | postiza | 2 |
| 9644 | postigos | 2 |
| 9645 | postas | 2 |
| 9646 | posibilidad | 2 |
| 9647 | poseer | 2 |
| 9648 | posada | 2 |
| 9649 | pórticos | 2 |
| 9650 | portátil | 2 |
| 9651 | porqué | 2 |
| 9652 | pormenor | 2 |
| 9653 | porcelana | 2 |
| 9654 | popularidad | 2 |
| 9655 | populacho | 2 |
| 9656 | pontificia | 2 |
| 9657 | pontifical | 2 |
| 9658 | ponga | 2 |
| 9659 | ponerme | 2 |
| 9660 | pomares | 2 |
| 9661 | polvos | 2 |
| 9662 | politiquilla | 2 |
| 9663 | políticas | 2 |
| 9664 | polichinela | 2 |
| 9665 | polémicas | 2 |
| 9666 | poéticos | 2 |
| 9667 | podridos | 2 |
| 9668 | podrido | 2 |
| 9669 | podríamos | 2 |
| 9670 | podrán | 2 |
| 9671 | poderes | 2 |
| 9672 | podaba | 2 |
| 9673 | poblaba | 2 |
| 9674 | plomizo | 2 |
| 9675 | pliegue | 2 |
| 9676 | plena | 2 |
| 9677 | pleitos | 2 |
| 9678 | pleito | 2 |
| 9679 | plegarias | 2 |
| 9680 | plazas | 2 |
| 9681 | platónicamente | 2 |
| 9682 | platerescos | 2 |
| 9683 | plastón | 2 |
| 9684 | plástica | 2 |
| 9685 | plantones | 2 |
| 9686 | plano | 2 |
| 9687 | placas | 2 |
| 9688 | pistoletazo | 2 |
| 9689 | pisotón | 2 |
| 9690 | pisarle | 2 |
| 9691 | pisaban | 2 |
| 9692 | piruetas | 2 |
| 9693 | piropo | 2 |
| 9694 | pirámide | 2 |
| 9695 | pintón | 2 |
| 9696 | pintas | 2 |
| 9697 | pintarle | 2 |
| 9698 | pintadas | 2 |
| 9699 | pintaba | 2 |
| 9700 | pinchazos | 2 |
| 9701 | pimientos | 2 |
| 9702 | pilón | 2 |
| 9703 | pilluelos | 2 |
| 9704 | pílades | 2 |
| 9705 | pila | 2 |
| 9706 | pierdo | 2 |
| 9707 | pienses | 2 |
| 9708 | piensas | 2 |
| 9709 | pieles | 2 |
| 9710 | pido | 2 |
| 9711 | pidiera | 2 |
| 9712 | pides | 2 |
| 9713 | picos | 2 |
| 9714 | picarescas | 2 |
| 9715 | picar | 2 |
| 9716 | pican | 2 |
| 9717 | picado | 2 |
| 9718 | picada | 2 |
| 9719 | pías | 2 |
| 9720 | petrica | 2 |
| 9721 | petitorio | 2 |
| 9722 | petaca | 2 |
| 9723 | pestañear | 2 |
| 9724 | pestañas | 2 |
| 9725 | pesos | 2 |
| 9726 | pesimista | 2 |
| 9727 | pésima | 2 |
| 9728 | pescaron | 2 |
| 9729 | pesando | 2 |
| 9730 | pésame | 2 |
| 9731 | pertenecían | 2 |
| 9732 | persuadir | 2 |
| 9733 | perspicaz | 2 |
| 9734 | personilla | 2 |
| 9735 | personalidad | 2 |
| 9736 | personales | 2 |
| 9737 | persigue | 2 |
| 9738 | perseguidas | 2 |
| 9739 | perseguida | 2 |
| 9740 | perpetuo | 2 |
| 9741 | permitirse | 2 |
| 9742 | permitiéndose | 2 |
| 9743 | permítame | 2 |
| 9744 | permanecer | 2 |
| 9745 | perla | 2 |
| 9746 | perjudica | 2 |
| 9747 | períodos | 2 |
| 9748 | pergamino | 2 |
| 9749 | perfiles | 2 |
| 9750 | perdones | 2 |
| 9751 | perdóneme | 2 |
| 9752 | perdonarla | 2 |
| 9753 | pérdida | 2 |
| 9754 | perdían | 2 |
| 9755 | perderlo | 2 |
| 9756 | perderle | 2 |
| 9757 | percha | 2 |
| 9758 | peón | 2 |
| 9759 | peñón | 2 |
| 9760 | peña | 2 |
| 9761 | pensativa | 2 |
| 9762 | pensase | 2 |
| 9763 | pensándolo | 2 |
| 9764 | penitencias | 2 |
| 9765 | penetrantes | 2 |
| 9766 | penetra | 2 |
| 9767 | pendón | 2 |
| 9768 | pendía | 2 |
| 9769 | peluca | 2 |
| 9770 | pelota | 2 |
| 9771 | peinaba | 2 |
| 9772 | pegar | 2 |
| 9773 | pegaban | 2 |
| 9774 | pega | 2 |
| 9775 | pedradas | 2 |
| 9776 | pedirla | 2 |
| 9777 | pediría | 2 |
| 9778 | pediré | 2 |
| 9779 | pedestre | 2 |
| 9780 | pedante | 2 |
| 9781 | pedagógico | 2 |
| 9782 | pechuga | 2 |
| 9783 | pecaminoso | 2 |
| 9784 | pecaminosas | 2 |
| 9785 | pecadores | 2 |
| 9786 | pecador | 2 |
| 9787 | pecaban | 2 |
| 9788 | pausas | 2 |
| 9789 | pausadas | 2 |
| 9790 | pausada | 2 |
| 9791 | patrón | 2 |
| 9792 | patrimonio | 2 |
| 9793 | pato | 2 |
| 9794 | patética | 2 |
| 9795 | patente | 2 |
| 9796 | patatas | 2 |
| 9797 | patata | 2 |
| 9798 | pataleo | 2 |
| 9799 | patada | 2 |
| 9800 | pata | 2 |
| 9801 | pastoril | 2 |
| 9802 | pastoral | 2 |
| 9803 | pasmos | 2 |
| 9804 | pasmo | 2 |
| 9805 | pásmese | 2 |
| 9806 | pasiva | 2 |
| 9807 | pasioncilla | 2 |
| 9808 | pasiegos | 2 |
| 9809 | pasearse | 2 |
| 9810 | pascuas | 2 |
| 9811 | pasatiempos | 2 |
| 9812 | pasas | 2 |
| 9813 | pasaría | 2 |
| 9814 | pasajero | 2 |
| 9815 | pasajeras | 2 |
| 9816 | pasadizos | 2 |
| 9817 | partir | 2 |
| 9818 | partículas | 2 |
| 9819 | participó | 2 |
| 9820 | participar | 2 |
| 9821 | partía | 2 |
| 9822 | parsimonia | 2 |
| 9823 | parroquianos | 2 |
| 9824 | párrocos | 2 |
| 9825 | párrafo | 2 |
| 9826 | parques | 2 |
| 9827 | paroxismo | 2 |
| 9828 | parodias | 2 |
| 9829 | pareciese | 2 |
| 9830 | parecerían | 2 |
| 9831 | parecería | 2 |
| 9832 | parecerá | 2 |
| 9833 | pardos | 2 |
| 9834 | pardiez | 2 |
| 9835 | parcería | 2 |
| 9836 | parase | 2 |
| 9837 | pararse | 2 |
| 9838 | parándose | 2 |
| 9839 | páramo | 2 |
| 9840 | paraje | 2 |
| 9841 | paraban | 2 |
| 9842 | paquita | 2 |
| 9843 | papas | 2 |
| 9844 | papando | 2 |
| 9845 | papanatas | 2 |
| 9846 | pañales | 2 |
| 9847 | panzudas | 2 |
| 9848 | pantorrillas | 2 |
| 9849 | pantoja | 2 |
| 9850 | paniaguados | 2 |
| 9851 | panes | 2 |
| 9852 | palpable | 2 |
| 9853 | palomar | 2 |
| 9854 | palmera | 2 |
| 9855 | palidece | 2 |
| 9856 | palaciegas | 2 |
| 9857 | paje | 2 |
| 9858 | pajas | 2 |
| 9859 | pájara | 2 |
| 9860 | paisanos | 2 |
| 9861 | pagó | 2 |
| 9862 | pagará | 2 |
| 9863 | pagada | 2 |
| 9864 | padrenuestros | 2 |
| 9865 | padeció | 2 |
| 9866 | padeciendo | 2 |
| 9867 | pacífica | 2 |
| 9868 | pace | 2 |
| 9869 | oyentes | 2 |
| 9870 | oyéndole | 2 |
| 9871 | oyen | 2 |
| 9872 | osos | 2 |
| 9873 | osaría | 2 |
| 9874 | osa | 2 |
| 9875 | ortodoxos | 2 |
| 9876 | ortigas | 2 |
| 9877 | ornitólogo | 2 |
| 9878 | ornamento | 2 |
| 9879 | orlada | 2 |
| 9880 | originado | 2 |
| 9881 | orientales | 2 |
| 9882 | orfandad | 2 |
| 9883 | ordenó | 2 |
| 9884 | ordenanza | 2 |
| 9885 | ordenados | 2 |
| 9886 | ordena | 2 |
| 9887 | or | 2 |
| 9888 | opuesto | 2 |
| 9889 | optimista | 2 |
| 9890 | oprimido | 2 |
| 9891 | oprime | 2 |
| 9892 | oponían | 2 |
| 9893 | operaciones | 2 |
| 9894 | opacas | 2 |
| 9895 | onzas | 2 |
| 9896 | ondulaciones | 2 |
| 9897 | olvidarse | 2 |
| 9898 | olvidaría | 2 |
| 9899 | olorosa | 2 |
| 9900 | olfateado | 2 |
| 9901 | ojival | 2 |
| 9902 | ojillos | 2 |
| 9903 | ojeroso | 2 |
| 9904 | oírlas | 2 |
| 9905 | oigan | 2 |
| 9906 | oidium | 2 |
| 9907 | oí | 2 |
| 9908 | ofrezca | 2 |
| 9909 | ofrenda | 2 |
| 9910 | ofreciera | 2 |
| 9911 | ofrecerle | 2 |
| 9912 | ofrecen | 2 |
| 9913 | oficialmente | 2 |
| 9914 | ofensa | 2 |
| 9915 | ofendía | 2 |
| 9916 | odios | 2 |
| 9917 | odiaba | 2 |
| 9918 | oda | 2 |
| 9919 | ocurrencias | 2 |
| 9920 | ocupase | 2 |
| 9921 | ocupados | 2 |
| 9922 | ocultárselo | 2 |
| 9923 | ocultarlo | 2 |
| 9924 | ociosos | 2 |
| 9925 | ocioso | 2 |
| 9926 | ociosidad | 2 |
| 9927 | ochocientos | 2 |
| 9928 | ocasionadas | 2 |
| 9929 | obstinó | 2 |
| 9930 | obstinado | 2 |
| 9931 | obstante | 2 |
| 9932 | observando | 2 |
| 9933 | observa | 2 |
| 9934 | obsequios | 2 |
| 9935 | obsequio | 2 |
| 9936 | obsequiándote | 2 |
| 9937 | obscenidades | 2 |
| 9938 | obrero | 2 |
| 9939 | obligo | 2 |
| 9940 | obligándole | 2 |
| 9941 | obligan | 2 |
| 9942 | obedeciendo | 2 |
| 9943 | obedecido | 2 |
| 9944 | nupcial | 2 |
| 9945 | nueces | 2 |
| 9946 | nubecilla | 2 |
| 9947 | novelesca | 2 |
| 9948 | notase | 2 |
| 9949 | nocturnas | 2 |
| 9950 | nobis | 2 |
| 9951 | niegue | 2 |
| 9952 | nido | 2 |
| 9953 | nichos | 2 |
| 9954 | nevada | 2 |
| 9955 | neuralgia | 2 |
| 9956 | nerviosilla | 2 |
| 9957 | negruzco | 2 |
| 9958 | negruzca | 2 |
| 9959 | negrura | 2 |
| 9960 | negarme | 2 |
| 9961 | negarle | 2 |
| 9962 | negando | 2 |
| 9963 | negaciones | 2 |
| 9964 | negación | 2 |
| 9965 | necias | 2 |
| 9966 | necesitará | 2 |
| 9967 | necesitado | 2 |
| 9968 | necesitaban | 2 |
| 9969 | neblina | 2 |
| 9970 | nazarena | 2 |
| 9971 | navegar | 2 |
| 9972 | nauseabundo | 2 |
| 9973 | naturalezas | 2 |
| 9974 | natura | 2 |
| 9975 | natillas | 2 |
| 9976 | narrador | 2 |
| 9977 | naranja | 2 |
| 9978 | nado | 2 |
| 9979 | nación | 2 |
| 9980 | mutuas | 2 |
| 9981 | muslo | 2 |
| 9982 | músico | 2 |
| 9983 | muscular | 2 |
| 9984 | murmura | 2 |
| 9985 | murmullos | 2 |
| 9986 | murillo | 2 |
| 9987 | muñeca | 2 |
| 9988 | mundanos | 2 |
| 9989 | mundana | 2 |
| 9990 | muevas | 2 |
| 9991 | muestra | 2 |
| 9992 | mueca | 2 |
| 9993 | mudó | 2 |
| 9994 | mudéjar | 2 |
| 9995 | mudarse | 2 |
| 9996 | mudar | 2 |
| 9997 | mudaba | 2 |
| 9998 | muchísimo | 2 |
| 9999 | muchedumbres | 2 |
| 10000 | mozalbete | 2 |
| 10001 | movile | 2 |
| 10002 | motín | 2 |
| 10003 | mostrencos | 2 |
| 10004 | mostrarse | 2 |
| 10005 | mosquitos | 2 |
| 10006 | mosquito | 2 |
| 10007 | mortificación | 2 |
| 10008 | mortifica | 2 |
| 10009 | moro | 2 |
| 10010 | morirás | 2 |
| 10011 | moreto | 2 |
| 10012 | mordiéndose | 2 |
| 10013 | mordiendo | 2 |
| 10014 | morderla | 2 |
| 10015 | moratín | 2 |
| 10016 | morados | 2 |
| 10017 | moqueta | 2 |
| 10018 | montañesa | 2 |
| 10019 | monótonos | 2 |
| 10020 | monísima | 2 |
| 10021 | molina | 2 |
| 10022 | molière | 2 |
| 10023 | molicie | 2 |
| 10024 | molestias | 2 |
| 10025 | molestas | 2 |
| 10026 | molestarla | 2 |
| 10027 | molestado | 2 |
| 10028 | mole | 2 |
| 10029 | molde | 2 |
| 10030 | mojigata | 2 |
| 10031 | mojadura | 2 |
| 10032 | mohín | 2 |
| 10033 | modificar | 2 |
| 10034 | modernas | 2 |
| 10035 | moderada | 2 |
| 10036 | modelada | 2 |
| 10037 | mister | 2 |
| 10038 | misiones | 2 |
| 10039 | misericordioso | 2 |
| 10040 | miro | 2 |
| 10041 | mírele | 2 |
| 10042 | mirarlo | 2 |
| 10043 | mirarles | 2 |
| 10044 | mirándose | 2 |
| 10045 | mirándole | 2 |
| 10046 | minoría | 2 |
| 10047 | mínimo | 2 |
| 10048 | mínguez | 2 |
| 10049 | minerva | 2 |
| 10050 | minarle | 2 |
| 10051 | minar | 2 |
| 10052 | minando | 2 |
| 10053 | mimoso | 2 |
| 10054 | mimosas | 2 |
| 10055 | mimos | 2 |
| 10056 | millonaria | 2 |
| 10057 | miliciano | 2 |
| 10058 | miles | 2 |
| 10059 | migajas | 2 |
| 10060 | miente | 2 |
| 10061 | mieles | 2 |
| 10062 | miedosos | 2 |
| 10063 | midiendo | 2 |
| 10064 | midas | 2 |
| 10065 | microscopio | 2 |
| 10066 | mías | 2 |
| 10067 | mezquina | 2 |
| 10068 | mezclar | 2 |
| 10069 | meticulosa | 2 |
| 10070 | meten | 2 |
| 10071 | mete | 2 |
| 10072 | metálicas | 2 |
| 10073 | metafísico | 2 |
| 10074 | meta | 2 |
| 10075 | mesándose | 2 |
| 10076 | meriendas | 2 |
| 10077 | meretriz | 2 |
| 10078 | mercancía | 2 |
| 10079 | mercaderes | 2 |
| 10080 | menudencias | 2 |
| 10081 | menudas | 2 |
| 10082 | mentecato | 2 |
| 10083 | menoscabo | 2 |
| 10084 | menores | 2 |
| 10085 | menear | 2 |
| 10086 | melosa | 2 |
| 10087 | melódica | 2 |
| 10088 | meléndez | 2 |
| 10089 | mejorcito | 2 |
| 10090 | mejorado | 2 |
| 10091 | mefistófeles | 2 |
| 10092 | medrando | 2 |
| 10093 | meditaría | 2 |
| 10094 | meditaciones | 2 |
| 10095 | meditabundo | 2 |
| 10096 | medido | 2 |
| 10097 | mediar | 2 |
| 10098 | mediana | 2 |
| 10099 | mediados | 2 |
| 10100 | medía | 2 |
| 10101 | medallón | 2 |
| 10102 | medallas | 2 |
| 10103 | mechones | 2 |
| 10104 | mecedoras | 2 |
| 10105 | mazorca | 2 |
| 10106 | matutinas | 2 |
| 10107 | matrona | 2 |
| 10108 | matrimonios | 2 |
| 10109 | matiz | 2 |
| 10110 | matilde | 2 |
| 10111 | matarlos | 2 |
| 10112 | matanzas | 2 |
| 10113 | matado | 2 |
| 10114 | mástil | 2 |
| 10115 | masculino | 2 |
| 10116 | mascar | 2 |
| 10117 | mascaba | 2 |
| 10118 | mártires | 2 |
| 10119 | marrullero | 2 |
| 10120 | marrón | 2 |
| 10121 | maroto | 2 |
| 10122 | margarita | 2 |
| 10123 | marejada | 2 |
| 10124 | marearle | 2 |
| 10125 | mareada | 2 |
| 10126 | mareaban | 2 |
| 10127 | marcho | 2 |
| 10128 | maquiavelo | 2 |
| 10129 | maquiavélico | 2 |
| 10130 | manzanos | 2 |
| 10131 | manuel | 2 |
| 10132 | manteca | 2 |
| 10133 | mansión | 2 |
| 10134 | mansedumbre | 2 |
| 10135 | manrique | 2 |
| 10136 | manotadas | 2 |
| 10137 | manolito | 2 |
| 10138 | manolé | 2 |
| 10139 | manirroto | 2 |
| 10140 | maniqueos | 2 |
| 10141 | maniático | 2 |
| 10142 | maníaco | 2 |
| 10143 | manejo | 2 |
| 10144 | maneje | 2 |
| 10145 | manejando | 2 |
| 10146 | maneja | 2 |
| 10147 | mandatos | 2 |
| 10148 | mandato | 2 |
| 10149 | mandan | 2 |
| 10150 | mancharse | 2 |
| 10151 | manchado | 2 |
| 10152 | mancebos | 2 |
| 10153 | mampara | 2 |
| 10154 | mamarracho | 2 |
| 10155 | maltratados | 2 |
| 10156 | maltratada | 2 |
| 10157 | malsano | 2 |
| 10158 | malsana | 2 |
| 10159 | malorum | 2 |
| 10160 | maliciosas | 2 |
| 10161 | malicias | 2 |
| 10162 | malhumorado | 2 |
| 10163 | maldiciones | 2 |
| 10164 | maldición | 2 |
| 10165 | maldicientes | 2 |
| 10166 | maldiciente | 2 |
| 10167 | maldice | 2 |
| 10168 | maldecían | 2 |
| 10169 | maldecía | 2 |
| 10170 | majestuosamente | 2 |
| 10171 | magullaba | 2 |
| 10172 | magnetismo | 2 |
| 10173 | mágica | 2 |
| 10174 | magia | 2 |
| 10175 | magdalena | 2 |
| 10176 | madrugón | 2 |
| 10177 | madrileños | 2 |
| 10178 | macizos | 2 |
| 10179 | lutero | 2 |
| 10180 | lunes | 2 |
| 10181 | lune | 2 |
| 10182 | lunar | 2 |
| 10183 | luminoso | 2 |
| 10184 | lujosas | 2 |
| 10185 | lugarteniente | 2 |
| 10186 | lugareños | 2 |
| 10187 | luciría | 2 |
| 10188 | lucientes | 2 |
| 10189 | luciente | 2 |
| 10190 | lucecillas | 2 |
| 10191 | luce | 2 |
| 10192 | lucas | 2 |
| 10193 | lotería | 2 |
| 10194 | lona | 2 |
| 10195 | lomos | 2 |
| 10196 | lograr | 2 |
| 10197 | logrado | 2 |
| 10198 | locuacidad | 2 |
| 10199 | locales | 2 |
| 10200 | llueva | 2 |
| 10201 | llovido | 2 |
| 10202 | llovería | 2 |
| 10203 | lloras | 2 |
| 10204 | llevo | 2 |
| 10205 | llevas | 2 |
| 10206 | llevárselo | 2 |
| 10207 | llevarse | 2 |
| 10208 | llevarle | 2 |
| 10209 | llevaría | 2 |
| 10210 | llevará | 2 |
| 10211 | llevándola | 2 |
| 10212 | llevamos | 2 |
| 10213 | llenaron | 2 |
| 10214 | llenar | 2 |
| 10215 | llegas | 2 |
| 10216 | llegaran | 2 |
| 10217 | llegará | 2 |
| 10218 | llegamos | 2 |
| 10219 | llavín | 2 |
| 10220 | llantos | 2 |
| 10221 | llana | 2 |
| 10222 | llamo | 2 |
| 10223 | llames | 2 |
| 10224 | llamémoslo | 2 |
| 10225 | llamaron | 2 |
| 10226 | llamaré | 2 |
| 10227 | llamamos | 2 |
| 10228 | llamadas | 2 |
| 10229 | liturgia | 2 |
| 10230 | literatas | 2 |
| 10231 | literarios | 2 |
| 10232 | listos | 2 |
| 10233 | listas | 2 |
| 10234 | lisonjas | 2 |
| 10235 | lírico | 2 |
| 10236 | lira | 2 |
| 10237 | liquidación | 2 |
| 10238 | linajudos | 2 |
| 10239 | linajudo | 2 |
| 10240 | linaje | 2 |
| 10241 | limpió | 2 |
| 10242 | limpiaba | 2 |
| 10243 | ligorio | 2 |
| 10244 | ligerezas | 2 |
| 10245 | liebres | 2 |
| 10246 | lides | 2 |
| 10247 | licores | 2 |
| 10248 | lícitos | 2 |
| 10249 | licencia | 2 |
| 10250 | librotes | 2 |
| 10251 | librería | 2 |
| 10252 | librepensadores | 2 |
| 10253 | librase | 2 |
| 10254 | librarla | 2 |
| 10255 | librándose | 2 |
| 10256 | libraba | 2 |
| 10257 | libertinos | 2 |
| 10258 | libertades | 2 |
| 10259 | liberalotes | 2 |
| 10260 | liberalote | 2 |
| 10261 | li | 2 |
| 10262 | levítico | 2 |
| 10263 | levitas | 2 |
| 10264 | leves | 2 |
| 10265 | levante | 2 |
| 10266 | levantaron | 2 |
| 10267 | levantándolo | 2 |
| 10268 | levantada | 2 |
| 10269 | letrina | 2 |
| 10270 | letrero | 2 |
| 10271 | lesa | 2 |
| 10272 | lentitud | 2 |
| 10273 | lengüeta | 2 |
| 10274 | leída | 2 |
| 10275 | legítimo | 2 |
| 10276 | legitimidad | 2 |
| 10277 | legítima | 2 |
| 10278 | leerlo | 2 |
| 10279 | leerlas | 2 |
| 10280 | leerla | 2 |
| 10281 | lee | 2 |
| 10282 | lear | 2 |
| 10283 | leandro | 2 |
| 10284 | lavandera | 2 |
| 10285 | lavan | 2 |
| 10286 | laurel | 2 |
| 10287 | latón | 2 |
| 10288 | latino | 2 |
| 10289 | latines | 2 |
| 10290 | latamente | 2 |
| 10291 | lascivas | 2 |
| 10292 | lanzas | 2 |
| 10293 | lánguida | 2 |
| 10294 | lamían | 2 |
| 10295 | lamentó | 2 |
| 10296 | lamentándose | 2 |
| 10297 | ladrona | 2 |
| 10298 | ladró | 2 |
| 10299 | lacónicamente | 2 |
| 10300 | lacayo | 2 |
| 10301 | labrar | 2 |
| 10302 | labrador | 2 |
| 10303 | labores | 2 |
| 10304 | kilómetros | 2 |
| 10305 | juvenil | 2 |
| 10306 | jurando | 2 |
| 10307 | jura | 2 |
| 10308 | júpiter | 2 |
| 10309 | juntan | 2 |
| 10310 | jugando | 2 |
| 10311 | jugado | 2 |
| 10312 | jueves | 2 |
| 10313 | judicial | 2 |
| 10314 | judías | 2 |
| 10315 | jubón | 2 |
| 10316 | jubiló | 2 |
| 10317 | joyas | 2 |
| 10318 | jornada | 2 |
| 10319 | joco | 2 |
| 10320 | jinetes | 2 |
| 10321 | jilguero | 2 |
| 10322 | jesuitismo | 2 |
| 10323 | jefes | 2 |
| 10324 | jaulas | 2 |
| 10325 | jaspe | 2 |
| 10326 | jarrones | 2 |
| 10327 | jarro | 2 |
| 10328 | jarras | 2 |
| 10329 | jaquet | 2 |
| 10330 | japoneses | 2 |
| 10331 | jamonas | 2 |
| 10332 | jactancia | 2 |
| 10333 | jactaba | 2 |
| 10334 | italiano | 2 |
| 10335 | italia | 2 |
| 10336 | isabel | 2 |
| 10337 | irrupción | 2 |
| 10338 | irritarse | 2 |
| 10339 | irritara | 2 |
| 10340 | irritante | 2 |
| 10341 | irrisoria | 2 |
| 10342 | irrevocables | 2 |
| 10343 | irrevocable | 2 |
| 10344 | irresponsable | 2 |
| 10345 | irrespetuoso | 2 |
| 10346 | irrespetuosas | 2 |
| 10347 | irreprochables | 2 |
| 10348 | irreparable | 2 |
| 10349 | irreflexiva | 2 |
| 10350 | irnos | 2 |
| 10351 | irguió | 2 |
| 10352 | invulnerable | 2 |
| 10353 | involuntario | 2 |
| 10354 | invocando | 2 |
| 10355 | invitaba | 2 |
| 10356 | inventores | 2 |
| 10357 | inventando | 2 |
| 10358 | inventada | 2 |
| 10359 | inventaba | 2 |
| 10360 | inventa | 2 |
| 10361 | invencibles | 2 |
| 10362 | invasión | 2 |
| 10363 | invariable | 2 |
| 10364 | invadido | 2 |
| 10365 | inútilmente | 2 |
| 10366 | inutilidad | 2 |
| 10367 | inundó | 2 |
| 10368 | inundaban | 2 |
| 10369 | intransigencia | 2 |
| 10370 | intolerancia | 2 |
| 10371 | intolerable | 2 |
| 10372 | intimar | 2 |
| 10373 | intervino | 2 |
| 10374 | intervención | 2 |
| 10375 | intervalo | 2 |
| 10376 | interrupciones | 2 |
| 10377 | interrumpir | 2 |
| 10378 | interrumpiendo | 2 |
| 10379 | interrumpían | 2 |
| 10380 | interpretado | 2 |
| 10381 | interpretaba | 2 |
| 10382 | interno | 2 |
| 10383 | intermedio | 2 |
| 10384 | interina | 2 |
| 10385 | interesar | 2 |
| 10386 | interesados | 2 |
| 10387 | interesada | 2 |
| 10388 | inter | 2 |
| 10389 | intentó | 2 |
| 10390 | intempestiva | 2 |
| 10391 | inteligible | 2 |
| 10392 | integridad | 2 |
| 10393 | insustanciales | 2 |
| 10394 | insultante | 2 |
| 10395 | insultaban | 2 |
| 10396 | insulta | 2 |
| 10397 | insufribles | 2 |
| 10398 | insuficiente | 2 |
| 10399 | instruido | 2 |
| 10400 | instrucción | 2 |
| 10401 | instintiva | 2 |
| 10402 | instantes | 2 |
| 10403 | inspiraban | 2 |
| 10404 | inspira | 2 |
| 10405 | inspección | 2 |
| 10406 | insistían | 2 |
| 10407 | insistente | 2 |
| 10408 | insistencia | 2 |
| 10409 | insípidos | 2 |
| 10410 | insípida | 2 |
| 10411 | insinuarle | 2 |
| 10412 | insinuación | 2 |
| 10413 | insinuaba | 2 |
| 10414 | insignes | 2 |
| 10415 | insensiblemente | 2 |
| 10416 | inscripciones | 2 |
| 10417 | insana | 2 |
| 10418 | inquina | 2 |
| 10419 | inquietudes | 2 |
| 10420 | inquietas | 2 |
| 10421 | inopinada | 2 |
| 10422 | inofensiva | 2 |
| 10423 | inmóviles | 2 |
| 10424 | inmemorial | 2 |
| 10425 | inmediato | 2 |
| 10426 | injusto | 2 |
| 10427 | injertar | 2 |
| 10428 | iniquidad | 2 |
| 10429 | inimitable | 2 |
| 10430 | inhabitable | 2 |
| 10431 | inglaterra | 2 |
| 10432 | ingenioso | 2 |
| 10433 | ingenios | 2 |
| 10434 | infundir | 2 |
| 10435 | ínfulas | 2 |
| 10436 | influyentes | 2 |
| 10437 | influyente | 2 |
| 10438 | influye | 2 |
| 10439 | influía | 2 |
| 10440 | inflo | 2 |
| 10441 | inflexible | 2 |
| 10442 | inflamados | 2 |
| 10443 | infinitos | 2 |
| 10444 | infiltraba | 2 |
| 10445 | infieles | 2 |
| 10446 | infernales | 2 |
| 10447 | infanzones | 2 |
| 10448 | infantiles | 2 |
| 10449 | infaliblemente | 2 |
| 10450 | inesperado | 2 |
| 10451 | inesperada | 2 |
| 10452 | industrias | 2 |
| 10453 | industriales | 2 |
| 10454 | individuo | 2 |
| 10455 | indignada | 2 |
| 10456 | indicios | 2 |
| 10457 | indescriptible | 2 |
| 10458 | independiente | 2 |
| 10459 | indefinidamente | 2 |
| 10460 | indefectiblemente | 2 |
| 10461 | indecente | 2 |
| 10462 | incrustaba | 2 |
| 10463 | incorporándose | 2 |
| 10464 | incompleta | 2 |
| 10465 | incompatibles | 2 |
| 10466 | incomparable | 2 |
| 10467 | incomoda | 2 |
| 10468 | incólume | 2 |
| 10469 | incógnito | 2 |
| 10470 | inclinaron | 2 |
| 10471 | inclinar | 2 |
| 10472 | incitante | 2 |
| 10473 | incalificable | 2 |
| 10474 | inaugural | 2 |
| 10475 | impurezas | 2 |
| 10476 | impunemente | 2 |
| 10477 | impuestas | 2 |
| 10478 | impúdica | 2 |
| 10479 | imprudencias | 2 |
| 10480 | improvisar | 2 |
| 10481 | improvisado | 2 |
| 10482 | improvisadas | 2 |
| 10483 | improvisaba | 2 |
| 10484 | impropia | 2 |
| 10485 | impresionable | 2 |
| 10486 | importunas | 2 |
| 10487 | importación | 2 |
| 10488 | imponente | 2 |
| 10489 | impondría | 2 |
| 10490 | implícitamente | 2 |
| 10491 | impía | 2 |
| 10492 | imperturbable | 2 |
| 10493 | impertinencia | 2 |
| 10494 | impedían | 2 |
| 10495 | imparcialmente | 2 |
| 10496 | impacientarse | 2 |
| 10497 | imitaré | 2 |
| 10498 | imitador | 2 |
| 10499 | imaginando | 2 |
| 10500 | imaginado | 2 |
| 10501 | ilumine | 2 |
| 10502 | iluminando | 2 |
| 10503 | iluminaban | 2 |
| 10504 | iii | 2 |
| 10505 | ignorarlo | 2 |
| 10506 | idolillo | 2 |
| 10507 | idólatra | 2 |
| 10508 | idiotas | 2 |
| 10509 | ida | 2 |
| 10510 | íbamos | 2 |
| 10511 | huyo | 2 |
| 10512 | hurto | 2 |
| 10513 | hurtadillas | 2 |
| 10514 | huracán | 2 |
| 10515 | hundiendo | 2 |
| 10516 | hunde | 2 |
| 10517 | humillar | 2 |
| 10518 | humillaciones | 2 |
| 10519 | humanos | 2 |
| 10520 | huiré | 2 |
| 10521 | huida | 2 |
| 10522 | huí | 2 |
| 10523 | huesuda | 2 |
| 10524 | huéspedes | 2 |
| 10525 | huella | 2 |
| 10526 | huecos | 2 |
| 10527 | hueca | 2 |
| 10528 | hubiéramos | 2 |
| 10529 | hoyo | 2 |
| 10530 | hostias | 2 |
| 10531 | hortera | 2 |
| 10532 | horrorosos | 2 |
| 10533 | horroriza | 2 |
| 10534 | horribles | 2 |
| 10535 | hornos | 2 |
| 10536 | hornilla | 2 |
| 10537 | hornacinas | 2 |
| 10538 | horizontes | 2 |
| 10539 | horizontales | 2 |
| 10540 | honradas | 2 |
| 10541 | honores | 2 |
| 10542 | honesto | 2 |
| 10543 | honda | 2 |
| 10544 | homo | 2 |
| 10545 | holanda | 2 |
| 10546 | hojeó | 2 |
| 10547 | hojalata | 2 |
| 10548 | hoc | 2 |
| 10549 | históricos | 2 |
| 10550 | históricas | 2 |
| 10551 | historias | 2 |
| 10552 | hisopos | 2 |
| 10553 | hiponax | 2 |
| 10554 | hinchando | 2 |
| 10555 | hinchados | 2 |
| 10556 | higienista | 2 |
| 10557 | hierático | 2 |
| 10558 | hierática | 2 |
| 10559 | hieran | 2 |
| 10560 | hiel | 2 |
| 10561 | hicieran | 2 |
| 10562 | heroicas | 2 |
| 10563 | herodes | 2 |
| 10564 | hermosísimo | 2 |
| 10565 | hermoseado | 2 |
| 10566 | hermanita | 2 |
| 10567 | heridas | 2 |
| 10568 | herejías | 2 |
| 10569 | herederos | 2 |
| 10570 | heredero | 2 |
| 10571 | herederas | 2 |
| 10572 | heredera | 2 |
| 10573 | heredara | 2 |
| 10574 | hércules | 2 |
| 10575 | herbario | 2 |
| 10576 | helados | 2 |
| 10577 | hechizado | 2 |
| 10578 | hebdomadario | 2 |
| 10579 | hayas | 2 |
| 10580 | hastiado | 2 |
| 10581 | harto | 2 |
| 10582 | hartazgo | 2 |
| 10583 | hambriento | 2 |
| 10584 | hallaba | 2 |
| 10585 | halagaría | 2 |
| 10586 | hacinados | 2 |
| 10587 | haciendas | 2 |
| 10588 | hachazos | 2 |
| 10589 | hacernos | 2 |
| 10590 | hacerlos | 2 |
| 10591 | hables | 2 |
| 10592 | hablarte | 2 |
| 10593 | hablarse | 2 |
| 10594 | hablarme | 2 |
| 10595 | hablarían | 2 |
| 10596 | habladores | 2 |
| 10597 | habladora | 2 |
| 10598 | hábitos | 2 |
| 10599 | habitaban | 2 |
| 10600 | habitaba | 2 |
| 10601 | habano | 2 |
| 10602 | gustar | 2 |
| 10603 | gustaban | 2 |
| 10604 | gusano | 2 |
| 10605 | gula | 2 |
| 10606 | guitarra | 2 |
| 10607 | guirnaldas | 2 |
| 10608 | guiñó | 2 |
| 10609 | guillotina | 2 |
| 10610 | guiarla | 2 |
| 10611 | guiada | 2 |
| 10612 | guía | 2 |
| 10613 | guarnición | 2 |
| 10614 | guardo | 2 |
| 10615 | guardaría | 2 |
| 10616 | guardado | 2 |
| 10617 | gruta | 2 |
| 10618 | grotescos | 2 |
| 10619 | grosería | 2 |
| 10620 | gritase | 2 |
| 10621 | gritado | 2 |
| 10622 | griegas | 2 |
| 10623 | griega | 2 |
| 10624 | grava | 2 |
| 10625 | gratuitos | 2 |
| 10626 | grasa | 2 |
| 10627 | granizo | 2 |
| 10628 | graciosísimo | 2 |
| 10629 | gracejo | 2 |
| 10630 | gozó | 2 |
| 10631 | gozándose | 2 |
| 10632 | götinga | 2 |
| 10633 | gótico | 2 |
| 10634 | gordas | 2 |
| 10635 | golosa | 2 |
| 10636 | goda | 2 |
| 10637 | goces | 2 |
| 10638 | gobernaba | 2 |
| 10639 | gitana | 2 |
| 10640 | giró | 2 |
| 10641 | gigante | 2 |
| 10642 | gesticulaban | 2 |
| 10643 | gesticulaba | 2 |
| 10644 | gertrudis | 2 |
| 10645 | geografía | 2 |
| 10646 | genui | 2 |
| 10647 | genuflexiones | 2 |
| 10648 | gentuza | 2 |
| 10649 | geniales | 2 |
| 10650 | generalmente | 2 |
| 10651 | generalizaba | 2 |
| 10652 | generalife | 2 |
| 10653 | generalidades | 2 |
| 10654 | generaciones | 2 |
| 10655 | gemía | 2 |
| 10656 | gazmoñería | 2 |
| 10657 | gavilanes | 2 |
| 10658 | gatas | 2 |
| 10659 | gastrónomo | 2 |
| 10660 | gastar | 2 |
| 10661 | gastan | 2 |
| 10662 | gastados | 2 |
| 10663 | gasta | 2 |
| 10664 | gasa | 2 |
| 10665 | garza | 2 |
| 10666 | gárrulos | 2 |
| 10667 | gárrulas | 2 |
| 10668 | gárrula | 2 |
| 10669 | garrote | 2 |
| 10670 | garras | 2 |
| 10671 | garra | 2 |
| 10672 | garcía | 2 |
| 10673 | garantías | 2 |
| 10674 | gañán | 2 |
| 10675 | ganosas | 2 |
| 10676 | ganchos | 2 |
| 10677 | ganaderos | 2 |
| 10678 | ganadero | 2 |
| 10679 | ganadas | 2 |
| 10680 | galones | 2 |
| 10681 | gallego | 2 |
| 10682 | gallardía | 2 |
| 10683 | galápago | 2 |
| 10684 | galanterías | 2 |
| 10685 | galanteo | 2 |
| 10686 | galante | 2 |
| 10687 | galanes | 2 |
| 10688 | gaitas | 2 |
| 10689 | gacetilleros | 2 |
| 10690 | futuros | 2 |
| 10691 | furores | 2 |
| 10692 | furiosos | 2 |
| 10693 | fundadores | 2 |
| 10694 | fumando | 2 |
| 10695 | fumaban | 2 |
| 10696 | fulano | 2 |
| 10697 | fui | 2 |
| 10698 | fugitivo | 2 |
| 10699 | fueros | 2 |
| 10700 | fuelle | 2 |
| 10701 | frotó | 2 |
| 10702 | freno | 2 |
| 10703 | frecuenta | 2 |
| 10704 | frailes | 2 |
| 10705 | fragilidad | 2 |
| 10706 | frágiles | 2 |
| 10707 | fósforo | 2 |
| 10708 | forzoso | 2 |
| 10709 | fortificar | 2 |
| 10710 | forrado | 2 |
| 10711 | forrada | 2 |
| 10712 | forraba | 2 |
| 10713 | fórmulas | 2 |
| 10714 | forminge | 2 |
| 10715 | formando | 2 |
| 10716 | formales | 2 |
| 10717 | formadas | 2 |
| 10718 | formaba | 2 |
| 10719 | forcejeaba | 2 |
| 10720 | foncé | 2 |
| 10721 | fomento | 2 |
| 10722 | fofa | 2 |
| 10723 | flotaba | 2 |
| 10724 | floricultura | 2 |
| 10725 | florete | 2 |
| 10726 | florecillas | 2 |
| 10727 | floreciente | 2 |
| 10728 | flojo | 2 |
| 10729 | flautas | 2 |
| 10730 | flauta | 2 |
| 10731 | flanqueada | 2 |
| 10732 | flammarion | 2 |
| 10733 | flamenca | 2 |
| 10734 | flacos | 2 |
| 10735 | fisonomía | 2 |
| 10736 | físicos | 2 |
| 10737 | fiscal | 2 |
| 10738 | firmaba | 2 |
| 10739 | firma | 2 |
| 10740 | finito | 2 |
| 10741 | finísima | 2 |
| 10742 | fingir | 2 |
| 10743 | fingimiento | 2 |
| 10744 | fingido | 2 |
| 10745 | filtraba | 2 |
| 10746 | filosóficos | 2 |
| 10747 | filosóficamente | 2 |
| 10748 | filosofando | 2 |
| 10749 | filius | 2 |
| 10750 | filípica | 2 |
| 10751 | fijeza | 2 |
| 10752 | fijas | 2 |
| 10753 | fijar | 2 |
| 10754 | figurémonos | 2 |
| 10755 | fígaro | 2 |
| 10756 | fieltro | 2 |
| 10757 | fiambre | 2 |
| 10758 | fía | 2 |
| 10759 | festivo | 2 |
| 10760 | fervorosamente | 2 |
| 10761 | ferviente | 2 |
| 10762 | férula | 2 |
| 10763 | ferrocarril | 2 |
| 10764 | ferreruelo | 2 |
| 10765 | fernando | 2 |
| 10766 | fermento | 2 |
| 10767 | féretro | 2 |
| 10768 | fenómenos | 2 |
| 10769 | femenina | 2 |
| 10770 | felonía | 2 |
| 10771 | felizmente | 2 |
| 10772 | felipe | 2 |
| 10773 | felicitaba | 2 |
| 10774 | fecunda | 2 |
| 10775 | fea | 2 |
| 10776 | fé | 2 |
| 10777 | favorita | 2 |
| 10778 | favorecía | 2 |
| 10779 | faut | 2 |
| 10780 | fauces | 2 |
| 10781 | fatuo | 2 |
| 10782 | fatigosa | 2 |
| 10783 | fatigas | 2 |
| 10784 | fatigados | 2 |
| 10785 | fatigada | 2 |
| 10786 | fatigaban | 2 |
| 10787 | fatigaba | 2 |
| 10788 | fascinado | 2 |
| 10789 | farolero | 2 |
| 10790 | faro | 2 |
| 10791 | fariseos | 2 |
| 10792 | fantástica | 2 |
| 10793 | fangosos | 2 |
| 10794 | fanatizados | 2 |
| 10795 | fanática | 2 |
| 10796 | famosos | 2 |
| 10797 | familiarmente | 2 |
| 10798 | faltaron | 2 |
| 10799 | faltarían | 2 |
| 10800 | faltaría | 2 |
| 10801 | faltado | 2 |
| 10802 | faldero | 2 |
| 10803 | faja | 2 |
| 10804 | facilitó | 2 |
| 10805 | facilitaban | 2 |
| 10806 | facha | 2 |
| 10807 | fábricas | 2 |
| 10808 | fabricar | 2 |
| 10809 | f | 2 |
| 10810 | exuberantes | 2 |
| 10811 | extremis | 2 |
| 10812 | extremada | 2 |
| 10813 | extraviados | 2 |
| 10814 | extrañó | 2 |
| 10815 | exteriores | 2 |
| 10816 | extensión | 2 |
| 10817 | extendido | 2 |
| 10818 | extender | 2 |
| 10819 | exquisitas | 2 |
| 10820 | expuestos | 2 |
| 10821 | expuestas | 2 |
| 10822 | expresaban | 2 |
| 10823 | expresaba | 2 |
| 10824 | exponemos | 2 |
| 10825 | explotar | 2 |
| 10826 | explícito | 2 |
| 10827 | explicaron | 2 |
| 10828 | explicarme | 2 |
| 10829 | explicarle | 2 |
| 10830 | explicaría | 2 |
| 10831 | explicando | 2 |
| 10832 | explicado | 2 |
| 10833 | explicaban | 2 |
| 10834 | experimentaba | 2 |
| 10835 | exordio | 2 |
| 10836 | exigen | 2 |
| 10837 | excusó | 2 |
| 10838 | exclusiva | 2 |
| 10839 | excitaciones | 2 |
| 10840 | excita | 2 |
| 10841 | exceso | 2 |
| 10842 | excesivos | 2 |
| 10843 | excelencias | 2 |
| 10844 | exageradas | 2 |
| 10845 | exageradamente | 2 |
| 10846 | exageraba | 2 |
| 10847 | exagera | 2 |
| 10848 | exacta | 2 |
| 10849 | evocaba | 2 |
| 10850 | evitarlo | 2 |
| 10851 | eunuco | 2 |
| 10852 | eudoro | 2 |
| 10853 | ética | 2 |
| 10854 | eternidades | 2 |
| 10855 | eternidad | 2 |
| 10856 | etelvina | 2 |
| 10857 | etcétera | 2 |
| 10858 | estuve | 2 |
| 10859 | estupefacto | 2 |
| 10860 | estudiarla | 2 |
| 10861 | estucada | 2 |
| 10862 | estrepitosa | 2 |
| 10863 | estrellitas | 2 |
| 10864 | estrellada | 2 |
| 10865 | estrechado | 2 |
| 10866 | estrangulado | 2 |
| 10867 | estrada | 2 |
| 10868 | estorbo | 2 |
| 10869 | estorbaré | 2 |
| 10870 | estorba | 2 |
| 10871 | estirando | 2 |
| 10872 | estiman | 2 |
| 10873 | estimación | 2 |
| 10874 | estética | 2 |
| 10875 | estertor | 2 |
| 10876 | estén | 2 |
| 10877 | estela | 2 |
| 10878 | estarse | 2 |
| 10879 | estarlo | 2 |
| 10880 | estaño | 2 |
| 10881 | estanquillos | 2 |
| 10882 | estanco | 2 |
| 10883 | estallidos | 2 |
| 10884 | estadística | 2 |
| 10885 | ésta | 2 |
| 10886 | esquivando | 2 |
| 10887 | esqueleto | 2 |
| 10888 | esputo | 2 |
| 10889 | esposos | 2 |
| 10890 | esponja | 2 |
| 10891 | espiritualismo | 2 |
| 10892 | espinoso | 2 |
| 10893 | espina | 2 |
| 10894 | espín | 2 |
| 10895 | espías | 2 |
| 10896 | espía | 2 |
| 10897 | espesos | 2 |
| 10898 | esperarle | 2 |
| 10899 | esperándole | 2 |
| 10900 | esperan | 2 |
| 10901 | especulaciones | 2 |
| 10902 | espectador | 2 |
| 10903 | especies | 2 |
| 10904 | especias | 2 |
| 10905 | esparto | 2 |
| 10906 | espantados | 2 |
| 10907 | espantado | 2 |
| 10908 | espadachín | 2 |
| 10909 | esferas | 2 |
| 10910 | esencias | 2 |
| 10911 | escupirle | 2 |
| 10912 | escultura | 2 |
| 10913 | escudriñar | 2 |
| 10914 | escudriñando | 2 |
| 10915 | escucha | 2 |
| 10916 | escuálida | 2 |
| 10917 | escrupuloso | 2 |
| 10918 | escribiendo | 2 |
| 10919 | escribían | 2 |
| 10920 | escriben | 2 |
| 10921 | escribanos | 2 |
| 10922 | escriba | 2 |
| 10923 | escote | 2 |
| 10924 | escotada | 2 |
| 10925 | escondites | 2 |
| 10926 | escondidos | 2 |
| 10927 | escondían | 2 |
| 10928 | esconder | 2 |
| 10929 | esconde | 2 |
| 10930 | escogió | 2 |
| 10931 | escoge | 2 |
| 10932 | esclavos | 2 |
| 10933 | escépticos | 2 |
| 10934 | escasez | 2 |
| 10935 | escarnio | 2 |
| 10936 | escarcha | 2 |
| 10937 | escarceos | 2 |
| 10938 | escapatorias | 2 |
| 10939 | escaparía | 2 |
| 10940 | escandalosamente | 2 |
| 10941 | escandalizó | 2 |
| 10942 | escandalizarse | 2 |
| 10943 | escandalizada | 2 |
| 10944 | escalo | 2 |
| 10945 | escalinata | 2 |
| 10946 | escajos | 2 |
| 10947 | esbeltas | 2 |
| 10948 | erre | 2 |
| 10949 | eróticos | 2 |
| 10950 | erótico | 2 |
| 10951 | erótica | 2 |
| 10952 | erizadas | 2 |
| 10953 | eriza | 2 |
| 10954 | erard | 2 |
| 10955 | éramos | 2 |
| 10956 | equivocó | 2 |
| 10957 | equivocarse | 2 |
| 10958 | equivocaciones | 2 |
| 10959 | equivocación | 2 |
| 10960 | equipaje | 2 |
| 10961 | episodios | 2 |
| 10962 | envuelve | 2 |
| 10963 | envueltas | 2 |
| 10964 | envidioso | 2 |
| 10965 | envidiosa | 2 |
| 10966 | envidiar | 2 |
| 10967 | envidiables | 2 |
| 10968 | envenenado | 2 |
| 10969 | envenenada | 2 |
| 10970 | envejecido | 2 |
| 10971 | envalentonado | 2 |
| 10972 | entusiástico | 2 |
| 10973 | entusiasmada | 2 |
| 10974 | entro | 2 |
| 10975 | entristecían | 2 |
| 10976 | entrevista | 2 |
| 10977 | entrever | 2 |
| 10978 | entretenido | 2 |
| 10979 | entretenía | 2 |
| 10980 | entremos | 2 |
| 10981 | entrego | 2 |
| 10982 | entregase | 2 |
| 10983 | entregarla | 2 |
| 10984 | entregadas | 2 |
| 10985 | entreacto | 2 |
| 10986 | entreabiertas | 2 |
| 10987 | entraría | 2 |
| 10988 | entraré | 2 |
| 10989 | entrañable | 2 |
| 10990 | entornados | 2 |
| 10991 | entierros | 2 |
| 10992 | enterrarle | 2 |
| 10993 | enterrador | 2 |
| 10994 | enteró | 2 |
| 10995 | enterneció | 2 |
| 10996 | enternecimiento | 2 |
| 10997 | entere | 2 |
| 10998 | enterasen | 2 |
| 10999 | enteras | 2 |
| 11000 | enterar | 2 |
| 11001 | enterada | 2 |
| 11002 | entendieron | 2 |
| 11003 | entendiera | 2 |
| 11004 | entendidos | 2 |
| 11005 | entenderle | 2 |
| 11006 | entenderla | 2 |
| 11007 | entallado | 2 |
| 11008 | entablaron | 2 |
| 11009 | ensueño | 2 |
| 11010 | ensimismada | 2 |
| 11011 | enseñorearse | 2 |
| 11012 | enseñarle | 2 |
| 11013 | enseñar | 2 |
| 11014 | enseña | 2 |
| 11015 | ensayos | 2 |
| 11016 | ensayo | 2 |
| 11017 | ensayar | 2 |
| 11018 | ensayado | 2 |
| 11019 | ensanchaba | 2 |
| 11020 | enroscaban | 2 |
| 11021 | enredos | 2 |
| 11022 | enredar | 2 |
| 11023 | enramadas | 2 |
| 11024 | enormísima | 2 |
| 11025 | enormes | 2 |
| 11026 | ennoblecía | 2 |
| 11027 | ennegrecida | 2 |
| 11028 | enlutadas | 2 |
| 11029 | enlutada | 2 |
| 11030 | enjugaba | 2 |
| 11031 | enjambres | 2 |
| 11032 | enhorabuena | 2 |
| 11033 | engordarla | 2 |
| 11034 | engomado | 2 |
| 11035 | engendrado | 2 |
| 11036 | engaños | 2 |
| 11037 | enfrascado | 2 |
| 11038 | enfermizo | 2 |
| 11039 | enfático | 2 |
| 11040 | enfadaba | 2 |
| 11041 | enero | 2 |
| 11042 | enérgicamente | 2 |
| 11043 | enemiga | 2 |
| 11044 | endiablada | 2 |
| 11045 | encuentran | 2 |
| 11046 | encubridora | 2 |
| 11047 | encontré | 2 |
| 11048 | encontrarle | 2 |
| 11049 | encontraría | 2 |
| 11050 | encomendarse | 2 |
| 11051 | encogiendo | 2 |
| 11052 | encogidos | 2 |
| 11053 | enciende | 2 |
| 11054 | encendieron | 2 |
| 11055 | encendidos | 2 |
| 11056 | encender | 2 |
| 11057 | encargado | 2 |
| 11058 | encargaba | 2 |
| 11059 | encarándose | 2 |
| 11060 | encaje | 2 |
| 11061 | enamoradas | 2 |
| 11062 | enamoraban | 2 |
| 11063 | empuñó | 2 |
| 11064 | empujó | 2 |
| 11065 | empresario | 2 |
| 11066 | emprendiese | 2 |
| 11067 | emprendido | 2 |
| 11068 | emporio | 2 |
| 11069 | empleada | 2 |
| 11070 | empirismo | 2 |
| 11071 | empeñarse | 2 |
| 11072 | empeñados | 2 |
| 11073 | empapelar | 2 |
| 11074 | empanadas | 2 |
| 11075 | empalagaba | 2 |
| 11076 | empadronamiento | 2 |
| 11077 | eminentes | 2 |
| 11078 | embutidos | 2 |
| 11079 | embutido | 2 |
| 11080 | embozos | 2 |
| 11081 | embozó | 2 |
| 11082 | embozadamente | 2 |
| 11083 | emborracharse | 2 |
| 11084 | emborracharon | 2 |
| 11085 | emborrachado | 2 |
| 11086 | embocadura | 2 |
| 11087 | embargado | 2 |
| 11088 | embarazosa | 2 |
| 11089 | elogiaba | 2 |
| 11090 | elevadas | 2 |
| 11091 | elemental | 2 |
| 11092 | elegías | 2 |
| 11093 | eléctrico | 2 |
| 11094 | electorales | 2 |
| 11095 | ejército | 2 |
| 11096 | ejercicios | 2 |
| 11097 | ejercer | 2 |
| 11098 | ejemplares | 2 |
| 11099 | égida | 2 |
| 11100 | efusión | 2 |
| 11101 | eficaces | 2 |
| 11102 | educandas | 2 |
| 11103 | educadas | 2 |
| 11104 | educaba | 2 |
| 11105 | edificantes | 2 |
| 11106 | edificado | 2 |
| 11107 | edificada | 2 |
| 11108 | edifica | 2 |
| 11109 | economías | 2 |
| 11110 | eclesiásticos | 2 |
| 11111 | eclesiásticas | 2 |
| 11112 | echo | 2 |
| 11113 | echarla | 2 |
| 11114 | echara | 2 |
| 11115 | echándose | 2 |
| 11116 | ecbátana | 2 |
| 11117 | ebrio | 2 |
| 11118 | dureza | 2 |
| 11119 | duraban | 2 |
| 11120 | dumas | 2 |
| 11121 | dulcísimas | 2 |
| 11122 | dufour | 2 |
| 11123 | dramáticos | 2 |
| 11124 | donna | 2 |
| 11125 | dones | 2 |
| 11126 | dominus | 2 |
| 11127 | dominante | 2 |
| 11128 | dominando | 2 |
| 11129 | domicilio | 2 |
| 11130 | domador | 2 |
| 11131 | dolió | 2 |
| 11132 | dolían | 2 |
| 11133 | doctrinas | 2 |
| 11134 | doctores | 2 |
| 11135 | doblando | 2 |
| 11136 | doblaba | 2 |
| 11137 | divisa | 2 |
| 11138 | divinidades | 2 |
| 11139 | divinas | 2 |
| 11140 | divierten | 2 |
| 11141 | divierta | 2 |
| 11142 | divididos | 2 |
| 11143 | divertida | 2 |
| 11144 | diversión | 2 |
| 11145 | distraía | 2 |
| 11146 | distintos | 2 |
| 11147 | distinguir | 2 |
| 11148 | distinguidos | 2 |
| 11149 | distinguida | 2 |
| 11150 | distingos | 2 |
| 11151 | distender | 2 |
| 11152 | distancias | 2 |
| 11153 | disputan | 2 |
| 11154 | dispuso | 2 |
| 11155 | dispuestas | 2 |
| 11156 | dispénseme | 2 |
| 11157 | dispensas | 2 |
| 11158 | disolventes | 2 |
| 11159 | disimuladas | 2 |
| 11160 | disimula | 2 |
| 11161 | disgustó | 2 |
| 11162 | disfruto | 2 |
| 11163 | disfrutar | 2 |
| 11164 | disfrazar | 2 |
| 11165 | disfrazaba | 2 |
| 11166 | disecado | 2 |
| 11167 | discutido | 2 |
| 11168 | discurrir | 2 |
| 11169 | disculpó | 2 |
| 11170 | disculpas | 2 |
| 11171 | discrecional | 2 |
| 11172 | discordantes | 2 |
| 11173 | discípulo | 2 |
| 11174 | disciplinadas | 2 |
| 11175 | dirigir | 2 |
| 11176 | dirigiendo | 2 |
| 11177 | dirige | 2 |
| 11178 | diosa | 2 |
| 11179 | diminutivos | 2 |
| 11180 | dimensiones | 2 |
| 11181 | dime | 2 |
| 11182 | dijeran | 2 |
| 11183 | dijéramos | 2 |
| 11184 | dignamente | 2 |
| 11185 | digestiones | 2 |
| 11186 | digas | 2 |
| 11187 | dígalo | 2 |
| 11188 | difusa | 2 |
| 11189 | difícilmente | 2 |
| 11190 | diferencias | 2 |
| 11191 | diego | 2 |
| 11192 | dieciséis | 2 |
| 11193 | dieciocho | 2 |
| 11194 | diecinueve | 2 |
| 11195 | diciembre | 2 |
| 11196 | dichas | 2 |
| 11197 | dicharachos | 2 |
| 11198 | dibujos | 2 |
| 11199 | dibujo | 2 |
| 11200 | dibujada | 2 |
| 11201 | diariamente | 2 |
| 11202 | diabólicas | 2 |
| 11203 | diablillos | 2 |
| 11204 | di | 2 |
| 11205 | devorando | 2 |
| 11206 | devolvía | 2 |
| 11207 | detiene | 2 |
| 11208 | determinada | 2 |
| 11209 | detenimiento | 2 |
| 11210 | detenerme | 2 |
| 11211 | desvergüenzas | 2 |
| 11212 | desvergonzada | 2 |
| 11213 | desvanes | 2 |
| 11214 | desvanecido | 2 |
| 11215 | desvanecida | 2 |
| 11216 | desvanecía | 2 |
| 11217 | desvanecer | 2 |
| 11218 | destinos | 2 |
| 11219 | destinado | 2 |
| 11220 | destinadas | 2 |
| 11221 | destinada | 2 |
| 11222 | desterrado | 2 |
| 11223 | desquite | 2 |
| 11224 | despreocupación | 2 |
| 11225 | desprendimiento | 2 |
| 11226 | despreciará | 2 |
| 11227 | desprecian | 2 |
| 11228 | despreciable | 2 |
| 11229 | despojó | 2 |
| 11230 | despojado | 2 |
| 11231 | despilfarros | 2 |
| 11232 | despiertos | 2 |
| 11233 | despide | 2 |
| 11234 | despertaron | 2 |
| 11235 | despertarla | 2 |
| 11236 | despertara | 2 |
| 11237 | despertaban | 2 |
| 11238 | desperdiciar | 2 |
| 11239 | despellejar | 2 |
| 11240 | despejado | 2 |
| 11241 | despedir | 2 |
| 11242 | despedidas | 2 |
| 11243 | despedazada | 2 |
| 11244 | despedazaba | 2 |
| 11245 | desocupada | 2 |
| 11246 | desmenuzar | 2 |
| 11247 | desmayado | 2 |
| 11248 | deslumbrantes | 2 |
| 11249 | deslumbran | 2 |
| 11250 | deslumbrador | 2 |
| 11251 | deslumbrado | 2 |
| 11252 | deslumbraba | 2 |
| 11253 | deslucían | 2 |
| 11254 | deslizaban | 2 |
| 11255 | deslenguado | 2 |
| 11256 | desinteresado | 2 |
| 11257 | designios | 2 |
| 11258 | deshizo | 2 |
| 11259 | deshacerse | 2 |
| 11260 | deshacerle | 2 |
| 11261 | desgraciados | 2 |
| 11262 | desfigurada | 2 |
| 11263 | desfallecer | 2 |
| 11264 | desfachatada | 2 |
| 11265 | desengaños | 2 |
| 11266 | desengañarse | 2 |
| 11267 | desenganchar | 2 |
| 11268 | desenfrenada | 2 |
| 11269 | desempeñaba | 2 |
| 11270 | desechaba | 2 |
| 11271 | desdichas | 2 |
| 11272 | desdeñoso | 2 |
| 11273 | desdeñando | 2 |
| 11274 | desdeñaba | 2 |
| 11275 | desdenes | 2 |
| 11276 | descuidados | 2 |
| 11277 | descuidado | 2 |
| 11278 | descuidadas | 2 |
| 11279 | descuida | 2 |
| 11280 | descuento | 2 |
| 11281 | descubriendo | 2 |
| 11282 | descubiertos | 2 |
| 11283 | descriptiva | 2 |
| 11284 | describiendo | 2 |
| 11285 | descreídos | 2 |
| 11286 | desconocidas | 2 |
| 11287 | desconfiando | 2 |
| 11288 | desconfía | 2 |
| 11289 | descomunal | 2 |
| 11290 | descomponía | 2 |
| 11291 | descendió | 2 |
| 11292 | descaro | 2 |
| 11293 | descarnado | 2 |
| 11294 | descarga | 2 |
| 11295 | descarado | 2 |
| 11296 | descansando | 2 |
| 11297 | descansa | 2 |
| 11298 | descalzas | 2 |
| 11299 | descabellada | 2 |
| 11300 | desató | 2 |
| 11301 | desarrollo | 2 |
| 11302 | desarrollada | 2 |
| 11303 | desanimado | 2 |
| 11304 | desairar | 2 |
| 11305 | desahogar | 2 |
| 11306 | desagravios | 2 |
| 11307 | desafinado | 2 |
| 11308 | desafiase | 2 |
| 11309 | desafiado | 2 |
| 11310 | desacreditado | 2 |
| 11311 | desabridos | 2 |
| 11312 | desabrido | 2 |
| 11313 | derretía | 2 |
| 11314 | derredor | 2 |
| 11315 | derramado | 2 |
| 11316 | depositó | 2 |
| 11317 | depositados | 2 |
| 11318 | deploraba | 2 |
| 11319 | dependientes | 2 |
| 11320 | dependía | 2 |
| 11321 | demuestra | 2 |
| 11322 | demostrarle | 2 |
| 11323 | demostrando | 2 |
| 11324 | demostrado | 2 |
| 11325 | demos | 2 |
| 11326 | demonches | 2 |
| 11327 | demócrata | 2 |
| 11328 | delitos | 2 |
| 11329 | deliquio | 2 |
| 11330 | delgados | 2 |
| 11331 | deleznable | 2 |
| 11332 | deleitaba | 2 |
| 11333 | delata | 2 |
| 11334 | dejos | 2 |
| 11335 | déjese | 2 |
| 11336 | dejas | 2 |
| 11337 | dejarlos | 2 |
| 11338 | dejarlo | 2 |
| 11339 | dejarán | 2 |
| 11340 | dejándote | 2 |
| 11341 | dejándole | 2 |
| 11342 | degenerar | 2 |
| 11343 | definitiva | 2 |
| 11344 | definido | 2 |
| 11345 | definida | 2 |
| 11346 | definición | 2 |
| 11347 | defiendo | 2 |
| 11348 | defensores | 2 |
| 11349 | defendido | 2 |
| 11350 | dedicarse | 2 |
| 11351 | dedican | 2 |
| 11352 | dedicaban | 2 |
| 11353 | decreto | 2 |
| 11354 | decorosamente | 2 |
| 11355 | declare | 2 |
| 11356 | declararse | 2 |
| 11357 | declararon | 2 |
| 11358 | declararme | 2 |
| 11359 | decirlas | 2 |
| 11360 | décimas | 2 |
| 11361 | decencia | 2 |
| 11362 | decaimiento | 2 |
| 11363 | decaer | 2 |
| 11364 | decadente | 2 |
| 11365 | decadencia | 2 |
| 11366 | debieron | 2 |
| 11367 | dato | 2 |
| 11368 | date | 2 |
| 11369 | darwinismo | 2 |
| 11370 | darnos | 2 |
| 11371 | dale | 2 |
| 11372 | curva | 2 |
| 11373 | curarme | 2 |
| 11374 | curado | 2 |
| 11375 | cundió | 2 |
| 11376 | cumplidos | 2 |
| 11377 | cumplida | 2 |
| 11378 | cultura | 2 |
| 11379 | cultivar | 2 |
| 11380 | culpaba | 2 |
| 11381 | culminante | 2 |
| 11382 | culinaria | 2 |
| 11383 | culebras | 2 |
| 11384 | culebra | 2 |
| 11385 | cuidarle | 2 |
| 11386 | cuidadosamente | 2 |
| 11387 | cuida | 2 |
| 11388 | cueva | 2 |
| 11389 | cuerpecito | 2 |
| 11390 | cuerdas | 2 |
| 11391 | cucuruchos | 2 |
| 11392 | cuchicheaban | 2 |
| 11393 | cuchicheaba | 2 |
| 11394 | cubrían | 2 |
| 11395 | cuba | 2 |
| 11396 | cuarteto | 2 |
| 11397 | cuarta | 2 |
| 11398 | cuantía | 2 |
| 11399 | cuáles | 2 |
| 11400 | crujió | 2 |
| 11401 | cruelmente | 2 |
| 11402 | cruda | 2 |
| 11403 | crucifijo | 2 |
| 11404 | crucifícale | 2 |
| 11405 | cronicones | 2 |
| 11406 | crónico | 2 |
| 11407 | cromos | 2 |
| 11408 | críticos | 2 |
| 11409 | cristianar | 2 |
| 11410 | crispaba | 2 |
| 11411 | crisóstomo | 2 |
| 11412 | cripta | 2 |
| 11413 | criminales | 2 |
| 11414 | cría | 2 |
| 11415 | crestas | 2 |
| 11416 | cresta | 2 |
| 11417 | creíase | 2 |
| 11418 | creerme | 2 |
| 11419 | creería | 2 |
| 11420 | creemos | 2 |
| 11421 | credulidad | 2 |
| 11422 | créditos | 2 |
| 11423 | creció | 2 |
| 11424 | crecimiento | 2 |
| 11425 | creciente | 2 |
| 11426 | creas | 2 |
| 11427 | créame | 2 |
| 11428 | créalo | 2 |
| 11429 | creado | 2 |
| 11430 | creaba | 2 |
| 11431 | crasitud | 2 |
| 11432 | costurera | 2 |
| 11433 | costura | 2 |
| 11434 | costar | 2 |
| 11435 | costaban | 2 |
| 11436 | corva | 2 |
| 11437 | corujedos | 2 |
| 11438 | cortó | 2 |
| 11439 | cortinas | 2 |
| 11440 | cortésmente | 2 |
| 11441 | cortesano | 2 |
| 11442 | cortes | 2 |
| 11443 | cortas | 2 |
| 11444 | cortaplumas | 2 |
| 11445 | cortando | 2 |
| 11446 | cortan | 2 |
| 11447 | cortaba | 2 |
| 11448 | corrompido | 2 |
| 11449 | corroborar | 2 |
| 11450 | corriste | 2 |
| 11451 | corrillo | 2 |
| 11452 | correspondientes | 2 |
| 11453 | correspondiente | 2 |
| 11454 | correligionario | 2 |
| 11455 | correligionarias | 2 |
| 11456 | corpulento | 2 |
| 11457 | corporales | 2 |
| 11458 | corporaciones | 2 |
| 11459 | coros | 2 |
| 11460 | coronada | 2 |
| 11461 | cornucopias | 2 |
| 11462 | coristas | 2 |
| 11463 | cordialidad | 2 |
| 11464 | corazonadas | 2 |
| 11465 | coquetona | 2 |
| 11466 | coqueterías | 2 |
| 11467 | coquetear | 2 |
| 11468 | coqueta | 2 |
| 11469 | copos | 2 |
| 11470 | copón | 2 |
| 11471 | copioso | 2 |
| 11472 | copias | 2 |
| 11473 | copiado | 2 |
| 11474 | convirtieron | 2 |
| 11475 | convertidas | 2 |
| 11476 | convertida | 2 |
| 11477 | converso | 2 |
| 11478 | conversaban | 2 |
| 11479 | convenio | 2 |
| 11480 | convendría | 2 |
| 11481 | convencionales | 2 |
| 11482 | convencional | 2 |
| 11483 | convencía | 2 |
| 11484 | convencerse | 2 |
| 11485 | contribuía | 2 |
| 11486 | contraventanas | 2 |
| 11487 | contraído | 2 |
| 11488 | contrahecha | 2 |
| 11489 | contradictorio | 2 |
| 11490 | contradictorias | 2 |
| 11491 | contradecir | 2 |
| 11492 | contradecía | 2 |
| 11493 | contingente | 2 |
| 11494 | contiene | 2 |
| 11495 | contestaron | 2 |
| 11496 | contertulios | 2 |
| 11497 | contentándose | 2 |
| 11498 | contendiente | 2 |
| 11499 | contemplarla | 2 |
| 11500 | contara | 2 |
| 11501 | consumo | 2 |
| 11502 | consuma | 2 |
| 11503 | consultas | 2 |
| 11504 | consultando | 2 |
| 11505 | consultado | 2 |
| 11506 | consultaba | 2 |
| 11507 | consuelos | 2 |
| 11508 | construida | 2 |
| 11509 | construían | 2 |
| 11510 | constitución | 2 |
| 11511 | constantemente | 2 |
| 11512 | consta | 2 |
| 11513 | conspirar | 2 |
| 11514 | conspiraba | 2 |
| 11515 | consonantes | 2 |
| 11516 | consoladora | 2 |
| 11517 | consolaban | 2 |
| 11518 | consistir | 2 |
| 11519 | consistente | 2 |
| 11520 | consistencia | 2 |
| 11521 | consintiera | 2 |
| 11522 | consiguieron | 2 |
| 11523 | consigue | 2 |
| 11524 | consideró | 2 |
| 11525 | considera | 2 |
| 11526 | conservadores | 2 |
| 11527 | consentirá | 2 |
| 11528 | consentimiento | 2 |
| 11529 | consejero | 2 |
| 11530 | conseguían | 2 |
| 11531 | consagrado | 2 |
| 11532 | consagración | 2 |
| 11533 | conozca | 2 |
| 11534 | conociendo | 2 |
| 11535 | conoces | 2 |
| 11536 | conocerle | 2 |
| 11537 | conocerla | 2 |
| 11538 | conocen | 2 |
| 11539 | conjurados | 2 |
| 11540 | conjurado | 2 |
| 11541 | conjuración | 2 |
| 11542 | congresos | 2 |
| 11543 | congéneres | 2 |
| 11544 | confusiones | 2 |
| 11545 | confundirse | 2 |
| 11546 | confundido | 2 |
| 11547 | confunde | 2 |
| 11548 | confortable | 2 |
| 11549 | confort | 2 |
| 11550 | confirmábase | 2 |
| 11551 | confidentes | 2 |
| 11552 | confidencia | 2 |
| 11553 | confiaban | 2 |
| 11554 | confiaba | 2 |
| 11555 | confesores | 2 |
| 11556 | confesata | 2 |
| 11557 | conducían | 2 |
| 11558 | conduce | 2 |
| 11559 | condicional | 2 |
| 11560 | condescendencia | 2 |
| 11561 | condes | 2 |
| 11562 | condeno | 2 |
| 11563 | condenar | 2 |
| 11564 | condenados | 2 |
| 11565 | condenado | 2 |
| 11566 | conde | 2 |
| 11567 | concurridos | 2 |
| 11568 | concurrían | 2 |
| 11569 | concubina | 2 |
| 11570 | concretas | 2 |
| 11571 | concordia | 2 |
| 11572 | conclusión | 2 |
| 11573 | concluir | 2 |
| 11574 | conciliábulos | 2 |
| 11575 | conciliábulo | 2 |
| 11576 | concierto | 2 |
| 11577 | concejal | 2 |
| 11578 | concedían | 2 |
| 11579 | conceder | 2 |
| 11580 | concebía | 2 |
| 11581 | conato | 2 |
| 11582 | comunicó | 2 |
| 11583 | comunicativa | 2 |
| 11584 | comunicar | 2 |
| 11585 | comulgaría | 2 |
| 11586 | comte | 2 |
| 11587 | compuesta | 2 |
| 11588 | compromisario | 2 |
| 11589 | comprometerla | 2 |
| 11590 | comprimida | 2 |
| 11591 | comprendiera | 2 |
| 11592 | comprendí | 2 |
| 11593 | comprenda | 2 |
| 11594 | componer | 2 |
| 11595 | complicación | 2 |
| 11596 | complexión | 2 |
| 11597 | compleja | 2 |
| 11598 | complaciéndose | 2 |
| 11599 | complacerle | 2 |
| 11600 | compensar | 2 |
| 11601 | compensaba | 2 |
| 11602 | compareció | 2 |
| 11603 | comparada | 2 |
| 11604 | comparable | 2 |
| 11605 | compara | 2 |
| 11606 | compadecían | 2 |
| 11607 | compadecerse | 2 |
| 11608 | cómodos | 2 |
| 11609 | cómodamente | 2 |
| 11610 | comm | 2 |
| 11611 | comiera | 2 |
| 11612 | comienza | 2 |
| 11613 | comidas | 2 |
| 11614 | comes | 2 |
| 11615 | comerse | 2 |
| 11616 | comenzada | 2 |
| 11617 | comentar | 2 |
| 11618 | comentaban | 2 |
| 11619 | comentaba | 2 |
| 11620 | comensales | 2 |
| 11621 | comedido | 2 |
| 11622 | combate | 2 |
| 11623 | comadronas | 2 |
| 11624 | columbrar | 2 |
| 11625 | coloso | 2 |
| 11626 | colorados | 2 |
| 11627 | coloquio | 2 |
| 11628 | colocado | 2 |
| 11629 | coloca | 2 |
| 11630 | colmar | 2 |
| 11631 | colmada | 2 |
| 11632 | coliseo | 2 |
| 11633 | colina | 2 |
| 11634 | colgó | 2 |
| 11635 | colgadura | 2 |
| 11636 | colgaba | 2 |
| 11637 | colegiales | 2 |
| 11638 | colega | 2 |
| 11639 | colectivo | 2 |
| 11640 | coleccionador | 2 |
| 11641 | colapso | 2 |
| 11642 | colación | 2 |
| 11643 | coja | 2 |
| 11644 | coincide | 2 |
| 11645 | cohechos | 2 |
| 11646 | cogiendo | 2 |
| 11647 | cogidos | 2 |
| 11648 | cogían | 2 |
| 11649 | codorniz | 2 |
| 11650 | codearse | 2 |
| 11651 | codeándose | 2 |
| 11652 | codazos | 2 |
| 11653 | cocineros | 2 |
| 11654 | cocineras | 2 |
| 11655 | cocido | 2 |
| 11656 | cocheras | 2 |
| 11657 | cloaca | 2 |
| 11658 | clavel | 2 |
| 11659 | clavarse | 2 |
| 11660 | clavarle | 2 |
| 11661 | clavada | 2 |
| 11662 | claudicante | 2 |
| 11663 | clarisas | 2 |
| 11664 | clarinetes | 2 |
| 11665 | clandestino | 2 |
| 11666 | claire | 2 |
| 11667 | clac | 2 |
| 11668 | ciudades | 2 |
| 11669 | ciudadanos | 2 |
| 11670 | citó | 2 |
| 11671 | cito | 2 |
| 11672 | citando | 2 |
| 11673 | citados | 2 |
| 11674 | citado | 2 |
| 11675 | citaban | 2 |
| 11676 | cirino | 2 |
| 11677 | circulante | 2 |
| 11678 | circulación | 2 |
| 11679 | circos | 2 |
| 11680 | cinto | 2 |
| 11681 | cinta | 2 |
| 11682 | cinismo | 2 |
| 11683 | cínicos | 2 |
| 11684 | cínico | 2 |
| 11685 | cima | 2 |
| 11686 | cilicio | 2 |
| 11687 | cigarras | 2 |
| 11688 | cierre | 2 |
| 11689 | cierra | 2 |
| 11690 | cientos | 2 |
| 11691 | ciencias | 2 |
| 11692 | ciegamente | 2 |
| 11693 | chupando | 2 |
| 11694 | chupan | 2 |
| 11695 | chorreaban | 2 |
| 11696 | chorreaba | 2 |
| 11697 | chocaban | 2 |
| 11698 | chitón | 2 |
| 11699 | chito | 2 |
| 11700 | chirridos | 2 |
| 11701 | chiripa | 2 |
| 11702 | chiquita | 2 |
| 11703 | chinto | 2 |
| 11704 | chino | 2 |
| 11705 | chinescas | 2 |
| 11706 | chasquido | 2 |
| 11707 | chascarrillos | 2 |
| 11708 | chas | 2 |
| 11709 | chartreuse | 2 |
| 11710 | charlando | 2 |
| 11711 | chaparrones | 2 |
| 11712 | chantre | 2 |
| 11713 | chalet | 2 |
| 11714 | chalecos | 2 |
| 11715 | cestas | 2 |
| 11716 | cesó | 2 |
| 11717 | césar | 2 |
| 11718 | cesantía | 2 |
| 11719 | cerradura | 2 |
| 11720 | cerillas | 2 |
| 11721 | ceremoniosa | 2 |
| 11722 | cerebral | 2 |
| 11723 | cerdo | 2 |
| 11724 | cercos | 2 |
| 11725 | cercanos | 2 |
| 11726 | cercano | 2 |
| 11727 | cerbatana | 2 |
| 11728 | cepillar | 2 |
| 11729 | central | 2 |
| 11730 | censuras | 2 |
| 11731 | cenó | 2 |
| 11732 | cenaron | 2 |
| 11733 | cenado | 2 |
| 11734 | celucos | 2 |
| 11735 | celibato | 2 |
| 11736 | celestiales | 2 |
| 11737 | celestes | 2 |
| 11738 | celebró | 2 |
| 11739 | célebres | 2 |
| 11740 | celdas | 2 |
| 11741 | cejijunto | 2 |
| 11742 | cegado | 2 |
| 11743 | cédula | 2 |
| 11744 | cediendo | 2 |
| 11745 | cede | 2 |
| 11746 | cebo | 2 |
| 11747 | cayeran | 2 |
| 11748 | cauterio | 2 |
| 11749 | causó | 2 |
| 11750 | causas | 2 |
| 11751 | causaban | 2 |
| 11752 | caudal | 2 |
| 11753 | catolicismo | 2 |
| 11754 | católicas | 2 |
| 11755 | categórica | 2 |
| 11756 | categoría | 2 |
| 11757 | cataratas | 2 |
| 11758 | casuchas | 2 |
| 11759 | casualidades | 2 |
| 11760 | casual | 2 |
| 11761 | castillos | 2 |
| 11762 | castigos | 2 |
| 11763 | castañuelas | 2 |
| 11764 | castañas | 2 |
| 11765 | casé | 2 |
| 11766 | cascabel | 2 |
| 11767 | casarían | 2 |
| 11768 | casar | 2 |
| 11769 | carvajal | 2 |
| 11770 | cartucho | 2 |
| 11771 | carros | 2 |
| 11772 | carpintero | 2 |
| 11773 | carnaza | 2 |
| 11774 | carnales | 2 |
| 11775 | carita | 2 |
| 11776 | cariñosos | 2 |
| 11777 | caricaturas | 2 |
| 11778 | cargamento | 2 |
| 11779 | carecía | 2 |
| 11780 | cardos | 2 |
| 11781 | cárdeno | 2 |
| 11782 | cárdenas | 2 |
| 11783 | carboneras | 2 |
| 11784 | carbonera | 2 |
| 11785 | carámbano | 2 |
| 11786 | carabina | 2 |
| 11787 | capullos | 2 |
| 11788 | caprichosos | 2 |
| 11789 | capones | 2 |
| 11790 | capitoné | 2 |
| 11791 | cañones | 2 |
| 11792 | cañonazos | 2 |
| 11793 | canturia | 2 |
| 11794 | cántico | 2 |
| 11795 | cante | 2 |
| 11796 | cantaron | 2 |
| 11797 | cántaro | 2 |
| 11798 | cantado | 2 |
| 11799 | cansar | 2 |
| 11800 | cansando | 2 |
| 11801 | canonjía | 2 |
| 11802 | canónicas | 2 |
| 11803 | cancel | 2 |
| 11804 | campechano | 2 |
| 11805 | campanada | 2 |
| 11806 | cambios | 2 |
| 11807 | cambió | 2 |
| 11808 | cambiando | 2 |
| 11809 | cambiaba | 2 |
| 11810 | camareros | 2 |
| 11811 | camarada | 2 |
| 11812 | cámara | 2 |
| 11813 | calzón | 2 |
| 11814 | calzar | 2 |
| 11815 | calvicie | 2 |
| 11816 | calumniaba | 2 |
| 11817 | calmar | 2 |
| 11818 | cállese | 2 |
| 11819 | callarse | 2 |
| 11820 | callarán | 2 |
| 11821 | caliza | 2 |
| 11822 | calificaba | 2 |
| 11823 | califas | 2 |
| 11824 | calidades | 2 |
| 11825 | calenturienta | 2 |
| 11826 | calentarse | 2 |
| 11827 | caldos | 2 |
| 11828 | calderonianas | 2 |
| 11829 | calatayud | 2 |
| 11830 | cafés | 2 |
| 11831 | caen | 2 |
| 11832 | caderas | 2 |
| 11833 | cacique | 2 |
| 11834 | cacho | 2 |
| 11835 | cacharros | 2 |
| 11836 | cabezadas | 2 |
| 11837 | cabellera | 2 |
| 11838 | cabecita | 2 |
| 11839 | caballeritos | 2 |
| 11840 | caballeresco | 2 |
| 11841 | caballerescas | 2 |
| 11842 | cabal | 2 |
| 11843 | c | 2 |
| 11844 | búsquela | 2 |
| 11845 | buscasen | 2 |
| 11846 | buscaron | 2 |
| 11847 | buscarla | 2 |
| 11848 | buscaría | 2 |
| 11849 | burlador | 2 |
| 11850 | burgueses | 2 |
| 11851 | buque | 2 |
| 11852 | bum | 2 |
| 11853 | bullicioso | 2 |
| 11854 | bullicio | 2 |
| 11855 | bullanguera | 2 |
| 11856 | bujía | 2 |
| 11857 | bufanda | 2 |
| 11858 | bucólicos | 2 |
| 11859 | bruscamente | 2 |
| 11860 | bruja | 2 |
| 11861 | brotó | 2 |
| 11862 | brindis | 2 |
| 11863 | brillar | 2 |
| 11864 | brilla | 2 |
| 11865 | brigadier | 2 |
| 11866 | brevedad | 2 |
| 11867 | breñas | 2 |
| 11868 | bramaba | 2 |
| 11869 | botellas | 2 |
| 11870 | bote | 2 |
| 11871 | bostezo | 2 |
| 11872 | bostezar | 2 |
| 11873 | borrosa | 2 |
| 11874 | borrego | 2 |
| 11875 | borradas | 2 |
| 11876 | borracha | 2 |
| 11877 | borde | 2 |
| 11878 | bordados | 2 |
| 11879 | boquiabierta | 2 |
| 11880 | bonitas | 2 |
| 11881 | bonete | 2 |
| 11882 | bombo | 2 |
| 11883 | bolsillos | 2 |
| 11884 | bochorno | 2 |
| 11885 | bobadas | 2 |
| 11886 | blindado | 2 |
| 11887 | blasfemar | 2 |
| 11888 | blasfemando | 2 |
| 11889 | blanquísimos | 2 |
| 11890 | blanquísimo | 2 |
| 11891 | blanduras | 2 |
| 11892 | bizcocho | 2 |
| 11893 | bizarro | 2 |
| 11894 | bis | 2 |
| 11895 | billete | 2 |
| 11896 | billares | 2 |
| 11897 | bijou | 2 |
| 11898 | bigotillo | 2 |
| 11899 | bestia | 2 |
| 11900 | besándole | 2 |
| 11901 | besa | 2 |
| 11902 | bernesga | 2 |
| 11903 | benito | 2 |
| 11904 | beneméritos | 2 |
| 11905 | beneficiao | 2 |
| 11906 | benéfica | 2 |
| 11907 | bendiciones | 2 |
| 11908 | benavides | 2 |
| 11909 | belvedere | 2 |
| 11910 | bebiendo | 2 |
| 11911 | bebés | 2 |
| 11912 | beatos | 2 |
| 11913 | beatífica | 2 |
| 11914 | beatería | 2 |
| 11915 | bazar | 2 |
| 11916 | batista | 2 |
| 11917 | batiéndose | 2 |
| 11918 | baterías | 2 |
| 11919 | batacazo | 2 |
| 11920 | bastidores | 2 |
| 11921 | bastaron | 2 |
| 11922 | base | 2 |
| 11923 | barroco | 2 |
| 11924 | barriada | 2 |
| 11925 | barra | 2 |
| 11926 | baronesas | 2 |
| 11927 | barbilindo | 2 |
| 11928 | bárbaros | 2 |
| 11929 | barbaridad | 2 |
| 11930 | baratos | 2 |
| 11931 | barata | 2 |
| 11932 | bañándose | 2 |
| 11933 | bañan | 2 |
| 11934 | bañaban | 2 |
| 11935 | banquetes | 2 |
| 11936 | banquero | 2 |
| 11937 | bandido | 2 |
| 11938 | bandeja | 2 |
| 11939 | banda | 2 |
| 11940 | balduque | 2 |
| 11941 | balbucear | 2 |
| 11942 | balaustrada | 2 |
| 11943 | balas | 2 |
| 11944 | balanceo | 2 |
| 11945 | bajeza | 2 |
| 11946 | bajera | 2 |
| 11947 | bajado | 2 |
| 11948 | bailé | 2 |
| 11949 | bailaban | 2 |
| 11950 | báculo | 2 |
| 11951 | baco | 2 |
| 11952 | babuchas | 2 |
| 11953 | azotes | 2 |
| 11954 | azote | 2 |
| 11955 | azotando | 2 |
| 11956 | azotaba | 2 |
| 11957 | azota | 2 |
| 11958 | azor | 2 |
| 11959 | azafranada | 2 |
| 11960 | ayunos | 2 |
| 11961 | ayuno | 2 |
| 11962 | ayudo | 2 |
| 11963 | ayúdeme | 2 |
| 11964 | ayude | 2 |
| 11965 | ayudarme | 2 |
| 11966 | ayudando | 2 |
| 11967 | ayudan | 2 |
| 11968 | axioma | 2 |
| 11969 | avizor | 2 |
| 11970 | avisos | 2 |
| 11971 | avisan | 2 |
| 11972 | averiguó | 2 |
| 11973 | averiguado | 2 |
| 11974 | avergonzaban | 2 |
| 11975 | aventurilla | 2 |
| 11976 | avenido | 2 |
| 11977 | avellanas | 2 |
| 11978 | avellana | 2 |
| 11979 | avanzó | 2 |
| 11980 | avanzar | 2 |
| 11981 | avanzada | 2 |
| 11982 | auxilios | 2 |
| 11983 | autoriza | 2 |
| 11984 | autonomía | 2 |
| 11985 | automático | 2 |
| 11986 | auténtica | 2 |
| 11987 | auricular | 2 |
| 11988 | aurea | 2 |
| 11989 | auras | 2 |
| 11990 | augusto | 2 |
| 11991 | aturdirse | 2 |
| 11992 | aturdía | 2 |
| 11993 | atronaba | 2 |
| 11994 | atrición | 2 |
| 11995 | atribulado | 2 |
| 11996 | atribuir | 2 |
| 11997 | atrevimientos | 2 |
| 11998 | atreviera | 2 |
| 11999 | atrévete | 2 |
| 12000 | atrever | 2 |
| 12001 | atreva | 2 |
| 12002 | atraviesa | 2 |
| 12003 | atravesado | 2 |
| 12004 | atravesaban | 2 |
| 12005 | atrasada | 2 |
| 12006 | atragantó | 2 |
| 12007 | atrae | 2 |
| 12008 | atormenten | 2 |
| 12009 | atormentarse | 2 |
| 12010 | atormentado | 2 |
| 12011 | atónitos | 2 |
| 12012 | atolondramiento | 2 |
| 12013 | aterraba | 2 |
| 12014 | ateos | 2 |
| 12015 | atentado | 2 |
| 12016 | atenta | 2 |
| 12017 | atendió | 2 |
| 12018 | atenciones | 2 |
| 12019 | atañe | 2 |
| 12020 | atadas | 2 |
| 12021 | atada | 2 |
| 12022 | asuste | 2 |
| 12023 | asustara | 2 |
| 12024 | asustar | 2 |
| 12025 | asustadiza | 2 |
| 12026 | asusta | 2 |
| 12027 | asquerosa | 2 |
| 12028 | aspiraciones | 2 |
| 12029 | ásperas | 2 |
| 12030 | asombrado | 2 |
| 12031 | asombrada | 2 |
| 12032 | asomaron | 2 |
| 12033 | asomara | 2 |
| 12034 | asomados | 2 |
| 12035 | asomado | 2 |
| 12036 | asomada | 2 |
| 12037 | asomaban | 2 |
| 12038 | asistió | 2 |
| 12039 | asistieron | 2 |
| 12040 | asistiera | 2 |
| 12041 | asisten | 2 |
| 12042 | asiduo | 2 |
| 12043 | asfixiaba | 2 |
| 12044 | asesinar | 2 |
| 12045 | asesinado | 2 |
| 12046 | aserto | 2 |
| 12047 | aseguraban | 2 |
| 12048 | asedio | 2 |
| 12049 | asedian | 2 |
| 12050 | ascuas | 2 |
| 12051 | ascos | 2 |
| 12052 | asceta | 2 |
| 12053 | artísticas | 2 |
| 12054 | artificios | 2 |
| 12055 | artificiales | 2 |
| 12056 | artífice | 2 |
| 12057 | articulista | 2 |
| 12058 | artesonado | 2 |
| 12059 | artesanos | 2 |
| 12060 | arrullos | 2 |
| 12061 | arrullo | 2 |
| 12062 | arrullaba | 2 |
| 12063 | arruinando | 2 |
| 12064 | arruina | 2 |
| 12065 | arrugas | 2 |
| 12066 | arrojo | 2 |
| 12067 | arrojaron | 2 |
| 12068 | arrojarle | 2 |
| 12069 | arrojara | 2 |
| 12070 | arrojando | 2 |
| 12071 | arrojada | 2 |
| 12072 | arrogancia | 2 |
| 12073 | arrobas | 2 |
| 12074 | arrinconado | 2 |
| 12075 | arrinconada | 2 |
| 12076 | arrimada | 2 |
| 12077 | arrepentido | 2 |
| 12078 | arrepentía | 2 |
| 12079 | arrastrase | 2 |
| 12080 | arrastrara | 2 |
| 12081 | arrastradas | 2 |
| 12082 | arrancó | 2 |
| 12083 | arrancado | 2 |
| 12084 | arraigado | 2 |
| 12085 | arqueológica | 2 |
| 12086 | árnica | 2 |
| 12087 | armoniosas | 2 |
| 12088 | armería | 2 |
| 12089 | armatoste | 2 |
| 12090 | armando | 2 |
| 12091 | armado | 2 |
| 12092 | arisca | 2 |
| 12093 | argentina | 2 |
| 12094 | areo | 2 |
| 12095 | arenga | 2 |
| 12096 | arenal | 2 |
| 12097 | área | 2 |
| 12098 | arduos | 2 |
| 12099 | arduo | 2 |
| 12100 | ardores | 2 |
| 12101 | ardiendo | 2 |
| 12102 | ardentísima | 2 |
| 12103 | arceas | 2 |
| 12104 | arcadia | 2 |
| 12105 | arboricultura | 2 |
| 12106 | arbolillos | 2 |
| 12107 | arboleda | 2 |
| 12108 | arbolado | 2 |
| 12109 | árbitro | 2 |
| 12110 | arabescos | 2 |
| 12111 | aquiles | 2 |
| 12112 | aquéllos | 2 |
| 12113 | aquélla | 2 |
| 12114 | apuesta | 2 |
| 12115 | aproximó | 2 |
| 12116 | aproximarse | 2 |
| 12117 | aprovechando | 2 |
| 12118 | aprovecha | 2 |
| 12119 | apretarla | 2 |
| 12120 | aprendió | 2 |
| 12121 | apreciaba | 2 |
| 12122 | apoyo | 2 |
| 12123 | apoyar | 2 |
| 12124 | apoyados | 2 |
| 12125 | apoyado | 2 |
| 12126 | apoteosis | 2 |
| 12127 | apóstoles | 2 |
| 12128 | apóstata | 2 |
| 12129 | apostasía | 2 |
| 12130 | apostar | 2 |
| 12131 | apoderó | 2 |
| 12132 | apoderado | 2 |
| 12133 | aplomo | 2 |
| 12134 | aplicaciones | 2 |
| 12135 | aplica | 2 |
| 12136 | aplaudió | 2 |
| 12137 | aplaude | 2 |
| 12138 | aplasto | 2 |
| 12139 | aplastar | 2 |
| 12140 | aplastado | 2 |
| 12141 | aplastadas | 2 |
| 12142 | apiñadas | 2 |
| 12143 | apetitosos | 2 |
| 12144 | apetitosa | 2 |
| 12145 | apencar | 2 |
| 12146 | aparentes | 2 |
| 12147 | aparentemente | 2 |
| 12148 | aparentar | 2 |
| 12149 | aparentando | 2 |
| 12150 | aparecieron | 2 |
| 12151 | apareciendo | 2 |
| 12152 | aparece | 2 |
| 12153 | aparatosa | 2 |
| 12154 | aparatos | 2 |
| 12155 | apagadas | 2 |
| 12156 | añadido | 2 |
| 12157 | anzuelo | 2 |
| 12158 | anunció | 2 |
| 12159 | anuncio | 2 |
| 12160 | anunciarse | 2 |
| 12161 | anunciando | 2 |
| 12162 | anuncian | 2 |
| 12163 | antonomasia | 2 |
| 12164 | antonio | 2 |
| 12165 | antoja | 2 |
| 12166 | antitéticos | 2 |
| 12167 | antinomia | 2 |
| 12168 | antífrasis | 2 |
| 12169 | anticuado | 2 |
| 12170 | anticipo | 2 |
| 12171 | anónimos | 2 |
| 12172 | anónimo | 2 |
| 12173 | annatas | 2 |
| 12174 | aniversario | 2 |
| 12175 | aniquilamiento | 2 |
| 12176 | ánimos | 2 |
| 12177 | animándose | 2 |
| 12178 | animadora | 2 |
| 12179 | anima | 2 |
| 12180 | anhelante | 2 |
| 12181 | anhelaba | 2 |
| 12182 | angulosa | 2 |
| 12183 | angosto | 2 |
| 12184 | angostas | 2 |
| 12185 | angelillo | 2 |
| 12186 | angelical | 2 |
| 12187 | anfiteatro | 2 |
| 12188 | anegado | 2 |
| 12189 | andrajosos | 2 |
| 12190 | andén | 2 |
| 12191 | anden | 2 |
| 12192 | andará | 2 |
| 12193 | andamiaje | 2 |
| 12194 | anatomía | 2 |
| 12195 | analizar | 2 |
| 12196 | anafrodita | 2 |
| 12197 | amorosamente | 2 |
| 12198 | amontonaban | 2 |
| 12199 | amiguitas | 2 |
| 12200 | amenazando | 2 |
| 12201 | ambrosio | 2 |
| 12202 | ámbitos | 2 |
| 12203 | amazona | 2 |
| 12204 | amas | 2 |
| 12205 | amarlas | 2 |
| 12206 | amarillas | 2 |
| 12207 | amargos | 2 |
| 12208 | amargor | 2 |
| 12209 | amaré | 2 |
| 12210 | amanerado | 2 |
| 12211 | amanerada | 2 |
| 12212 | amando | 2 |
| 12213 | aman | 2 |
| 12214 | amador | 2 |
| 12215 | alzar | 2 |
| 12216 | alvarín | 2 |
| 12217 | alusivos | 2 |
| 12218 | alusivo | 2 |
| 12219 | alumbrar | 2 |
| 12220 | alumbrada | 2 |
| 12221 | aludió | 2 |
| 12222 | aludido | 2 |
| 12223 | alude | 2 |
| 12224 | alucinación | 2 |
| 12225 | alturas | 2 |
| 12226 | altruista | 2 |
| 12227 | altozanos | 2 |
| 12228 | altiva | 2 |
| 12229 | alternativamente | 2 |
| 12230 | alternaban | 2 |
| 12231 | alteración | 2 |
| 12232 | altanera | 2 |
| 12233 | alquiler | 2 |
| 12234 | almorzar | 2 |
| 12235 | almohadillas | 2 |
| 12236 | almo | 2 |
| 12237 | almidonada | 2 |
| 12238 | almacén | 2 |
| 12239 | alimentarse | 2 |
| 12240 | alimentado | 2 |
| 12241 | alimentaba | 2 |
| 12242 | alhambra | 2 |
| 12243 | aleluya | 2 |
| 12244 | alejar | 2 |
| 12245 | alejandro | 2 |
| 12246 | alejandría | 2 |
| 12247 | alegra | 2 |
| 12248 | aleación | 2 |
| 12249 | aldeanas | 2 |
| 12250 | aldabón | 2 |
| 12251 | alcoholismo | 2 |
| 12252 | alcobas | 2 |
| 12253 | alcanzaron | 2 |
| 12254 | alborotadores | 2 |
| 12255 | alborota | 2 |
| 12256 | albañiles | 2 |
| 12257 | albañil | 2 |
| 12258 | alarmar | 2 |
| 12259 | alarmado | 2 |
| 12260 | alargaba | 2 |
| 12261 | alambre | 2 |
| 12262 | alambicados | 2 |
| 12263 | alambicado | 2 |
| 12264 | alambicada | 2 |
| 12265 | alabado | 2 |
| 12266 | alaba | 2 |
| 12267 | aislamiento | 2 |
| 12268 | airecillo | 2 |
| 12269 | ahorrarme | 2 |
| 12270 | ahondaba | 2 |
| 12271 | ahogarle | 2 |
| 12272 | ahogándose | 2 |
| 12273 | ahoga | 2 |
| 12274 | aguardar | 2 |
| 12275 | aguantaba | 2 |
| 12276 | aguaceros | 2 |
| 12277 | agridulce | 2 |
| 12278 | agregó | 2 |
| 12279 | agravó | 2 |
| 12280 | agravios | 2 |
| 12281 | agradezco | 2 |
| 12282 | agradecer | 2 |
| 12283 | agradarla | 2 |
| 12284 | agradables | 2 |
| 12285 | agitado | 2 |
| 12286 | agarrado | 2 |
| 12287 | áfrica | 2 |
| 12288 | afortunado | 2 |
| 12289 | afligidos | 2 |
| 12290 | afirmó | 2 |
| 12291 | afirman | 2 |
| 12292 | afeminamiento | 2 |
| 12293 | afeitados | 2 |
| 12294 | afectado | 2 |
| 12295 | afabilidad | 2 |
| 12296 | advertirle | 2 |
| 12297 | advertida | 2 |
| 12298 | advertencia | 2 |
| 12299 | adusto | 2 |
| 12300 | adulación | 2 |
| 12301 | adquiridas | 2 |
| 12302 | adquirida | 2 |
| 12303 | adquiría | 2 |
| 12304 | adornado | 2 |
| 12305 | adoratrices | 2 |
| 12306 | adocenados | 2 |
| 12307 | admiten | 2 |
| 12308 | admita | 2 |
| 12309 | admiraciones | 2 |
| 12310 | admirables | 2 |
| 12311 | adivinación | 2 |
| 12312 | adelantó | 2 |
| 12313 | adelantarse | 2 |
| 12314 | adelantada | 2 |
| 12315 | adelanta | 2 |
| 12316 | adaptación | 2 |
| 12317 | adán | 2 |
| 12318 | acusarse | 2 |
| 12319 | acusación | 2 |
| 12320 | acumulado | 2 |
| 12321 | acuesta | 2 |
| 12322 | acuerdan | 2 |
| 12323 | actualmente | 2 |
| 12324 | actualidad | 2 |
| 12325 | actuales | 2 |
| 12326 | actor | 2 |
| 12327 | acreditados | 2 |
| 12328 | acostumbró | 2 |
| 12329 | acostumbrados | 2 |
| 12330 | acostumbraban | 2 |
| 12331 | acostado | 2 |
| 12332 | acosado | 2 |
| 12333 | acordes | 2 |
| 12334 | acordarás | 2 |
| 12335 | acordaban | 2 |
| 12336 | aconsejarle | 2 |
| 12337 | aconsejar | 2 |
| 12338 | aconsejado | 2 |
| 12339 | aconsejaba | 2 |
| 12340 | aconseja | 2 |
| 12341 | acompasados | 2 |
| 12342 | acompañarle | 2 |
| 12343 | acomodo | 2 |
| 12344 | acoger | 2 |
| 12345 | aclaraban | 2 |
| 12346 | aclaraba | 2 |
| 12347 | achaque | 2 |
| 12348 | achacoso | 2 |
| 12349 | acertó | 2 |
| 12350 | acertado | 2 |
| 12351 | acercase | 2 |
| 12352 | acercando | 2 |
| 12353 | acequia | 2 |
| 12354 | aceituna | 2 |
| 12355 | accediendo | 2 |
| 12356 | acariciaba | 2 |
| 12357 | acaloró | 2 |
| 12358 | académico | 2 |
| 12359 | académica | 2 |
| 12360 | academia | 2 |
| 12361 | acabe | 2 |
| 12362 | acabarse | 2 |
| 12363 | acabara | 2 |
| 12364 | acaban | 2 |
| 12365 | abusar | 2 |
| 12366 | abusado | 2 |
| 12367 | abusaba | 2 |
| 12368 | abusa | 2 |
| 12369 | aburrían | 2 |
| 12370 | aburre | 2 |
| 12371 | abundaban | 2 |
| 12372 | abultadas | 2 |
| 12373 | abuelos | 2 |
| 12374 | abuela | 2 |
| 12375 | abstracciones | 2 |
| 12376 | abstinencia | 2 |
| 12377 | abstengo | 2 |
| 12378 | absolvía | 2 |
| 12379 | abrumados | 2 |
| 12380 | abroño | 2 |
| 12381 | abrochaba | 2 |
| 12382 | abriría | 2 |
| 12383 | abriera | 2 |
| 12384 | abrazar | 2 |
| 12385 | abrazado | 2 |
| 12386 | abrasarse | 2 |
| 12387 | abrasados | 2 |
| 12388 | aborrezco | 2 |
| 12389 | aborreciendo | 2 |
| 12390 | abordar | 2 |
| 12391 | abonadas | 2 |
| 12392 | abogados | 2 |
| 12393 | abismarse | 2 |
| 12394 | aberración | 2 |
| 12395 | abecedario | 2 |
| 12396 | abdomen | 2 |
| 12397 | abdicar | 2 |
| 12398 | abandonase | 2 |
| 12399 | abandonarse | 2 |
| 12400 | abandona | 2 |
| 12401 | zurriagazo | 1 |
| 12402 | zurcidos | 1 |
| 12403 | zurcido | 1 |
| 12404 | zurbarán | 1 |
| 12405 | zumbaban | 1 |
| 12406 | zumarri | 1 |
| 12407 | zuecos | 1 |
| 12408 | zueco | 1 |
| 12409 | zuavo | 1 |
| 12410 | zozobra | 1 |
| 12411 | zoológica | 1 |
| 12412 | zona | 1 |
| 12413 | zodiaco | 1 |
| 12414 | zascandil | 1 |
| 12415 | zarzuelas | 1 |
| 12416 | zarzaparrilla | 1 |
| 12417 | zarza | 1 |
| 12418 | zarpa | 1 |
| 12419 | zarandeando | 1 |
| 12420 | zarandeaban | 1 |
| 12421 | zarandajas | 1 |
| 12422 | zaquizamí | 1 |
| 12423 | zapatilla | 1 |
| 12424 | zángano | 1 |
| 12425 | zancadilla | 1 |
| 12426 | zambulló | 1 |
| 12427 | zamarra | 1 |
| 12428 | zamacois | 1 |
| 12429 | zalamea | 1 |
| 12430 | zag | 1 |
| 12431 | zafio | 1 |
| 12432 | yodo | 1 |
| 12433 | yema | 1 |
| 12434 | xxx | 1 |
| 12435 | xxviii | 1 |
| 12436 | xxvii | 1 |
| 12437 | xxvi | 1 |
| 12438 | xxv | 1 |
| 12439 | xxix | 1 |
| 12440 | xxiv | 1 |
| 12441 | xxiii | 1 |
| 12442 | xxii | 1 |
| 12443 | xxi | 1 |
| 12444 | xx | 1 |
| 12445 | xviii | 1 |
| 12446 | xvii | 1 |
| 12447 | xvi | 1 |
| 12448 | xix | 1 |
| 12449 | xiii | 1 |
| 12450 | xii | 1 |
| 12451 | xi | 1 |
| 12452 | wisseman | 1 |
| 12453 | wieland | 1 |
| 12454 | washingtonia | 1 |
| 12455 | w | 1 |
| 12456 | vulgarísimo | 1 |
| 12457 | vulgaridad | 1 |
| 12458 | vuestros | 1 |
| 12459 | vuestro | 1 |
| 12460 | vuélvete | 1 |
| 12461 | vuelves | 1 |
| 12462 | vuela | 1 |
| 12463 | vuecencia | 1 |
| 12464 | voyageur | 1 |
| 12465 | vox | 1 |
| 12466 | votaron | 1 |
| 12467 | votaciones | 1 |
| 12468 | votación | 1 |
| 12469 | votaba | 1 |
| 12470 | vosotros | 1 |
| 12471 | vosotras | 1 |
| 12472 | volviolos | 1 |
| 12473 | volvimos | 1 |
| 12474 | volviéramos | 1 |
| 12475 | volvíase | 1 |
| 12476 | volvernos | 1 |
| 12477 | volverla | 1 |
| 12478 | volutas | 1 |
| 12479 | voluptuosas | 1 |
| 12480 | voluntario | 1 |
| 12481 | voluminoso | 1 |
| 12482 | volteriano | 1 |
| 12483 | voló | 1 |
| 12484 | volatilizándolo | 1 |
| 12485 | volaré | 1 |
| 12486 | volara | 1 |
| 12487 | volada | 1 |
| 12488 | vogt | 1 |
| 12489 | vocis | 1 |
| 12490 | vocinglera | 1 |
| 12491 | vociferando | 1 |
| 12492 | vociferaban | 1 |
| 12493 | vociferaba | 1 |
| 12494 | vocifera | 1 |
| 12495 | vocales | 1 |
| 12496 | vocaciones | 1 |
| 12497 | vocablos | 1 |
| 12498 | vobis | 1 |
| 12499 | vizconde | 1 |
| 12500 | vivirlas | 1 |
| 12501 | vivirá | 1 |
| 12502 | viviendas | 1 |
| 12503 | vividos | 1 |
| 12504 | vividor | 1 |
| 12505 | viví | 1 |
| 12506 | vivendi | 1 |
| 12507 | vivarachos | 1 |
| 12508 | vivan | 1 |
| 12509 | viudo | 1 |
| 12510 | vituperar | 1 |
| 12511 | vitriolo | 1 |
| 12512 | vitrina | 1 |
| 12513 | vitandos | 1 |
| 12514 | vitalidad | 1 |
| 12515 | vitalicia | 1 |
| 12516 | vita | 1 |
| 12517 | vistosos | 1 |
| 12518 | vistoso | 1 |
| 12519 | vístose | 1 |
| 12520 | vistosas | 1 |
| 12521 | vistos | 1 |
| 12522 | vistieron | 1 |
| 12523 | vistiera | 1 |
| 12524 | vísperas | 1 |
| 12525 | visos | 1 |
| 12526 | vislumbres | 1 |
| 12527 | vislumbrar | 1 |
| 12528 | visitarle | 1 |
| 12529 | visitara | 1 |
| 12530 | visitamos | 1 |
| 12531 | visitaciones | 1 |
| 12532 | visionaria | 1 |
| 12533 | visiblemente | 1 |
| 12534 | visera | 1 |
| 12535 | viseo | 1 |
| 12536 | viscosos | 1 |
| 12537 | vis | 1 |
| 12538 | viruelas | 1 |
| 12539 | virtutis | 1 |
| 12540 | virtuosas | 1 |
| 12541 | virilidad | 1 |
| 12542 | viriles | 1 |
| 12543 | virchov | 1 |
| 12544 | vir | 1 |
| 12545 | violentando | 1 |
| 12546 | violas | 1 |
| 12547 | viñas | 1 |
| 12548 | viña | 1 |
| 12549 | viniere | 1 |
| 12550 | viniendo | 1 |
| 12551 | vinci | 1 |
| 12552 | vinader | 1 |
| 12553 | vilo | 1 |
| 12554 | villavieja | 1 |
| 12555 | villancicos | 1 |
| 12556 | villanas | 1 |
| 12557 | villafranca | 1 |
| 12558 | villa | 1 |
| 12559 | vigoroso | 1 |
| 12560 | vigorizar | 1 |
| 12561 | vigilaré | 1 |
| 12562 | vigilara | 1 |
| 12563 | vigilar | 1 |
| 12564 | vigentes | 1 |
| 12565 | vieses | 1 |
| 12566 | viéramos | 1 |
| 12567 | vientecillo | 1 |
| 12568 | viéndolos | 1 |
| 12569 | viéndolas | 1 |
| 12570 | viéndola | 1 |
| 12571 | viena | 1 |
| 12572 | vien | 1 |
| 12573 | viejecito | 1 |
| 12574 | vidriosa | 1 |
| 12575 | vidrio | 1 |
| 12576 | videor | 1 |
| 12577 | vidente | 1 |
| 12578 | victis | 1 |
| 12579 | vicioso | 1 |
| 12580 | vicia | 1 |
| 12581 | vicepresidente | 1 |
| 12582 | vicarios | 1 |
| 12583 | vibrando | 1 |
| 12584 | vibraba | 1 |
| 12585 | viborezno | 1 |
| 12586 | víbora | 1 |
| 12587 | viático | 1 |
| 12588 | vías | 1 |
| 12589 | viajado | 1 |
| 12590 | viajaba | 1 |
| 12591 | viable | 1 |
| 12592 | vetustente | 1 |
| 12593 | vetustas | 1 |
| 12594 | veteranos | 1 |
| 12595 | veterano | 1 |
| 12596 | vestusta | 1 |
| 12597 | vestuario | 1 |
| 12598 | vestimos | 1 |
| 12599 | vestimenta | 1 |
| 12600 | vestiglos | 1 |
| 12601 | vertió | 1 |
| 12602 | vértigo | 1 |
| 12603 | vertieron | 1 |
| 12604 | vertiente | 1 |
| 12605 | vertido | 1 |
| 12606 | vertical | 1 |
| 12607 | vertederos | 1 |
| 12608 | versión | 1 |
| 12609 | versículo | 1 |
| 12610 | versate | 1 |
| 12611 | versalles | 1 |
| 12612 | veros | 1 |
| 12613 | vernos | 1 |
| 12614 | vermis | 1 |
| 12615 | verles | 1 |
| 12616 | verificar | 1 |
| 12617 | vergüenzas | 1 |
| 12618 | vergonzosas | 1 |
| 12619 | veremundo | 1 |
| 12620 | veréis | 1 |
| 12621 | verduleras | 1 |
| 12622 | verdosas | 1 |
| 12623 | verdinegro | 1 |
| 12624 | verbum | 1 |
| 12625 | verbosidad | 1 |
| 12626 | verbo | 1 |
| 12627 | verbigracia | 1 |
| 12628 | veraniega | 1 |
| 12629 | veraneo | 1 |
| 12630 | veraneado | 1 |
| 12631 | veraneaban | 1 |
| 12632 | veraneaba | 1 |
| 12633 | venzo | 1 |
| 12634 | ventrílocuo | 1 |
| 12635 | ventilen | 1 |
| 12636 | ventilar | 1 |
| 12637 | ventilaba | 1 |
| 12638 | venteros | 1 |
| 12639 | ventanillo | 1 |
| 12640 | ventanillas | 1 |
| 12641 | venta | 1 |
| 12642 | venirle | 1 |
| 12643 | venideras | 1 |
| 12644 | venida | 1 |
| 12645 | venid | 1 |
| 12646 | venias | 1 |
| 12647 | venia | 1 |
| 12648 | vengarme | 1 |
| 12649 | vengándose | 1 |
| 12650 | vengando | 1 |
| 12651 | vengado | 1 |
| 12652 | vengaban | 1 |
| 12653 | venero | 1 |
| 12654 | venerando | 1 |
| 12655 | venenos | 1 |
| 12656 | veneciana | 1 |
| 12657 | venecia | 1 |
| 12658 | vendrían | 1 |
| 12659 | vendrás | 1 |
| 12660 | vendo | 1 |
| 12661 | vendiese | 1 |
| 12662 | vendiendo | 1 |
| 12663 | venderse | 1 |
| 12664 | venderlos | 1 |
| 12665 | vender | 1 |
| 12666 | venciendo | 1 |
| 12667 | vencí | 1 |
| 12668 | vencerme | 1 |
| 12669 | vencerlos | 1 |
| 12670 | vencerlas | 1 |
| 12671 | vencedora | 1 |
| 12672 | venales | 1 |
| 12673 | vena | 1 |
| 12674 | velón | 1 |
| 12675 | velocidad | 1 |
| 12676 | velludo | 1 |
| 12677 | velluda | 1 |
| 12678 | vellones | 1 |
| 12679 | velis | 1 |
| 12680 | veleidoso | 1 |
| 12681 | velarle | 1 |
| 12682 | velando | 1 |
| 12683 | velados | 1 |
| 12684 | velado | 1 |
| 12685 | vejetes | 1 |
| 12686 | vejamen | 1 |
| 12687 | veintitrés | 1 |
| 12688 | veíalo | 1 |
| 12689 | veíalas | 1 |
| 12690 | veíala | 1 |
| 12691 | vehículo | 1 |
| 12692 | vehemencia | 1 |
| 12693 | veguellinas | 1 |
| 12694 | vegetando | 1 |
| 12695 | vegetación | 1 |
| 12696 | vegetaba | 1 |
| 12697 | vegallanas | 1 |
| 12698 | vedado | 1 |
| 12699 | veamos | 1 |
| 12700 | veáis | 1 |
| 12701 | váyase | 1 |
| 12702 | vauban | 1 |
| 12703 | vate | 1 |
| 12704 | vastos | 1 |
| 12705 | vastísimos | 1 |
| 12706 | vastísimo | 1 |
| 12707 | vástago | 1 |
| 12708 | vasares | 1 |
| 12709 | variantes | 1 |
| 12710 | variados | 1 |
| 12711 | variadas | 1 |
| 12712 | variada | 1 |
| 12713 | variación | 1 |
| 12714 | variaba | 1 |
| 12715 | vaqueros | 1 |
| 12716 | vaquero | 1 |
| 12717 | vaporosos | 1 |
| 12718 | vaporoso | 1 |
| 12719 | vaporosa | 1 |
| 12720 | vanidosos | 1 |
| 12721 | vanidoso | 1 |
| 12722 | vanagloriarse | 1 |
| 12723 | vanagloriaba | 1 |
| 12724 | vampiro | 1 |
| 12725 | valió | 1 |
| 12726 | valieran | 1 |
| 12727 | valiéndose | 1 |
| 12728 | valían | 1 |
| 12729 | válgate | 1 |
| 12730 | valetudinario | 1 |
| 12731 | valerosos | 1 |
| 12732 | valeroso | 1 |
| 12733 | valera | 1 |
| 12734 | valentísimo | 1 |
| 12735 | valentías | 1 |
| 12736 | valentía | 1 |
| 12737 | valemos | 1 |
| 12738 | valdrían | 1 |
| 12739 | valdría | 1 |
| 12740 | valdiñón | 1 |
| 12741 | vaivenes | 1 |
| 12742 | vais | 1 |
| 12743 | vaina | 1 |
| 12744 | vaguedades | 1 |
| 12745 | vagaban | 1 |
| 12746 | vae | 1 |
| 12747 | vacilando | 1 |
| 12748 | vacías | 1 |
| 12749 | vacantes | 1 |
| 12750 | uva | 1 |
| 12751 | utrecht | 1 |
| 12752 | utilizado | 1 |
| 12753 | utilizaba | 1 |
| 12754 | utilitario | 1 |
| 12755 | utilidades | 1 |
| 12756 | útiles | 1 |
| 12757 | utile | 1 |
| 12758 | utero | 1 |
| 12759 | utensilios | 1 |
| 12760 | usurpador | 1 |
| 12761 | usura | 1 |
| 12762 | usual | 1 |
| 12763 | usté | 1 |
| 12764 | usos | 1 |
| 12765 | usen | 1 |
| 12766 | usase | 1 |
| 12767 | usarse | 1 |
| 12768 | usarlo | 1 |
| 12769 | usara | 1 |
| 12770 | usados | 1 |
| 12771 | usada | 1 |
| 12772 | us | 1 |
| 12773 | urgentísimo | 1 |
| 12774 | urdido | 1 |
| 12775 | urbicesorbi | 1 |
| 12776 | urbano | 1 |
| 12777 | urbanidad | 1 |
| 12778 | urbana | 1 |
| 12779 | unto | 1 |
| 12780 | untados | 1 |
| 12781 | untaba | 1 |
| 12782 | universidades | 1 |
| 12783 | universi | 1 |
| 12784 | unísono | 1 |
| 12785 | unió | 1 |
| 12786 | unidas | 1 |
| 12787 | únicos | 1 |
| 12788 | uníase | 1 |
| 12789 | unía | 1 |
| 12790 | uní | 1 |
| 12791 | une | 1 |
| 12792 | ultratelúrica | 1 |
| 12793 | ultramontano | 1 |
| 12794 | ultramontanismo | 1 |
| 12795 | ultramontanas | 1 |
| 12796 | ultrajando | 1 |
| 12797 | ultrajada | 1 |
| 12798 | ulloa | 1 |
| 12799 | ujier | 1 |
| 12800 | ue | 1 |
| 12801 | tuyo | 1 |
| 12802 | tuy | 1 |
| 12803 | tuviste | 1 |
| 12804 | tuviéramos | 1 |
| 12805 | tutor | 1 |
| 12806 | tutela | 1 |
| 12807 | tute | 1 |
| 12808 | turris | 1 |
| 12809 | turres | 1 |
| 12810 | turquía | 1 |
| 12811 | turpia | 1 |
| 12812 | turnaban | 1 |
| 12813 | turgencia | 1 |
| 12814 | turcas | 1 |
| 12815 | turbio | 1 |
| 12816 | turbias | 1 |
| 12817 | turbarle | 1 |
| 12818 | turbante | 1 |
| 12819 | turbándose | 1 |
| 12820 | turbamulta | 1 |
| 12821 | turbaciones | 1 |
| 12822 | turbación | 1 |
| 12823 | tupida | 1 |
| 12824 | túnicas | 1 |
| 12825 | túnel | 1 |
| 12826 | tunantes | 1 |
| 12827 | tunanta | 1 |
| 12828 | tumban | 1 |
| 12829 | tumbados | 1 |
| 12830 | tugurios | 1 |
| 12831 | tufillo | 1 |
| 12832 | tuesta | 1 |
| 12833 | tuerces | 1 |
| 12834 | tuerce | 1 |
| 12835 | tuerca | 1 |
| 12836 | tubos | 1 |
| 12837 | tuberculosis | 1 |
| 12838 | tuae | 1 |
| 12839 | truqueurs | 1 |
| 12840 | truncado | 1 |
| 12841 | truenan | 1 |
| 12842 | trozos | 1 |
| 12843 | troya | 1 |
| 12844 | trotes | 1 |
| 12845 | tropo | 1 |
| 12846 | tropiece | 1 |
| 12847 | tropezasen | 1 |
| 12848 | tropel | 1 |
| 12849 | trono | 1 |
| 12850 | tronar | 1 |
| 12851 | tronados | 1 |
| 12852 | tronaba | 1 |
| 12853 | trompeteada | 1 |
| 12854 | trompas | 1 |
| 12855 | trocitos | 1 |
| 12856 | trochas | 1 |
| 12857 | trocha | 1 |
| 12858 | trocarse | 1 |
| 12859 | trocados | 1 |
| 12860 | triunfe | 1 |
| 12861 | triunfantes | 1 |
| 12862 | triunfando | 1 |
| 12863 | triunfal | 1 |
| 12864 | triunfaban | 1 |
| 12865 | triunfa | 1 |
| 12866 | tristemente | 1 |
| 12867 | tripulando | 1 |
| 12868 | tripulaban | 1 |
| 12869 | triple | 1 |
| 12870 | tripa | 1 |
| 12871 | trincheras | 1 |
| 12872 | trinchante | 1 |
| 12873 | trimestre | 1 |
| 12874 | trifoncito | 1 |
| 12875 | trifoncillo | 1 |
| 12876 | trifona | 1 |
| 12877 | tridentino | 1 |
| 12878 | tributó | 1 |
| 12879 | tributar | 1 |
| 12880 | tributaban | 1 |
| 12881 | tribus | 1 |
| 12882 | tribunales | 1 |
| 12883 | triángulo | 1 |
| 12884 | trepidación | 1 |
| 12885 | trepando | 1 |
| 12886 | trepaba | 1 |
| 12887 | trepa | 1 |
| 12888 | trenzados | 1 |
| 12889 | trena | 1 |
| 12890 | trémolo | 1 |
| 12891 | treguas | 1 |
| 12892 | trazó | 1 |
| 12893 | trazaba | 1 |
| 12894 | travesaños | 1 |
| 12895 | tratos | 1 |
| 12896 | traté | 1 |
| 12897 | tratarse | 1 |
| 12898 | tratarlo | 1 |
| 12899 | tratarle | 1 |
| 12900 | tratarla | 1 |
| 12901 | tratando | 1 |
| 12902 | tratados | 1 |
| 12903 | tratable | 1 |
| 12904 | trasvolado | 1 |
| 12905 | trasunto | 1 |
| 12906 | trasplantada | 1 |
| 12907 | trasplantaba | 1 |
| 12908 | traspasar | 1 |
| 12909 | trasnochar | 1 |
| 12910 | trasnochado | 1 |
| 12911 | trasnochaban | 1 |
| 12912 | traslucir | 1 |
| 12913 | trasladaron | 1 |
| 12914 | trasladarle | 1 |
| 12915 | trasladándose | 1 |
| 12916 | trasladándonos | 1 |
| 12917 | trasladan | 1 |
| 12918 | trasladaba | 1 |
| 12919 | trascender | 1 |
| 12920 | trascendencia | 1 |
| 12921 | traqueteo | 1 |
| 12922 | trapicheo | 1 |
| 12923 | trapacero | 1 |
| 12924 | tranvías | 1 |
| 12925 | transportada | 1 |
| 12926 | transparente | 1 |
| 12927 | transparentarse | 1 |
| 12928 | transparentando | 1 |
| 12929 | transmitían | 1 |
| 12930 | tránsito | 1 |
| 12931 | transijo | 1 |
| 12932 | transigió | 1 |
| 12933 | transigía | 1 |
| 12934 | transición | 1 |
| 12935 | transfusiones | 1 |
| 12936 | transfusión | 1 |
| 12937 | transformismo | 1 |
| 12938 | transformase | 1 |
| 12939 | transformado | 1 |
| 12940 | transformación | 1 |
| 12941 | transcurrido | 1 |
| 12942 | transacción | 1 |
| 12943 | tranquilizado | 1 |
| 12944 | tranquilizaba | 1 |
| 12945 | trances | 1 |
| 12946 | tramposo | 1 |
| 12947 | tramando | 1 |
| 12948 | tramaban | 1 |
| 12949 | trajese | 1 |
| 12950 | traiga | 1 |
| 12951 | traídos | 1 |
| 12952 | traidoras | 1 |
| 12953 | traída | 1 |
| 12954 | tragué | 1 |
| 12955 | trago | 1 |
| 12956 | trágicos | 1 |
| 12957 | tragedias | 1 |
| 12958 | tragas | 1 |
| 12959 | tragármela | 1 |
| 12960 | tragaría | 1 |
| 12961 | tragaluces | 1 |
| 12962 | tragaban | 1 |
| 12963 | traerlos | 1 |
| 12964 | traerle | 1 |
| 12965 | traerla | 1 |
| 12966 | traería | 1 |
| 12967 | traerá | 1 |
| 12968 | traductora | 1 |
| 12969 | traducidos | 1 |
| 12970 | tradicionalmente | 1 |
| 12971 | trabucos | 1 |
| 12972 | trabillas | 1 |
| 12973 | trabajó | 1 |
| 12974 | trabajase | 1 |
| 12975 | tostasen | 1 |
| 12976 | tostado | 1 |
| 12977 | tostadas | 1 |
| 12978 | tosiendo | 1 |
| 12979 | tosido | 1 |
| 12980 | toscas | 1 |
| 12981 | torvo | 1 |
| 12982 | tortuosos | 1 |
| 12983 | tortillas | 1 |
| 12984 | tortilla | 1 |
| 12985 | torrente | 1 |
| 12986 | torpemente | 1 |
| 12987 | toro | 1 |
| 12988 | tornillos | 1 |
| 12989 | tornadiza | 1 |
| 12990 | tornaba | 1 |
| 12991 | tormentas | 1 |
| 12992 | toreros | 1 |
| 12993 | torcuato | 1 |
| 12994 | torcieron | 1 |
| 12995 | torciéndose | 1 |
| 12996 | torciendo | 1 |
| 12997 | torcidos | 1 |
| 12998 | torcedor | 1 |
| 12999 | toral | 1 |
| 13000 | toraces | 1 |
| 13001 | tópicos | 1 |
| 13002 | tópico | 1 |
| 13003 | topetazo | 1 |
| 13004 | too | 1 |
| 13005 | tontunas | 1 |
| 13006 | tontina | 1 |
| 13007 | tontear | 1 |
| 13008 | tontas | 1 |
| 13009 | tonillo | 1 |
| 13010 | ton | 1 |
| 13011 | tomos | 1 |
| 13012 | tomé | 1 |
| 13013 | tomase | 1 |
| 13014 | tomarlo | 1 |
| 13015 | tomarla | 1 |
| 13016 | tomarán | 1 |
| 13017 | tomará | 1 |
| 13018 | tomándolo | 1 |
| 13019 | tomándole | 1 |
| 13020 | tomadas | 1 |
| 13021 | tomada | 1 |
| 13022 | toleres | 1 |
| 13023 | toleraron | 1 |
| 13024 | tolerarlo | 1 |
| 13025 | toleraría | 1 |
| 13026 | toleran | 1 |
| 13027 | toleradas | 1 |
| 13028 | toleraban | 1 |
| 13029 | tolera | 1 |
| 13030 | tole | 1 |
| 13031 | tocase | 1 |
| 13032 | tocas | 1 |
| 13033 | tocarlos | 1 |
| 13034 | tocarás | 1 |
| 13035 | tocándole | 1 |
| 13036 | tocándola | 1 |
| 13037 | tocada | 1 |
| 13038 | tobillo | 1 |
| 13039 | tiznes | 1 |
| 13040 | tiznándole | 1 |
| 13041 | tiznado | 1 |
| 13042 | titulados | 1 |
| 13043 | titulado | 1 |
| 13044 | titubear | 1 |
| 13045 | tito | 1 |
| 13046 | titilar | 1 |
| 13047 | títeres | 1 |
| 13048 | titanes | 1 |
| 13049 | titán | 1 |
| 13050 | tísico | 1 |
| 13051 | tirsos | 1 |
| 13052 | tiroteo | 1 |
| 13053 | tiritando | 1 |
| 13054 | tirilla | 1 |
| 13055 | tiraría | 1 |
| 13056 | tiránico | 1 |
| 13057 | tiple | 1 |
| 13058 | tío | 1 |
| 13059 | tiñéndolo | 1 |
| 13060 | tinteros | 1 |
| 13061 | tintero | 1 |
| 13062 | tímpano | 1 |
| 13063 | timoratos | 1 |
| 13064 | timorata | 1 |
| 13065 | tímido | 1 |
| 13066 | tímidas | 1 |
| 13067 | timarse | 1 |
| 13068 | timaban | 1 |
| 13069 | timaba | 1 |
| 13070 | tigres | 1 |
| 13071 | tiesos | 1 |
| 13072 | tiernísimo | 1 |
| 13073 | tiernísima | 1 |
| 13074 | tiende | 1 |
| 13075 | tiemblas | 1 |
| 13076 | tiembla | 1 |
| 13077 | tiburón | 1 |
| 13078 | tibios | 1 |
| 13079 | thackeray | 1 |
| 13080 | tétrico | 1 |
| 13081 | tetrarca | 1 |
| 13082 | tessitura | 1 |
| 13083 | terso | 1 |
| 13084 | terruño | 1 |
| 13085 | terrorista | 1 |
| 13086 | terrores | 1 |
| 13087 | terrón | 1 |
| 13088 | territorio | 1 |
| 13089 | terrenas | 1 |
| 13090 | terranova | 1 |
| 13091 | terrados | 1 |
| 13092 | terrado | 1 |
| 13093 | terpsícore | 1 |
| 13094 | ternuras | 1 |
| 13095 | ternezas | 1 |
| 13096 | termómetro | 1 |
| 13097 | termine | 1 |
| 13098 | terminasen | 1 |
| 13099 | terminantemente | 1 |
| 13100 | terminando | 1 |
| 13101 | terminadas | 1 |
| 13102 | terminaciones | 1 |
| 13103 | terminaban | 1 |
| 13104 | tergiversemos | 1 |
| 13105 | tercos | 1 |
| 13106 | terciar | 1 |
| 13107 | terciado | 1 |
| 13108 | terciaba | 1 |
| 13109 | tercetos | 1 |
| 13110 | tercas | 1 |
| 13111 | terapéutica | 1 |
| 13112 | teórica | 1 |
| 13113 | teorías | 1 |
| 13114 | teólogos | 1 |
| 13115 | teológicos | 1 |
| 13116 | teócrito | 1 |
| 13117 | teocrático | 1 |
| 13118 | teñidas | 1 |
| 13119 | tenues | 1 |
| 13120 | tentativa | 1 |
| 13121 | tentarse | 1 |
| 13122 | tentar | 1 |
| 13123 | tentando | 1 |
| 13124 | tentadores | 1 |
| 13125 | tentadora | 1 |
| 13126 | tentáculos | 1 |
| 13127 | tenientes | 1 |
| 13128 | teniendo | 1 |
| 13129 | tenida | 1 |
| 13130 | tenias | 1 |
| 13131 | tenia | 1 |
| 13132 | tengan | 1 |
| 13133 | tengamos | 1 |
| 13134 | tenerles | 1 |
| 13135 | tenerlas | 1 |
| 13136 | tenebrosa | 1 |
| 13137 | tendrían | 1 |
| 13138 | tendríamos | 1 |
| 13139 | tendrán | 1 |
| 13140 | tendieron | 1 |
| 13141 | tendiendo | 1 |
| 13142 | tendían | 1 |
| 13143 | tender | 1 |
| 13144 | tenaz | 1 |
| 13145 | tenaces | 1 |
| 13146 | tempranos | 1 |
| 13147 | temprana | 1 |
| 13148 | temporis | 1 |
| 13149 | temporadas | 1 |
| 13150 | tempora | 1 |
| 13151 | templete | 1 |
| 13152 | templar | 1 |
| 13153 | templanza | 1 |
| 13154 | tempestades | 1 |
| 13155 | tempé | 1 |
| 13156 | temiéndolo | 1 |
| 13157 | temido | 1 |
| 13158 | temida | 1 |
| 13159 | temías | 1 |
| 13160 | temes | 1 |
| 13161 | temerosa | 1 |
| 13162 | temerones | 1 |
| 13163 | temeridades | 1 |
| 13164 | temeridad | 1 |
| 13165 | temerarios | 1 |
| 13166 | temerario | 1 |
| 13167 | temeraria | 1 |
| 13168 | temblorosos | 1 |
| 13169 | tembloroso | 1 |
| 13170 | temblorcico | 1 |
| 13171 | temblase | 1 |
| 13172 | temblaron | 1 |
| 13173 | temblábale | 1 |
| 13174 | telones | 1 |
| 13175 | telescopio | 1 |
| 13176 | telegramas | 1 |
| 13177 | telégrafos | 1 |
| 13178 | tejiendo | 1 |
| 13179 | tejido | 1 |
| 13180 | tejadillos | 1 |
| 13181 | tecum | 1 |
| 13182 | técnico | 1 |
| 13183 | tecnicismo | 1 |
| 13184 | técnica | 1 |
| 13185 | teclas | 1 |
| 13186 | techos | 1 |
| 13187 | teatrales | 1 |
| 13188 | teatral | 1 |
| 13189 | tazas | 1 |
| 13190 | taurina | 1 |
| 13191 | tatiste | 1 |
| 13192 | tasso | 1 |
| 13193 | tascaba | 1 |
| 13194 | tartana | 1 |
| 13195 | tarso | 1 |
| 13196 | tarsilita | 1 |
| 13197 | tareas | 1 |
| 13198 | tardo | 1 |
| 13199 | tardío | 1 |
| 13200 | tardé | 1 |
| 13201 | tardaron | 1 |
| 13202 | tardado | 1 |
| 13203 | tardaban | 1 |
| 13204 | tarasca | 1 |
| 13205 | tapó | 1 |
| 13206 | tapizada | 1 |
| 13207 | tapiceros | 1 |
| 13208 | tapias | 1 |
| 13209 | tape | 1 |
| 13210 | taparse | 1 |
| 13211 | taparle | 1 |
| 13212 | taparelli | 1 |
| 13213 | tapándose | 1 |
| 13214 | tapado | 1 |
| 13215 | tapadillos | 1 |
| 13216 | tañida | 1 |
| 13217 | tañía | 1 |
| 13218 | tañedor | 1 |
| 13219 | tantico | 1 |
| 13220 | tamizada | 1 |
| 13221 | tamiz | 1 |
| 13222 | tamboril | 1 |
| 13223 | tambores | 1 |
| 13224 | tambaleándose | 1 |
| 13225 | tamaños | 1 |
| 13226 | tamañitos | 1 |
| 13227 | tallos | 1 |
| 13228 | tallado | 1 |
| 13229 | talismán | 1 |
| 13230 | talegas | 1 |
| 13231 | talares | 1 |
| 13232 | tajos | 1 |
| 13233 | taimado | 1 |
| 13234 | taimada | 1 |
| 13235 | taigeto | 1 |
| 13236 | tahúr | 1 |
| 13237 | tagarnina | 1 |
| 13238 | tafurería | 1 |
| 13239 | tafetán | 1 |
| 13240 | taconeo | 1 |
| 13241 | tacón | 1 |
| 13242 | taciturnos | 1 |
| 13243 | taciturnas | 1 |
| 13244 | tácitos | 1 |
| 13245 | tácitamente | 1 |
| 13246 | tacita | 1 |
| 13247 | tachó | 1 |
| 13248 | tachado | 1 |
| 13249 | tacha | 1 |
| 13250 | taburete | 1 |
| 13251 | tablillas | 1 |
| 13252 | tableros | 1 |
| 13253 | tabernáculo | 1 |
| 13254 | suum | 1 |
| 13255 | sutilísimas | 1 |
| 13256 | sutilezas | 1 |
| 13257 | sutileza | 1 |
| 13258 | susurros | 1 |
| 13259 | sustraérsele | 1 |
| 13260 | sustentase | 1 |
| 13261 | sustentadas | 1 |
| 13262 | sustanciales | 1 |
| 13263 | sustancial | 1 |
| 13264 | sustancia | 1 |
| 13265 | suspirado | 1 |
| 13266 | suspicacias | 1 |
| 13267 | suspensión | 1 |
| 13268 | suspendo | 1 |
| 13269 | suspendiesen | 1 |
| 13270 | suspendidos | 1 |
| 13271 | suspende | 1 |
| 13272 | susodicho | 1 |
| 13273 | suscripción | 1 |
| 13274 | suscitar | 1 |
| 13275 | suscitaba | 1 |
| 13276 | surgieron | 1 |
| 13277 | surgiendo | 1 |
| 13278 | surgido | 1 |
| 13279 | surcadas | 1 |
| 13280 | surcaban | 1 |
| 13281 | surbicesorbi | 1 |
| 13282 | suprimiendo | 1 |
| 13283 | suprimida | 1 |
| 13284 | suprimían | 1 |
| 13285 | supremacía | 1 |
| 13286 | supra | 1 |
| 13287 | suposición | 1 |
| 13288 | suponiéndole | 1 |
| 13289 | suponíalo | 1 |
| 13290 | suponérseles | 1 |
| 13291 | suponerlo | 1 |
| 13292 | suplir | 1 |
| 13293 | suplico | 1 |
| 13294 | suplicio | 1 |
| 13295 | suplicaron | 1 |
| 13296 | suplicarle | 1 |
| 13297 | suplicar | 1 |
| 13298 | súplica | 1 |
| 13299 | suplica | 1 |
| 13300 | suplían | 1 |
| 13301 | suplía | 1 |
| 13302 | suple | 1 |
| 13303 | supersticiosas | 1 |
| 13304 | superfino | 1 |
| 13305 | superficialidades | 1 |
| 13306 | superficialidad | 1 |
| 13307 | superficial | 1 |
| 13308 | superan | 1 |
| 13309 | superaba | 1 |
| 13310 | supeditado | 1 |
| 13311 | supeditada | 1 |
| 13312 | supe | 1 |
| 13313 | suñera | 1 |
| 13314 | suntuosa | 1 |
| 13315 | sunt | 1 |
| 13316 | sumirlo | 1 |
| 13317 | suministraba | 1 |
| 13318 | sumergida | 1 |
| 13319 | sumas | 1 |
| 13320 | sumando | 1 |
| 13321 | sum | 1 |
| 13322 | sulfure | 1 |
| 13323 | sujetos | 1 |
| 13324 | sujetándole | 1 |
| 13325 | sujetando | 1 |
| 13326 | sujétale | 1 |
| 13327 | suizas | 1 |
| 13328 | suicidarnos | 1 |
| 13329 | suicida | 1 |
| 13330 | sugirió | 1 |
| 13331 | sugiriese | 1 |
| 13332 | sugirieron | 1 |
| 13333 | sugiriéndole | 1 |
| 13334 | sugieran | 1 |
| 13335 | sugestión | 1 |
| 13336 | sugeridas | 1 |
| 13337 | sugerían | 1 |
| 13338 | sufrirlos | 1 |
| 13339 | sufrirle | 1 |
| 13340 | sufrirlas | 1 |
| 13341 | sufrirá | 1 |
| 13342 | sufrió | 1 |
| 13343 | sufrimientos | 1 |
| 13344 | sufrimiento | 1 |
| 13345 | sufridos | 1 |
| 13346 | sufragio | 1 |
| 13347 | sufra | 1 |
| 13348 | suene | 1 |
| 13349 | suenan | 1 |
| 13350 | sueldos | 1 |
| 13351 | suegro | 1 |
| 13352 | suecos | 1 |
| 13353 | sueco | 1 |
| 13354 | suecia | 1 |
| 13355 | sudario | 1 |
| 13356 | sudar | 1 |
| 13357 | sucursal | 1 |
| 13358 | sucumbían | 1 |
| 13359 | suculenta | 1 |
| 13360 | sucesores | 1 |
| 13361 | sucesivas | 1 |
| 13362 | sucesivamente | 1 |
| 13363 | sucesiva | 1 |
| 13364 | sucedieran | 1 |
| 13365 | sucediéndose | 1 |
| 13366 | sucederse | 1 |
| 13367 | sucedáneo | 1 |
| 13368 | sucedan | 1 |
| 13369 | suceda | 1 |
| 13370 | subversivo | 1 |
| 13371 | subversiva | 1 |
| 13372 | subvenciones | 1 |
| 13373 | suburbios | 1 |
| 13374 | subterfugios | 1 |
| 13375 | subteniente | 1 |
| 13376 | subsuelo | 1 |
| 13377 | substituía | 1 |
| 13378 | subsistir | 1 |
| 13379 | subsiguientes | 1 |
| 13380 | subsiguiente | 1 |
| 13381 | subrepticios | 1 |
| 13382 | subrayó | 1 |
| 13383 | subrayando | 1 |
| 13384 | subrayadas | 1 |
| 13385 | subrayaba | 1 |
| 13386 | sublimizado | 1 |
| 13387 | sublimiza | 1 |
| 13388 | sublevó | 1 |
| 13389 | sublevarse | 1 |
| 13390 | sublevaron | 1 |
| 13391 | sublevado | 1 |
| 13392 | sublevadas | 1 |
| 13393 | sublevaban | 1 |
| 13394 | subleva | 1 |
| 13395 | subjetivo | 1 |
| 13396 | súbitas | 1 |
| 13397 | subirla | 1 |
| 13398 | subiría | 1 |
| 13399 | subidos | 1 |
| 13400 | subidas | 1 |
| 13401 | subes | 1 |
| 13402 | suben | 1 |
| 13403 | súbditos | 1 |
| 13404 | subalternos | 1 |
| 13405 | suba | 1 |
| 13406 | suavice | 1 |
| 13407 | stulta | 1 |
| 13408 | stream | 1 |
| 13409 | strauss | 1 |
| 13410 | stoa | 1 |
| 13411 | sprit | 1 |
| 13412 | sposa | 1 |
| 13413 | sport | 1 |
| 13414 | splendorum | 1 |
| 13415 | spiritu | 1 |
| 13416 | spínolas | 1 |
| 13417 | sousa | 1 |
| 13418 | sostenido | 1 |
| 13419 | sostenga | 1 |
| 13420 | sostendré | 1 |
| 13421 | sospechoso | 1 |
| 13422 | sospechó | 1 |
| 13423 | sospecho | 1 |
| 13424 | sospecharse | 1 |
| 13425 | sospechabas | 1 |
| 13426 | sosiéguese | 1 |
| 13427 | sosiego | 1 |
| 13428 | sosegado | 1 |
| 13429 | sorteaba | 1 |
| 13430 | sorprendieron | 1 |
| 13431 | sorprendiera | 1 |
| 13432 | sorprendiéndola | 1 |
| 13433 | sorprendían | 1 |
| 13434 | sorprenderle | 1 |
| 13435 | sorprenda | 1 |
| 13436 | sordomudos | 1 |
| 13437 | sordina | 1 |
| 13438 | sórdidos | 1 |
| 13439 | sórdidas | 1 |
| 13440 | sórdida | 1 |
| 13441 | sordas | 1 |
| 13442 | sorbos | 1 |
| 13443 | sorbete | 1 |
| 13444 | soportar | 1 |
| 13445 | soportable | 1 |
| 13446 | soporíferos | 1 |
| 13447 | soporífera | 1 |
| 13448 | sopló | 1 |
| 13449 | soplarse | 1 |
| 13450 | soplándose | 1 |
| 13451 | soñolientos | 1 |
| 13452 | soñoliento | 1 |
| 13453 | soñolientas | 1 |
| 13454 | soñarlo | 1 |
| 13455 | soñaré | 1 |
| 13456 | soñadores | 1 |
| 13457 | sonsoniche | 1 |
| 13458 | sonrosadas | 1 |
| 13459 | sonrojaba | 1 |
| 13460 | sonrisilla | 1 |
| 13461 | sonriéndoles | 1 |
| 13462 | sonreírse | 1 |
| 13463 | sonorosos | 1 |
| 13464 | sonoro | 1 |
| 13465 | sonidos | 1 |
| 13466 | sonetos | 1 |
| 13467 | sondearle | 1 |
| 13468 | sondear | 1 |
| 13469 | sondeado | 1 |
| 13470 | sonda | 1 |
| 13471 | sonasen | 1 |
| 13472 | sonase | 1 |
| 13473 | sonarían | 1 |
| 13474 | sonara | 1 |
| 13475 | sonantes | 1 |
| 13476 | sonante | 1 |
| 13477 | sonámbulos | 1 |
| 13478 | sonámbula | 1 |
| 13479 | sonados | 1 |
| 13480 | sonada | 1 |
| 13481 | somieda | 1 |
| 13482 | sometieron | 1 |
| 13483 | sometidos | 1 |
| 13484 | sometido | 1 |
| 13485 | sometida | 1 |
| 13486 | sometía | 1 |
| 13487 | somete | 1 |
| 13488 | someros | 1 |
| 13489 | somera | 1 |
| 13490 | sombríos | 1 |
| 13491 | solterona | 1 |
| 13492 | solterón | 1 |
| 13493 | soltero | 1 |
| 13494 | solteras | 1 |
| 13495 | soltarse | 1 |
| 13496 | soltaron | 1 |
| 13497 | soltarlo | 1 |
| 13498 | soltar | 1 |
| 13499 | soltaba | 1 |
| 13500 | sollozo | 1 |
| 13501 | soliviantados | 1 |
| 13502 | sólido | 1 |
| 13503 | solideo | 1 |
| 13504 | sólidas | 1 |
| 13505 | solidaridad | 1 |
| 13506 | solidaria | 1 |
| 13507 | sólidamente | 1 |
| 13508 | solícitos | 1 |
| 13509 | solicitaron | 1 |
| 13510 | solicitan | 1 |
| 13511 | solicitado | 1 |
| 13512 | solicitada | 1 |
| 13513 | solicitación | 1 |
| 13514 | solicita | 1 |
| 13515 | solfeó | 1 |
| 13516 | solemos | 1 |
| 13517 | solemnes | 1 |
| 13518 | solecismos | 1 |
| 13519 | solazarse | 1 |
| 13520 | solar | 1 |
| 13521 | solapas | 1 |
| 13522 | solamente | 1 |
| 13523 | soit | 1 |
| 13524 | soga | 1 |
| 13525 | sofocar | 1 |
| 13526 | sofocado | 1 |
| 13527 | sofocaciones | 1 |
| 13528 | sofiones | 1 |
| 13529 | socorros | 1 |
| 13530 | socialismo | 1 |
| 13531 | sociable | 1 |
| 13532 | socia | 1 |
| 13533 | sochantre | 1 |
| 13534 | sobrón | 1 |
| 13535 | sobrios | 1 |
| 13536 | sobrio | 1 |
| 13537 | sobrino | 1 |
| 13538 | sobrinitas | 1 |
| 13539 | sobrevivirían | 1 |
| 13540 | sobrevivirá | 1 |
| 13541 | sobrevenía | 1 |
| 13542 | sobresalto | 1 |
| 13543 | sobresaltadas | 1 |
| 13544 | sobresaltada | 1 |
| 13545 | sobrenadó | 1 |
| 13546 | sobremesa | 1 |
| 13547 | sobrehumano | 1 |
| 13548 | sobrecogió | 1 |
| 13549 | sobrecogían | 1 |
| 13550 | sobrecogía | 1 |
| 13551 | sobrecogería | 1 |
| 13552 | sobras | 1 |
| 13553 | sobran | 1 |
| 13554 | sobramos | 1 |
| 13555 | sobradamente | 1 |
| 13556 | sobrada | 1 |
| 13557 | soberanos | 1 |
| 13558 | soberano | 1 |
| 13559 | soberanía | 1 |
| 13560 | sobadas | 1 |
| 13561 | sobaco | 1 |
| 13562 | sixto | 1 |
| 13563 | situada | 1 |
| 13564 | sitial | 1 |
| 13565 | sitiada | 1 |
| 13566 | sitiaba | 1 |
| 13567 | sistemática | 1 |
| 13568 | sisas | 1 |
| 13569 | sisar | 1 |
| 13570 | sirvieron | 1 |
| 13571 | sirves | 1 |
| 13572 | sirva | 1 |
| 13573 | siria | 1 |
| 13574 | sirenas | 1 |
| 13575 | sirena | 1 |
| 13576 | sinuoso | 1 |
| 13577 | sinuosidades | 1 |
| 13578 | sinuosa | 1 |
| 13579 | sintiéndolo | 1 |
| 13580 | sintetizan | 1 |
| 13581 | sinrazones | 1 |
| 13582 | sinónimo | 1 |
| 13583 | singularísima | 1 |
| 13584 | singulares | 1 |
| 13585 | síncopes | 1 |
| 13586 | síncope | 1 |
| 13587 | sinceras | 1 |
| 13588 | sinapismos | 1 |
| 13589 | simultáneos | 1 |
| 13590 | simultáneo | 1 |
| 13591 | simulacros | 1 |
| 13592 | simulaba | 1 |
| 13593 | simplicidad | 1 |
| 13594 | simplemente | 1 |
| 13595 | simpatías | 1 |
| 13596 | simonías | 1 |
| 13597 | símil | 1 |
| 13598 | simiente | 1 |
| 13599 | simétricas | 1 |
| 13600 | simetría | 1 |
| 13601 | simeón | 1 |
| 13602 | símbolos | 1 |
| 13603 | simbolismos | 1 |
| 13604 | simbólica | 1 |
| 13605 | simancas | 1 |
| 13606 | sima | 1 |
| 13607 | silva | 1 |
| 13608 | sillería | 1 |
| 13609 | sillares | 1 |
| 13610 | silenciosas | 1 |
| 13611 | silencios | 1 |
| 13612 | silbar | 1 |
| 13613 | silbante | 1 |
| 13614 | silbándoles | 1 |
| 13615 | silbado | 1 |
| 13616 | siguiesen | 1 |
| 13617 | siguiera | 1 |
| 13618 | sígueme | 1 |
| 13619 | signo | 1 |
| 13620 | significativo | 1 |
| 13621 | significativas | 1 |
| 13622 | significada | 1 |
| 13623 | sigiloso | 1 |
| 13624 | sigas | 1 |
| 13625 | sigan | 1 |
| 13626 | siga | 1 |
| 13627 | sietemesinos | 1 |
| 13628 | sierpes | 1 |
| 13629 | sientes | 1 |
| 13630 | sienten | 1 |
| 13631 | siéntate | 1 |
| 13632 | sientas | 1 |
| 13633 | sien | 1 |
| 13634 | siemprevivas | 1 |
| 13635 | sic | 1 |
| 13636 | sibila | 1 |
| 13637 | shakespeare | 1 |
| 13638 | sexta | 1 |
| 13639 | sevillano | 1 |
| 13640 | severos | 1 |
| 13641 | severísima | 1 |
| 13642 | severas | 1 |
| 13643 | sesiones | 1 |
| 13644 | sesgaba | 1 |
| 13645 | sesentona | 1 |
| 13646 | servilmente | 1 |
| 13647 | servilletero | 1 |
| 13648 | servilletas | 1 |
| 13649 | serviles | 1 |
| 13650 | servida | 1 |
| 13651 | servicial | 1 |
| 13652 | serviam | 1 |
| 13653 | servíale | 1 |
| 13654 | serrallo | 1 |
| 13655 | serpiente | 1 |
| 13656 | serpentones | 1 |
| 13657 | serpeando | 1 |
| 13658 | serpeaba | 1 |
| 13659 | serpea | 1 |
| 13660 | serones | 1 |
| 13661 | sernos | 1 |
| 13662 | serme | 1 |
| 13663 | serle | 1 |
| 13664 | serie | 1 |
| 13665 | serenísimo | 1 |
| 13666 | serenatas | 1 |
| 13667 | serenata | 1 |
| 13668 | serenarse | 1 |
| 13669 | seráfica | 1 |
| 13670 | sequedades | 1 |
| 13671 | sepultadas | 1 |
| 13672 | sépase | 1 |
| 13673 | sepas | 1 |
| 13674 | separose | 1 |
| 13675 | sepárese | 1 |
| 13676 | separarme | 1 |
| 13677 | separarlo | 1 |
| 13678 | separarlas | 1 |
| 13679 | separarla | 1 |
| 13680 | separadas | 1 |
| 13681 | separaban | 1 |
| 13682 | sepan | 1 |
| 13683 | señoriles | 1 |
| 13684 | señoa | 1 |
| 13685 | señalo | 1 |
| 13686 | señalados | 1 |
| 13687 | señaladas | 1 |
| 13688 | señalaban | 1 |
| 13689 | señala | 1 |
| 13690 | sentirlos | 1 |
| 13691 | sentirle | 1 |
| 13692 | sentirlas | 1 |
| 13693 | sentimos | 1 |
| 13694 | sentíalo | 1 |
| 13695 | sentarte | 1 |
| 13696 | sentarnos | 1 |
| 13697 | sentao | 1 |
| 13698 | sentándose | 1 |
| 13699 | sensualista | 1 |
| 13700 | sensualismo | 1 |
| 13701 | sensualidad | 1 |
| 13702 | sensiblería | 1 |
| 13703 | sensatos | 1 |
| 13704 | sensatas | 1 |
| 13705 | sensatamente | 1 |
| 13706 | senil | 1 |
| 13707 | sencillos | 1 |
| 13708 | sencillísimo | 1 |
| 13709 | sempiternas | 1 |
| 13710 | semillero | 1 |
| 13711 | semicírculo | 1 |
| 13712 | semicientífico | 1 |
| 13713 | sementales | 1 |
| 13714 | semejanzas | 1 |
| 13715 | sembrara | 1 |
| 13716 | sembrar | 1 |
| 13717 | sembrados | 1 |
| 13718 | sembraba | 1 |
| 13719 | selvática | 1 |
| 13720 | selva | 1 |
| 13721 | sellos | 1 |
| 13722 | sello | 1 |
| 13723 | selecto | 1 |
| 13724 | seguridades | 1 |
| 13725 | seguirlas | 1 |
| 13726 | seguiremos | 1 |
| 13727 | seguiré | 1 |
| 13728 | seguirán | 1 |
| 13729 | seguirá | 1 |
| 13730 | seguí | 1 |
| 13731 | segadora | 1 |
| 13732 | segaban | 1 |
| 13733 | sedúzcanmela | 1 |
| 13734 | sedujeron | 1 |
| 13735 | seductoras | 1 |
| 13736 | seducírselo | 1 |
| 13737 | seducida | 1 |
| 13738 | seduce | 1 |
| 13739 | seducciones | 1 |
| 13740 | sedoso | 1 |
| 13741 | sediento | 1 |
| 13742 | sedentarismo | 1 |
| 13743 | sedentario | 1 |
| 13744 | sedentaria | 1 |
| 13745 | secundum | 1 |
| 13746 | secundario | 1 |
| 13747 | secundarias | 1 |
| 13748 | secundaria | 1 |
| 13749 | secundar | 1 |
| 13750 | secundaba | 1 |
| 13751 | secularizándose | 1 |
| 13752 | secularización | 1 |
| 13753 | secuestrarlo | 1 |
| 13754 | secuestramos | 1 |
| 13755 | secuestrador | 1 |
| 13756 | secuentia | 1 |
| 13757 | secretillo | 1 |
| 13758 | secretario | 1 |
| 13759 | secretamente | 1 |
| 13760 | secciones | 1 |
| 13761 | secchi | 1 |
| 13762 | secarse | 1 |
| 13763 | secando | 1 |
| 13764 | secado | 1 |
| 13765 | secaban | 1 |
| 13766 | sebastopol | 1 |
| 13767 | sebastián | 1 |
| 13768 | sazonada | 1 |
| 13769 | sayones | 1 |
| 13770 | sauces | 1 |
| 13771 | sauce | 1 |
| 13772 | saturnillo | 1 |
| 13773 | saturación | 1 |
| 13774 | satisfizo | 1 |
| 13775 | satisfagan | 1 |
| 13776 | satisfacerles | 1 |
| 13777 | satisfacerle | 1 |
| 13778 | satíricos | 1 |
| 13779 | sátira | 1 |
| 13780 | satinado | 1 |
| 13781 | satén | 1 |
| 13782 | satánico | 1 |
| 13783 | satán | 1 |
| 13784 | sastrerías | 1 |
| 13785 | sarraceno | 1 |
| 13786 | sardou | 1 |
| 13787 | sardónica | 1 |
| 13788 | sarcástica | 1 |
| 13789 | saquen | 1 |
| 13790 | saqueaban | 1 |
| 13791 | santurrona | 1 |
| 13792 | santurrón | 1 |
| 13793 | santina | 1 |
| 13794 | santiguado | 1 |
| 13795 | santiguaba | 1 |
| 13796 | santificante | 1 |
| 13797 | sansón | 1 |
| 13798 | sansimoniano | 1 |
| 13799 | sanos | 1 |
| 13800 | sanó | 1 |
| 13801 | sanitario | 1 |
| 13802 | sanguis | 1 |
| 13803 | sanguinolenta | 1 |
| 13804 | sanguinario | 1 |
| 13805 | sanguijuelas | 1 |
| 13806 | sangrientamente | 1 |
| 13807 | sangrienta | 1 |
| 13808 | sangrar | 1 |
| 13809 | sangraban | 1 |
| 13810 | sandunga | 1 |
| 13811 | sandalias | 1 |
| 13812 | sanctos | 1 |
| 13813 | sanctorum | 1 |
| 13814 | sancti | 1 |
| 13815 | sancionaría | 1 |
| 13816 | sanción | 1 |
| 13817 | sancho | 1 |
| 13818 | sanase | 1 |
| 13819 | sanaría | 1 |
| 13820 | sanaba | 1 |
| 13821 | salvó | 1 |
| 13822 | sálvense | 1 |
| 13823 | salvaremos | 1 |
| 13824 | salvara | 1 |
| 13825 | salvadora | 1 |
| 13826 | salvada | 1 |
| 13827 | salvaba | 1 |
| 13828 | salus | 1 |
| 13829 | salúdele | 1 |
| 13830 | saludarse | 1 |
| 13831 | saludarme | 1 |
| 13832 | saludarle | 1 |
| 13833 | saludarlas | 1 |
| 13834 | saludaran | 1 |
| 13835 | saludándola | 1 |
| 13836 | saludado | 1 |
| 13837 | saludables | 1 |
| 13838 | saluda | 1 |
| 13839 | salté | 1 |
| 13840 | saltase | 1 |
| 13841 | saltarlo | 1 |
| 13842 | saltarines | 1 |
| 13843 | saltará | 1 |
| 13844 | saltan | 1 |
| 13845 | salpimentar | 1 |
| 13846 | salpicar | 1 |
| 13847 | salomónicas | 1 |
| 13848 | salomón | 1 |
| 13849 | salmones | 1 |
| 13850 | salmistas | 1 |
| 13851 | salirle | 1 |
| 13852 | salimos | 1 |
| 13853 | salientes | 1 |
| 13854 | salidas | 1 |
| 13855 | salid | 1 |
| 13856 | saldaba | 1 |
| 13857 | salchichón | 1 |
| 13858 | salado | 1 |
| 13859 | salada | 1 |
| 13860 | sahumados | 1 |
| 13861 | sagunto | 1 |
| 13862 | sagrarios | 1 |
| 13863 | sacudirse | 1 |
| 13864 | sacudirles | 1 |
| 13865 | sacudimientos | 1 |
| 13866 | sacudiéndola | 1 |
| 13867 | sacudido | 1 |
| 13868 | sacrosanto | 1 |
| 13869 | sacristán | 1 |
| 13870 | sacris | 1 |
| 13871 | sacrilegio | 1 |
| 13872 | sacrifico | 1 |
| 13873 | sacrificase | 1 |
| 13874 | sacrificaría | 1 |
| 13875 | sacrificándose | 1 |
| 13876 | sacrifican | 1 |
| 13877 | sacrificada | 1 |
| 13878 | sacrificaba | 1 |
| 13879 | sacramentales | 1 |
| 13880 | sacramental | 1 |
| 13881 | sacias | 1 |
| 13882 | sacerdotisa | 1 |
| 13883 | sacerdotal | 1 |
| 13884 | sacatrapos | 1 |
| 13885 | sacaste | 1 |
| 13886 | sacarte | 1 |
| 13887 | sacaron | 1 |
| 13888 | sacarlo | 1 |
| 13889 | sacaran | 1 |
| 13890 | sacará | 1 |
| 13891 | sacao | 1 |
| 13892 | sacada | 1 |
| 13893 | sabroso | 1 |
| 13894 | sabrosas | 1 |
| 13895 | sabrás | 1 |
| 13896 | sabores | 1 |
| 13897 | saboreó | 1 |
| 13898 | saboreando | 1 |
| 13899 | sablazos | 1 |
| 13900 | sabihondo | 1 |
| 13901 | saberle | 1 |
| 13902 | saberlas | 1 |
| 13903 | sábelo | 1 |
| 13904 | sabandija | 1 |
| 13905 | sabanas | 1 |
| 13906 | rutinas | 1 |
| 13907 | rutinarios | 1 |
| 13908 | rutinaria | 1 |
| 13909 | rústico | 1 |
| 13910 | rural | 1 |
| 13911 | rumorosa | 1 |
| 13912 | rumorcillo | 1 |
| 13913 | rumiase | 1 |
| 13914 | rumiara | 1 |
| 13915 | rumboso | 1 |
| 13916 | rumbosa | 1 |
| 13917 | ruleta | 1 |
| 13918 | ruinosos | 1 |
| 13919 | ruinosas | 1 |
| 13920 | ruinosa | 1 |
| 13921 | ruidosos | 1 |
| 13922 | ruidosas | 1 |
| 13923 | rugir | 1 |
| 13924 | rugidos | 1 |
| 13925 | rugía | 1 |
| 13926 | rufinita | 1 |
| 13927 | ruego | 1 |
| 13928 | ruedos | 1 |
| 13929 | ruedo | 1 |
| 13930 | rudo | 1 |
| 13931 | rudesinda | 1 |
| 13932 | rucutucua | 1 |
| 13933 | rúbrica | 1 |
| 13934 | ruborizándose | 1 |
| 13935 | ruborizadas | 1 |
| 13936 | rubores | 1 |
| 13937 | rubita | 1 |
| 13938 | rozase | 1 |
| 13939 | rozarse | 1 |
| 13940 | rozando | 1 |
| 13941 | rozagantes | 1 |
| 13942 | rozado | 1 |
| 13943 | rozaba | 1 |
| 13944 | royéndolo | 1 |
| 13945 | rotundo | 1 |
| 13946 | rótulo | 1 |
| 13947 | rotos | 1 |
| 13948 | rotin | 1 |
| 13949 | rosendo | 1 |
| 13950 | rorro | 1 |
| 13951 | roquetes | 1 |
| 13952 | roquero | 1 |
| 13953 | ropón | 1 |
| 13954 | ropas | 1 |
| 13955 | ronzalillo | 1 |
| 13956 | ronzalesco | 1 |
| 13957 | ronzalesca | 1 |
| 13958 | ronquidos | 1 |
| 13959 | rondaba | 1 |
| 13960 | roncas | 1 |
| 13961 | roncando | 1 |
| 13962 | ron | 1 |
| 13963 | rompiéndose | 1 |
| 13964 | rompiéndome | 1 |
| 13965 | romperse | 1 |
| 13966 | romperla | 1 |
| 13967 | rompen | 1 |
| 13968 | rompecabezas | 1 |
| 13969 | romerías | 1 |
| 13970 | romea | 1 |
| 13971 | romas | 1 |
| 13972 | romanus | 1 |
| 13973 | romantismo | 1 |
| 13974 | románica | 1 |
| 13975 | romancero | 1 |
| 13976 | romanas | 1 |
| 13977 | rollizos | 1 |
| 13978 | rollizo | 1 |
| 13979 | rojizo | 1 |
| 13980 | roían | 1 |
| 13981 | roía | 1 |
| 13982 | rogativas | 1 |
| 13983 | rogando | 1 |
| 13984 | rogaba | 1 |
| 13985 | rodríguez | 1 |
| 13986 | rodó | 1 |
| 13987 | rodeó | 1 |
| 13988 | rodearte | 1 |
| 13989 | rodear | 1 |
| 13990 | rodaron | 1 |
| 13991 | rococó | 1 |
| 13992 | roció | 1 |
| 13993 | rociaba | 1 |
| 13994 | robustas | 1 |
| 13995 | robledo | 1 |
| 13996 | robledales | 1 |
| 13997 | robas | 1 |
| 13998 | robarle | 1 |
| 13999 | robándole | 1 |
| 14000 | robando | 1 |
| 14001 | rivalizar | 1 |
| 14002 | rivales | 1 |
| 14003 | ritos | 1 |
| 14004 | rítmicos | 1 |
| 14005 | ristre | 1 |
| 14006 | rire | 1 |
| 14007 | rio | 1 |
| 14008 | riñó | 1 |
| 14009 | riño | 1 |
| 14010 | riñeran | 1 |
| 14011 | ríñeme | 1 |
| 14012 | riñas | 1 |
| 14013 | riña | 1 |
| 14014 | rinconadas | 1 |
| 14015 | rima | 1 |
| 14016 | riguroso | 1 |
| 14017 | rigolade | 1 |
| 14018 | rigodones | 1 |
| 14019 | rigidez | 1 |
| 14020 | rígida | 1 |
| 14021 | rifas | 1 |
| 14022 | ríes | 1 |
| 14023 | riendas | 1 |
| 14024 | riegan | 1 |
| 14025 | ridente | 1 |
| 14026 | ricacho | 1 |
| 14027 | ribera | 1 |
| 14028 | ríanse | 1 |
| 14029 | rían | 1 |
| 14030 | rezumaba | 1 |
| 14031 | rezos | 1 |
| 14032 | rezarle | 1 |
| 14033 | rezaría | 1 |
| 14034 | rezagados | 1 |
| 14035 | rezagadas | 1 |
| 14036 | rewólver | 1 |
| 14037 | revuelven | 1 |
| 14038 | revue | 1 |
| 14039 | revolvió | 1 |
| 14040 | revolverse | 1 |
| 14041 | revoluciones | 1 |
| 14042 | revolucionarios | 1 |
| 14043 | revoltoso | 1 |
| 14044 | revoltosas | 1 |
| 14045 | revoltosa | 1 |
| 14046 | revolando | 1 |
| 14047 | revestido | 1 |
| 14048 | revestían | 1 |
| 14049 | reverso | 1 |
| 14050 | reverencias | 1 |
| 14051 | reverbero | 1 |
| 14052 | reverberada | 1 |
| 14053 | reventó | 1 |
| 14054 | reventaba | 1 |
| 14055 | revele | 1 |
| 14056 | revelase | 1 |
| 14057 | revelaron | 1 |
| 14058 | revelarle | 1 |
| 14059 | revelando | 1 |
| 14060 | reveladas | 1 |
| 14061 | reunidos | 1 |
| 14062 | reunidas | 1 |
| 14063 | reúna | 1 |
| 14064 | retumbante | 1 |
| 14065 | retumba | 1 |
| 14066 | retuerce | 1 |
| 14067 | retrospectivo | 1 |
| 14068 | retrospectiva | 1 |
| 14069 | retroceso | 1 |
| 14070 | retrocediendo | 1 |
| 14071 | retrato | 1 |
| 14072 | retrataba | 1 |
| 14073 | retrasó | 1 |
| 14074 | retrasen | 1 |
| 14075 | retrasaba | 1 |
| 14076 | retrae | 1 |
| 14077 | retractase | 1 |
| 14078 | retractarse | 1 |
| 14079 | retractación | 1 |
| 14080 | retozaba | 1 |
| 14081 | retour | 1 |
| 14082 | retorta | 1 |
| 14083 | retórico | 1 |
| 14084 | retorció | 1 |
| 14085 | retorcida | 1 |
| 14086 | retorcerse | 1 |
| 14087 | retocados | 1 |
| 14088 | retiré | 1 |
| 14089 | retirasen | 1 |
| 14090 | retirarlo | 1 |
| 14091 | retiran | 1 |
| 14092 | retira | 1 |
| 14093 | retintín | 1 |
| 14094 | retina | 1 |
| 14095 | retebién | 1 |
| 14096 | retarde | 1 |
| 14097 | retardaba | 1 |
| 14098 | retado | 1 |
| 14099 | retaba | 1 |
| 14100 | resurrección | 1 |
| 14101 | resumía | 1 |
| 14102 | resultas | 1 |
| 14103 | resultan | 1 |
| 14104 | resuelven | 1 |
| 14105 | resueltos | 1 |
| 14106 | resuello | 1 |
| 14107 | resucitaba | 1 |
| 14108 | resucita | 1 |
| 14109 | restriñimientos | 1 |
| 14110 | restringido | 1 |
| 14111 | restreñimientos | 1 |
| 14112 | restituya | 1 |
| 14113 | restituirse | 1 |
| 14114 | restituirlo | 1 |
| 14115 | restituir | 1 |
| 14116 | restituida | 1 |
| 14117 | restituía | 1 |
| 14118 | restaurar | 1 |
| 14119 | restaurando | 1 |
| 14120 | restaurado | 1 |
| 14121 | restañar | 1 |
| 14122 | restablecido | 1 |
| 14123 | respuestas | 1 |
| 14124 | responsos | 1 |
| 14125 | respondieron | 1 |
| 14126 | responda | 1 |
| 14127 | resplandeciente | 1 |
| 14128 | respiraron | 1 |
| 14129 | respiraban | 1 |
| 14130 | respira | 1 |
| 14131 | respetuosos | 1 |
| 14132 | respetuosa | 1 |
| 14133 | respeten | 1 |
| 14134 | respetaron | 1 |
| 14135 | respetaran | 1 |
| 14136 | respetadas | 1 |
| 14137 | respetabilísimos | 1 |
| 14138 | respectivamente | 1 |
| 14139 | respecta | 1 |
| 14140 | respaldos | 1 |
| 14141 | resonaron | 1 |
| 14142 | resonante | 1 |
| 14143 | resonaban | 1 |
| 14144 | resonaba | 1 |
| 14145 | resolvía | 1 |
| 14146 | resolvérsele | 1 |
| 14147 | resolverse | 1 |
| 14148 | resolvería | 1 |
| 14149 | resolvamos | 1 |
| 14150 | resoluciones | 1 |
| 14151 | resistiría | 1 |
| 14152 | resistido | 1 |
| 14153 | resistían | 1 |
| 14154 | resignó | 1 |
| 14155 | resignaron | 1 |
| 14156 | resignarnos | 1 |
| 14157 | resignan | 1 |
| 14158 | residir | 1 |
| 14159 | residencia | 1 |
| 14160 | reservarle | 1 |
| 14161 | reservarían | 1 |
| 14162 | reservados | 1 |
| 14163 | reservaban | 1 |
| 14164 | reseñada | 1 |
| 14165 | resentido | 1 |
| 14166 | rescatar | 1 |
| 14167 | resbaló | 1 |
| 14168 | resbalas | 1 |
| 14169 | resbalan | 1 |
| 14170 | resbalaban | 1 |
| 14171 | resbalaba | 1 |
| 14172 | res | 1 |
| 14173 | requirió | 1 |
| 14174 | requerido | 1 |
| 14175 | requerida | 1 |
| 14176 | requebrarla | 1 |
| 14177 | reputaciones | 1 |
| 14178 | reputación | 1 |
| 14179 | reputábala | 1 |
| 14180 | repugnándole | 1 |
| 14181 | repugnancias | 1 |
| 14182 | repugnan | 1 |
| 14183 | repugna | 1 |
| 14184 | repuesto | 1 |
| 14185 | republicanitos | 1 |
| 14186 | republicana | 1 |
| 14187 | reproducen | 1 |
| 14188 | reprimió | 1 |
| 14189 | represiva | 1 |
| 14190 | representativo | 1 |
| 14191 | representársela | 1 |
| 14192 | representarse | 1 |
| 14193 | representante | 1 |
| 14194 | representado | 1 |
| 14195 | representadas | 1 |
| 14196 | reprendo | 1 |
| 14197 | reprendiese | 1 |
| 14198 | reprendido | 1 |
| 14199 | reprendía | 1 |
| 14200 | reprenden | 1 |
| 14201 | reposado | 1 |
| 14202 | reposaba | 1 |
| 14203 | reportase | 1 |
| 14204 | reportarse | 1 |
| 14205 | repone | 1 |
| 14206 | repliegues | 1 |
| 14207 | replicar | 1 |
| 14208 | replicado | 1 |
| 14209 | replicaba | 1 |
| 14210 | repletos | 1 |
| 14211 | repleta | 1 |
| 14212 | repitiendo | 1 |
| 14213 | repiqueteo | 1 |
| 14214 | repiquen | 1 |
| 14215 | repique | 1 |
| 14216 | repetirlo | 1 |
| 14217 | repetiría | 1 |
| 14218 | repertorio | 1 |
| 14219 | repercutiendo | 1 |
| 14220 | repentista | 1 |
| 14221 | repecho | 1 |
| 14222 | repartirse | 1 |
| 14223 | repartiros | 1 |
| 14224 | repartidos | 1 |
| 14225 | repartido | 1 |
| 14226 | repartidas | 1 |
| 14227 | repartida | 1 |
| 14228 | repartían | 1 |
| 14229 | reparten | 1 |
| 14230 | repartan | 1 |
| 14231 | reparos | 1 |
| 14232 | repararon | 1 |
| 14233 | reparar | 1 |
| 14234 | reparando | 1 |
| 14235 | reparaciones | 1 |
| 14236 | reo | 1 |
| 14237 | reñirle | 1 |
| 14238 | reñir | 1 |
| 14239 | reñía | 1 |
| 14240 | renuncio | 1 |
| 14241 | renunciarla | 1 |
| 14242 | renunciando | 1 |
| 14243 | renunciado | 1 |
| 14244 | renuncia | 1 |
| 14245 | renueva | 1 |
| 14246 | rentístico | 1 |
| 14247 | renovar | 1 |
| 14248 | renovada | 1 |
| 14249 | renovación | 1 |
| 14250 | renovaban | 1 |
| 14251 | reniega | 1 |
| 14252 | renglón | 1 |
| 14253 | rendondilla | 1 |
| 14254 | rendirse | 1 |
| 14255 | rendirle | 1 |
| 14256 | rendimiento | 1 |
| 14257 | rendidas | 1 |
| 14258 | rendían | 1 |
| 14259 | rencoroso | 1 |
| 14260 | rencorosas | 1 |
| 14261 | rencorosa | 1 |
| 14262 | renacimiento | 1 |
| 14263 | renaciera | 1 |
| 14264 | renacían | 1 |
| 14265 | removiendo | 1 |
| 14266 | removida | 1 |
| 14267 | removían | 1 |
| 14268 | removía | 1 |
| 14269 | remover | 1 |
| 14270 | remoto | 1 |
| 14271 | remordiera | 1 |
| 14272 | remontar | 1 |
| 14273 | remonísima | 1 |
| 14274 | remolque | 1 |
| 14275 | remolones | 1 |
| 14276 | remolacha | 1 |
| 14277 | remito | 1 |
| 14278 | remitido | 1 |
| 14279 | remiso | 1 |
| 14280 | remendón | 1 |
| 14281 | remendando | 1 |
| 14282 | remendados | 1 |
| 14283 | remendado | 1 |
| 14284 | remedia | 1 |
| 14285 | remedaban | 1 |
| 14286 | remate | 1 |
| 14287 | rematados | 1 |
| 14288 | remanso | 1 |
| 14289 | relucían | 1 |
| 14290 | relojes | 1 |
| 14291 | relojero | 1 |
| 14292 | rellenas | 1 |
| 14293 | reliquia | 1 |
| 14294 | relevaban | 1 |
| 14295 | relator | 1 |
| 14296 | relativos | 1 |
| 14297 | relamida | 1 |
| 14298 | relajar | 1 |
| 14299 | relajamiento | 1 |
| 14300 | relajado | 1 |
| 14301 | relajación | 1 |
| 14302 | relacionaba | 1 |
| 14303 | rejuveneciendo | 1 |
| 14304 | reivindicar | 1 |
| 14305 | reivindicación | 1 |
| 14306 | reiteradas | 1 |
| 14307 | reírse | 1 |
| 14308 | reintegrado | 1 |
| 14309 | reinase | 1 |
| 14310 | reinas | 1 |
| 14311 | reinar | 1 |
| 14312 | reíanse | 1 |
| 14313 | rehusar | 1 |
| 14314 | rehuir | 1 |
| 14315 | rehuía | 1 |
| 14316 | rehabilitarse | 1 |
| 14317 | regumque | 1 |
| 14318 | regularmente | 1 |
| 14319 | regulam | 1 |
| 14320 | regresó | 1 |
| 14321 | regocijó | 1 |
| 14322 | reglamento | 1 |
| 14323 | reglamentarios | 1 |
| 14324 | registrar | 1 |
| 14325 | registrándole | 1 |
| 14326 | registrando | 1 |
| 14327 | regio | 1 |
| 14328 | regeneración | 1 |
| 14329 | rege | 1 |
| 14330 | regazados | 1 |
| 14331 | regateo | 1 |
| 14332 | regatear | 1 |
| 14333 | regatean | 1 |
| 14334 | regar | 1 |
| 14335 | regalen | 1 |
| 14336 | regalarle | 1 |
| 14337 | regalan | 1 |
| 14338 | regalados | 1 |
| 14339 | regaladas | 1 |
| 14340 | regada | 1 |
| 14341 | refutaría | 1 |
| 14342 | refugió | 1 |
| 14343 | refugiarse | 1 |
| 14344 | refugiadas | 1 |
| 14345 | refugiábanse | 1 |
| 14346 | refugiaba | 1 |
| 14347 | refuerzos | 1 |
| 14348 | refrigerado | 1 |
| 14349 | refriega | 1 |
| 14350 | refrescar | 1 |
| 14351 | refrenada | 1 |
| 14352 | refrán | 1 |
| 14353 | refractaban | 1 |
| 14354 | reforzada | 1 |
| 14355 | reformistas | 1 |
| 14356 | reformista | 1 |
| 14357 | reflexivo | 1 |
| 14358 | reflexionando | 1 |
| 14359 | reflejados | 1 |
| 14360 | reflejado | 1 |
| 14361 | reflejadas | 1 |
| 14362 | refiriéndose | 1 |
| 14363 | refinamiento | 1 |
| 14364 | refinados | 1 |
| 14365 | refieren | 1 |
| 14366 | refiere | 1 |
| 14367 | referírselas | 1 |
| 14368 | referiré | 1 |
| 14369 | referente | 1 |
| 14370 | reencarnación | 1 |
| 14371 | reemplazarlas | 1 |
| 14372 | reedificaba | 1 |
| 14373 | reduplicado | 1 |
| 14374 | redundantes | 1 |
| 14375 | redundancia | 1 |
| 14376 | redujo | 1 |
| 14377 | reducto | 1 |
| 14378 | reducirle | 1 |
| 14379 | reducida | 1 |
| 14380 | redondos | 1 |
| 14381 | redondillas | 1 |
| 14382 | redondeaban | 1 |
| 14383 | redoma | 1 |
| 14384 | redobló | 1 |
| 14385 | redoble | 1 |
| 14386 | redoblar | 1 |
| 14387 | redivivo | 1 |
| 14388 | rediviva | 1 |
| 14389 | réditos | 1 |
| 14390 | redimirse | 1 |
| 14391 | redimirle | 1 |
| 14392 | redimir | 1 |
| 14393 | redimido | 1 |
| 14394 | redimidas | 1 |
| 14395 | redimía | 1 |
| 14396 | redentor | 1 |
| 14397 | redención | 1 |
| 14398 | redactor | 1 |
| 14399 | redactaré | 1 |
| 14400 | recurrió | 1 |
| 14401 | reculó | 1 |
| 14402 | recuerden | 1 |
| 14403 | recuento | 1 |
| 14404 | rectos | 1 |
| 14405 | rectificando | 1 |
| 14406 | rectas | 1 |
| 14407 | rectángulos | 1 |
| 14408 | rectángulo | 1 |
| 14409 | rectangular | 1 |
| 14410 | rectae | 1 |
| 14411 | recta | 1 |
| 14412 | recreos | 1 |
| 14413 | recrearme | 1 |
| 14414 | recreándose | 1 |
| 14415 | recreándonos | 1 |
| 14416 | recreaban | 1 |
| 14417 | recostole | 1 |
| 14418 | recostó | 1 |
| 14419 | recostaba | 1 |
| 14420 | recortes | 1 |
| 14421 | recortado | 1 |
| 14422 | recortadas | 1 |
| 14423 | recortaba | 1 |
| 14424 | recorriese | 1 |
| 14425 | recorrían | 1 |
| 14426 | recorre | 1 |
| 14427 | recordasen | 1 |
| 14428 | recordarlo | 1 |
| 14429 | recordarla | 1 |
| 14430 | recordará | 1 |
| 14431 | recordara | 1 |
| 14432 | recordadas | 1 |
| 14433 | recopilación | 1 |
| 14434 | reconvención | 1 |
| 14435 | recontaba | 1 |
| 14436 | reconquista | 1 |
| 14437 | reconocieron | 1 |
| 14438 | reconociera | 1 |
| 14439 | reconociendo | 1 |
| 14440 | reconocidos | 1 |
| 14441 | reconocida | 1 |
| 14442 | reconocí | 1 |
| 14443 | reconocerle | 1 |
| 14444 | reconocerla | 1 |
| 14445 | reconocería | 1 |
| 14446 | recóndito | 1 |
| 14447 | recóndita | 1 |
| 14448 | reconcilió | 1 |
| 14449 | reconciliarme | 1 |
| 14450 | reconciliaría | 1 |
| 14451 | reconciliarás | 1 |
| 14452 | reconciliaciones | 1 |
| 14453 | reconcentradas | 1 |
| 14454 | reconcentrada | 1 |
| 14455 | recompensar | 1 |
| 14456 | recomendó | 1 |
| 14457 | recomendarle | 1 |
| 14458 | recomendados | 1 |
| 14459 | recomendación | 1 |
| 14460 | recoletos | 1 |
| 14461 | recojo | 1 |
| 14462 | recoja | 1 |
| 14463 | recogidos | 1 |
| 14464 | recogerlo | 1 |
| 14465 | recogen | 1 |
| 14466 | recogemos | 1 |
| 14467 | recobraste | 1 |
| 14468 | recobrará | 1 |
| 14469 | recobrando | 1 |
| 14470 | reclinada | 1 |
| 14471 | reclamando | 1 |
| 14472 | reclama | 1 |
| 14473 | recitados | 1 |
| 14474 | recíproca | 1 |
| 14475 | recintos | 1 |
| 14476 | recientes | 1 |
| 14477 | recibirá | 1 |
| 14478 | recibimos | 1 |
| 14479 | recibimiento | 1 |
| 14480 | recibiera | 1 |
| 14481 | recibiéndolas | 1 |
| 14482 | recibidas | 1 |
| 14483 | recibida | 1 |
| 14484 | recibí | 1 |
| 14485 | recias | 1 |
| 14486 | rechinasen | 1 |
| 14487 | rechinaran | 1 |
| 14488 | rechinaban | 1 |
| 14489 | rechinaba | 1 |
| 14490 | rechazar | 1 |
| 14491 | rechazando | 1 |
| 14492 | rechazadas | 1 |
| 14493 | recetas | 1 |
| 14494 | recetaba | 1 |
| 14495 | receta | 1 |
| 14496 | recentales | 1 |
| 14497 | recelosas | 1 |
| 14498 | recelosa | 1 |
| 14499 | recelos | 1 |
| 14500 | rece | 1 |
| 14501 | recayó | 1 |
| 14502 | recaudado | 1 |
| 14503 | recatarse | 1 |
| 14504 | recatados | 1 |
| 14505 | recatadamente | 1 |
| 14506 | recatada | 1 |
| 14507 | recalcitrantes | 1 |
| 14508 | recaía | 1 |
| 14509 | recados | 1 |
| 14510 | rebuscar | 1 |
| 14511 | rebuscaban | 1 |
| 14512 | rebullir | 1 |
| 14513 | rebrinquen | 1 |
| 14514 | rebozo | 1 |
| 14515 | rebozado | 1 |
| 14516 | rebozada | 1 |
| 14517 | rebotaron | 1 |
| 14518 | rebosando | 1 |
| 14519 | rebosaba | 1 |
| 14520 | rebosa | 1 |
| 14521 | reblandecer | 1 |
| 14522 | rebeliones | 1 |
| 14523 | rebeldes | 1 |
| 14524 | rebela | 1 |
| 14525 | rebeca | 1 |
| 14526 | rebasaría | 1 |
| 14527 | rebasara | 1 |
| 14528 | rebajó | 1 |
| 14529 | rebajarse | 1 |
| 14530 | rebajar | 1 |
| 14531 | rebajando | 1 |
| 14532 | rebaja | 1 |
| 14533 | reapareció | 1 |
| 14534 | reaparecía | 1 |
| 14535 | reanudó | 1 |
| 14536 | reanudados | 1 |
| 14537 | reanuda | 1 |
| 14538 | reanimó | 1 |
| 14539 | realizando | 1 |
| 14540 | realizados | 1 |
| 14541 | realizaban | 1 |
| 14542 | reacias | 1 |
| 14543 | reaccionarios | 1 |
| 14544 | re | 1 |
| 14545 | razonable | 1 |
| 14546 | razonaba | 1 |
| 14547 | rayó | 1 |
| 14548 | rayar | 1 |
| 14549 | raudales | 1 |
| 14550 | raudal | 1 |
| 14551 | ratoncillo | 1 |
| 14552 | ratificó | 1 |
| 14553 | rastrero | 1 |
| 14554 | rastrera | 1 |
| 14555 | raspaba | 1 |
| 14556 | rasgarse | 1 |
| 14557 | rasgara | 1 |
| 14558 | rasgando | 1 |
| 14559 | rasgadas | 1 |
| 14560 | rascándose | 1 |
| 14561 | rarísimas | 1 |
| 14562 | raquítica | 1 |
| 14563 | rapto | 1 |
| 14564 | rapsodias | 1 |
| 14565 | rápidos | 1 |
| 14566 | rapidísima | 1 |
| 14567 | rapado | 1 |
| 14568 | rapa | 1 |
| 14569 | rancios | 1 |
| 14570 | rana | 1 |
| 14571 | ramilletes | 1 |
| 14572 | ramillete | 1 |
| 14573 | ramificaciones | 1 |
| 14574 | ramerilla | 1 |
| 14575 | ramayana | 1 |
| 14576 | ralea | 1 |
| 14577 | raja | 1 |
| 14578 | raídas | 1 |
| 14579 | racionalmente | 1 |
| 14580 | racionalismo | 1 |
| 14581 | ración | 1 |
| 14582 | raciocinios | 1 |
| 14583 | racimos | 1 |
| 14584 | racha | 1 |
| 14585 | rabiosos | 1 |
| 14586 | rabien | 1 |
| 14587 | rabiar | 1 |
| 14588 | rabian | 1 |
| 14589 | rábano | 1 |
| 14590 | r | 1 |
| 14591 | quum | 1 |
| 14592 | quod | 1 |
| 14593 | quizá | 1 |
| 14594 | quito | 1 |
| 14595 | quítese | 1 |
| 14596 | quite | 1 |
| 14597 | quitaron | 1 |
| 14598 | quitarme | 1 |
| 14599 | quitando | 1 |
| 14600 | quítame | 1 |
| 14601 | quitado | 1 |
| 14602 | quisquilloso | 1 |
| 14603 | quisque | 1 |
| 14604 | quisiste | 1 |
| 14605 | quisieras | 1 |
| 14606 | quisicosa | 1 |
| 14607 | quis | 1 |
| 14608 | quinto | 1 |
| 14609 | quinti | 1 |
| 14610 | quintales | 1 |
| 14611 | quinientas | 1 |
| 14612 | químicos | 1 |
| 14613 | químico | 1 |
| 14614 | quijotescos | 1 |
| 14615 | quijotada | 1 |
| 14616 | quijada | 1 |
| 14617 | quietud | 1 |
| 14618 | quietismo | 1 |
| 14619 | quiés | 1 |
| 14620 | quid | 1 |
| 14621 | quia | 1 |
| 14622 | qui | 1 |
| 14623 | question | 1 |
| 14624 | querrías | 1 |
| 14625 | querríamos | 1 |
| 14626 | querrás | 1 |
| 14627 | querrán | 1 |
| 14628 | queridísima | 1 |
| 14629 | queríala | 1 |
| 14630 | quererme | 1 |
| 14631 | quererlos | 1 |
| 14632 | quererlo | 1 |
| 14633 | querella | 1 |
| 14634 | queréis | 1 |
| 14635 | quepa | 1 |
| 14636 | quemó | 1 |
| 14637 | quemarlo | 1 |
| 14638 | quemando | 1 |
| 14639 | quemadura | 1 |
| 14640 | quemado | 1 |
| 14641 | quejumbrosos | 1 |
| 14642 | quejumbroso | 1 |
| 14643 | quejumbrosa | 1 |
| 14644 | quejo | 1 |
| 14645 | queje | 1 |
| 14646 | quejaron | 1 |
| 14647 | quejándose | 1 |
| 14648 | quejabas | 1 |
| 14649 | quejaban | 1 |
| 14650 | quedase | 1 |
| 14651 | quedarte | 1 |
| 14652 | quedarían | 1 |
| 14653 | quedaremos | 1 |
| 14654 | quedaré | 1 |
| 14655 | quedaran | 1 |
| 14656 | quedaos | 1 |
| 14657 | quedábamos | 1 |
| 14658 | quebrantarse | 1 |
| 14659 | quebrándose | 1 |
| 14660 | quebrada | 1 |
| 14661 | quebraba | 1 |
| 14662 | quanti | 1 |
| 14663 | quando | 1 |
| 14664 | quam | 1 |
| 14665 | pústulas | 1 |
| 14666 | pusiste | 1 |
| 14667 | pusilánime | 1 |
| 14668 | pusiese | 1 |
| 14669 | puse | 1 |
| 14670 | purulentas | 1 |
| 14671 | purpurinos | 1 |
| 14672 | purísimas | 1 |
| 14673 | purísima | 1 |
| 14674 | purificada | 1 |
| 14675 | puridad | 1 |
| 14676 | purezas | 1 |
| 14677 | pupilo | 1 |
| 14678 | pupila | 1 |
| 14679 | puñalada | 1 |
| 14680 | puñados | 1 |
| 14681 | puñado | 1 |
| 14682 | puñada | 1 |
| 14683 | puntuación | 1 |
| 14684 | puntillo | 1 |
| 14685 | puntiagudas | 1 |
| 14686 | puntiaguda | 1 |
| 14687 | puntapié | 1 |
| 14688 | puntales | 1 |
| 14689 | puntal | 1 |
| 14690 | puntadas | 1 |
| 14691 | pundonor | 1 |
| 14692 | pumaradas | 1 |
| 14693 | pumarada | 1 |
| 14694 | pum | 1 |
| 14695 | pulvis | 1 |
| 14696 | pulverizarse | 1 |
| 14697 | pulverizar | 1 |
| 14698 | pululan | 1 |
| 14699 | pululáis | 1 |
| 14700 | pulsa | 1 |
| 14701 | pulidas | 1 |
| 14702 | pulgas | 1 |
| 14703 | pulgada | 1 |
| 14704 | pujanza | 1 |
| 14705 | pugnaban | 1 |
| 14706 | pugnaba | 1 |
| 14707 | pugna | 1 |
| 14708 | pugilato | 1 |
| 14709 | puéstole | 1 |
| 14710 | pués | 1 |
| 14711 | puerros | 1 |
| 14712 | puerro | 1 |
| 14713 | puerperio | 1 |
| 14714 | puerperales | 1 |
| 14715 | puerilidades | 1 |
| 14716 | puerilidad | 1 |
| 14717 | pueriles | 1 |
| 14718 | puercos | 1 |
| 14719 | pué | 1 |
| 14720 | pudrirse | 1 |
| 14721 | pudriría | 1 |
| 14722 | pudrirá | 1 |
| 14723 | pudrían | 1 |
| 14724 | pudren | 1 |
| 14725 | pudre | 1 |
| 14726 | pudra | 1 |
| 14727 | pudorosa | 1 |
| 14728 | pudieras | 1 |
| 14729 | pudiéramos | 1 |
| 14730 | pudientes | 1 |
| 14731 | pudibundo | 1 |
| 14732 | publicidad | 1 |
| 14733 | publicarlas | 1 |
| 14734 | publicaría | 1 |
| 14735 | publicar | 1 |
| 14736 | públicamente | 1 |
| 14737 | publicación | 1 |
| 14738 | publicaban | 1 |
| 14739 | psíquico | 1 |
| 14740 | psicológico | 1 |
| 14741 | psicológicas | 1 |
| 14742 | psicológicamente | 1 |
| 14743 | psicologías | 1 |
| 14744 | pseudoclásico | 1 |
| 14745 | pruebo | 1 |
| 14746 | pruebe | 1 |
| 14747 | prudentemente | 1 |
| 14748 | proyectiles | 1 |
| 14749 | proyectado | 1 |
| 14750 | proyectada | 1 |
| 14751 | proyectaba | 1 |
| 14752 | próximas | 1 |
| 14753 | provocó | 1 |
| 14754 | provocativo | 1 |
| 14755 | provocarlas | 1 |
| 14756 | provocan | 1 |
| 14757 | provocados | 1 |
| 14758 | provocador | 1 |
| 14759 | provocado | 1 |
| 14760 | provoca | 1 |
| 14761 | provisto | 1 |
| 14762 | provisores | 1 |
| 14763 | provisionalmente | 1 |
| 14764 | provincianos | 1 |
| 14765 | provinciana | 1 |
| 14766 | proviene | 1 |
| 14767 | proverbial | 1 |
| 14768 | proveer | 1 |
| 14769 | provechosos | 1 |
| 14770 | provechosas | 1 |
| 14771 | provechosa | 1 |
| 14772 | protoplasma | 1 |
| 14773 | protestase | 1 |
| 14774 | protestaron | 1 |
| 14775 | protestara | 1 |
| 14776 | protestante | 1 |
| 14777 | protestan | 1 |
| 14778 | protejo | 1 |
| 14779 | proteja | 1 |
| 14780 | protegió | 1 |
| 14781 | protegiendo | 1 |
| 14782 | prostituta | 1 |
| 14783 | prosternaban | 1 |
| 14784 | próspero | 1 |
| 14785 | prosperidad | 1 |
| 14786 | prosperaría | 1 |
| 14787 | prosperaba | 1 |
| 14788 | prosopopeya | 1 |
| 14789 | prosigue | 1 |
| 14790 | prosigas | 1 |
| 14791 | prosélito | 1 |
| 14792 | proseguir | 1 |
| 14793 | prorrumpir | 1 |
| 14794 | prorrumpiéramos | 1 |
| 14795 | propuesta | 1 |
| 14796 | propter | 1 |
| 14797 | proposiciones | 1 |
| 14798 | proporcionado | 1 |
| 14799 | proponían | 1 |
| 14800 | propongo | 1 |
| 14801 | proponga | 1 |
| 14802 | proponemos | 1 |
| 14803 | propietarios | 1 |
| 14804 | prophani | 1 |
| 14805 | propedéutica | 1 |
| 14806 | propasó | 1 |
| 14807 | propasase | 1 |
| 14808 | propasado | 1 |
| 14809 | propasa | 1 |
| 14810 | propalar | 1 |
| 14811 | propalando | 1 |
| 14812 | propalaba | 1 |
| 14813 | propala | 1 |
| 14814 | propagar | 1 |
| 14815 | propagandistas | 1 |
| 14816 | propagandista | 1 |
| 14817 | propagaban | 1 |
| 14818 | pronunció | 1 |
| 14819 | pronunciaron | 1 |
| 14820 | pronuncia | 1 |
| 14821 | pronósticos | 1 |
| 14822 | pronosticado | 1 |
| 14823 | promulgó | 1 |
| 14824 | prominencias | 1 |
| 14825 | prometo | 1 |
| 14826 | prometida | 1 |
| 14827 | prometían | 1 |
| 14828 | prometerse | 1 |
| 14829 | prometerla | 1 |
| 14830 | prometería | 1 |
| 14831 | promete | 1 |
| 14832 | prolongándose | 1 |
| 14833 | prolongadas | 1 |
| 14834 | prolongaban | 1 |
| 14835 | prolonga | 1 |
| 14836 | prolija | 1 |
| 14837 | proletarios | 1 |
| 14838 | proletarias | 1 |
| 14839 | prole | 1 |
| 14840 | prohibiría | 1 |
| 14841 | prohibió | 1 |
| 14842 | prohibiera | 1 |
| 14843 | prohibían | 1 |
| 14844 | prohíban | 1 |
| 14845 | progresa | 1 |
| 14846 | profundísima | 1 |
| 14847 | profiriese | 1 |
| 14848 | profesores | 1 |
| 14849 | profesor | 1 |
| 14850 | profeso | 1 |
| 14851 | profesaron | 1 |
| 14852 | profesar | 1 |
| 14853 | profesadas | 1 |
| 14854 | profesaban | 1 |
| 14855 | profanó | 1 |
| 14856 | profanarlo | 1 |
| 14857 | profanaran | 1 |
| 14858 | profanaban | 1 |
| 14859 | proezas | 1 |
| 14860 | produciendo | 1 |
| 14861 | producidas | 1 |
| 14862 | producida | 1 |
| 14863 | prodromos | 1 |
| 14864 | prodigioso | 1 |
| 14865 | prodigiosamente | 1 |
| 14866 | prodigiosa | 1 |
| 14867 | prodigara | 1 |
| 14868 | prodigando | 1 |
| 14869 | prodigalidad | 1 |
| 14870 | pródiga | 1 |
| 14871 | procurose | 1 |
| 14872 | procuro | 1 |
| 14873 | procurarse | 1 |
| 14874 | procurarla | 1 |
| 14875 | procurará | 1 |
| 14876 | procurándolo | 1 |
| 14877 | procuradores | 1 |
| 14878 | procura | 1 |
| 14879 | proclamarse | 1 |
| 14880 | proclamamos | 1 |
| 14881 | proclama | 1 |
| 14882 | procedimientos | 1 |
| 14883 | procedimiento | 1 |
| 14884 | procedentes | 1 |
| 14885 | procedente | 1 |
| 14886 | procedencia | 1 |
| 14887 | procede | 1 |
| 14888 | proboscidio | 1 |
| 14889 | problemas | 1 |
| 14890 | probidad | 1 |
| 14891 | probecicos | 1 |
| 14892 | probasen | 1 |
| 14893 | probarme | 1 |
| 14894 | probarlo | 1 |
| 14895 | proba | 1 |
| 14896 | pro | 1 |
| 14897 | privilegiado | 1 |
| 14898 | privilegiadas | 1 |
| 14899 | privilegiada | 1 |
| 14900 | privarse | 1 |
| 14901 | privarle | 1 |
| 14902 | privación | 1 |
| 14903 | priva | 1 |
| 14904 | prístina | 1 |
| 14905 | prismáticos | 1 |
| 14906 | prisionero | 1 |
| 14907 | principium | 1 |
| 14908 | principiar | 1 |
| 14909 | principado | 1 |
| 14910 | princesas | 1 |
| 14911 | primos | 1 |
| 14912 | primorosa | 1 |
| 14913 | primordiales | 1 |
| 14914 | primitivas | 1 |
| 14915 | primita | 1 |
| 14916 | primicias | 1 |
| 14917 | primerizos | 1 |
| 14918 | primerizo | 1 |
| 14919 | primeriza | 1 |
| 14920 | primeramente | 1 |
| 14921 | previo | 1 |
| 14922 | previamente | 1 |
| 14923 | preveo | 1 |
| 14924 | prevenirnos | 1 |
| 14925 | prevenirle | 1 |
| 14926 | prevenida | 1 |
| 14927 | prevenía | 1 |
| 14928 | prevención | 1 |
| 14929 | prevaricaciones | 1 |
| 14930 | prevaliéndose | 1 |
| 14931 | prevaleciese | 1 |
| 14932 | pretil | 1 |
| 14933 | pretexta | 1 |
| 14934 | pretéritos | 1 |
| 14935 | pretérita | 1 |
| 14936 | pretericiones | 1 |
| 14937 | pretendientes | 1 |
| 14938 | pretendí | 1 |
| 14939 | pretenda | 1 |
| 14940 | presurosos | 1 |
| 14941 | presuntuoso | 1 |
| 14942 | presuntuosa | 1 |
| 14943 | presumiese | 1 |
| 14944 | presumidillas | 1 |
| 14945 | presumían | 1 |
| 14946 | prestidigitador | 1 |
| 14947 | preste | 1 |
| 14948 | prestaríamos | 1 |
| 14949 | prestaría | 1 |
| 14950 | prestar | 1 |
| 14951 | préstamos | 1 |
| 14952 | prestamista | 1 |
| 14953 | prestada | 1 |
| 14954 | presión | 1 |
| 14955 | presillas | 1 |
| 14956 | presiento | 1 |
| 14957 | presidió | 1 |
| 14958 | presidiera | 1 |
| 14959 | presididos | 1 |
| 14960 | presidido | 1 |
| 14961 | presidiario | 1 |
| 14962 | presidencia | 1 |
| 14963 | presentimientos | 1 |
| 14964 | presentían | 1 |
| 14965 | presentía | 1 |
| 14966 | presenten | 1 |
| 14967 | presentase | 1 |
| 14968 | presentarlo | 1 |
| 14969 | presentarles | 1 |
| 14970 | presentaría | 1 |
| 14971 | presentada | 1 |
| 14972 | presentación | 1 |
| 14973 | presentable | 1 |
| 14974 | presenció | 1 |
| 14975 | presenciara | 1 |
| 14976 | presenciado | 1 |
| 14977 | presenciaba | 1 |
| 14978 | preseas | 1 |
| 14979 | presea | 1 |
| 14980 | prescribe | 1 |
| 14981 | prescindirían | 1 |
| 14982 | prescindiendo | 1 |
| 14983 | prescindido | 1 |
| 14984 | prescindamos | 1 |
| 14985 | presbiterio | 1 |
| 14986 | presas | 1 |
| 14987 | prerrogativa | 1 |
| 14988 | prepararme | 1 |
| 14989 | prepararían | 1 |
| 14990 | prepararía | 1 |
| 14991 | preparándolos | 1 |
| 14992 | preparadas | 1 |
| 14993 | prepara | 1 |
| 14994 | preocupó | 1 |
| 14995 | preocuparse | 1 |
| 14996 | preocupándole | 1 |
| 14997 | preocupan | 1 |
| 14998 | preñadas | 1 |
| 14999 | prensas | 1 |
| 15000 | prensados | 1 |
| 15001 | prendieran | 1 |
| 15002 | prendido | 1 |
| 15003 | prendían | 1 |
| 15004 | prenderle | 1 |
| 15005 | premioso | 1 |
| 15006 | premiosas | 1 |
| 15007 | premiarle | 1 |
| 15008 | premiaba | 1 |
| 15009 | premeditada | 1 |
| 15010 | prematuro | 1 |
| 15011 | preguntes | 1 |
| 15012 | pregunte | 1 |
| 15013 | pregúntaselo | 1 |
| 15014 | preguntase | 1 |
| 15015 | preguntarte | 1 |
| 15016 | preguntarme | 1 |
| 15017 | preguntaré | 1 |
| 15018 | preguntara | 1 |
| 15019 | preguntándose | 1 |
| 15020 | pregonero | 1 |
| 15021 | pregonar | 1 |
| 15022 | pregonaban | 1 |
| 15023 | pregonaba | 1 |
| 15024 | prefirieron | 1 |
| 15025 | prefiriendo | 1 |
| 15026 | prefieren | 1 |
| 15027 | prefiera | 1 |
| 15028 | preferiría | 1 |
| 15029 | preferible | 1 |
| 15030 | prefación | 1 |
| 15031 | preeminentes | 1 |
| 15032 | predominar | 1 |
| 15033 | predominaban | 1 |
| 15034 | predomina | 1 |
| 15035 | predisposición | 1 |
| 15036 | predique | 1 |
| 15037 | predios | 1 |
| 15038 | predio | 1 |
| 15039 | predilectos | 1 |
| 15040 | predilecciones | 1 |
| 15041 | predicó | 1 |
| 15042 | predicas | 1 |
| 15043 | predicado | 1 |
| 15044 | predicaban | 1 |
| 15045 | precursor | 1 |
| 15046 | preclara | 1 |
| 15047 | precisión | 1 |
| 15048 | precisas | 1 |
| 15049 | precipitó | 1 |
| 15050 | precipitarse | 1 |
| 15051 | precipitadamente | 1 |
| 15052 | precipitaban | 1 |
| 15053 | precipitaba | 1 |
| 15054 | precipita | 1 |
| 15055 | precipicios | 1 |
| 15056 | preciosos | 1 |
| 15057 | precios | 1 |
| 15058 | precian | 1 |
| 15059 | preciaban | 1 |
| 15060 | precia | 1 |
| 15061 | precepto | 1 |
| 15062 | precedido | 1 |
| 15063 | precedía | 1 |
| 15064 | preceden | 1 |
| 15065 | precavido | 1 |
| 15066 | precaución | 1 |
| 15067 | prebendas | 1 |
| 15068 | pragmática | 1 |
| 15069 | practicaron | 1 |
| 15070 | practican | 1 |
| 15071 | practicada | 1 |
| 15072 | pozos | 1 |
| 15073 | poussin | 1 |
| 15074 | pour | 1 |
| 15075 | potros | 1 |
| 15076 | potente | 1 |
| 15077 | potentado | 1 |
| 15078 | potencias | 1 |
| 15079 | póstuma | 1 |
| 15080 | postró | 1 |
| 15081 | postizos | 1 |
| 15082 | postizo | 1 |
| 15083 | posteriores | 1 |
| 15084 | posterior | 1 |
| 15085 | postdata | 1 |
| 15086 | posta | 1 |
| 15087 | post | 1 |
| 15088 | possumus | 1 |
| 15089 | posponerle | 1 |
| 15090 | posiciones | 1 |
| 15091 | posesiones | 1 |
| 15092 | poseo | 1 |
| 15093 | poseía | 1 |
| 15094 | poseerte | 1 |
| 15095 | poseerla | 1 |
| 15096 | poseerás | 1 |
| 15097 | posee | 1 |
| 15098 | posarse | 1 |
| 15099 | posaban | 1 |
| 15100 | posaba | 1 |
| 15101 | portuguesa | 1 |
| 15102 | portugués | 1 |
| 15103 | portocarrero | 1 |
| 15104 | portó | 1 |
| 15105 | portier | 1 |
| 15106 | portezuela | 1 |
| 15107 | portería | 1 |
| 15108 | portentosa | 1 |
| 15109 | portento | 1 |
| 15110 | porte | 1 |
| 15111 | portátiles | 1 |
| 15112 | portador | 1 |
| 15113 | portaban | 1 |
| 15114 | portaba | 1 |
| 15115 | porrazo | 1 |
| 15116 | porra | 1 |
| 15117 | porquerías | 1 |
| 15118 | porquería | 1 |
| 15119 | porfiado | 1 |
| 15120 | porfía | 1 |
| 15121 | porches | 1 |
| 15122 | poquísimo | 1 |
| 15123 | populoso | 1 |
| 15124 | populi | 1 |
| 15125 | populares | 1 |
| 15126 | pontificii | 1 |
| 15127 | pontificado | 1 |
| 15128 | ponte | 1 |
| 15129 | ponío | 1 |
| 15130 | poniéndosele | 1 |
| 15131 | poniéndole | 1 |
| 15132 | poníase | 1 |
| 15133 | póngase | 1 |
| 15134 | ponérselas | 1 |
| 15135 | ponérsela | 1 |
| 15136 | ponernos | 1 |
| 15137 | ponerlos | 1 |
| 15138 | ponerlo | 1 |
| 15139 | pon | 1 |
| 15140 | pomposo | 1 |
| 15141 | pompas | 1 |
| 15142 | pompa | 1 |
| 15143 | pomarada | 1 |
| 15144 | polvorosas | 1 |
| 15145 | polvorín | 1 |
| 15146 | polvorientas | 1 |
| 15147 | polvorienta | 1 |
| 15148 | polvareda | 1 |
| 15149 | polo | 1 |
| 15150 | pollastre | 1 |
| 15151 | polizontes | 1 |
| 15152 | pólizas | 1 |
| 15153 | poliuto | 1 |
| 15154 | pólipo | 1 |
| 15155 | polilla | 1 |
| 15156 | policías | 1 |
| 15157 | polémica | 1 |
| 15158 | poleas | 1 |
| 15159 | polainas | 1 |
| 15160 | polaco | 1 |
| 15161 | poetizados | 1 |
| 15162 | poetillas | 1 |
| 15163 | poetilla | 1 |
| 15164 | poe | 1 |
| 15165 | podredumbres | 1 |
| 15166 | podrás | 1 |
| 15167 | pocula | 1 |
| 15168 | pocilgas | 1 |
| 15169 | pobretes | 1 |
| 15170 | pobretería | 1 |
| 15171 | pobladas | 1 |
| 15172 | poblada | 1 |
| 15173 | poblachones | 1 |
| 15174 | poblachón | 1 |
| 15175 | pluralidad | 1 |
| 15176 | plun | 1 |
| 15177 | plomizas | 1 |
| 15178 | plomiza | 1 |
| 15179 | plenos | 1 |
| 15180 | plenamente | 1 |
| 15181 | plegadera | 1 |
| 15182 | plegaba | 1 |
| 15183 | plebeyas | 1 |
| 15184 | plebeya | 1 |
| 15185 | plazos | 1 |
| 15186 | plazo | 1 |
| 15187 | platónicos | 1 |
| 15188 | platónica | 1 |
| 15189 | platón | 1 |
| 15190 | platillos | 1 |
| 15191 | platillo | 1 |
| 15192 | platicar | 1 |
| 15193 | plateresca | 1 |
| 15194 | plateadas | 1 |
| 15195 | plásticos | 1 |
| 15196 | plástico | 1 |
| 15197 | plasticidad | 1 |
| 15198 | plantón | 1 |
| 15199 | plantó | 1 |
| 15200 | plantando | 1 |
| 15201 | plantados | 1 |
| 15202 | plantaba | 1 |
| 15203 | planicies | 1 |
| 15204 | planetas | 1 |
| 15205 | planchas | 1 |
| 15206 | planchar | 1 |
| 15207 | planchadoras | 1 |
| 15208 | planchado | 1 |
| 15209 | placa | 1 |
| 15210 | pizpiretas | 1 |
| 15211 | pizpireta | 1 |
| 15212 | pizarro | 1 |
| 15213 | pittore | 1 |
| 15214 | pitonisa | 1 |
| 15215 | pitisa | 1 |
| 15216 | pitillos | 1 |
| 15217 | pitanza | 1 |
| 15218 | pitando | 1 |
| 15219 | pitágoras | 1 |
| 15220 | pisto | 1 |
| 15221 | pistilos | 1 |
| 15222 | pista | 1 |
| 15223 | pisoteado | 1 |
| 15224 | pisoteadas | 1 |
| 15225 | pisoteada | 1 |
| 15226 | piscis | 1 |
| 15227 | pisarlas | 1 |
| 15228 | pisara | 1 |
| 15229 | pisándose | 1 |
| 15230 | pisado | 1 |
| 15231 | pirueta | 1 |
| 15232 | piratas | 1 |
| 15233 | piquillo | 1 |
| 15234 | piquemos | 1 |
| 15235 | piqué | 1 |
| 15236 | pionono | 1 |
| 15237 | piña | 1 |
| 15238 | pinzones | 1 |
| 15239 | pintorescos | 1 |
| 15240 | pintoresco | 1 |
| 15241 | pintorescas | 1 |
| 15242 | pintoresca | 1 |
| 15243 | pintarse | 1 |
| 15244 | pintaría | 1 |
| 15245 | pintao | 1 |
| 15246 | pinón | 1 |
| 15247 | pingües | 1 |
| 15248 | pingos | 1 |
| 15249 | pinchó | 1 |
| 15250 | pincharle | 1 |
| 15251 | pincharlas | 1 |
| 15252 | pinchándole | 1 |
| 15253 | pinchado | 1 |
| 15254 | pinchaba | 1 |
| 15255 | pinares | 1 |
| 15256 | pin | 1 |
| 15257 | pimpollo | 1 |
| 15258 | pillastres | 1 |
| 15259 | píldoras | 1 |
| 15260 | pigault | 1 |
| 15261 | pietista | 1 |
| 15262 | piensan | 1 |
| 15263 | pidieron | 1 |
| 15264 | pidiéndole | 1 |
| 15265 | picoteaba | 1 |
| 15266 | picota | 1 |
| 15267 | picona | 1 |
| 15268 | pichones | 1 |
| 15269 | picazón | 1 |
| 15270 | pícaros | 1 |
| 15271 | picarísima | 1 |
| 15272 | picarilla | 1 |
| 15273 | picarescos | 1 |
| 15274 | picaresco | 1 |
| 15275 | picará | 1 |
| 15276 | picador | 1 |
| 15277 | picachos | 1 |
| 15278 | piara | 1 |
| 15279 | piafar | 1 |
| 15280 | phorminx | 1 |
| 15281 | petrificada | 1 |
| 15282 | petirrojos | 1 |
| 15283 | petatur | 1 |
| 15284 | petardos | 1 |
| 15285 | pétalos | 1 |
| 15286 | pespunteados | 1 |
| 15287 | peseteros | 1 |
| 15288 | pescas | 1 |
| 15289 | pescaremos | 1 |
| 15290 | pescante | 1 |
| 15291 | pescador | 1 |
| 15292 | pescaba | 1 |
| 15293 | pesas | 1 |
| 15294 | pesaría | 1 |
| 15295 | pesara | 1 |
| 15296 | pesándole | 1 |
| 15297 | pesadísimo | 1 |
| 15298 | pesadez | 1 |
| 15299 | pesaban | 1 |
| 15300 | pervertido | 1 |
| 15301 | pervertidas | 1 |
| 15302 | pervertía | 1 |
| 15303 | perversas | 1 |
| 15304 | perú | 1 |
| 15305 | perturbadora | 1 |
| 15306 | perturbado | 1 |
| 15307 | pertinente | 1 |
| 15308 | pertinaz | 1 |
| 15309 | perteneció | 1 |
| 15310 | perteneciera | 1 |
| 15311 | perteneces | 1 |
| 15312 | pertenecerle | 1 |
| 15313 | pertenecen | 1 |
| 15314 | pertenece | 1 |
| 15315 | persuasión | 1 |
| 15316 | persuadirle | 1 |
| 15317 | persuadidos | 1 |
| 15318 | persuadido | 1 |
| 15319 | persuadida | 1 |
| 15320 | perspectivas | 1 |
| 15321 | personificar | 1 |
| 15322 | personifican | 1 |
| 15323 | personificaciones | 1 |
| 15324 | personalidades | 1 |
| 15325 | persistía | 1 |
| 15326 | persistente | 1 |
| 15327 | persiguió | 1 |
| 15328 | persiguiéndose | 1 |
| 15329 | persiguiendo | 1 |
| 15330 | persiguen | 1 |
| 15331 | persignarse | 1 |
| 15332 | pérsica | 1 |
| 15333 | perseguirla | 1 |
| 15334 | perseguidor | 1 |
| 15335 | persecuciones | 1 |
| 15336 | perrerías | 1 |
| 15337 | perpetuos | 1 |
| 15338 | peros | 1 |
| 15339 | perorando | 1 |
| 15340 | peroles | 1 |
| 15341 | perol | 1 |
| 15342 | permito | 1 |
| 15343 | permitirme | 1 |
| 15344 | permitir | 1 |
| 15345 | permitiese | 1 |
| 15346 | permitieron | 1 |
| 15347 | permitiera | 1 |
| 15348 | permita | 1 |
| 15349 | permanezca | 1 |
| 15350 | permanecido | 1 |
| 15351 | permanecía | 1 |
| 15352 | perladas | 1 |
| 15353 | perjuicios | 1 |
| 15354 | perjudicaría | 1 |
| 15355 | perjudicar | 1 |
| 15356 | peritonitis | 1 |
| 15357 | perito | 1 |
| 15358 | peripatético | 1 |
| 15359 | periodista | 1 |
| 15360 | periódica | 1 |
| 15361 | perifollo | 1 |
| 15362 | periféricos | 1 |
| 15363 | pergeño | 1 |
| 15364 | pergeñadas | 1 |
| 15365 | pergaminos | 1 |
| 15366 | perfumería | 1 |
| 15367 | perfidia | 1 |
| 15368 | perfeccionarse | 1 |
| 15369 | perfeccionando | 1 |
| 15370 | perezosamente | 1 |
| 15371 | perezas | 1 |
| 15372 | pérez | 1 |
| 15373 | perentoria | 1 |
| 15374 | peregrinación | 1 |
| 15375 | pereda | 1 |
| 15376 | perecedero | 1 |
| 15377 | perdulario | 1 |
| 15378 | perdonóselos | 1 |
| 15379 | perdonase | 1 |
| 15380 | perdonarlo | 1 |
| 15381 | perdonarle | 1 |
| 15382 | perdonaría | 1 |
| 15383 | perdonara | 1 |
| 15384 | perdonándoselo | 1 |
| 15385 | perdonando | 1 |
| 15386 | perdóname | 1 |
| 15387 | perdonadle | 1 |
| 15388 | perdonaban | 1 |
| 15389 | perdigones | 1 |
| 15390 | perdigonada | 1 |
| 15391 | perdigón | 1 |
| 15392 | perdiese | 1 |
| 15393 | perdieron | 1 |
| 15394 | perdiera | 1 |
| 15395 | perdiéndose | 1 |
| 15396 | perdí | 1 |
| 15397 | perceptivas | 1 |
| 15398 | percalina | 1 |
| 15399 | percales | 1 |
| 15400 | peras | 1 |
| 15401 | peraltados | 1 |
| 15402 | per | 1 |
| 15403 | pequeñuelos | 1 |
| 15404 | pequeñísimo | 1 |
| 15405 | pequeñísima | 1 |
| 15406 | pepinillos | 1 |
| 15407 | peores | 1 |
| 15408 | peonza | 1 |
| 15409 | peones | 1 |
| 15410 | peoncillo | 1 |
| 15411 | peñasco | 1 |
| 15412 | penuria | 1 |
| 15413 | penumbra | 1 |
| 15414 | penúltimo | 1 |
| 15415 | penúltima | 1 |
| 15416 | pentagrama | 1 |
| 15417 | pensé | 1 |
| 15418 | pense | 1 |
| 15419 | pensarse | 1 |
| 15420 | pensamos | 1 |
| 15421 | pensadorzuelo | 1 |
| 15422 | pensadas | 1 |
| 15423 | penosos | 1 |
| 15424 | penoso | 1 |
| 15425 | penitenciarias | 1 |
| 15426 | penetrante | 1 |
| 15427 | penetrando | 1 |
| 15428 | péndulos | 1 |
| 15429 | pendones | 1 |
| 15430 | pendientes | 1 |
| 15431 | pender | 1 |
| 15432 | pendencias | 1 |
| 15433 | pendebat | 1 |
| 15434 | penachos | 1 |
| 15435 | penacho | 1 |
| 15436 | peluquería | 1 |
| 15437 | peluconas | 1 |
| 15438 | pelotas | 1 |
| 15439 | pellizcaban | 1 |
| 15440 | pellejo | 1 |
| 15441 | peligró | 1 |
| 15442 | peligra | 1 |
| 15443 | peleo | 1 |
| 15444 | peleé | 1 |
| 15445 | pelear | 1 |
| 15446 | peldaños | 1 |
| 15447 | pelayo | 1 |
| 15448 | pelada | 1 |
| 15449 | pela | 1 |
| 15450 | peinó | 1 |
| 15451 | peino | 1 |
| 15452 | peinar | 1 |
| 15453 | peinamos | 1 |
| 15454 | peinador | 1 |
| 15455 | peinadas | 1 |
| 15456 | pegó | 1 |
| 15457 | pegarse | 1 |
| 15458 | pegarnos | 1 |
| 15459 | pegarle | 1 |
| 15460 | pegando | 1 |
| 15461 | pegan | 1 |
| 15462 | pegajosos | 1 |
| 15463 | pegajosas | 1 |
| 15464 | pegados | 1 |
| 15465 | pedimos | 1 |
| 15466 | pedigüeño | 1 |
| 15467 | pedestal | 1 |
| 15468 | pedantón | 1 |
| 15469 | pedantesca | 1 |
| 15470 | pedantes | 1 |
| 15471 | pedantería | 1 |
| 15472 | pedagógicas | 1 |
| 15473 | pecuniarios | 1 |
| 15474 | peculiares | 1 |
| 15475 | pechinas | 1 |
| 15476 | peces | 1 |
| 15477 | peccata | 1 |
| 15478 | pecará | 1 |
| 15479 | pecaminosos | 1 |
| 15480 | pecadoras | 1 |
| 15481 | pecadillo | 1 |
| 15482 | peca | 1 |
| 15483 | pebetero | 1 |
| 15484 | pche | 1 |
| 15485 | pavorosos | 1 |
| 15486 | pavés | 1 |
| 15487 | pausado | 1 |
| 15488 | pauperum | 1 |
| 15489 | paulo | 1 |
| 15490 | paulatinos | 1 |
| 15491 | paulatinamente | 1 |
| 15492 | paul | 1 |
| 15493 | patrones | 1 |
| 15494 | patronato | 1 |
| 15495 | patrocinado | 1 |
| 15496 | patris | 1 |
| 15497 | patrióticas | 1 |
| 15498 | patriótica | 1 |
| 15499 | patriotas | 1 |
| 15500 | patriota | 1 |
| 15501 | patriarca | 1 |
| 15502 | patrañas | 1 |
| 15503 | patitas | 1 |
| 15504 | patios | 1 |
| 15505 | patíbulo | 1 |
| 15506 | paternales | 1 |
| 15507 | patena | 1 |
| 15508 | patearle | 1 |
| 15509 | patarata | 1 |
| 15510 | pastoreo | 1 |
| 15511 | pastora | 1 |
| 15512 | pasto | 1 |
| 15513 | pastillas | 1 |
| 15514 | pasteur | 1 |
| 15515 | pasteles | 1 |
| 15516 | pastelero | 1 |
| 15517 | pastas | 1 |
| 15518 | pasmasen | 1 |
| 15519 | pasmadas | 1 |
| 15520 | pasmada | 1 |
| 15521 | pasmábase | 1 |
| 15522 | pasmaban | 1 |
| 15523 | pasmaba | 1 |
| 15524 | pasma | 1 |
| 15525 | pasivos | 1 |
| 15526 | pasemos | 1 |
| 15527 | paseíto | 1 |
| 15528 | pasearon | 1 |
| 15529 | paseándola | 1 |
| 15530 | pasean | 1 |
| 15531 | pasea | 1 |
| 15532 | pascal | 1 |
| 15533 | pasarlas | 1 |
| 15534 | pasarla | 1 |
| 15535 | pasaremos | 1 |
| 15536 | pasaran | 1 |
| 15537 | pasao | 1 |
| 15538 | pasándolos | 1 |
| 15539 | pasamano | 1 |
| 15540 | pasajes | 1 |
| 15541 | pasabas | 1 |
| 15542 | parves | 1 |
| 15543 | parvedad | 1 |
| 15544 | parto | 1 |
| 15545 | partiquino | 1 |
| 15546 | partió | 1 |
| 15547 | particularmente | 1 |
| 15548 | partícula | 1 |
| 15549 | participaba | 1 |
| 15550 | parterre | 1 |
| 15551 | parteras | 1 |
| 15552 | parta | 1 |
| 15553 | parroquiales | 1 |
| 15554 | parrilla | 1 |
| 15555 | paroxismos | 1 |
| 15556 | parodiar | 1 |
| 15557 | parodiaba | 1 |
| 15558 | parodia | 1 |
| 15559 | parnaso | 1 |
| 15560 | parisienses | 1 |
| 15561 | parisién | 1 |
| 15562 | parió | 1 |
| 15563 | parezcan | 1 |
| 15564 | parejita | 1 |
| 15565 | paredones | 1 |
| 15566 | pareciendo | 1 |
| 15567 | parecíanle | 1 |
| 15568 | pareces | 1 |
| 15569 | parecérselo | 1 |
| 15570 | parecernos | 1 |
| 15571 | parecerla | 1 |
| 15572 | pareceres | 1 |
| 15573 | parduzco | 1 |
| 15574 | pardeaba | 1 |
| 15575 | pardales | 1 |
| 15576 | parciales | 1 |
| 15577 | parche | 1 |
| 15578 | parca | 1 |
| 15579 | pararrayos | 1 |
| 15580 | pararía | 1 |
| 15581 | parangón | 1 |
| 15582 | paran | 1 |
| 15583 | paralelos | 1 |
| 15584 | paralelo | 1 |
| 15585 | paradojas | 1 |
| 15586 | parábola | 1 |
| 15587 | parábanse | 1 |
| 15588 | paquete | 1 |
| 15589 | papista | 1 |
| 15590 | papisa | 1 |
| 15591 | papelucho | 1 |
| 15592 | pañuelos | 1 |
| 15593 | panzuda | 1 |
| 15594 | pantorriiiilla | 1 |
| 15595 | panteísticos | 1 |
| 15596 | panteística | 1 |
| 15597 | panteísta | 1 |
| 15598 | panteísmos | 1 |
| 15599 | pantalla | 1 |
| 15600 | panoplia | 1 |
| 15601 | paniaguado | 1 |
| 15602 | panegíricos | 1 |
| 15603 | panegírico | 1 |
| 15604 | panecillo | 1 |
| 15605 | panderetas | 1 |
| 15606 | pamplinas | 1 |
| 15607 | palúdicas | 1 |
| 15608 | palpitaciones | 1 |
| 15609 | palparles | 1 |
| 15610 | palpar | 1 |
| 15611 | palpando | 1 |
| 15612 | palpables | 1 |
| 15613 | palpaba | 1 |
| 15614 | paloma | 1 |
| 15615 | palmito | 1 |
| 15616 | palmeras | 1 |
| 15617 | palmario | 1 |
| 15618 | pallavicini | 1 |
| 15619 | palisandro | 1 |
| 15620 | palio | 1 |
| 15621 | palinodia | 1 |
| 15622 | palillo | 1 |
| 15623 | palillero | 1 |
| 15624 | paliducha | 1 |
| 15625 | palido | 1 |
| 15626 | palideció | 1 |
| 15627 | palidecer | 1 |
| 15628 | palas | 1 |
| 15629 | palafrén | 1 |
| 15630 | palación | 1 |
| 15631 | palabrotas | 1 |
| 15632 | pajarracos | 1 |
| 15633 | pajaritas | 1 |
| 15634 | pajarita | 1 |
| 15635 | pajar | 1 |
| 15636 | paix | 1 |
| 15637 | pagina | 1 |
| 15638 | pagase | 1 |
| 15639 | pagárselo | 1 |
| 15640 | pagaron | 1 |
| 15641 | pagarlo | 1 |
| 15642 | pagarías | 1 |
| 15643 | pagaríamos | 1 |
| 15644 | pagarás | 1 |
| 15645 | pagarán | 1 |
| 15646 | paganos | 1 |
| 15647 | paganismo | 1 |
| 15648 | pagamos | 1 |
| 15649 | pagados | 1 |
| 15650 | pagado | 1 |
| 15651 | pagaderos | 1 |
| 15652 | pagaderas | 1 |
| 15653 | paece | 1 |
| 15654 | padrenuestro | 1 |
| 15655 | padrazo | 1 |
| 15656 | padezco | 1 |
| 15657 | padezcas | 1 |
| 15658 | padezca | 1 |
| 15659 | padecimientos | 1 |
| 15660 | padecieron | 1 |
| 15661 | padeces | 1 |
| 15662 | padecerla | 1 |
| 15663 | padecerá | 1 |
| 15664 | padece | 1 |
| 15665 | pactos | 1 |
| 15666 | pacos | 1 |
| 15667 | pacíficos | 1 |
| 15668 | pacíficamente | 1 |
| 15669 | pacientes | 1 |
| 15670 | pábilos | 1 |
| 15671 | oyesen | 1 |
| 15672 | oyéndola | 1 |
| 15673 | oxígeno | 1 |
| 15674 | oxidadas | 1 |
| 15675 | ovillo | 1 |
| 15676 | oveja | 1 |
| 15677 | ovaladas | 1 |
| 15678 | oval | 1 |
| 15679 | ovación | 1 |
| 15680 | otrosí | 1 |
| 15681 | otorgaría | 1 |
| 15682 | otorgar | 1 |
| 15683 | otorgado | 1 |
| 15684 | otorgaba | 1 |
| 15685 | otoños | 1 |
| 15686 | otoñada | 1 |
| 15687 | osuna | 1 |
| 15688 | ostracismo | 1 |
| 15689 | ostentosos | 1 |
| 15690 | ostentosas | 1 |
| 15691 | ostentando | 1 |
| 15692 | ostentan | 1 |
| 15693 | ostensiblemente | 1 |
| 15694 | osó | 1 |
| 15695 | oscilando | 1 |
| 15696 | osaron | 1 |
| 15697 | osar | 1 |
| 15698 | osados | 1 |
| 15699 | osadía | 1 |
| 15700 | osadas | 1 |
| 15701 | orza | 1 |
| 15702 | ortodoxas | 1 |
| 15703 | ortodoxa | 1 |
| 15704 | orto | 1 |
| 15705 | ortiz | 1 |
| 15706 | orsini | 1 |
| 15707 | oropel | 1 |
| 15708 | oró | 1 |
| 15709 | ornato | 1 |
| 15710 | orladas | 1 |
| 15711 | orlaban | 1 |
| 15712 | orillo | 1 |
| 15713 | originó | 1 |
| 15714 | originarse | 1 |
| 15715 | originales | 1 |
| 15716 | origina | 1 |
| 15717 | orígenes | 1 |
| 15718 | orientarse | 1 |
| 15719 | orientalista | 1 |
| 15720 | oriental | 1 |
| 15721 | orgullosos | 1 |
| 15722 | orgullos | 1 |
| 15723 | orgullito | 1 |
| 15724 | orgasmo | 1 |
| 15725 | organizado | 1 |
| 15726 | organizaba | 1 |
| 15727 | organismo | 1 |
| 15728 | organdí | 1 |
| 15729 | orejeras | 1 |
| 15730 | ordo | 1 |
| 15731 | ordine | 1 |
| 15732 | ordenase | 1 |
| 15733 | ordenarse | 1 |
| 15734 | ordenaba | 1 |
| 15735 | órbita | 1 |
| 15736 | orangutanes | 1 |
| 15737 | oradoras | 1 |
| 15738 | orado | 1 |
| 15739 | oráculo | 1 |
| 15740 | opusieron | 1 |
| 15741 | opusiera | 1 |
| 15742 | opulenta | 1 |
| 15743 | opulencia | 1 |
| 15744 | opuestas | 1 |
| 15745 | opuesta | 1 |
| 15746 | óptima | 1 |
| 15747 | óptico | 1 |
| 15748 | oprimiéndose | 1 |
| 15749 | oprimiendo | 1 |
| 15750 | oprimidos | 1 |
| 15751 | oprimida | 1 |
| 15752 | opresor | 1 |
| 15753 | opresiones | 1 |
| 15754 | opresión | 1 |
| 15755 | oppert | 1 |
| 15756 | opositor | 1 |
| 15757 | oportunos | 1 |
| 15758 | oportunísimo | 1 |
| 15759 | oportunas | 1 |
| 15760 | oportunamente | 1 |
| 15761 | opino | 1 |
| 15762 | opinar | 1 |
| 15763 | opinan | 1 |
| 15764 | opaco | 1 |
| 15765 | ondeado | 1 |
| 15766 | ondeadas | 1 |
| 15767 | ondeada | 1 |
| 15768 | onda | 1 |
| 15769 | omnipotencia | 1 |
| 15770 | omnilateral | 1 |
| 15771 | ominosos | 1 |
| 15772 | ominoso | 1 |
| 15773 | olvidos | 1 |
| 15774 | olvides | 1 |
| 15775 | olvidastes | 1 |
| 15776 | olvidase | 1 |
| 15777 | olvidas | 1 |
| 15778 | olvidarlo | 1 |
| 15779 | olvidarlas | 1 |
| 15780 | olvidarla | 1 |
| 15781 | olvidan | 1 |
| 15782 | olvidadas | 1 |
| 15783 | olvida | 1 |
| 15784 | olivo | 1 |
| 15785 | olimpo | 1 |
| 15786 | oliente | 1 |
| 15787 | olido | 1 |
| 15788 | olfato | 1 |
| 15789 | olfateo | 1 |
| 15790 | olfateando | 1 |
| 15791 | olé | 1 |
| 15792 | ojivas | 1 |
| 15793 | ojivales | 1 |
| 15794 | ojitos | 1 |
| 15795 | ojazos | 1 |
| 15796 | oírte | 1 |
| 15797 | oírme | 1 |
| 15798 | oírlos | 1 |
| 15799 | oírlo | 1 |
| 15800 | oírla | 1 |
| 15801 | oirían | 1 |
| 15802 | oirás | 1 |
| 15803 | oirá | 1 |
| 15804 | oigámoslo | 1 |
| 15805 | óigame | 1 |
| 15806 | óigalo | 1 |
| 15807 | oi | 1 |
| 15808 | ogaño | 1 |
| 15809 | ofrecieron | 1 |
| 15810 | ofreciéndole | 1 |
| 15811 | ofrecida | 1 |
| 15812 | ofidiana | 1 |
| 15813 | oficiando | 1 |
| 15814 | ofensivas | 1 |
| 15815 | ofendidos | 1 |
| 15816 | ofendida | 1 |
| 15817 | ofendían | 1 |
| 15818 | ofenderse | 1 |
| 15819 | ofenderle | 1 |
| 15820 | ofenda | 1 |
| 15821 | odias | 1 |
| 15822 | odiarme | 1 |
| 15823 | odiar | 1 |
| 15824 | odas | 1 |
| 15825 | ocurrírsele | 1 |
| 15826 | ocurriría | 1 |
| 15827 | ocurrir | 1 |
| 15828 | ocurrieron | 1 |
| 15829 | ocurrieran | 1 |
| 15830 | ocurren | 1 |
| 15831 | ocurra | 1 |
| 15832 | ocupe | 1 |
| 15833 | ocuparse | 1 |
| 15834 | ocuparé | 1 |
| 15835 | ocupándose | 1 |
| 15836 | ocupadas | 1 |
| 15837 | ocupábase | 1 |
| 15838 | ocupa | 1 |
| 15839 | ocultes | 1 |
| 15840 | ocultéis | 1 |
| 15841 | ocultase | 1 |
| 15842 | ocultas | 1 |
| 15843 | ocultaron | 1 |
| 15844 | ocultarlos | 1 |
| 15845 | ocultarle | 1 |
| 15846 | ocultarlas | 1 |
| 15847 | ocultado | 1 |
| 15848 | octavo | 1 |
| 15849 | octava | 1 |
| 15850 | ociosa | 1 |
| 15851 | ochentón | 1 |
| 15852 | ochavos | 1 |
| 15853 | occidental | 1 |
| 15854 | ocasional | 1 |
| 15855 | obtuvo | 1 |
| 15856 | obtener | 1 |
| 15857 | obstinada | 1 |
| 15858 | obstinaba | 1 |
| 15859 | obseso | 1 |
| 15860 | observo | 1 |
| 15861 | observe | 1 |
| 15862 | observatorios | 1 |
| 15863 | observatorio | 1 |
| 15864 | observarle | 1 |
| 15865 | observamos | 1 |
| 15866 | observadores | 1 |
| 15867 | observaban | 1 |
| 15868 | obsequiarle | 1 |
| 15869 | obsequiadas | 1 |
| 15870 | obsequiaban | 1 |
| 15871 | obsequiaba | 1 |
| 15872 | obscurezca | 1 |
| 15873 | obscurecida | 1 |
| 15874 | obscurantismo | 1 |
| 15875 | obraban | 1 |
| 15876 | oblonga | 1 |
| 15877 | obligatorio | 1 |
| 15878 | obligase | 1 |
| 15879 | obligaron | 1 |
| 15880 | obligarle | 1 |
| 15881 | obligarla | 1 |
| 15882 | obligaríanles | 1 |
| 15883 | obligara | 1 |
| 15884 | obligando | 1 |
| 15885 | oblicuos | 1 |
| 15886 | oblicuo | 1 |
| 15887 | oblicuas | 1 |
| 15888 | objetó | 1 |
| 15889 | objetivo | 1 |
| 15890 | objetado | 1 |
| 15891 | objetaba | 1 |
| 15892 | objeción | 1 |
| 15893 | obispillo | 1 |
| 15894 | obedientes | 1 |
| 15895 | obediente | 1 |
| 15896 | obedecí | 1 |
| 15897 | obedecerle | 1 |
| 15898 | obedece | 1 |
| 15899 | obdulias | 1 |
| 15900 | obcecado | 1 |
| 15901 | nutrir | 1 |
| 15902 | nuncio | 1 |
| 15903 | numeroso | 1 |
| 15904 | numerosa | 1 |
| 15905 | nulo | 1 |
| 15906 | nulas | 1 |
| 15907 | nuez | 1 |
| 15908 | nudos | 1 |
| 15909 | nublada | 1 |
| 15910 | nubarrones | 1 |
| 15911 | novísima | 1 |
| 15912 | novios | 1 |
| 15913 | noviazgos | 1 |
| 15914 | novia | 1 |
| 15915 | novenario | 1 |
| 15916 | novelistas | 1 |
| 15917 | novelescos | 1 |
| 15918 | noveladores | 1 |
| 15919 | notorio | 1 |
| 15920 | notoria | 1 |
| 15921 | noticierismo | 1 |
| 15922 | noten | 1 |
| 15923 | notasen | 1 |
| 15924 | notadas | 1 |
| 15925 | notada | 1 |
| 15926 | notabilidad | 1 |
| 15927 | not | 1 |
| 15928 | noruega | 1 |
| 15929 | normandos | 1 |
| 15930 | normal | 1 |
| 15931 | nordeste | 1 |
| 15932 | nomine | 1 |
| 15933 | nombró | 1 |
| 15934 | nombrando | 1 |
| 15935 | nombramientos | 1 |
| 15936 | nombramiento | 1 |
| 15937 | nombra | 1 |
| 15938 | nolis | 1 |
| 15939 | nogales | 1 |
| 15940 | nodrizas | 1 |
| 15941 | nocivas | 1 |
| 15942 | nociones | 1 |
| 15943 | nocedal | 1 |
| 15944 | noblemente | 1 |
| 15945 | nobilísimo | 1 |
| 15946 | nivelaba | 1 |
| 15947 | nisi | 1 |
| 15948 | ninon | 1 |
| 15949 | nínive | 1 |
| 15950 | ninfa | 1 |
| 15951 | nimbo | 1 |
| 15952 | nihil | 1 |
| 15953 | nieves | 1 |
| 15954 | nieto | 1 |
| 15955 | niegas | 1 |
| 15956 | nidos | 1 |
| 15957 | nevatilla | 1 |
| 15958 | nevase | 1 |
| 15959 | nevado | 1 |
| 15960 | nevaba | 1 |
| 15961 | neutra | 1 |
| 15962 | neos | 1 |
| 15963 | neo | 1 |
| 15964 | nenas | 1 |
| 15965 | nemrod | 1 |
| 15966 | nemorosos | 1 |
| 15967 | negruzcas | 1 |
| 15968 | negruras | 1 |
| 15969 | negrillo | 1 |
| 15970 | negligencia | 1 |
| 15971 | negase | 1 |
| 15972 | negarte | 1 |
| 15973 | negaron | 1 |
| 15974 | negarla | 1 |
| 15975 | negarán | 1 |
| 15976 | negándoles | 1 |
| 15977 | negado | 1 |
| 15978 | nefastos | 1 |
| 15979 | nefasta | 1 |
| 15980 | nefas | 1 |
| 15981 | nefando | 1 |
| 15982 | necesiten | 1 |
| 15983 | necesite | 1 |
| 15984 | necesitarlos | 1 |
| 15985 | necesitarlas | 1 |
| 15986 | necesitara | 1 |
| 15987 | necesitáis | 1 |
| 15988 | necesitados | 1 |
| 15989 | necesitábamos | 1 |
| 15990 | nebuloso | 1 |
| 15991 | nebulosa | 1 |
| 15992 | nazcan | 1 |
| 15993 | nay | 1 |
| 15994 | navío | 1 |
| 15995 | navegando | 1 |
| 15996 | navegados | 1 |
| 15997 | navegación | 1 |
| 15998 | naval | 1 |
| 15999 | náutica | 1 |
| 16000 | naturans | 1 |
| 16001 | naturalistas | 1 |
| 16002 | naturalísimo | 1 |
| 16003 | natividad | 1 |
| 16004 | natalicio | 1 |
| 16005 | natalia | 1 |
| 16006 | natal | 1 |
| 16007 | narrar | 1 |
| 16008 | narigudo | 1 |
| 16009 | narciso | 1 |
| 16010 | naranjos | 1 |
| 16011 | naipes | 1 |
| 16012 | naipe | 1 |
| 16013 | nadar | 1 |
| 16014 | nadando | 1 |
| 16015 | nacimientos | 1 |
| 16016 | naciera | 1 |
| 16017 | naciente | 1 |
| 16018 | naciendo | 1 |
| 16019 | nacida | 1 |
| 16020 | nací | 1 |
| 16021 | mutuos | 1 |
| 16022 | mutua | 1 |
| 16023 | mustios | 1 |
| 16024 | mustias | 1 |
| 16025 | mustia | 1 |
| 16026 | muslos | 1 |
| 16027 | musgosas | 1 |
| 16028 | musgo | 1 |
| 16029 | musculosa | 1 |
| 16030 | músculo | 1 |
| 16031 | musas | 1 |
| 16032 | musa | 1 |
| 16033 | murmuren | 1 |
| 16034 | murmurase | 1 |
| 16035 | murmuraría | 1 |
| 16036 | murmuran | 1 |
| 16037 | murmurador | 1 |
| 16038 | murmurado | 1 |
| 16039 | muriéndose | 1 |
| 16040 | muriéndonos | 1 |
| 16041 | muñoz | 1 |
| 16042 | muñón | 1 |
| 16043 | muñeira | 1 |
| 16044 | muñecos | 1 |
| 16045 | muñeco | 1 |
| 16046 | munificencia | 1 |
| 16047 | mundanales | 1 |
| 16048 | munda | 1 |
| 16049 | multiplicándose | 1 |
| 16050 | multiplicadas | 1 |
| 16051 | múltiples | 1 |
| 16052 | multas | 1 |
| 16053 | mullido | 1 |
| 16054 | mulata | 1 |
| 16055 | mulas | 1 |
| 16056 | mujerzuela | 1 |
| 16057 | mujerota | 1 |
| 16058 | mujeril | 1 |
| 16059 | mugre | 1 |
| 16060 | muévete | 1 |
| 16061 | mueven | 1 |
| 16062 | mueres | 1 |
| 16063 | mueren | 1 |
| 16064 | muerdes | 1 |
| 16065 | muelles | 1 |
| 16066 | muecas | 1 |
| 16067 | mueblista | 1 |
| 16068 | mueblaje | 1 |
| 16069 | múdese | 1 |
| 16070 | mudando | 1 |
| 16071 | muchísimos | 1 |
| 16072 | muchachuelas | 1 |
| 16073 | mucetas | 1 |
| 16074 | mu | 1 |
| 16075 | mr | 1 |
| 16076 | mozalbetes | 1 |
| 16077 | moviesen | 1 |
| 16078 | moviese | 1 |
| 16079 | movieron | 1 |
| 16080 | moviera | 1 |
| 16081 | moviéndose | 1 |
| 16082 | movido | 1 |
| 16083 | movibles | 1 |
| 16084 | moverlos | 1 |
| 16085 | moverla | 1 |
| 16086 | movediza | 1 |
| 16087 | motes | 1 |
| 16088 | mote | 1 |
| 16089 | mostró | 1 |
| 16090 | mostrase | 1 |
| 16091 | mostrarlo | 1 |
| 16092 | mostrarle | 1 |
| 16093 | mostrándose | 1 |
| 16094 | mostrándole | 1 |
| 16095 | mostradas | 1 |
| 16096 | mostaza | 1 |
| 16097 | mosco | 1 |
| 16098 | mortificarme | 1 |
| 16099 | mortificarla | 1 |
| 16100 | mortificar | 1 |
| 16101 | mortificado | 1 |
| 16102 | mortífero | 1 |
| 16103 | mortífera | 1 |
| 16104 | morro | 1 |
| 16105 | morosos | 1 |
| 16106 | morirme | 1 |
| 16107 | morimos | 1 |
| 16108 | morigerado | 1 |
| 16109 | morigerada | 1 |
| 16110 | morfina | 1 |
| 16111 | morería | 1 |
| 16112 | morenos | 1 |
| 16113 | morenas | 1 |
| 16114 | mordieron | 1 |
| 16115 | mordían | 1 |
| 16116 | morderse | 1 |
| 16117 | mordería | 1 |
| 16118 | mordedura | 1 |
| 16119 | morcillas | 1 |
| 16120 | morcilla | 1 |
| 16121 | morbosa | 1 |
| 16122 | mórbido | 1 |
| 16123 | morbidez | 1 |
| 16124 | mórbida | 1 |
| 16125 | moran | 1 |
| 16126 | moralmente | 1 |
| 16127 | moralizarla | 1 |
| 16128 | moralizar | 1 |
| 16129 | mora | 1 |
| 16130 | moño | 1 |
| 16131 | moña | 1 |
| 16132 | monumental | 1 |
| 16133 | monterilla | 1 |
| 16134 | montecristo | 1 |
| 16135 | montase | 1 |
| 16136 | montar | 1 |
| 16137 | montados | 1 |
| 16138 | montadas | 1 |
| 16139 | montada | 1 |
| 16140 | montaba | 1 |
| 16141 | monta | 1 |
| 16142 | monstruoso | 1 |
| 16143 | monstruosas | 1 |
| 16144 | monstruosa | 1 |
| 16145 | monosílabo | 1 |
| 16146 | monólogo | 1 |
| 16147 | monolito | 1 |
| 16148 | monocromos | 1 |
| 16149 | monjitas | 1 |
| 16150 | monjío | 1 |
| 16151 | monjes | 1 |
| 16152 | monje | 1 |
| 16153 | mónica | 1 |
| 16154 | monescillo | 1 |
| 16155 | monederos | 1 |
| 16156 | monedero | 1 |
| 16157 | mondes | 1 |
| 16158 | mondar | 1 |
| 16159 | monda | 1 |
| 16160 | monástica | 1 |
| 16161 | monagos | 1 |
| 16162 | mona | 1 |
| 16163 | momentánea | 1 |
| 16164 | mollera | 1 |
| 16165 | molinos | 1 |
| 16166 | molineros | 1 |
| 16167 | moliera | 1 |
| 16168 | molestos | 1 |
| 16169 | moleste | 1 |
| 16170 | molestarse | 1 |
| 16171 | molestándolos | 1 |
| 16172 | molestándoles | 1 |
| 16173 | molestándole | 1 |
| 16174 | moleslo | 1 |
| 16175 | moleschott | 1 |
| 16176 | moléculas | 1 |
| 16177 | molécula | 1 |
| 16178 | molduras | 1 |
| 16179 | moldes | 1 |
| 16180 | mojigatos | 1 |
| 16181 | mojigangas | 1 |
| 16182 | mojar | 1 |
| 16183 | mojando | 1 |
| 16184 | mojados | 1 |
| 16185 | mojadas | 1 |
| 16186 | mohicanos | 1 |
| 16187 | modus | 1 |
| 16188 | modismos | 1 |
| 16189 | modificado | 1 |
| 16190 | modificaciones | 1 |
| 16191 | modificaba | 1 |
| 16192 | moderados | 1 |
| 16193 | moderado | 1 |
| 16194 | mocosos | 1 |
| 16195 | mochuelos | 1 |
| 16196 | mochuelo | 1 |
| 16197 | mobiliario | 1 |
| 16198 | mo | 1 |
| 16199 | mixto | 1 |
| 16200 | mixtificación | 1 |
| 16201 | mitológicos | 1 |
| 16202 | mitologías | 1 |
| 16203 | mitigado | 1 |
| 16204 | mitigada | 1 |
| 16205 | místicamente | 1 |
| 16206 | misteriosas | 1 |
| 16207 | miss | 1 |
| 16208 | mismísima | 1 |
| 16209 | misiva | 1 |
| 16210 | misérrimo | 1 |
| 16211 | míseros | 1 |
| 16212 | miserablemente | 1 |
| 16213 | misántropo | 1 |
| 16214 | mirones | 1 |
| 16215 | mirlaba | 1 |
| 16216 | mirarme | 1 |
| 16217 | mirarían | 1 |
| 16218 | mirarás | 1 |
| 16219 | mirándoos | 1 |
| 16220 | mirándola | 1 |
| 16221 | miramiento | 1 |
| 16222 | mírale | 1 |
| 16223 | mirábala | 1 |
| 16224 | miope | 1 |
| 16225 | minuta | 1 |
| 16226 | minué | 1 |
| 16227 | minucioso | 1 |
| 16228 | minuciosamente | 1 |
| 16229 | minuciosa | 1 |
| 16230 | ministerios | 1 |
| 16231 | ministerio | 1 |
| 16232 | miniatura | 1 |
| 16233 | minero | 1 |
| 16234 | mineralógicas | 1 |
| 16235 | minerales | 1 |
| 16236 | mimosa | 1 |
| 16237 | mimo | 1 |
| 16238 | mímicos | 1 |
| 16239 | mímicas | 1 |
| 16240 | mimaban | 1 |
| 16241 | mimaba | 1 |
| 16242 | milo | 1 |
| 16243 | millón | 1 |
| 16244 | milito | 1 |
| 16245 | militantes | 1 |
| 16246 | militante | 1 |
| 16247 | militaba | 1 |
| 16248 | miliarias | 1 |
| 16249 | milano | 1 |
| 16250 | milagrosamente | 1 |
| 16251 | miguel | 1 |
| 16252 | miento | 1 |
| 16253 | mienta | 1 |
| 16254 | miedosa | 1 |
| 16255 | midiéramos | 1 |
| 16256 | mide | 1 |
| 16257 | mica | 1 |
| 16258 | mezquita | 1 |
| 16259 | mezcló | 1 |
| 16260 | mezclase | 1 |
| 16261 | mezclarse | 1 |
| 16262 | mezclándose | 1 |
| 16263 | mezclados | 1 |
| 16264 | meus | 1 |
| 16265 | meum | 1 |
| 16266 | metz | 1 |
| 16267 | metropolitano | 1 |
| 16268 | metralla | 1 |
| 16269 | método | 1 |
| 16270 | metodista | 1 |
| 16271 | metiera | 1 |
| 16272 | metiéndose | 1 |
| 16273 | metiéndole | 1 |
| 16274 | metiditos | 1 |
| 16275 | metidito | 1 |
| 16276 | metidas | 1 |
| 16277 | metérselo | 1 |
| 16278 | meteorológicos | 1 |
| 16279 | meteorología | 1 |
| 16280 | metamorfosis | 1 |
| 16281 | metalizado | 1 |
| 16282 | metálicos | 1 |
| 16283 | metafóricamente | 1 |
| 16284 | mesetas | 1 |
| 16285 | mescolanzas | 1 |
| 16286 | mesaba | 1 |
| 16287 | mero | 1 |
| 16288 | mermas | 1 |
| 16289 | meritorio | 1 |
| 16290 | meritoria | 1 |
| 16291 | merino | 1 |
| 16292 | meriendo | 1 |
| 16293 | meridionales | 1 |
| 16294 | merezco | 1 |
| 16295 | merendado | 1 |
| 16296 | merendaba | 1 |
| 16297 | merecimiento | 1 |
| 16298 | mereciese | 1 |
| 16299 | merecidísimo | 1 |
| 16300 | merecerles | 1 |
| 16301 | mera | 1 |
| 16302 | mequetrefes | 1 |
| 16303 | mequetrefe | 1 |
| 16304 | menudeando | 1 |
| 16305 | menudean | 1 |
| 16306 | menuda | 1 |
| 16307 | mentor | 1 |
| 16308 | mentón | 1 |
| 16309 | mentís | 1 |
| 16310 | mentido | 1 |
| 16311 | mentida | 1 |
| 16312 | mentían | 1 |
| 16313 | mentarle | 1 |
| 16314 | mentarla | 1 |
| 16315 | mentalmente | 1 |
| 16316 | mentales | 1 |
| 16317 | mensual | 1 |
| 16318 | menjurjes | 1 |
| 16319 | menguada | 1 |
| 16320 | menguaba | 1 |
| 16321 | mengua | 1 |
| 16322 | menestrales | 1 |
| 16323 | menesteres | 1 |
| 16324 | meneses | 1 |
| 16325 | meneó | 1 |
| 16326 | meneo | 1 |
| 16327 | meneaban | 1 |
| 16328 | mendrugos | 1 |
| 16329 | mendrugo | 1 |
| 16330 | méndez | 1 |
| 16331 | mencionaré | 1 |
| 16332 | memento | 1 |
| 16333 | membibres | 1 |
| 16334 | meloso | 1 |
| 16335 | melosas | 1 |
| 16336 | melodiosa | 1 |
| 16337 | melodías | 1 |
| 16338 | melocotón | 1 |
| 16339 | meliora | 1 |
| 16340 | melindrán | 1 |
| 16341 | melifluo | 1 |
| 16342 | melancólicamente | 1 |
| 16343 | mejorase | 1 |
| 16344 | mejorarán | 1 |
| 16345 | mejorar | 1 |
| 16346 | mejoraba | 1 |
| 16347 | méjico | 1 |
| 16348 | mefistofélicos | 1 |
| 16349 | médula | 1 |
| 16350 | medró | 1 |
| 16351 | medro | 1 |
| 16352 | medrar | 1 |
| 16353 | medran | 1 |
| 16354 | medrados | 1 |
| 16355 | medite | 1 |
| 16356 | meditan | 1 |
| 16357 | meditado | 1 |
| 16358 | meditabunda | 1 |
| 16359 | medita | 1 |
| 16360 | medirse | 1 |
| 16361 | médicis | 1 |
| 16362 | medianoche | 1 |
| 16363 | medianería | 1 |
| 16364 | medianeras | 1 |
| 16365 | medianas | 1 |
| 16366 | medalla | 1 |
| 16367 | mecida | 1 |
| 16368 | mecía | 1 |
| 16369 | mecheros | 1 |
| 16370 | mecha | 1 |
| 16371 | mecanismo | 1 |
| 16372 | mecánicamente | 1 |
| 16373 | mazas | 1 |
| 16374 | mayúscula | 1 |
| 16375 | mayorazguetes | 1 |
| 16376 | mayorazguete | 1 |
| 16377 | mayorazgo | 1 |
| 16378 | mayoral | 1 |
| 16379 | mayaba | 1 |
| 16380 | máximo | 1 |
| 16381 | máximas | 1 |
| 16382 | maudsley | 1 |
| 16383 | matutinos | 1 |
| 16384 | matutino | 1 |
| 16385 | matutina | 1 |
| 16386 | matronas | 1 |
| 16387 | matriculados | 1 |
| 16388 | matriculadas | 1 |
| 16389 | matrícula | 1 |
| 16390 | matinée | 1 |
| 16391 | matiella | 1 |
| 16392 | matías | 1 |
| 16393 | maternidad | 1 |
| 16394 | materialistas | 1 |
| 16395 | mateo | 1 |
| 16396 | maten | 1 |
| 16397 | matemáticos | 1 |
| 16398 | matemático | 1 |
| 16399 | matemáticamente | 1 |
| 16400 | maté | 1 |
| 16401 | matase | 1 |
| 16402 | matas | 1 |
| 16403 | matarse | 1 |
| 16404 | matara | 1 |
| 16405 | mátale | 1 |
| 16406 | matadero | 1 |
| 16407 | masini | 1 |
| 16408 | masculinos | 1 |
| 16409 | masculinas | 1 |
| 16410 | máscaras | 1 |
| 16411 | masca | 1 |
| 16412 | martirizarle | 1 |
| 16413 | martillazo | 1 |
| 16414 | marte | 1 |
| 16415 | marsilla | 1 |
| 16416 | marquilla | 1 |
| 16417 | marquesitas | 1 |
| 16418 | marquesina | 1 |
| 16419 | marmolillo | 1 |
| 16420 | mármoles | 1 |
| 16421 | marmitón | 1 |
| 16422 | maritornes | 1 |
| 16423 | mariscos | 1 |
| 16424 | mariposa | 1 |
| 16425 | marinos | 1 |
| 16426 | marino | 1 |
| 16427 | marimachos | 1 |
| 16428 | marimacho | 1 |
| 16429 | marearlos | 1 |
| 16430 | mareantes | 1 |
| 16431 | mareado | 1 |
| 16432 | mare | 1 |
| 16433 | marchitos | 1 |
| 16434 | marchitaban | 1 |
| 16435 | marcharte | 1 |
| 16436 | marcharía | 1 |
| 16437 | marchando | 1 |
| 16438 | marcando | 1 |
| 16439 | maravillosa | 1 |
| 16440 | maravillado | 1 |
| 16441 | maragato | 1 |
| 16442 | maquinillas | 1 |
| 16443 | maquinalmente | 1 |
| 16444 | maquinal | 1 |
| 16445 | maquinaciones | 1 |
| 16446 | maquinación | 1 |
| 16447 | mapa | 1 |
| 16448 | manuscrito | 1 |
| 16449 | manu | 1 |
| 16450 | mantuvo | 1 |
| 16451 | mantuvieron | 1 |
| 16452 | mantillas | 1 |
| 16453 | manterola | 1 |
| 16454 | mantenido | 1 |
| 16455 | mantengo | 1 |
| 16456 | mantengas | 1 |
| 16457 | mantenerlo | 1 |
| 16458 | mantendría | 1 |
| 16459 | manteleta | 1 |
| 16460 | manteles | 1 |
| 16461 | mantas | 1 |
| 16462 | mansa | 1 |
| 16463 | manriques | 1 |
| 16464 | manoseando | 1 |
| 16465 | manolesco | 1 |
| 16466 | manola | 1 |
| 16467 | manojo | 1 |
| 16468 | manirrota | 1 |
| 16469 | maniqueo | 1 |
| 16470 | maniobras | 1 |
| 16471 | manifestase | 1 |
| 16472 | manifestara | 1 |
| 16473 | manifestándose | 1 |
| 16474 | manifestamos | 1 |
| 16475 | manifestado | 1 |
| 16476 | manifestaciones | 1 |
| 16477 | manifestaban | 1 |
| 16478 | maniática | 1 |
| 16479 | manejaban | 1 |
| 16480 | mandria | 1 |
| 16481 | mandobles | 1 |
| 16482 | mandilona | 1 |
| 16483 | mandé | 1 |
| 16484 | mandasen | 1 |
| 16485 | mandase | 1 |
| 16486 | mandarse | 1 |
| 16487 | mandaron | 1 |
| 16488 | mandarlo | 1 |
| 16489 | mandarla | 1 |
| 16490 | mandaremos | 1 |
| 16491 | mandando | 1 |
| 16492 | mandamos | 1 |
| 16493 | mandamientos | 1 |
| 16494 | mandamiento | 1 |
| 16495 | manchara | 1 |
| 16496 | manchar | 1 |
| 16497 | manchándolos | 1 |
| 16498 | manchan | 1 |
| 16499 | manchadas | 1 |
| 16500 | manchada | 1 |
| 16501 | manar | 1 |
| 16502 | maná | 1 |
| 16503 | mampostería | 1 |
| 16504 | mamar | 1 |
| 16505 | maltrecho | 1 |
| 16506 | maltratadas | 1 |
| 16507 | maltrataba | 1 |
| 16508 | malquistarle | 1 |
| 16509 | malla | 1 |
| 16510 | maliciado | 1 |
| 16511 | maliciaban | 1 |
| 16512 | malhumor | 1 |
| 16513 | malhechor | 1 |
| 16514 | malgré | 1 |
| 16515 | malgastado | 1 |
| 16516 | malgastada | 1 |
| 16517 | malévolas | 1 |
| 16518 | malestar | 1 |
| 16519 | malditos | 1 |
| 16520 | maldiciendo | 1 |
| 16521 | maldecirá | 1 |
| 16522 | malbaratado | 1 |
| 16523 | malamente | 1 |
| 16524 | malabares | 1 |
| 16525 | majo | 1 |
| 16526 | majestuosos | 1 |
| 16527 | majas | 1 |
| 16528 | majaderías | 1 |
| 16529 | maizales | 1 |
| 16530 | maitines | 1 |
| 16531 | mainates | 1 |
| 16532 | mahoma | 1 |
| 16533 | magyares | 1 |
| 16534 | magullar | 1 |
| 16535 | mago | 1 |
| 16536 | magno | 1 |
| 16537 | magnitud | 1 |
| 16538 | magnífica | 1 |
| 16539 | magnético | 1 |
| 16540 | magnéticas | 1 |
| 16541 | magnética | 1 |
| 16542 | magnates | 1 |
| 16543 | magnanimidad | 1 |
| 16544 | magistratura | 1 |
| 16545 | magistrales | 1 |
| 16546 | maduros | 1 |
| 16547 | madurando | 1 |
| 16548 | madrugue | 1 |
| 16549 | madrugones | 1 |
| 16550 | madrugo | 1 |
| 16551 | madrugaría | 1 |
| 16552 | madrugado | 1 |
| 16553 | madrileñitos | 1 |
| 16554 | madrileñas | 1 |
| 16555 | madrigueras | 1 |
| 16556 | madrigales | 1 |
| 16557 | madrejón | 1 |
| 16558 | madrastra | 1 |
| 16559 | madona | 1 |
| 16560 | maderos | 1 |
| 16561 | maderita | 1 |
| 16562 | madeja | 1 |
| 16563 | macizo | 1 |
| 16564 | maciza | 1 |
| 16565 | macilento | 1 |
| 16566 | machacona | 1 |
| 16567 | machacan | 1 |
| 16568 | machacaba | 1 |
| 16569 | macetas | 1 |
| 16570 | macedónico | 1 |
| 16571 | macabra | 1 |
| 16572 | macabeos | 1 |
| 16573 | luzbel | 1 |
| 16574 | luys | 1 |
| 16575 | lustroso | 1 |
| 16576 | lustre | 1 |
| 16577 | lusitana | 1 |
| 16578 | lupus | 1 |
| 16579 | lunares | 1 |
| 16580 | luminosos | 1 |
| 16581 | luminosas | 1 |
| 16582 | lujosos | 1 |
| 16583 | luján | 1 |
| 16584 | lúgubres | 1 |
| 16585 | lugarón | 1 |
| 16586 | lugareñas | 1 |
| 16587 | lugarejo | 1 |
| 16588 | luenga | 1 |
| 16589 | lucubraciones | 1 |
| 16590 | lucro | 1 |
| 16591 | lucrecio | 1 |
| 16592 | lucrativa | 1 |
| 16593 | lucrar | 1 |
| 16594 | lució | 1 |
| 16595 | luciferum | 1 |
| 16596 | lucifer | 1 |
| 16597 | luciéramos | 1 |
| 16598 | luciera | 1 |
| 16599 | lucidos | 1 |
| 16600 | lucidas | 1 |
| 16601 | lucí | 1 |
| 16602 | lucho | 1 |
| 16603 | luché | 1 |
| 16604 | lucharía | 1 |
| 16605 | luchador | 1 |
| 16606 | luchaban | 1 |
| 16607 | lucero | 1 |
| 16608 | lucerna | 1 |
| 16609 | lucaaam | 1 |
| 16610 | lúbricos | 1 |
| 16611 | lubricidad | 1 |
| 16612 | lúbricas | 1 |
| 16613 | lozoya | 1 |
| 16614 | lozanías | 1 |
| 16615 | loza | 1 |
| 16616 | lovelace | 1 |
| 16617 | lote | 1 |
| 16618 | lot | 1 |
| 16619 | losas | 1 |
| 16620 | loriga | 1 |
| 16621 | loquitur | 1 |
| 16622 | loquillo | 1 |
| 16623 | loquillas | 1 |
| 16624 | loquilla | 1 |
| 16625 | lonjas | 1 |
| 16626 | longevidad | 1 |
| 16627 | longanizas | 1 |
| 16628 | logrando | 1 |
| 16629 | lograba | 1 |
| 16630 | logomaquias | 1 |
| 16631 | lodazales | 1 |
| 16632 | locus | 1 |
| 16633 | localidad | 1 |
| 16634 | lóbrega | 1 |
| 16635 | lobezno | 1 |
| 16636 | loable | 1 |
| 16637 | llovió | 1 |
| 16638 | lloviera | 1 |
| 16639 | lloviendo | 1 |
| 16640 | llorón | 1 |
| 16641 | lloriqueando | 1 |
| 16642 | lloréis | 1 |
| 16643 | lloraría | 1 |
| 16644 | lloraré | 1 |
| 16645 | llorará | 1 |
| 16646 | llora | 1 |
| 16647 | lleve | 1 |
| 16648 | llevarnos | 1 |
| 16649 | llevármela | 1 |
| 16650 | llevarlo | 1 |
| 16651 | llevarles | 1 |
| 16652 | llevaré | 1 |
| 16653 | llevarás | 1 |
| 16654 | llevarán | 1 |
| 16655 | llevándoselo | 1 |
| 16656 | llevándose | 1 |
| 16657 | llevan | 1 |
| 16658 | llévame | 1 |
| 16659 | llevados | 1 |
| 16660 | llevadas | 1 |
| 16661 | llevada | 1 |
| 16662 | llenen | 1 |
| 16663 | llenaría | 1 |
| 16664 | llenará | 1 |
| 16665 | llenándole | 1 |
| 16666 | lleguemos | 1 |
| 16667 | llegasen | 1 |
| 16668 | llegarían | 1 |
| 16669 | llegaremos | 1 |
| 16670 | llegaré | 1 |
| 16671 | llanuras | 1 |
| 16672 | llanura | 1 |
| 16673 | llaneza | 1 |
| 16674 | llamen | 1 |
| 16675 | llamémosle | 1 |
| 16676 | llámelo | 1 |
| 16677 | llamé | 1 |
| 16678 | llamativos | 1 |
| 16679 | llamativa | 1 |
| 16680 | llamárselo | 1 |
| 16681 | llamarnos | 1 |
| 16682 | llamarlo | 1 |
| 16683 | llamarlas | 1 |
| 16684 | llamaremos | 1 |
| 16685 | llamarán | 1 |
| 16686 | llamaran | 1 |
| 16687 | llamará | 1 |
| 16688 | llamara | 1 |
| 16689 | llamándolos | 1 |
| 16690 | llaga | 1 |
| 16691 | liviana | 1 |
| 16692 | litigantes | 1 |
| 16693 | literato | 1 |
| 16694 | listillas | 1 |
| 16695 | listado | 1 |
| 16696 | lisonjera | 1 |
| 16697 | lisonjeado | 1 |
| 16698 | lisonjea | 1 |
| 16699 | lisa | 1 |
| 16700 | líricamente | 1 |
| 16701 | lírica | 1 |
| 16702 | líquida | 1 |
| 16703 | liquen | 1 |
| 16704 | liquefacta | 1 |
| 16705 | lionense | 1 |
| 16706 | lío | 1 |
| 16707 | linfas | 1 |
| 16708 | línea | 1 |
| 16709 | lindoro | 1 |
| 16710 | linajudas | 1 |
| 16711 | limpios | 1 |
| 16712 | límpido | 1 |
| 16713 | límpida | 1 |
| 16714 | limpiaron | 1 |
| 16715 | limpiarle | 1 |
| 16716 | limpiándose | 1 |
| 16717 | limones | 1 |
| 16718 | limón | 1 |
| 16719 | limítrofe | 1 |
| 16720 | limitarse | 1 |
| 16721 | limitada | 1 |
| 16722 | limitaban | 1 |
| 16723 | limbo | 1 |
| 16724 | ligeros | 1 |
| 16725 | ligereza | 1 |
| 16726 | ligamen | 1 |
| 16727 | ligaduras | 1 |
| 16728 | ligados | 1 |
| 16729 | life | 1 |
| 16730 | liebre | 1 |
| 16731 | lidiaba | 1 |
| 16732 | licenciarse | 1 |
| 16733 | licenciados | 1 |
| 16734 | librerías | 1 |
| 16735 | librepensamiento | 1 |
| 16736 | librepensador | 1 |
| 16737 | librasen | 1 |
| 16738 | libras | 1 |
| 16739 | librara | 1 |
| 16740 | libraco | 1 |
| 16741 | liberté | 1 |
| 16742 | libelo | 1 |
| 16743 | libellus | 1 |
| 16744 | leyeron | 1 |
| 16745 | levítica | 1 |
| 16746 | levantisca | 1 |
| 16747 | levántate | 1 |
| 16748 | levantaría | 1 |
| 16749 | levantara | 1 |
| 16750 | levantados | 1 |
| 16751 | leva | 1 |
| 16752 | letargo | 1 |
| 16753 | letanía | 1 |
| 16754 | lesiones | 1 |
| 16755 | lesión | 1 |
| 16756 | lesbos | 1 |
| 16757 | leproso | 1 |
| 16758 | leonor | 1 |
| 16759 | leones | 1 |
| 16760 | leonardo | 1 |
| 16761 | lentos | 1 |
| 16762 | lento | 1 |
| 16763 | lentejas | 1 |
| 16764 | lenidad | 1 |
| 16765 | lengüetería | 1 |
| 16766 | lenclós | 1 |
| 16767 | lema | 1 |
| 16768 | lego | 1 |
| 16769 | legislación | 1 |
| 16770 | legendarios | 1 |
| 16771 | lege | 1 |
| 16772 | legalmente | 1 |
| 16773 | lees | 1 |
| 16774 | leerse | 1 |
| 16775 | leerme | 1 |
| 16776 | leen | 1 |
| 16777 | léela | 1 |
| 16778 | lectora | 1 |
| 16779 | lechuguinos | 1 |
| 16780 | lechuga | 1 |
| 16781 | lechoso | 1 |
| 16782 | lechosa | 1 |
| 16783 | leccioncita | 1 |
| 16784 | lebrun | 1 |
| 16785 | léanla | 1 |
| 16786 | leal | 1 |
| 16787 | laxitud | 1 |
| 16788 | lavó | 1 |
| 16789 | lavarse | 1 |
| 16790 | lavaron | 1 |
| 16791 | lavadas | 1 |
| 16792 | lavaban | 1 |
| 16793 | laurent | 1 |
| 16794 | laudes | 1 |
| 16795 | laudatores | 1 |
| 16796 | latorre | 1 |
| 16797 | latitudinario | 1 |
| 16798 | latió | 1 |
| 16799 | latigazo | 1 |
| 16800 | latieron | 1 |
| 16801 | latía | 1 |
| 16802 | lateral | 1 |
| 16803 | late | 1 |
| 16804 | lastimosa | 1 |
| 16805 | lastimero | 1 |
| 16806 | lastimarla | 1 |
| 16807 | lastimara | 1 |
| 16808 | lastimar | 1 |
| 16809 | lastimada | 1 |
| 16810 | lastimaban | 1 |
| 16811 | lastimaba | 1 |
| 16812 | lastima | 1 |
| 16813 | lascivos | 1 |
| 16814 | larguísima | 1 |
| 16815 | largarse | 1 |
| 16816 | largamente | 1 |
| 16817 | lanzó | 1 |
| 16818 | lanzándose | 1 |
| 16819 | lanzaba | 1 |
| 16820 | lanza | 1 |
| 16821 | lante | 1 |
| 16822 | lánguidos | 1 |
| 16823 | lánguido | 1 |
| 16824 | languidecer | 1 |
| 16825 | lánguidas | 1 |
| 16826 | lánguidamente | 1 |
| 16827 | landó | 1 |
| 16828 | lanchas | 1 |
| 16829 | lancha | 1 |
| 16830 | láncese | 1 |
| 16831 | lampiño | 1 |
| 16832 | lamparilla | 1 |
| 16833 | laminada | 1 |
| 16834 | lamiéndose | 1 |
| 16835 | lamiendo | 1 |
| 16836 | lamidas | 1 |
| 16837 | lamía | 1 |
| 16838 | lamería | 1 |
| 16839 | lamento | 1 |
| 16840 | lamentaron | 1 |
| 16841 | lamentando | 1 |
| 16842 | lamentamos | 1 |
| 16843 | lamentable | 1 |
| 16844 | lamenta | 1 |
| 16845 | lamego | 1 |
| 16846 | lamartine | 1 |
| 16847 | laicos | 1 |
| 16848 | lagarto | 1 |
| 16849 | lagar | 1 |
| 16850 | ladre | 1 |
| 16851 | ladrar | 1 |
| 16852 | lacrimosa | 1 |
| 16853 | lacrimae | 1 |
| 16854 | lacónico | 1 |
| 16855 | lacónicas | 1 |
| 16856 | lacónica | 1 |
| 16857 | lacería | 1 |
| 16858 | labriegos | 1 |
| 16859 | labranza | 1 |
| 16860 | labrado | 1 |
| 16861 | labraba | 1 |
| 16862 | laboriosa | 1 |
| 16863 | laberintos | 1 |
| 16864 | labe | 1 |
| 16865 | kock | 1 |
| 16866 | kirschen | 1 |
| 16867 | kilómetro | 1 |
| 16868 | juzgarse | 1 |
| 16869 | juzgando | 1 |
| 16870 | juzgada | 1 |
| 16871 | juzgaban | 1 |
| 16872 | justillo | 1 |
| 16873 | justificar | 1 |
| 16874 | justificables | 1 |
| 16875 | justas | 1 |
| 16876 | jurisconsultos | 1 |
| 16877 | juris | 1 |
| 16878 | jurídico | 1 |
| 16879 | juremos | 1 |
| 16880 | jure | 1 |
| 16881 | juraste | 1 |
| 16882 | jurarse | 1 |
| 16883 | jurarle | 1 |
| 16884 | jurándose | 1 |
| 16885 | júramelo | 1 |
| 16886 | jurados | 1 |
| 16887 | jurada | 1 |
| 16888 | juraban | 1 |
| 16889 | junturas | 1 |
| 16890 | juntaran | 1 |
| 16891 | juntado | 1 |
| 16892 | juntaba | 1 |
| 16893 | juncos | 1 |
| 16894 | juicios | 1 |
| 16895 | juguetona | 1 |
| 16896 | jugueteando | 1 |
| 16897 | jugueteaban | 1 |
| 16898 | jugo | 1 |
| 16899 | jugándose | 1 |
| 16900 | jugáis | 1 |
| 16901 | jugábamos | 1 |
| 16902 | juegan | 1 |
| 16903 | judit | 1 |
| 16904 | judíos | 1 |
| 16905 | jubileos | 1 |
| 16906 | jubilé | 1 |
| 16907 | joyero | 1 |
| 16908 | jovialidad | 1 |
| 16909 | jovellanos | 1 |
| 16910 | jota | 1 |
| 16911 | jorobado | 1 |
| 16912 | jornaleros | 1 |
| 16913 | jornal | 1 |
| 16914 | jónico | 1 |
| 16915 | jofaina | 1 |
| 16916 | jocoso | 1 |
| 16917 | jocoserio | 1 |
| 16918 | jirones | 1 |
| 16919 | jirón | 1 |
| 16920 | jinojo | 1 |
| 16921 | jícara | 1 |
| 16922 | jesuítica | 1 |
| 16923 | jerusalén | 1 |
| 16924 | jerusalem | 1 |
| 16925 | jeroma | 1 |
| 16926 | jericó | 1 |
| 16927 | jerga | 1 |
| 16928 | jeremías | 1 |
| 16929 | jerárquicos | 1 |
| 16930 | jehová | 1 |
| 16931 | jazmín | 1 |
| 16932 | jaropes | 1 |
| 16933 | jardineros | 1 |
| 16934 | jardinero | 1 |
| 16935 | jardineras | 1 |
| 16936 | jarana | 1 |
| 16937 | japón | 1 |
| 16938 | jamones | 1 |
| 16939 | jamón | 1 |
| 16940 | jaleadores | 1 |
| 16941 | jaime | 1 |
| 16942 | jadeantes | 1 |
| 16943 | jactancioso | 1 |
| 16944 | jactanciosa | 1 |
| 16945 | jaco | 1 |
| 16946 | jaccoud | 1 |
| 16947 | jacas | 1 |
| 16948 | jabalíes | 1 |
| 16949 | j | 1 |
| 16950 | izquierdo | 1 |
| 16951 | ix | 1 |
| 16952 | iv | 1 |
| 16953 | ítem | 1 |
| 16954 | israelitas | 1 |
| 16955 | israel | 1 |
| 16956 | islote | 1 |
| 16957 | islas | 1 |
| 16958 | isis | 1 |
| 16959 | is | 1 |
| 16960 | irrupciones | 1 |
| 16961 | irritó | 1 |
| 16962 | irritarla | 1 |
| 16963 | irritar | 1 |
| 16964 | irritados | 1 |
| 16965 | irritación | 1 |
| 16966 | irritabilidad | 1 |
| 16967 | irrita | 1 |
| 16968 | irrisión | 1 |
| 16969 | irreverentes | 1 |
| 16970 | irresponsabilidad | 1 |
| 16971 | irreprochable | 1 |
| 16972 | irremisiblemente | 1 |
| 16973 | irremediables | 1 |
| 16974 | irremediable | 1 |
| 16975 | irregularidades | 1 |
| 16976 | irreflexivas | 1 |
| 16977 | irreflexivamente | 1 |
| 16978 | irradiaba | 1 |
| 16979 | irracionales | 1 |
| 16980 | irónicos | 1 |
| 16981 | irónico | 1 |
| 16982 | ironías | 1 |
| 16983 | irisados | 1 |
| 16984 | iria | 1 |
| 16985 | irás | 1 |
| 16986 | irá | 1 |
| 16987 | ipsa | 1 |
| 16988 | io | 1 |
| 16989 | involucremos | 1 |
| 16990 | invitó | 1 |
| 16991 | invitarle | 1 |
| 16992 | invitarla | 1 |
| 16993 | invitar | 1 |
| 16994 | invitándole | 1 |
| 16995 | invitando | 1 |
| 16996 | invita | 1 |
| 16997 | invirtieron | 1 |
| 16998 | inveterado | 1 |
| 16999 | inveteradas | 1 |
| 17000 | investigar | 1 |
| 17001 | invernante | 1 |
| 17002 | invernadero | 1 |
| 17003 | invernáculo | 1 |
| 17004 | inventor | 1 |
| 17005 | inventó | 1 |
| 17006 | inventaron | 1 |
| 17007 | inventario | 1 |
| 17008 | inventados | 1 |
| 17009 | inventaban | 1 |
| 17010 | invenciones | 1 |
| 17011 | invasores | 1 |
| 17012 | invasor | 1 |
| 17013 | invasiones | 1 |
| 17014 | invariablemente | 1 |
| 17015 | inválido | 1 |
| 17016 | inválidas | 1 |
| 17017 | invadieron | 1 |
| 17018 | invadida | 1 |
| 17019 | invadían | 1 |
| 17020 | invadía | 1 |
| 17021 | inusitadas | 1 |
| 17022 | inundarle | 1 |
| 17023 | inundara | 1 |
| 17024 | inundar | 1 |
| 17025 | intuiciones | 1 |
| 17026 | intuición | 1 |
| 17027 | intrusos | 1 |
| 17028 | intrusa | 1 |
| 17029 | introduzcan | 1 |
| 17030 | introdujese | 1 |
| 17031 | introducir | 1 |
| 17032 | introduciendo | 1 |
| 17033 | introducido | 1 |
| 17034 | intrincados | 1 |
| 17035 | intrigantes | 1 |
| 17036 | intrigado | 1 |
| 17037 | intrépidas | 1 |
| 17038 | intransigentes | 1 |
| 17039 | intranquilo | 1 |
| 17040 | intranquila | 1 |
| 17041 | intimó | 1 |
| 17042 | intimo | 1 |
| 17043 | intimidades | 1 |
| 17044 | intimarle | 1 |
| 17045 | intimaba | 1 |
| 17046 | intestinal | 1 |
| 17047 | intervinieran | 1 |
| 17048 | intervenido | 1 |
| 17049 | intervenía | 1 |
| 17050 | intersticios | 1 |
| 17051 | interrumpirla | 1 |
| 17052 | interrumpieron | 1 |
| 17053 | interrumpiera | 1 |
| 17054 | interrumpiéndole | 1 |
| 17055 | interrumpida | 1 |
| 17056 | interrumpen | 1 |
| 17057 | interrumpas | 1 |
| 17058 | interrogatorios | 1 |
| 17059 | interrogatorio | 1 |
| 17060 | interrogarle | 1 |
| 17061 | interrogante | 1 |
| 17062 | interpretó | 1 |
| 17063 | intérprete | 1 |
| 17064 | interpretar | 1 |
| 17065 | interpretación | 1 |
| 17066 | interponiendo | 1 |
| 17067 | intermitentes | 1 |
| 17068 | interlocutores | 1 |
| 17069 | interjecciones | 1 |
| 17070 | interioridades | 1 |
| 17071 | interinos | 1 |
| 17072 | interino | 1 |
| 17073 | interinas | 1 |
| 17074 | interinamente | 1 |
| 17075 | interesarse | 1 |
| 17076 | interesarla | 1 |
| 17077 | intercolumnios | 1 |
| 17078 | intercolumnio | 1 |
| 17079 | interceptado | 1 |
| 17080 | interceptaban | 1 |
| 17081 | intentona | 1 |
| 17082 | intenté | 1 |
| 17083 | intentaré | 1 |
| 17084 | intentado | 1 |
| 17085 | intentaban | 1 |
| 17086 | intenta | 1 |
| 17087 | intensas | 1 |
| 17088 | intensamente | 1 |
| 17089 | intendente | 1 |
| 17090 | intende | 1 |
| 17091 | intencionados | 1 |
| 17092 | intempestivo | 1 |
| 17093 | intellectu | 1 |
| 17094 | inteligentes | 1 |
| 17095 | íntegro | 1 |
| 17096 | integrar | 1 |
| 17097 | integrante | 1 |
| 17098 | integral | 1 |
| 17099 | intacta | 1 |
| 17100 | intachables | 1 |
| 17101 | insurrectos | 1 |
| 17102 | insultó | 1 |
| 17103 | insultara | 1 |
| 17104 | insultando | 1 |
| 17105 | insulsos | 1 |
| 17106 | insulsez | 1 |
| 17107 | insulsas | 1 |
| 17108 | insulsa | 1 |
| 17109 | instrumentista | 1 |
| 17110 | instruidas | 1 |
| 17111 | instrucciones | 1 |
| 17112 | instó | 1 |
| 17113 | instituto | 1 |
| 17114 | instigara | 1 |
| 17115 | instantáneo | 1 |
| 17116 | instantánea | 1 |
| 17117 | instancia | 1 |
| 17118 | instalar | 1 |
| 17119 | inspire | 1 |
| 17120 | inspirarse | 1 |
| 17121 | inspirará | 1 |
| 17122 | inspiran | 1 |
| 17123 | inspirados | 1 |
| 17124 | inspiraciones | 1 |
| 17125 | insoportables | 1 |
| 17126 | insomnios | 1 |
| 17127 | insomnio | 1 |
| 17128 | insólito | 1 |
| 17129 | insolenta | 1 |
| 17130 | insolencias | 1 |
| 17131 | insistimos | 1 |
| 17132 | insistieron | 1 |
| 17133 | insistiendo | 1 |
| 17134 | insistido | 1 |
| 17135 | insisten | 1 |
| 17136 | insinuó | 1 |
| 17137 | insinuar | 1 |
| 17138 | insinuado | 1 |
| 17139 | insignificancia | 1 |
| 17140 | insidiosos | 1 |
| 17141 | inservible | 1 |
| 17142 | insertar | 1 |
| 17143 | inseparables | 1 |
| 17144 | inseparable | 1 |
| 17145 | insensato | 1 |
| 17146 | insectos | 1 |
| 17147 | insecto | 1 |
| 17148 | inquisidores | 1 |
| 17149 | inquisición | 1 |
| 17150 | inquirió | 1 |
| 17151 | inquilinos | 1 |
| 17152 | inquietarle | 1 |
| 17153 | inquietaban | 1 |
| 17154 | inquieta | 1 |
| 17155 | inoportunos | 1 |
| 17156 | inoportunamente | 1 |
| 17157 | inoportuna | 1 |
| 17158 | inopinado | 1 |
| 17159 | inocentadas | 1 |
| 17160 | innumerables | 1 |
| 17161 | innovador | 1 |
| 17162 | innovación | 1 |
| 17163 | innobles | 1 |
| 17164 | innata | 1 |
| 17165 | inmundas | 1 |
| 17166 | inmovilidad | 1 |
| 17167 | inmoralidad | 1 |
| 17168 | inmodestia | 1 |
| 17169 | inmediaciones | 1 |
| 17170 | inmaculados | 1 |
| 17171 | inmaculado | 1 |
| 17172 | injustísima | 1 |
| 17173 | injuriosas | 1 |
| 17174 | injertos | 1 |
| 17175 | injerto | 1 |
| 17176 | injerencias | 1 |
| 17177 | inició | 1 |
| 17178 | iniciarse | 1 |
| 17179 | iniciales | 1 |
| 17180 | inicial | 1 |
| 17181 | iniciado | 1 |
| 17182 | iniciadas | 1 |
| 17183 | iniciación | 1 |
| 17184 | inhibirse | 1 |
| 17185 | inhibía | 1 |
| 17186 | ingresos | 1 |
| 17187 | ingresamos | 1 |
| 17188 | ingratos | 1 |
| 17189 | ingenuos | 1 |
| 17190 | ingenuo | 1 |
| 17191 | ingenuidad | 1 |
| 17192 | ingenuas | 1 |
| 17193 | ingenuamente | 1 |
| 17194 | ingenua | 1 |
| 17195 | ingénitos | 1 |
| 17196 | ingénita | 1 |
| 17197 | ingenieros | 1 |
| 17198 | ingeniara | 1 |
| 17199 | infusorios | 1 |
| 17200 | infundía | 1 |
| 17201 | infundan | 1 |
| 17202 | infructuosa | 1 |
| 17203 | infringir | 1 |
| 17204 | infraganti | 1 |
| 17205 | infracción | 1 |
| 17206 | informes | 1 |
| 17207 | informe | 1 |
| 17208 | influyó | 1 |
| 17209 | influido | 1 |
| 17210 | influencias | 1 |
| 17211 | inflexiones | 1 |
| 17212 | inflexibles | 1 |
| 17213 | inflamable | 1 |
| 17214 | inflados | 1 |
| 17215 | inflaba | 1 |
| 17216 | infinitas | 1 |
| 17217 | infestarse | 1 |
| 17218 | infestado | 1 |
| 17219 | inferiores | 1 |
| 17220 | infecundos | 1 |
| 17221 | infausta | 1 |
| 17222 | infatigable | 1 |
| 17223 | infantería | 1 |
| 17224 | infante | 1 |
| 17225 | infamias | 1 |
| 17226 | infamatorio | 1 |
| 17227 | infalibidad | 1 |
| 17228 | infali | 1 |
| 17229 | inextinguible | 1 |
| 17230 | inexplicable | 1 |
| 17231 | inexpertos | 1 |
| 17232 | inexperto | 1 |
| 17233 | inesperados | 1 |
| 17234 | inesperadas | 1 |
| 17235 | inescrutables | 1 |
| 17236 | inertes | 1 |
| 17237 | inequívocas | 1 |
| 17238 | ineludible | 1 |
| 17239 | indumentario | 1 |
| 17240 | indómitos | 1 |
| 17241 | indomable | 1 |
| 17242 | individuos | 1 |
| 17243 | indispensables | 1 |
| 17244 | indiscutibles | 1 |
| 17245 | indiscutible | 1 |
| 17246 | indiscretos | 1 |
| 17247 | indiscretas | 1 |
| 17248 | indisciplinado | 1 |
| 17249 | indiqué | 1 |
| 17250 | indique | 1 |
| 17251 | indios | 1 |
| 17252 | indino | 1 |
| 17253 | indignos | 1 |
| 17254 | indignas | 1 |
| 17255 | indignaría | 1 |
| 17256 | indignamente | 1 |
| 17257 | indignaban | 1 |
| 17258 | indignaba | 1 |
| 17259 | indígena | 1 |
| 17260 | indicó | 1 |
| 17261 | indicarse | 1 |
| 17262 | indicaron | 1 |
| 17263 | indicarán | 1 |
| 17264 | indicando | 1 |
| 17265 | indicado | 1 |
| 17266 | indica | 1 |
| 17267 | indescifrable | 1 |
| 17268 | indemnizaciones | 1 |
| 17269 | indefinidos | 1 |
| 17270 | indefenso | 1 |
| 17271 | indecorosas | 1 |
| 17272 | indecisa | 1 |
| 17273 | indecible | 1 |
| 17274 | indecentes | 1 |
| 17275 | indecencias | 1 |
| 17276 | indecencia | 1 |
| 17277 | indagadas | 1 |
| 17278 | incurrir | 1 |
| 17279 | incurría | 1 |
| 17280 | incuria | 1 |
| 17281 | incurables | 1 |
| 17282 | incumbencia | 1 |
| 17283 | inculcará | 1 |
| 17284 | incrustadas | 1 |
| 17285 | incrusta | 1 |
| 17286 | incruentos | 1 |
| 17287 | incruentas | 1 |
| 17288 | increíble | 1 |
| 17289 | incredulidad | 1 |
| 17290 | incorruptible | 1 |
| 17291 | incorregible | 1 |
| 17292 | incorrecto | 1 |
| 17293 | incorrectas | 1 |
| 17294 | incorrecta | 1 |
| 17295 | incorporó | 1 |
| 17296 | incorporada | 1 |
| 17297 | incorporaban | 1 |
| 17298 | inconveniencia | 1 |
| 17299 | incontrastable | 1 |
| 17300 | inconstancia | 1 |
| 17301 | inconsolable | 1 |
| 17302 | inconscientes | 1 |
| 17303 | inconfesables | 1 |
| 17304 | inconexos | 1 |
| 17305 | incompatible | 1 |
| 17306 | incompatibilidades | 1 |
| 17307 | incomparables | 1 |
| 17308 | incomparablemente | 1 |
| 17309 | incomodo | 1 |
| 17310 | incomodidades | 1 |
| 17311 | incomodidad | 1 |
| 17312 | incomodarme | 1 |
| 17313 | incomodada | 1 |
| 17314 | incomodaba | 1 |
| 17315 | incombustible | 1 |
| 17316 | incoherentes | 1 |
| 17317 | incoherente | 1 |
| 17318 | incoherencia | 1 |
| 17319 | inclinan | 1 |
| 17320 | inclinados | 1 |
| 17321 | inclinaban | 1 |
| 17322 | incisos | 1 |
| 17323 | inciertos | 1 |
| 17324 | incierta | 1 |
| 17325 | incentivos | 1 |
| 17326 | incensario | 1 |
| 17327 | incendio | 1 |
| 17328 | incendiada | 1 |
| 17329 | incautos | 1 |
| 17330 | incauto | 1 |
| 17331 | incasables | 1 |
| 17332 | incalificables | 1 |
| 17333 | incalculable | 1 |
| 17334 | inauguró | 1 |
| 17335 | inauguren | 1 |
| 17336 | inaugurar | 1 |
| 17337 | inauguraban | 1 |
| 17338 | inaudito | 1 |
| 17339 | inaudita | 1 |
| 17340 | inarticulada | 1 |
| 17341 | inarco | 1 |
| 17342 | inapreciable | 1 |
| 17343 | inapetencias | 1 |
| 17344 | inanimados | 1 |
| 17345 | inanición | 1 |
| 17346 | inalienables | 1 |
| 17347 | inaguantable | 1 |
| 17348 | inadvertencia | 1 |
| 17349 | inacabable | 1 |
| 17350 | imputaban | 1 |
| 17351 | impusiese | 1 |
| 17352 | impusieron | 1 |
| 17353 | impusiera | 1 |
| 17354 | impuse | 1 |
| 17355 | impureza | 1 |
| 17356 | impura | 1 |
| 17357 | impune | 1 |
| 17358 | impulsan | 1 |
| 17359 | impuesta | 1 |
| 17360 | impúdicas | 1 |
| 17361 | improvisaron | 1 |
| 17362 | improvisados | 1 |
| 17363 | improvisada | 1 |
| 17364 | improvisación | 1 |
| 17365 | improvisaban | 1 |
| 17366 | improvisa | 1 |
| 17367 | impropias | 1 |
| 17368 | impropiamente | 1 |
| 17369 | improperios | 1 |
| 17370 | ímprobo | 1 |
| 17371 | imprimían | 1 |
| 17372 | impreso | 1 |
| 17373 | impresionables | 1 |
| 17374 | impresionaban | 1 |
| 17375 | impresiona | 1 |
| 17376 | imprescindible | 1 |
| 17377 | impresas | 1 |
| 17378 | impregnado | 1 |
| 17379 | imprecaciones | 1 |
| 17380 | imprecaba | 1 |
| 17381 | impotente | 1 |
| 17382 | impotencia | 1 |
| 17383 | impostura | 1 |
| 17384 | imposición | 1 |
| 17385 | imposibilidad | 1 |
| 17386 | importunase | 1 |
| 17387 | importó | 1 |
| 17388 | importasen | 1 |
| 17389 | importarle | 1 |
| 17390 | importará | 1 |
| 17391 | importantísimo | 1 |
| 17392 | importan | 1 |
| 17393 | importadores | 1 |
| 17394 | importado | 1 |
| 17395 | imponían | 1 |
| 17396 | impongan | 1 |
| 17397 | imponerse | 1 |
| 17398 | imponerme | 1 |
| 17399 | imponerle | 1 |
| 17400 | imponer | 1 |
| 17401 | imponentes | 1 |
| 17402 | imponen | 1 |
| 17403 | imploro | 1 |
| 17404 | implícito | 1 |
| 17405 | implícitas | 1 |
| 17406 | implacables | 1 |
| 17407 | impidió | 1 |
| 17408 | impidiesen | 1 |
| 17409 | impidiera | 1 |
| 17410 | impide | 1 |
| 17411 | impías | 1 |
| 17412 | ímpetus | 1 |
| 17413 | impertinencias | 1 |
| 17414 | impermeable | 1 |
| 17415 | imperiosos | 1 |
| 17416 | imperioso | 1 |
| 17417 | imperiosas | 1 |
| 17418 | impericia | 1 |
| 17419 | imperiales | 1 |
| 17420 | imperceptible | 1 |
| 17421 | imperativo | 1 |
| 17422 | imperando | 1 |
| 17423 | impedirlos | 1 |
| 17424 | impedirlo | 1 |
| 17425 | impedirle | 1 |
| 17426 | impedir | 1 |
| 17427 | impedido | 1 |
| 17428 | impecable | 1 |
| 17429 | imparcial | 1 |
| 17430 | impacientes | 1 |
| 17431 | imitarse | 1 |
| 17432 | imitara | 1 |
| 17433 | imita | 1 |
| 17434 | imbuirlas | 1 |
| 17435 | imbécil | 1 |
| 17436 | imantada | 1 |
| 17437 | imanes | 1 |
| 17438 | imán | 1 |
| 17439 | imagínole | 1 |
| 17440 | imaginativos | 1 |
| 17441 | imaginarse | 1 |
| 17442 | imaginarlo | 1 |
| 17443 | imaginarla | 1 |
| 17444 | imaginarios | 1 |
| 17445 | imaginada | 1 |
| 17446 | imaginaciones | 1 |
| 17447 | ilustrarse | 1 |
| 17448 | ilustradas | 1 |
| 17449 | ilusos | 1 |
| 17450 | ilusorios | 1 |
| 17451 | iluminó | 1 |
| 17452 | iluminarme | 1 |
| 17453 | iluminados | 1 |
| 17454 | iluminado | 1 |
| 17455 | iluminaba | 1 |
| 17456 | ilumina | 1 |
| 17457 | ilmo | 1 |
| 17458 | iliteratas | 1 |
| 17459 | ilíada | 1 |
| 17460 | ilegítima | 1 |
| 17461 | ilegibles | 1 |
| 17462 | ilegal | 1 |
| 17463 | iguale | 1 |
| 17464 | igualdades | 1 |
| 17465 | ignore | 1 |
| 17466 | ignoraría | 1 |
| 17467 | ignorantes | 1 |
| 17468 | ignorada | 1 |
| 17469 | ignora | 1 |
| 17470 | idilio | 1 |
| 17471 | idénticos | 1 |
| 17472 | idéntica | 1 |
| 17473 | idealizar | 1 |
| 17474 | id | 1 |
| 17475 | ictericia | 1 |
| 17476 | íberos | 1 |
| 17477 | ibérica | 1 |
| 17478 | huyes | 1 |
| 17479 | huyeron | 1 |
| 17480 | huyen | 1 |
| 17481 | hurtos | 1 |
| 17482 | hurtado | 1 |
| 17483 | hurgaba | 1 |
| 17484 | hundió | 1 |
| 17485 | hundimos | 1 |
| 17486 | hundidas | 1 |
| 17487 | hundíamos | 1 |
| 17488 | humour | 1 |
| 17489 | humorístico | 1 |
| 17490 | humorísticas | 1 |
| 17491 | humorística | 1 |
| 17492 | humorado | 1 |
| 17493 | humilló | 1 |
| 17494 | humíllate | 1 |
| 17495 | humillaría | 1 |
| 17496 | humillante | 1 |
| 17497 | humillación | 1 |
| 17498 | humedecerse | 1 |
| 17499 | humedecer | 1 |
| 17500 | humeante | 1 |
| 17501 | humanizada | 1 |
| 17502 | humanizaban | 1 |
| 17503 | humanitarias | 1 |
| 17504 | humanidades | 1 |
| 17505 | humani | 1 |
| 17506 | huiría | 1 |
| 17507 | huían | 1 |
| 17508 | hugonotes | 1 |
| 17509 | hugo | 1 |
| 17510 | huevo | 1 |
| 17511 | huevecillo | 1 |
| 17512 | huestes | 1 |
| 17513 | huésped | 1 |
| 17514 | huesca | 1 |
| 17515 | huertos | 1 |
| 17516 | huérfanas | 1 |
| 17517 | huelo | 1 |
| 17518 | hueles | 1 |
| 17519 | huela | 1 |
| 17520 | hubieras | 1 |
| 17521 | hoz | 1 |
| 17522 | hoteles | 1 |
| 17523 | hostilidades | 1 |
| 17524 | hostia | 1 |
| 17525 | hospitalidad | 1 |
| 17526 | hospicios | 1 |
| 17527 | hospiciano | 1 |
| 17528 | horticultura | 1 |
| 17529 | horteras | 1 |
| 17530 | hortelano | 1 |
| 17531 | hortaliza | 1 |
| 17532 | horrorosas | 1 |
| 17533 | horriblemente | 1 |
| 17534 | hormigueo | 1 |
| 17535 | hormigas | 1 |
| 17536 | hormiga | 1 |
| 17537 | horchaterías | 1 |
| 17538 | horchata | 1 |
| 17539 | horada | 1 |
| 17540 | honrosa | 1 |
| 17541 | honrar | 1 |
| 17542 | honrando | 1 |
| 17543 | honradamente | 1 |
| 17544 | honraba | 1 |
| 17545 | honorario | 1 |
| 17546 | honni | 1 |
| 17547 | hongos | 1 |
| 17548 | hongo | 1 |
| 17549 | honestidad | 1 |
| 17550 | honestamente | 1 |
| 17551 | honduras | 1 |
| 17552 | hondos | 1 |
| 17553 | hondonadas | 1 |
| 17554 | hondamente | 1 |
| 17555 | homini | 1 |
| 17556 | homero | 1 |
| 17557 | hombrunas | 1 |
| 17558 | hombruna | 1 |
| 17559 | hombreándose | 1 |
| 17560 | holgazanes | 1 |
| 17561 | holgazanería | 1 |
| 17562 | holgadamente | 1 |
| 17563 | holgada | 1 |
| 17564 | hojaldres | 1 |
| 17565 | hogares | 1 |
| 17566 | hodie | 1 |
| 17567 | hocico | 1 |
| 17568 | hita | 1 |
| 17569 | histerismo | 1 |
| 17570 | histérica | 1 |
| 17571 | hiriese | 1 |
| 17572 | hipotéticos | 1 |
| 17573 | hipotérmico | 1 |
| 17574 | hipotecada | 1 |
| 17575 | hipopótamos | 1 |
| 17576 | hipódromos | 1 |
| 17577 | hiperbólicas | 1 |
| 17578 | hiperbólicamente | 1 |
| 17579 | hiperbólica | 1 |
| 17580 | hinojos | 1 |
| 17581 | hinchó | 1 |
| 17582 | hinchazón | 1 |
| 17583 | hincaba | 1 |
| 17584 | himnos | 1 |
| 17585 | hilaba | 1 |
| 17586 | hijuelos | 1 |
| 17587 | higuera | 1 |
| 17588 | higiénicos | 1 |
| 17589 | high | 1 |
| 17590 | hígado | 1 |
| 17591 | hierros | 1 |
| 17592 | hierocrático | 1 |
| 17593 | hierbas | 1 |
| 17594 | hielos | 1 |
| 17595 | hidra | 1 |
| 17596 | hidalga | 1 |
| 17597 | hiciste | 1 |
| 17598 | hic | 1 |
| 17599 | heterogéneos | 1 |
| 17600 | heterogénea | 1 |
| 17601 | hervir | 1 |
| 17602 | herreros | 1 |
| 17603 | herrar | 1 |
| 17604 | herradura | 1 |
| 17605 | herpéticos | 1 |
| 17606 | heroísmo | 1 |
| 17607 | heroicidad | 1 |
| 17608 | herodías | 1 |
| 17609 | hermanitos | 1 |
| 17610 | herirle | 1 |
| 17611 | heridos | 1 |
| 17612 | herían | 1 |
| 17613 | hería | 1 |
| 17614 | heréticas | 1 |
| 17615 | herética | 1 |
| 17616 | heresiarcas | 1 |
| 17617 | heresiarca | 1 |
| 17618 | heredar | 1 |
| 17619 | heredan | 1 |
| 17620 | heredad | 1 |
| 17621 | herborizando | 1 |
| 17622 | heráldica | 1 |
| 17623 | hepatitis | 1 |
| 17624 | henao | 1 |
| 17625 | hemostática | 1 |
| 17626 | heló | 1 |
| 17627 | helar | 1 |
| 17628 | helándole | 1 |
| 17629 | hegemonía | 1 |
| 17630 | hedores | 1 |
| 17631 | hediondas | 1 |
| 17632 | hechuras | 1 |
| 17633 | hechizo | 1 |
| 17634 | hazle | 1 |
| 17635 | hazaña | 1 |
| 17636 | hastía | 1 |
| 17637 | harinas | 1 |
| 17638 | harina | 1 |
| 17639 | haríamos | 1 |
| 17640 | haremos | 1 |
| 17641 | haraposa | 1 |
| 17642 | harapos | 1 |
| 17643 | harapo | 1 |
| 17644 | harán | 1 |
| 17645 | hamlet | 1 |
| 17646 | hame | 1 |
| 17647 | hambrientos | 1 |
| 17648 | hamaca | 1 |
| 17649 | hallé | 1 |
| 17650 | hallarás | 1 |
| 17651 | hallará | 1 |
| 17652 | hallándose | 1 |
| 17653 | halladas | 1 |
| 17654 | halagüeños | 1 |
| 17655 | halagasen | 1 |
| 17656 | halagaron | 1 |
| 17657 | halagada | 1 |
| 17658 | halagaban | 1 |
| 17659 | halaga | 1 |
| 17660 | hágase | 1 |
| 17661 | hagámosela | 1 |
| 17662 | hagámonos | 1 |
| 17663 | hágame | 1 |
| 17664 | haec | 1 |
| 17665 | haciéndome | 1 |
| 17666 | haciéndoles | 1 |
| 17667 | hacíale | 1 |
| 17668 | hachones | 1 |
| 17669 | hache | 1 |
| 17670 | hacha | 1 |
| 17671 | hacerte | 1 |
| 17672 | hacérsenos | 1 |
| 17673 | hacérsele | 1 |
| 17674 | hacérsela | 1 |
| 17675 | hacerlas | 1 |
| 17676 | habrías | 1 |
| 17677 | habré | 1 |
| 17678 | hablen | 1 |
| 17679 | hablasteis | 1 |
| 17680 | hablasen | 1 |
| 17681 | hablaríamos | 1 |
| 17682 | hablaran | 1 |
| 17683 | habláramos | 1 |
| 17684 | hablándose | 1 |
| 17685 | hablándole | 1 |
| 17686 | háblame | 1 |
| 17687 | hablábamos | 1 |
| 17688 | habitaron | 1 |
| 17689 | habitar | 1 |
| 17690 | habitan | 1 |
| 17691 | habitados | 1 |
| 17692 | habitado | 1 |
| 17693 | habitable | 1 |
| 17694 | habita | 1 |
| 17695 | hábilmente | 1 |
| 17696 | hábiles | 1 |
| 17697 | habiendo | 1 |
| 17698 | habíase | 1 |
| 17699 | habíanle | 1 |
| 17700 | habet | 1 |
| 17701 | habérselas | 1 |
| 17702 | haberme | 1 |
| 17703 | haberlos | 1 |
| 17704 | haberlas | 1 |
| 17705 | haberla | 1 |
| 17706 | habas | 1 |
| 17707 | guturales | 1 |
| 17708 | gutierre | 1 |
| 17709 | gutapercha | 1 |
| 17710 | gustoso | 1 |
| 17711 | gustazo | 1 |
| 17712 | gustas | 1 |
| 17713 | gustaría | 1 |
| 17714 | gusanera | 1 |
| 17715 | gulf | 1 |
| 17716 | guisar | 1 |
| 17717 | guisaban | 1 |
| 17718 | guiñando | 1 |
| 17719 | guíe | 1 |
| 17720 | guías | 1 |
| 17721 | guiar | 1 |
| 17722 | guerrero | 1 |
| 17723 | guedejas | 1 |
| 17724 | guasa | 1 |
| 17725 | guarecidos | 1 |
| 17726 | guardolo | 1 |
| 17727 | guardillas | 1 |
| 17728 | guardias | 1 |
| 17729 | guárdese | 1 |
| 17730 | guarden | 1 |
| 17731 | guardé | 1 |
| 17732 | guarde | 1 |
| 17733 | guardase | 1 |
| 17734 | guardas | 1 |
| 17735 | guardarlas | 1 |
| 17736 | guardaré | 1 |
| 17737 | guardándose | 1 |
| 17738 | guardándonos | 1 |
| 17739 | guardando | 1 |
| 17740 | guardamalletas | 1 |
| 17741 | guardados | 1 |
| 17742 | guardador | 1 |
| 17743 | guardada | 1 |
| 17744 | guapos | 1 |
| 17745 | guapetona | 1 |
| 17746 | guadalquivir | 1 |
| 17747 | gruyer | 1 |
| 17748 | grupa | 1 |
| 17749 | gruñó | 1 |
| 17750 | gruñendo | 1 |
| 17751 | gruesecillo | 1 |
| 17752 | grotescas | 1 |
| 17753 | groserías | 1 |
| 17754 | grites | 1 |
| 17755 | grillo | 1 |
| 17756 | grilletes | 1 |
| 17757 | grillete | 1 |
| 17758 | grilleras | 1 |
| 17759 | grillera | 1 |
| 17760 | grijalte | 1 |
| 17761 | grifo | 1 |
| 17762 | griegos | 1 |
| 17763 | grecia | 1 |
| 17764 | graznar | 1 |
| 17765 | graznado | 1 |
| 17766 | gravísimo | 1 |
| 17767 | gravemente | 1 |
| 17768 | grato | 1 |
| 17769 | gratis | 1 |
| 17770 | grata | 1 |
| 17771 | grasiento | 1 |
| 17772 | grasientas | 1 |
| 17773 | granujas | 1 |
| 17774 | granizada | 1 |
| 17775 | graneado | 1 |
| 17776 | grandísimos | 1 |
| 17777 | grandioso | 1 |
| 17778 | grandiosas | 1 |
| 17779 | grandilocuentes | 1 |
| 17780 | gráficas | 1 |
| 17781 | gradas | 1 |
| 17782 | grada | 1 |
| 17783 | graciosas | 1 |
| 17784 | graciosamente | 1 |
| 17785 | gozquecillo | 1 |
| 17786 | gozose | 1 |
| 17787 | gozosa | 1 |
| 17788 | gozase | 1 |
| 17789 | gozarlo | 1 |
| 17790 | gozará | 1 |
| 17791 | gozamos | 1 |
| 17792 | goza | 1 |
| 17793 | goteaban | 1 |
| 17794 | gorros | 1 |
| 17795 | gorrona | 1 |
| 17796 | gorrión | 1 |
| 17797 | gorjeos | 1 |
| 17798 | gorjeaban | 1 |
| 17799 | gordos | 1 |
| 17800 | gonzález | 1 |
| 17801 | gongorino | 1 |
| 17802 | góngora | 1 |
| 17803 | gomogga | 1 |
| 17804 | golpeó | 1 |
| 17805 | golpecito | 1 |
| 17806 | golpeaban | 1 |
| 17807 | golondrinas | 1 |
| 17808 | gollería | 1 |
| 17809 | golfos | 1 |
| 17810 | gobiernos | 1 |
| 17811 | gobiernan | 1 |
| 17812 | gobernarse | 1 |
| 17813 | gloriosos | 1 |
| 17814 | gloriosamente | 1 |
| 17815 | giros | 1 |
| 17816 | giro | 1 |
| 17817 | giras | 1 |
| 17818 | girando | 1 |
| 17819 | giraldi | 1 |
| 17820 | ginebrino | 1 |
| 17821 | gimnásticos | 1 |
| 17822 | gimnasio | 1 |
| 17823 | gimió | 1 |
| 17824 | gil | 1 |
| 17825 | gigantona | 1 |
| 17826 | gigantón | 1 |
| 17827 | gigantescas | 1 |
| 17828 | gigantesca | 1 |
| 17829 | gigantes | 1 |
| 17830 | gesticularíamos | 1 |
| 17831 | gesticulando | 1 |
| 17832 | gestación | 1 |
| 17833 | gerundio | 1 |
| 17834 | geométricos | 1 |
| 17835 | geométricas | 1 |
| 17836 | geométrica | 1 |
| 17837 | geológicos | 1 |
| 17838 | geográficos | 1 |
| 17839 | genuinamente | 1 |
| 17840 | gentleman | 1 |
| 17841 | gentío | 1 |
| 17842 | gentileza | 1 |
| 17843 | gentiles | 1 |
| 17844 | genios | 1 |
| 17845 | genil | 1 |
| 17846 | genial | 1 |
| 17847 | generoso | 1 |
| 17848 | generosidad | 1 |
| 17849 | gemir | 1 |
| 17850 | gazmoña | 1 |
| 17851 | gayarre | 1 |
| 17852 | gaya | 1 |
| 17853 | gauthier | 1 |
| 17854 | gatito | 1 |
| 17855 | gatazo | 1 |
| 17856 | gastronómicos | 1 |
| 17857 | gastronómico | 1 |
| 17858 | gastroenteritis | 1 |
| 17859 | gástrico | 1 |
| 17860 | gastó | 1 |
| 17861 | gasto | 1 |
| 17862 | gasten | 1 |
| 17863 | gastase | 1 |
| 17864 | gastando | 1 |
| 17865 | gastada | 1 |
| 17866 | gastaban | 1 |
| 17867 | gastaba | 1 |
| 17868 | gaseosos | 1 |
| 17869 | garzos | 1 |
| 17870 | garden | 1 |
| 17871 | garcilaso | 1 |
| 17872 | garbanzo | 1 |
| 17873 | garante | 1 |
| 17874 | garabatos | 1 |
| 17875 | ganzúa | 1 |
| 17876 | ganosos | 1 |
| 17877 | ganoso | 1 |
| 17878 | ganosa | 1 |
| 17879 | gancho | 1 |
| 17880 | ganarnos | 1 |
| 17881 | ganaría | 1 |
| 17882 | ganara | 1 |
| 17883 | gananciales | 1 |
| 17884 | ganamos | 1 |
| 17885 | ganados | 1 |
| 17886 | ganadera | 1 |
| 17887 | ganada | 1 |
| 17888 | gamo | 1 |
| 17889 | galope | 1 |
| 17890 | gallineros | 1 |
| 17891 | galleta | 1 |
| 17892 | gallardísima | 1 |
| 17893 | gallardete | 1 |
| 17894 | gallardamente | 1 |
| 17895 | galileo | 1 |
| 17896 | galicismos | 1 |
| 17897 | galgo | 1 |
| 17898 | galerna | 1 |
| 17899 | galera | 1 |
| 17900 | galdós | 1 |
| 17901 | galas | 1 |
| 17902 | galardonaron | 1 |
| 17903 | galantes | 1 |
| 17904 | galantear | 1 |
| 17905 | gaitero | 1 |
| 17906 | gacha | 1 |
| 17907 | gacetillas | 1 |
| 17908 | gaceta | 1 |
| 17909 | futuras | 1 |
| 17910 | futraque | 1 |
| 17911 | fútiles | 1 |
| 17912 | fustis | 1 |
| 17913 | fusiles | 1 |
| 17914 | fusilémosle | 1 |
| 17915 | furtivos | 1 |
| 17916 | furtivo | 1 |
| 17917 | furiosas | 1 |
| 17918 | furibundos | 1 |
| 17919 | fungosa | 1 |
| 17920 | funesto | 1 |
| 17921 | fundó | 1 |
| 17922 | fundido | 1 |
| 17923 | fundidas | 1 |
| 17924 | fundición | 1 |
| 17925 | funde | 1 |
| 17926 | fundarse | 1 |
| 17927 | fundamentos | 1 |
| 17928 | fundadora | 1 |
| 17929 | fundador | 1 |
| 17930 | fundada | 1 |
| 17931 | fundaciones | 1 |
| 17932 | fundación | 1 |
| 17933 | funcionario | 1 |
| 17934 | funcionaba | 1 |
| 17935 | funámbula | 1 |
| 17936 | fuman | 1 |
| 17937 | fumador | 1 |
| 17938 | fumado | 1 |
| 17939 | fulminó | 1 |
| 17940 | fulminantes | 1 |
| 17941 | fulgores | 1 |
| 17942 | fulanito | 1 |
| 17943 | fulanita | 1 |
| 17944 | fuiste | 1 |
| 17945 | fuimos | 1 |
| 17946 | fuguillas | 1 |
| 17947 | fuga | 1 |
| 17948 | fueses | 1 |
| 17949 | fuertemente | 1 |
| 17950 | fuero | 1 |
| 17951 | fuéramos | 1 |
| 17952 | fuer | 1 |
| 17953 | frutas | 1 |
| 17954 | frutales | 1 |
| 17955 | frustrado | 1 |
| 17956 | frustó | 1 |
| 17957 | fruncido | 1 |
| 17958 | fruela | 1 |
| 17959 | frotar | 1 |
| 17960 | frotándose | 1 |
| 17961 | frotando | 1 |
| 17962 | frontones | 1 |
| 17963 | frontispicio | 1 |
| 17964 | frontera | 1 |
| 17965 | frontal | 1 |
| 17966 | frondosos | 1 |
| 17967 | frívolos | 1 |
| 17968 | frivolidad | 1 |
| 17969 | fritos | 1 |
| 17970 | frisar | 1 |
| 17971 | frisaban | 1 |
| 17972 | frisaba | 1 |
| 17973 | frigorífico | 1 |
| 17974 | fríamente | 1 |
| 17975 | frenéticos | 1 |
| 17976 | frenéticas | 1 |
| 17977 | frenética | 1 |
| 17978 | frecuentase | 1 |
| 17979 | frecuentan | 1 |
| 17980 | frecuentado | 1 |
| 17981 | frecuentaban | 1 |
| 17982 | frecuentaba | 1 |
| 17983 | fraternizar | 1 |
| 17984 | fraternal | 1 |
| 17985 | frascueeeelo | 1 |
| 17986 | francklin | 1 |
| 17987 | franciscos | 1 |
| 17988 | franciscas | 1 |
| 17989 | francesas | 1 |
| 17990 | fraigerundio | 1 |
| 17991 | fragmento | 1 |
| 17992 | fraganti | 1 |
| 17993 | fragancias | 1 |
| 17994 | fragancia | 1 |
| 17995 | fr | 1 |
| 17996 | fósforos | 1 |
| 17997 | fosforeras | 1 |
| 17998 | fosco | 1 |
| 17999 | forzada | 1 |
| 18000 | fortunas | 1 |
| 18001 | fortuitos | 1 |
| 18002 | fortísimo | 1 |
| 18003 | fortísima | 1 |
| 18004 | fortificaba | 1 |
| 18005 | fortifica | 1 |
| 18006 | fortalezas | 1 |
| 18007 | fortalecían | 1 |
| 18008 | forró | 1 |
| 18009 | forrados | 1 |
| 18010 | forradas | 1 |
| 18011 | foros | 1 |
| 18012 | fornos | 1 |
| 18013 | fornidos | 1 |
| 18014 | formulismo | 1 |
| 18015 | formulando | 1 |
| 18016 | formó | 1 |
| 18017 | formemos | 1 |
| 18018 | formaron | 1 |
| 18019 | forman | 1 |
| 18020 | forjado | 1 |
| 18021 | forcejeaban | 1 |
| 18022 | forajidos | 1 |
| 18023 | fontanero | 1 |
| 18024 | follis | 1 |
| 18025 | follajes | 1 |
| 18026 | fogonazo | 1 |
| 18027 | foco | 1 |
| 18028 | fluir | 1 |
| 18029 | flota | 1 |
| 18030 | floricultor | 1 |
| 18031 | flórez | 1 |
| 18032 | floreros | 1 |
| 18033 | flojas | 1 |
| 18034 | flema | 1 |
| 18035 | flegmasías | 1 |
| 18036 | flegmasía | 1 |
| 18037 | flecos | 1 |
| 18038 | flatus | 1 |
| 18039 | flanqueándola | 1 |
| 18040 | flanes | 1 |
| 18041 | flan | 1 |
| 18042 | flammarión | 1 |
| 18043 | flamígeros | 1 |
| 18044 | flamencos | 1 |
| 18045 | flamencas | 1 |
| 18046 | flamantes | 1 |
| 18047 | flamante | 1 |
| 18048 | flagrantes | 1 |
| 18049 | fisonomías | 1 |
| 18050 | fisiólogo | 1 |
| 18051 | fisiológicos | 1 |
| 18052 | fisiológicas | 1 |
| 18053 | fisiológicamente | 1 |
| 18054 | físicas | 1 |
| 18055 | fiscalías | 1 |
| 18056 | firmó | 1 |
| 18057 | firmeza | 1 |
| 18058 | firmado | 1 |
| 18059 | finitas | 1 |
| 18060 | fingimientos | 1 |
| 18061 | fingiera | 1 |
| 18062 | fingidos | 1 |
| 18063 | fingidas | 1 |
| 18064 | fingen | 1 |
| 18065 | fineza | 1 |
| 18066 | fincas | 1 |
| 18067 | finca | 1 |
| 18068 | finado | 1 |
| 18069 | filtro | 1 |
| 18070 | filtrando | 1 |
| 18071 | filtrado | 1 |
| 18072 | filtración | 1 |
| 18073 | filosofías | 1 |
| 18074 | filosofastros | 1 |
| 18075 | filosofaba | 1 |
| 18076 | filón | 1 |
| 18077 | filis | 1 |
| 18078 | filigranas | 1 |
| 18079 | filigrana | 1 |
| 18080 | filete | 1 |
| 18081 | filarmónico | 1 |
| 18082 | filantrópicos | 1 |
| 18083 | filantrópico | 1 |
| 18084 | filantropía | 1 |
| 18085 | fijara | 1 |
| 18086 | fijan | 1 |
| 18087 | fijamente | 1 |
| 18088 | fijado | 1 |
| 18089 | fijaban | 1 |
| 18090 | figuronas | 1 |
| 18091 | figuro | 1 |
| 18092 | figurines | 1 |
| 18093 | figurillas | 1 |
| 18094 | figúreselo | 1 |
| 18095 | figures | 1 |
| 18096 | figurársele | 1 |
| 18097 | figuraríamos | 1 |
| 18098 | figurar | 1 |
| 18099 | figurándoselo | 1 |
| 18100 | figurándosela | 1 |
| 18101 | figuran | 1 |
| 18102 | figurábase | 1 |
| 18103 | figaro | 1 |
| 18104 | fierabrás | 1 |
| 18105 | fielding | 1 |
| 18106 | fidelísimo | 1 |
| 18107 | fidei | 1 |
| 18108 | fichas | 1 |
| 18109 | ficciones | 1 |
| 18110 | ficción | 1 |
| 18111 | fibra | 1 |
| 18112 | fiarse | 1 |
| 18113 | fían | 1 |
| 18114 | fiado | 1 |
| 18115 | fiada | 1 |
| 18116 | feudalismo | 1 |
| 18117 | feudales | 1 |
| 18118 | fétido | 1 |
| 18119 | fervorosa | 1 |
| 18120 | fervientes | 1 |
| 18121 | fertilidad | 1 |
| 18122 | fértiles | 1 |
| 18123 | feroz | 1 |
| 18124 | fementida | 1 |
| 18125 | femeniles | 1 |
| 18126 | felpudo | 1 |
| 18127 | felinos | 1 |
| 18128 | felinas | 1 |
| 18129 | felicitó | 1 |
| 18130 | felicitaron | 1 |
| 18131 | felice | 1 |
| 18132 | feísima | 1 |
| 18133 | feijóo | 1 |
| 18134 | federación | 1 |
| 18135 | fecit | 1 |
| 18136 | fechas | 1 |
| 18137 | febrero | 1 |
| 18138 | feas | 1 |
| 18139 | fealdades | 1 |
| 18140 | fealdad | 1 |
| 18141 | faz | 1 |
| 18142 | favorecido | 1 |
| 18143 | favorecida | 1 |
| 18144 | favorecían | 1 |
| 18145 | favorecerle | 1 |
| 18146 | favorables | 1 |
| 18147 | fatua | 1 |
| 18148 | fatigosas | 1 |
| 18149 | fatigado | 1 |
| 18150 | fatalista | 1 |
| 18151 | fatales | 1 |
| 18152 | fastuosidad | 1 |
| 18153 | fastos | 1 |
| 18154 | fastidiosos | 1 |
| 18155 | fastidiarle | 1 |
| 18156 | fascinada | 1 |
| 18157 | fascinaba | 1 |
| 18158 | fas | 1 |
| 18159 | farsas | 1 |
| 18160 | farolón | 1 |
| 18161 | farnesios | 1 |
| 18162 | fariseas | 1 |
| 18163 | faringe | 1 |
| 18164 | faraones | 1 |
| 18165 | fantásticas | 1 |
| 18166 | fantásticamente | 1 |
| 18167 | fantasías | 1 |
| 18168 | fantaseaba | 1 |
| 18169 | fangoso | 1 |
| 18170 | fanfarrones | 1 |
| 18171 | fanatizada | 1 |
| 18172 | fanáticas | 1 |
| 18173 | fanal | 1 |
| 18174 | famosísimo | 1 |
| 18175 | famosas | 1 |
| 18176 | familiaridad | 1 |
| 18177 | faltriquera | 1 |
| 18178 | falten | 1 |
| 18179 | faltemos | 1 |
| 18180 | faltase | 1 |
| 18181 | faltarle | 1 |
| 18182 | faltaré | 1 |
| 18183 | faltará | 1 |
| 18184 | faltando | 1 |
| 18185 | falsísima | 1 |
| 18186 | falsificó | 1 |
| 18187 | falsificado | 1 |
| 18188 | falsificada | 1 |
| 18189 | falló | 1 |
| 18190 | fallo | 1 |
| 18191 | fallidas | 1 |
| 18192 | fallecido | 1 |
| 18193 | falange | 1 |
| 18194 | faisán | 1 |
| 18195 | facultativos | 1 |
| 18196 | facultativa | 1 |
| 18197 | facultad | 1 |
| 18198 | factum | 1 |
| 18199 | factorías | 1 |
| 18200 | factores | 1 |
| 18201 | façon | 1 |
| 18202 | facistol | 1 |
| 18203 | facimus | 1 |
| 18204 | facilitaba | 1 |
| 18205 | facilita | 1 |
| 18206 | facilidad | 1 |
| 18207 | facial | 1 |
| 18208 | fachenda | 1 |
| 18209 | fachadas | 1 |
| 18210 | fabuloso | 1 |
| 18211 | fabulosas | 1 |
| 18212 | fábulas | 1 |
| 18213 | fabricante | 1 |
| 18214 | fabricado | 1 |
| 18215 | fabricada | 1 |
| 18216 | fabrica | 1 |
| 18217 | fabiolita | 1 |
| 18218 | fabiola | 1 |
| 18219 | fa | 1 |
| 18220 | extremidades | 1 |
| 18221 | extremeño | 1 |
| 18222 | extrememos | 1 |
| 18223 | extremas | 1 |
| 18224 | extravió | 1 |
| 18225 | extravío | 1 |
| 18226 | extravían | 1 |
| 18227 | extraviada | 1 |
| 18228 | extraviaba | 1 |
| 18229 | extraordinarios | 1 |
| 18230 | extrañar | 1 |
| 18231 | extrañado | 1 |
| 18232 | extrañaba | 1 |
| 18233 | extranjera | 1 |
| 18234 | extraído | 1 |
| 18235 | extinguirse | 1 |
| 18236 | extinguir | 1 |
| 18237 | extinguiera | 1 |
| 18238 | extinguido | 1 |
| 18239 | extiende | 1 |
| 18240 | extenuado | 1 |
| 18241 | extendiera | 1 |
| 18242 | extendiéndome | 1 |
| 18243 | extendidos | 1 |
| 18244 | extendidas | 1 |
| 18245 | extendida | 1 |
| 18246 | extenderse | 1 |
| 18247 | extática | 1 |
| 18248 | extasiado | 1 |
| 18249 | extasiada | 1 |
| 18250 | exquisitos | 1 |
| 18251 | expropiación | 1 |
| 18252 | exprofeso | 1 |
| 18253 | exprimían | 1 |
| 18254 | expreso | 1 |
| 18255 | expresivas | 1 |
| 18256 | exprese | 1 |
| 18257 | expresando | 1 |
| 18258 | expresa | 1 |
| 18259 | expositio | 1 |
| 18260 | exportado | 1 |
| 18261 | exponiendo | 1 |
| 18262 | expones | 1 |
| 18263 | exponerte | 1 |
| 18264 | exponerla | 1 |
| 18265 | exponer | 1 |
| 18266 | expone | 1 |
| 18267 | expondría | 1 |
| 18268 | explotarlos | 1 |
| 18269 | explotarlo | 1 |
| 18270 | explotaré | 1 |
| 18271 | explotación | 1 |
| 18272 | explosiva | 1 |
| 18273 | explosión | 1 |
| 18274 | exploremos | 1 |
| 18275 | exploraciones | 1 |
| 18276 | expliques | 1 |
| 18277 | expliquen | 1 |
| 18278 | explíquemelo | 1 |
| 18279 | explico | 1 |
| 18280 | explícate | 1 |
| 18281 | explicase | 1 |
| 18282 | explicárselo | 1 |
| 18283 | explicárselas | 1 |
| 18284 | explicársela | 1 |
| 18285 | explicaré | 1 |
| 18286 | explicará | 1 |
| 18287 | explicara | 1 |
| 18288 | explican | 1 |
| 18289 | explicados | 1 |
| 18290 | expiraba | 1 |
| 18291 | expertos | 1 |
| 18292 | expertas | 1 |
| 18293 | experimentos | 1 |
| 18294 | experimento | 1 |
| 18295 | experimentar | 1 |
| 18296 | experiencias | 1 |
| 18297 | expedita | 1 |
| 18298 | expediciones | 1 |
| 18299 | expedicionario | 1 |
| 18300 | expectación | 1 |
| 18301 | expansivas | 1 |
| 18302 | exóticas | 1 |
| 18303 | exótica | 1 |
| 18304 | exorbitantes | 1 |
| 18305 | exorbitante | 1 |
| 18306 | existiese | 1 |
| 18307 | existieran | 1 |
| 18308 | existían | 1 |
| 18309 | existente | 1 |
| 18310 | existencias | 1 |
| 18311 | existen | 1 |
| 18312 | exíjase | 1 |
| 18313 | exigua | 1 |
| 18314 | exigiría | 1 |
| 18315 | exigió | 1 |
| 18316 | exigieron | 1 |
| 18317 | exigiendo | 1 |
| 18318 | exigencia | 1 |
| 18319 | exhaustas | 1 |
| 18320 | exhalaban | 1 |
| 18321 | exenta | 1 |
| 18322 | exegéticas | 1 |
| 18323 | execración | 1 |
| 18324 | execrables | 1 |
| 18325 | execrable | 1 |
| 18326 | excusar | 1 |
| 18327 | excusadas | 1 |
| 18328 | excusaba | 1 |
| 18329 | excusa | 1 |
| 18330 | excomulgado | 1 |
| 18331 | excluye | 1 |
| 18332 | excluía | 1 |
| 18333 | exclaustrar | 1 |
| 18334 | exclamado | 1 |
| 18335 | exclamación | 1 |
| 18336 | excitó | 1 |
| 18337 | excitarlo | 1 |
| 18338 | excitantes | 1 |
| 18339 | excitante | 1 |
| 18340 | excitadota | 1 |
| 18341 | excitados | 1 |
| 18342 | excitadilla | 1 |
| 18343 | excitadas | 1 |
| 18344 | excesivamente | 1 |
| 18345 | exceptuaba | 1 |
| 18346 | excepcionales | 1 |
| 18347 | excelentísima | 1 |
| 18348 | excelentes | 1 |
| 18349 | excedía | 1 |
| 18350 | excavaciones | 1 |
| 18351 | examino | 1 |
| 18352 | examinarme | 1 |
| 18353 | examinar | 1 |
| 18354 | examinaba | 1 |
| 18355 | examina | 1 |
| 18356 | exaltó | 1 |
| 18357 | exaltas | 1 |
| 18358 | exaltados | 1 |
| 18359 | exaltadas | 1 |
| 18360 | exaltaciones | 1 |
| 18361 | exalta | 1 |
| 18362 | exagerarlos | 1 |
| 18363 | exagerando | 1 |
| 18364 | exagerado | 1 |
| 18365 | exageradísima | 1 |
| 18366 | exactos | 1 |
| 18367 | evocarla | 1 |
| 18368 | evocar | 1 |
| 18369 | evocados | 1 |
| 18370 | evite | 1 |
| 18371 | evitarse | 1 |
| 18372 | evitarlos | 1 |
| 18373 | evitara | 1 |
| 18374 | evitado | 1 |
| 18375 | evitaba | 1 |
| 18376 | evidentemente | 1 |
| 18377 | evaporaban | 1 |
| 18378 | evaporaba | 1 |
| 18379 | evangelii | 1 |
| 18380 | europea | 1 |
| 18381 | eureka | 1 |
| 18382 | eufemismo | 1 |
| 18383 | eucologio | 1 |
| 18384 | eucaliptos | 1 |
| 18385 | etruscos | 1 |
| 18386 | etnógrafo | 1 |
| 18387 | eternizaba | 1 |
| 18388 | était | 1 |
| 18389 | estuviste | 1 |
| 18390 | estuvieras | 1 |
| 18391 | estuviéramos | 1 |
| 18392 | estupro | 1 |
| 18393 | estupor | 1 |
| 18394 | estúpidos | 1 |
| 18395 | estupenda | 1 |
| 18396 | estupefactos | 1 |
| 18397 | estupefacta | 1 |
| 18398 | estupefacción | 1 |
| 18399 | estudioso | 1 |
| 18400 | estudiarse | 1 |
| 18401 | estudiaría | 1 |
| 18402 | estudiando | 1 |
| 18403 | estudian | 1 |
| 18404 | estudiado | 1 |
| 18405 | estudiaban | 1 |
| 18406 | estuches | 1 |
| 18407 | estuche | 1 |
| 18408 | estucado | 1 |
| 18409 | estrujarse | 1 |
| 18410 | estrujar | 1 |
| 18411 | estrujándose | 1 |
| 18412 | estrujado | 1 |
| 18413 | estrujaba | 1 |
| 18414 | estropicio | 1 |
| 18415 | estridentes | 1 |
| 18416 | estricta | 1 |
| 18417 | estribor | 1 |
| 18418 | estrepitoso | 1 |
| 18419 | estremecimientos | 1 |
| 18420 | estremeciéndose | 1 |
| 18421 | estremecía | 1 |
| 18422 | estremecerse | 1 |
| 18423 | estrechaban | 1 |
| 18424 | estrangulada | 1 |
| 18425 | estrangulación | 1 |
| 18426 | estragados | 1 |
| 18427 | estrados | 1 |
| 18428 | estote | 1 |
| 18429 | estorninos | 1 |
| 18430 | estorbos | 1 |
| 18431 | estorbase | 1 |
| 18432 | estorbarse | 1 |
| 18433 | estorbarle | 1 |
| 18434 | estorbar | 1 |
| 18435 | estoraque | 1 |
| 18436 | estoposa | 1 |
| 18437 | estola | 1 |
| 18438 | estofa | 1 |
| 18439 | estocadas | 1 |
| 18440 | estirpe | 1 |
| 18441 | estirada | 1 |
| 18442 | estiraba | 1 |
| 18443 | estímulo | 1 |
| 18444 | estimule | 1 |
| 18445 | estimando | 1 |
| 18446 | estimado | 1 |
| 18447 | estilita | 1 |
| 18448 | estilista | 1 |
| 18449 | estético | 1 |
| 18450 | estés | 1 |
| 18451 | estériles | 1 |
| 18452 | estereotipada | 1 |
| 18453 | estera | 1 |
| 18454 | ester | 1 |
| 18455 | estepas | 1 |
| 18456 | estemos | 1 |
| 18457 | estatutos | 1 |
| 18458 | estáte | 1 |
| 18459 | estate | 1 |
| 18460 | estaré | 1 |
| 18461 | estarás | 1 |
| 18462 | estanquero | 1 |
| 18463 | estanque | 1 |
| 18464 | estandartes | 1 |
| 18465 | estandarte | 1 |
| 18466 | estancamiento | 1 |
| 18467 | estancadas | 1 |
| 18468 | estampilla | 1 |
| 18469 | estampada | 1 |
| 18470 | estambres | 1 |
| 18471 | estambre | 1 |
| 18472 | estalle | 1 |
| 18473 | estallaron | 1 |
| 18474 | estallarme | 1 |
| 18475 | estáis | 1 |
| 18476 | estacada | 1 |
| 18477 | establos | 1 |
| 18478 | establo | 1 |
| 18479 | establecido | 1 |
| 18480 | establecidas | 1 |
| 18481 | establecer | 1 |
| 18482 | establecen | 1 |
| 18483 | estable | 1 |
| 18484 | esquivar | 1 |
| 18485 | esquilón | 1 |
| 18486 | esquilas | 1 |
| 18487 | esquilache | 1 |
| 18488 | esqueletos | 1 |
| 18489 | esquela | 1 |
| 18490 | espumar | 1 |
| 18491 | espuela | 1 |
| 18492 | esprit | 1 |
| 18493 | espontáneos | 1 |
| 18494 | esponjosa | 1 |
| 18495 | esponjan | 1 |
| 18496 | espolios | 1 |
| 18497 | espliego | 1 |
| 18498 | esplendorosa | 1 |
| 18499 | espirituosos | 1 |
| 18500 | espiritualista | 1 |
| 18501 | espiritualísima | 1 |
| 18502 | espirar | 1 |
| 18503 | espirando | 1 |
| 18504 | espío | 1 |
| 18505 | espinosas | 1 |
| 18506 | espinosa | 1 |
| 18507 | espinos | 1 |
| 18508 | espinazo | 1 |
| 18509 | espifor | 1 |
| 18510 | espiarlos | 1 |
| 18511 | espesura | 1 |
| 18512 | espesísima | 1 |
| 18513 | esperemos | 1 |
| 18514 | esperé | 1 |
| 18515 | esperarse | 1 |
| 18516 | esperaron | 1 |
| 18517 | esperarla | 1 |
| 18518 | esperará | 1 |
| 18519 | esperándola | 1 |
| 18520 | espejismo | 1 |
| 18521 | espectación | 1 |
| 18522 | especificado | 1 |
| 18523 | especialistas | 1 |
| 18524 | especialista | 1 |
| 18525 | especialísima | 1 |
| 18526 | especiales | 1 |
| 18527 | espartero | 1 |
| 18528 | esparcir | 1 |
| 18529 | esparció | 1 |
| 18530 | esparcida | 1 |
| 18531 | españolas | 1 |
| 18532 | espantoso | 1 |
| 18533 | espantosas | 1 |
| 18534 | espantosa | 1 |
| 18535 | espantó | 1 |
| 18536 | espantes | 1 |
| 18537 | espantando | 1 |
| 18538 | espantajo | 1 |
| 18539 | espantadiza | 1 |
| 18540 | espanta | 1 |
| 18541 | espaldera | 1 |
| 18542 | espaciosos | 1 |
| 18543 | espacioso | 1 |
| 18544 | espaciosa | 1 |
| 18545 | espaciada | 1 |
| 18546 | esotéricos | 1 |
| 18547 | esmerado | 1 |
| 18548 | esmerada | 1 |
| 18549 | esgrimía | 1 |
| 18550 | esforzó | 1 |
| 18551 | esforzarse | 1 |
| 18552 | esforzaban | 1 |
| 18553 | esenciada | 1 |
| 18554 | escupiría | 1 |
| 18555 | escupirá | 1 |
| 18556 | escupiendo | 1 |
| 18557 | esculturales | 1 |
| 18558 | escultural | 1 |
| 18559 | escultóricos | 1 |
| 18560 | escultor | 1 |
| 18561 | escuetas | 1 |
| 18562 | escueta | 1 |
| 18563 | escudriñó | 1 |
| 18564 | escudriñado | 1 |
| 18565 | escuchase | 1 |
| 18566 | escucharle | 1 |
| 18567 | escuchando | 1 |
| 18568 | escuchado | 1 |
| 18569 | escuchad | 1 |
| 18570 | escuálido | 1 |
| 18571 | escuadra | 1 |
| 18572 | escrupulosos | 1 |
| 18573 | escrupulosidad | 1 |
| 18574 | escrupulosamente | 1 |
| 18575 | escrupulosa | 1 |
| 18576 | escrituras | 1 |
| 18577 | escribirlas | 1 |
| 18578 | escribiría | 1 |
| 18579 | escribiré | 1 |
| 18580 | escribieron | 1 |
| 18581 | escribiera | 1 |
| 18582 | escribas | 1 |
| 18583 | escríbame | 1 |
| 18584 | escozor | 1 |
| 18585 | escotillón | 1 |
| 18586 | escosura | 1 |
| 18587 | escorias | 1 |
| 18588 | escopetas | 1 |
| 18589 | escondrijos | 1 |
| 18590 | escondieron | 1 |
| 18591 | escondiéndose | 1 |
| 18592 | esconderla | 1 |
| 18593 | escondería | 1 |
| 18594 | escombros | 1 |
| 18595 | escolta | 1 |
| 18596 | escolios | 1 |
| 18597 | escolasticismo | 1 |
| 18598 | escolástica | 1 |
| 18599 | escoja | 1 |
| 18600 | escogitar | 1 |
| 18601 | escogieron | 1 |
| 18602 | escogidos | 1 |
| 18603 | escogidísimos | 1 |
| 18604 | escogidísimo | 1 |
| 18605 | escogidas | 1 |
| 18606 | escogida | 1 |
| 18607 | escogen | 1 |
| 18608 | escocias | 1 |
| 18609 | escocés | 1 |
| 18610 | escobazos | 1 |
| 18611 | escobazo | 1 |
| 18612 | esclavas | 1 |
| 18613 | esclarecidos | 1 |
| 18614 | escepticismo | 1 |
| 18615 | escénico | 1 |
| 18616 | escayola | 1 |
| 18617 | escatimados | 1 |
| 18618 | escasos | 1 |
| 18619 | escasearían | 1 |
| 18620 | escaseando | 1 |
| 18621 | escarnecía | 1 |
| 18622 | escarmiento | 1 |
| 18623 | escarchas | 1 |
| 18624 | escarabajo | 1 |
| 18625 | escapularios | 1 |
| 18626 | escapatoria | 1 |
| 18627 | escapase | 1 |
| 18628 | escapas | 1 |
| 18629 | escaparon | 1 |
| 18630 | escaparían | 1 |
| 18631 | escaparates | 1 |
| 18632 | escapan | 1 |
| 18633 | escapadas | 1 |
| 18634 | escapa | 1 |
| 18635 | escandalizarte | 1 |
| 18636 | escandalizando | 1 |
| 18637 | escandalizan | 1 |
| 18638 | escandalizado | 1 |
| 18639 | escandalizaba | 1 |
| 18640 | escame | 1 |
| 18641 | escamandro | 1 |
| 18642 | escalpelo | 1 |
| 18643 | escalones | 1 |
| 18644 | escalonada | 1 |
| 18645 | escalón | 1 |
| 18646 | escalasen | 1 |
| 18647 | escalar | 1 |
| 18648 | escabrosas | 1 |
| 18649 | esbirros | 1 |
| 18650 | esbirro | 1 |
| 18651 | ésas | 1 |
| 18652 | eruptos | 1 |
| 18653 | eruditos | 1 |
| 18654 | eruditamente | 1 |
| 18655 | erudita | 1 |
| 18656 | erudición | 1 |
| 18657 | eructaba | 1 |
| 18658 | errónea | 1 |
| 18659 | errante | 1 |
| 18660 | erradamente | 1 |
| 18661 | erotismo | 1 |
| 18662 | ermitaño | 1 |
| 18663 | erizó | 1 |
| 18664 | erizaron | 1 |
| 18665 | erizándose | 1 |
| 18666 | erizando | 1 |
| 18667 | erizados | 1 |
| 18668 | erizada | 1 |
| 18669 | erizaban | 1 |
| 18670 | erguido | 1 |
| 18671 | ergo | 1 |
| 18672 | erba | 1 |
| 18673 | erat | 1 |
| 18674 | erario | 1 |
| 18675 | equivoco | 1 |
| 18676 | equivocar | 1 |
| 18677 | equivocando | 1 |
| 18678 | equivocados | 1 |
| 18679 | equivocada | 1 |
| 18680 | equívoca | 1 |
| 18681 | equivoca | 1 |
| 18682 | equivalía | 1 |
| 18683 | equitativo | 1 |
| 18684 | equinoccio | 1 |
| 18685 | equilibrios | 1 |
| 18686 | equilibrado | 1 |
| 18687 | epopeya | 1 |
| 18688 | episcopal | 1 |
| 18689 | epílogo | 1 |
| 18690 | epigramático | 1 |
| 18691 | epidemia | 1 |
| 18692 | epicuro | 1 |
| 18693 | epicurista | 1 |
| 18694 | epicureísmo | 1 |
| 18695 | épico | 1 |
| 18696 | epiceno | 1 |
| 18697 | epicena | 1 |
| 18698 | épica | 1 |
| 18699 | epanadiplosis | 1 |
| 18700 | envuelven | 1 |
| 18701 | envolviole | 1 |
| 18702 | envolvió | 1 |
| 18703 | envolvían | 1 |
| 18704 | envolverla | 1 |
| 18705 | envolver | 1 |
| 18706 | envoltorio | 1 |
| 18707 | envidiando | 1 |
| 18708 | envidiados | 1 |
| 18709 | envidiado | 1 |
| 18710 | enviarle | 1 |
| 18711 | enviados | 1 |
| 18712 | envenenando | 1 |
| 18713 | envenenaban | 1 |
| 18714 | envejeciendo | 1 |
| 18715 | envejecía | 1 |
| 18716 | envanecían | 1 |
| 18717 | enumerar | 1 |
| 18718 | enumeraciones | 1 |
| 18719 | enumeración | 1 |
| 18720 | entusiastas | 1 |
| 18721 | entusiasmó | 1 |
| 18722 | entusiasmarse | 1 |
| 18723 | entusiasmaba | 1 |
| 18724 | enturbiar | 1 |
| 18725 | entumecimiento | 1 |
| 18726 | entumecidos | 1 |
| 18727 | entumecida | 1 |
| 18728 | entumecían | 1 |
| 18729 | entumecía | 1 |
| 18730 | entrometidos | 1 |
| 18731 | entrometido | 1 |
| 18732 | entrometidas | 1 |
| 18733 | entreverados | 1 |
| 18734 | entretienen | 1 |
| 18735 | entretiene | 1 |
| 18736 | entretenimiento | 1 |
| 18737 | entretenían | 1 |
| 18738 | entretengan | 1 |
| 18739 | entresuelo | 1 |
| 18740 | entremetidos | 1 |
| 18741 | entremetido | 1 |
| 18742 | entregárselo | 1 |
| 18743 | entregarme | 1 |
| 18744 | entregarlo | 1 |
| 18745 | entregarle | 1 |
| 18746 | entregaría | 1 |
| 18747 | entregara | 1 |
| 18748 | entregándose | 1 |
| 18749 | entregándole | 1 |
| 18750 | entregándolas | 1 |
| 18751 | entregan | 1 |
| 18752 | entregados | 1 |
| 18753 | entreabrió | 1 |
| 18754 | entreabiertos | 1 |
| 18755 | entrasen | 1 |
| 18756 | entrase | 1 |
| 18757 | entras | 1 |
| 18758 | entrarle | 1 |
| 18759 | entraremos | 1 |
| 18760 | entraras | 1 |
| 18761 | entrara | 1 |
| 18762 | entraña | 1 |
| 18763 | entran | 1 |
| 18764 | entramos | 1 |
| 18765 | entradas | 1 |
| 18766 | entorpecimientos | 1 |
| 18767 | entornó | 1 |
| 18768 | entornándolos | 1 |
| 18769 | entornado | 1 |
| 18770 | entornada | 1 |
| 18771 | entornaba | 1 |
| 18772 | entonado | 1 |
| 18773 | entonadas | 1 |
| 18774 | entomólogo | 1 |
| 18775 | entomológicas | 1 |
| 18776 | entierren | 1 |
| 18777 | entierre | 1 |
| 18778 | entienden | 1 |
| 18779 | entidades | 1 |
| 18780 | entibiaba | 1 |
| 18781 | enterrarán | 1 |
| 18782 | enterramientos | 1 |
| 18783 | enterraba | 1 |
| 18784 | enternezco | 1 |
| 18785 | enternecerse | 1 |
| 18786 | enternecer | 1 |
| 18787 | enteren | 1 |
| 18788 | enterarle | 1 |
| 18789 | enterados | 1 |
| 18790 | enteraba | 1 |
| 18791 | entendimiento | 1 |
| 18792 | entendieran | 1 |
| 18793 | entendiendo | 1 |
| 18794 | entendidas | 1 |
| 18795 | entendida | 1 |
| 18796 | entendernos | 1 |
| 18797 | entenderían | 1 |
| 18798 | entenderé | 1 |
| 18799 | entendedor | 1 |
| 18800 | ente | 1 |
| 18801 | entallada | 1 |
| 18802 | entablaba | 1 |
| 18803 | ensuciar | 1 |
| 18804 | ensortijado | 1 |
| 18805 | ensoñadora | 1 |
| 18806 | ensoñación | 1 |
| 18807 | ensimismado | 1 |
| 18808 | enseñorease | 1 |
| 18809 | enseñoreados | 1 |
| 18810 | enseñó | 1 |
| 18811 | enseñes | 1 |
| 18812 | enseñarte | 1 |
| 18813 | enseñaron | 1 |
| 18814 | enseñanzas | 1 |
| 18815 | enseñándole | 1 |
| 18816 | ensayó | 1 |
| 18817 | ensartadas | 1 |
| 18818 | ensanche | 1 |
| 18819 | ensancharse | 1 |
| 18820 | ensanchándose | 1 |
| 18821 | ensalzarás | 1 |
| 18822 | enroscarse | 1 |
| 18823 | enroscándose | 1 |
| 18824 | enroscado | 1 |
| 18825 | enroscadas | 1 |
| 18826 | enrevesados | 1 |
| 18827 | enredó | 1 |
| 18828 | enredado | 1 |
| 18829 | enredaderas | 1 |
| 18830 | enredadera | 1 |
| 18831 | enredada | 1 |
| 18832 | enredaban | 1 |
| 18833 | enreda | 1 |
| 18834 | enojosísimos | 1 |
| 18835 | enojaba | 1 |
| 18836 | ennoblecemos | 1 |
| 18837 | ennegrecidos | 1 |
| 18838 | ennegrecidas | 1 |
| 18839 | ennegrecían | 1 |
| 18840 | enmudece | 1 |
| 18841 | enmienda | 1 |
| 18842 | enmascarado | 1 |
| 18843 | enloquecidas | 1 |
| 18844 | enlazados | 1 |
| 18845 | enlazaba | 1 |
| 18846 | enjutos | 1 |
| 18847 | enjugó | 1 |
| 18848 | enjugar | 1 |
| 18849 | enjugando | 1 |
| 18850 | enjaulado | 1 |
| 18851 | enjaulada | 1 |
| 18852 | enjambre | 1 |
| 18853 | enigma | 1 |
| 18854 | enhiesto | 1 |
| 18855 | engrandecía | 1 |
| 18856 | engrandecer | 1 |
| 18857 | engordase | 1 |
| 18858 | engordando | 1 |
| 18859 | engordado | 1 |
| 18860 | engomada | 1 |
| 18861 | engolfarse | 1 |
| 18862 | englobado | 1 |
| 18863 | engendrar | 1 |
| 18864 | engendraban | 1 |
| 18865 | engañaste | 1 |
| 18866 | engañarlos | 1 |
| 18867 | engañándose | 1 |
| 18868 | engañando | 1 |
| 18869 | enganchó | 1 |
| 18870 | enganchados | 1 |
| 18871 | enganchado | 1 |
| 18872 | enganchadas | 1 |
| 18873 | enganchaba | 1 |
| 18874 | engalanadas | 1 |
| 18875 | enfurecía | 1 |
| 18876 | enfundadas | 1 |
| 18877 | enfriara | 1 |
| 18878 | enfriado | 1 |
| 18879 | enfriaban | 1 |
| 18880 | enfrenados | 1 |
| 18881 | enfrascarse | 1 |
| 18882 | enfrascados | 1 |
| 18883 | enfilándose | 1 |
| 18884 | enfermucho | 1 |
| 18885 | enfermero | 1 |
| 18886 | enfermemos | 1 |
| 18887 | enfermaste | 1 |
| 18888 | enfermar | 1 |
| 18889 | enfant | 1 |
| 18890 | enfado | 1 |
| 18891 | enfadarle | 1 |
| 18892 | enfadado | 1 |
| 18893 | enfadada | 1 |
| 18894 | enfada | 1 |
| 18895 | enerve | 1 |
| 18896 | energúmenos | 1 |
| 18897 | energúmeno | 1 |
| 18898 | enérgicos | 1 |
| 18899 | enemistad | 1 |
| 18900 | endiosas | 1 |
| 18901 | endiosarse | 1 |
| 18902 | enderezarle | 1 |
| 18903 | endemoniada | 1 |
| 18904 | endémicos | 1 |
| 18905 | encuentras | 1 |
| 18906 | encubridoras | 1 |
| 18907 | encorvadas | 1 |
| 18908 | encopetadas | 1 |
| 18909 | encontremos | 1 |
| 18910 | encontrase | 1 |
| 18911 | encontrársela | 1 |
| 18912 | encontrarla | 1 |
| 18913 | encontraremos | 1 |
| 18914 | encontrarán | 1 |
| 18915 | encontraran | 1 |
| 18916 | encontrará | 1 |
| 18917 | encontramos | 1 |
| 18918 | encontrados | 1 |
| 18919 | encontrábase | 1 |
| 18920 | encomienda | 1 |
| 18921 | encomendó | 1 |
| 18922 | encomendaron | 1 |
| 18923 | encogimiento | 1 |
| 18924 | encogiéndose | 1 |
| 18925 | encogida | 1 |
| 18926 | encogerse | 1 |
| 18927 | encoge | 1 |
| 18928 | enclenques | 1 |
| 18929 | encinta | 1 |
| 18930 | encina | 1 |
| 18931 | encierros | 1 |
| 18932 | encierras | 1 |
| 18933 | encierra | 1 |
| 18934 | encienden | 1 |
| 18935 | encienda | 1 |
| 18936 | enchufaban | 1 |
| 18937 | encharcados | 1 |
| 18938 | encerrona | 1 |
| 18939 | encerraron | 1 |
| 18940 | encerrarla | 1 |
| 18941 | encerrar | 1 |
| 18942 | encerrándose | 1 |
| 18943 | encerrados | 1 |
| 18944 | encerraban | 1 |
| 18945 | encerado | 1 |
| 18946 | encendiese | 1 |
| 18947 | encenderse | 1 |
| 18948 | encenderla | 1 |
| 18949 | encenagó | 1 |
| 18950 | encenagados | 1 |
| 18951 | encenagaba | 1 |
| 18952 | encauzada | 1 |
| 18953 | encaró | 1 |
| 18954 | encarnizada | 1 |
| 18955 | encarnados | 1 |
| 18956 | encarnación | 1 |
| 18957 | encarnaba | 1 |
| 18958 | encargarse | 1 |
| 18959 | encargaría | 1 |
| 18960 | encargadas | 1 |
| 18961 | encargada | 1 |
| 18962 | encargaban | 1 |
| 18963 | encareciendo | 1 |
| 18964 | encarcelado | 1 |
| 18965 | encaraman | 1 |
| 18966 | encaramaban | 1 |
| 18967 | encaprichara | 1 |
| 18968 | encaprichadas | 1 |
| 18969 | encapotado | 1 |
| 18970 | encantar | 1 |
| 18971 | encantadora | 1 |
| 18972 | encajarte | 1 |
| 18973 | encajan | 1 |
| 18974 | enanos | 1 |
| 18975 | enano | 1 |
| 18976 | enamoro | 1 |
| 18977 | enamoren | 1 |
| 18978 | enamorarla | 1 |
| 18979 | enamorándome | 1 |
| 18980 | enamoran | 1 |
| 18981 | enamoramiento | 1 |
| 18982 | enamoraba | 1 |
| 18983 | enaltecerla | 1 |
| 18984 | enajenación | 1 |
| 18985 | emulación | 1 |
| 18986 | empuño | 1 |
| 18987 | empuñar | 1 |
| 18988 | empuñando | 1 |
| 18989 | empujón | 1 |
| 18990 | empuje | 1 |
| 18991 | empujasen | 1 |
| 18992 | empujando | 1 |
| 18993 | empujado | 1 |
| 18994 | empujaban | 1 |
| 18995 | emprendieron | 1 |
| 18996 | emprendían | 1 |
| 18997 | emprenderla | 1 |
| 18998 | emprendemos | 1 |
| 18999 | emprendedor | 1 |
| 19000 | empotrados | 1 |
| 19001 | empotrado | 1 |
| 19002 | empolvado | 1 |
| 19003 | empolvada | 1 |
| 19004 | empleos | 1 |
| 19005 | emplearse | 1 |
| 19006 | empleará | 1 |
| 19007 | empleara | 1 |
| 19008 | empleando | 1 |
| 19009 | emplea | 1 |
| 19010 | emplazamiento | 1 |
| 19011 | emplastos | 1 |
| 19012 | empingorotados | 1 |
| 19013 | empingorotado | 1 |
| 19014 | empinados | 1 |
| 19015 | empinada | 1 |
| 19016 | empezara | 1 |
| 19017 | empezamos | 1 |
| 19018 | empero | 1 |
| 19019 | emperifolladas | 1 |
| 19020 | emperador | 1 |
| 19021 | empequeñecido | 1 |
| 19022 | empeorar | 1 |
| 19023 | empeñas | 1 |
| 19024 | empeñaron | 1 |
| 19025 | empeñada | 1 |
| 19026 | empedrado | 1 |
| 19027 | empedradas | 1 |
| 19028 | empedrada | 1 |
| 19029 | empedernido | 1 |
| 19030 | empecía | 1 |
| 19031 | empecemos | 1 |
| 19032 | empecé | 1 |
| 19033 | empecatado | 1 |
| 19034 | empecatadas | 1 |
| 19035 | emparejó | 1 |
| 19036 | emparejarse | 1 |
| 19037 | emparejaron | 1 |
| 19038 | emparejaba | 1 |
| 19039 | emparedados | 1 |
| 19040 | emparedada | 1 |
| 19041 | empapelado | 1 |
| 19042 | empapando | 1 |
| 19043 | empapada | 1 |
| 19044 | empalmándose | 1 |
| 19045 | empalagosa | 1 |
| 19046 | empadronar | 1 |
| 19047 | emisarios | 1 |
| 19048 | emisario | 1 |
| 19049 | eminentemente | 1 |
| 19050 | eminente | 1 |
| 19051 | emigró | 1 |
| 19052 | emigrar | 1 |
| 19053 | emigrada | 1 |
| 19054 | embutiendo | 1 |
| 19055 | embutida | 1 |
| 19056 | embute | 1 |
| 19057 | embustera | 1 |
| 19058 | embuste | 1 |
| 19059 | embrutecimiento | 1 |
| 19060 | embrutecían | 1 |
| 19061 | embrutecía | 1 |
| 19062 | embrujado | 1 |
| 19063 | embrollo | 1 |
| 19064 | embrollado | 1 |
| 19065 | embrollaba | 1 |
| 19066 | embrión | 1 |
| 19067 | embriagada | 1 |
| 19068 | embozarse | 1 |
| 19069 | embozándose | 1 |
| 19070 | embozando | 1 |
| 19071 | embozan | 1 |
| 19072 | embozadas | 1 |
| 19073 | embozada | 1 |
| 19074 | embozaban | 1 |
| 19075 | embozaba | 1 |
| 19076 | embotar | 1 |
| 19077 | emboscadas | 1 |
| 19078 | emborracharle | 1 |
| 19079 | emborrachan | 1 |
| 19080 | emborrachaban | 1 |
| 19081 | emborrachaba | 1 |
| 19082 | embobado | 1 |
| 19083 | embelleció | 1 |
| 19084 | embeleso | 1 |
| 19085 | embebecido | 1 |
| 19086 | embargó | 1 |
| 19087 | embarcarte | 1 |
| 19088 | embarazosos | 1 |
| 19089 | embarazosas | 1 |
| 19090 | embajada | 1 |
| 19091 | emanciparse | 1 |
| 19092 | emancipado | 1 |
| 19093 | emancipación | 1 |
| 19094 | eludiendo | 1 |
| 19095 | eloïm | 1 |
| 19096 | elogiando | 1 |
| 19097 | élite | 1 |
| 19098 | eligiesen | 1 |
| 19099 | elevados | 1 |
| 19100 | elevada | 1 |
| 19101 | elegido | 1 |
| 19102 | elegida | 1 |
| 19103 | elegíaca | 1 |
| 19104 | elegantón | 1 |
| 19105 | elegantemente | 1 |
| 19106 | elegancias | 1 |
| 19107 | elefante | 1 |
| 19108 | eléctricos | 1 |
| 19109 | electores | 1 |
| 19110 | elector | 1 |
| 19111 | elástico | 1 |
| 19112 | elaboración | 1 |
| 19113 | ejercitaba | 1 |
| 19114 | ejerció | 1 |
| 19115 | ejerciendo | 1 |
| 19116 | ejercido | 1 |
| 19117 | ejemplos | 1 |
| 19118 | ejecutor | 1 |
| 19119 | ejecutivo | 1 |
| 19120 | ejecución | 1 |
| 19121 | egoístas | 1 |
| 19122 | ego | 1 |
| 19123 | églogas | 1 |
| 19124 | égloga | 1 |
| 19125 | egipcias | 1 |
| 19126 | egida | 1 |
| 19127 | egeria | 1 |
| 19128 | efusivo | 1 |
| 19129 | efluvios | 1 |
| 19130 | efímeros | 1 |
| 19131 | efímera | 1 |
| 19132 | efectiva | 1 |
| 19133 | educó | 1 |
| 19134 | educar | 1 |
| 19135 | eduardo | 1 |
| 19136 | editores | 1 |
| 19137 | editor | 1 |
| 19138 | edificando | 1 |
| 19139 | edifican | 1 |
| 19140 | edificaba | 1 |
| 19141 | edicto | 1 |
| 19142 | edgar | 1 |
| 19143 | edemíaca | 1 |
| 19144 | ecuestre | 1 |
| 19145 | ecos | 1 |
| 19146 | economizarlo | 1 |
| 19147 | economista | 1 |
| 19148 | económica | 1 |
| 19149 | economato | 1 |
| 19150 | eclipses | 1 |
| 19151 | eclipsar | 1 |
| 19152 | eciomo | 1 |
| 19153 | échele | 1 |
| 19154 | echasen | 1 |
| 19155 | echas | 1 |
| 19156 | echarlos | 1 |
| 19157 | echándole | 1 |
| 19158 | echados | 1 |
| 19159 | ecco | 1 |
| 19160 | ebro | 1 |
| 19161 | ebria | 1 |
| 19162 | ébano | 1 |
| 19163 | ebanista | 1 |
| 19164 | è | 1 |
| 19165 | é | 1 |
| 19166 | durmiese | 1 |
| 19167 | durmiéndola | 1 |
| 19168 | durmiendo | 1 |
| 19169 | dure | 1 |
| 19170 | durase | 1 |
| 19171 | durará | 1 |
| 19172 | duraderos | 1 |
| 19173 | duración | 1 |
| 19174 | dupanloup | 1 |
| 19175 | dúo | 1 |
| 19176 | dumio | 1 |
| 19177 | dum | 1 |
| 19178 | dulzones | 1 |
| 19179 | dulzón | 1 |
| 19180 | dulcísimo | 1 |
| 19181 | duermes | 1 |
| 19182 | duerma | 1 |
| 19183 | dueña | 1 |
| 19184 | duelos | 1 |
| 19185 | dudoso | 1 |
| 19186 | dudosas | 1 |
| 19187 | dudosa | 1 |
| 19188 | dudemos | 1 |
| 19189 | dudase | 1 |
| 19190 | dudando | 1 |
| 19191 | dudaban | 1 |
| 19192 | dúctil | 1 |
| 19193 | duchas | 1 |
| 19194 | dualista | 1 |
| 19195 | dramaturgo | 1 |
| 19196 | dramáticas | 1 |
| 19197 | dovelas | 1 |
| 19198 | dotó | 1 |
| 19199 | dotar | 1 |
| 19200 | dotada | 1 |
| 19201 | dosis | 1 |
| 19202 | dosimétrico | 1 |
| 19203 | doseletes | 1 |
| 19204 | dorso | 1 |
| 19205 | dormitorio | 1 |
| 19206 | dormitar | 1 |
| 19207 | dormitan | 1 |
| 19208 | dormitaban | 1 |
| 19209 | dormitaba | 1 |
| 19210 | dormiremos | 1 |
| 19211 | dormidas | 1 |
| 19212 | dórico | 1 |
| 19213 | donosura | 1 |
| 19214 | donosa | 1 |
| 19215 | domini | 1 |
| 19216 | domingos | 1 |
| 19217 | dómine | 1 |
| 19218 | dominase | 1 |
| 19219 | dominarnos | 1 |
| 19220 | dominarla | 1 |
| 19221 | dominándolos | 1 |
| 19222 | dominándola | 1 |
| 19223 | dominados | 1 |
| 19224 | dominada | 1 |
| 19225 | domina | 1 |
| 19226 | domiciliada | 1 |
| 19227 | domésticas | 1 |
| 19228 | domesticado | 1 |
| 19229 | domaba | 1 |
| 19230 | dolorosos | 1 |
| 19231 | döllinger | 1 |
| 19232 | dolido | 1 |
| 19233 | dolería | 1 |
| 19234 | dogmáticos | 1 |
| 19235 | dogmático | 1 |
| 19236 | dogmáticas | 1 |
| 19237 | documento | 1 |
| 19238 | doctrino | 1 |
| 19239 | docente | 1 |
| 19240 | doceañista | 1 |
| 19241 | doblaron | 1 |
| 19242 | doblándose | 1 |
| 19243 | doblado | 1 |
| 19244 | dobla | 1 |
| 19245 | dixit | 1 |
| 19246 | divulgar | 1 |
| 19247 | divulgado | 1 |
| 19248 | divisó | 1 |
| 19249 | divisibles | 1 |
| 19250 | divisas | 1 |
| 19251 | divisar | 1 |
| 19252 | divirtiendo | 1 |
| 19253 | divinos | 1 |
| 19254 | divinam | 1 |
| 19255 | divido | 1 |
| 19256 | dividió | 1 |
| 19257 | dividido | 1 |
| 19258 | divertirme | 1 |
| 19259 | divertiría | 1 |
| 19260 | divertidísima | 1 |
| 19261 | disuelven | 1 |
| 19262 | disuelve | 1 |
| 19263 | disueltas | 1 |
| 19264 | disuelta | 1 |
| 19265 | disuadir | 1 |
| 19266 | disuadía | 1 |
| 19267 | distributiva | 1 |
| 19268 | distribución | 1 |
| 19269 | distrajo | 1 |
| 19270 | distrajeran | 1 |
| 19271 | distrajera | 1 |
| 19272 | distraídas | 1 |
| 19273 | distraían | 1 |
| 19274 | distraerte | 1 |
| 19275 | distraerle | 1 |
| 19276 | distraerla | 1 |
| 19277 | distraerían | 1 |
| 19278 | distraer | 1 |
| 19279 | distrae | 1 |
| 19280 | distintivo | 1 |
| 19281 | distintamente | 1 |
| 19282 | distinguirse | 1 |
| 19283 | distinguirlos | 1 |
| 19284 | distinguirlo | 1 |
| 19285 | distinguió | 1 |
| 19286 | distinguidísimo | 1 |
| 19287 | distingue | 1 |
| 19288 | distinciones | 1 |
| 19289 | disputó | 1 |
| 19290 | disputárselo | 1 |
| 19291 | disputaron | 1 |
| 19292 | disputándose | 1 |
| 19293 | dispusiera | 1 |
| 19294 | disposiciones | 1 |
| 19295 | disponiendo | 1 |
| 19296 | disponían | 1 |
| 19297 | disponerse | 1 |
| 19298 | displicencia | 1 |
| 19299 | dispersos | 1 |
| 19300 | dispersión | 1 |
| 19301 | dispersar | 1 |
| 19302 | dispersándose | 1 |
| 19303 | dispersado | 1 |
| 19304 | dispersa | 1 |
| 19305 | dispensase | 1 |
| 19306 | dispensado | 1 |
| 19307 | disparo | 1 |
| 19308 | disparitas | 1 |
| 19309 | disparatando | 1 |
| 19310 | disparatado | 1 |
| 19311 | disparataba | 1 |
| 19312 | disolvió | 1 |
| 19313 | disolviera | 1 |
| 19314 | disolvían | 1 |
| 19315 | disolvía | 1 |
| 19316 | disolverse | 1 |
| 19317 | disoluta | 1 |
| 19318 | disminuyó | 1 |
| 19319 | disminuyendo | 1 |
| 19320 | disminuían | 1 |
| 19321 | disminuía | 1 |
| 19322 | dislocado | 1 |
| 19323 | dislocada | 1 |
| 19324 | dislate | 1 |
| 19325 | disipar | 1 |
| 19326 | disimulase | 1 |
| 19327 | disimularon | 1 |
| 19328 | disimularlos | 1 |
| 19329 | disgustillo | 1 |
| 19330 | disgustarse | 1 |
| 19331 | disgustaron | 1 |
| 19332 | disgustarle | 1 |
| 19333 | disgustan | 1 |
| 19334 | disfrazasen | 1 |
| 19335 | disfrazase | 1 |
| 19336 | disfrazadas | 1 |
| 19337 | disfrazada | 1 |
| 19338 | disertaciones | 1 |
| 19339 | disertación | 1 |
| 19340 | disertaba | 1 |
| 19341 | discutirla | 1 |
| 19342 | discutiría | 1 |
| 19343 | discutiendo | 1 |
| 19344 | discursito | 1 |
| 19345 | discurrió | 1 |
| 19346 | discurrido | 1 |
| 19347 | disculparlo | 1 |
| 19348 | disculpando | 1 |
| 19349 | disculpables | 1 |
| 19350 | discretísimas | 1 |
| 19351 | discreteo | 1 |
| 19352 | discretas | 1 |
| 19353 | discípulos | 1 |
| 19354 | disciplinarias | 1 |
| 19355 | disciplentes | 1 |
| 19356 | discernir | 1 |
| 19357 | dirigiese | 1 |
| 19358 | dirigieron | 1 |
| 19359 | diríase | 1 |
| 19360 | diretes | 1 |
| 19361 | diremos | 1 |
| 19362 | directores | 1 |
| 19363 | directo | 1 |
| 19364 | direcciones | 1 |
| 19365 | dirás | 1 |
| 19366 | diputación | 1 |
| 19367 | diplomática | 1 |
| 19368 | dionisíacas | 1 |
| 19369 | dintel | 1 |
| 19370 | dinidad | 1 |
| 19371 | dinásticos | 1 |
| 19372 | dinastía | 1 |
| 19373 | dimisionario | 1 |
| 19374 | diminuto | 1 |
| 19375 | dimes | 1 |
| 19376 | dilucidar | 1 |
| 19377 | diligentes | 1 |
| 19378 | diligente | 1 |
| 19379 | dile | 1 |
| 19380 | dilatación | 1 |
| 19381 | dilacerar | 1 |
| 19382 | díjolo | 1 |
| 19383 | dijes | 1 |
| 19384 | dignificar | 1 |
| 19385 | dignidades | 1 |
| 19386 | dignatario | 1 |
| 19387 | dignase | 1 |
| 19388 | dignarse | 1 |
| 19389 | dignaba | 1 |
| 19390 | digestivas | 1 |
| 19391 | digería | 1 |
| 19392 | díganme | 1 |
| 19393 | digamos | 1 |
| 19394 | dígame | 1 |
| 19395 | difuntas | 1 |
| 19396 | difundirse | 1 |
| 19397 | difundían | 1 |
| 19398 | dificultaban | 1 |
| 19399 | dificultaba | 1 |
| 19400 | dificilísima | 1 |
| 19401 | diezmos | 1 |
| 19402 | dieta | 1 |
| 19403 | diestra | 1 |
| 19404 | diesen | 1 |
| 19405 | dies | 1 |
| 19406 | diéramos | 1 |
| 19407 | diecisiete | 1 |
| 19408 | die | 1 |
| 19409 | dictatorial | 1 |
| 19410 | dictaría | 1 |
| 19411 | dictando | 1 |
| 19412 | dictan | 1 |
| 19413 | dictamen | 1 |
| 19414 | dictadura | 1 |
| 19415 | dico | 1 |
| 19416 | dickens | 1 |
| 19417 | diciéndoselo | 1 |
| 19418 | diciéndome | 1 |
| 19419 | dichosos | 1 |
| 19420 | dichosas | 1 |
| 19421 | dichos | 1 |
| 19422 | dicharacheros | 1 |
| 19423 | dibujó | 1 |
| 19424 | dibujar | 1 |
| 19425 | dibujándose | 1 |
| 19426 | dibujando | 1 |
| 19427 | dibujado | 1 |
| 19428 | dibujaban | 1 |
| 19429 | dibujaba | 1 |
| 19430 | diapasón | 1 |
| 19431 | diana | 1 |
| 19432 | diaforético | 1 |
| 19433 | diáfano | 1 |
| 19434 | diácono | 1 |
| 19435 | diablesas | 1 |
| 19436 | diablejo | 1 |
| 19437 | devuelto | 1 |
| 19438 | devorándola | 1 |
| 19439 | devoran | 1 |
| 19440 | devora | 1 |
| 19441 | devolvió | 1 |
| 19442 | devolvieran | 1 |
| 19443 | devolviéndole | 1 |
| 19444 | devolviendo | 1 |
| 19445 | devolvían | 1 |
| 19446 | devocionarios | 1 |
| 19447 | devastación | 1 |
| 19448 | devaneo | 1 |
| 19449 | devanadera | 1 |
| 19450 | deux | 1 |
| 19451 | deus | 1 |
| 19452 | deudo | 1 |
| 19453 | detuvieron | 1 |
| 19454 | detuviera | 1 |
| 19455 | detractores | 1 |
| 19456 | detonación | 1 |
| 19457 | determinarse | 1 |
| 19458 | determinaron | 1 |
| 19459 | determinadas | 1 |
| 19460 | determinación | 1 |
| 19461 | determinaban | 1 |
| 19462 | determinaba | 1 |
| 19463 | deteriorando | 1 |
| 19464 | detenido | 1 |
| 19465 | detenidamente | 1 |
| 19466 | detenida | 1 |
| 19467 | detenerlo | 1 |
| 19468 | detenerle | 1 |
| 19469 | detener | 1 |
| 19470 | detenemos | 1 |
| 19471 | detalles | 1 |
| 19472 | desvivo | 1 |
| 19473 | desviadas | 1 |
| 19474 | desvergüenza | 1 |
| 19475 | desvergonzarse | 1 |
| 19476 | desvergonzados | 1 |
| 19477 | desvergonzado | 1 |
| 19478 | desventurada | 1 |
| 19479 | desvencijado | 1 |
| 19480 | desvencijadas | 1 |
| 19481 | desvelos | 1 |
| 19482 | desvelada | 1 |
| 19483 | desvaríos | 1 |
| 19484 | desvaneció | 1 |
| 19485 | desvanecimiento | 1 |
| 19486 | desvaneciéndose | 1 |
| 19487 | desvaneciendo | 1 |
| 19488 | desvanecidos | 1 |
| 19489 | desvanecidas | 1 |
| 19490 | desvanecíase | 1 |
| 19491 | desvanecen | 1 |
| 19492 | desván | 1 |
| 19493 | desvalijado | 1 |
| 19494 | desuso | 1 |
| 19495 | destruyó | 1 |
| 19496 | destruyeron | 1 |
| 19497 | destruía | 1 |
| 19498 | destrucción | 1 |
| 19499 | destrozarme | 1 |
| 19500 | destrozáis | 1 |
| 19501 | destrozado | 1 |
| 19502 | destreza | 1 |
| 19503 | destocándose | 1 |
| 19504 | destocado | 1 |
| 19505 | destinados | 1 |
| 19506 | destinaba | 1 |
| 19507 | desterrada | 1 |
| 19508 | desteñía | 1 |
| 19509 | destemplado | 1 |
| 19510 | destempladas | 1 |
| 19511 | destartalado | 1 |
| 19512 | destajo | 1 |
| 19513 | destacaban | 1 |
| 19514 | desquitaba | 1 |
| 19515 | despuntaba | 1 |
| 19516 | desprovistos | 1 |
| 19517 | despropósito | 1 |
| 19518 | desproporcionadas | 1 |
| 19519 | desprestigio | 1 |
| 19520 | despreocupada | 1 |
| 19521 | desprendido | 1 |
| 19522 | desprenderse | 1 |
| 19523 | despreció | 1 |
| 19524 | despreciase | 1 |
| 19525 | despreciarse | 1 |
| 19526 | despreciaros | 1 |
| 19527 | despreciara | 1 |
| 19528 | despreciándolos | 1 |
| 19529 | despreciándole | 1 |
| 19530 | despreciándolas | 1 |
| 19531 | despojo | 1 |
| 19532 | despojaban | 1 |
| 19533 | despojaba | 1 |
| 19534 | despoblado | 1 |
| 19535 | desplumarle | 1 |
| 19536 | desplumaban | 1 |
| 19537 | desplomarse | 1 |
| 19538 | desplomaba | 1 |
| 19539 | desplieguen | 1 |
| 19540 | despilfarro | 1 |
| 19541 | despidiéndose | 1 |
| 19542 | despidiendo | 1 |
| 19543 | despídete | 1 |
| 19544 | despídame | 1 |
| 19545 | despertarnos | 1 |
| 19546 | despertarle | 1 |
| 19547 | despertadora | 1 |
| 19548 | desperezarse | 1 |
| 19549 | desperdicios | 1 |
| 19550 | desperdiciado | 1 |
| 19551 | despeñada | 1 |
| 19552 | despeluznado | 1 |
| 19553 | despellejarse | 1 |
| 19554 | despellejaban | 1 |
| 19555 | despellejaba | 1 |
| 19556 | despejarse | 1 |
| 19557 | despejados | 1 |
| 19558 | despejadas | 1 |
| 19559 | despejada | 1 |
| 19560 | despeinarse | 1 |
| 19561 | despego | 1 |
| 19562 | despedirlos | 1 |
| 19563 | despedido | 1 |
| 19564 | despedazara | 1 |
| 19565 | despedazar | 1 |
| 19566 | despedazado | 1 |
| 19567 | despearse | 1 |
| 19568 | despeada | 1 |
| 19569 | despavorida | 1 |
| 19570 | desparramándose | 1 |
| 19571 | desparramaban | 1 |
| 19572 | despache | 1 |
| 19573 | despachar | 1 |
| 19574 | despachaba | 1 |
| 19575 | despabilaban | 1 |
| 19576 | desorientada | 1 |
| 19577 | desollar | 1 |
| 19578 | desolación | 1 |
| 19579 | desocupados | 1 |
| 19580 | desocupadas | 1 |
| 19581 | desnudó | 1 |
| 19582 | desnudeces | 1 |
| 19583 | desnudar | 1 |
| 19584 | desmoronarse | 1 |
| 19585 | desmoronar | 1 |
| 19586 | desmorona | 1 |
| 19587 | desmesurada | 1 |
| 19588 | desmentía | 1 |
| 19589 | desmedida | 1 |
| 19590 | desmayos | 1 |
| 19591 | desmayo | 1 |
| 19592 | desmayé | 1 |
| 19593 | desmayaron | 1 |
| 19594 | desmayados | 1 |
| 19595 | desmayadas | 1 |
| 19596 | desmayaba | 1 |
| 19597 | desmaya | 1 |
| 19598 | desmañado | 1 |
| 19599 | desmantelada | 1 |
| 19600 | desmanes | 1 |
| 19601 | desmadejado | 1 |
| 19602 | desmadejadas | 1 |
| 19603 | deslumbro | 1 |
| 19604 | deslumbradora | 1 |
| 19605 | deslumbrada | 1 |
| 19606 | deslumbraban | 1 |
| 19607 | deslizó | 1 |
| 19608 | deslizarse | 1 |
| 19609 | desliz | 1 |
| 19610 | deslices | 1 |
| 19611 | desleído | 1 |
| 19612 | desistieron | 1 |
| 19613 | desistido | 1 |
| 19614 | desiguales | 1 |
| 19615 | desigualdades | 1 |
| 19616 | desiertas | 1 |
| 19617 | desidia | 1 |
| 19618 | deshora | 1 |
| 19619 | deshonran | 1 |
| 19620 | deshonrada | 1 |
| 19621 | deshonesto | 1 |
| 19622 | deshojadas | 1 |
| 19623 | deshilachaban | 1 |
| 19624 | desheredados | 1 |
| 19625 | deshechas | 1 |
| 19626 | desharía | 1 |
| 19627 | deshaciéndola | 1 |
| 19628 | deshacían | 1 |
| 19629 | deshacer | 1 |
| 19630 | deshacen | 1 |
| 19631 | deshace | 1 |
| 19632 | desgarrarse | 1 |
| 19633 | desgarrando | 1 |
| 19634 | desgarrador | 1 |
| 19635 | desgarradas | 1 |
| 19636 | desgarrada | 1 |
| 19637 | desgarraban | 1 |
| 19638 | desgajarse | 1 |
| 19639 | desfiladero | 1 |
| 19640 | desfavorable | 1 |
| 19641 | desfallecimiento | 1 |
| 19642 | desfallecidos | 1 |
| 19643 | desfallecía | 1 |
| 19644 | desestero | 1 |
| 19645 | desespera | 1 |
| 19646 | deseoso | 1 |
| 19647 | desenvoltura | 1 |
| 19648 | desentonar | 1 |
| 19649 | desentona | 1 |
| 19650 | desenterrado | 1 |
| 19651 | desentendido | 1 |
| 19652 | desenlace | 1 |
| 19653 | desengañados | 1 |
| 19654 | desengañadas | 1 |
| 19655 | desenfreno | 1 |
| 19656 | desenfado | 1 |
| 19657 | desencanto | 1 |
| 19658 | desencadenado | 1 |
| 19659 | desempeñado | 1 |
| 19660 | desempeña | 1 |
| 19661 | desembolsos | 1 |
| 19662 | desembarco | 1 |
| 19663 | desecho | 1 |
| 19664 | desechado | 1 |
| 19665 | desechaban | 1 |
| 19666 | deseara | 1 |
| 19667 | dese | 1 |
| 19668 | desdoro | 1 |
| 19669 | desdiga | 1 |
| 19670 | desdentada | 1 |
| 19671 | descuidos | 1 |
| 19672 | descuidillo | 1 |
| 19673 | descuidarse | 1 |
| 19674 | descuidada | 1 |
| 19675 | descuidaba | 1 |
| 19676 | descubrirse | 1 |
| 19677 | descubrirlos | 1 |
| 19678 | descubrirlo | 1 |
| 19679 | descubrieron | 1 |
| 19680 | descubrieran | 1 |
| 19681 | descubriéndole | 1 |
| 19682 | descubridor | 1 |
| 19683 | descubría | 1 |
| 19684 | descubiertas | 1 |
| 19685 | descuartizaba | 1 |
| 19686 | descriptivas | 1 |
| 19687 | descripciones | 1 |
| 19688 | describe | 1 |
| 19689 | descreimiento | 1 |
| 19690 | descreídas | 1 |
| 19691 | descotada | 1 |
| 19692 | descoser | 1 |
| 19693 | descontenta | 1 |
| 19694 | desconsoladoras | 1 |
| 19695 | desconsolador | 1 |
| 19696 | desconocidos | 1 |
| 19697 | desconocíamos | 1 |
| 19698 | desconocen | 1 |
| 19699 | desconcierto | 1 |
| 19700 | descomponiéndose | 1 |
| 19701 | descomponerla | 1 |
| 19702 | descompone | 1 |
| 19703 | descompasado | 1 |
| 19704 | descollando | 1 |
| 19705 | descollaban | 1 |
| 19706 | descolgarse | 1 |
| 19707 | descolgarla | 1 |
| 19708 | descolgaba | 1 |
| 19709 | descoco | 1 |
| 19710 | desciñó | 1 |
| 19711 | descifró | 1 |
| 19712 | descifrarlas | 1 |
| 19713 | desceñida | 1 |
| 19714 | descenso | 1 |
| 19715 | descendimiento | 1 |
| 19716 | descendiendo | 1 |
| 19717 | descendía | 1 |
| 19718 | descastada | 1 |
| 19719 | descarnadas | 1 |
| 19720 | descarnada | 1 |
| 19721 | descarnaba | 1 |
| 19722 | descargaría | 1 |
| 19723 | descargado | 1 |
| 19724 | descargada | 1 |
| 19725 | descarada | 1 |
| 19726 | descanse | 1 |
| 19727 | descansan | 1 |
| 19728 | descansaban | 1 |
| 19729 | descaminos | 1 |
| 19730 | descaminada | 1 |
| 19731 | descalzo | 1 |
| 19732 | descalzaba | 1 |
| 19733 | descabellado | 1 |
| 19734 | desbordar | 1 |
| 19735 | desbordado | 1 |
| 19736 | desbanque | 1 |
| 19737 | desbancado | 1 |
| 19738 | desazones | 1 |
| 19739 | desayuno | 1 |
| 19740 | desatinos | 1 |
| 19741 | desatino | 1 |
| 19742 | desatinada | 1 |
| 19743 | desataron | 1 |
| 19744 | desataban | 1 |
| 19745 | desata | 1 |
| 19746 | desasosiego | 1 |
| 19747 | desasirse | 1 |
| 19748 | desarróllase | 1 |
| 19749 | desarrolla | 1 |
| 19750 | desarreglos | 1 |
| 19751 | desaprobación | 1 |
| 19752 | desapasionado | 1 |
| 19753 | desapartarse | 1 |
| 19754 | desaparición | 1 |
| 19755 | desaparecieron | 1 |
| 19756 | desapareciera | 1 |
| 19757 | desaparecíamos | 1 |
| 19758 | desapacible | 1 |
| 19759 | desanimar | 1 |
| 19760 | desanimaba | 1 |
| 19761 | desanduvo | 1 |
| 19762 | desandando | 1 |
| 19763 | desamparado | 1 |
| 19764 | desaliño | 1 |
| 19765 | desalientos | 1 |
| 19766 | desalentada | 1 |
| 19767 | desalado | 1 |
| 19768 | desairarlos | 1 |
| 19769 | desairarle | 1 |
| 19770 | desairarla | 1 |
| 19771 | desairados | 1 |
| 19772 | desairadas | 1 |
| 19773 | desairada | 1 |
| 19774 | desahuciarlo | 1 |
| 19775 | desahuciado | 1 |
| 19776 | desahogue | 1 |
| 19777 | desahogan | 1 |
| 19778 | desahogaban | 1 |
| 19779 | desagravio | 1 |
| 19780 | desagradecida | 1 |
| 19781 | desafió | 1 |
| 19782 | desafíe | 1 |
| 19783 | desafiarle | 1 |
| 19784 | desafiaría | 1 |
| 19785 | desacreditó | 1 |
| 19786 | desacreditarse | 1 |
| 19787 | desacreditar | 1 |
| 19788 | desacreditándote | 1 |
| 19789 | desacreditan | 1 |
| 19790 | desacredita | 1 |
| 19791 | desaciertos | 1 |
| 19792 | desabrochándose | 1 |
| 19793 | desabrimiento | 1 |
| 19794 | des | 1 |
| 19795 | derrumbara | 1 |
| 19796 | derrumbar | 1 |
| 19797 | derrotada | 1 |
| 19798 | derrota | 1 |
| 19799 | derrochaban | 1 |
| 19800 | derritiéndose | 1 |
| 19801 | derríbela | 1 |
| 19802 | derribarme | 1 |
| 19803 | derribarle | 1 |
| 19804 | derribado | 1 |
| 19805 | derribaba | 1 |
| 19806 | derretirá | 1 |
| 19807 | derretían | 1 |
| 19808 | derrengado | 1 |
| 19809 | derramó | 1 |
| 19810 | derrame | 1 |
| 19811 | derramarse | 1 |
| 19812 | derramamiento | 1 |
| 19813 | derivados | 1 |
| 19814 | derivación | 1 |
| 19815 | depresivo | 1 |
| 19816 | deprecaba | 1 |
| 19817 | depositario | 1 |
| 19818 | depositando | 1 |
| 19819 | depositado | 1 |
| 19820 | depositadas | 1 |
| 19821 | depositaban | 1 |
| 19822 | depositaba | 1 |
| 19823 | dependiese | 1 |
| 19824 | dependiente | 1 |
| 19825 | depender | 1 |
| 19826 | depende | 1 |
| 19827 | departamentos | 1 |
| 19828 | departamento | 1 |
| 19829 | dentera | 1 |
| 19830 | dentadura | 1 |
| 19831 | densidad | 1 |
| 19832 | densa | 1 |
| 19833 | dengue | 1 |
| 19834 | den | 1 |
| 19835 | demuestran | 1 |
| 19836 | demostré | 1 |
| 19837 | demostraban | 1 |
| 19838 | demontres | 1 |
| 19839 | demonche | 1 |
| 19840 | demoler | 1 |
| 19841 | demodoco | 1 |
| 19842 | demócratas | 1 |
| 19843 | demasía | 1 |
| 19844 | demanda | 1 |
| 19845 | demagogo | 1 |
| 19846 | demagoga | 1 |
| 19847 | deliró | 1 |
| 19848 | delirado | 1 |
| 19849 | deliraba | 1 |
| 19850 | delincuentes | 1 |
| 19851 | delincuente | 1 |
| 19852 | deliciosos | 1 |
| 19853 | delicadísimo | 1 |
| 19854 | delicadísima | 1 |
| 19855 | delicadezas | 1 |
| 19856 | deliberó | 1 |
| 19857 | deliberemos | 1 |
| 19858 | deliberase | 1 |
| 19859 | deliberaron | 1 |
| 19860 | deliberar | 1 |
| 19861 | deliberado | 1 |
| 19862 | delgadilla | 1 |
| 19863 | deletéreos | 1 |
| 19864 | deleites | 1 |
| 19865 | deleitasen | 1 |
| 19866 | deleitábale | 1 |
| 19867 | delegado | 1 |
| 19868 | delegación | 1 |
| 19869 | delatores | 1 |
| 19870 | delator | 1 |
| 19871 | delató | 1 |
| 19872 | delatase | 1 |
| 19873 | delatarse | 1 |
| 19874 | delataron | 1 |
| 19875 | delatar | 1 |
| 19876 | delataban | 1 |
| 19877 | delataba | 1 |
| 19878 | delanteros | 1 |
| 19879 | delantera | 1 |
| 19880 | dejose | 1 |
| 19881 | dejémoslo | 1 |
| 19882 | déjele | 1 |
| 19883 | dejaste | 1 |
| 19884 | dejarlas | 1 |
| 19885 | dejarían | 1 |
| 19886 | dejaré | 1 |
| 19887 | dejaras | 1 |
| 19888 | déjala | 1 |
| 19889 | déjà | 1 |
| 19890 | deísmo | 1 |
| 19891 | degradarse | 1 |
| 19892 | degradarla | 1 |
| 19893 | degradan | 1 |
| 19894 | degradado | 1 |
| 19895 | degollarla | 1 |
| 19896 | degollar | 1 |
| 19897 | degollado | 1 |
| 19898 | degli | 1 |
| 19899 | degeneraba | 1 |
| 19900 | defraudaba | 1 |
| 19901 | deforme | 1 |
| 19902 | definitivo | 1 |
| 19903 | definitivamente | 1 |
| 19904 | definirse | 1 |
| 19905 | definía | 1 |
| 19906 | defienden | 1 |
| 19907 | defiende | 1 |
| 19908 | deficiencias | 1 |
| 19909 | defensor | 1 |
| 19910 | defensiva | 1 |
| 19911 | defensas | 1 |
| 19912 | defendió | 1 |
| 19913 | defendiera | 1 |
| 19914 | defendiendo | 1 |
| 19915 | defenderle | 1 |
| 19916 | defenderla | 1 |
| 19917 | defectillo | 1 |
| 19918 | deducía | 1 |
| 19919 | dedique | 1 |
| 19920 | dedicar | 1 |
| 19921 | dedicándonos | 1 |
| 19922 | decurión | 1 |
| 19923 | decretos | 1 |
| 19924 | decretó | 1 |
| 19925 | decretado | 1 |
| 19926 | decoración | 1 |
| 19927 | declive | 1 |
| 19928 | declaro | 1 |
| 19929 | declarados | 1 |
| 19930 | declarada | 1 |
| 19931 | declaraciones | 1 |
| 19932 | declaraban | 1 |
| 19933 | declamador | 1 |
| 19934 | declamado | 1 |
| 19935 | declamaciones | 1 |
| 19936 | declamaba | 1 |
| 19937 | decisiva | 1 |
| 19938 | decisión | 1 |
| 19939 | decírtelo | 1 |
| 19940 | decírsele | 1 |
| 19941 | decirlos | 1 |
| 19942 | decimales | 1 |
| 19943 | décima | 1 |
| 19944 | decidores | 1 |
| 19945 | decidir | 1 |
| 19946 | decidiera | 1 |
| 19947 | decidiendo | 1 |
| 19948 | decididamente | 1 |
| 19949 | decidía | 1 |
| 19950 | decidí | 1 |
| 19951 | decida | 1 |
| 19952 | decíale | 1 |
| 19953 | decentemente | 1 |
| 19954 | decantado | 1 |
| 19955 | decálogo | 1 |
| 19956 | decaimientos | 1 |
| 19957 | decaído | 1 |
| 19958 | decadencias | 1 |
| 19959 | debiste | 1 |
| 19960 | debilucho | 1 |
| 19961 | débilmente | 1 |
| 19962 | debilitado | 1 |
| 19963 | debiéramos | 1 |
| 19964 | debiéndolo | 1 |
| 19965 | debida | 1 |
| 19966 | debíase | 1 |
| 19967 | debías | 1 |
| 19968 | debérsela | 1 |
| 19969 | deberían | 1 |
| 19970 | debería | 1 |
| 19971 | davídicas | 1 |
| 19972 | dativo | 1 |
| 19973 | das | 1 |
| 19974 | darwinista | 1 |
| 19975 | darwin | 1 |
| 19976 | dárselos | 1 |
| 19977 | dárselo | 1 |
| 19978 | dárselas | 1 |
| 19979 | dársela | 1 |
| 19980 | darro | 1 |
| 19981 | darlos | 1 |
| 19982 | darla | 1 |
| 19983 | dardos | 1 |
| 19984 | dardo | 1 |
| 19985 | daños | 1 |
| 19986 | dañaría | 1 |
| 19987 | dañaba | 1 |
| 19988 | daña | 1 |
| 19989 | dante | 1 |
| 19990 | dándola | 1 |
| 19991 | damos | 1 |
| 19992 | damiselas | 1 |
| 19993 | dami | 1 |
| 19994 | dalila | 1 |
| 19995 | daga | 1 |
| 19996 | dadme | 1 |
| 19997 | custodire | 1 |
| 19998 | cúspide | 1 |
| 19999 | curtidos | 1 |
| 20000 | curtido | 1 |
| 20001 | cursilona | 1 |
| 20002 | currente | 1 |
| 20003 | curita | 1 |
| 20004 | curiosos | 1 |
| 20005 | curiosón | 1 |
| 20006 | curiosa | 1 |
| 20007 | curiales | 1 |
| 20008 | curial | 1 |
| 20009 | curarse | 1 |
| 20010 | curaría | 1 |
| 20011 | curando | 1 |
| 20012 | curada | 1 |
| 20013 | cúpula | 1 |
| 20014 | cuota | 1 |
| 20015 | cuñado | 1 |
| 20016 | cuñada | 1 |
| 20017 | cuneta | 1 |
| 20018 | cunero | 1 |
| 20019 | cundiese | 1 |
| 20020 | cúmulus | 1 |
| 20021 | cumulus | 1 |
| 20022 | cumplirse | 1 |
| 20023 | cumplirlas | 1 |
| 20024 | cumpliría | 1 |
| 20025 | cumplirá | 1 |
| 20026 | cumplimientos | 1 |
| 20027 | cumplimiento | 1 |
| 20028 | cumplieron | 1 |
| 20029 | cumplieran | 1 |
| 20030 | cumpliendo | 1 |
| 20031 | cumplidamente | 1 |
| 20032 | cumplen | 1 |
| 20033 | cumpleaños | 1 |
| 20034 | cumple | 1 |
| 20035 | cumplas | 1 |
| 20036 | cumín | 1 |
| 20037 | cum | 1 |
| 20038 | cultus | 1 |
| 20039 | cultivara | 1 |
| 20040 | cultivando | 1 |
| 20041 | cultivan | 1 |
| 20042 | cultas | 1 |
| 20043 | culparle | 1 |
| 20044 | culpar | 1 |
| 20045 | culpables | 1 |
| 20046 | culotte | 1 |
| 20047 | culinarias | 1 |
| 20048 | culata | 1 |
| 20049 | cuique | 1 |
| 20050 | cuide | 1 |
| 20051 | cuidase | 1 |
| 20052 | cuidara | 1 |
| 20053 | cuidada | 1 |
| 20054 | cueto | 1 |
| 20055 | cuestores | 1 |
| 20056 | cuestan | 1 |
| 20057 | cuernos | 1 |
| 20058 | cuerdamente | 1 |
| 20059 | cuentan | 1 |
| 20060 | cuellos | 1 |
| 20061 | cuelgue | 1 |
| 20062 | cuelgan | 1 |
| 20063 | cuelga | 1 |
| 20064 | cuchufletas | 1 |
| 20065 | cuchillos | 1 |
| 20066 | cuchicheando | 1 |
| 20067 | cucharilla | 1 |
| 20068 | cucharada | 1 |
| 20069 | cubrirse | 1 |
| 20070 | cubriera | 1 |
| 20071 | cubriéndolos | 1 |
| 20072 | cubriéndola | 1 |
| 20073 | cubríale | 1 |
| 20074 | cubren | 1 |
| 20075 | cubiletes | 1 |
| 20076 | cúbicos | 1 |
| 20077 | cuartucho | 1 |
| 20078 | cuartilla | 1 |
| 20079 | cuartetos | 1 |
| 20080 | cuartas | 1 |
| 20081 | cuajados | 1 |
| 20082 | cuadriculado | 1 |
| 20083 | cuadras | 1 |
| 20084 | cuadradillos | 1 |
| 20085 | cuadradas | 1 |
| 20086 | cuadraban | 1 |
| 20087 | cruzarse | 1 |
| 20088 | cruzar | 1 |
| 20089 | cruzan | 1 |
| 20090 | cruzada | 1 |
| 20091 | cruza | 1 |
| 20092 | crusología | 1 |
| 20093 | crujieron | 1 |
| 20094 | cruelísimo | 1 |
| 20095 | crueles | 1 |
| 20096 | crudos | 1 |
| 20097 | crudezas | 1 |
| 20098 | crudas | 1 |
| 20099 | crucifixión | 1 |
| 20100 | crucificó | 1 |
| 20101 | cronométrica | 1 |
| 20102 | cromo | 1 |
| 20103 | cromáticas | 1 |
| 20104 | croiset | 1 |
| 20105 | criticaron | 1 |
| 20106 | criticar | 1 |
| 20107 | criterios | 1 |
| 20108 | cristos | 1 |
| 20109 | cristóbal | 1 |
| 20110 | cristinos | 1 |
| 20111 | cristalino | 1 |
| 20112 | cristalinas | 1 |
| 20113 | cristalina | 1 |
| 20114 | cristalerías | 1 |
| 20115 | crispan | 1 |
| 20116 | crispados | 1 |
| 20117 | crispadas | 1 |
| 20118 | crisol | 1 |
| 20119 | crisálida | 1 |
| 20120 | crin | 1 |
| 20121 | criminalmente | 1 |
| 20122 | criaos | 1 |
| 20123 | criao | 1 |
| 20124 | criaban | 1 |
| 20125 | creyesen | 1 |
| 20126 | creyéndolo | 1 |
| 20127 | creó | 1 |
| 20128 | crema | 1 |
| 20129 | creías | 1 |
| 20130 | creíale | 1 |
| 20131 | creíala | 1 |
| 20132 | creernos | 1 |
| 20133 | creerlos | 1 |
| 20134 | creerlo | 1 |
| 20135 | creerle | 1 |
| 20136 | creerla | 1 |
| 20137 | creerían | 1 |
| 20138 | creerás | 1 |
| 20139 | creerán | 1 |
| 20140 | crédulas | 1 |
| 20141 | crédula | 1 |
| 20142 | creciese | 1 |
| 20143 | creciendo | 1 |
| 20144 | crecían | 1 |
| 20145 | creces | 1 |
| 20146 | crecería | 1 |
| 20147 | crece | 1 |
| 20148 | crearía | 1 |
| 20149 | créanme | 1 |
| 20150 | créanlo | 1 |
| 20151 | crac | 1 |
| 20152 | coyuntura | 1 |
| 20153 | covent | 1 |
| 20154 | covadonga | 1 |
| 20155 | covachuelismo | 1 |
| 20156 | cotorrón | 1 |
| 20157 | cotorra | 1 |
| 20158 | coto | 1 |
| 20159 | cotización | 1 |
| 20160 | cotidianas | 1 |
| 20161 | cotarro | 1 |
| 20162 | cota | 1 |
| 20163 | costurero | 1 |
| 20164 | costoso | 1 |
| 20165 | costera | 1 |
| 20166 | costase | 1 |
| 20167 | costas | 1 |
| 20168 | costará | 1 |
| 20169 | costara | 1 |
| 20170 | cosquilleo | 1 |
| 20171 | cosméticos | 1 |
| 20172 | cositas | 1 |
| 20173 | cosido | 1 |
| 20174 | cosía | 1 |
| 20175 | cosechero | 1 |
| 20176 | cosechas | 1 |
| 20177 | cosecha | 1 |
| 20178 | coscorrón | 1 |
| 20179 | corzos | 1 |
| 20180 | corvetas | 1 |
| 20181 | cortito | 1 |
| 20182 | cortinillas | 1 |
| 20183 | cortarle | 1 |
| 20184 | cortados | 1 |
| 20185 | corsé | 1 |
| 20186 | corruptela | 1 |
| 20187 | corrupciones | 1 |
| 20188 | corrosivo | 1 |
| 20189 | corrompidas | 1 |
| 20190 | corrompía | 1 |
| 20191 | corromperla | 1 |
| 20192 | corromper | 1 |
| 20193 | corroboró | 1 |
| 20194 | corroboraba | 1 |
| 20195 | corrijan | 1 |
| 20196 | corrigió | 1 |
| 20197 | corrigiendo | 1 |
| 20198 | corriese | 1 |
| 20199 | corriéndose | 1 |
| 20200 | corridos | 1 |
| 20201 | correveidile | 1 |
| 20202 | correspondió | 1 |
| 20203 | correspondiera | 1 |
| 20204 | correspondían | 1 |
| 20205 | corresponderle | 1 |
| 20206 | correrías | 1 |
| 20207 | corren | 1 |
| 20208 | correligionarios | 1 |
| 20209 | corregir | 1 |
| 20210 | correctos | 1 |
| 20211 | correctamente | 1 |
| 20212 | correccionalista | 1 |
| 20213 | correa | 1 |
| 20214 | corran | 1 |
| 20215 | corralón | 1 |
| 20216 | corrales | 1 |
| 20217 | corra | 1 |
| 20218 | corpulentas | 1 |
| 20219 | corporación | 1 |
| 20220 | corpiño | 1 |
| 20221 | corpachón | 1 |
| 20222 | coronilla | 1 |
| 20223 | coronas | 1 |
| 20224 | coronarse | 1 |
| 20225 | coronarlo | 1 |
| 20226 | coronar | 1 |
| 20227 | coronando | 1 |
| 20228 | coronado | 1 |
| 20229 | coronadas | 1 |
| 20230 | coronaba | 1 |
| 20231 | corolario | 1 |
| 20232 | cornisas | 1 |
| 20233 | cornisa | 1 |
| 20234 | corneta | 1 |
| 20235 | cornamenta | 1 |
| 20236 | corintio | 1 |
| 20237 | córdoba | 1 |
| 20238 | cordilleras | 1 |
| 20239 | cordillera | 1 |
| 20240 | cordialmente | 1 |
| 20241 | corderos | 1 |
| 20242 | corcovados | 1 |
| 20243 | corchetes | 1 |
| 20244 | corbatín | 1 |
| 20245 | corbatas | 1 |
| 20246 | corazoncito | 1 |
| 20247 | coram | 1 |
| 20248 | corales | 1 |
| 20249 | coraceros | 1 |
| 20250 | coquetismo | 1 |
| 20251 | coqueteaban | 1 |
| 20252 | copones | 1 |
| 20253 | coplas | 1 |
| 20254 | copla | 1 |
| 20255 | copiosamente | 1 |
| 20256 | copiaremos | 1 |
| 20257 | copiar | 1 |
| 20258 | copiando | 1 |
| 20259 | copiados | 1 |
| 20260 | copiada | 1 |
| 20261 | coordinar | 1 |
| 20262 | coooosa | 1 |
| 20263 | conyugales | 1 |
| 20264 | convulso | 1 |
| 20265 | convocándole | 1 |
| 20266 | convocando | 1 |
| 20267 | convocados | 1 |
| 20268 | convivencia | 1 |
| 20269 | conviniesen | 1 |
| 20270 | conviniese | 1 |
| 20271 | conviniera | 1 |
| 20272 | convierten | 1 |
| 20273 | convídesele | 1 |
| 20274 | convidase | 1 |
| 20275 | convidarles | 1 |
| 20276 | convidándoles | 1 |
| 20277 | conversiones | 1 |
| 20278 | convergencia | 1 |
| 20279 | convenza | 1 |
| 20280 | conventual | 1 |
| 20281 | convenirle | 1 |
| 20282 | convenir | 1 |
| 20283 | convenientes | 1 |
| 20284 | conveniencias | 1 |
| 20285 | convenida | 1 |
| 20286 | convenciendo | 1 |
| 20287 | convencernos | 1 |
| 20288 | convencerme | 1 |
| 20289 | convencerle | 1 |
| 20290 | convenceré | 1 |
| 20291 | contumaz | 1 |
| 20292 | controversias | 1 |
| 20293 | contrincantes | 1 |
| 20294 | contrición | 1 |
| 20295 | contribuyo | 1 |
| 20296 | contribuyente | 1 |
| 20297 | contribuye | 1 |
| 20298 | contribuirá | 1 |
| 20299 | contribuido | 1 |
| 20300 | contribuían | 1 |
| 20301 | contribución | 1 |
| 20302 | contratiempos | 1 |
| 20303 | contratantes | 1 |
| 20304 | contratado | 1 |
| 20305 | contrastaban | 1 |
| 20306 | contrastaba | 1 |
| 20307 | contrasentidos | 1 |
| 20308 | contrarios | 1 |
| 20309 | contrariedad | 1 |
| 20310 | contrariar | 1 |
| 20311 | contrajudías | 1 |
| 20312 | contrahechas | 1 |
| 20313 | contradiciéndose | 1 |
| 20314 | contradiciendo | 1 |
| 20315 | contradicciones | 1 |
| 20316 | contradecirse | 1 |
| 20317 | contradecían | 1 |
| 20318 | contradanza | 1 |
| 20319 | contrabandista | 1 |
| 20320 | contoneo | 1 |
| 20321 | continuos | 1 |
| 20322 | continúo | 1 |
| 20323 | continuasen | 1 |
| 20324 | continuase | 1 |
| 20325 | continuado | 1 |
| 20326 | continua | 1 |
| 20327 | continentes | 1 |
| 20328 | contienda | 1 |
| 20329 | conteste | 1 |
| 20330 | contestarle | 1 |
| 20331 | contestaras | 1 |
| 20332 | contesta | 1 |
| 20333 | contentón | 1 |
| 20334 | contenti | 1 |
| 20335 | contentas | 1 |
| 20336 | contentaron | 1 |
| 20337 | contentaría | 1 |
| 20338 | contentar | 1 |
| 20339 | contentándonos | 1 |
| 20340 | contentado | 1 |
| 20341 | contentadiza | 1 |
| 20342 | contentaban | 1 |
| 20343 | conteniéndose | 1 |
| 20344 | conteniendo | 1 |
| 20345 | contenerte | 1 |
| 20346 | contenerlos | 1 |
| 20347 | contenerle | 1 |
| 20348 | contemporáneas | 1 |
| 20349 | contemplo | 1 |
| 20350 | contemplativo | 1 |
| 20351 | contemplarse | 1 |
| 20352 | contemplarían | 1 |
| 20353 | contemplado | 1 |
| 20354 | contemplaciones | 1 |
| 20355 | contemplaban | 1 |
| 20356 | conté | 1 |
| 20357 | contárselo | 1 |
| 20358 | contarles | 1 |
| 20359 | contarle | 1 |
| 20360 | contarla | 1 |
| 20361 | contarían | 1 |
| 20362 | contaré | 1 |
| 20363 | contarás | 1 |
| 20364 | contándoselo | 1 |
| 20365 | contándose | 1 |
| 20366 | contándome | 1 |
| 20367 | contándoles | 1 |
| 20368 | contagió | 1 |
| 20369 | contagiar | 1 |
| 20370 | contagiado | 1 |
| 20371 | contadas | 1 |
| 20372 | contada | 1 |
| 20373 | contactos | 1 |
| 20374 | consumidores | 1 |
| 20375 | consumían | 1 |
| 20376 | consumes | 1 |
| 20377 | consumaría | 1 |
| 20378 | consultó | 1 |
| 20379 | consultaron | 1 |
| 20380 | consultaría | 1 |
| 20381 | consulta | 1 |
| 20382 | consules | 1 |
| 20383 | consuetudinaria | 1 |
| 20384 | consuelan | 1 |
| 20385 | construyó | 1 |
| 20386 | construyendo | 1 |
| 20387 | construyan | 1 |
| 20388 | construir | 1 |
| 20389 | construido | 1 |
| 20390 | construidas | 1 |
| 20391 | construcción | 1 |
| 20392 | constituyen | 1 |
| 20393 | constituida | 1 |
| 20394 | constituían | 1 |
| 20395 | constipado | 1 |
| 20396 | constipada | 1 |
| 20397 | constipaba | 1 |
| 20398 | consternado | 1 |
| 20399 | constelaciones | 1 |
| 20400 | constelación | 1 |
| 20401 | constantinopla | 1 |
| 20402 | constaban | 1 |
| 20403 | conspirando | 1 |
| 20404 | conspiradores | 1 |
| 20405 | conspiraciones | 1 |
| 20406 | conspiración | 1 |
| 20407 | consorte | 1 |
| 20408 | consolidó | 1 |
| 20409 | consolémonos | 1 |
| 20410 | consolase | 1 |
| 20411 | consolarse | 1 |
| 20412 | consolarme | 1 |
| 20413 | consolaría | 1 |
| 20414 | consolará | 1 |
| 20415 | consolando | 1 |
| 20416 | consolador | 1 |
| 20417 | consistorios | 1 |
| 20418 | consiguiera | 1 |
| 20419 | consiguientes | 1 |
| 20420 | consiguiendo | 1 |
| 20421 | consiguen | 1 |
| 20422 | consigna | 1 |
| 20423 | considerarle | 1 |
| 20424 | considerado | 1 |
| 20425 | considerada | 1 |
| 20426 | considerábase | 1 |
| 20427 | conservo | 1 |
| 20428 | conserve | 1 |
| 20429 | conservas | 1 |
| 20430 | conservando | 1 |
| 20431 | conservaduría | 1 |
| 20432 | conservadoras | 1 |
| 20433 | conservadora | 1 |
| 20434 | conservada | 1 |
| 20435 | conserjería | 1 |
| 20436 | consentiría | 1 |
| 20437 | consentidas | 1 |
| 20438 | consejeros | 1 |
| 20439 | consejas | 1 |
| 20440 | consagrarse | 1 |
| 20441 | consagrarlos | 1 |
| 20442 | consagrarle | 1 |
| 20443 | consagrándose | 1 |
| 20444 | consabido | 1 |
| 20445 | consabida | 1 |
| 20446 | conquistaron | 1 |
| 20447 | conquistarla | 1 |
| 20448 | conquistando | 1 |
| 20449 | conquistada | 1 |
| 20450 | conquistaba | 1 |
| 20451 | conozcamos | 1 |
| 20452 | conocieron | 1 |
| 20453 | conocieran | 1 |
| 20454 | conociera | 1 |
| 20455 | conocidas | 1 |
| 20456 | conocí | 1 |
| 20457 | conocería | 1 |
| 20458 | conocerá | 1 |
| 20459 | cono | 1 |
| 20460 | conmutó | 1 |
| 20461 | conmoverse | 1 |
| 20462 | conmiseración | 1 |
| 20463 | conmemoraban | 1 |
| 20464 | conmemora | 1 |
| 20465 | conjuro | 1 |
| 20466 | conjurar | 1 |
| 20467 | conjuraban | 1 |
| 20468 | conjuraba | 1 |
| 20469 | conjetura | 1 |
| 20470 | cónicos | 1 |
| 20471 | congruas | 1 |
| 20472 | congregarla | 1 |
| 20473 | congregados | 1 |
| 20474 | congraciándose | 1 |
| 20475 | congojosa | 1 |
| 20476 | congestión | 1 |
| 20477 | congeniaban | 1 |
| 20478 | confusamente | 1 |
| 20479 | confundiéndose | 1 |
| 20480 | confundiendo | 1 |
| 20481 | confundidos | 1 |
| 20482 | confundidas | 1 |
| 20483 | confundamos | 1 |
| 20484 | confunda | 1 |
| 20485 | confortante | 1 |
| 20486 | conformarse | 1 |
| 20487 | conformaba | 1 |
| 20488 | confitero | 1 |
| 20489 | confiterías | 1 |
| 20490 | confirmar | 1 |
| 20491 | confirmación | 1 |
| 20492 | confirmaba | 1 |
| 20493 | confirma | 1 |
| 20494 | confiéseme | 1 |
| 20495 | confiaría | 1 |
| 20496 | confiadote | 1 |
| 20497 | confiado | 1 |
| 20498 | confiada | 1 |
| 20499 | confesaron | 1 |
| 20500 | confesarme | 1 |
| 20501 | confesarle | 1 |
| 20502 | confesarla | 1 |
| 20503 | confesaré | 1 |
| 20504 | confesados | 1 |
| 20505 | conferenciaban | 1 |
| 20506 | confectu | 1 |
| 20507 | confeccionar | 1 |
| 20508 | condujo | 1 |
| 20509 | condiscípulo | 1 |
| 20510 | condimento | 1 |
| 20511 | condescendiente | 1 |
| 20512 | condensadas | 1 |
| 20513 | condenó | 1 |
| 20514 | condene | 1 |
| 20515 | condenase | 1 |
| 20516 | condenarse | 1 |
| 20517 | condenarlo | 1 |
| 20518 | condenaría | 1 |
| 20519 | condenando | 1 |
| 20520 | condecoraciones | 1 |
| 20521 | concurridas | 1 |
| 20522 | concurrida | 1 |
| 20523 | concupiscente | 1 |
| 20524 | concupiscencias | 1 |
| 20525 | concreto | 1 |
| 20526 | concreten | 1 |
| 20527 | concretar | 1 |
| 20528 | concretamente | 1 |
| 20529 | concordato | 1 |
| 20530 | concluyen | 1 |
| 20531 | conciso | 1 |
| 20532 | concilios | 1 |
| 20533 | concilió | 1 |
| 20534 | concilia | 1 |
| 20535 | concibió | 1 |
| 20536 | conchas | 1 |
| 20537 | concha | 1 |
| 20538 | concesiones | 1 |
| 20539 | concertar | 1 |
| 20540 | concertando | 1 |
| 20541 | concertado | 1 |
| 20542 | conceptuosos | 1 |
| 20543 | concepta | 1 |
| 20544 | concedo | 1 |
| 20545 | concederle | 1 |
| 20546 | cóncava | 1 |
| 20547 | concausas | 1 |
| 20548 | comúnmente | 1 |
| 20549 | comunidades | 1 |
| 20550 | comunicárselo | 1 |
| 20551 | comunicará | 1 |
| 20552 | comunican | 1 |
| 20553 | comunicados | 1 |
| 20554 | comunicado | 1 |
| 20555 | comunicación | 1 |
| 20556 | comulgó | 1 |
| 20557 | comulgando | 1 |
| 20558 | comulgaba | 1 |
| 20559 | comulga | 1 |
| 20560 | compuso | 1 |
| 20561 | compunción | 1 |
| 20562 | compuertas | 1 |
| 20563 | comprometo | 1 |
| 20564 | comprometida | 1 |
| 20565 | comprometían | 1 |
| 20566 | comprometernos | 1 |
| 20567 | comprobar | 1 |
| 20568 | comprobados | 1 |
| 20569 | comprimió | 1 |
| 20570 | comprimidas | 1 |
| 20571 | comprime | 1 |
| 20572 | comprendida | 1 |
| 20573 | comprenderle | 1 |
| 20574 | comprenderlas | 1 |
| 20575 | comprenderá | 1 |
| 20576 | comprendan | 1 |
| 20577 | compre | 1 |
| 20578 | comprarlos | 1 |
| 20579 | comprarla | 1 |
| 20580 | compraran | 1 |
| 20581 | compradores | 1 |
| 20582 | compostura | 1 |
| 20583 | composiciones | 1 |
| 20584 | composicioncilla | 1 |
| 20585 | componía | 1 |
| 20586 | componenda | 1 |
| 20587 | componen | 1 |
| 20588 | compondría | 1 |
| 20589 | complicidad | 1 |
| 20590 | completos | 1 |
| 20591 | completan | 1 |
| 20592 | complemento | 1 |
| 20593 | complejas | 1 |
| 20594 | complazco | 1 |
| 20595 | complaciente | 1 |
| 20596 | complacíase | 1 |
| 20597 | complaces | 1 |
| 20598 | complaceros | 1 |
| 20599 | complacencias | 1 |
| 20600 | complace | 1 |
| 20601 | competente | 1 |
| 20602 | compensara | 1 |
| 20603 | compenetran | 1 |
| 20604 | compatibles | 1 |
| 20605 | compasivo | 1 |
| 20606 | compartía | 1 |
| 20607 | comparten | 1 |
| 20608 | comparó | 1 |
| 20609 | comparo | 1 |
| 20610 | compares | 1 |
| 20611 | comparen | 1 |
| 20612 | compare | 1 |
| 20613 | comparanza | 1 |
| 20614 | comparados | 1 |
| 20615 | comparaban | 1 |
| 20616 | compadres | 1 |
| 20617 | compadre | 1 |
| 20618 | compadeció | 1 |
| 20619 | compadeciéndose | 1 |
| 20620 | compadecidos | 1 |
| 20621 | compadecerle | 1 |
| 20622 | compadece | 1 |
| 20623 | compactas | 1 |
| 20624 | cómoda | 1 |
| 20625 | commis | 1 |
| 20626 | comisuras | 1 |
| 20627 | comistrajos | 1 |
| 20628 | comiste | 1 |
| 20629 | comisionista | 1 |
| 20630 | comisiones | 1 |
| 20631 | comisionados | 1 |
| 20632 | comisario | 1 |
| 20633 | comino | 1 |
| 20634 | comineros | 1 |
| 20635 | comilonas | 1 |
| 20636 | comiesen | 1 |
| 20637 | comienzos | 1 |
| 20638 | comienzan | 1 |
| 20639 | comías | 1 |
| 20640 | comezones | 1 |
| 20641 | cometiese | 1 |
| 20642 | cometiera | 1 |
| 20643 | cometiendo | 1 |
| 20644 | cometidos | 1 |
| 20645 | cometí | 1 |
| 20646 | cómetela | 1 |
| 20647 | comercios | 1 |
| 20648 | comerciando | 1 |
| 20649 | comercial | 1 |
| 20650 | comerciaban | 1 |
| 20651 | comercia | 1 |
| 20652 | comerá | 1 |
| 20653 | comentarlas | 1 |
| 20654 | comentario | 1 |
| 20655 | comentando | 1 |
| 20656 | comentado | 1 |
| 20657 | comentada | 1 |
| 20658 | comensalía | 1 |
| 20659 | comemos | 1 |
| 20660 | comehostias | 1 |
| 20661 | comedimiento | 1 |
| 20662 | comedidos | 1 |
| 20663 | comedidas | 1 |
| 20664 | comediantes | 1 |
| 20665 | combustión | 1 |
| 20666 | combinar | 1 |
| 20667 | combinadas | 1 |
| 20668 | combinación | 1 |
| 20669 | combinaban | 1 |
| 20670 | combinaba | 1 |
| 20671 | combatirla | 1 |
| 20672 | combatiré | 1 |
| 20673 | combatió | 1 |
| 20674 | combatientes | 1 |
| 20675 | combatiendo | 1 |
| 20676 | combatido | 1 |
| 20677 | combatida | 1 |
| 20678 | comarcanos | 1 |
| 20679 | coman | 1 |
| 20680 | columpiaron | 1 |
| 20681 | columpiar | 1 |
| 20682 | columbraba | 1 |
| 20683 | colosal | 1 |
| 20684 | colorines | 1 |
| 20685 | colorete | 1 |
| 20686 | coloradilla | 1 |
| 20687 | coloradas | 1 |
| 20688 | colono | 1 |
| 20689 | colonial | 1 |
| 20690 | colones | 1 |
| 20691 | colón | 1 |
| 20692 | colocarse | 1 |
| 20693 | colocaran | 1 |
| 20694 | colocando | 1 |
| 20695 | colmó | 1 |
| 20696 | colmillo | 1 |
| 20697 | colmaba | 1 |
| 20698 | collis | 1 |
| 20699 | collares | 1 |
| 20700 | collados | 1 |
| 20701 | colgaron | 1 |
| 20702 | colgarlo | 1 |
| 20703 | colgados | 1 |
| 20704 | colgadizos | 1 |
| 20705 | colgadas | 1 |
| 20706 | colgaban | 1 |
| 20707 | colerilla | 1 |
| 20708 | colérica | 1 |
| 20709 | colegios | 1 |
| 20710 | colegiala | 1 |
| 20711 | colectividades | 1 |
| 20712 | colectivamente | 1 |
| 20713 | colasa | 1 |
| 20714 | colas | 1 |
| 20715 | colaboraba | 1 |
| 20716 | cójala | 1 |
| 20717 | coincidir | 1 |
| 20718 | coincidiese | 1 |
| 20719 | coincidencias | 1 |
| 20720 | coincidencia | 1 |
| 20721 | coimbra | 1 |
| 20722 | cohonestarse | 1 |
| 20723 | cohete | 1 |
| 20724 | cogiese | 1 |
| 20725 | cogiera | 1 |
| 20726 | cogerlo | 1 |
| 20727 | cogerás | 1 |
| 20728 | cofre | 1 |
| 20729 | coeteris | 1 |
| 20730 | coetáneos | 1 |
| 20731 | coetáneo | 1 |
| 20732 | coercitivo | 1 |
| 20733 | codornices | 1 |
| 20734 | codillos | 1 |
| 20735 | codillo | 1 |
| 20736 | codiciosa | 1 |
| 20737 | codiciar | 1 |
| 20738 | codeaban | 1 |
| 20739 | codeaba | 1 |
| 20740 | codazo | 1 |
| 20741 | cocotte | 1 |
| 20742 | cocinaba | 1 |
| 20743 | cochera | 1 |
| 20744 | coces | 1 |
| 20745 | cobro | 1 |
| 20746 | cobras | 1 |
| 20747 | cobrárselo | 1 |
| 20748 | cobrarlos | 1 |
| 20749 | cobrarla | 1 |
| 20750 | cobrarían | 1 |
| 20751 | cobrándole | 1 |
| 20752 | cobran | 1 |
| 20753 | cobos | 1 |
| 20754 | cobijados | 1 |
| 20755 | cobijaba | 1 |
| 20756 | cobija | 1 |
| 20757 | cobertizo | 1 |
| 20758 | coadjutor | 1 |
| 20759 | cloacas | 1 |
| 20760 | climatológica | 1 |
| 20761 | clientes | 1 |
| 20762 | cliente | 1 |
| 20763 | clerófobo | 1 |
| 20764 | clerófoba | 1 |
| 20765 | clavijas | 1 |
| 20766 | claveteada | 1 |
| 20767 | clave | 1 |
| 20768 | clavaron | 1 |
| 20769 | clavarlos | 1 |
| 20770 | clavarás | 1 |
| 20771 | clavándose | 1 |
| 20772 | clavándole | 1 |
| 20773 | clavan | 1 |
| 20774 | cláusulas | 1 |
| 20775 | claudio | 1 |
| 20776 | clasificarla | 1 |
| 20777 | clasificar | 1 |
| 20778 | clarito | 1 |
| 20779 | claridades | 1 |
| 20780 | claraboya | 1 |
| 20781 | clandestinamente | 1 |
| 20782 | clamor | 1 |
| 20783 | clamó | 1 |
| 20784 | clamar | 1 |
| 20785 | clamaba | 1 |
| 20786 | clama | 1 |
| 20787 | civis | 1 |
| 20788 | civilizado | 1 |
| 20789 | civilizada | 1 |
| 20790 | ciutti | 1 |
| 20791 | ciudadano | 1 |
| 20792 | ciudadanas | 1 |
| 20793 | citarse | 1 |
| 20794 | citar | 1 |
| 20795 | citan | 1 |
| 20796 | cisterna | 1 |
| 20797 | ciruelo | 1 |
| 20798 | cirrus | 1 |
| 20799 | cirio | 1 |
| 20800 | circunstanciales | 1 |
| 20801 | circunstancia | 1 |
| 20802 | circunspección | 1 |
| 20803 | circulo | 1 |
| 20804 | circulillos | 1 |
| 20805 | circulando | 1 |
| 20806 | cipreses | 1 |
| 20807 | ciñó | 1 |
| 20808 | ciñendo | 1 |
| 20809 | ciñen | 1 |
| 20810 | cinturón | 1 |
| 20811 | cintajos | 1 |
| 20812 | cínicamente | 1 |
| 20813 | cínica | 1 |
| 20814 | cinegético | 1 |
| 20815 | cinegéticas | 1 |
| 20816 | cincel | 1 |
| 20817 | cimodocea | 1 |
| 20818 | cimientos | 1 |
| 20819 | cimas | 1 |
| 20820 | cilíndricos | 1 |
| 20821 | cigüeña | 1 |
| 20822 | cigarreras | 1 |
| 20823 | cifra | 1 |
| 20824 | cierzo | 1 |
| 20825 | ciervo | 1 |
| 20826 | cierro | 1 |
| 20827 | ciernes | 1 |
| 20828 | científico | 1 |
| 20829 | científica | 1 |
| 20830 | ciel | 1 |
| 20831 | ciegas | 1 |
| 20832 | cicuta | 1 |
| 20833 | ciclopios | 1 |
| 20834 | ciclópea | 1 |
| 20835 | cíclope | 1 |
| 20836 | ciclones | 1 |
| 20837 | ciclo | 1 |
| 20838 | cíclades | 1 |
| 20839 | cicatrices | 1 |
| 20840 | chusquin | 1 |
| 20841 | churriguerescos | 1 |
| 20842 | chupó | 1 |
| 20843 | chupar | 1 |
| 20844 | chupándose | 1 |
| 20845 | chupa | 1 |
| 20846 | chulos | 1 |
| 20847 | chulo | 1 |
| 20848 | chubascos | 1 |
| 20849 | chorritos | 1 |
| 20850 | chorretadas | 1 |
| 20851 | chorrea | 1 |
| 20852 | choques | 1 |
| 20853 | chomel | 1 |
| 20854 | chochas | 1 |
| 20855 | chocasen | 1 |
| 20856 | chocarían | 1 |
| 20857 | chocando | 1 |
| 20858 | chocaba | 1 |
| 20859 | chistera | 1 |
| 20860 | chistar | 1 |
| 20861 | chisporroteos | 1 |
| 20862 | chisporroteo | 1 |
| 20863 | chisporroteaba | 1 |
| 20864 | chirrido | 1 |
| 20865 | chipre | 1 |
| 20866 | chinitas | 1 |
| 20867 | chillonas | 1 |
| 20868 | chillón | 1 |
| 20869 | chiflao | 1 |
| 20870 | chicuela | 1 |
| 20871 | chiaror | 1 |
| 20872 | chevrière | 1 |
| 20873 | che | 1 |
| 20874 | chata | 1 |
| 20875 | chasquidos | 1 |
| 20876 | charlatán | 1 |
| 20877 | charlar | 1 |
| 20878 | charlado | 1 |
| 20879 | charanga | 1 |
| 20880 | chaquetón | 1 |
| 20881 | chaquet | 1 |
| 20882 | chapas | 1 |
| 20883 | chanza | 1 |
| 20884 | chantal | 1 |
| 20885 | chance | 1 |
| 20886 | chambra | 1 |
| 20887 | chambones | 1 |
| 20888 | chambergo | 1 |
| 20889 | chalets | 1 |
| 20890 | cetro | 1 |
| 20891 | cesantías | 1 |
| 20892 | cesando | 1 |
| 20893 | cesado | 1 |
| 20894 | cesa | 1 |
| 20895 | cerviz | 1 |
| 20896 | cervantesca | 1 |
| 20897 | cervantes | 1 |
| 20898 | certámenes | 1 |
| 20899 | cerro | 1 |
| 20900 | cerriles | 1 |
| 20901 | cerril | 1 |
| 20902 | cerrarlos | 1 |
| 20903 | cerraduras | 1 |
| 20904 | cerradas | 1 |
| 20905 | cernida | 1 |
| 20906 | cernía | 1 |
| 20907 | cerilla | 1 |
| 20908 | ceremoniosos | 1 |
| 20909 | ceremonioso | 1 |
| 20910 | ceremonial | 1 |
| 20911 | cereales | 1 |
| 20912 | cerdas | 1 |
| 20913 | cercioraba | 1 |
| 20914 | cercenando | 1 |
| 20915 | cercana | 1 |
| 20916 | cepo | 1 |
| 20917 | cepilla | 1 |
| 20918 | ceñudo | 1 |
| 20919 | ceñuda | 1 |
| 20920 | ceños | 1 |
| 20921 | ceñidas | 1 |
| 20922 | centuria | 1 |
| 20923 | centros | 1 |
| 20924 | céntimos | 1 |
| 20925 | céntimo | 1 |
| 20926 | centímetro | 1 |
| 20927 | centésima | 1 |
| 20928 | centelleaba | 1 |
| 20929 | censuró | 1 |
| 20930 | censuren | 1 |
| 20931 | censores | 1 |
| 20932 | censor | 1 |
| 20933 | ceno | 1 |
| 20934 | cenit | 1 |
| 20935 | ceniciento | 1 |
| 20936 | cenicientas | 1 |
| 20937 | cenarían | 1 |
| 20938 | cenarás | 1 |
| 20939 | cenaban | 1 |
| 20940 | cementerios | 1 |
| 20941 | celtíberos | 1 |
| 20942 | celtas | 1 |
| 20943 | celosos | 1 |
| 20944 | celoso | 1 |
| 20945 | celonio | 1 |
| 20946 | celestinas | 1 |
| 20947 | celeste | 1 |
| 20948 | celesta | 1 |
| 20949 | celeres | 1 |
| 20950 | celenio | 1 |
| 20951 | celebro | 1 |
| 20952 | celebraron | 1 |
| 20953 | celebrarlos | 1 |
| 20954 | celebrarla | 1 |
| 20955 | celebraría | 1 |
| 20956 | celebrara | 1 |
| 20957 | celebrando | 1 |
| 20958 | celebrado | 1 |
| 20959 | celajes | 1 |
| 20960 | celaba | 1 |
| 20961 | cejijuntos | 1 |
| 20962 | cejase | 1 |
| 20963 | cejaría | 1 |
| 20964 | ceguedad | 1 |
| 20965 | cegó | 1 |
| 20966 | cegaba | 1 |
| 20967 | cefiso | 1 |
| 20968 | céfiro | 1 |
| 20969 | cefalalgia | 1 |
| 20970 | cedros | 1 |
| 20971 | cedía | 1 |
| 20972 | cedí | 1 |
| 20973 | cederá | 1 |
| 20974 | cebollas | 1 |
| 20975 | cebolla | 1 |
| 20976 | ce | 1 |
| 20977 | cazurro | 1 |
| 20978 | cazuela | 1 |
| 20979 | cazas | 1 |
| 20980 | cazaron | 1 |
| 20981 | cazara | 1 |
| 20982 | cazando | 1 |
| 20983 | cazan | 1 |
| 20984 | cazado | 1 |
| 20985 | cazaderos | 1 |
| 20986 | cavilar | 1 |
| 20987 | caverna | 1 |
| 20988 | caveant | 1 |
| 20989 | cavar | 1 |
| 20990 | cavando | 1 |
| 20991 | cavadores | 1 |
| 20992 | cavador | 1 |
| 20993 | cavada | 1 |
| 20994 | cauto | 1 |
| 20995 | cautivó | 1 |
| 20996 | cautiverio | 1 |
| 20997 | causaron | 1 |
| 20998 | causar | 1 |
| 20999 | causan | 1 |
| 21000 | causada | 1 |
| 21001 | caulis | 1 |
| 21002 | cathedra | 1 |
| 21003 | categórico | 1 |
| 21004 | catedráticos | 1 |
| 21005 | catedrales | 1 |
| 21006 | cátate | 1 |
| 21007 | catarros | 1 |
| 21008 | catar | 1 |
| 21009 | catalunga | 1 |
| 21010 | catálogo | 1 |
| 21011 | catalanes | 1 |
| 21012 | catafalcos | 1 |
| 21013 | catafalco | 1 |
| 21014 | catacumbas | 1 |
| 21015 | cataclismos | 1 |
| 21016 | cataclismo | 1 |
| 21017 | casulla | 1 |
| 21018 | casuismo | 1 |
| 21019 | castos | 1 |
| 21020 | castigue | 1 |
| 21021 | castigó | 1 |
| 21022 | castigarlos | 1 |
| 21023 | castigaran | 1 |
| 21024 | castigaban | 1 |
| 21025 | castigaba | 1 |
| 21026 | castiga | 1 |
| 21027 | castellana | 1 |
| 21028 | castelar | 1 |
| 21029 | castañeteo | 1 |
| 21030 | castañedos | 1 |
| 21031 | castañares | 1 |
| 21032 | casquivano | 1 |
| 21033 | casinos | 1 |
| 21034 | casilla | 1 |
| 21035 | caseta | 1 |
| 21036 | caseríos | 1 |
| 21037 | caserío | 1 |
| 21038 | caserías | 1 |
| 21039 | casería | 1 |
| 21040 | caseosa | 1 |
| 21041 | case | 1 |
| 21042 | casco | 1 |
| 21043 | cascarón | 1 |
| 21044 | cáscara | 1 |
| 21045 | casase | 1 |
| 21046 | casarte | 1 |
| 21047 | casarme | 1 |
| 21048 | casaría | 1 |
| 21049 | casará | 1 |
| 21050 | casara | 1 |
| 21051 | casándose | 1 |
| 21052 | casamatas | 1 |
| 21053 | casados | 1 |
| 21054 | casadera | 1 |
| 21055 | cartulina | 1 |
| 21056 | cartujo | 1 |
| 21057 | cartitas | 1 |
| 21058 | cartera | 1 |
| 21059 | carteles | 1 |
| 21060 | cartelas | 1 |
| 21061 | cartapacio | 1 |
| 21062 | carruajes | 1 |
| 21063 | carrick | 1 |
| 21064 | carreteros | 1 |
| 21065 | carretero | 1 |
| 21066 | carraspiques | 1 |
| 21067 | carracas | 1 |
| 21068 | carpinteros | 1 |
| 21069 | carpanta | 1 |
| 21070 | carolo | 1 |
| 21071 | carolina | 1 |
| 21072 | carnoso | 1 |
| 21073 | carnosa | 1 |
| 21074 | carnavalesco | 1 |
| 21075 | carmín | 1 |
| 21076 | caritativos | 1 |
| 21077 | cariños | 1 |
| 21078 | caricia | 1 |
| 21079 | caricatura | 1 |
| 21080 | cargarse | 1 |
| 21081 | cargantes | 1 |
| 21082 | cargante | 1 |
| 21083 | cargan | 1 |
| 21084 | caretas | 1 |
| 21085 | carestía | 1 |
| 21086 | cardona | 1 |
| 21087 | cardiopatía | 1 |
| 21088 | cardíacos | 1 |
| 21089 | cárdenos | 1 |
| 21090 | cardenales | 1 |
| 21091 | cárdena | 1 |
| 21092 | cardan | 1 |
| 21093 | carcunda | 1 |
| 21094 | carcomida | 1 |
| 21095 | carcas | 1 |
| 21096 | carcamal | 1 |
| 21097 | carbonizaban | 1 |
| 21098 | carbayeda | 1 |
| 21099 | carátulas | 1 |
| 21100 | carambolas | 1 |
| 21101 | caramba | 1 |
| 21102 | característicos | 1 |
| 21103 | caracoles | 1 |
| 21104 | caracolear | 1 |
| 21105 | capullo | 1 |
| 21106 | capua | 1 |
| 21107 | capotón | 1 |
| 21108 | capota | 1 |
| 21109 | capitulares | 1 |
| 21110 | capitular | 1 |
| 21111 | capiteles | 1 |
| 21112 | capitanes | 1 |
| 21113 | capitaneaban | 1 |
| 21114 | capitalista | 1 |
| 21115 | capisco | 1 |
| 21116 | capirotes | 1 |
| 21117 | capelo | 1 |
| 21118 | capellanes | 1 |
| 21119 | capciosa | 1 |
| 21120 | capalleja | 1 |
| 21121 | capacidad | 1 |
| 21122 | caótico | 1 |
| 21123 | caos | 1 |
| 21124 | cañedo | 1 |
| 21125 | cañamones | 1 |
| 21126 | cantero | 1 |
| 21127 | cantera | 1 |
| 21128 | canten | 1 |
| 21129 | cantatrices | 1 |
| 21130 | cantarse | 1 |
| 21131 | cántaros | 1 |
| 21132 | cantaran | 1 |
| 21133 | cantante | 1 |
| 21134 | cantándole | 1 |
| 21135 | cantados | 1 |
| 21136 | cantábrico | 1 |
| 21137 | cansase | 1 |
| 21138 | cansaron | 1 |
| 21139 | cansados | 1 |
| 21140 | cansadas | 1 |
| 21141 | cansaba | 1 |
| 21142 | cansa | 1 |
| 21143 | canonistas | 1 |
| 21144 | canónigas | 1 |
| 21145 | canónicos | 1 |
| 21146 | canon | 1 |
| 21147 | canela | 1 |
| 21148 | candorosa | 1 |
| 21149 | candil | 1 |
| 21150 | cándido | 1 |
| 21151 | candidaturas | 1 |
| 21152 | cándida | 1 |
| 21153 | candentes | 1 |
| 21154 | candelillas | 1 |
| 21155 | candelabros | 1 |
| 21156 | candelabro | 1 |
| 21157 | candado | 1 |
| 21158 | cancerbero | 1 |
| 21159 | canceles | 1 |
| 21160 | canario | 1 |
| 21161 | canariera | 1 |
| 21162 | canales | 1 |
| 21163 | canal | 1 |
| 21164 | cana | 1 |
| 21165 | camposanto | 1 |
| 21166 | campestre | 1 |
| 21167 | campesinos | 1 |
| 21168 | campesinas | 1 |
| 21169 | campbell | 1 |
| 21170 | campanillazos | 1 |
| 21171 | campanillas | 1 |
| 21172 | campamento | 1 |
| 21173 | camisolín | 1 |
| 21174 | camisola | 1 |
| 21175 | camisas | 1 |
| 21176 | caminando | 1 |
| 21177 | caminaban | 1 |
| 21178 | camilla | 1 |
| 21179 | camelias | 1 |
| 21180 | cambie | 1 |
| 21181 | cambiaban | 1 |
| 21182 | cambia | 1 |
| 21183 | camas | 1 |
| 21184 | camarote | 1 |
| 21185 | camarín | 1 |
| 21186 | camaradas | 1 |
| 21187 | calzonazos | 1 |
| 21188 | calzo | 1 |
| 21189 | calzadas | 1 |
| 21190 | calzaban | 1 |
| 21191 | calza | 1 |
| 21192 | calvicies | 1 |
| 21193 | calva | 1 |
| 21194 | calumniosas | 1 |
| 21195 | calumniosa | 1 |
| 21196 | calumnian | 1 |
| 21197 | calumniadores | 1 |
| 21198 | calumniaban | 1 |
| 21199 | calorosa | 1 |
| 21200 | calores | 1 |
| 21201 | calomarde | 1 |
| 21202 | calmarse | 1 |
| 21203 | calmándose | 1 |
| 21204 | calmado | 1 |
| 21205 | calmaba | 1 |
| 21206 | callos | 1 |
| 21207 | callis | 1 |
| 21208 | callejuela | 1 |
| 21209 | callejones | 1 |
| 21210 | callejero | 1 |
| 21211 | callejera | 1 |
| 21212 | callase | 1 |
| 21213 | callaría | 1 |
| 21214 | callan | 1 |
| 21215 | calladas | 1 |
| 21216 | caliginosas | 1 |
| 21217 | calificada | 1 |
| 21218 | cálidas | 1 |
| 21219 | calibre | 1 |
| 21220 | calepino | 1 |
| 21221 | calentura | 1 |
| 21222 | calentar | 1 |
| 21223 | calentándose | 1 |
| 21224 | calentaban | 1 |
| 21225 | calendario | 1 |
| 21226 | calefacción | 1 |
| 21227 | caldeaba | 1 |
| 21228 | cálculo | 1 |
| 21229 | calculo | 1 |
| 21230 | calcular | 1 |
| 21231 | calculador | 1 |
| 21232 | calcetines | 1 |
| 21233 | calceta | 1 |
| 21234 | calaverilla | 1 |
| 21235 | calaveras | 1 |
| 21236 | calatravas | 1 |
| 21237 | calamo | 1 |
| 21238 | calados | 1 |
| 21239 | calado | 1 |
| 21240 | calabozo | 1 |
| 21241 | cajonería | 1 |
| 21242 | cajistas | 1 |
| 21243 | caín | 1 |
| 21244 | caídas | 1 |
| 21245 | cafetera | 1 |
| 21246 | caes | 1 |
| 21247 | cadera | 1 |
| 21248 | cadenillas | 1 |
| 21249 | cadenciosas | 1 |
| 21250 | cadenaaa | 1 |
| 21251 | cadáveres | 1 |
| 21252 | cacofónico | 1 |
| 21253 | caciquil | 1 |
| 21254 | cachos | 1 |
| 21255 | cachivaches | 1 |
| 21256 | cachetes | 1 |
| 21257 | cachete | 1 |
| 21258 | cachazudas | 1 |
| 21259 | cachazuda | 1 |
| 21260 | cachaza | 1 |
| 21261 | cacerolas | 1 |
| 21262 | cacería | 1 |
| 21263 | cabremos | 1 |
| 21264 | cabras | 1 |
| 21265 | cabra | 1 |
| 21266 | cabotaje | 1 |
| 21267 | cables | 1 |
| 21268 | cabizbaja | 1 |
| 21269 | cabida | 1 |
| 21270 | cabezota | 1 |
| 21271 | cabezada | 1 |
| 21272 | cabañas | 1 |
| 21273 | cabalmente | 1 |
| 21274 | caballerosos | 1 |
| 21275 | caballeroso | 1 |
| 21276 | caballeriza | 1 |
| 21277 | caballerías | 1 |
| 21278 | caballeretes | 1 |
| 21279 | caballeresca | 1 |
| 21280 | cabalística | 1 |
| 21281 | ca | 1 |
| 21282 | byroniano | 1 |
| 21283 | byron | 1 |
| 21284 | bustos | 1 |
| 21285 | búsquenle | 1 |
| 21286 | búsquelo | 1 |
| 21287 | busilis | 1 |
| 21288 | busco | 1 |
| 21289 | buscárselos | 1 |
| 21290 | buscarlas | 1 |
| 21291 | buscaré | 1 |
| 21292 | buscara | 1 |
| 21293 | buscándote | 1 |
| 21294 | buscándola | 1 |
| 21295 | buscadas | 1 |
| 21296 | buscada | 1 |
| 21297 | burocráticas | 1 |
| 21298 | burlonas | 1 |
| 21299 | burlescos | 1 |
| 21300 | burlesco | 1 |
| 21301 | burlasen | 1 |
| 21302 | burlarían | 1 |
| 21303 | burlando | 1 |
| 21304 | burlan | 1 |
| 21305 | burdos | 1 |
| 21306 | bulló | 1 |
| 21307 | bullían | 1 |
| 21308 | bullen | 1 |
| 21309 | bullanguero | 1 |
| 21310 | bulas | 1 |
| 21311 | bula | 1 |
| 21312 | bujías | 1 |
| 21313 | buitre | 1 |
| 21314 | buhoneros | 1 |
| 21315 | bufos | 1 |
| 21316 | bufando | 1 |
| 21317 | buey | 1 |
| 21318 | bucólicas | 1 |
| 21319 | buchner | 1 |
| 21320 | buche | 1 |
| 21321 | bruyère | 1 |
| 21322 | brutos | 1 |
| 21323 | brusquer | 1 |
| 21324 | bruscas | 1 |
| 21325 | brusca | 1 |
| 21326 | brujas | 1 |
| 21327 | brotando | 1 |
| 21328 | brota | 1 |
| 21329 | brooke | 1 |
| 21330 | bronces | 1 |
| 21331 | bromista | 1 |
| 21332 | brochada | 1 |
| 21333 | brocado | 1 |
| 21334 | briscada | 1 |
| 21335 | briosos | 1 |
| 21336 | brindar | 1 |
| 21337 | brindaba | 1 |
| 21338 | brincar | 1 |
| 21339 | brincan | 1 |
| 21340 | brincaban | 1 |
| 21341 | brincaba | 1 |
| 21342 | brilló | 1 |
| 21343 | brillaron | 1 |
| 21344 | brillará | 1 |
| 21345 | brillando | 1 |
| 21346 | brígida | 1 |
| 21347 | bribón | 1 |
| 21348 | brevísima | 1 |
| 21349 | brevemente | 1 |
| 21350 | bretón | 1 |
| 21351 | brechas | 1 |
| 21352 | brea | 1 |
| 21353 | bravos | 1 |
| 21354 | brava | 1 |
| 21355 | bramidos | 1 |
| 21356 | bramido | 1 |
| 21357 | bramar | 1 |
| 21358 | bramante | 1 |
| 21359 | brama | 1 |
| 21360 | braga | 1 |
| 21361 | braceando | 1 |
| 21362 | bozal | 1 |
| 21363 | boutade | 1 |
| 21364 | bouquet | 1 |
| 21365 | botonazos | 1 |
| 21366 | boticario | 1 |
| 21367 | botica | 1 |
| 21368 | botarga | 1 |
| 21369 | botarate | 1 |
| 21370 | botánicas | 1 |
| 21371 | botánica | 1 |
| 21372 | botando | 1 |
| 21373 | bota | 1 |
| 21374 | bostezos | 1 |
| 21375 | bostezara | 1 |
| 21376 | bostezado | 1 |
| 21377 | bostezaban | 1 |
| 21378 | bostezaba | 1 |
| 21379 | borrosos | 1 |
| 21380 | borrón | 1 |
| 21381 | borró | 1 |
| 21382 | borro | 1 |
| 21383 | borrascas | 1 |
| 21384 | borrasca | 1 |
| 21385 | borran | 1 |
| 21386 | borrador | 1 |
| 21387 | borrada | 1 |
| 21388 | borrachón | 1 |
| 21389 | borracheras | 1 |
| 21390 | borraban | 1 |
| 21391 | borraba | 1 |
| 21392 | borona | 1 |
| 21393 | bordó | 1 |
| 21394 | bordeando | 1 |
| 21395 | bordado | 1 |
| 21396 | borda | 1 |
| 21397 | boquirris | 1 |
| 21398 | bonus | 1 |
| 21399 | bonitos | 1 |
| 21400 | bondadoso | 1 |
| 21401 | bombardeo | 1 |
| 21402 | bolsón | 1 |
| 21403 | bolsistas | 1 |
| 21404 | bolera | 1 |
| 21405 | bogando | 1 |
| 21406 | bofetá | 1 |
| 21407 | bodegón | 1 |
| 21408 | bodegas | 1 |
| 21409 | bodega | 1 |
| 21410 | bock | 1 |
| 21411 | bochornosos | 1 |
| 21412 | bochornosa | 1 |
| 21413 | bocas | 1 |
| 21414 | bocacalle | 1 |
| 21415 | bobalicona | 1 |
| 21416 | bobalicón | 1 |
| 21417 | bloqueo | 1 |
| 21418 | bloqueadas | 1 |
| 21419 | bloque | 1 |
| 21420 | blindaje | 1 |
| 21421 | blasfemos | 1 |
| 21422 | blasfemo | 1 |
| 21423 | blasfemia | 1 |
| 21424 | blasfeme | 1 |
| 21425 | blasfemaba | 1 |
| 21426 | blanquísima | 1 |
| 21427 | blanquecinas | 1 |
| 21428 | blanquear | 1 |
| 21429 | blandos | 1 |
| 21430 | blandones | 1 |
| 21431 | blandiéndolo | 1 |
| 21432 | blandía | 1 |
| 21433 | blandamente | 1 |
| 21434 | bizco | 1 |
| 21435 | bizarra | 1 |
| 21436 | bizantina | 1 |
| 21437 | birrete | 1 |
| 21438 | bípedo | 1 |
| 21439 | bion | 1 |
| 21440 | biografías | 1 |
| 21441 | biografía | 1 |
| 21442 | bilioso | 1 |
| 21443 | bílbilis | 1 |
| 21444 | bilbao | 1 |
| 21445 | bilateral | 1 |
| 21446 | bienquisto | 1 |
| 21447 | bienquista | 1 |
| 21448 | bienhechora | 1 |
| 21449 | bicho | 1 |
| 21450 | bibliófilo | 1 |
| 21451 | bibelot | 1 |
| 21452 | bi | 1 |
| 21453 | betún | 1 |
| 21454 | bethlehem | 1 |
| 21455 | bestialidad | 1 |
| 21456 | bestial | 1 |
| 21457 | besas | 1 |
| 21458 | besaron | 1 |
| 21459 | besarla | 1 |
| 21460 | besara | 1 |
| 21461 | besando | 1 |
| 21462 | besado | 1 |
| 21463 | besada | 1 |
| 21464 | besaban | 1 |
| 21465 | berruguete | 1 |
| 21466 | berroqueño | 1 |
| 21467 | bernardo | 1 |
| 21468 | bernard | 1 |
| 21469 | bermudo | 1 |
| 21470 | berlín | 1 |
| 21471 | bengala | 1 |
| 21472 | benévolos | 1 |
| 21473 | beneplácito | 1 |
| 21474 | benemérito | 1 |
| 21475 | benéfico | 1 |
| 21476 | beneficioso | 1 |
| 21477 | benedicto | 1 |
| 21478 | bendiga | 1 |
| 21479 | bendición | 1 |
| 21480 | bendecir | 1 |
| 21481 | bendecían | 1 |
| 21482 | bendecía | 1 |
| 21483 | belo | 1 |
| 21484 | bellos | 1 |
| 21485 | belloritas | 1 |
| 21486 | bellaquerías | 1 |
| 21487 | bellacas | 1 |
| 21488 | belem | 1 |
| 21489 | begonia | 1 |
| 21490 | becerro | 1 |
| 21491 | bebo | 1 |
| 21492 | bebiese | 1 |
| 21493 | bebiera | 1 |
| 21494 | bebida | 1 |
| 21495 | bebería | 1 |
| 21496 | bebedores | 1 |
| 21497 | beatuela | 1 |
| 21498 | bayonetazos | 1 |
| 21499 | bautizar | 1 |
| 21500 | baúles | 1 |
| 21501 | battistini | 1 |
| 21502 | batrania | 1 |
| 21503 | bato | 1 |
| 21504 | batirme | 1 |
| 21505 | batiría | 1 |
| 21506 | batieran | 1 |
| 21507 | batido | 1 |
| 21508 | batía | 1 |
| 21509 | batería | 1 |
| 21510 | baten | 1 |
| 21511 | batas | 1 |
| 21512 | batallones | 1 |
| 21513 | batallón | 1 |
| 21514 | bastos | 1 |
| 21515 | bastonazos | 1 |
| 21516 | bastón | 1 |
| 21517 | bastiat | 1 |
| 21518 | basteado | 1 |
| 21519 | basteada | 1 |
| 21520 | bastase | 1 |
| 21521 | bastarle | 1 |
| 21522 | bastará | 1 |
| 21523 | bastan | 1 |
| 21524 | bastamos | 1 |
| 21525 | bastado | 1 |
| 21526 | bastaban | 1 |
| 21527 | basquiña | 1 |
| 21528 | basilisco | 1 |
| 21529 | barullón | 1 |
| 21530 | barullero | 1 |
| 21531 | barroquismo | 1 |
| 21532 | barrió | 1 |
| 21533 | barriera | 1 |
| 21534 | barriendo | 1 |
| 21535 | barriadas | 1 |
| 21536 | barreras | 1 |
| 21537 | barreno | 1 |
| 21538 | barrenaba | 1 |
| 21539 | barnizados | 1 |
| 21540 | barnizada | 1 |
| 21541 | barcos | 1 |
| 21542 | barcelona | 1 |
| 21543 | baratas | 1 |
| 21544 | baraja | 1 |
| 21545 | báquico | 1 |
| 21546 | bañarse | 1 |
| 21547 | bañarme | 1 |
| 21548 | bañando | 1 |
| 21549 | bañados | 1 |
| 21550 | bañado | 1 |
| 21551 | baña | 1 |
| 21552 | banqueta | 1 |
| 21553 | banqueros | 1 |
| 21554 | bandolero | 1 |
| 21555 | bandidos | 1 |
| 21556 | bandas | 1 |
| 21557 | bandada | 1 |
| 21558 | bamboleaban | 1 |
| 21559 | bambalinas | 1 |
| 21560 | balzac | 1 |
| 21561 | baltasar | 1 |
| 21562 | baldo | 1 |
| 21563 | balda | 1 |
| 21564 | balbuciente | 1 |
| 21565 | balbuceó | 1 |
| 21566 | balaustres | 1 |
| 21567 | balanceaban | 1 |
| 21568 | bajito | 1 |
| 21569 | bájese | 1 |
| 21570 | baje | 1 |
| 21571 | bajarte | 1 |
| 21572 | bajarme | 1 |
| 21573 | bajarán | 1 |
| 21574 | bajada | 1 |
| 21575 | bailasen | 1 |
| 21576 | bailaron | 1 |
| 21577 | bailarín | 1 |
| 21578 | bailan | 1 |
| 21579 | bailábamos | 1 |
| 21580 | baglivio | 1 |
| 21581 | badulaque | 1 |
| 21582 | bachillera | 1 |
| 21583 | bachiller | 1 |
| 21584 | bacalao | 1 |
| 21585 | babosa | 1 |
| 21586 | babor | 1 |
| 21587 | babilónicos | 1 |
| 21588 | babilónico | 1 |
| 21589 | azuzarlas | 1 |
| 21590 | azulados | 1 |
| 21591 | azufre | 1 |
| 21592 | azucarera | 1 |
| 21593 | azucarada | 1 |
| 21594 | azotarla | 1 |
| 21595 | azotada | 1 |
| 21596 | azotacalles | 1 |
| 21597 | azotaban | 1 |
| 21598 | azogue | 1 |
| 21599 | azares | 1 |
| 21600 | ayunaría | 1 |
| 21601 | ayudó | 1 |
| 21602 | ayuden | 1 |
| 21603 | ayudémonos | 1 |
| 21604 | ayudase | 1 |
| 21605 | ayudas | 1 |
| 21606 | ayudaron | 1 |
| 21607 | ayudarnos | 1 |
| 21608 | ayudarlos | 1 |
| 21609 | ayudaría | 1 |
| 21610 | ayudaremos | 1 |
| 21611 | ayudará | 1 |
| 21612 | ayudantes | 1 |
| 21613 | ayudados | 1 |
| 21614 | ayudada | 1 |
| 21615 | ayudábala | 1 |
| 21616 | axis | 1 |
| 21617 | avisó | 1 |
| 21618 | avise | 1 |
| 21619 | avisaría | 1 |
| 21620 | avisaré | 1 |
| 21621 | avisarán | 1 |
| 21622 | avisaba | 1 |
| 21623 | avisa | 1 |
| 21624 | avinagrados | 1 |
| 21625 | avinagrado | 1 |
| 21626 | aviene | 1 |
| 21627 | averigüé | 1 |
| 21628 | averiguarlo | 1 |
| 21629 | averiguaciones | 1 |
| 21630 | averiados | 1 |
| 21631 | averiada | 1 |
| 21632 | avergüence | 1 |
| 21633 | avergonzarme | 1 |
| 21634 | avergonzarla | 1 |
| 21635 | avergonzando | 1 |
| 21636 | avergonzadas | 1 |
| 21637 | aventurillas | 1 |
| 21638 | aventurero | 1 |
| 21639 | aventurarse | 1 |
| 21640 | aventurándose | 1 |
| 21641 | aventuradas | 1 |
| 21642 | aventuraba | 1 |
| 21643 | aventado | 1 |
| 21644 | avenirse | 1 |
| 21645 | avenidos | 1 |
| 21646 | avenida | 1 |
| 21647 | avenía | 1 |
| 21648 | avellanos | 1 |
| 21649 | avellanado | 1 |
| 21650 | ave | 1 |
| 21651 | avasallan | 1 |
| 21652 | avasalladores | 1 |
| 21653 | avaros | 1 |
| 21654 | avaro | 1 |
| 21655 | avariento | 1 |
| 21656 | avanzando | 1 |
| 21657 | avanzaba | 1 |
| 21658 | avalora | 1 |
| 21659 | autos | 1 |
| 21660 | autorizar | 1 |
| 21661 | autorizado | 1 |
| 21662 | autorizaba | 1 |
| 21663 | autora | 1 |
| 21664 | autómatas | 1 |
| 21665 | autolatría | 1 |
| 21666 | auténtico | 1 |
| 21667 | ausenta | 1 |
| 21668 | ausencias | 1 |
| 21669 | aura | 1 |
| 21670 | aúpa | 1 |
| 21671 | aunarme | 1 |
| 21672 | aúnan | 1 |
| 21673 | aumento | 1 |
| 21674 | aumentar | 1 |
| 21675 | aumentado | 1 |
| 21676 | aulló | 1 |
| 21677 | aullidos | 1 |
| 21678 | augustas | 1 |
| 21679 | audiencias | 1 |
| 21680 | atusando | 1 |
| 21681 | atusaba | 1 |
| 21682 | aturdiendo | 1 |
| 21683 | aturdidos | 1 |
| 21684 | atropellos | 1 |
| 21685 | atropello | 1 |
| 21686 | atropellaban | 1 |
| 21687 | atronando | 1 |
| 21688 | atronador | 1 |
| 21689 | atriles | 1 |
| 21690 | atribuyeron | 1 |
| 21691 | atribuyendo | 1 |
| 21692 | atribuye | 1 |
| 21693 | atribulada | 1 |
| 21694 | atribuciones | 1 |
| 21695 | atrevidísima | 1 |
| 21696 | atrevidas | 1 |
| 21697 | atreví | 1 |
| 21698 | atreverme | 1 |
| 21699 | atreverías | 1 |
| 21700 | atrayendo | 1 |
| 21701 | atravesasen | 1 |
| 21702 | atravesaron | 1 |
| 21703 | atravesadas | 1 |
| 21704 | atravesada | 1 |
| 21705 | atrajo | 1 |
| 21706 | atraído | 1 |
| 21707 | atraían | 1 |
| 21708 | atragantaban | 1 |
| 21709 | atraerle | 1 |
| 21710 | atraería | 1 |
| 21711 | atraer | 1 |
| 21712 | atraen | 1 |
| 21713 | atracón | 1 |
| 21714 | atracción | 1 |
| 21715 | atormentarle | 1 |
| 21716 | atormentarla | 1 |
| 21717 | atormentando | 1 |
| 21718 | atonía | 1 |
| 21719 | átomos | 1 |
| 21720 | átomo | 1 |
| 21721 | ató | 1 |
| 21722 | atizaron | 1 |
| 21723 | atiende | 1 |
| 21724 | atice | 1 |
| 21725 | atestados | 1 |
| 21726 | atestadas | 1 |
| 21727 | atesoraba | 1 |
| 21728 | atesora | 1 |
| 21729 | aterrados | 1 |
| 21730 | aterrado | 1 |
| 21731 | aterida | 1 |
| 21732 | atenuaba | 1 |
| 21733 | atenía | 1 |
| 21734 | atengo | 1 |
| 21735 | ateneo | 1 |
| 21736 | atenea | 1 |
| 21737 | atendía | 1 |
| 21738 | atemorizado | 1 |
| 21739 | atea | 1 |
| 21740 | atávicas | 1 |
| 21741 | ataúd | 1 |
| 21742 | atarse | 1 |
| 21743 | atarla | 1 |
| 21744 | atareada | 1 |
| 21745 | atar | 1 |
| 21746 | atan | 1 |
| 21747 | atalaya | 1 |
| 21748 | atajo | 1 |
| 21749 | atajado | 1 |
| 21750 | atados | 1 |
| 21751 | ataco | 1 |
| 21752 | atacarte | 1 |
| 21753 | atacarle | 1 |
| 21754 | ataca | 1 |
| 21755 | ataban | 1 |
| 21756 | ataba | 1 |
| 21757 | ata | 1 |
| 21758 | asustes | 1 |
| 21759 | asustemos | 1 |
| 21760 | asusté | 1 |
| 21761 | asustarte | 1 |
| 21762 | asustaría | 1 |
| 21763 | asueto | 1 |
| 21764 | asturias | 1 |
| 21765 | asturiana | 1 |
| 21766 | astronomía | 1 |
| 21767 | astro | 1 |
| 21768 | astri | 1 |
| 21769 | astillas | 1 |
| 21770 | assistentiam | 1 |
| 21771 | asquerosos | 1 |
| 21772 | aspirado | 1 |
| 21773 | aspiradas | 1 |
| 21774 | aspiraban | 1 |
| 21775 | aspira | 1 |
| 21776 | ásperos | 1 |
| 21777 | aspereza | 1 |
| 21778 | áspera | 1 |
| 21779 | aspectos | 1 |
| 21780 | aspas | 1 |
| 21781 | aspa | 1 |
| 21782 | asombrosamente | 1 |
| 21783 | asombraban | 1 |
| 21784 | asomasen | 1 |
| 21785 | asomaran | 1 |
| 21786 | asomando | 1 |
| 21787 | asolado | 1 |
| 21788 | asociarla | 1 |
| 21789 | asociación | 1 |
| 21790 | asistirlos | 1 |
| 21791 | asistirle | 1 |
| 21792 | asiste | 1 |
| 21793 | asirle | 1 |
| 21794 | asimilaba | 1 |
| 21795 | asignatura | 1 |
| 21796 | asiduos | 1 |
| 21797 | asia | 1 |
| 21798 | asfixiarse | 1 |
| 21799 | asfixiado | 1 |
| 21800 | aseveraba | 1 |
| 21801 | asestaban | 1 |
| 21802 | asesorado | 1 |
| 21803 | asesinos | 1 |
| 21804 | asesinato | 1 |
| 21805 | asesinarla | 1 |
| 21806 | aseo | 1 |
| 21807 | asentaba | 1 |
| 21808 | asegurarlo | 1 |
| 21809 | asegurarle | 1 |
| 21810 | asegurando | 1 |
| 21811 | asegurado | 1 |
| 21812 | asegurada | 1 |
| 21813 | asegura | 1 |
| 21814 | asediaban | 1 |
| 21815 | asediaba | 1 |
| 21816 | asedia | 1 |
| 21817 | ascetismo | 1 |
| 21818 | ascética | 1 |
| 21819 | ascendiendo | 1 |
| 21820 | ascendido | 1 |
| 21821 | ascendía | 1 |
| 21822 | asar | 1 |
| 21823 | asamblea | 1 |
| 21824 | asaltaron | 1 |
| 21825 | asaltar | 1 |
| 21826 | asaltaba | 1 |
| 21827 | asafétida | 1 |
| 21828 | asada | 1 |
| 21829 | as | 1 |
| 21830 | arúspice | 1 |
| 21831 | artificial | 1 |
| 21832 | articulillo | 1 |
| 21833 | articulejo | 1 |
| 21834 | artesano | 1 |
| 21835 | artela | 1 |
| 21836 | artefactos | 1 |
| 21837 | arrullado | 1 |
| 21838 | arrullaban | 1 |
| 21839 | arruine | 1 |
| 21840 | arruinarle | 1 |
| 21841 | arruinados | 1 |
| 21842 | arrugase | 1 |
| 21843 | arrugar | 1 |
| 21844 | arrugados | 1 |
| 21845 | arrugaditos | 1 |
| 21846 | arrugadas | 1 |
| 21847 | arroz | 1 |
| 21848 | arropada | 1 |
| 21849 | arrollado | 1 |
| 21850 | arrojasen | 1 |
| 21851 | arrojárselo | 1 |
| 21852 | arrojarme | 1 |
| 21853 | arrojarlo | 1 |
| 21854 | arrojarles | 1 |
| 21855 | arrojarla | 1 |
| 21856 | arrogantes | 1 |
| 21857 | arrodilladas | 1 |
| 21858 | arrobado | 1 |
| 21859 | arrinconadas | 1 |
| 21860 | arrimó | 1 |
| 21861 | arrimaron | 1 |
| 21862 | arriesgándose | 1 |
| 21863 | arriesgados | 1 |
| 21864 | arriesgado | 1 |
| 21865 | arriesgada | 1 |
| 21866 | arrieros | 1 |
| 21867 | arresto | 1 |
| 21868 | arrepintió | 1 |
| 21869 | arrepintiéndose | 1 |
| 21870 | arreo | 1 |
| 21871 | arrendamientos | 1 |
| 21872 | arremolinó | 1 |
| 21873 | arremolinaban | 1 |
| 21874 | arremetida | 1 |
| 21875 | arrellanados | 1 |
| 21876 | arrellanado | 1 |
| 21877 | arreglos | 1 |
| 21878 | arreglo | 1 |
| 21879 | arreglarlo | 1 |
| 21880 | arreglaría | 1 |
| 21881 | arreglarás | 1 |
| 21882 | arreglan | 1 |
| 21883 | arreglaba | 1 |
| 21884 | arrebató | 1 |
| 21885 | arrebatando | 1 |
| 21886 | arrebatado | 1 |
| 21887 | arrebataba | 1 |
| 21888 | arrastró | 1 |
| 21889 | arrasados | 1 |
| 21890 | arras | 1 |
| 21891 | arranco | 1 |
| 21892 | arrancasen | 1 |
| 21893 | arrancas | 1 |
| 21894 | arrancarse | 1 |
| 21895 | arrancaron | 1 |
| 21896 | arrancarlo | 1 |
| 21897 | arrancarla | 1 |
| 21898 | arrancaría | 1 |
| 21899 | arrancándoles | 1 |
| 21900 | arrancándola | 1 |
| 21901 | arrancados | 1 |
| 21902 | arraigo | 1 |
| 21903 | arraigada | 1 |
| 21904 | arraigaba | 1 |
| 21905 | arrabales | 1 |
| 21906 | arquitecto | 1 |
| 21907 | arqueológicos | 1 |
| 21908 | arouet | 1 |
| 21909 | aromático | 1 |
| 21910 | aromáticas | 1 |
| 21911 | aroma | 1 |
| 21912 | aro | 1 |
| 21913 | armonioso | 1 |
| 21914 | armónico | 1 |
| 21915 | armonías | 1 |
| 21916 | armisticios | 1 |
| 21917 | armisticio | 1 |
| 21918 | armiños | 1 |
| 21919 | armadura | 1 |
| 21920 | aristocráticos | 1 |
| 21921 | aristocráticas | 1 |
| 21922 | arisco | 1 |
| 21923 | ariscas | 1 |
| 21924 | áridos | 1 |
| 21925 | argumosa | 1 |
| 21926 | argucias | 1 |
| 21927 | argos | 1 |
| 21928 | arenilla | 1 |
| 21929 | arengas | 1 |
| 21930 | arengaba | 1 |
| 21931 | arduas | 1 |
| 21932 | ardió | 1 |
| 21933 | ardilla | 1 |
| 21934 | ardiera | 1 |
| 21935 | arder | 1 |
| 21936 | ardentísimo | 1 |
| 21937 | arde | 1 |
| 21938 | arcos | 1 |
| 21939 | arcones | 1 |
| 21940 | arciprestazgo | 1 |
| 21941 | arcilla | 1 |
| 21942 | archivo | 1 |
| 21943 | archimonástica | 1 |
| 21944 | arcadias | 1 |
| 21945 | arboricultor | 1 |
| 21946 | arbitrista | 1 |
| 21947 | arbitrar | 1 |
| 21948 | arañazos | 1 |
| 21949 | arañazo | 1 |
| 21950 | aragonesa | 1 |
| 21951 | árabes | 1 |
| 21952 | aquilata | 1 |
| 21953 | aquéllas | 1 |
| 21954 | apuren | 1 |
| 21955 | apurasen | 1 |
| 21956 | apuras | 1 |
| 21957 | apurarse | 1 |
| 21958 | apuran | 1 |
| 21959 | apuntara | 1 |
| 21960 | apuntado | 1 |
| 21961 | aproximando | 1 |
| 21962 | aproximadamente | 1 |
| 21963 | aproximaba | 1 |
| 21964 | aprovechemos | 1 |
| 21965 | aprovecharon | 1 |
| 21966 | aprovecharlo | 1 |
| 21967 | aprovecharlas | 1 |
| 21968 | aprovechándose | 1 |
| 21969 | aprovechado | 1 |
| 21970 | apropósito | 1 |
| 21971 | aprobar | 1 |
| 21972 | aprobando | 1 |
| 21973 | aprobado | 1 |
| 21974 | aprobadas | 1 |
| 21975 | aprisionados | 1 |
| 21976 | aprisionaba | 1 |
| 21977 | aprietos | 1 |
| 21978 | aprietan | 1 |
| 21979 | aprieta | 1 |
| 21980 | apretarse | 1 |
| 21981 | apretándose | 1 |
| 21982 | apresure | 1 |
| 21983 | aprensivo | 1 |
| 21984 | aprendiz | 1 |
| 21985 | aprendiera | 1 |
| 21986 | aprendidas | 1 |
| 21987 | aprendices | 1 |
| 21988 | aprendían | 1 |
| 21989 | aprendía | 1 |
| 21990 | aprendí | 1 |
| 21991 | aprenderá | 1 |
| 21992 | aprende | 1 |
| 21993 | apremiante | 1 |
| 21994 | apreció | 1 |
| 21995 | apreciarlos | 1 |
| 21996 | apreciaciones | 1 |
| 21997 | aprecia | 1 |
| 21998 | approbante | 1 |
| 21999 | apoyos | 1 |
| 22000 | apoyadas | 1 |
| 22001 | apóstrofes | 1 |
| 22002 | apostatar | 1 |
| 22003 | apostaría | 1 |
| 22004 | apostados | 1 |
| 22005 | apostado | 1 |
| 22006 | apostaba | 1 |
| 22007 | aposentos | 1 |
| 22008 | aportaría | 1 |
| 22009 | apoplético | 1 |
| 22010 | apoplejía | 1 |
| 22011 | apólogos | 1 |
| 22012 | apologías | 1 |
| 22013 | apodos | 1 |
| 22014 | apodere | 1 |
| 22015 | apoderarse | 1 |
| 22016 | apoderando | 1 |
| 22017 | apoderaba | 1 |
| 22018 | apocalípticas | 1 |
| 22019 | apocados | 1 |
| 22020 | aplico | 1 |
| 22021 | aplicarse | 1 |
| 22022 | aplicándose | 1 |
| 22023 | aplicando | 1 |
| 22024 | aplicación | 1 |
| 22025 | aplicable | 1 |
| 22026 | aplazando | 1 |
| 22027 | aplazado | 1 |
| 22028 | aplazaba | 1 |
| 22029 | aplauso | 1 |
| 22030 | aplaudiese | 1 |
| 22031 | aplaudidos | 1 |
| 22032 | aplaudido | 1 |
| 22033 | aplaudían | 1 |
| 22034 | aplastemos | 1 |
| 22035 | aplastarla | 1 |
| 22036 | aplastarían | 1 |
| 22037 | aplastada | 1 |
| 22038 | aplacarla | 1 |
| 22039 | aplacar | 1 |
| 22040 | aplacaban | 1 |
| 22041 | apiñada | 1 |
| 22042 | apiñábase | 1 |
| 22043 | ápice | 1 |
| 22044 | apiadarse | 1 |
| 22045 | apiadaba | 1 |
| 22046 | apetitoso | 1 |
| 22047 | apetecida | 1 |
| 22048 | apetecibles | 1 |
| 22049 | apesto | 1 |
| 22050 | apestas | 1 |
| 22051 | apestaba | 1 |
| 22052 | aperitivos | 1 |
| 22053 | apeó | 1 |
| 22054 | apéndice | 1 |
| 22055 | apelmazada | 1 |
| 22056 | apellido | 1 |
| 22057 | apellidaban | 1 |
| 22058 | apellidaba | 1 |
| 22059 | apego | 1 |
| 22060 | apearon | 1 |
| 22061 | apearme | 1 |
| 22062 | apeado | 1 |
| 22063 | apeaba | 1 |
| 22064 | apatía | 1 |
| 22065 | apasionamiento | 1 |
| 22066 | apasionadas | 1 |
| 22067 | aparto | 1 |
| 22068 | apartarle | 1 |
| 22069 | apartaría | 1 |
| 22070 | apartamiento | 1 |
| 22071 | apartado | 1 |
| 22072 | apartadas | 1 |
| 22073 | apartada | 1 |
| 22074 | apartaban | 1 |
| 22075 | apartaba | 1 |
| 22076 | aparta | 1 |
| 22077 | apariciones | 1 |
| 22078 | aparentarla | 1 |
| 22079 | aparentan | 1 |
| 22080 | aparecérsele | 1 |
| 22081 | aparatoso | 1 |
| 22082 | aparador | 1 |
| 22083 | apañaré | 1 |
| 22084 | apaleaban | 1 |
| 22085 | apagase | 1 |
| 22086 | apagarla | 1 |
| 22087 | apacentaba | 1 |
| 22088 | añosos | 1 |
| 22089 | añicos | 1 |
| 22090 | añado | 1 |
| 22091 | añadiría | 1 |
| 22092 | añadiendo | 1 |
| 22093 | añadían | 1 |
| 22094 | anuncita | 1 |
| 22095 | anuncios | 1 |
| 22096 | anuncias | 1 |
| 22097 | anunciarle | 1 |
| 22098 | anunciándoles | 1 |
| 22099 | anunciadas | 1 |
| 22100 | anulo | 1 |
| 22101 | anual | 1 |
| 22102 | antro | 1 |
| 22103 | antonelli | 1 |
| 22104 | antón | 1 |
| 22105 | antolínez | 1 |
| 22106 | antojos | 1 |
| 22107 | antojase | 1 |
| 22108 | antojársele | 1 |
| 22109 | antojara | 1 |
| 22110 | antojado | 1 |
| 22111 | antojadiza | 1 |
| 22112 | antojábasele | 1 |
| 22113 | antítesis | 1 |
| 22114 | antipáticos | 1 |
| 22115 | antiguamente | 1 |
| 22116 | antiespasmódicos | 1 |
| 22117 | anticuarios | 1 |
| 22118 | anticuada | 1 |
| 22119 | anticipos | 1 |
| 22120 | anticipar | 1 |
| 22121 | anticipándose | 1 |
| 22122 | anticipando | 1 |
| 22123 | anticipado | 1 |
| 22124 | anticipada | 1 |
| 22125 | anticipaba | 1 |
| 22126 | antepasados | 1 |
| 22127 | antecesores | 1 |
| 22128 | antecesor | 1 |
| 22129 | antecedentes | 1 |
| 22130 | ansiando | 1 |
| 22131 | ansiaban | 1 |
| 22132 | anónimas | 1 |
| 22133 | anónima | 1 |
| 22134 | anochecía | 1 |
| 22135 | aniquilarme | 1 |
| 22136 | aniquilarle | 1 |
| 22137 | aniquilados | 1 |
| 22138 | animen | 1 |
| 22139 | ánimas | 1 |
| 22140 | animaron | 1 |
| 22141 | animando | 1 |
| 22142 | animan | 1 |
| 22143 | animalucho | 1 |
| 22144 | animalitos | 1 |
| 22145 | animalejo | 1 |
| 22146 | animados | 1 |
| 22147 | animada | 1 |
| 22148 | aniceto | 1 |
| 22149 | anhelaban | 1 |
| 22150 | angustioso | 1 |
| 22151 | angustiado | 1 |
| 22152 | angustiaba | 1 |
| 22153 | ángulos | 1 |
| 22154 | anguilas | 1 |
| 22155 | angosta | 1 |
| 22156 | angola | 1 |
| 22157 | angelito | 1 |
| 22158 | angélico | 1 |
| 22159 | angarillas | 1 |
| 22160 | anfibológico | 1 |
| 22161 | anfibios | 1 |
| 22162 | anfibio | 1 |
| 22163 | anegó | 1 |
| 22164 | anegarse | 1 |
| 22165 | anegar | 1 |
| 22166 | anegamos | 1 |
| 22167 | anegaban | 1 |
| 22168 | anduviese | 1 |
| 22169 | anduvieron | 1 |
| 22170 | anduvieran | 1 |
| 22171 | anduviera | 1 |
| 22172 | andrómaca | 1 |
| 22173 | andrina | 1 |
| 22174 | andrajosa | 1 |
| 22175 | andrajos | 1 |
| 22176 | andrajo | 1 |
| 22177 | anday | 1 |
| 22178 | andas | 1 |
| 22179 | andarín | 1 |
| 22180 | andaríamos | 1 |
| 22181 | andamos | 1 |
| 22182 | andalucía | 1 |
| 22183 | andaluces | 1 |
| 22184 | andábamos | 1 |
| 22185 | ancor | 1 |
| 22186 | anchuras | 1 |
| 22187 | anchura | 1 |
| 22188 | anchísima | 1 |
| 22189 | anch | 1 |
| 22190 | análogo | 1 |
| 22191 | analogías | 1 |
| 22192 | analogía | 1 |
| 22193 | análoga | 1 |
| 22194 | analizarla | 1 |
| 22195 | analítica | 1 |
| 22196 | anagnórisis | 1 |
| 22197 | anafrodíticos | 1 |
| 22198 | anafrodítico | 1 |
| 22199 | anafroditas | 1 |
| 22200 | anacronismo | 1 |
| 22201 | anacreóntica | 1 |
| 22202 | amueblada | 1 |
| 22203 | amplitud | 1 |
| 22204 | amplios | 1 |
| 22205 | amplias | 1 |
| 22206 | ampliar | 1 |
| 22207 | amplia | 1 |
| 22208 | ampararse | 1 |
| 22209 | amparando | 1 |
| 22210 | amotinados | 1 |
| 22211 | amostazado | 1 |
| 22212 | amortajada | 1 |
| 22213 | amorcillo | 1 |
| 22214 | amoratados | 1 |
| 22215 | amoratado | 1 |
| 22216 | amoratada | 1 |
| 22217 | amontonado | 1 |
| 22218 | amontonaba | 1 |
| 22219 | amoldarse | 1 |
| 22220 | amó | 1 |
| 22221 | amnistía | 1 |
| 22222 | amistosas | 1 |
| 22223 | amiguito | 1 |
| 22224 | américo | 1 |
| 22225 | américas | 1 |
| 22226 | americanilla | 1 |
| 22227 | ameno | 1 |
| 22228 | amenizaba | 1 |
| 22229 | amenidad | 1 |
| 22230 | amengua | 1 |
| 22231 | amenazas | 1 |
| 22232 | amenazarla | 1 |
| 22233 | amenazar | 1 |
| 22234 | amenazándome | 1 |
| 22235 | amenazándola | 1 |
| 22236 | amenazador | 1 |
| 22237 | amenazaban | 1 |
| 22238 | amenas | 1 |
| 22239 | amen | 1 |
| 22240 | ambulante | 1 |
| 22241 | ambiciones | 1 |
| 22242 | ambicionaba | 1 |
| 22243 | amazacotada | 1 |
| 22244 | amasijo | 1 |
| 22245 | amasados | 1 |
| 22246 | amarrado | 1 |
| 22247 | amarla | 1 |
| 22248 | amarillez | 1 |
| 22249 | amarillentos | 1 |
| 22250 | amarillentas | 1 |
| 22251 | amarilleaba | 1 |
| 22252 | amarilis | 1 |
| 22253 | amaranto | 1 |
| 22254 | amaños | 1 |
| 22255 | amansando | 1 |
| 22256 | amaneramiento | 1 |
| 22257 | amaneció | 1 |
| 22258 | amanecido | 1 |
| 22259 | amanecía | 1 |
| 22260 | amagos | 1 |
| 22261 | amagó | 1 |
| 22262 | amago | 1 |
| 22263 | amaga | 1 |
| 22264 | amadas | 1 |
| 22265 | alzó | 1 |
| 22266 | alzasen | 1 |
| 22267 | alzase | 1 |
| 22268 | alzando | 1 |
| 22269 | alza | 1 |
| 22270 | alvarico | 1 |
| 22271 | aluvión | 1 |
| 22272 | alusiva | 1 |
| 22273 | alumbramiento | 1 |
| 22274 | alumbraban | 1 |
| 22275 | alumbra | 1 |
| 22276 | aludían | 1 |
| 22277 | alucinas | 1 |
| 22278 | altruistas | 1 |
| 22279 | altozano | 1 |
| 22280 | altivez | 1 |
| 22281 | altisonante | 1 |
| 22282 | altísimos | 1 |
| 22283 | alteró | 1 |
| 22284 | alternando | 1 |
| 22285 | alteres | 1 |
| 22286 | altercados | 1 |
| 22287 | altercado | 1 |
| 22288 | alterarse | 1 |
| 22289 | alterar | 1 |
| 22290 | alteraciones | 1 |
| 22291 | altaneros | 1 |
| 22292 | altanero | 1 |
| 22293 | altanería | 1 |
| 22294 | alquilar | 1 |
| 22295 | alpiste | 1 |
| 22296 | alondras | 1 |
| 22297 | almuerzo | 1 |
| 22298 | almorzaba | 1 |
| 22299 | almohadón | 1 |
| 22300 | almohadillado | 1 |
| 22301 | almohadillada | 1 |
| 22302 | almidonadas | 1 |
| 22303 | almidón | 1 |
| 22304 | almibarados | 1 |
| 22305 | almibarado | 1 |
| 22306 | almenas | 1 |
| 22307 | almacenó | 1 |
| 22308 | almacenes | 1 |
| 22309 | alleluia | 1 |
| 22310 | allanarlo | 1 |
| 22311 | alivio | 1 |
| 22312 | aliviada | 1 |
| 22313 | aliviaban | 1 |
| 22314 | alineado | 1 |
| 22315 | alineadas | 1 |
| 22316 | alimentan | 1 |
| 22317 | alimentada | 1 |
| 22318 | alimentación | 1 |
| 22319 | alimenta | 1 |
| 22320 | alimañas | 1 |
| 22321 | alientos | 1 |
| 22322 | alientan | 1 |
| 22323 | alicientes | 1 |
| 22324 | alianza | 1 |
| 22325 | alharaca | 1 |
| 22326 | alhajas | 1 |
| 22327 | alhaja | 1 |
| 22328 | algos | 1 |
| 22329 | algodones | 1 |
| 22330 | algodón | 1 |
| 22331 | algaradas | 1 |
| 22332 | alforjas | 1 |
| 22333 | alfonsos | 1 |
| 22334 | alfombras | 1 |
| 22335 | alfiletero | 1 |
| 22336 | alfileres | 1 |
| 22337 | alfiler | 1 |
| 22338 | alfayate | 1 |
| 22339 | aletean | 1 |
| 22340 | aletargada | 1 |
| 22341 | alero | 1 |
| 22342 | alentaba | 1 |
| 22343 | alemania | 1 |
| 22344 | alejaran | 1 |
| 22345 | alegué | 1 |
| 22346 | alegremente | 1 |
| 22347 | alegrase | 1 |
| 22348 | alegrarle | 1 |
| 22349 | alegrar | 1 |
| 22350 | alegraban | 1 |
| 22351 | alegórica | 1 |
| 22352 | alegoría | 1 |
| 22353 | alegando | 1 |
| 22354 | alegaba | 1 |
| 22355 | aleccionado | 1 |
| 22356 | aleatorio | 1 |
| 22357 | aldebarán | 1 |
| 22358 | aldabonazos | 1 |
| 22359 | aldabonazo | 1 |
| 22360 | aldabonada | 1 |
| 22361 | alcurnia | 1 |
| 22362 | alcubilla | 1 |
| 22363 | alcornoque | 1 |
| 22364 | alcohólicos | 1 |
| 22365 | alcides | 1 |
| 22366 | alcanzó | 1 |
| 22367 | alcanzase | 1 |
| 22368 | alcanzara | 1 |
| 22369 | alcanzamos | 1 |
| 22370 | alcanzados | 1 |
| 22371 | alcanzaban | 1 |
| 22372 | alcanzaba | 1 |
| 22373 | alcances | 1 |
| 22374 | alcaldito | 1 |
| 22375 | alcaldesa | 1 |
| 22376 | alcaide | 1 |
| 22377 | alcacer | 1 |
| 22378 | álbum | 1 |
| 22379 | alborotó | 1 |
| 22380 | alboroto | 1 |
| 22381 | alborote | 1 |
| 22382 | alborotando | 1 |
| 22383 | alborotan | 1 |
| 22384 | alborotado | 1 |
| 22385 | alborotaban | 1 |
| 22386 | alboroque | 1 |
| 22387 | alborada | 1 |
| 22388 | albión | 1 |
| 22389 | albergaba | 1 |
| 22390 | alberca | 1 |
| 22391 | albéitar | 1 |
| 22392 | albedrío | 1 |
| 22393 | albas | 1 |
| 22394 | albañal | 1 |
| 22395 | albaicín | 1 |
| 22396 | alarmó | 1 |
| 22397 | alarmasen | 1 |
| 22398 | alarmará | 1 |
| 22399 | alarmantes | 1 |
| 22400 | alarmada | 1 |
| 22401 | alargó | 1 |
| 22402 | alargarse | 1 |
| 22403 | alargando | 1 |
| 22404 | alarcón | 1 |
| 22405 | alancardan | 1 |
| 22406 | alambres | 1 |
| 22407 | alambicadas | 1 |
| 22408 | alacenas | 1 |
| 22409 | alacena | 1 |
| 22410 | alabó | 1 |
| 22411 | alabarle | 1 |
| 22412 | alabarla | 1 |
| 22413 | alabando | 1 |
| 22414 | alaban | 1 |
| 22415 | alabados | 1 |
| 22416 | alabada | 1 |
| 22417 | ala | 1 |
| 22418 | ajutorium | 1 |
| 22419 | ajustadas | 1 |
| 22420 | ajustábase | 1 |
| 22421 | ajenjo | 1 |
| 22422 | ajajá | 1 |
| 22423 | ajado | 1 |
| 22424 | aislarla | 1 |
| 22425 | aislados | 1 |
| 22426 | aislador | 1 |
| 22427 | aislado | 1 |
| 22428 | aislada | 1 |
| 22429 | airosas | 1 |
| 22430 | airosa | 1 |
| 22431 | airada | 1 |
| 22432 | ahuyentaba | 1 |
| 22433 | ahumados | 1 |
| 22434 | ahorró | 1 |
| 22435 | ahorrar | 1 |
| 22436 | ahorrada | 1 |
| 22437 | ahorraba | 1 |
| 22438 | ahorita | 1 |
| 22439 | ahorcarse | 1 |
| 22440 | ahorcar | 1 |
| 22441 | ahorcado | 1 |
| 22442 | ahogó | 1 |
| 22443 | ahogarse | 1 |
| 22444 | ahogaron | 1 |
| 22445 | ahogarlo | 1 |
| 22446 | ahogarla | 1 |
| 22447 | ahogar | 1 |
| 22448 | ahogando | 1 |
| 22449 | ahogados | 1 |
| 22450 | ahogaban | 1 |
| 22451 | ahítas | 1 |
| 22452 | ahíta | 1 |
| 22453 | aguzado | 1 |
| 22454 | aguzaba | 1 |
| 22455 | agustinito | 1 |
| 22456 | agujerito | 1 |
| 22457 | aguijones | 1 |
| 22458 | aguijonearle | 1 |
| 22459 | aguerrido | 1 |
| 22460 | agüero | 1 |
| 22461 | agudezas | 1 |
| 22462 | agudeza | 1 |
| 22463 | aguarde | 1 |
| 22464 | aguardando | 1 |
| 22465 | aguanto | 1 |
| 22466 | aguantado | 1 |
| 22467 | aguacero | 1 |
| 22468 | agrónomo | 1 |
| 22469 | agrietadas | 1 |
| 22470 | agrietada | 1 |
| 22471 | agrícola | 1 |
| 22472 | agrias | 1 |
| 22473 | agriado | 1 |
| 22474 | agreste | 1 |
| 22475 | agregarse | 1 |
| 22476 | agregadas | 1 |
| 22477 | agravio | 1 |
| 22478 | agravante | 1 |
| 22479 | agravaba | 1 |
| 22480 | agradézcaselo | 1 |
| 22481 | agradezcamos | 1 |
| 22482 | agradeces | 1 |
| 22483 | agradecerlo | 1 |
| 22484 | agradecerle | 1 |
| 22485 | agradecería | 1 |
| 22486 | agradeceré | 1 |
| 22487 | agradece | 1 |
| 22488 | agrade | 1 |
| 22489 | agradarle | 1 |
| 22490 | agradado | 1 |
| 22491 | agradablemente | 1 |
| 22492 | agradaban | 1 |
| 22493 | agradábale | 1 |
| 22494 | agotando | 1 |
| 22495 | agostado | 1 |
| 22496 | agostada | 1 |
| 22497 | agoreras | 1 |
| 22498 | agonizaba | 1 |
| 22499 | agonía | 1 |
| 22500 | agolpándose | 1 |
| 22501 | agolpaba | 1 |
| 22502 | agobiados | 1 |
| 22503 | aglomeraron | 1 |
| 22504 | aglomeración | 1 |
| 22505 | agitada | 1 |
| 22506 | agitaba | 1 |
| 22507 | agilidad | 1 |
| 22508 | ágil | 1 |
| 22509 | agentes | 1 |
| 22510 | agente | 1 |
| 22511 | agencias | 1 |
| 22512 | agencia | 1 |
| 22513 | agazapado | 1 |
| 22514 | agasajos | 1 |
| 22515 | agasajada | 1 |
| 22516 | agarró | 1 |
| 22517 | agarrarse | 1 |
| 22518 | agarrándose | 1 |
| 22519 | agarran | 1 |
| 22520 | agarraban | 1 |
| 22521 | agarraba | 1 |
| 22522 | agachar | 1 |
| 22523 | agachándose | 1 |
| 22524 | agachado | 1 |
| 22525 | afueras | 1 |
| 22526 | afrodisíaco | 1 |
| 22527 | africana | 1 |
| 22528 | afrento | 1 |
| 22529 | afrenta | 1 |
| 22530 | afortunados | 1 |
| 22531 | aforismos | 1 |
| 22532 | aforismo | 1 |
| 22533 | aflojara | 1 |
| 22534 | aflojando | 1 |
| 22535 | aflojaban | 1 |
| 22536 | aflojaba | 1 |
| 22537 | aflija | 1 |
| 22538 | afligió | 1 |
| 22539 | afligido | 1 |
| 22540 | afirmativa | 1 |
| 22541 | afirmarse | 1 |
| 22542 | afirmar | 1 |
| 22543 | afirma | 1 |
| 22544 | afinaban | 1 |
| 22545 | afiló | 1 |
| 22546 | afilador | 1 |
| 22547 | aficionara | 1 |
| 22548 | afianzaría | 1 |
| 22549 | affma | 1 |
| 22550 | aferradas | 1 |
| 22551 | afeminados | 1 |
| 22552 | afeitar | 1 |
| 22553 | afeitado | 1 |
| 22554 | afectuoso | 1 |
| 22555 | afectuosa | 1 |
| 22556 | afectivo | 1 |
| 22557 | afectísimo | 1 |
| 22558 | afectar | 1 |
| 22559 | afectando | 1 |
| 22560 | afearlo | 1 |
| 22561 | afanes | 1 |
| 22562 | afanaba | 1 |
| 22563 | afables | 1 |
| 22564 | afablemente | 1 |
| 22565 | aeroterapia | 1 |
| 22566 | aéreo | 1 |
| 22567 | aereación | 1 |
| 22568 | advirtieron | 1 |
| 22569 | advierto | 1 |
| 22570 | advertirse | 1 |
| 22571 | advertencias | 1 |
| 22572 | adversa | 1 |
| 22573 | advenediza | 1 |
| 22574 | adustos | 1 |
| 22575 | adúlteros | 1 |
| 22576 | adúlteras | 1 |
| 22577 | adulterado | 1 |
| 22578 | adúltera | 1 |
| 22579 | aduladores | 1 |
| 22580 | adulaban | 1 |
| 22581 | aducía | 1 |
| 22582 | aduana | 1 |
| 22583 | adquisición | 1 |
| 22584 | adquirió | 1 |
| 22585 | adquirieron | 1 |
| 22586 | adquirían | 1 |
| 22587 | adquirí | 1 |
| 22588 | adquiera | 1 |
| 22589 | adornó | 1 |
| 22590 | adornar | 1 |
| 22591 | adornadas | 1 |
| 22592 | adornada | 1 |
| 22593 | adormecida | 1 |
| 22594 | adormecerla | 1 |
| 22595 | adorarle | 1 |
| 22596 | adorarla | 1 |
| 22597 | adorar | 1 |
| 22598 | adorando | 1 |
| 22599 | adorados | 1 |
| 22600 | adorada | 1 |
| 22601 | adoptar | 1 |
| 22602 | adoptado | 1 |
| 22603 | adolescentes | 1 |
| 22604 | adocenado | 1 |
| 22605 | adocenada | 1 |
| 22606 | adobes | 1 |
| 22607 | admito | 1 |
| 22608 | admitirlos | 1 |
| 22609 | admitieron | 1 |
| 22610 | admitiera | 1 |
| 22611 | admitida | 1 |
| 22612 | admitían | 1 |
| 22613 | admiré | 1 |
| 22614 | admirarla | 1 |
| 22615 | admiraría | 1 |
| 22616 | admirándole | 1 |
| 22617 | admirándolas | 1 |
| 22618 | admirando | 1 |
| 22619 | admirados | 1 |
| 22620 | admiradora | 1 |
| 22621 | admirador | 1 |
| 22622 | admira | 1 |
| 22623 | administrar | 1 |
| 22624 | administrado | 1 |
| 22625 | adjuntos | 1 |
| 22626 | adjetivos | 1 |
| 22627 | adivinarle | 1 |
| 22628 | adivinando | 1 |
| 22629 | adivinaciones | 1 |
| 22630 | adivina | 1 |
| 22631 | adiosito | 1 |
| 22632 | adiciones | 1 |
| 22633 | adhesión | 1 |
| 22634 | adherirme | 1 |
| 22635 | aderezos | 1 |
| 22636 | adelantos | 1 |
| 22637 | adelantarlo | 1 |
| 22638 | adelantarle | 1 |
| 22639 | adelantándose | 1 |
| 22640 | adelantados | 1 |
| 22641 | adefesios | 1 |
| 22642 | adecuados | 1 |
| 22643 | adecuadas | 1 |
| 22644 | adaptarse | 1 |
| 22645 | adamascado | 1 |
| 22646 | adamado | 1 |
| 22647 | acústico | 1 |
| 22648 | acusó | 1 |
| 22649 | acuso | 1 |
| 22650 | acusemos | 1 |
| 22651 | acusara | 1 |
| 22652 | acusadora | 1 |
| 22653 | acusada | 1 |
| 22654 | acusaciones | 1 |
| 22655 | acusaban | 1 |
| 22656 | acumulando | 1 |
| 22657 | acuestes | 1 |
| 22658 | acuéstate | 1 |
| 22659 | acuestas | 1 |
| 22660 | acuérdese | 1 |
| 22661 | acuerda | 1 |
| 22662 | acudiesen | 1 |
| 22663 | acudiese | 1 |
| 22664 | acudiendo | 1 |
| 22665 | acuden | 1 |
| 22666 | acude | 1 |
| 22667 | acuda | 1 |
| 22668 | acuarelas | 1 |
| 22669 | actrices | 1 |
| 22670 | actitudes | 1 |
| 22671 | acti | 1 |
| 22672 | acta | 1 |
| 22673 | acróbata | 1 |
| 22674 | acritud | 1 |
| 22675 | acribillada | 1 |
| 22676 | acreedores | 1 |
| 22677 | acreditado | 1 |
| 22678 | acreditadas | 1 |
| 22679 | acreditaban | 1 |
| 22680 | acostumbre | 1 |
| 22681 | acostumbra | 1 |
| 22682 | acostaron | 1 |
| 22683 | acostarla | 1 |
| 22684 | acostara | 1 |
| 22685 | acostada | 1 |
| 22686 | acostabas | 1 |
| 22687 | acosarla | 1 |
| 22688 | acortaban | 1 |
| 22689 | acordase | 1 |
| 22690 | acordarte | 1 |
| 22691 | acordaron | 1 |
| 22692 | acordaría | 1 |
| 22693 | acontecimiento | 1 |
| 22694 | acontecía | 1 |
| 22695 | acontecer | 1 |
| 22696 | acontecemos | 1 |
| 22697 | aconsejó | 1 |
| 22698 | aconsejes | 1 |
| 22699 | aconsejarte | 1 |
| 22700 | aconsejaron | 1 |
| 22701 | aconsejaría | 1 |
| 22702 | aconsejan | 1 |
| 22703 | aconsejada | 1 |
| 22704 | aconsejaban | 1 |
| 22705 | acongojaba | 1 |
| 22706 | acompasado | 1 |
| 22707 | acompañó | 1 |
| 22708 | acompáñenos | 1 |
| 22709 | acompáñeme | 1 |
| 22710 | acompañe | 1 |
| 22711 | acompañase | 1 |
| 22712 | acompañarse | 1 |
| 22713 | acompañarlos | 1 |
| 22714 | acompañaré | 1 |
| 22715 | acompañados | 1 |
| 22716 | acompañadas | 1 |
| 22717 | acompaña | 1 |
| 22718 | acomodaron | 1 |
| 22719 | acomodamiento | 1 |
| 22720 | acomoda | 1 |
| 22721 | acogido | 1 |
| 22722 | acogidas | 1 |
| 22723 | acogida | 1 |
| 22724 | acogíase | 1 |
| 22725 | acogerse | 1 |
| 22726 | aclimató | 1 |
| 22727 | aclimataba | 1 |
| 22728 | aclararlo | 1 |
| 22729 | aclamación | 1 |
| 22730 | aciertos | 1 |
| 22731 | aciertas | 1 |
| 22732 | acierta | 1 |
| 22733 | acíbar | 1 |
| 22734 | achico | 1 |
| 22735 | achicaba | 1 |
| 22736 | achaparrado | 1 |
| 22737 | achaparrada | 1 |
| 22738 | achantarse | 1 |
| 22739 | achacó | 1 |
| 22740 | achacaban | 1 |
| 22741 | acervo | 1 |
| 22742 | acertaría | 1 |
| 22743 | acertar | 1 |
| 22744 | acertada | 1 |
| 22745 | acertaba | 1 |
| 22746 | acerquen | 1 |
| 22747 | acerque | 1 |
| 22748 | aceros | 1 |
| 22749 | acerico | 1 |
| 22750 | acércate | 1 |
| 22751 | acercará | 1 |
| 22752 | acercamos | 1 |
| 22753 | acerados | 1 |
| 22754 | aceptaré | 1 |
| 22755 | aceptámosla | 1 |
| 22756 | aceptables | 1 |
| 22757 | acentos | 1 |
| 22758 | acendrados | 1 |
| 22759 | acelerar | 1 |
| 22760 | aceleraba | 1 |
| 22761 | aceitunas | 1 |
| 22762 | acecharse | 1 |
| 22763 | acechar | 1 |
| 22764 | acecha | 1 |
| 22765 | accionistas | 1 |
| 22766 | accionaba | 1 |
| 22767 | accesorios | 1 |
| 22768 | acceso | 1 |
| 22769 | accèsit | 1 |
| 22770 | accedido | 1 |
| 22771 | accedería | 1 |
| 22772 | acceder | 1 |
| 22773 | acatarrada | 1 |
| 22774 | acartonada | 1 |
| 22775 | acarreaba | 1 |
| 22776 | acaricie | 1 |
| 22777 | acariciarte | 1 |
| 22778 | acariciarle | 1 |
| 22779 | acariciar | 1 |
| 22780 | acariciadores | 1 |
| 22781 | acariciado | 1 |
| 22782 | acariciaban | 1 |
| 22783 | acaparó | 1 |
| 22784 | acaparadores | 1 |
| 22785 | acantos | 1 |
| 22786 | acantilados | 1 |
| 22787 | acamparon | 1 |
| 22788 | acalorado | 1 |
| 22789 | acalorada | 1 |
| 22790 | acaloraba | 1 |
| 22791 | acalló | 1 |
| 22792 | acallar | 1 |
| 22793 | académicos | 1 |
| 22794 | acabose | 1 |
| 22795 | acabo | 1 |
| 22796 | acaben | 1 |
| 22797 | acabemos | 1 |
| 22798 | acabasen | 1 |
| 22799 | acabársele | 1 |
| 22800 | acabaría | 1 |
| 22801 | acabarás | 1 |
| 22802 | acabará | 1 |
| 22803 | acabando | 1 |
| 22804 | acabamos | 1 |
| 22805 | abyección | 1 |
| 22806 | abuse | 1 |
| 22807 | abusas | 1 |
| 22808 | abusarse | 1 |
| 22809 | aburro | 1 |
| 22810 | aburrirle | 1 |
| 22811 | aburrieran | 1 |
| 22812 | aburriéndose | 1 |
| 22813 | aburriendo | 1 |
| 22814 | aburridos | 1 |
| 22815 | aburridas | 1 |
| 22816 | abur | 1 |
| 22817 | abundasen | 1 |
| 22818 | abundantemente | 1 |
| 22819 | abundando | 1 |
| 22820 | abunda | 1 |
| 22821 | abultado | 1 |
| 22822 | abultada | 1 |
| 22823 | abuelo | 1 |
| 22824 | absueltos | 1 |
| 22825 | absuelto | 1 |
| 22826 | absuelta | 1 |
| 22827 | abstuviese | 1 |
| 22828 | abstuviera | 1 |
| 22829 | abstraída | 1 |
| 22830 | abstractos | 1 |
| 22831 | abstiene | 1 |
| 22832 | abstenerse | 1 |
| 22833 | abstenerme | 1 |
| 22834 | abstendría | 1 |
| 22835 | abstención | 1 |
| 22836 | absortos | 1 |
| 22837 | absorto | 1 |
| 22838 | absorta | 1 |
| 22839 | absorbía | 1 |
| 22840 | absorben | 1 |
| 22841 | absolvería | 1 |
| 22842 | absolutos | 1 |
| 22843 | abrumándole | 1 |
| 22844 | abrumando | 1 |
| 22845 | abrumadores | 1 |
| 22846 | abrumadora | 1 |
| 22847 | abrumador | 1 |
| 22848 | abrumada | 1 |
| 22849 | abroquelado | 1 |
| 22850 | abrochar | 1 |
| 22851 | abrochándose | 1 |
| 22852 | abrochando | 1 |
| 22853 | abrochado | 1 |
| 22854 | abrochada | 1 |
| 22855 | abro | 1 |
| 22856 | abrirse | 1 |
| 22857 | abrirá | 1 |
| 22858 | abriles | 1 |
| 22859 | abrigos | 1 |
| 22860 | abrigara | 1 |
| 22861 | abrigan | 1 |
| 22862 | abrigábala | 1 |
| 22863 | abrigaba | 1 |
| 22864 | abrieran | 1 |
| 22865 | abreviaturas | 1 |
| 22866 | abreviar | 1 |
| 22867 | abreviada | 1 |
| 22868 | abren | 1 |
| 22869 | ábreme | 1 |
| 22870 | abre | 1 |
| 22871 | abrazase | 1 |
| 22872 | abrazada | 1 |
| 22873 | abrazaba | 1 |
| 22874 | ábrase | 1 |
| 22875 | abrasarme | 1 |
| 22876 | abrasadores | 1 |
| 22877 | abrasa | 1 |
| 22878 | aborrecían | 1 |
| 22879 | aborrecerá | 1 |
| 22880 | aborrecen | 1 |
| 22881 | abordase | 1 |
| 22882 | abonado | 1 |
| 22883 | abomino | 1 |
| 22884 | abominación | 1 |
| 22885 | abominaba | 1 |
| 22886 | abogadote | 1 |
| 22887 | abogado | 1 |
| 22888 | abogadillos | 1 |
| 22889 | abogadetes | 1 |
| 22890 | abofetear | 1 |
| 22891 | abluciones | 1 |
| 22892 | ablativo | 1 |
| 22893 | ablandado | 1 |
| 22894 | abismado | 1 |
| 22895 | abismada | 1 |
| 22896 | abertura | 1 |
| 22897 | abelardo | 1 |
| 22898 | abeja | 1 |
| 22899 | abarcándola | 1 |
| 22900 | abarcaba | 1 |
| 22901 | abanicándose | 1 |
| 22902 | abanicaba | 1 |
| 22903 | abandonó | 1 |
| 22904 | abandonarme | 1 |
| 22905 | abandonarlo | 1 |
| 22906 | abandonados | 1 |
| 22907 | abandonadas | 1 |
|
| Rank | Palabra | Frec |
|---|
| 1 | el | 29227 |
| 2 | de | 19493 |
| 3 | que | 9866 |
| 4 | a | 9542 |
| 5 | y | 9435 |
| 6 | lo | 7613 |
| 7 | en | 7123 |
| 8 | se | 6093 |
| 9 | un | 5272 |
| 10 | no | 4979 |
| 11 | ser | 4157 |
| 12 | su | 4081 |
| 13 | haber | 3872 |
| 14 | con | 3199 |
| 15 | por | 2872 |
| 16 | pero | 1908 |
| 17 | aquel | 1882 |
| 18 | don | 1791 |
| 19 | todo | 1770 |
| 20 | como | 1751 |
| 21 | más | 1725 |
| 22 | estar | 1438 |
| 23 | tener | 1431 |
| 24 | decir | 1398 |
| 25 | para | 1365 |
| 26 | si | 1165 |
| 27 | él | 1112 |
| 28 | qué | 1109 |
| 29 | sin | 1096 |
| 30 | poder | 1039 |
| 31 | ella | 1007 |
| 32 | hacer | 999 |
| 33 | otro | 944 |
| 34 | ver | 920 |
| 35 | ya | 902 |
| 36 | ana | 896 |
| 37 | saber | 867 |
| 38 | querer | 865 |
| 39 | usted | 806 |
| 40 | ir | 781 |
| 41 | me | 774 |
| 42 | magistral | 769 |
| 43 | este | 745 |
| 44 | yo | 696 |
| 45 | dar | 693 |
| 46 | sí | 671 |
| 47 | ni | 671 |
| 48 | era | 669 |
| 49 | mucho | 659 |
| 50 | hablar | 636 |
| 51 | o | 634 |
| 52 | la | 631 |
| 53 | vez | 608 |
| 54 | poco | 594 |
| 55 | éste | 590 |
| 56 | pensar | 570 |
| 57 | parecer | 563 |
| 58 | muy | 555 |
| 59 | señor | 529 |
| 60 | volver | 514 |
| 61 | sobre | 506 |
| 62 | cuando | 494 |
| 63 | víctor | 490 |
| 64 | casa | 488 |
| 65 | mismo | 485 |
| 66 | regenta | 468 |
| 67 | sentir | 453 |
| 68 | allí | 446 |
| 69 | bueno | 445 |
| 70 | día | 444 |
| 71 | vetusta | 443 |
| 72 | dejar | 440 |
| 73 | nada | 416 |
| 74 | después | 416 |
| 75 | doña | 414 |
| 76 | llegar | 410 |
| 77 | porque | 396 |
| 78 | creer | 393 |
| 79 | algún | 381 |
| 80 | hombre | 378 |
| 81 | grande | 378 |
| 82 | salir | 376 |
| 83 | también | 374 |
| 84 | mesía | 372 |
| 85 | oír | 363 |
| 86 | ahora | 361 |
| 87 | entre | 360 |
| 88 | bien | 358 |
| 89 | ojo | 355 |
| 90 | hasta | 352 |
| 91 | mi | 350 |
| 92 | mujer | 349 |
| 93 | llamar | 349 |
| 94 | fermín | 349 |
| 95 | cosa | 348 |
| 96 | pasar | 347 |
| 97 | dios | 346 |
| 98 | dos | 333 |
| 99 | ése | 331 |
| 100 | siempre | 330 |
| 101 | tan | 327 |
| 102 | menos | 325 |
| 103 | así | 325 |
| 104 | deber | 324 |
| 105 | vida | 319 |
| 106 | algo | 318 |
| 107 | amor | 314 |
| 108 | mirar | 306 |
| 109 | tiempo | 304 |
| 110 | quintanar | 304 |
| 111 | ese | 304 |
| 112 | amigo | 303 |
| 113 | venir | 301 |
| 114 | señora | 301 |
| 115 | hijo | 296 |
| 116 | tanto | 294 |
| 117 | mundo | 292 |
| 118 | alma | 292 |
| 119 | te | 286 |
| 120 | mano | 286 |
| 121 | hora | 283 |
| 122 | poner | 280 |
| 123 | noche | 270 |
| 124 | voz | 266 |
| 125 | comer | 262 |
| 126 | mal | 258 |
| 127 | mejor | 253 |
| 128 | madre | 252 |
| 129 | desde | 251 |
| 130 | aquél | 251 |
| 131 | pues | 249 |
| 132 | cabeza | 248 |
| 133 | tal | 245 |
| 134 | petra | 241 |
| 135 | año | 238 |
| 136 | quien | 231 |
| 137 | quedar | 231 |
| 138 | entrar | 230 |
| 139 | seguir | 220 |
| 140 | aunque | 219 |
| 141 | cuanto | 212 |
| 142 | tarde | 209 |
| 143 | llevar | 208 |
| 144 | frígilis | 207 |
| 145 | tomar | 205 |
| 146 | cierto | 205 |
| 147 | además | 205 |
| 148 | es | 202 |
| 149 | encontrar | 202 |
| 150 | pie | 200 |
| 151 | nuevo | 200 |
| 152 | solo | 199 |
| 153 | palabra | 199 |
| 154 | nadie | 199 |
| 155 | leer | 197 |
| 156 | caer | 197 |
| 157 | obdulia | 194 |
| 158 | los | 194 |
| 159 | buscar | 194 |
| 160 | casi | 192 |
| 161 | según | 191 |
| 162 | morir | 190 |
| 163 | entonces | 190 |
| 164 | anita | 189 |
| 165 | antes | 187 |
| 166 | donde | 186 |
| 167 | cómo | 186 |
| 168 | quién | 183 |
| 169 | idea | 183 |
| 170 | mientras | 182 |
| 171 | entender | 182 |
| 172 | conocer | 182 |
| 173 | vivir | 181 |
| 174 | visita | 179 |
| 175 | recordar | 178 |
| 176 | perder | 178 |
| 177 | cuerpo | 175 |
| 178 | cada | 174 |
| 179 | paula | 173 |
| 180 | sólo | 172 |
| 181 | paco | 171 |
| 182 | aquí | 171 |
| 183 | pas | 170 |
| 184 | esperar | 170 |
| 185 | dentro | 167 |
| 186 | luz | 166 |
| 187 | fin | 166 |
| 188 | allá | 166 |
| 189 | nunca | 164 |
| 190 | paso | 162 |
| 191 | pobre | 159 |
| 192 | correr | 159 |
| 193 | tratar | 158 |
| 194 | fuera | 158 |
| 195 | puerta | 157 |
| 196 | momento | 157 |
| 197 | verdad | 155 |
| 198 | provisor | 155 |
| 199 | subir | 154 |
| 200 | modo | 153 |
| 201 | mayor | 153 |
| 202 | atrever | 149 |
| 203 | negro | 146 |
| 204 | demás | 145 |
| 205 | brazo | 144 |
| 206 | al | 143 |
| 207 | abrir | 143 |
| 208 | una | 142 |
| 209 | parte | 142 |
| 210 | iglesia | 142 |
| 211 | marquesa | 141 |
| 212 | tú | 140 |
| 213 | sonreír | 140 |
| 214 | necesitar | 140 |
| 215 | padre | 139 |
| 216 | contar | 139 |
| 217 | comprender | 139 |
| 218 | santo | 138 |
| 219 | pedir | 138 |
| 220 | miedo | 138 |
| 221 | hecho | 138 |
| 222 | echar | 138 |
| 223 | nos | 137 |
| 224 | malo | 137 |
| 225 | marqués | 136 |
| 226 | alto | 134 |
| 227 | confesar | 133 |
| 228 | vegallana | 132 |
| 229 | lado | 132 |
| 230 | calle | 132 |
| 231 | sino | 131 |
| 232 | ellos | 131 |
| 233 | tres | 130 |
| 234 | ronzal | 130 |
| 235 | callar | 130 |
| 236 | oh | 129 |
| 237 | seguro | 128 |
| 238 | medio | 128 |
| 239 | fuerza | 128 |
| 240 | uno | 127 |
| 241 | frío | 127 |
| 242 | marido | 126 |
| 243 | levantar | 126 |
| 244 | fuerte | 126 |
| 245 | acabar | 126 |
| 246 | pompeyo | 125 |
| 247 | obispo | 125 |
| 248 | espíritu | 125 |
| 249 | llenar | 124 |
| 250 | aire | 123 |
| 251 | figurar | 122 |
| 252 | dormir | 122 |
| 253 | suyo | 121 |
| 254 | servir | 121 |
| 255 | pueblo | 121 |
| 256 | ozores | 121 |
| 257 | catedral | 121 |
| 258 | blanco | 120 |
| 259 | mí | 119 |
| 260 | pasión | 118 |
| 261 | casino | 118 |
| 262 | balcón | 118 |
| 263 | triste | 117 |
| 264 | loco | 117 |
| 265 | lejos | 117 |
| 266 | acercar | 117 |
| 267 | faltar | 116 |
| 268 | pesar | 115 |
| 269 | eso | 115 |
| 270 | pronto | 114 |
| 271 | mañana | 114 |
| 272 | ante | 114 |
| 273 | corazón | 112 |
| 274 | soler | 111 |
| 275 | claro | 111 |
| 276 | vestir | 110 |
| 277 | mío | 110 |
| 278 | libro | 110 |
| 279 | empezar | 110 |
| 280 | paseo | 108 |
| 281 | agua | 108 |
| 282 | último | 107 |
| 283 | ruido | 107 |
| 284 | junto | 107 |
| 285 | cual | 107 |
| 286 | santos | 106 |
| 287 | bajo | 106 |
| 288 | propio | 104 |
| 289 | placer | 104 |
| 290 | dulce | 104 |
| 291 | contra | 104 |
| 292 | sentar | 103 |
| 293 | san | 103 |
| 294 | notar | 103 |
| 295 | escribir | 103 |
| 296 | cura | 103 |
| 297 | visitación | 102 |
| 298 | tocar | 102 |
| 299 | rostro | 102 |
| 300 | dama | 102 |
| 301 | cantar | 102 |
| 302 | teatro | 101 |
| 303 | salón | 101 |
| 304 | puro | 101 |
| 305 | cielo | 101 |
| 306 | traer | 100 |
| 307 | temer | 100 |
| 308 | presentar | 100 |
| 309 | canónigo | 100 |
| 310 | sol | 99 |
| 311 | silencio | 99 |
| 312 | cerca | 98 |
| 313 | ripamilán | 97 |
| 314 | ridículo | 97 |
| 315 | mesa | 97 |
| 316 | enemigo | 97 |
| 317 | olvidar | 96 |
| 318 | procurar | 95 |
| 319 | preguntar | 95 |
| 320 | camino | 95 |
| 321 | mover | 94 |
| 322 | importar | 94 |
| 323 | hacia | 94 |
| 324 | detrás | 94 |
| 325 | andar | 94 |
| 326 | virtud | 93 |
| 327 | matar | 93 |
| 328 | mandar | 93 |
| 329 | las | 93 |
| 330 | foja | 93 |
| 331 | casar | 93 |
| 332 | boca | 93 |
| 333 | amo | 93 |
| 334 | obscuro | 92 |
| 335 | hermoso | 92 |
| 336 | caso | 92 |
| 337 | cualquier | 91 |
| 338 | todavía | 90 |
| 339 | sacar | 90 |
| 340 | piedad | 90 |
| 341 | pensamiento | 90 |
| 342 | llorar | 90 |
| 343 | jamás | 90 |
| 344 | fe | 90 |
| 345 | explicar | 90 |
| 346 | alegría | 90 |
| 347 | sombra | 89 |
| 348 | reír | 89 |
| 349 | glocester | 89 |
| 350 | delante | 89 |
| 351 | veces | 88 |
| 352 | religión | 88 |
| 353 | razón | 88 |
| 354 | enamorar | 88 |
| 355 | cerrar | 88 |
| 356 | único | 87 |
| 357 | tierra | 87 |
| 358 | vuelta | 86 |
| 359 | ello | 86 |
| 360 | amar | 86 |
| 361 | acordar | 86 |
| 362 | nuestro | 85 |
| 363 | general | 85 |
| 364 | contestar | 85 |
| 365 | color | 85 |
| 366 | ningún | 84 |
| 367 | gritar | 84 |
| 368 | gozar | 84 |
| 369 | cara | 84 |
| 370 | orgaz | 83 |
| 371 | médico | 83 |
| 372 | tales | 82 |
| 373 | preferir | 82 |
| 374 | persona | 82 |
| 375 | pasado | 82 |
| 376 | largo | 82 |
| 377 | guimarán | 82 |
| 378 | clérigo | 82 |
| 379 | arte | 82 |
| 380 | viejo | 81 |
| 381 | noble | 81 |
| 382 | negar | 81 |
| 383 | siquiera | 80 |
| 384 | pálido | 80 |
| 385 | muerte | 80 |
| 386 | mirada | 80 |
| 387 | media | 80 |
| 388 | gabinete | 80 |
| 389 | frente | 80 |
| 390 | natural | 79 |
| 391 | dónde | 79 |
| 392 | conciencia | 79 |
| 393 | ustedes | 78 |
| 394 | ocasión | 78 |
| 395 | miserable | 78 |
| 396 | efecto | 78 |
| 397 | asustar | 78 |
| 398 | vivero | 77 |
| 399 | obra | 77 |
| 400 | ellas | 77 |
| 401 | carne | 77 |
| 402 | tu | 76 |
| 403 | gracia | 76 |
| 404 | dijo | 76 |
| 405 | conversación | 76 |
| 406 | capilla | 76 |
| 407 | campo | 76 |
| 408 | lecho | 75 |
| 409 | hombro | 75 |
| 410 | engañar | 75 |
| 411 | deseo | 75 |
| 412 | debajo | 75 |
| 413 | bajar | 75 |
| 414 | joven | 74 |
| 415 | cuatro | 74 |
| 416 | cuarto | 74 |
| 417 | coger | 74 |
| 418 | bermúdez | 74 |
| 419 | arrojar | 74 |
| 420 | religioso | 73 |
| 421 | pagar | 73 |
| 422 | ocultar | 73 |
| 423 | niño | 73 |
| 424 | madrid | 73 |
| 425 | enfermo | 73 |
| 426 | despertar | 73 |
| 427 | abajo | 73 |
| 428 | vencer | 72 |
| 429 | repente | 72 |
| 430 | punto | 72 |
| 431 | preparar | 72 |
| 432 | papel | 72 |
| 433 | tono | 71 |
| 434 | secreto | 71 |
| 435 | piedra | 71 |
| 436 | manera | 71 |
| 437 | dolor | 71 |
| 438 | convertir | 71 |
| 439 | antiguo | 71 |
| 440 | sueño | 70 |
| 441 | mil | 70 |
| 442 | fuego | 70 |
| 443 | esposo | 70 |
| 444 | despreciar | 70 |
| 445 | ahí | 70 |
| 446 | puesto | 69 |
| 447 | público | 69 |
| 448 | meter | 69 |
| 449 | huir | 69 |
| 450 | hoy | 69 |
| 451 | despacho | 69 |
| 452 | serio | 68 |
| 453 | saltar | 68 |
| 454 | primero | 68 |
| 455 | lágrima | 68 |
| 456 | costumbre | 68 |
| 457 | comenzar | 68 |
| 458 | tristeza | 67 |
| 459 | tampoco | 67 |
| 460 | sonar | 67 |
| 461 | saludar | 67 |
| 462 | primera | 67 |
| 463 | nombre | 67 |
| 464 | jesús | 67 |
| 465 | fingir | 67 |
| 466 | conseguir | 67 |
| 467 | carta | 67 |
| 468 | ayudar | 67 |
| 469 | asunto | 67 |
| 470 | temblar | 66 |
| 471 | salud | 66 |
| 472 | recibir | 66 |
| 473 | petronila | 66 |
| 474 | ofrecer | 66 |
| 475 | honor | 66 |
| 476 | fondo | 66 |
| 477 | despedir | 66 |
| 478 | confesión | 66 |
| 479 | cama | 66 |
| 480 | sentido | 65 |
| 481 | santa | 65 |
| 482 | pasear | 65 |
| 483 | exigir | 65 |
| 484 | demasiado | 65 |
| 485 | dignar | 64 |
| 486 | derecho | 64 |
| 487 | caserón | 64 |
| 488 | verde | 63 |
| 489 | valer | 63 |
| 490 | señorita | 63 |
| 491 | dedo | 63 |
| 492 | tranquilo | 62 |
| 493 | presencia | 62 |
| 494 | moral | 62 |
| 495 | gusto | 62 |
| 496 | gustar | 62 |
| 497 | entregar | 62 |
| 498 | duda | 62 |
| 499 | culpa | 62 |
| 500 | coche | 62 |
| 501 | carlos | 62 |
| 502 | ocho | 61 |
| 503 | inclinar | 61 |
| 504 | historia | 61 |
| 505 | atrás | 61 |
| 506 | arcipreste | 61 |
| 507 | verso | 60 |
| 508 | sangre | 60 |
| 509 | peor | 60 |
| 510 | hermano | 60 |
| 511 | espiritual | 60 |
| 512 | cerebro | 60 |
| 513 | bastar | 60 |
| 514 | banco | 60 |
| 515 | arriba | 60 |
| 516 | alegrar | 60 |
| 517 | acompañar | 60 |
| 518 | sé | 59 |
| 519 | satisfacer | 59 |
| 520 | peligro | 59 |
| 521 | labio | 59 |
| 522 | frase | 59 |
| 523 | espolón | 59 |
| 524 | elegante | 59 |
| 525 | aparecer | 59 |
| 526 | admirar | 59 |
| 527 | vergüenza | 58 |
| 528 | primer | 58 |
| 529 | pared | 58 |
| 530 | gesto | 58 |
| 531 | detener | 58 |
| 532 | clase | 58 |
| 533 | alcoba | 58 |
| 534 | tío | 57 |
| 535 | separar | 57 |
| 536 | principal | 57 |
| 537 | plaza | 57 |
| 538 | escándalo | 57 |
| 539 | criar | 57 |
| 540 | barinaga | 57 |
| 541 | voluntad | 56 |
| 542 | pecado | 56 |
| 543 | libre | 56 |
| 544 | entero | 56 |
| 545 | disimular | 56 |
| 546 | calor | 56 |
| 547 | aventura | 56 |
| 548 | apretar | 56 |
| 549 | apoyar | 56 |
| 550 | valor | 55 |
| 551 | teresina | 55 |
| 552 | rodear | 55 |
| 553 | obligar | 55 |
| 554 | mozo | 55 |
| 555 | jurar | 55 |
| 556 | joaquín | 55 |
| 557 | íntimo | 55 |
| 558 | ganar | 55 |
| 559 | curar | 55 |
| 560 | cubrir | 55 |
| 561 | caballero | 55 |
| 562 | verdadero | 54 |
| 563 | tentación | 54 |
| 564 | rincón | 54 |
| 565 | repetir | 54 |
| 566 | remordimiento | 54 |
| 567 | reconocer | 54 |
| 568 | oro | 54 |
| 569 | mar | 54 |
| 570 | gritó | 54 |
| 571 | escena | 54 |
| 572 | embargo | 54 |
| 573 | coro | 54 |
| 574 | bastante | 54 |
| 575 | absurdo | 54 |
| 576 | traje | 53 |
| 577 | nube | 53 |
| 578 | materia | 53 |
| 579 | juventud | 53 |
| 580 | edelmira | 53 |
| 581 | disponer | 53 |
| 582 | cuyo | 53 |
| 583 | culto | 53 |
| 584 | continuar | 53 |
| 585 | árbol | 53 |
| 586 | aldea | 53 |
| 587 | sotana | 52 |
| 588 | rico | 52 |
| 589 | propósito | 52 |
| 590 | luna | 52 |
| 591 | forma | 52 |
| 592 | estrecho | 52 |
| 593 | cruz | 52 |
| 594 | convenir | 52 |
| 595 | contener | 52 |
| 596 | adelantar | 52 |
| 597 | acudir | 52 |
| 598 | respetar | 51 |
| 599 | oído | 51 |
| 600 | mejilla | 51 |
| 601 | liberal | 51 |
| 602 | huerta | 51 |
| 603 | doncella | 51 |
| 604 | costar | 51 |
| 605 | confianza | 51 |
| 606 | clavar | 51 |
| 607 | son | 50 |
| 608 | somoza | 50 |
| 609 | siglo | 50 |
| 610 | representar | 50 |
| 611 | palacio | 50 |
| 612 | necesario | 50 |
| 613 | mes | 50 |
| 614 | humor | 50 |
| 615 | etcétera | 50 |
| 616 | especie | 50 |
| 617 | cristal | 50 |
| 618 | contemplar | 50 |
| 619 | atención | 50 |
| 620 | antojar | 50 |
| 621 | ánimo | 50 |
| 622 | teresa | 49 |
| 623 | sospechar | 49 |
| 624 | proponer | 49 |
| 625 | prometer | 49 |
| 626 | perdonar | 49 |
| 627 | pedro | 49 |
| 628 | espalda | 49 |
| 629 | enfermedad | 49 |
| 630 | declarar | 49 |
| 631 | custodio | 49 |
| 632 | carcajada | 49 |
| 633 | ancho | 49 |
| 634 | visitar | 48 |
| 635 | ventana | 48 |
| 636 | usar | 48 |
| 637 | suerte | 48 |
| 638 | soñar | 48 |
| 639 | sonrisa | 48 |
| 640 | preguntó | 48 |
| 641 | permitir | 48 |
| 642 | ocurrir | 48 |
| 643 | motivo | 48 |
| 644 | jugar | 48 |
| 645 | guardar | 48 |
| 646 | dinero | 48 |
| 647 | cuestión | 48 |
| 648 | cuadro | 48 |
| 649 | cayetano | 48 |
| 650 | broma | 48 |
| 651 | bosque | 48 |
| 652 | arrancar | 48 |
| 653 | arcediano | 48 |
| 654 | templo | 47 |
| 655 | suelo | 47 |
| 656 | segundo | 47 |
| 657 | salvar | 47 |
| 658 | romántico | 47 |
| 659 | resolver | 47 |
| 660 | polvo | 47 |
| 661 | perro | 47 |
| 662 | naturaleza | 47 |
| 663 | música | 47 |
| 664 | mezclar | 47 |
| 665 | fijo | 47 |
| 666 | d | 47 |
| 667 | contentar | 47 |
| 668 | clero | 47 |
| 669 | chico | 47 |
| 670 | caballo | 47 |
| 671 | baile | 47 |
| 672 | anuncia | 47 |
| 673 | adelante | 47 |
| 674 | vulgar | 46 |
| 675 | verano | 46 |
| 676 | trabajo | 46 |
| 677 | suave | 46 |
| 678 | prohibir | 46 |
| 679 | profundo | 46 |
| 680 | partido | 46 |
| 681 | parque | 46 |
| 682 | místico | 46 |
| 683 | locura | 46 |
| 684 | ley | 46 |
| 685 | hoja | 46 |
| 686 | hermosura | 46 |
| 687 | eterno | 46 |
| 688 | esconder | 46 |
| 689 | e | 46 |
| 690 | ciudad | 46 |
| 691 | ciencia | 46 |
| 692 | carraspique | 46 |
| 693 | cargar | 46 |
| 694 | asomar | 46 |
| 695 | añadir | 46 |
| 696 | vamos | 45 |
| 697 | silla | 45 |
| 698 | señorito | 45 |
| 699 | recuerdo | 45 |
| 700 | piadoso | 45 |
| 701 | parar | 45 |
| 702 | páez | 45 |
| 703 | letra | 45 |
| 704 | juan | 45 |
| 705 | frutos | 45 |
| 706 | diez | 45 |
| 707 | descubrir | 45 |
| 708 | decía | 45 |
| 709 | dado | 45 |
| 710 | cinco | 45 |
| 711 | aborrecer | 45 |
| 712 | volar | 44 |
| 713 | semejante | 44 |
| 714 | seguida | 44 |
| 715 | periódico | 44 |
| 716 | ocupar | 44 |
| 717 | murmurar | 44 |
| 718 | lugar | 44 |
| 719 | hija | 44 |
| 720 | grosero | 44 |
| 721 | estilo | 44 |
| 722 | esperanza | 44 |
| 723 | encoger | 44 |
| 724 | devoto | 44 |
| 725 | cumplir | 44 |
| 726 | crimen | 44 |
| 727 | caridad | 44 |
| 728 | benítez | 44 |
| 729 | amistad | 44 |
| 730 | alegre | 44 |
| 731 | acaso | 44 |
| 732 | siguiente | 43 |
| 733 | saturnino | 43 |
| 734 | sala | 43 |
| 735 | sacerdote | 43 |
| 736 | sabio | 43 |
| 737 | quejar | 43 |
| 738 | minuto | 43 |
| 739 | marquesito | 43 |
| 740 | le | 43 |
| 741 | esfuerzo | 43 |
| 742 | del | 43 |
| 743 | confesor | 43 |
| 744 | comedor | 43 |
| 745 | cocina | 43 |
| 746 | beber | 43 |
| 747 | aprensión | 43 |
| 748 | vengar | 42 |
| 749 | sociedad | 42 |
| 750 | político | 42 |
| 751 | nosotros | 42 |
| 752 | molestar | 42 |
| 753 | merecer | 42 |
| 754 | interés | 42 |
| 755 | imagen | 42 |
| 756 | ideal | 42 |
| 757 | hierro | 42 |
| 758 | familia | 42 |
| 759 | falda | 42 |
| 760 | enterar | 42 |
| 761 | dominar | 42 |
| 762 | aún | 42 |
| 763 | tardar | 41 |
| 764 | soledad | 41 |
| 765 | señalar | 41 |
| 766 | recoger | 41 |
| 767 | protestar | 41 |
| 768 | orgullo | 41 |
| 769 | nervioso | 41 |
| 770 | movimiento | 41 |
| 771 | expresión | 41 |
| 772 | ex | 41 |
| 773 | envidiar | 41 |
| 774 | ejemplo | 41 |
| 775 | diablo | 41 |
| 776 | desear | 41 |
| 777 | crespo | 41 |
| 778 | celo | 41 |
| 779 | virgen | 40 |
| 780 | romper | 40 |
| 781 | respirar | 40 |
| 782 | quitar | 40 |
| 783 | probar | 40 |
| 784 | paz | 40 |
| 785 | opinión | 40 |
| 786 | necesidad | 40 |
| 787 | muerto | 40 |
| 788 | monte | 40 |
| 789 | memoria | 40 |
| 790 | lleno | 40 |
| 791 | lengua | 40 |
| 792 | lástima | 40 |
| 793 | juego | 40 |
| 794 | irritar | 40 |
| 795 | hambre | 40 |
| 796 | grito | 40 |
| 797 | energía | 40 |
| 798 | emplear | 40 |
| 799 | emoción | 40 |
| 800 | cortar | 40 |
| 801 | cabo | 40 |
| 802 | asegurar | 40 |
| 803 | suspirar | 39 |
| 804 | remedio | 39 |
| 805 | referir | 39 |
| 806 | perseguir | 39 |
| 807 | marchar | 39 |
| 808 | luego | 39 |
| 809 | lucir | 39 |
| 810 | lejano | 39 |
| 811 | ira | 39 |
| 812 | imponer | 39 |
| 813 | imaginación | 39 |
| 814 | cuánto | 39 |
| 815 | cristiano | 39 |
| 816 | calumnia | 39 |
| 817 | café | 39 |
| 818 | aprovechar | 39 |
| 819 | apenas | 39 |
| 820 | amante | 39 |
| 821 | vanidad | 38 |
| 822 | trabuco | 38 |
| 823 | temprano | 38 |
| 824 | saturno | 38 |
| 825 | ropa | 38 |
| 826 | rayo | 38 |
| 827 | provincia | 38 |
| 828 | principio | 38 |
| 829 | orden | 38 |
| 830 | objeto | 38 |
| 831 | menudo | 38 |
| 832 | llave | 38 |
| 833 | humilde | 38 |
| 834 | furioso | 38 |
| 835 | fresco | 38 |
| 836 | figura | 38 |
| 837 | estado | 38 |
| 838 | escalera | 38 |
| 839 | delicia | 38 |
| 840 | defender | 38 |
| 841 | convencer | 38 |
| 842 | cenar | 38 |
| 843 | camila | 38 |
| 844 | arrastrar | 38 |
| 845 | acostar | 38 |
| 846 | abandonar | 38 |
| 847 | vista | 37 |
| 848 | trabajar | 37 |
| 849 | torre | 37 |
| 850 | terreno | 37 |
| 851 | sombrero | 37 |
| 852 | resistir | 37 |
| 853 | realidad | 37 |
| 854 | querido | 37 |
| 855 | piso | 37 |
| 856 | pecho | 37 |
| 857 | observar | 37 |
| 858 | nacer | 37 |
| 859 | madera | 37 |
| 860 | librar | 37 |
| 861 | invierno | 37 |
| 862 | imposible | 37 |
| 863 | extremo | 37 |
| 864 | encerrar | 37 |
| 865 | durar | 37 |
| 866 | dudar | 37 |
| 867 | cuidado | 37 |
| 868 | cuello | 37 |
| 869 | comprar | 37 |
| 870 | cansar | 37 |
| 871 | borracho | 37 |
| 872 | venganza | 36 |
| 873 | vano | 36 |
| 874 | suponer | 36 |
| 875 | solemne | 36 |
| 876 | socio | 36 |
| 877 | servicio | 36 |
| 878 | presidente | 36 |
| 879 | luchar | 36 |
| 880 | inútil | 36 |
| 881 | imitar | 36 |
| 882 | gato | 36 |
| 883 | flor | 36 |
| 884 | falta | 36 |
| 885 | escapar | 36 |
| 886 | enfrente | 36 |
| 887 | edad | 36 |
| 888 | divertir | 36 |
| 889 | desgracia | 36 |
| 890 | decidir | 36 |
| 891 | cruzar | 36 |
| 892 | criada | 36 |
| 893 | convento | 36 |
| 894 | consentir | 36 |
| 895 | comedia | 36 |
| 896 | bailar | 36 |
| 897 | ay | 36 |
| 898 | anselmo | 36 |
| 899 | vino | 35 |
| 900 | triunfo | 35 |
| 901 | ti | 35 |
| 902 | rojo | 35 |
| 903 | rezar | 35 |
| 904 | olor | 35 |
| 905 | misa | 35 |
| 906 | mía | 35 |
| 907 | máquina | 35 |
| 908 | gente | 35 |
| 909 | fijar | 35 |
| 910 | feliz | 35 |
| 911 | envidia | 35 |
| 912 | desaparecer | 35 |
| 913 | coser | 35 |
| 914 | corriente | 35 |
| 915 | contento | 35 |
| 916 | considerar | 35 |
| 917 | compañía | 35 |
| 918 | brillar | 35 |
| 919 | aun | 35 |
| 920 | asistir | 35 |
| 921 | anterior | 35 |
| 922 | acto | 35 |
| 923 | viento | 34 |
| 924 | viaje | 34 |
| 925 | tropezar | 34 |
| 926 | tomás | 34 |
| 927 | terminar | 34 |
| 928 | supuesto | 34 |
| 929 | sorprender | 34 |
| 930 | solas | 34 |
| 931 | rumor | 34 |
| 932 | robustiano | 34 |
| 933 | rama | 34 |
| 934 | prado | 34 |
| 935 | pepe | 34 |
| 936 | mostrar | 34 |
| 937 | manteo | 34 |
| 938 | joaquinito | 34 |
| 939 | género | 34 |
| 940 | falso | 34 |
| 941 | extender | 34 |
| 942 | estrépito | 34 |
| 943 | contrario | 34 |
| 944 | cien | 34 |
| 945 | burlar | 34 |
| 946 | azul | 34 |
| 947 | apagar | 34 |
| 948 | aburrir | 34 |
| 949 | tender | 33 |
| 950 | sucio | 33 |
| 951 | suceder | 33 |
| 952 | sacrificio | 33 |
| 953 | reloj | 33 |
| 954 | prueba | 33 |
| 955 | presente | 33 |
| 956 | personaje | 33 |
| 957 | pequeño | 33 |
| 958 | pena | 33 |
| 959 | pecar | 33 |
| 960 | palomares | 33 |
| 961 | padecer | 33 |
| 962 | novela | 33 |
| 963 | nervio | 33 |
| 964 | instante | 33 |
| 965 | había | 33 |
| 966 | formar | 33 |
| 967 | fiel | 33 |
| 968 | exponer | 33 |
| 969 | entusiasmo | 33 |
| 970 | entraña | 33 |
| 971 | eclesiástico | 33 |
| 972 | duelo | 33 |
| 973 | discutir | 33 |
| 974 | dirigir | 33 |
| 975 | diente | 33 |
| 976 | cuidar | 33 |
| 977 | cuenta | 33 |
| 978 | causa | 33 |
| 979 | beata | 33 |
| 980 | viuda | 32 |
| 981 | vago | 32 |
| 982 | terror | 32 |
| 983 | sacudir | 32 |
| 984 | posible | 32 |
| 985 | poesía | 32 |
| 986 | pisar | 32 |
| 987 | piel | 32 |
| 988 | patio | 32 |
| 989 | pan | 32 |
| 990 | pájaro | 32 |
| 991 | morder | 32 |
| 992 | meditar | 32 |
| 993 | maría | 32 |
| 994 | libertad | 32 |
| 995 | fino | 32 |
| 996 | fermo | 32 |
| 997 | enseñar | 32 |
| 998 | encimada | 32 |
| 999 | encender | 32 |
| 1000 | durante | 32 |
| 1001 | digno | 32 |
| 1002 | desafiar | 32 |
| 1003 | cariño | 32 |
| 1004 | beso | 32 |
| 1005 | ateo | 32 |
| 1006 | ataque | 32 |
| 1007 | agradecer | 32 |
| 1008 | admitir | 32 |
| 1009 | víctima | 31 |
| 1010 | tormento | 31 |
| 1011 | terrible | 31 |
| 1012 | risa | 31 |
| 1013 | relación | 31 |
| 1014 | redondo | 31 |
| 1015 | plata | 31 |
| 1016 | pasillo | 31 |
| 1017 | jefe | 31 |
| 1018 | interrumpir | 31 |
| 1019 | insistir | 31 |
| 1020 | hogar | 31 |
| 1021 | grave | 31 |
| 1022 | filósofo | 31 |
| 1023 | farol | 31 |
| 1024 | fama | 31 |
| 1025 | evitar | 31 |
| 1026 | esto | 31 |
| 1027 | encima | 31 |
| 1028 | empeñar | 31 |
| 1029 | consolar | 31 |
| 1030 | comparar | 31 |
| 1031 | cómico | 31 |
| 1032 | citar | 31 |
| 1033 | cesar | 31 |
| 1034 | cazador | 31 |
| 1035 | capaz | 31 |
| 1036 | besar | 31 |
| 1037 | altar | 31 |
| 1038 | vicio | 30 |
| 1039 | vecino | 30 |
| 1040 | varias | 30 |
| 1041 | todas | 30 |
| 1042 | tienda | 30 |
| 1043 | robar | 30 |
| 1044 | río | 30 |
| 1045 | respeto | 30 |
| 1046 | producir | 30 |
| 1047 | poeta | 30 |
| 1048 | noticia | 30 |
| 1049 | nobleza | 30 |
| 1050 | lectura | 30 |
| 1051 | instinto | 30 |
| 1052 | fortunato | 30 |
| 1053 | fortuna | 30 |
| 1054 | fiebre | 30 |
| 1055 | envolver | 30 |
| 1056 | devoción | 30 |
| 1057 | derecha | 30 |
| 1058 | condenar | 30 |
| 1059 | colocar | 30 |
| 1060 | colgar | 30 |
| 1061 | causar | 30 |
| 1062 | ayer | 30 |
| 1063 | adiós | 30 |
| 1064 | yerba | 29 |
| 1065 | vivo | 29 |
| 1066 | tirar | 29 |
| 1067 | susto | 29 |
| 1068 | sujetar | 29 |
| 1069 | social | 29 |
| 1070 | sermón | 29 |
| 1071 | sentimiento | 29 |
| 1072 | rufina | 29 |
| 1073 | rosa | 29 |
| 1074 | respetable | 29 |
| 1075 | regente | 29 |
| 1076 | portal | 29 |
| 1077 | poderoso | 29 |
| 1078 | pasa | 29 |
| 1079 | misterioso | 29 |
| 1080 | juntar | 29 |
| 1081 | humano | 29 |
| 1082 | honrar | 29 |
| 1083 | grandeza | 29 |
| 1084 | galería | 29 |
| 1085 | distraer | 29 |
| 1086 | discreto | 29 |
| 1087 | débil | 29 |
| 1088 | cristo | 29 |
| 1089 | consuelo | 29 |
| 1090 | conservar | 29 |
| 1091 | carretera | 29 |
| 1092 | anunciar | 29 |
| 1093 | animar | 29 |
| 1094 | veras | 28 |
| 1095 | unir | 28 |
| 1096 | tonto | 28 |
| 1097 | talento | 28 |
| 1098 | sitio | 28 |
| 1099 | semana | 28 |
| 1100 | sagrado | 28 |
| 1101 | retirar | 28 |
| 1102 | púlpito | 28 |
| 1103 | plan | 28 |
| 1104 | pintar | 28 |
| 1105 | milagro | 28 |
| 1106 | infierno | 28 |
| 1107 | gracioso | 28 |
| 1108 | gloria | 28 |
| 1109 | exclamar | 28 |
| 1110 | estudiar | 28 |
| 1111 | estrechar | 28 |
| 1112 | desierto | 28 |
| 1113 | copa | 28 |
| 1114 | celebrar | 28 |
| 1115 | animal | 28 |
| 1116 | ambición | 28 |
| 1117 | ala | 28 |
| 1118 | adivinar | 28 |
| 1119 | versar | 27 |
| 1120 | veinte | 27 |
| 1121 | superior | 27 |
| 1122 | soltar | 27 |
| 1123 | señores | 27 |
| 1124 | saborear | 27 |
| 1125 | oreja | 27 |
| 1126 | necio | 27 |
| 1127 | mourelo | 27 |
| 1128 | monja | 27 |
| 1129 | maestro | 27 |
| 1130 | loreto | 27 |
| 1131 | llover | 27 |
| 1132 | interior | 27 |
| 1133 | inocente | 27 |
| 1134 | humedad | 27 |
| 1135 | guante | 27 |
| 1136 | gobierno | 27 |
| 1137 | francisco | 27 |
| 1138 | favor | 27 |
| 1139 | fantasía | 27 |
| 1140 | familiar | 27 |
| 1141 | fácil | 27 |
| 1142 | extrañar | 27 |
| 1143 | excitar | 27 |
| 1144 | encanto | 27 |
| 1145 | emprender | 27 |
| 1146 | elocuencia | 27 |
| 1147 | doce | 27 |
| 1148 | disputar | 27 |
| 1149 | cuándo | 27 |
| 1150 | comercio | 27 |
| 1151 | chispa | 27 |
| 1152 | capricho | 27 |
| 1153 | aya | 27 |
| 1154 | atravesar | 27 |
| 1155 | adorar | 27 |
| 1156 | abierto | 27 |
| 1157 | turbar | 26 |
| 1158 | tenorio | 26 |
| 1159 | techo | 26 |
| 1160 | tabla | 26 |
| 1161 | sencillo | 26 |
| 1162 | seis | 26 |
| 1163 | satisfecho | 26 |
| 1164 | responder | 26 |
| 1165 | primavera | 26 |
| 1166 | poético | 26 |
| 1167 | pies | 26 |
| 1168 | pereza | 26 |
| 1169 | palco | 26 |
| 1170 | olvido | 26 |
| 1171 | oficio | 26 |
| 1172 | obedecer | 26 |
| 1173 | ministro | 26 |
| 1174 | lucha | 26 |
| 1175 | ladrón | 26 |
| 1176 | infame | 26 |
| 1177 | grupo | 26 |
| 1178 | flaco | 26 |
| 1179 | escuchar | 26 |
| 1180 | drama | 26 |
| 1181 | desnudo | 26 |
| 1182 | debilidad | 26 |
| 1183 | costa | 26 |
| 1184 | condición | 26 |
| 1185 | compañero | 26 |
| 1186 | cena | 26 |
| 1187 | celedonio | 26 |
| 1188 | católico | 26 |
| 1189 | cármenes | 26 |
| 1190 | carácter | 26 |
| 1191 | cambio | 26 |
| 1192 | calumniar | 26 |
| 1193 | aturdir | 26 |
| 1194 | asco | 26 |
| 1195 | aprender | 26 |
| 1196 | amoroso | 26 |
| 1197 | amenazar | 26 |
| 1198 | alabar | 26 |
| 1199 | afición | 26 |
| 1200 | admiración | 26 |
| 1201 | torcer | 25 |
| 1202 | sufrir | 25 |
| 1203 | solitario | 25 |
| 1204 | situación | 25 |
| 1205 | sacristía | 25 |
| 1206 | robusto | 25 |
| 1207 | resolución | 25 |
| 1208 | preocupar | 25 |
| 1209 | preciso | 25 |
| 1210 | perfectamente | 25 |
| 1211 | perezoso | 25 |
| 1212 | oprimir | 25 |
| 1213 | oponer | 25 |
| 1214 | opinar | 25 |
| 1215 | montar | 25 |
| 1216 | miseria | 25 |
| 1217 | mire | 25 |
| 1218 | mantener | 25 |
| 1219 | limpiar | 25 |
| 1220 | justicia | 25 |
| 1221 | influencia | 25 |
| 1222 | infinito | 25 |
| 1223 | indignar | 25 |
| 1224 | importante | 25 |
| 1225 | hueso | 25 |
| 1226 | forzar | 25 |
| 1227 | filosofía | 25 |
| 1228 | duro | 25 |
| 1229 | dueño | 25 |
| 1230 | dogma | 25 |
| 1231 | distraído | 25 |
| 1232 | delicado | 25 |
| 1233 | convidar | 25 |
| 1234 | cólera | 25 |
| 1235 | cambiar | 25 |
| 1236 | bedoya | 25 |
| 1237 | barón | 25 |
| 1238 | barca | 25 |
| 1239 | ah | 25 |
| 1240 | adentros | 25 |
| 1241 | aceptar | 25 |
| 1242 | victoria | 24 |
| 1243 | suplicar | 24 |
| 1244 | seco | 24 |
| 1245 | rey | 24 |
| 1246 | rendir | 24 |
| 1247 | rato | 24 |
| 1248 | pormenor | 24 |
| 1249 | pariente | 24 |
| 1250 | oración | 24 |
| 1251 | oler | 24 |
| 1252 | nave | 24 |
| 1253 | malicia | 24 |
| 1254 | lodo | 24 |
| 1255 | intención | 24 |
| 1256 | húmedo | 24 |
| 1257 | golpe | 24 |
| 1258 | fiesta | 24 |
| 1259 | exclamó | 24 |
| 1260 | esquina | 24 |
| 1261 | español | 24 |
| 1262 | época | 24 |
| 1263 | crecer | 24 |
| 1264 | consagrar | 24 |
| 1265 | cobarde | 24 |
| 1266 | ciego | 24 |
| 1267 | cera | 24 |
| 1268 | ceñir | 24 |
| 1269 | cazar | 24 |
| 1270 | bóveda | 24 |
| 1271 | beneficiar | 24 |
| 1272 | belleza | 24 |
| 1273 | bah | 24 |
| 1274 | avisar | 24 |
| 1275 | autoridad | 24 |
| 1276 | ambiente | 24 |
| 1277 | amarillo | 24 |
| 1278 | agradar | 24 |
| 1279 | trato | 23 |
| 1280 | tras | 23 |
| 1281 | traición | 23 |
| 1282 | tiniebla | 23 |
| 1283 | suficiente | 23 |
| 1284 | sostener | 23 |
| 1285 | siete | 23 |
| 1286 | rigor | 23 |
| 1287 | repugnante | 23 |
| 1288 | remediar | 23 |
| 1289 | puño | 23 |
| 1290 | pluma | 23 |
| 1291 | perdón | 23 |
| 1292 | partir | 23 |
| 1293 | pañuelo | 23 |
| 1294 | obscurecer | 23 |
| 1295 | nueva | 23 |
| 1296 | niebla | 23 |
| 1297 | material | 23 |
| 1298 | honra | 23 |
| 1299 | hipócrita | 23 |
| 1300 | habilidad | 23 |
| 1301 | guapo | 23 |
| 1302 | gris | 23 |
| 1303 | grado | 23 |
| 1304 | gracias | 23 |
| 1305 | fuente | 23 |
| 1306 | felicidad | 23 |
| 1307 | experiencia | 23 |
| 1308 | espectáculo | 23 |
| 1309 | disgusto | 23 |
| 1310 | desprecio | 23 |
| 1311 | demostrar | 23 |
| 1312 | delgado | 23 |
| 1313 | curiosidad | 23 |
| 1314 | compasión | 23 |
| 1315 | circunstancia | 23 |
| 1316 | caza | 23 |
| 1317 | carrera | 23 |
| 1318 | caber | 23 |
| 1319 | avergonzar | 23 |
| 1320 | autor | 23 |
| 1321 | aludir | 23 |
| 1322 | alejar | 23 |
| 1323 | aldeano | 23 |
| 1324 | ahogar | 23 |
| 1325 | trifón | 22 |
| 1326 | tren | 22 |
| 1327 | treinta | 22 |
| 1328 | tocador | 22 |
| 1329 | tapar | 22 |
| 1330 | seda | 22 |
| 1331 | secar | 22 |
| 1332 | rubio | 22 |
| 1333 | rodar | 22 |
| 1334 | raro | 22 |
| 1335 | próximo | 22 |
| 1336 | pegar | 22 |
| 1337 | pardo | 22 |
| 1338 | par | 22 |
| 1339 | oye | 22 |
| 1340 | nariz | 22 |
| 1341 | moda | 22 |
| 1342 | melancólico | 22 |
| 1343 | marcha | 22 |
| 1344 | mamá | 22 |
| 1345 | junta | 22 |
| 1346 | impulso | 22 |
| 1347 | idiota | 22 |
| 1348 | humillar | 22 |
| 1349 | fandiño | 22 |
| 1350 | estimar | 22 |
| 1351 | educación | 22 |
| 1352 | doler | 22 |
| 1353 | difícil | 22 |
| 1354 | devorar | 22 |
| 1355 | desconocido | 22 |
| 1356 | contacto | 22 |
| 1357 | confundir | 22 |
| 1358 | concluir | 22 |
| 1359 | completo | 22 |
| 1360 | columna | 22 |
| 1361 | civil | 22 |
| 1362 | cabildo | 22 |
| 1363 | buen | 22 |
| 1364 | baño | 22 |
| 1365 | atormentar | 22 |
| 1366 | aquella | 22 |
| 1367 | aplicar | 22 |
| 1368 | alcalde | 22 |
| 1369 | absoluto | 22 |
| 1370 | voluptuoso | 21 |
| 1371 | vinagre | 21 |
| 1372 | supremo | 21 |
| 1373 | seña | 21 |
| 1374 | seno | 21 |
| 1375 | sea | 21 |
| 1376 | sanar | 21 |
| 1377 | rodillas | 21 |
| 1378 | rival | 21 |
| 1379 | revelar | 21 |
| 1380 | repartir | 21 |
| 1381 | reflejar | 21 |
| 1382 | real | 21 |
| 1383 | promesa | 21 |
| 1384 | prisa | 21 |
| 1385 | pretender | 21 |
| 1386 | paquito | 21 |
| 1387 | orilla | 21 |
| 1388 | ordinario | 21 |
| 1389 | oportuno | 21 |
| 1390 | mueble | 21 |
| 1391 | mitad | 21 |
| 1392 | manchar | 21 |
| 1393 | magistrado | 21 |
| 1394 | lección | 21 |
| 1395 | justo | 21 |
| 1396 | ja | 21 |
| 1397 | inventar | 21 |
| 1398 | imaginar | 21 |
| 1399 | horror | 21 |
| 1400 | halagar | 21 |
| 1401 | fortaleza | 21 |
| 1402 | extraño | 21 |
| 1403 | espiar | 21 |
| 1404 | espejo | 21 |
| 1405 | espada | 21 |
| 1406 | escoger | 21 |
| 1407 | esbelto | 21 |
| 1408 | entierro | 21 |
| 1409 | disimulo | 21 |
| 1410 | deshacer | 21 |
| 1411 | consistir | 21 |
| 1412 | consejo | 21 |
| 1413 | comida | 21 |
| 1414 | cocinero | 21 |
| 1415 | capa | 21 |
| 1416 | camisa | 21 |
| 1417 | atar | 21 |
| 1418 | aquello | 21 |
| 1419 | apariencia | 21 |
| 1420 | ángel | 21 |
| 1421 | amable | 21 |
| 1422 | agujero | 21 |
| 1423 | advertir | 21 |
| 1424 | actividad | 21 |
| 1425 | virtuoso | 20 |
| 1426 | tresillo | 20 |
| 1427 | tertuliar | 20 |
| 1428 | sospecha | 20 |
| 1429 | sordo | 20 |
| 1430 | seducir | 20 |
| 1431 | salvación | 20 |
| 1432 | salar | 20 |
| 1433 | respecto | 20 |
| 1434 | regalar | 20 |
| 1435 | raíz | 20 |
| 1436 | quinta | 20 |
| 1437 | prosaico | 20 |
| 1438 | preocupación | 20 |
| 1439 | papá | 20 |
| 1440 | país | 20 |
| 1441 | órgano | 20 |
| 1442 | novio | 20 |
| 1443 | necedad | 20 |
| 1444 | mudar | 20 |
| 1445 | montón | 20 |
| 1446 | malicioso | 20 |
| 1447 | lluvia | 20 |
| 1448 | levita | 20 |
| 1449 | león | 20 |
| 1450 | lavar | 20 |
| 1451 | jardín | 20 |
| 1452 | gobernador | 20 |
| 1453 | gastar | 20 |
| 1454 | garganta | 20 |
| 1455 | formidable | 20 |
| 1456 | fábrica | 20 |
| 1457 | estrella | 20 |
| 1458 | estallar | 20 |
| 1459 | escrúpulo | 20 |
| 1460 | escandaloso | 20 |
| 1461 | escalofrío | 20 |
| 1462 | doblar | 20 |
| 1463 | distinguir | 20 |
| 1464 | dignidad | 20 |
| 1465 | desdén | 20 |
| 1466 | colorar | 20 |
| 1467 | claridad | 20 |
| 1468 | capital | 20 |
| 1469 | cajón | 20 |
| 1470 | buenas | 20 |
| 1471 | bravo | 20 |
| 1472 | aristocracia | 20 |
| 1473 | argumento | 20 |
| 1474 | ardiente | 20 |
| 1475 | alta | 20 |
| 1476 | acusar | 20 |
| 1477 | acostumbrar | 20 |
| 1478 | voluptuosidad | 19 |
| 1479 | verja | 19 |
| 1480 | vaya | 19 |
| 1481 | varios | 19 |
| 1482 | trasladar | 19 |
| 1483 | tolerar | 19 |
| 1484 | tierno | 19 |
| 1485 | testigo | 19 |
| 1486 | sistema | 19 |
| 1487 | sexo | 19 |
| 1488 | sereno | 19 |
| 1489 | santidad | 19 |
| 1490 | región | 19 |
| 1491 | recorrer | 19 |
| 1492 | recitar | 19 |
| 1493 | rápido | 19 |
| 1494 | punta | 19 |
| 1495 | prudente | 19 |
| 1496 | proyecto | 19 |
| 1497 | profanar | 19 |
| 1498 | primo | 19 |
| 1499 | precisamente | 19 |
| 1500 | positivo | 19 |
| 1501 | plato | 19 |
| 1502 | plantar | 19 |
| 1503 | pistola | 19 |
| 1504 | pesado | 19 |
| 1505 | pelo | 19 |
| 1506 | peligroso | 19 |
| 1507 | particular | 19 |
| 1508 | mérito | 19 |
| 1509 | menor | 19 |
| 1510 | matrimonio | 19 |
| 1511 | marear | 19 |
| 1512 | manía | 19 |
| 1513 | manejar | 19 |
| 1514 | lujo | 19 |
| 1515 | interesar | 19 |
| 1516 | inspirar | 19 |
| 1517 | insignificante | 19 |
| 1518 | impaciencia | 19 |
| 1519 | iluminar | 19 |
| 1520 | humo | 19 |
| 1521 | humildad | 19 |
| 1522 | hola | 19 |
| 1523 | habitación | 19 |
| 1524 | gorro | 19 |
| 1525 | germán | 19 |
| 1526 | frialdad | 19 |
| 1527 | flaqueza | 19 |
| 1528 | firmar | 19 |
| 1529 | fiar | 19 |
| 1530 | exaltación | 19 |
| 1531 | estudiante | 19 |
| 1532 | estirar | 19 |
| 1533 | estaba | 19 |
| 1534 | está | 19 |
| 1535 | esposar | 19 |
| 1536 | espesar | 19 |
| 1537 | elemento | 19 |
| 1538 | dorar | 19 |
| 1539 | doméstico | 19 |
| 1540 | desnudar | 19 |
| 1541 | delito | 19 |
| 1542 | conquistar | 19 |
| 1543 | confuso | 19 |
| 1544 | comulgar | 19 |
| 1545 | colonia | 19 |
| 1546 | ceder | 19 |
| 1547 | casualidad | 19 |
| 1548 | calma | 19 |
| 1549 | brillante | 19 |
| 1550 | bismarck | 19 |
| 1551 | batir | 19 |
| 1552 | barba | 19 |
| 1553 | atacar | 19 |
| 1554 | arreglar | 19 |
| 1555 | apuntar | 19 |
| 1556 | anda | 19 |
| 1557 | ambos | 19 |
| 1558 | ajeno | 19 |
| 1559 | vieja | 18 |
| 1560 | vejez | 18 |
| 1561 | tragar | 18 |
| 1562 | término | 18 |
| 1563 | tela | 18 |
| 1564 | sus | 18 |
| 1565 | sudor | 18 |
| 1566 | sobrino | 18 |
| 1567 | simpático | 18 |
| 1568 | silencioso | 18 |
| 1569 | seductor | 18 |
| 1570 | sacrificar | 18 |
| 1571 | rodilla | 18 |
| 1572 | resultar | 18 |
| 1573 | pozo | 18 |
| 1574 | parroquia | 18 |
| 1575 | paciencia | 18 |
| 1576 | ostentar | 18 |
| 1577 | orar | 18 |
| 1578 | novena | 18 |
| 1579 | muchacho | 18 |
| 1580 | monótono | 18 |
| 1581 | moderno | 18 |
| 1582 | medir | 18 |
| 1583 | largar | 18 |
| 1584 | lámpara | 18 |
| 1585 | jesuita | 18 |
| 1586 | invisible | 18 |
| 1587 | intenso | 18 |
| 1588 | ingrato | 18 |
| 1589 | inglés | 18 |
| 1590 | inefable | 18 |
| 1591 | igual | 18 |
| 1592 | hundir | 18 |
| 1593 | gritos | 18 |
| 1594 | fonda | 18 |
| 1595 | existencia | 18 |
| 1596 | exaltar | 18 |
| 1597 | esclavo | 18 |
| 1598 | escaso | 18 |
| 1599 | esa | 18 |
| 1600 | ensueño | 18 |
| 1601 | elocuente | 18 |
| 1602 | ejercicio | 18 |
| 1603 | egoísmo | 18 |
| 1604 | disgustar | 18 |
| 1605 | cursi | 18 |
| 1606 | consultar | 18 |
| 1607 | constantino | 18 |
| 1608 | conducta | 18 |
| 1609 | común | 18 |
| 1610 | complacer | 18 |
| 1611 | codo | 18 |
| 1612 | círculo | 18 |
| 1613 | chiquillo | 18 |
| 1614 | cariñoso | 18 |
| 1615 | caricia | 18 |
| 1616 | calleja | 18 |
| 1617 | caja | 18 |
| 1618 | butaca | 18 |
| 1619 | barrio | 18 |
| 1620 | azotar | 18 |
| 1621 | aventurar | 18 |
| 1622 | audiencia | 18 |
| 1623 | asiento | 18 |
| 1624 | americano | 18 |
| 1625 | alborotar | 18 |
| 1626 | afán | 18 |
| 1627 | aconsejar | 18 |
| 1628 | acera | 18 |
| 1629 | visión | 17 |
| 1630 | vender | 17 |
| 1631 | tus | 17 |
| 1632 | trapo | 17 |
| 1633 | ternura | 17 |
| 1634 | talar | 17 |
| 1635 | sudar | 17 |
| 1636 | sublime | 17 |
| 1637 | sonriente | 17 |
| 1638 | solemnidad | 17 |
| 1639 | sofá | 17 |
| 1640 | salvaje | 17 |
| 1641 | romanticismo | 17 |
| 1642 | resto | 17 |
| 1643 | renunciar | 17 |
| 1644 | recobrar | 17 |
| 1645 | quince | 17 |
| 1646 | prudencia | 17 |
| 1647 | procesión | 17 |
| 1648 | probable | 17 |
| 1649 | predicar | 17 |
| 1650 | pícaro | 17 |
| 1651 | picante | 17 |
| 1652 | penetrar | 17 |
| 1653 | pedazo | 17 |
| 1654 | párroco | 17 |
| 1655 | pareja | 17 |
| 1656 | paraguas | 17 |
| 1657 | obrar | 17 |
| 1658 | murmuración | 17 |
| 1659 | mísero | 17 |
| 1660 | mentira | 17 |
| 1661 | mentir | 17 |
| 1662 | manifestar | 17 |
| 1663 | manga | 17 |
| 1664 | limosna | 17 |
| 1665 | insultar | 17 |
| 1666 | inmóvil | 17 |
| 1667 | influenciar | 17 |
| 1668 | ilusión | 17 |
| 1669 | hipocresía | 17 |
| 1670 | ha | 17 |
| 1671 | gritaba | 17 |
| 1672 | gran | 17 |
| 1673 | gas | 17 |
| 1674 | fresca | 17 |
| 1675 | frecuentar | 17 |
| 1676 | finar | 17 |
| 1677 | feo | 17 |
| 1678 | fanatismo | 17 |
| 1679 | estúpido | 17 |
| 1680 | estación | 17 |
| 1681 | especial | 17 |
| 1682 | escuela | 17 |
| 1683 | enternecer | 17 |
| 1684 | dulzura | 17 |
| 1685 | divino | 17 |
| 1686 | disparatar | 17 |
| 1687 | discurso | 17 |
| 1688 | diócesis | 17 |
| 1689 | dificultad | 17 |
| 1690 | descargar | 17 |
| 1691 | desaire | 17 |
| 1692 | demonio | 17 |
| 1693 | cuerda | 17 |
| 1694 | corte | 17 |
| 1695 | concepto | 17 |
| 1696 | completamente | 17 |
| 1697 | cigarro | 17 |
| 1698 | cercar | 17 |
| 1699 | castaño | 17 |
| 1700 | bolsillo | 17 |
| 1701 | atribuir | 17 |
| 1702 | atraer | 17 |
| 1703 | arder | 17 |
| 1704 | apetito | 17 |
| 1705 | acariciar | 17 |
| 1706 | velar | 16 |
| 1707 | vagamente | 16 |
| 1708 | trueno | 16 |
| 1709 | tronco | 16 |
| 1710 | todos | 16 |
| 1711 | tiro | 16 |
| 1712 | sutil | 16 |
| 1713 | solicitar | 16 |
| 1714 | singular | 16 |
| 1715 | respectivo | 16 |
| 1716 | rasgar | 16 |
| 1717 | prosa | 16 |
| 1718 | primeros | 16 |
| 1719 | pretensión | 16 |
| 1720 | presidir | 16 |
| 1721 | poema | 16 |
| 1722 | picar | 16 |
| 1723 | peso | 16 |
| 1724 | permiso | 16 |
| 1725 | perfume | 16 |
| 1726 | perdiz | 16 |
| 1727 | perales | 16 |
| 1728 | partes | 16 |
| 1729 | padrino | 16 |
| 1730 | os | 16 |
| 1731 | orador | 16 |
| 1732 | ola | 16 |
| 1733 | ofender | 16 |
| 1734 | ocupación | 16 |
| 1735 | novedad | 16 |
| 1736 | muro | 16 |
| 1737 | multitud | 16 |
| 1738 | moralidad | 16 |
| 1739 | montaña | 16 |
| 1740 | melancolía | 16 |
| 1741 | marqueses | 16 |
| 1742 | ligero | 16 |
| 1743 | legua | 16 |
| 1744 | infeliz | 16 |
| 1745 | indignación | 16 |
| 1746 | impío | 16 |
| 1747 | horrorizar | 16 |
| 1748 | horizonte | 16 |
| 1749 | hábito | 16 |
| 1750 | fila | 16 |
| 1751 | fatigar | 16 |
| 1752 | fantasma | 16 |
| 1753 | excursión | 16 |
| 1754 | estudio | 16 |
| 1755 | estatua | 16 |
| 1756 | esta | 16 |
| 1757 | espina | 16 |
| 1758 | equivocar | 16 |
| 1759 | enérgico | 16 |
| 1760 | elegancia | 16 |
| 1761 | disparar | 16 |
| 1762 | desvanecer | 16 |
| 1763 | descansar | 16 |
| 1764 | cuento | 16 |
| 1765 | convidado | 16 |
| 1766 | contiguo | 16 |
| 1767 | confidencia | 16 |
| 1768 | conferencia | 16 |
| 1769 | cometer | 16 |
| 1770 | cobrar | 16 |
| 1771 | cita | 16 |
| 1772 | chato | 16 |
| 1773 | cenador | 16 |
| 1774 | cementerio | 16 |
| 1775 | castigar | 16 |
| 1776 | cabello | 16 |
| 1777 | blando | 16 |
| 1778 | ausencia | 16 |
| 1779 | arrogante | 16 |
| 1780 | armario | 16 |
| 1781 | aristócrata | 16 |
| 1782 | aplastar | 16 |
| 1783 | apartar | 16 |
| 1784 | almo | 16 |
| 1785 | alimento | 16 |
| 1786 | alcohol | 16 |
| 1787 | agradable | 16 |
| 1788 | adornar | 16 |
| 1789 | acción | 16 |
| 1790 | abusar | 16 |
| 1791 | abismo | 16 |
| 1792 | vuelo | 15 |
| 1793 | vicario | 15 |
| 1794 | venerable | 15 |
| 1795 | vela | 15 |
| 1796 | vaso | 15 |
| 1797 | vacilar | 15 |
| 1798 | universal | 15 |
| 1799 | triunfante | 15 |
| 1800 | torpe | 15 |
| 1801 | tigre | 15 |
| 1802 | tertulia | 15 |
| 1803 | teología | 15 |
| 1804 | temperamento | 15 |
| 1805 | tembloroso | 15 |
| 1806 | taberna | 15 |
| 1807 | suspender | 15 |
| 1808 | subterráneo | 15 |
| 1809 | soplar | 15 |
| 1810 | sofisma | 15 |
| 1811 | símbolo | 15 |
| 1812 | serenar | 15 |
| 1813 | señal | 15 |
| 1814 | satisfacción | 15 |
| 1815 | salto | 15 |
| 1816 | sábana | 15 |
| 1817 | rianzares | 15 |
| 1818 | retumbar | 15 |
| 1819 | repentino | 15 |
| 1820 | raza | 15 |
| 1821 | querida | 15 |
| 1822 | pudor | 15 |
| 1823 | provocar | 15 |
| 1824 | primeras | 15 |
| 1825 | prestar | 15 |
| 1826 | pollo | 15 |
| 1827 | pierna | 15 |
| 1828 | pico | 15 |
| 1829 | peligrar | 15 |
| 1830 | palo | 15 |
| 1831 | osar | 15 |
| 1832 | norte | 15 |
| 1833 | negocio | 15 |
| 1834 | mira | 15 |
| 1835 | medida | 15 |
| 1836 | matalerejo | 15 |
| 1837 | mármol | 15 |
| 1838 | juzgar | 15 |
| 1839 | juicio | 15 |
| 1840 | injusticia | 15 |
| 1841 | infamar | 15 |
| 1842 | inconveniente | 15 |
| 1843 | impresión | 15 |
| 1844 | ilustre | 15 |
| 1845 | ilustrar | 15 |
| 1846 | ignorar | 15 |
| 1847 | helar | 15 |
| 1848 | hastío | 15 |
| 1849 | futuro | 15 |
| 1850 | fumar | 15 |
| 1851 | fruto | 15 |
| 1852 | excepción | 15 |
| 1853 | españa | 15 |
| 1854 | enterrar | 15 |
| 1855 | encantar | 15 |
| 1856 | eh | 15 |
| 1857 | difunto | 15 |
| 1858 | deshonra | 15 |
| 1859 | describir | 15 |
| 1860 | dedicar | 15 |
| 1861 | culpar | 15 |
| 1862 | corredor | 15 |
| 1863 | contemplación | 15 |
| 1864 | comprometer | 15 |
| 1865 | compadecer | 15 |
| 1866 | coincidir | 15 |
| 1867 | chiste | 15 |
| 1868 | chimenea | 15 |
| 1869 | cerrado | 15 |
| 1870 | celestina | 15 |
| 1871 | canción | 15 |
| 1872 | camoirán | 15 |
| 1873 | bulto | 15 |
| 1874 | aspirar | 15 |
| 1875 | arqueólogo | 15 |
| 1876 | apenar | 15 |
| 1877 | ansia | 15 |
| 1878 | alrededor | 15 |
| 1879 | almohada | 15 |
| 1880 | adquirir | 15 |
| 1881 | acero | 15 |
| 1882 | zapato | 14 |
| 1883 | yacer | 14 |
| 1884 | vergonzoso | 14 |
| 1885 | ventaja | 14 |
| 1886 | varón | 14 |
| 1887 | trampa | 14 |
| 1888 | tordo | 14 |
| 1889 | tesoro | 14 |
| 1890 | terciopelo | 14 |
| 1891 | temor | 14 |
| 1892 | tejado | 14 |
| 1893 | supersticioso | 14 |
| 1894 | sumir | 14 |
| 1895 | suceso | 14 |
| 1896 | sublevar | 14 |
| 1897 | silenciar | 14 |
| 1898 | significar | 14 |
| 1899 | seducción | 14 |
| 1900 | ruina | 14 |
| 1901 | rubia | 14 |
| 1902 | rotar | 14 |
| 1903 | rinconada | 14 |
| 1904 | revolución | 14 |
| 1905 | revelación | 14 |
| 1906 | repugnancia | 14 |
| 1907 | reinar | 14 |
| 1908 | recinto | 14 |
| 1909 | pulcro | 14 |
| 1910 | profanación | 14 |
| 1911 | prestigio | 14 |
| 1912 | postura | 14 |
| 1913 | pliegue | 14 |
| 1914 | patria | 14 |
| 1915 | pastor | 14 |
| 1916 | pantalón | 14 |
| 1917 | obrero | 14 |
| 1918 | misterio | 14 |
| 1919 | millón | 14 |
| 1920 | militar | 14 |
| 1921 | miel | 14 |
| 1922 | medias | 14 |
| 1923 | llanto | 14 |
| 1924 | literata | 14 |
| 1925 | literario | 14 |
| 1926 | liga | 14 |
| 1927 | lenguaje | 14 |
| 1928 | latín | 14 |
| 1929 | intentar | 14 |
| 1930 | inocencia | 14 |
| 1931 | inmenso | 14 |
| 1932 | infanzón | 14 |
| 1933 | indispensable | 14 |
| 1934 | improvisar | 14 |
| 1935 | humanidad | 14 |
| 1936 | hondo | 14 |
| 1937 | herir | 14 |
| 1938 | gravar | 14 |
| 1939 | gordo | 14 |
| 1940 | expansivo | 14 |
| 1941 | exagerar | 14 |
| 1942 | estorbar | 14 |
| 1943 | estómago | 14 |
| 1944 | esparcir | 14 |
| 1945 | dominio | 14 |
| 1946 | doloroso | 14 |
| 1947 | disimulado | 14 |
| 1948 | discretamente | 14 |
| 1949 | disciplina | 14 |
| 1950 | diferente | 14 |
| 1951 | diálogo | 14 |
| 1952 | destino | 14 |
| 1953 | desafío | 14 |
| 1954 | deje | 14 |
| 1955 | criminal | 14 |
| 1956 | criado | 14 |
| 1957 | coronel | 14 |
| 1958 | convicción | 14 |
| 1959 | constante | 14 |
| 1960 | conocimiento | 14 |
| 1961 | columpio | 14 |
| 1962 | charco | 14 |
| 1963 | centro | 14 |
| 1964 | celosía | 14 |
| 1965 | cegar | 14 |
| 1966 | castidad | 14 |
| 1967 | casero | 14 |
| 1968 | cargo | 14 |
| 1969 | calzar | 14 |
| 1970 | calderón | 14 |
| 1971 | cadena | 14 |
| 1972 | buena | 14 |
| 1973 | brotar | 14 |
| 1974 | bolsa | 14 |
| 1975 | bofetada | 14 |
| 1976 | batalla | 14 |
| 1977 | bañar | 14 |
| 1978 | auditorio | 14 |
| 1979 | atender | 14 |
| 1980 | aspecto | 14 |
| 1981 | asir | 14 |
| 1982 | artístico | 14 |
| 1983 | artista | 14 |
| 1984 | arrugar | 14 |
| 1985 | arena | 14 |
| 1986 | apurar | 14 |
| 1987 | apreciar | 14 |
| 1988 | alumbrar | 14 |
| 1989 | agustín | 14 |
| 1990 | ademán | 14 |
| 1991 | vocación | 13 |
| 1992 | violín | 13 |
| 1993 | viernes | 13 |
| 1994 | vacío | 13 |
| 1995 | uso | 13 |
| 1996 | tranquilidad | 13 |
| 1997 | tarea | 13 |
| 1998 | soso | 13 |
| 1999 | sorpresa | 13 |
| 2000 | sincero | 13 |
| 2001 | severo | 13 |
| 2002 | salida | 13 |
| 2003 | sabiduría | 13 |
| 2004 | risueño | 13 |
| 2005 | revolver | 13 |
| 2006 | retórica | 13 |
| 2007 | reparar | 13 |
| 2008 | reñir | 13 |
| 2009 | relámpago | 13 |
| 2010 | reflejo | 13 |
| 2011 | reconciliar | 13 |
| 2012 | recomendar | 13 |
| 2013 | reclamar | 13 |
| 2014 | quemar | 13 |
| 2015 | pulso | 13 |
| 2016 | puesta | 13 |
| 2017 | proceder | 13 |
| 2018 | prenda | 13 |
| 2019 | porvenir | 13 |
| 2020 | plebeyo | 13 |
| 2021 | pino | 13 |
| 2022 | piano | 13 |
| 2023 | pernueces | 13 |
| 2024 | penitente | 13 |
| 2025 | pendiente | 13 |
| 2026 | pavimento | 13 |
| 2027 | pausa | 13 |
| 2028 | pasmar | 13 |
| 2029 | partidario | 13 |
| 2030 | página | 13 |
| 2031 | orgulloso | 13 |
| 2032 | ópera | 13 |
| 2033 | músculo | 13 |
| 2034 | murmullo | 13 |
| 2035 | muralla | 13 |
| 2036 | mundano | 13 |
| 2037 | moribundo | 13 |
| 2038 | moneda | 13 |
| 2039 | medicina | 13 |
| 2040 | mártir | 13 |
| 2041 | maneras | 13 |
| 2042 | maldecir | 13 |
| 2043 | libertino | 13 |
| 2044 | lazo | 13 |
| 2045 | jugador | 13 |
| 2046 | ironía | 13 |
| 2047 | intimidad | 13 |
| 2048 | interesante | 13 |
| 2049 | inteligente | 13 |
| 2050 | infancia | 13 |
| 2051 | indicar | 13 |
| 2052 | imprudencia | 13 |
| 2053 | ignorancia | 13 |
| 2054 | ídolo | 13 |
| 2055 | horroroso | 13 |
| 2056 | honrado | 13 |
| 2057 | hermosísimo | 13 |
| 2058 | heredar | 13 |
| 2059 | guerra | 13 |
| 2060 | grano | 13 |
| 2061 | gota | 13 |
| 2062 | freír | 13 |
| 2063 | flotar | 13 |
| 2064 | flamenco | 13 |
| 2065 | fanático | 13 |
| 2066 | famoso | 13 |
| 2067 | explicación | 13 |
| 2068 | excelente | 13 |
| 2069 | escopeta | 13 |
| 2070 | error | 13 |
| 2071 | entusiasmar | 13 |
| 2072 | entrada | 13 |
| 2073 | engaño | 13 |
| 2074 | empleado | 13 |
| 2075 | elevar | 13 |
| 2076 | egoísta | 13 |
| 2077 | dorado | 13 |
| 2078 | doctor | 13 |
| 2079 | distancia | 13 |
| 2080 | disparate | 13 |
| 2081 | dicho | 13 |
| 2082 | deslumbrar | 13 |
| 2083 | desgraciado | 13 |
| 2084 | desesperar | 13 |
| 2085 | descanso | 13 |
| 2086 | delicioso | 13 |
| 2087 | deleite | 13 |
| 2088 | decente | 13 |
| 2089 | daño | 13 |
| 2090 | cuervo | 13 |
| 2091 | cuarenta | 13 |
| 2092 | corto | 13 |
| 2093 | corfín | 13 |
| 2094 | coquetería | 13 |
| 2095 | contraste | 13 |
| 2096 | contestó | 13 |
| 2097 | construir | 13 |
| 2098 | conquista | 13 |
| 2099 | cómplice | 13 |
| 2100 | chocar | 13 |
| 2101 | castigo | 13 |
| 2102 | caro | 13 |
| 2103 | capitán | 13 |
| 2104 | cansado | 13 |
| 2105 | campana | 13 |
| 2106 | caliente | 13 |
| 2107 | calidad | 13 |
| 2108 | calentar | 13 |
| 2109 | brazos | 13 |
| 2110 | bendito | 13 |
| 2111 | bello | 13 |
| 2112 | atmósfera | 13 |
| 2113 | asqueroso | 13 |
| 2114 | artículo | 13 |
| 2115 | arruinar | 13 |
| 2116 | armonía | 13 |
| 2117 | aprobar | 13 |
| 2118 | amanecer | 13 |
| 2119 | altura | 13 |
| 2120 | aliento | 13 |
| 2121 | algazara | 13 |
| 2122 | alcanzar | 13 |
| 2123 | acá | 13 |
| 2124 | abrazar | 13 |
| 2125 | vulgo | 12 |
| 2126 | violentar | 12 |
| 2127 | vetusto | 12 |
| 2128 | triunfar | 12 |
| 2129 | tipo | 12 |
| 2130 | tila | 12 |
| 2131 | suma | 12 |
| 2132 | sugerir | 12 |
| 2133 | sofocar | 12 |
| 2134 | sobrenatural | 12 |
| 2135 | sería | 12 |
| 2136 | sensación | 12 |
| 2137 | sendos | 12 |
| 2138 | sendero | 12 |
| 2139 | seminario | 12 |
| 2140 | secular | 12 |
| 2141 | sastre | 12 |
| 2142 | sarcasmo | 12 |
| 2143 | salesas | 12 |
| 2144 | sacrílego | 12 |
| 2145 | restituir | 12 |
| 2146 | reservar | 12 |
| 2147 | repasar | 12 |
| 2148 | reluciente | 12 |
| 2149 | religiosidad | 12 |
| 2150 | recurso | 12 |
| 2151 | recado | 12 |
| 2152 | rasar | 12 |
| 2153 | quedo | 12 |
| 2154 | puramente | 12 |
| 2155 | publicar | 12 |
| 2156 | propasar | 12 |
| 2157 | profano | 12 |
| 2158 | probablemente | 12 |
| 2159 | preguntaba | 12 |
| 2160 | pregunta | 12 |
| 2161 | pobreza | 12 |
| 2162 | pilar | 12 |
| 2163 | parís | 12 |
| 2164 | parecido | 12 |
| 2165 | otoño | 12 |
| 2166 | original | 12 |
| 2167 | odio | 12 |
| 2168 | obstáculo | 12 |
| 2169 | observación | 12 |
| 2170 | moza | 12 |
| 2171 | mortal | 12 |
| 2172 | moreno | 12 |
| 2173 | morar | 12 |
| 2174 | mojar | 12 |
| 2175 | mina | 12 |
| 2176 | majestuoso | 12 |
| 2177 | madrugar | 12 |
| 2178 | lugareño | 12 |
| 2179 | lontananza | 12 |
| 2180 | loma | 12 |
| 2181 | limpieza | 12 |
| 2182 | levitar | 12 |
| 2183 | lector | 12 |
| 2184 | latigazo | 12 |
| 2185 | lascivo | 12 |
| 2186 | lascivia | 12 |
| 2187 | lamentar | 12 |
| 2188 | italiano | 12 |
| 2189 | invitar | 12 |
| 2190 | invencible | 12 |
| 2191 | inundar | 12 |
| 2192 | indiferencia | 12 |
| 2193 | incapaz | 12 |
| 2194 | imprudente | 12 |
| 2195 | impacientar | 12 |
| 2196 | hueco | 12 |
| 2197 | histórico | 12 |
| 2198 | hilo | 12 |
| 2199 | gallo | 12 |
| 2200 | furor | 12 |
| 2201 | frescura | 12 |
| 2202 | francés | 12 |
| 2203 | florar | 12 |
| 2204 | firme | 12 |
| 2205 | fiera | 12 |
| 2206 | fervor | 12 |
| 2207 | farsa | 12 |
| 2208 | fantástico | 12 |
| 2209 | exquisito | 12 |
| 2210 | expediente | 12 |
| 2211 | exageración | 12 |
| 2212 | estridente | 12 |
| 2213 | especialmente | 12 |
| 2214 | escenario | 12 |
| 2215 | escape | 12 |
| 2216 | enfermar | 12 |
| 2217 | encargar | 12 |
| 2218 | embozar | 12 |
| 2219 | educar | 12 |
| 2220 | edificio | 12 |
| 2221 | distracción | 12 |
| 2222 | discreción | 12 |
| 2223 | diputado | 12 |
| 2224 | deuda | 12 |
| 2225 | delirio | 12 |
| 2226 | defecto | 12 |
| 2227 | crítico | 12 |
| 2228 | coronar | 12 |
| 2229 | comunicar | 12 |
| 2230 | comerciante | 12 |
| 2231 | colchón | 12 |
| 2232 | codiciar | 12 |
| 2233 | clásico | 12 |
| 2234 | claramente | 12 |
| 2235 | cereza | 12 |
| 2236 | célebre | 12 |
| 2237 | casado | 12 |
| 2238 | cántico | 12 |
| 2239 | bullicioso | 12 |
| 2240 | breve | 12 |
| 2241 | baronesa | 12 |
| 2242 | ayuntamiento | 12 |
| 2243 | averiguar | 12 |
| 2244 | aragonés | 12 |
| 2245 | apresurar | 12 |
| 2246 | antigüedad | 12 |
| 2247 | amarillento | 12 |
| 2248 | amabilidad | 12 |
| 2249 | alarmar | 12 |
| 2250 | alarde | 12 |
| 2251 | aguardiente | 12 |
| 2252 | afirmar | 12 |
| 2253 | aficionado | 12 |
| 2254 | adulterio | 12 |
| 2255 | activo | 12 |
| 2256 | acólito | 12 |
| 2257 | abnegación | 12 |
| 2258 | vientre | 11 |
| 2259 | ves | 11 |
| 2260 | valiente | 11 |
| 2261 | universo | 11 |
| 2262 | tronar | 11 |
| 2263 | tribunal | 11 |
| 2264 | transformar | 11 |
| 2265 | traidor | 11 |
| 2266 | tirano | 11 |
| 2267 | terso | 11 |
| 2268 | tenía | 11 |
| 2269 | tambor | 11 |
| 2270 | suspiro | 11 |
| 2271 | sublimar | 11 |
| 2272 | suavidad | 11 |
| 2273 | sopa | 11 |
| 2274 | sillón | 11 |
| 2275 | silbar | 11 |
| 2276 | sierra | 11 |
| 2277 | servidumbre | 11 |
| 2278 | seriedad | 11 |
| 2279 | será | 11 |
| 2280 | sentimental | 11 |
| 2281 | secretar | 11 |
| 2282 | saludo | 11 |
| 2283 | roncar | 11 |
| 2284 | roce | 11 |
| 2285 | roble | 11 |
| 2286 | riqueza | 11 |
| 2287 | reunir | 11 |
| 2288 | retorcer | 11 |
| 2289 | reja | 11 |
| 2290 | reina | 11 |
| 2291 | reflexión | 11 |
| 2292 | recrear | 11 |
| 2293 | ratos | 11 |
| 2294 | pupila | 11 |
| 2295 | puntillas | 11 |
| 2296 | puerto | 11 |
| 2297 | prójimo | 11 |
| 2298 | progreso | 11 |
| 2299 | prodigar | 11 |
| 2300 | presenciar | 11 |
| 2301 | precisar | 11 |
| 2302 | precioso | 11 |
| 2303 | plomo | 11 |
| 2304 | plazuela | 11 |
| 2305 | pinchar | 11 |
| 2306 | pesadilla | 11 |
| 2307 | pertenecer | 11 |
| 2308 | perfecto | 11 |
| 2309 | perdido | 11 |
| 2310 | percal | 11 |
| 2311 | peinar | 11 |
| 2312 | pegajoso | 11 |
| 2313 | partida | 11 |
| 2314 | párpado | 11 |
| 2315 | parece | 11 |
| 2316 | paño | 11 |
| 2317 | palidez | 11 |
| 2318 | oriente | 11 |
| 2319 | once | 11 |
| 2320 | oiga | 11 |
| 2321 | náusea | 11 |
| 2322 | museo | 11 |
| 2323 | mortificar | 11 |
| 2324 | molino | 11 |
| 2325 | modelo | 11 |
| 2326 | metálico | 11 |
| 2327 | mayo | 11 |
| 2328 | marisma | 11 |
| 2329 | maldito | 11 |
| 2330 | majadero | 11 |
| 2331 | maíz | 11 |
| 2332 | magnífico | 11 |
| 2333 | limpio | 11 |
| 2334 | jaqueca | 11 |
| 2335 | izquierda | 11 |
| 2336 | irresistible | 11 |
| 2337 | inmediatamente | 11 |
| 2338 | importancia | 11 |
| 2339 | impedir | 11 |
| 2340 | héroe | 11 |
| 2341 | grueso | 11 |
| 2342 | golosina | 11 |
| 2343 | fúnebre | 11 |
| 2344 | formalidad | 11 |
| 2345 | fácilmente | 11 |
| 2346 | expresar | 11 |
| 2347 | exposición | 11 |
| 2348 | excesivo | 11 |
| 2349 | evidente | 11 |
| 2350 | eucaliptus | 11 |
| 2351 | estoy | 11 |
| 2352 | espeso | 11 |
| 2353 | espantar | 11 |
| 2354 | entretener | 11 |
| 2355 | engordar | 11 |
| 2356 | enamorado | 11 |
| 2357 | empresa | 11 |
| 2358 | embozo | 11 |
| 2359 | elogio | 11 |
| 2360 | dramático | 11 |
| 2361 | dividir | 11 |
| 2362 | distinto | 11 |
| 2363 | dispensar | 11 |
| 2364 | dichoso | 11 |
| 2365 | devolver | 11 |
| 2366 | desmayar | 11 |
| 2367 | desfachatez | 11 |
| 2368 | descalzar | 11 |
| 2369 | depositar | 11 |
| 2370 | delantero | 11 |
| 2371 | dejado | 11 |
| 2372 | dañar | 11 |
| 2373 | crujir | 11 |
| 2374 | cruel | 11 |
| 2375 | cristianar | 11 |
| 2376 | crear | 11 |
| 2377 | correcto | 11 |
| 2378 | conversión | 11 |
| 2379 | continuo | 11 |
| 2380 | consiguiente | 11 |
| 2381 | conducir | 11 |
| 2382 | comisión | 11 |
| 2383 | comentario | 11 |
| 2384 | combatir | 11 |
| 2385 | brutal | 11 |
| 2386 | bronce | 11 |
| 2387 | borrar | 11 |
| 2388 | bondad | 11 |
| 2389 | biblioteca | 11 |
| 2390 | berlina | 11 |
| 2391 | basta | 11 |
| 2392 | barrer | 11 |
| 2393 | arranque | 11 |
| 2394 | armar | 11 |
| 2395 | arco | 11 |
| 2396 | apóstol | 11 |
| 2397 | aplaudir | 11 |
| 2398 | aparte | 11 |
| 2399 | apagado | 11 |
| 2400 | ansiedad | 11 |
| 2401 | anhelo | 11 |
| 2402 | almunia | 11 |
| 2403 | alfombra | 11 |
| 2404 | agudo | 11 |
| 2405 | acendrado | 11 |
| 2406 | aburrimiento | 11 |
| 2407 | abrazo | 11 |
| 2408 | abanico | 11 |
| 2409 | visto | 10 |
| 2410 | vigor | 10 |
| 2411 | vigilia | 10 |
| 2412 | vencedor | 10 |
| 2413 | vehemente | 10 |
| 2414 | útil | 10 |
| 2415 | trébol | 10 |
| 2416 | tranquilizar | 10 |
| 2417 | trágico | 10 |
| 2418 | tercera | 10 |
| 2419 | temible | 10 |
| 2420 | temblor | 10 |
| 2421 | taza | 10 |
| 2422 | tapia | 10 |
| 2423 | tamaño | 10 |
| 2424 | taciturno | 10 |
| 2425 | sor | 10 |
| 2426 | soñador | 10 |
| 2427 | solemnemente | 10 |
| 2428 | soberbio | 10 |
| 2429 | so | 10 |
| 2430 | sien | 10 |
| 2431 | servanda | 10 |
| 2432 | seriar | 10 |
| 2433 | sequedad | 10 |
| 2434 | semilla | 10 |
| 2435 | seguridad | 10 |
| 2436 | sano | 10 |
| 2437 | romería | 10 |
| 2438 | retroceder | 10 |
| 2439 | respuesta | 10 |
| 2440 | resorte | 10 |
| 2441 | resistencia | 10 |
| 2442 | resbalar | 10 |
| 2443 | repugnar | 10 |
| 2444 | regular | 10 |
| 2445 | regla | 10 |
| 2446 | recreo | 10 |
| 2447 | rebelión | 10 |
| 2448 | puñetazo | 10 |
| 2449 | proposición | 10 |
| 2450 | propiedad | 10 |
| 2451 | propaganda | 10 |
| 2452 | pronunciar | 10 |
| 2453 | profesar | 10 |
| 2454 | pretexto | 10 |
| 2455 | predicador | 10 |
| 2456 | precio | 10 |
| 2457 | posición | 10 |
| 2458 | platónico | 10 |
| 2459 | pintura | 10 |
| 2460 | personal | 10 |
| 2461 | perfección | 10 |
| 2462 | pellizco | 10 |
| 2463 | pechera | 10 |
| 2464 | paraíso | 10 |
| 2465 | pantorrilla | 10 |
| 2466 | paisano | 10 |
| 2467 | pacífico | 10 |
| 2468 | olfatear | 10 |
| 2469 | oficina | 10 |
| 2470 | oculto | 10 |
| 2471 | nueve | 10 |
| 2472 | nosotras | 10 |
| 2473 | náufrago | 10 |
| 2474 | merienda | 10 |
| 2475 | materialismo | 10 |
| 2476 | masa | 10 |
| 2477 | maldad | 10 |
| 2478 | luis | 10 |
| 2479 | lógica | 10 |
| 2480 | leyenda | 10 |
| 2481 | jinete | 10 |
| 2482 | instrumento | 10 |
| 2483 | insolente | 10 |
| 2484 | inferior | 10 |
| 2485 | inés | 10 |
| 2486 | indudablemente | 10 |
| 2487 | indiscreto | 10 |
| 2488 | i | 10 |
| 2489 | huérfano | 10 |
| 2490 | higiene | 10 |
| 2491 | heroico | 10 |
| 2492 | hereje | 10 |
| 2493 | haz | 10 |
| 2494 | hay | 10 |
| 2495 | hallar | 10 |
| 2496 | grotesco | 10 |
| 2497 | griego | 10 |
| 2498 | ganancia | 10 |
| 2499 | galantería | 10 |
| 2500 | fundar | 10 |
| 2501 | fulgosio | 10 |
| 2502 | franco | 10 |
| 2503 | fraile | 10 |
| 2504 | forastero | 10 |
| 2505 | florido | 10 |
| 2506 | fingido | 10 |
| 2507 | filosófico | 10 |
| 2508 | fidelidad | 10 |
| 2509 | facultad | 10 |
| 2510 | exterior | 10 |
| 2511 | expansión | 10 |
| 2512 | estrado | 10 |
| 2513 | estante | 10 |
| 2514 | estancia | 10 |
| 2515 | espacio | 10 |
| 2516 | escupir | 10 |
| 2517 | escandalizar | 10 |
| 2518 | erótico | 10 |
| 2519 | erizar | 10 |
| 2520 | emborrachar | 10 |
| 2521 | elección | 10 |
| 2522 | edificar | 10 |
| 2523 | economía | 10 |
| 2524 | ea | 10 |
| 2525 | divinidad | 10 |
| 2526 | disposición | 10 |
| 2527 | disfrazar | 10 |
| 2528 | discusión | 10 |
| 2529 | disculpar | 10 |
| 2530 | diccionario | 10 |
| 2531 | deshonrar | 10 |
| 2532 | desgraciar | 10 |
| 2533 | descuido | 10 |
| 2534 | desahogar | 10 |
| 2535 | curia | 10 |
| 2536 | cuchillo | 10 |
| 2537 | cuál | 10 |
| 2538 | crucero | 10 |
| 2539 | criterio | 10 |
| 2540 | crisis | 10 |
| 2541 | criatura | 10 |
| 2542 | creo | 10 |
| 2543 | corresponder | 10 |
| 2544 | constancia | 10 |
| 2545 | conservador | 10 |
| 2546 | complicado | 10 |
| 2547 | comentar | 10 |
| 2548 | cofradía | 10 |
| 2549 | cintura | 10 |
| 2550 | cincuenta | 10 |
| 2551 | ceja | 10 |
| 2552 | catecismo | 10 |
| 2553 | carlista | 10 |
| 2554 | capellán | 10 |
| 2555 | campanario | 10 |
| 2556 | caminar | 10 |
| 2557 | bocado | 10 |
| 2558 | billar | 10 |
| 2559 | bando | 10 |
| 2560 | ausente | 10 |
| 2561 | atener | 10 |
| 2562 | arroyo | 10 |
| 2563 | arrimar | 10 |
| 2564 | arribar | 10 |
| 2565 | arrepentir | 10 |
| 2566 | arma | 10 |
| 2567 | aristocrático | 10 |
| 2568 | apear | 10 |
| 2569 | aparente | 10 |
| 2570 | anegar | 10 |
| 2571 | anciano | 10 |
| 2572 | amargura | 10 |
| 2573 | amantar | 10 |
| 2574 | alguien | 10 |
| 2575 | alabanza | 10 |
| 2576 | agarrar | 10 |
| 2577 | afortunadamente | 10 |
| 2578 | actual | 10 |
| 2579 | abrochar | 10 |
| 2580 | zorrilla | 9 |
| 2581 | zarzuela | 9 |
| 2582 | zapatilla | 9 |
| 2583 | violencia | 9 |
| 2584 | vestido | 9 |
| 2585 | vara | 9 |
| 2586 | valle | 9 |
| 2587 | vagar | 9 |
| 2588 | utilidad | 9 |
| 2589 | tributar | 9 |
| 2590 | trecho | 9 |
| 2591 | través | 9 |
| 2592 | trascoro | 9 |
| 2593 | trance | 9 |
| 2594 | toser | 9 |
| 2595 | título | 9 |
| 2596 | tienes | 9 |
| 2597 | tiene | 9 |
| 2598 | teoría | 9 |
| 2599 | tenue | 9 |
| 2600 | sur | 9 |
| 2601 | suavemente | 9 |
| 2602 | soslayar | 9 |
| 2603 | sombrío | 9 |
| 2604 | sólido | 9 |
| 2605 | solícito | 9 |
| 2606 | sobrar | 9 |
| 2607 | síntoma | 9 |
| 2608 | silbido | 9 |
| 2609 | sed | 9 |
| 2610 | saludable | 9 |
| 2611 | sable | 9 |
| 2612 | sabes | 9 |
| 2613 | rueda | 9 |
| 2614 | roma | 9 |
| 2615 | responsabilidad | 9 |
| 2616 | resignar | 9 |
| 2617 | repitió | 9 |
| 2618 | reducir | 9 |
| 2619 | recurrir | 9 |
| 2620 | reaccionario | 9 |
| 2621 | reacción | 9 |
| 2622 | quería | 9 |
| 2623 | quejido | 9 |
| 2624 | pureza | 9 |
| 2625 | punzante | 9 |
| 2626 | pulcritud | 9 |
| 2627 | provecho | 9 |
| 2628 | protesta | 9 |
| 2629 | prisión | 9 |
| 2630 | principalmente | 9 |
| 2631 | prescindir | 9 |
| 2632 | precaución | 9 |
| 2633 | portar | 9 |
| 2634 | población | 9 |
| 2635 | pesimismo | 9 |
| 2636 | perfumar | 9 |
| 2637 | penitencia | 9 |
| 2638 | peláez | 9 |
| 2639 | pecador | 9 |
| 2640 | ojos | 9 |
| 2641 | odioso | 9 |
| 2642 | novelar | 9 |
| 2643 | nombrar | 9 |
| 2644 | nadar | 9 |
| 2645 | nacimiento | 9 |
| 2646 | motivar | 9 |
| 2647 | materialista | 9 |
| 2648 | marinero | 9 |
| 2649 | lujuria | 9 |
| 2650 | lograr | 9 |
| 2651 | línea | 9 |
| 2652 | límite | 9 |
| 2653 | lance | 9 |
| 2654 | kempis | 9 |
| 2655 | juez | 9 |
| 2656 | isidro | 9 |
| 2657 | intensar | 9 |
| 2658 | inteligencia | 9 |
| 2659 | insustancial | 9 |
| 2660 | infalibilidad | 9 |
| 2661 | industria | 9 |
| 2662 | indiano | 9 |
| 2663 | incienso | 9 |
| 2664 | importuno | 9 |
| 2665 | ilustrado | 9 |
| 2666 | idear | 9 |
| 2667 | idealismo | 9 |
| 2668 | ida | 9 |
| 2669 | honesto | 9 |
| 2670 | hembra | 9 |
| 2671 | habitar | 9 |
| 2672 | hábil | 9 |
| 2673 | guiar | 9 |
| 2674 | guardia | 9 |
| 2675 | gravedad | 9 |
| 2676 | gratitud | 9 |
| 2677 | grandísimo | 9 |
| 2678 | granada | 9 |
| 2679 | glorioso | 9 |
| 2680 | glorieta | 9 |
| 2681 | gárrulo | 9 |
| 2682 | gallina | 9 |
| 2683 | gallardo | 9 |
| 2684 | galán | 9 |
| 2685 | función | 9 |
| 2686 | frotar | 9 |
| 2687 | froilán | 9 |
| 2688 | frecuente | 9 |
| 2689 | franqueza | 9 |
| 2690 | frac | 9 |
| 2691 | forrar | 9 |
| 2692 | físico | 9 |
| 2693 | fatiga | 9 |
| 2694 | existir | 9 |
| 2695 | exigencia | 9 |
| 2696 | examen | 9 |
| 2697 | etiqueta | 9 |
| 2698 | estremecer | 9 |
| 2699 | espontáneo | 9 |
| 2700 | espera | 9 |
| 2701 | espanto | 9 |
| 2702 | escocés | 9 |
| 2703 | entrañar | 9 |
| 2704 | enseñanza | 9 |
| 2705 | enfrentar | 9 |
| 2706 | encuentro | 9 |
| 2707 | empujar | 9 |
| 2708 | eficaz | 9 |
| 2709 | dominó | 9 |
| 2710 | disolver | 9 |
| 2711 | disfrutar | 9 |
| 2712 | dirección | 9 |
| 2713 | dinástico | 9 |
| 2714 | diabólico | 9 |
| 2715 | desesperación | 9 |
| 2716 | descuidar | 9 |
| 2717 | delatar | 9 |
| 2718 | declaración | 9 |
| 2719 | deán | 9 |
| 2720 | dato | 9 |
| 2721 | damasco | 9 |
| 2722 | curva | 9 |
| 2723 | cuchicheo | 9 |
| 2724 | cuales | 9 |
| 2725 | corro | 9 |
| 2726 | conversar | 9 |
| 2727 | convalecencia | 9 |
| 2728 | continente | 9 |
| 2729 | conmigo | 9 |
| 2730 | componer | 9 |
| 2731 | comparación | 9 |
| 2732 | colorado | 9 |
| 2733 | colección | 9 |
| 2734 | clavo | 9 |
| 2735 | ciento | 9 |
| 2736 | chorrear | 9 |
| 2737 | choque | 9 |
| 2738 | chillón | 9 |
| 2739 | chateaubriand | 9 |
| 2740 | ceniza | 9 |
| 2741 | catalejo | 9 |
| 2742 | casto | 9 |
| 2743 | cascabel | 9 |
| 2744 | carro | 9 |
| 2745 | carnal | 9 |
| 2746 | carga | 9 |
| 2747 | capítulo | 9 |
| 2748 | campanada | 9 |
| 2749 | calvario | 9 |
| 2750 | caldo | 9 |
| 2751 | cadáver | 9 |
| 2752 | cabaña | 9 |
| 2753 | busca | 9 |
| 2754 | burla | 9 |
| 2755 | bruto | 9 |
| 2756 | brisa | 9 |
| 2757 | bostezar | 9 |
| 2758 | bonito | 9 |
| 2759 | bola | 9 |
| 2760 | blanquecino | 9 |
| 2761 | blandura | 9 |
| 2762 | beato | 9 |
| 2763 | bailarín | 9 |
| 2764 | azular | 9 |
| 2765 | auténtico | 9 |
| 2766 | aureola | 9 |
| 2767 | aumentar | 9 |
| 2768 | audacia | 9 |
| 2769 | atrocidad | 9 |
| 2770 | atrevimiento | 9 |
| 2771 | aspaviento | 9 |
| 2772 | asesinar | 9 |
| 2773 | arduo | 9 |
| 2774 | apasionar | 9 |
| 2775 | añadió | 9 |
| 2776 | antipático | 9 |
| 2777 | anchas | 9 |
| 2778 | amontonar | 9 |
| 2779 | alusión | 9 |
| 2780 | alimentar | 9 |
| 2781 | ajustar | 9 |
| 2782 | ajedrez | 9 |
| 2783 | airoso | 9 |
| 2784 | aguja | 9 |
| 2785 | agradecimiento | 9 |
| 2786 | afectar | 9 |
| 2787 | acoger | 9 |
| 2788 | acertar | 9 |
| 2789 | accidente | 9 |
| 2790 | abundante | 9 |
| 2791 | abrumar | 9 |
| 2792 | abrasar | 9 |
| 2793 | abandono | 9 |
| 2794 | voto | 8 |
| 2795 | vil | 8 |
| 2796 | vía | 8 |
| 2797 | vetar | 8 |
| 2798 | verdura | 8 |
| 2799 | veneno | 8 |
| 2800 | vena | 8 |
| 2801 | velo | 8 |
| 2802 | vapor | 8 |
| 2803 | ultrajar | 8 |
| 2804 | trémulo | 8 |
| 2805 | traza | 8 |
| 2806 | trasnochador | 8 |
| 2807 | trasaltar | 8 |
| 2808 | transigir | 8 |
| 2809 | torpeza | 8 |
| 2810 | tormenta | 8 |
| 2811 | tolerancia | 8 |
| 2812 | toda | 8 |
| 2813 | tinta | 8 |
| 2814 | timbre | 8 |
| 2815 | tibio | 8 |
| 2816 | teólogo | 8 |
| 2817 | tentador | 8 |
| 2818 | temporada | 8 |
| 2819 | tema | 8 |
| 2820 | teja | 8 |
| 2821 | tajada | 8 |
| 2822 | superioridad | 8 |
| 2823 | sumo | 8 |
| 2824 | suelto | 8 |
| 2825 | soplo | 8 |
| 2826 | sonoro | 8 |
| 2827 | solución | 8 |
| 2828 | siesta | 8 |
| 2829 | seglar | 8 |
| 2830 | sapo | 8 |
| 2831 | salvo | 8 |
| 2832 | sacramento | 8 |
| 2833 | saciar | 8 |
| 2834 | sabroso | 8 |
| 2835 | sabe | 8 |
| 2836 | s | 8 |
| 2837 | roja | 8 |
| 2838 | rogar | 8 |
| 2839 | respondió | 8 |
| 2840 | reputar | 8 |
| 2841 | repetía | 8 |
| 2842 | renegar | 8 |
| 2843 | rencor | 8 |
| 2844 | remontar | 8 |
| 2845 | relativo | 8 |
| 2846 | reflexionar | 8 |
| 2847 | rasgo | 8 |
| 2848 | ráfaga | 8 |
| 2849 | racional | 8 |
| 2850 | provocativo | 8 |
| 2851 | proporción | 8 |
| 2852 | prolongar | 8 |
| 2853 | programa | 8 |
| 2854 | pretextar | 8 |
| 2855 | presumir | 8 |
| 2856 | preparativo | 8 |
| 2857 | prensa | 8 |
| 2858 | premio | 8 |
| 2859 | práctica | 8 |
| 2860 | poseer | 8 |
| 2861 | podredumbre | 8 |
| 2862 | pintor | 8 |
| 2863 | picaresco | 8 |
| 2864 | peseta | 8 |
| 2865 | persecución | 8 |
| 2866 | permanecer | 8 |
| 2867 | perfil | 8 |
| 2868 | pepa | 8 |
| 2869 | pender | 8 |
| 2870 | pecaminoso | 8 |
| 2871 | paternal | 8 |
| 2872 | participar | 8 |
| 2873 | papa | 8 |
| 2874 | paloma | 8 |
| 2875 | palmo | 8 |
| 2876 | palique | 8 |
| 2877 | paja | 8 |
| 2878 | ostentoso | 8 |
| 2879 | onda | 8 |
| 2880 | oleaje | 8 |
| 2881 | oficial | 8 |
| 2882 | ocurrencia | 8 |
| 2883 | ocioso | 8 |
| 2884 | obispado | 8 |
| 2885 | notable | 8 |
| 2886 | nocturno | 8 |
| 2887 | niñez | 8 |
| 2888 | nieve | 8 |
| 2889 | nazareno | 8 |
| 2890 | naturalismo | 8 |
| 2891 | muchedumbre | 8 |
| 2892 | moro | 8 |
| 2893 | morada | 8 |
| 2894 | montañés | 8 |
| 2895 | mono | 8 |
| 2896 | monaguillo | 8 |
| 2897 | mojado | 8 |
| 2898 | mitología | 8 |
| 2899 | minar | 8 |
| 2900 | millonario | 8 |
| 2901 | mercado | 8 |
| 2902 | mediar | 8 |
| 2903 | mediante | 8 |
| 2904 | mecedora | 8 |
| 2905 | mate | 8 |
| 2906 | marfil | 8 |
| 2907 | maravilla | 8 |
| 2908 | manzana | 8 |
| 2909 | manos | 8 |
| 2910 | macho | 8 |
| 2911 | lumbre | 8 |
| 2912 | lujuriar | 8 |
| 2913 | lúbrico | 8 |
| 2914 | lomo | 8 |
| 2915 | literatura | 8 |
| 2916 | líquido | 8 |
| 2917 | licenciar | 8 |
| 2918 | leve | 8 |
| 2919 | lento | 8 |
| 2920 | lana | 8 |
| 2921 | ladrar | 8 |
| 2922 | jesucristo | 8 |
| 2923 | jaula | 8 |
| 2924 | inverosímil | 8 |
| 2925 | intriga | 8 |
| 2926 | intervenir | 8 |
| 2927 | institución | 8 |
| 2928 | instalar | 8 |
| 2929 | inquieto | 8 |
| 2930 | inmundicia | 8 |
| 2931 | incorporar | 8 |
| 2932 | incidente | 8 |
| 2933 | impertinente | 8 |
| 2934 | horrible | 8 |
| 2935 | hojarasca | 8 |
| 2936 | hierba | 8 |
| 2937 | heredero | 8 |
| 2938 | hablador | 8 |
| 2939 | gruñir | 8 |
| 2940 | gritaron | 8 |
| 2941 | grabar | 8 |
| 2942 | godino | 8 |
| 2943 | gobernar | 8 |
| 2944 | formal | 8 |
| 2945 | fatuo | 8 |
| 2946 | fabricar | 8 |
| 2947 | extraordinario | 8 |
| 2948 | exacto | 8 |
| 2949 | estupidez | 8 |
| 2950 | estribo | 8 |
| 2951 | estrepitoso | 8 |
| 2952 | esplendor | 8 |
| 2953 | esencia | 8 |
| 2954 | escéptico | 8 |
| 2955 | eran | 8 |
| 2956 | equilibrio | 8 |
| 2957 | enredar | 8 |
| 2958 | enorme | 8 |
| 2959 | encendido | 8 |
| 2960 | encarnar | 8 |
| 2961 | encaramar | 8 |
| 2962 | enagua | 8 |
| 2963 | empuñar | 8 |
| 2964 | ejercer | 8 |
| 2965 | efímero | 8 |
| 2966 | dolores | 8 |
| 2967 | docena | 8 |
| 2968 | distinguido | 8 |
| 2969 | dibujar | 8 |
| 2970 | destinar | 8 |
| 2971 | destacar | 8 |
| 2972 | desesperado | 8 |
| 2973 | desdeñar | 8 |
| 2974 | desconfiar | 8 |
| 2975 | desconfianza | 8 |
| 2976 | descender | 8 |
| 2977 | descalzo | 8 |
| 2978 | desairar | 8 |
| 2979 | desacreditar | 8 |
| 2980 | desabrido | 8 |
| 2981 | derribar | 8 |
| 2982 | deprisa | 8 |
| 2983 | defensa | 8 |
| 2984 | cualidad | 8 |
| 2985 | cuadrado | 8 |
| 2986 | crianza | 8 |
| 2987 | creencia | 8 |
| 2988 | cortés | 8 |
| 2989 | correo | 8 |
| 2990 | corbata | 8 |
| 2991 | corazonada | 8 |
| 2992 | copiar | 8 |
| 2993 | contradecir | 8 |
| 2994 | contracayes | 8 |
| 2995 | contorno | 8 |
| 2996 | consideración | 8 |
| 2997 | consecuencia | 8 |
| 2998 | conocido | 8 |
| 2999 | conformar | 8 |
| 3000 | colmo | 8 |
| 3001 | colgadura | 8 |
| 3002 | cola | 8 |
| 3003 | cochero | 8 |
| 3004 | claustro | 8 |
| 3005 | cirio | 8 |
| 3006 | churrigueresco | 8 |
| 3007 | chupar | 8 |
| 3008 | champaña | 8 |
| 3009 | ceremonia | 8 |
| 3010 | celestial | 8 |
| 3011 | celda | 8 |
| 3012 | catástrofe | 8 |
| 3013 | castilla | 8 |
| 3014 | carnaval | 8 |
| 3015 | cárcel | 8 |
| 3016 | carbón | 8 |
| 3017 | caprichoso | 8 |
| 3018 | cañón | 8 |
| 3019 | canto | 8 |
| 3020 | canónico | 8 |
| 3021 | canon | 8 |
| 3022 | cana | 8 |
| 3023 | campaña | 8 |
| 3024 | calmar | 8 |
| 3025 | caído | 8 |
| 3026 | brusco | 8 |
| 3027 | brigadiera | 8 |
| 3028 | botón | 8 |
| 3029 | bota | 8 |
| 3030 | bordar | 8 |
| 3031 | bigote | 8 |
| 3032 | batallar | 8 |
| 3033 | barquilla | 8 |
| 3034 | barato | 8 |
| 3035 | azúcar | 8 |
| 3036 | asombrar | 8 |
| 3037 | arrodillar | 8 |
| 3038 | arquitectura | 8 |
| 3039 | arqueológico | 8 |
| 3040 | aridez | 8 |
| 3041 | apuro | 8 |
| 3042 | apretón | 8 |
| 3043 | aparición | 8 |
| 3044 | aparentar | 8 |
| 3045 | angustia | 8 |
| 3046 | andadas | 8 |
| 3047 | análogo | 8 |
| 3048 | amparo | 8 |
| 3049 | américa | 8 |
| 3050 | amargar | 8 |
| 3051 | almíbar | 8 |
| 3052 | alas | 8 |
| 3053 | agosto | 8 |
| 3054 | afirmación | 8 |
| 3055 | aficionar | 8 |
| 3056 | acuerdo | 8 |
| 3057 | acontecimiento | 8 |
| 3058 | acerca | 8 |
| 3059 | abstener | 8 |
| 3060 | abril | 8 |
| 3061 | abrigo | 8 |
| 3062 | abrigar | 8 |
| 3063 | zaragoza | 7 |
| 3064 | zapatero | 7 |
| 3065 | yeso | 7 |
| 3066 | voltaire | 7 |
| 3067 | vigoroso | 7 |
| 3068 | vigilar | 7 |
| 3069 | vicente | 7 |
| 3070 | ven | 7 |
| 3071 | vegetar | 7 |
| 3072 | v | 7 |
| 3073 | usurero | 7 |
| 3074 | urgente | 7 |
| 3075 | unción | 7 |
| 3076 | umbral | 7 |
| 3077 | trepar | 7 |
| 3078 | tremendo | 7 |
| 3079 | trazar | 7 |
| 3080 | transeúnte | 7 |
| 3081 | tranquilamente | 7 |
| 3082 | tradición | 7 |
| 3083 | tórtola | 7 |
| 3084 | tornear | 7 |
| 3085 | toldo | 7 |
| 3086 | terco | 7 |
| 3087 | teñir | 7 |
| 3088 | técnico | 7 |
| 3089 | té | 7 |
| 3090 | taller | 7 |
| 3091 | sujeto | 7 |
| 3092 | suculento | 7 |
| 3093 | soy | 7 |
| 3094 | sórdido | 7 |
| 3095 | somnolencia | 7 |
| 3096 | solterona | 7 |
| 3097 | solitaria | 7 |
| 3098 | soberbia | 7 |
| 3099 | simpatía | 7 |
| 3100 | sigilo | 7 |
| 3101 | severidad | 7 |
| 3102 | seso | 7 |
| 3103 | septiembre | 7 |
| 3104 | seguido | 7 |
| 3105 | santiguar | 7 |
| 3106 | sangrar | 7 |
| 3107 | sabor | 7 |
| 3108 | ruborizar | 7 |
| 3109 | rozar | 7 |
| 3110 | rosita | 7 |
| 3111 | rizo | 7 |
| 3112 | rítmico | 7 |
| 3113 | rita | 7 |
| 3114 | reyerta | 7 |
| 3115 | resucitar | 7 |
| 3116 | resplandor | 7 |
| 3117 | resonar | 7 |
| 3118 | resignación | 7 |
| 3119 | reserva | 7 |
| 3120 | reprender | 7 |
| 3121 | renta | 7 |
| 3122 | renacer | 7 |
| 3123 | remoto | 7 |
| 3124 | relucir | 7 |
| 3125 | regencia | 7 |
| 3126 | realizar | 7 |
| 3127 | rabiar | 7 |
| 3128 | rabia | 7 |
| 3129 | quiere | 7 |
| 3130 | quebrar | 7 |
| 3131 | puede | 7 |
| 3132 | pudrir | 7 |
| 3133 | providencia | 7 |
| 3134 | proseguir | 7 |
| 3135 | progresista | 7 |
| 3136 | principiar | 7 |
| 3137 | pretendiente | 7 |
| 3138 | prender | 7 |
| 3139 | prelado | 7 |
| 3140 | precipitar | 7 |
| 3141 | prebendado | 7 |
| 3142 | postigo | 7 |
| 3143 | popular | 7 |
| 3144 | plática | 7 |
| 3145 | plástico | 7 |
| 3146 | pillar | 7 |
| 3147 | picardía | 7 |
| 3148 | pescar | 7 |
| 3149 | perspectiva | 7 |
| 3150 | pequeñez | 7 |
| 3151 | pensó | 7 |
| 3152 | pasajero | 7 |
| 3153 | pasaje | 7 |
| 3154 | párrafo | 7 |
| 3155 | parir | 7 |
| 3156 | parche | 7 |
| 3157 | paraje | 7 |
| 3158 | paraguay | 7 |
| 3159 | pánico | 7 |
| 3160 | palidecer | 7 |
| 3161 | paisaje | 7 |
| 3162 | pagano | 7 |
| 3163 | p | 7 |
| 3164 | otorgar | 7 |
| 3165 | origen | 7 |
| 3166 | ordenar | 7 |
| 3167 | oratorio | 7 |
| 3168 | oposición | 7 |
| 3169 | oía | 7 |
| 3170 | odiar | 7 |
| 3171 | octubre | 7 |
| 3172 | obligación | 7 |
| 3173 | nota | 7 |
| 3174 | negra | 7 |
| 3175 | nata | 7 |
| 3176 | na | 7 |
| 3177 | mudo | 7 |
| 3178 | mosca | 7 |
| 3179 | modos | 7 |
| 3180 | modestia | 7 |
| 3181 | mística | 7 |
| 3182 | misión | 7 |
| 3183 | metido | 7 |
| 3184 | merendar | 7 |
| 3185 | merced | 7 |
| 3186 | mejorar | 7 |
| 3187 | mecánico | 7 |
| 3188 | mayoría | 7 |
| 3189 | mata | 7 |
| 3190 | martirio | 7 |
| 3191 | mantel | 7 |
| 3192 | maliciar | 7 |
| 3193 | maledicencia | 7 |
| 3194 | maestra | 7 |
| 3195 | madrileño | 7 |
| 3196 | luminoso | 7 |
| 3197 | leche | 7 |
| 3198 | lastimar | 7 |
| 3199 | larga | 7 |
| 3200 | lanzar | 7 |
| 3201 | lamer | 7 |
| 3202 | juramento | 7 |
| 3203 | junio | 7 |
| 3204 | jilguero | 7 |
| 3205 | isla | 7 |
| 3206 | inveterado | 7 |
| 3207 | interlocutor | 7 |
| 3208 | insulto | 7 |
| 3209 | insufrible | 7 |
| 3210 | insinuación | 7 |
| 3211 | inmortal | 7 |
| 3212 | injusto | 7 |
| 3213 | injuria | 7 |
| 3214 | ingenio | 7 |
| 3215 | infiel | 7 |
| 3216 | infantil | 7 |
| 3217 | infalible | 7 |
| 3218 | indiferente | 7 |
| 3219 | indecoroso | 7 |
| 3220 | inclusive | 7 |
| 3221 | inclinación | 7 |
| 3222 | incierto | 7 |
| 3223 | imitación | 7 |
| 3224 | idolatría | 7 |
| 3225 | ido | 7 |
| 3226 | honradez | 7 |
| 3227 | heroína | 7 |
| 3228 | herencia | 7 |
| 3229 | hacienda | 7 |
| 3230 | guiñar | 7 |
| 3231 | globo | 7 |
| 3232 | gaita | 7 |
| 3233 | frecuencia | 7 |
| 3234 | fórmula | 7 |
| 3235 | folletín | 7 |
| 3236 | follaje | 7 |
| 3237 | favorecer | 7 |
| 3238 | facción | 7 |
| 3239 | extravío | 7 |
| 3240 | éxtasis | 7 |
| 3241 | exceso | 7 |
| 3242 | exaltado | 7 |
| 3243 | estrago | 7 |
| 3244 | estos | 7 |
| 3245 | están | 7 |
| 3246 | establecer | 7 |
| 3247 | esquivar | 7 |
| 3248 | espectador | 7 |
| 3249 | esforzar | 7 |
| 3250 | escribano | 7 |
| 3251 | escondite | 7 |
| 3252 | erudito | 7 |
| 3253 | erguir | 7 |
| 3254 | envidioso | 7 |
| 3255 | enfadar | 7 |
| 3256 | encarnado | 7 |
| 3257 | empeño | 7 |
| 3258 | eléctrico | 7 |
| 3259 | edificante | 7 |
| 3260 | dote | 7 |
| 3261 | divertido | 7 |
| 3262 | dispersar | 7 |
| 3263 | discurrir | 7 |
| 3264 | diferencia | 7 |
| 3265 | diestro | 7 |
| 3266 | despierto | 7 |
| 3267 | despedazar | 7 |
| 3268 | despachar | 7 |
| 3269 | desorden | 7 |
| 3270 | desmoronar | 7 |
| 3271 | desechar | 7 |
| 3272 | descubrimiento | 7 |
| 3273 | delicadeza | 7 |
| 3274 | deleitar | 7 |
| 3275 | decidor | 7 |
| 3276 | debe | 7 |
| 3277 | cumbre | 7 |
| 3278 | cueva | 7 |
| 3279 | cuaresma | 7 |
| 3280 | crueldad | 7 |
| 3281 | cortesía | 7 |
| 3282 | corral | 7 |
| 3283 | cordel | 7 |
| 3284 | conyugal | 7 |
| 3285 | contribuir | 7 |
| 3286 | constar | 7 |
| 3287 | conserje | 7 |
| 3288 | conjunto | 7 |
| 3289 | confidente | 7 |
| 3290 | cómodo | 7 |
| 3291 | comodidad | 7 |
| 3292 | combinación | 7 |
| 3293 | colega | 7 |
| 3294 | casulla | 7 |
| 3295 | cartucho | 7 |
| 3296 | capar | 7 |
| 3297 | caña | 7 |
| 3298 | cansancio | 7 |
| 3299 | campanero | 7 |
| 3300 | callado | 7 |
| 3301 | calificar | 7 |
| 3302 | cal | 7 |
| 3303 | bucólico | 7 |
| 3304 | brinco | 7 |
| 3305 | brecha | 7 |
| 3306 | brasa | 7 |
| 3307 | borbotones | 7 |
| 3308 | bonachón | 7 |
| 3309 | blasfemar | 7 |
| 3310 | blas | 7 |
| 3311 | barco | 7 |
| 3312 | avaricia | 7 |
| 3313 | avanzar | 7 |
| 3314 | auxilio | 7 |
| 3315 | atractivo | 7 |
| 3316 | atentar | 7 |
| 3317 | áspero | 7 |
| 3318 | aspereza | 7 |
| 3319 | asesino | 7 |
| 3320 | artillero | 7 |
| 3321 | ara | 7 |
| 3322 | apretado | 7 |
| 3323 | apoderar | 7 |
| 3324 | aparato | 7 |
| 3325 | anticuario | 7 |
| 3326 | ángulo | 7 |
| 3327 | amiguito | 7 |
| 3328 | alvarito | 7 |
| 3329 | alentar | 7 |
| 3330 | álamo | 7 |
| 3331 | aguantar | 7 |
| 3332 | actitud | 7 |
| 3333 | achacar | 7 |
| 3334 | abuso | 7 |
| 3335 | abonar | 7 |
| 3336 | abdicación | 7 |
| 3337 | zumbar | 6 |
| 3338 | zorro | 6 |
| 3339 | vulgaridad | 6 |
| 3340 | vinculete | 6 |
| 3341 | verá | 6 |
| 3342 | vecindario | 6 |
| 3343 | variedad | 6 |
| 3344 | varar | 6 |
| 3345 | valladolid | 6 |
| 3346 | vaguedad | 6 |
| 3347 | vacilante | 6 |
| 3348 | va | 6 |
| 3349 | urraca | 6 |
| 3350 | turgente | 6 |
| 3351 | traslacerca | 6 |
| 3352 | tostar | 6 |
| 3353 | torbellino | 6 |
| 3354 | tontería | 6 |
| 3355 | tomo | 6 |
| 3356 | tísico | 6 |
| 3357 | tinte | 6 |
| 3358 | tímido | 6 |
| 3359 | tientas | 6 |
| 3360 | tesis | 6 |
| 3361 | telón | 6 |
| 3362 | tacto | 6 |
| 3363 | subrepticio | 6 |
| 3364 | sopor | 6 |
| 3365 | someter | 6 |
| 3366 | soltero | 6 |
| 3367 | sollozo | 6 |
| 3368 | solar | 6 |
| 3369 | socarrón | 6 |
| 3370 | sobresalto | 6 |
| 3371 | sinceramente | 6 |
| 3372 | silueta | 6 |
| 3373 | seto | 6 |
| 3374 | sesión | 6 |
| 3375 | sesenta | 6 |
| 3376 | servilleta | 6 |
| 3377 | seriamente | 6 |
| 3378 | señorón | 6 |
| 3379 | sal | 6 |
| 3380 | saco | 6 |
| 3381 | sabía | 6 |
| 3382 | rutina | 6 |
| 3383 | ruin | 6 |
| 3384 | rubor | 6 |
| 3385 | rozagante | 6 |
| 3386 | rosario | 6 |
| 3387 | ronco | 6 |
| 3388 | rocío | 6 |
| 3389 | roca | 6 |
| 3390 | rizar | 6 |
| 3391 | retrasar | 6 |
| 3392 | resumen | 6 |
| 3393 | resultado | 6 |
| 3394 | restituto | 6 |
| 3395 | respiración | 6 |
| 3396 | resonancia | 6 |
| 3397 | remorder | 6 |
| 3398 | relieve | 6 |
| 3399 | régimen | 6 |
| 3400 | redimir | 6 |
| 3401 | red | 6 |
| 3402 | recto | 6 |
| 3403 | recomendación | 6 |
| 3404 | reciente | 6 |
| 3405 | rechinar | 6 |
| 3406 | rechazar | 6 |
| 3407 | rebaño | 6 |
| 3408 | rapidez | 6 |
| 3409 | ramona | 6 |
| 3410 | quieto | 6 |
| 3411 | queja | 6 |
| 3412 | puntiagudo | 6 |
| 3413 | pulla | 6 |
| 3414 | pueril | 6 |
| 3415 | ps | 6 |
| 3416 | proximidad | 6 |
| 3417 | provincial | 6 |
| 3418 | proteger | 6 |
| 3419 | profundamente | 6 |
| 3420 | príncipe | 6 |
| 3421 | predominar | 6 |
| 3422 | predilecto | 6 |
| 3423 | pórtico | 6 |
| 3424 | portero | 6 |
| 3425 | policía | 6 |
| 3426 | poblar | 6 |
| 3427 | plateresco | 6 |
| 3428 | plataforma | 6 |
| 3429 | planta | 6 |
| 3430 | pío | 6 |
| 3431 | pimienta | 6 |
| 3432 | pieza | 6 |
| 3433 | pez | 6 |
| 3434 | petróleo | 6 |
| 3435 | peste | 6 |
| 3436 | perversión | 6 |
| 3437 | persuadir | 6 |
| 3438 | perpetuo | 6 |
| 3439 | perjuicio | 6 |
| 3440 | perfumado | 6 |
| 3441 | pensador | 6 |
| 3442 | pécora | 6 |
| 3443 | pavor | 6 |
| 3444 | paulinas | 6 |
| 3445 | palmadita | 6 |
| 3446 | palmada | 6 |
| 3447 | palma | 6 |
| 3448 | pablo | 6 |
| 3449 | oso | 6 |
| 3450 | orgía | 6 |
| 3451 | oportunidad | 6 |
| 3452 | ondulante | 6 |
| 3453 | oeste | 6 |
| 3454 | océano | 6 |
| 3455 | obstinar | 6 |
| 3456 | obsequiar | 6 |
| 3457 | número | 6 |
| 3458 | noticiar | 6 |
| 3459 | notario | 6 |
| 3460 | noches | 6 |
| 3461 | naranja | 6 |
| 3462 | muelle | 6 |
| 3463 | muceta | 6 |
| 3464 | morado | 6 |
| 3465 | monotonía | 6 |
| 3466 | molestia | 6 |
| 3467 | mismísimo | 6 |
| 3468 | milagroso | 6 |
| 3469 | miembro | 6 |
| 3470 | metal | 6 |
| 3471 | metáfora | 6 |
| 3472 | mesilla | 6 |
| 3473 | mesar | 6 |
| 3474 | melifluo | 6 |
| 3475 | meditación | 6 |
| 3476 | mediquillo | 6 |
| 3477 | matiz | 6 |
| 3478 | mas | 6 |
| 3479 | martillazo | 6 |
| 3480 | mantón | 6 |
| 3481 | mantilla | 6 |
| 3482 | manosear | 6 |
| 3483 | manifestación | 6 |
| 3484 | mancebo | 6 |
| 3485 | malvado | 6 |
| 3486 | luto | 6 |
| 3487 | lujoso | 6 |
| 3488 | lucía | 6 |
| 3489 | lope | 6 |
| 3490 | listo | 6 |
| 3491 | licor | 6 |
| 3492 | lícito | 6 |
| 3493 | laurel | 6 |
| 3494 | ladrido | 6 |
| 3495 | lacayo | 6 |
| 3496 | juguete | 6 |
| 3497 | juanito | 6 |
| 3498 | juana | 6 |
| 3499 | joya | 6 |
| 3500 | invocar | 6 |
| 3501 | invención | 6 |
| 3502 | invadir | 6 |
| 3503 | intimar | 6 |
| 3504 | interpretar | 6 |
| 3505 | interminable | 6 |
| 3506 | intensidad | 6 |
| 3507 | intelectual | 6 |
| 3508 | inspiración | 6 |
| 3509 | insoportable | 6 |
| 3510 | insolencia | 6 |
| 3511 | insinuar | 6 |
| 3512 | inquietud | 6 |
| 3513 | inofensivo | 6 |
| 3514 | inmaculado | 6 |
| 3515 | injertar | 6 |
| 3516 | iniciativa | 6 |
| 3517 | influir | 6 |
| 3518 | infidelidad | 6 |
| 3519 | infernal | 6 |
| 3520 | inesperado | 6 |
| 3521 | inerte | 6 |
| 3522 | indigno | 6 |
| 3523 | incomodar | 6 |
| 3524 | inclinado | 6 |
| 3525 | impropio | 6 |
| 3526 | importunar | 6 |
| 3527 | impiedad | 6 |
| 3528 | imperioso | 6 |
| 3529 | imperio | 6 |
| 3530 | ilustrísimo | 6 |
| 3531 | igualdad | 6 |
| 3532 | humanar | 6 |
| 3533 | horno | 6 |
| 3534 | hito | 6 |
| 3535 | himno | 6 |
| 3536 | higiénico | 6 |
| 3537 | hermandad | 6 |
| 3538 | herida | 6 |
| 3539 | herejía | 6 |
| 3540 | helado | 6 |
| 3541 | hechizo | 6 |
| 3542 | hastiar | 6 |
| 3543 | hallazgo | 6 |
| 3544 | gutural | 6 |
| 3545 | grillo | 6 |
| 3546 | gloriar | 6 |
| 3547 | gesticular | 6 |
| 3548 | genio | 6 |
| 3549 | gabán | 6 |
| 3550 | fusil | 6 |
| 3551 | fray | 6 |
| 3552 | franja | 6 |
| 3553 | francamente | 6 |
| 3554 | fornido | 6 |
| 3555 | flotante | 6 |
| 3556 | flojo | 6 |
| 3557 | favorito | 6 |
| 3558 | fatal | 6 |
| 3559 | fango | 6 |
| 3560 | fanatizar | 6 |
| 3561 | facilitar | 6 |
| 3562 | fachada | 6 |
| 3563 | exuberante | 6 |
| 3564 | extraviar | 6 |
| 3565 | excitación | 6 |
| 3566 | evangelio | 6 |
| 3567 | eternamente | 6 |
| 3568 | estéril | 6 |
| 3569 | espaldas | 6 |
| 3570 | esmero | 6 |
| 3571 | escudriñar | 6 |
| 3572 | escoba | 6 |
| 3573 | escandalosa | 6 |
| 3574 | envidiable | 6 |
| 3575 | envenenar | 6 |
| 3576 | entrega | 6 |
| 3577 | entablar | 6 |
| 3578 | ensayar | 6 |
| 3579 | enroscar | 6 |
| 3580 | enfriar | 6 |
| 3581 | endiablado | 6 |
| 3582 | encina | 6 |
| 3583 | embustero | 6 |
| 3584 | elegía | 6 |
| 3585 | ejemplar | 6 |
| 3586 | eficacia | 6 |
| 3587 | económico | 6 |
| 3588 | eco | 6 |
| 3589 | dotar | 6 |
| 3590 | domingo | 6 |
| 3591 | distinción | 6 |
| 3592 | disputa | 6 |
| 3593 | director | 6 |
| 3594 | diputar | 6 |
| 3595 | diplomático | 6 |
| 3596 | diplomacia | 6 |
| 3597 | determinar | 6 |
| 3598 | desvergonzar | 6 |
| 3599 | destrozar | 6 |
| 3600 | despotismo | 6 |
| 3601 | despojar | 6 |
| 3602 | despensa | 6 |
| 3603 | despacio | 6 |
| 3604 | desinteresado | 6 |
| 3605 | desengaño | 6 |
| 3606 | desengañar | 6 |
| 3607 | desconocer | 6 |
| 3608 | descomponer | 6 |
| 3609 | derrotar | 6 |
| 3610 | deliberar | 6 |
| 3611 | dejo | 6 |
| 3612 | decoroso | 6 |
| 3613 | cutis | 6 |
| 3614 | cuna | 6 |
| 3615 | cultivar | 6 |
| 3616 | culinario | 6 |
| 3617 | crónica | 6 |
| 3618 | crítica | 6 |
| 3619 | crepúsculo | 6 |
| 3620 | creía | 6 |
| 3621 | costurero | 6 |
| 3622 | cosquillar | 6 |
| 3623 | cortina | 6 |
| 3624 | corrillo | 6 |
| 3625 | corregir | 6 |
| 3626 | corrección | 6 |
| 3627 | corporal | 6 |
| 3628 | corona | 6 |
| 3629 | cordial | 6 |
| 3630 | conveniencia | 6 |
| 3631 | convaleciente | 6 |
| 3632 | contenido | 6 |
| 3633 | consola | 6 |
| 3634 | congoja | 6 |
| 3635 | confusión | 6 |
| 3636 | confiar | 6 |
| 3637 | concierto | 6 |
| 3638 | concejal | 6 |
| 3639 | conceder | 6 |
| 3640 | compromiso | 6 |
| 3641 | complicar | 6 |
| 3642 | compás | 6 |
| 3643 | comezón | 6 |
| 3644 | comediar | 6 |
| 3645 | colondres | 6 |
| 3646 | colmar | 6 |
| 3647 | colina | 6 |
| 3648 | colcha | 6 |
| 3649 | cogote | 6 |
| 3650 | codear | 6 |
| 3651 | chusco | 6 |
| 3652 | chorro | 6 |
| 3653 | chocolate | 6 |
| 3654 | chillido | 6 |
| 3655 | chaleco | 6 |
| 3656 | cerebrar | 6 |
| 3657 | ceño | 6 |
| 3658 | cejar | 6 |
| 3659 | cavilación | 6 |
| 3660 | catorce | 6 |
| 3661 | catequista | 6 |
| 3662 | catarata | 6 |
| 3663 | castillo | 6 |
| 3664 | carruaje | 6 |
| 3665 | cárdeno | 6 |
| 3666 | campestre | 6 |
| 3667 | callejón | 6 |
| 3668 | cabecero | 6 |
| 3669 | bobo | 6 |
| 3670 | blasfemia | 6 |
| 3671 | blancura | 6 |
| 3672 | beneficio | 6 |
| 3673 | bautista | 6 |
| 3674 | bata | 6 |
| 3675 | basílica | 6 |
| 3676 | barquero | 6 |
| 3677 | bárbaro | 6 |
| 3678 | barandilla | 6 |
| 3679 | balandrán | 6 |
| 3680 | bacante | 6 |
| 3681 | baba | 6 |
| 3682 | ayuda | 6 |
| 3683 | avenir | 6 |
| 3684 | ave | 6 |
| 3685 | aturdimiento | 6 |
| 3686 | ateísmo | 6 |
| 3687 | asomo | 6 |
| 3688 | asombro | 6 |
| 3689 | asfixiar | 6 |
| 3690 | ascender | 6 |
| 3691 | arriesgar | 6 |
| 3692 | arrebato | 6 |
| 3693 | armonioso | 6 |
| 3694 | armiño | 6 |
| 3695 | arca | 6 |
| 3696 | arañar | 6 |
| 3697 | aproximar | 6 |
| 3698 | aplazar | 6 |
| 3699 | antepecho | 6 |
| 3700 | amorío | 6 |
| 3701 | amores | 6 |
| 3702 | amistar | 6 |
| 3703 | amenaza | 6 |
| 3704 | ambas | 6 |
| 3705 | alzar | 6 |
| 3706 | alzacuello | 6 |
| 3707 | alcance | 6 |
| 3708 | alba | 6 |
| 3709 | ahorrar | 6 |
| 3710 | aguardar | 6 |
| 3711 | afable | 6 |
| 3712 | adúltero | 6 |
| 3713 | adorno | 6 |
| 3714 | adorador | 6 |
| 3715 | administración | 6 |
| 3716 | acento | 6 |
| 3717 | acechar | 6 |
| 3718 | acceso | 6 |
| 3719 | acabado | 6 |
| 3720 | aburrido | 6 |
| 3721 | abstracto | 6 |
| 3722 | abstracción | 6 |
| 3723 | absolver | 6 |
| 3724 | absolutamente | 6 |
| 3725 | abandonado | 6 |
| 3726 | zarza | 5 |
| 3727 | zapico | 5 |
| 3728 | zaguán | 5 |
| 3729 | xv | 5 |
| 3730 | votar | 5 |
| 3731 | volvió | 5 |
| 3732 | vociferar | 5 |
| 3733 | vivienda | 5 |
| 3734 | vivaracho | 5 |
| 3735 | viudo | 5 |
| 3736 | víspera | 5 |
| 3737 | visionar | 5 |
| 3738 | viscoso | 5 |
| 3739 | villano | 5 |
| 3740 | vigilancia | 5 |
| 3741 | vidrio | 5 |
| 3742 | viciar | 5 |
| 3743 | vibrar | 5 |
| 3744 | vibrante | 5 |
| 3745 | vibración | 5 |
| 3746 | vestíbulo | 5 |
| 3747 | vericueto | 5 |
| 3748 | vencido | 5 |
| 3749 | veinticinco | 5 |
| 3750 | varonil | 5 |
| 3751 | valía | 5 |
| 3752 | vacante | 5 |
| 3753 | vaca | 5 |
| 3754 | utilizar | 5 |
| 3755 | tuyo | 5 |
| 3756 | túnica | 5 |
| 3757 | trucha | 5 |
| 3758 | trote | 5 |
| 3759 | tripa | 5 |
| 3760 | tradicional | 5 |
| 3761 | total | 5 |
| 3762 | tosco | 5 |
| 3763 | tomate | 5 |
| 3764 | tiranía | 5 |
| 3765 | tijera | 5 |
| 3766 | texto | 5 |
| 3767 | testamento | 5 |
| 3768 | terciar | 5 |
| 3769 | teológico | 5 |
| 3770 | tentar | 5 |
| 3771 | temporal | 5 |
| 3772 | templar | 5 |
| 3773 | tempestad | 5 |
| 3774 | temeroso | 5 |
| 3775 | temerario | 5 |
| 3776 | temblón | 5 |
| 3777 | telégrafo | 5 |
| 3778 | telaraña | 5 |
| 3779 | tejar | 5 |
| 3780 | tarima | 5 |
| 3781 | tapiz | 5 |
| 3782 | tapiar | 5 |
| 3783 | talle | 5 |
| 3784 | taco | 5 |
| 3785 | tácito | 5 |
| 3786 | ta | 5 |
| 3787 | súplica | 5 |
| 3788 | superstición | 5 |
| 3789 | superficie | 5 |
| 3790 | sumisión | 5 |
| 3791 | sucumbir | 5 |
| 3792 | suavizar | 5 |
| 3793 | soto | 5 |
| 3794 | sospechoso | 5 |
| 3795 | soporífero | 5 |
| 3796 | soñoliento | 5 |
| 3797 | sonrosado | 5 |
| 3798 | soldado | 5 |
| 3799 | socialista | 5 |
| 3800 | sinceridad | 5 |
| 3801 | sincerar | 5 |
| 3802 | simétrico | 5 |
| 3803 | simbólico | 5 |
| 3804 | sesgo | 5 |
| 3805 | señas | 5 |
| 3806 | seminarista | 5 |
| 3807 | semejar | 5 |
| 3808 | semejanza | 5 |
| 3809 | sembrar | 5 |
| 3810 | segunda | 5 |
| 3811 | santuario | 5 |
| 3812 | santianes | 5 |
| 3813 | salmón | 5 |
| 3814 | salido | 5 |
| 3815 | sacramentos | 5 |
| 3816 | ruego | 5 |
| 3817 | rúa | 5 |
| 3818 | rosado | 5 |
| 3819 | rondar | 5 |
| 3820 | ronca | 5 |
| 3821 | roblar | 5 |
| 3822 | ritmo | 5 |
| 3823 | rienda | 5 |
| 3824 | revoltoso | 5 |
| 3825 | reunión | 5 |
| 3826 | retoño | 5 |
| 3827 | responsable | 5 |
| 3828 | remover | 5 |
| 3829 | relato | 5 |
| 3830 | rejuvenecer | 5 |
| 3831 | reino | 5 |
| 3832 | registro | 5 |
| 3833 | regentar | 5 |
| 3834 | regazo | 5 |
| 3835 | regalo | 5 |
| 3836 | refugio | 5 |
| 3837 | refinar | 5 |
| 3838 | redacción | 5 |
| 3839 | rectoral | 5 |
| 3840 | rector | 5 |
| 3841 | rectificar | 5 |
| 3842 | recetar | 5 |
| 3843 | rebajar | 5 |
| 3844 | rara | 5 |
| 3845 | quiero | 5 |
| 3846 | puñalada | 5 |
| 3847 | puñal | 5 |
| 3848 | pulmón | 5 |
| 3849 | pudo | 5 |
| 3850 | próximamente | 5 |
| 3851 | provinciano | 5 |
| 3852 | protestante | 5 |
| 3853 | protector | 5 |
| 3854 | propinar | 5 |
| 3855 | problema | 5 |
| 3856 | privilegio | 5 |
| 3857 | prisionero | 5 |
| 3858 | princesa | 5 |
| 3859 | presupuesto | 5 |
| 3860 | prestado | 5 |
| 3861 | presidio | 5 |
| 3862 | presentimiento | 5 |
| 3863 | preparado | 5 |
| 3864 | premiar | 5 |
| 3865 | pregonar | 5 |
| 3866 | preciar | 5 |
| 3867 | práctico | 5 |
| 3868 | porción | 5 |
| 3869 | poética | 5 |
| 3870 | podrido | 5 |
| 3871 | pliego | 5 |
| 3872 | platear | 5 |
| 3873 | pizca | 5 |
| 3874 | pinche | 5 |
| 3875 | pillete | 5 |
| 3876 | pillastre | 5 |
| 3877 | perdición | 5 |
| 3878 | pensativo | 5 |
| 3879 | pensaba | 5 |
| 3880 | penoso | 5 |
| 3881 | penitenciar | 5 |
| 3882 | pavo | 5 |
| 3883 | pato | 5 |
| 3884 | patético | 5 |
| 3885 | patena | 5 |
| 3886 | patada | 5 |
| 3887 | pascua | 5 |
| 3888 | pasatiempo | 5 |
| 3889 | pasadizo | 5 |
| 3890 | pasada | 5 |
| 3891 | parroquiano | 5 |
| 3892 | parroquial | 5 |
| 3893 | parentesco | 5 |
| 3894 | panza | 5 |
| 3895 | panera | 5 |
| 3896 | palmatoria | 5 |
| 3897 | palmar | 5 |
| 3898 | ostensible | 5 |
| 3899 | orlar | 5 |
| 3900 | originar | 5 |
| 3901 | organista | 5 |
| 3902 | ordinariamente | 5 |
| 3903 | operación | 5 |
| 3904 | olla | 5 |
| 3905 | olías | 5 |
| 3906 | ochavo | 5 |
| 3907 | ocaso | 5 |
| 3908 | obsesión | 5 |
| 3909 | observador | 5 |
| 3910 | obdulita | 5 |
| 3911 | numeroso | 5 |
| 3912 | nudo | 5 |
| 3913 | nuca | 5 |
| 3914 | nogal | 5 |
| 3915 | negruzco | 5 |
| 3916 | negativo | 5 |
| 3917 | nauplia | 5 |
| 3918 | naturalista | 5 |
| 3919 | nacido | 5 |
| 3920 | murmurador | 5 |
| 3921 | murciélago | 5 |
| 3922 | muñeca | 5 |
| 3923 | multiplicar | 5 |
| 3924 | mujercita | 5 |
| 3925 | muestra | 5 |
| 3926 | monumento | 5 |
| 3927 | monstruo | 5 |
| 3928 | modesto | 5 |
| 3929 | miramiento | 5 |
| 3930 | miércoles | 5 |
| 3931 | metro | 5 |
| 3932 | meretriz | 5 |
| 3933 | mercader | 5 |
| 3934 | medrar | 5 |
| 3935 | mediodía | 5 |
| 3936 | matutino | 5 |
| 3937 | máscara | 5 |
| 3938 | mascar | 5 |
| 3939 | martillo | 5 |
| 3940 | marquetería | 5 |
| 3941 | mariposa | 5 |
| 3942 | marina | 5 |
| 3943 | manso | 5 |
| 3944 | mandil | 5 |
| 3945 | manantial | 5 |
| 3946 | majestad | 5 |
| 3947 | local | 5 |
| 3948 | llaga | 5 |
| 3949 | lista | 5 |
| 3950 | linajudo | 5 |
| 3951 | ligar | 5 |
| 3952 | lienzo | 5 |
| 3953 | lid | 5 |
| 3954 | licenciado | 5 |
| 3955 | levemente | 5 |
| 3956 | leopoldo | 5 |
| 3957 | leñador | 5 |
| 3958 | lentamente | 5 |
| 3959 | lechuguino | 5 |
| 3960 | latir | 5 |
| 3961 | látigo | 5 |
| 3962 | lateral | 5 |
| 3963 | lápiz | 5 |
| 3964 | lánguido | 5 |
| 3965 | languidez | 5 |
| 3966 | laico | 5 |
| 3967 | labor | 5 |
| 3968 | judío | 5 |
| 3969 | júbilo | 5 |
| 3970 | jergón | 5 |
| 3971 | jamona | 5 |
| 3972 | jactar | 5 |
| 3973 | izquierdo | 5 |
| 3974 | irreverente | 5 |
| 3975 | irónico | 5 |
| 3976 | introducir | 5 |
| 3977 | intervalo | 5 |
| 3978 | interrumpió | 5 |
| 3979 | intachable | 5 |
| 3980 | insinuante | 5 |
| 3981 | inmediato | 5 |
| 3982 | ingratitud | 5 |
| 3983 | inexpugnable | 5 |
| 3984 | inercia | 5 |
| 3985 | inconsciente | 5 |
| 3986 | implacable | 5 |
| 3987 | ilustrísima | 5 |
| 3988 | ii | 5 |
| 3989 | ignorante | 5 |
| 3990 | iconoclasta | 5 |
| 3991 | huracán | 5 |
| 3992 | huevo | 5 |
| 3993 | huerto | 5 |
| 3994 | hospital | 5 |
| 3995 | hortaliza | 5 |
| 3996 | hielo | 5 |
| 3997 | hermanar | 5 |
| 3998 | heno | 5 |
| 3999 | he | 5 |
| 4000 | hazaña | 5 |
| 4001 | habla | 5 |
| 4002 | habitual | 5 |
| 4003 | gusano | 5 |
| 4004 | groseramente | 5 |
| 4005 | gótico | 5 |
| 4006 | gorrión | 5 |
| 4007 | goce | 5 |
| 4008 | genuflexión | 5 |
| 4009 | generación | 5 |
| 4010 | garantía | 5 |
| 4011 | ganoso | 5 |
| 4012 | ganado | 5 |
| 4013 | ganadero | 5 |
| 4014 | gana | 5 |
| 4015 | gala | 5 |
| 4016 | gacetillero | 5 |
| 4017 | gacetilla | 5 |
| 4018 | fundamento | 5 |
| 4019 | fragua | 5 |
| 4020 | fragmento | 5 |
| 4021 | frágil | 5 |
| 4022 | forzoso | 5 |
| 4023 | fogón | 5 |
| 4024 | firmemente | 5 |
| 4025 | filosofar | 5 |
| 4026 | fibra | 5 |
| 4027 | fiambre | 5 |
| 4028 | feria | 5 |
| 4029 | fecha | 5 |
| 4030 | extranjero | 5 |
| 4031 | explotar | 5 |
| 4032 | experto | 5 |
| 4033 | expedición | 5 |
| 4034 | excusar | 5 |
| 4035 | excomulgar | 5 |
| 4036 | examinar | 5 |
| 4037 | exactitud | 5 |
| 4038 | evocar | 5 |
| 4039 | evidenciar | 5 |
| 4040 | eufemismo | 5 |
| 4041 | estuco | 5 |
| 4042 | estrujar | 5 |
| 4043 | estrechez | 5 |
| 4044 | estatura | 5 |
| 4045 | estanquillo | 5 |
| 4046 | estallido | 5 |
| 4047 | espuma | 5 |
| 4048 | esperanzar | 5 |
| 4049 | esclavitud | 5 |
| 4050 | escaparate | 5 |
| 4051 | escalar | 5 |
| 4052 | escala | 5 |
| 4053 | entrecejo | 5 |
| 4054 | entornar | 5 |
| 4055 | ennegrecer | 5 |
| 4056 | enjugar | 5 |
| 4057 | enganchar | 5 |
| 4058 | empecatado | 5 |
| 4059 | empapar | 5 |
| 4060 | emma | 5 |
| 4061 | embargar | 5 |
| 4062 | electoral | 5 |
| 4063 | ejército | 5 |
| 4064 | egipcio | 5 |
| 4065 | efectivamente | 5 |
| 4066 | dulcemente | 5 |
| 4067 | dolorosa | 5 |
| 4068 | documento | 5 |
| 4069 | doctrinar | 5 |
| 4070 | dócil | 5 |
| 4071 | diversión | 5 |
| 4072 | displicente | 5 |
| 4073 | disparatado | 5 |
| 4074 | disolvente | 5 |
| 4075 | disimuladamente | 5 |
| 4076 | disculpa | 5 |
| 4077 | directo | 5 |
| 4078 | directamente | 5 |
| 4079 | digestión | 5 |
| 4080 | dificultar | 5 |
| 4081 | dictador | 5 |
| 4082 | diablura | 5 |
| 4083 | devocionario | 5 |
| 4084 | desplomar | 5 |
| 4085 | despertador | 5 |
| 4086 | despellejar | 5 |
| 4087 | desnudez | 5 |
| 4088 | deslumbrante | 5 |
| 4089 | desgarrar | 5 |
| 4090 | derretir | 5 |
| 4091 | depender | 5 |
| 4092 | demasía | 5 |
| 4093 | decoro | 5 |
| 4094 | debido | 5 |
| 4095 | curso | 5 |
| 4096 | curioso | 5 |
| 4097 | cumplido | 5 |
| 4098 | culpable | 5 |
| 4099 | cuerno | 5 |
| 4100 | cuclillas | 5 |
| 4101 | cuchichear | 5 |
| 4102 | cubierto | 5 |
| 4103 | cuartel | 5 |
| 4104 | cuántas | 5 |
| 4105 | crucificar | 5 |
| 4106 | creyente | 5 |
| 4107 | cree | 5 |
| 4108 | crédito | 5 |
| 4109 | correligionario | 5 |
| 4110 | copia | 5 |
| 4111 | convite | 5 |
| 4112 | contradicción | 5 |
| 4113 | contigo | 5 |
| 4114 | consumir | 5 |
| 4115 | conspirar | 5 |
| 4116 | conjurar | 5 |
| 4117 | confirmar | 5 |
| 4118 | condicional | 5 |
| 4119 | concurso | 5 |
| 4120 | concurrir | 5 |
| 4121 | concilio | 5 |
| 4122 | concienciar | 5 |
| 4123 | concepción | 5 |
| 4124 | conato | 5 |
| 4125 | comprimir | 5 |
| 4126 | complicación | 5 |
| 4127 | complacencia | 5 |
| 4128 | compensar | 5 |
| 4129 | comerciar | 5 |
| 4130 | colectivo | 5 |
| 4131 | colás | 5 |
| 4132 | cohete | 5 |
| 4133 | circular | 5 |
| 4134 | circo | 5 |
| 4135 | cinta | 5 |
| 4136 | cínico | 5 |
| 4137 | ciertamente | 5 |
| 4138 | científico | 5 |
| 4139 | chocho | 5 |
| 4140 | chaparrón | 5 |
| 4141 | cháchara | 5 |
| 4142 | cesta | 5 |
| 4143 | cerdo | 5 |
| 4144 | cerco | 5 |
| 4145 | cercano | 5 |
| 4146 | censura | 5 |
| 4147 | ceniciento | 5 |
| 4148 | cenceño | 5 |
| 4149 | ceguera | 5 |
| 4150 | cautela | 5 |
| 4151 | cátedra | 5 |
| 4152 | catalán | 5 |
| 4153 | castellano | 5 |
| 4154 | casco | 5 |
| 4155 | carmesí | 5 |
| 4156 | careta | 5 |
| 4157 | cardenal | 5 |
| 4158 | caracol | 5 |
| 4159 | canario | 5 |
| 4160 | campiña | 5 |
| 4161 | calzado | 5 |
| 4162 | cálculo | 5 |
| 4163 | calcular | 5 |
| 4164 | caballeresco | 5 |
| 4165 | burlesco | 5 |
| 4166 | burdeos | 5 |
| 4167 | bruces | 5 |
| 4168 | brindar | 5 |
| 4169 | brincar | 5 |
| 4170 | brillo | 5 |
| 4171 | boulevard | 5 |
| 4172 | botella | 5 |
| 4173 | botánico | 5 |
| 4174 | borrachera | 5 |
| 4175 | bobalicón | 5 |
| 4176 | bilis | 5 |
| 4177 | biblia | 5 |
| 4178 | besugo | 5 |
| 4179 | bestia | 5 |
| 4180 | belén | 5 |
| 4181 | bayeta | 5 |
| 4182 | basilio | 5 |
| 4183 | barro | 5 |
| 4184 | barra | 5 |
| 4185 | barcaza | 5 |
| 4186 | banquete | 5 |
| 4187 | balmes | 5 |
| 4188 | balar | 5 |
| 4189 | azar | 5 |
| 4190 | aviso | 5 |
| 4191 | avanzado | 5 |
| 4192 | autorizar | 5 |
| 4193 | atrevido | 5 |
| 4194 | atrasado | 5 |
| 4195 | astro | 5 |
| 4196 | aspiración | 5 |
| 4197 | asís | 5 |
| 4198 | asediar | 5 |
| 4199 | asalto | 5 |
| 4200 | ardor | 5 |
| 4201 | araña | 5 |
| 4202 | aprobación | 5 |
| 4203 | aprensivo | 5 |
| 4204 | apostar | 5 |
| 4205 | aplauso | 5 |
| 4206 | apiñar | 5 |
| 4207 | apetecible | 5 |
| 4208 | anunciación | 5 |
| 4209 | anticipar | 5 |
| 4210 | anteojo | 5 |
| 4211 | antaño | 5 |
| 4212 | ansiar | 5 |
| 4213 | anónimo | 5 |
| 4214 | anochecer | 5 |
| 4215 | anoche | 5 |
| 4216 | anís | 5 |
| 4217 | anhelar | 5 |
| 4218 | anguloso | 5 |
| 4219 | ampuloso | 5 |
| 4220 | amparar | 5 |
| 4221 | ameno | 5 |
| 4222 | amargo | 5 |
| 4223 | amanerado | 5 |
| 4224 | amado | 5 |
| 4225 | alusivo | 5 |
| 4226 | alias | 5 |
| 4227 | alargar | 5 |
| 4228 | alambicar | 5 |
| 4229 | águila | 5 |
| 4230 | agolpar | 5 |
| 4231 | adversario | 5 |
| 4232 | adoración | 5 |
| 4233 | adónde | 5 |
| 4234 | adolescente | 5 |
| 4235 | admirable | 5 |
| 4236 | acostumbrado | 5 |
| 4237 | aclarar | 5 |
| 4238 | acceder | 5 |
| 4239 | académico | 5 |
| 4240 | acacia | 5 |
| 4241 | abundar | 5 |
| 4242 | abuelo | 5 |
| 4243 | absolución | 5 |
| 4244 | abismar | 5 |
| 4245 | aberración | 5 |
| 4246 | vocinglero | 4 |
| 4247 | viva | 4 |
| 4248 | viudedad | 4 |
| 4249 | violento | 4 |
| 4250 | viene | 4 |
| 4251 | verosimilitud | 4 |
| 4252 | verosímil | 4 |
| 4253 | venus | 4 |
| 4254 | ventura | 4 |
| 4255 | ventanilla | 4 |
| 4256 | venga | 4 |
| 4257 | veintisiete | 4 |
| 4258 | vecindad | 4 |
| 4259 | valla | 4 |
| 4260 | vale | 4 |
| 4261 | vacación | 4 |
| 4262 | usía | 4 |
| 4263 | uña | 4 |
| 4264 | universidad | 4 |
| 4265 | uniforme | 4 |
| 4266 | únicamente | 4 |
| 4267 | ultraje | 4 |
| 4268 | últimamente | 4 |
| 4269 | turno | 4 |
| 4270 | turgencia | 4 |
| 4271 | tubo | 4 |
| 4272 | tropezón | 4 |
| 4273 | tronado | 4 |
| 4274 | trompeta | 4 |
| 4275 | tributo | 4 |
| 4276 | trechos | 4 |
| 4277 | trasto | 4 |
| 4278 | trabajador | 4 |
| 4279 | tos | 4 |
| 4280 | toro | 4 |
| 4281 | torcido | 4 |
| 4282 | tomillo | 4 |
| 4283 | tolerable | 4 |
| 4284 | toga | 4 |
| 4285 | tisis | 4 |
| 4286 | timorato | 4 |
| 4287 | timidez | 4 |
| 4288 | tímidamente | 4 |
| 4289 | tieso | 4 |
| 4290 | tibieza | 4 |
| 4291 | tibiar | 4 |
| 4292 | terrón | 4 |
| 4293 | territorial | 4 |
| 4294 | terminante | 4 |
| 4295 | tercer | 4 |
| 4296 | tentativa | 4 |
| 4297 | tenor | 4 |
| 4298 | tendido | 4 |
| 4299 | tenaza | 4 |
| 4300 | tenacidad | 4 |
| 4301 | tedio | 4 |
| 4302 | tarsila | 4 |
| 4303 | tambalear | 4 |
| 4304 | tamaña | 4 |
| 4305 | talón | 4 |
| 4306 | taburete | 4 |
| 4307 | tablado | 4 |
| 4308 | tabique | 4 |
| 4309 | tabaco | 4 |
| 4310 | sustituto | 4 |
| 4311 | suplir | 4 |
| 4312 | supino | 4 |
| 4313 | sueños | 4 |
| 4314 | suela | 4 |
| 4315 | sucesor | 4 |
| 4316 | sucesión | 4 |
| 4317 | sótano | 4 |
| 4318 | soportal | 4 |
| 4319 | sollozar | 4 |
| 4320 | solicitud | 4 |
| 4321 | sócrates | 4 |
| 4322 | sobrecoger | 4 |
| 4323 | soberano | 4 |
| 4324 | sobado | 4 |
| 4325 | sinuoso | 4 |
| 4326 | siniestro | 4 |
| 4327 | singularmente | 4 |
| 4328 | simonía | 4 |
| 4329 | significativo | 4 |
| 4330 | sietemesino | 4 |
| 4331 | sepultura | 4 |
| 4332 | señorío | 4 |
| 4333 | sentimentalismo | 4 |
| 4334 | sentada | 4 |
| 4335 | sensual | 4 |
| 4336 | sencillez | 4 |
| 4337 | secularizar | 4 |
| 4338 | sebo | 4 |
| 4339 | santísima | 4 |
| 4340 | salvador | 4 |
| 4341 | salpicar | 4 |
| 4342 | salga | 4 |
| 4343 | sagaz | 4 |
| 4344 | sacudida | 4 |
| 4345 | sabiamente | 4 |
| 4346 | rutinario | 4 |
| 4347 | rústico | 4 |
| 4348 | rural | 4 |
| 4349 | rumiar | 4 |
| 4350 | rugió | 4 |
| 4351 | romano | 4 |
| 4352 | rollizo | 4 |
| 4353 | rodeo | 4 |
| 4354 | rizado | 4 |
| 4355 | riesgo | 4 |
| 4356 | retozón | 4 |
| 4357 | retorcido | 4 |
| 4358 | retirado | 4 |
| 4359 | retablo | 4 |
| 4360 | restauración | 4 |
| 4361 | respetuoso | 4 |
| 4362 | resonante | 4 |
| 4363 | resbaladizo | 4 |
| 4364 | republicano | 4 |
| 4365 | representación | 4 |
| 4366 | reprensión | 4 |
| 4367 | reposo | 4 |
| 4368 | reponer | 4 |
| 4369 | replicar | 4 |
| 4370 | reparto | 4 |
| 4371 | reparación | 4 |
| 4372 | reliquia | 4 |
| 4373 | registrar | 4 |
| 4374 | regir | 4 |
| 4375 | refugiar | 4 |
| 4376 | refuerzo | 4 |
| 4377 | refresco | 4 |
| 4378 | recortar | 4 |
| 4379 | recóndito | 4 |
| 4380 | recio | 4 |
| 4381 | raya | 4 |
| 4382 | ratón | 4 |
| 4383 | ras | 4 |
| 4384 | ramos | 4 |
| 4385 | raíces | 4 |
| 4386 | radical | 4 |
| 4387 | racimo | 4 |
| 4388 | rabillo | 4 |
| 4389 | quizás | 4 |
| 4390 | quintilla | 4 |
| 4391 | quehacer | 4 |
| 4392 | quebrantar | 4 |
| 4393 | quebradero | 4 |
| 4394 | púrpura | 4 |
| 4395 | purísimo | 4 |
| 4396 | puñada | 4 |
| 4397 | pulquérrimo | 4 |
| 4398 | pulmonía | 4 |
| 4399 | puente | 4 |
| 4400 | puchero | 4 |
| 4401 | psicológico | 4 |
| 4402 | psicología | 4 |
| 4403 | prurito | 4 |
| 4404 | provisión | 4 |
| 4405 | protección | 4 |
| 4406 | propalar | 4 |
| 4407 | producto | 4 |
| 4408 | pródigo | 4 |
| 4409 | procurador | 4 |
| 4410 | probabilidad | 4 |
| 4411 | primitivo | 4 |
| 4412 | presbítero | 4 |
| 4413 | preparación | 4 |
| 4414 | preocupado | 4 |
| 4415 | prematuro | 4 |
| 4416 | preferencia | 4 |
| 4417 | predilección | 4 |
| 4418 | postizo | 4 |
| 4419 | posesión | 4 |
| 4420 | portento | 4 |
| 4421 | pontífice | 4 |
| 4422 | pongo | 4 |
| 4423 | podrir | 4 |
| 4424 | podía | 4 |
| 4425 | podar | 4 |
| 4426 | pocilga | 4 |
| 4427 | plomizo | 4 |
| 4428 | pleito | 4 |
| 4429 | plegar | 4 |
| 4430 | plebe | 4 |
| 4431 | pitillo | 4 |
| 4432 | pipa | 4 |
| 4433 | pintoresco | 4 |
| 4434 | pillo | 4 |
| 4435 | piar | 4 |
| 4436 | personar | 4 |
| 4437 | permanente | 4 |
| 4438 | perjudicar | 4 |
| 4439 | perilla | 4 |
| 4440 | peral | 4 |
| 4441 | pellizcar | 4 |
| 4442 | pellejo | 4 |
| 4443 | peculiar | 4 |
| 4444 | pausar | 4 |
| 4445 | pausadamente | 4 |
| 4446 | pátina | 4 |
| 4447 | patata | 4 |
| 4448 | patadas | 4 |
| 4449 | pata | 4 |
| 4450 | pasmo | 4 |
| 4451 | parterre | 4 |
| 4452 | parcerisa | 4 |
| 4453 | parábola | 4 |
| 4454 | panteísmo | 4 |
| 4455 | panorama | 4 |
| 4456 | pana | 4 |
| 4457 | palpar | 4 |
| 4458 | pajarera | 4 |
| 4459 | pacto | 4 |
| 4460 | pábulo | 4 |
| 4461 | otra | 4 |
| 4462 | ortodoxo | 4 |
| 4463 | orquesta | 4 |
| 4464 | orillas | 4 |
| 4465 | optimismo | 4 |
| 4466 | occidente | 4 |
| 4467 | obsequio | 4 |
| 4468 | objetar | 4 |
| 4469 | objeción | 4 |
| 4470 | nuestra | 4 |
| 4471 | nublado | 4 |
| 4472 | noviembre | 4 |
| 4473 | novicio | 4 |
| 4474 | nostalgia | 4 |
| 4475 | noroeste | 4 |
| 4476 | noé | 4 |
| 4477 | niñería | 4 |
| 4478 | negación | 4 |
| 4479 | navidad | 4 |
| 4480 | navegar | 4 |
| 4481 | naturalidad | 4 |
| 4482 | narrar | 4 |
| 4483 | napoleón | 4 |
| 4484 | nácar | 4 |
| 4485 | mutuo | 4 |
| 4486 | mustio | 4 |
| 4487 | municipio | 4 |
| 4488 | mundanal | 4 |
| 4489 | mula | 4 |
| 4490 | muda | 4 |
| 4491 | mostrador | 4 |
| 4492 | mosquito | 4 |
| 4493 | monumental | 4 |
| 4494 | montaraz | 4 |
| 4495 | monosílabo | 4 |
| 4496 | mondar | 4 |
| 4497 | molinero | 4 |
| 4498 | modificar | 4 |
| 4499 | moderar | 4 |
| 4500 | modelar | 4 |
| 4501 | mitra | 4 |
| 4502 | minero | 4 |
| 4503 | mimar | 4 |
| 4504 | mia | 4 |
| 4505 | mezquino | 4 |
| 4506 | metafísica | 4 |
| 4507 | meseta | 4 |
| 4508 | mental | 4 |
| 4509 | mensual | 4 |
| 4510 | menester | 4 |
| 4511 | menear | 4 |
| 4512 | meloso | 4 |
| 4513 | medicinar | 4 |
| 4514 | mecánica | 4 |
| 4515 | maza | 4 |
| 4516 | maternal | 4 |
| 4517 | masculino | 4 |
| 4518 | marzo | 4 |
| 4519 | marcial | 4 |
| 4520 | maravillar | 4 |
| 4521 | marasmo | 4 |
| 4522 | manto | 4 |
| 4523 | manta | 4 |
| 4524 | mandilón | 4 |
| 4525 | mandato | 4 |
| 4526 | mancha | 4 |
| 4527 | malva | 4 |
| 4528 | maltratar | 4 |
| 4529 | malsano | 4 |
| 4530 | maldición | 4 |
| 4531 | maldiciente | 4 |
| 4532 | magnate | 4 |
| 4533 | madrugador | 4 |
| 4534 | madero | 4 |
| 4535 | lúgubre | 4 |
| 4536 | luciente | 4 |
| 4537 | llegó | 4 |
| 4538 | llano | 4 |
| 4539 | llamarada | 4 |
| 4540 | lisonjero | 4 |
| 4541 | linterna | 4 |
| 4542 | ligeramente | 4 |
| 4543 | libremente | 4 |
| 4544 | liberalismo | 4 |
| 4545 | leña | 4 |
| 4546 | lego | 4 |
| 4547 | legítimo | 4 |
| 4548 | lechar | 4 |
| 4549 | latino | 4 |
| 4550 | larva | 4 |
| 4551 | jubilado | 4 |
| 4552 | jesuitas | 4 |
| 4553 | jerarquía | 4 |
| 4554 | jadeante | 4 |
| 4555 | irrespetuoso | 4 |
| 4556 | irracional | 4 |
| 4557 | iriarte | 4 |
| 4558 | intersticio | 4 |
| 4559 | insípido | 4 |
| 4560 | inquisidor | 4 |
| 4561 | inoportuno | 4 |
| 4562 | inmundo | 4 |
| 4563 | inminente | 4 |
| 4564 | iniciar | 4 |
| 4565 | ingenuo | 4 |
| 4566 | ingeniero | 4 |
| 4567 | infundir | 4 |
| 4568 | influyente | 4 |
| 4569 | influjo | 4 |
| 4570 | inflar | 4 |
| 4571 | infamia | 4 |
| 4572 | indumentaria | 4 |
| 4573 | indiscreción | 4 |
| 4574 | índice | 4 |
| 4575 | incurable | 4 |
| 4576 | incrustar | 4 |
| 4577 | incluso | 4 |
| 4578 | incertidumbre | 4 |
| 4579 | incensar | 4 |
| 4580 | inaugurar | 4 |
| 4581 | inagotable | 4 |
| 4582 | impuro | 4 |
| 4583 | impulsar | 4 |
| 4584 | impresionar | 4 |
| 4585 | imposición | 4 |
| 4586 | ímpetu | 4 |
| 4587 | ilegítimo | 4 |
| 4588 | idealista | 4 |
| 4589 | huella | 4 |
| 4590 | homenaje | 4 |
| 4591 | hoguera | 4 |
| 4592 | hinchar | 4 |
| 4593 | hilar | 4 |
| 4594 | hierático | 4 |
| 4595 | herrar | 4 |
| 4596 | hacha | 4 |
| 4597 | hace | 4 |
| 4598 | hablilla | 4 |
| 4599 | habana | 4 |
| 4600 | guisar | 4 |
| 4601 | gruñido | 4 |
| 4602 | gregorio | 4 |
| 4603 | granate | 4 |
| 4604 | gozoso | 4 |
| 4605 | gorra | 4 |
| 4606 | golpecito | 4 |
| 4607 | girar | 4 |
| 4608 | gimnasia | 4 |
| 4609 | gemelo | 4 |
| 4610 | gata | 4 |
| 4611 | gasto | 4 |
| 4612 | gastado | 4 |
| 4613 | garra | 4 |
| 4614 | fundador | 4 |
| 4615 | funciones | 4 |
| 4616 | fruta | 4 |
| 4617 | francisca | 4 |
| 4618 | francia | 4 |
| 4619 | flexible | 4 |
| 4620 | flauta | 4 |
| 4621 | fisiológico | 4 |
| 4622 | finura | 4 |
| 4623 | final | 4 |
| 4624 | filtrar | 4 |
| 4625 | filial | 4 |
| 4626 | figurín | 4 |
| 4627 | femenino | 4 |
| 4628 | femenil | 4 |
| 4629 | felicitar | 4 |
| 4630 | favorable | 4 |
| 4631 | fatalidad | 4 |
| 4632 | fascinar | 4 |
| 4633 | falsedad | 4 |
| 4634 | factor | 4 |
| 4635 | extremar | 4 |
| 4636 | extraviado | 4 |
| 4637 | extinguir | 4 |
| 4638 | externo | 4 |
| 4639 | éxito | 4 |
| 4640 | excepcional | 4 |
| 4641 | excelentísimo | 4 |
| 4642 | evangélico | 4 |
| 4643 | eternidad | 4 |
| 4644 | estupefacto | 4 |
| 4645 | estufa | 4 |
| 4646 | estímulo | 4 |
| 4647 | estameña | 4 |
| 4648 | esponja | 4 |
| 4649 | esplendoroso | 4 |
| 4650 | espléndido | 4 |
| 4651 | espantado | 4 |
| 4652 | esfera | 4 |
| 4653 | esencial | 4 |
| 4654 | escrupuloso | 4 |
| 4655 | escarabajo | 4 |
| 4656 | equivocación | 4 |
| 4657 | epigrama | 4 |
| 4658 | enseñorear | 4 |
| 4659 | ensanchar | 4 |
| 4660 | enramada | 4 |
| 4661 | enojo | 4 |
| 4662 | engendrar | 4 |
| 4663 | énfasis | 4 |
| 4664 | encomendar | 4 |
| 4665 | encimar | 4 |
| 4666 | encierro | 4 |
| 4667 | encerrona | 4 |
| 4668 | encaje | 4 |
| 4669 | empleo | 4 |
| 4670 | embutir | 4 |
| 4671 | embriaguez | 4 |
| 4672 | embriagar | 4 |
| 4673 | embarazoso | 4 |
| 4674 | emanación | 4 |
| 4675 | elogiar | 4 |
| 4676 | elegir | 4 |
| 4677 | eclipsar | 4 |
| 4678 | duradero | 4 |
| 4679 | dormitar | 4 |
| 4680 | doctrina | 4 |
| 4681 | doctora | 4 |
| 4682 | doble | 4 |
| 4683 | distingo | 4 |
| 4684 | disminuir | 4 |
| 4685 | dimisión | 4 |
| 4686 | diluvio | 4 |
| 4687 | diligenciar | 4 |
| 4688 | diligencia | 4 |
| 4689 | digo | 4 |
| 4690 | dignísimo | 4 |
| 4691 | diario | 4 |
| 4692 | devaneo | 4 |
| 4693 | determinado | 4 |
| 4694 | desvencijado | 4 |
| 4695 | despojo | 4 |
| 4696 | despejar | 4 |
| 4697 | despedida | 4 |
| 4698 | despecho | 4 |
| 4699 | deslizar | 4 |
| 4700 | desigualdad | 4 |
| 4701 | desigual | 4 |
| 4702 | desfallecimiento | 4 |
| 4703 | desfallecer | 4 |
| 4704 | desempeñar | 4 |
| 4705 | descuidado | 4 |
| 4706 | descripción | 4 |
| 4707 | descrédito | 4 |
| 4708 | desconsuelo | 4 |
| 4709 | descendiente | 4 |
| 4710 | desatar | 4 |
| 4711 | desaliento | 4 |
| 4712 | derramar | 4 |
| 4713 | degradar | 4 |
| 4714 | degradación | 4 |
| 4715 | definir | 4 |
| 4716 | decoración | 4 |
| 4717 | declamar | 4 |
| 4718 | decisivo | 4 |
| 4719 | debo | 4 |
| 4720 | danza | 4 |
| 4721 | culebra | 4 |
| 4722 | cuestas | 4 |
| 4723 | cuántos | 4 |
| 4724 | cruzado | 4 |
| 4725 | cruzada | 4 |
| 4726 | crudo | 4 |
| 4727 | crucificado | 4 |
| 4728 | cristianismo | 4 |
| 4729 | crispar | 4 |
| 4730 | cresta | 4 |
| 4731 | cráneo | 4 |
| 4732 | cosas | 4 |
| 4733 | corujedo | 4 |
| 4734 | cortesano | 4 |
| 4735 | corrupción | 4 |
| 4736 | corrosivo | 4 |
| 4737 | corromper | 4 |
| 4738 | correspondiente | 4 |
| 4739 | cordón | 4 |
| 4740 | convencional | 4 |
| 4741 | controversia | 4 |
| 4742 | contratiempo | 4 |
| 4743 | contrarrestar | 4 |
| 4744 | contrariedad | 4 |
| 4745 | contradictorio | 4 |
| 4746 | contemporáneo | 4 |
| 4747 | consunción | 4 |
| 4748 | conspirador | 4 |
| 4749 | considerable | 4 |
| 4750 | conquistador | 4 |
| 4751 | conforme | 4 |
| 4752 | conflicto | 4 |
| 4753 | confitería | 4 |
| 4754 | confidencial | 4 |
| 4755 | conde | 4 |
| 4756 | conciudadano | 4 |
| 4757 | conciliábulo | 4 |
| 4758 | comunión | 4 |
| 4759 | composición | 4 |
| 4760 | complot | 4 |
| 4761 | compatible | 4 |
| 4762 | comendador | 4 |
| 4763 | comedir | 4 |
| 4764 | combinar | 4 |
| 4765 | colono | 4 |
| 4766 | colegio | 4 |
| 4767 | codicia | 4 |
| 4768 | cobre | 4 |
| 4769 | clerical | 4 |
| 4770 | clara | 4 |
| 4771 | ciudadano | 4 |
| 4772 | cilicio | 4 |
| 4773 | cieno | 4 |
| 4774 | chubasco | 4 |
| 4775 | chorizo | 4 |
| 4776 | charlar | 4 |
| 4777 | charada | 4 |
| 4778 | césped | 4 |
| 4779 | cerveza | 4 |
| 4780 | ceremonioso | 4 |
| 4781 | cepillar | 4 |
| 4782 | censurar | 4 |
| 4783 | caviloso | 4 |
| 4784 | catedrático | 4 |
| 4785 | casilla | 4 |
| 4786 | casera | 4 |
| 4787 | cascada | 4 |
| 4788 | casadero | 4 |
| 4789 | cartón | 4 |
| 4790 | carmen | 4 |
| 4791 | carbonero | 4 |
| 4792 | capellanía | 4 |
| 4793 | cantero | 4 |
| 4794 | candoroso | 4 |
| 4795 | calvo | 4 |
| 4796 | calavera | 4 |
| 4797 | calar | 4 |
| 4798 | calabaza | 4 |
| 4799 | cabizbajo | 4 |
| 4800 | busto | 4 |
| 4801 | burlón | 4 |
| 4802 | brasero | 4 |
| 4803 | brasar | 4 |
| 4804 | borla | 4 |
| 4805 | bordada | 4 |
| 4806 | boquirroto | 4 |
| 4807 | bondadoso | 4 |
| 4808 | boj | 4 |
| 4809 | bendecir | 4 |
| 4810 | beltrand | 4 |
| 4811 | baúl | 4 |
| 4812 | barniz | 4 |
| 4813 | barítono | 4 |
| 4814 | bandada | 4 |
| 4815 | bancarrota | 4 |
| 4816 | balde | 4 |
| 4817 | babilonia | 4 |
| 4818 | azafrán | 4 |
| 4819 | ayuno | 4 |
| 4820 | avergonzado | 4 |
| 4821 | aurora | 4 |
| 4822 | audaz | 4 |
| 4823 | atleta | 4 |
| 4824 | aterrar | 4 |
| 4825 | atento | 4 |
| 4826 | asaltar | 4 |
| 4827 | artillería | 4 |
| 4828 | artefacto | 4 |
| 4829 | arrullo | 4 |
| 4830 | arrullar | 4 |
| 4831 | arrepentimiento | 4 |
| 4832 | arrebatar | 4 |
| 4833 | arraigar | 4 |
| 4834 | arraigado | 4 |
| 4835 | arqueología | 4 |
| 4836 | arcángel | 4 |
| 4837 | aquellas | 4 |
| 4838 | apostólico | 4 |
| 4839 | apetitoso | 4 |
| 4840 | apacible | 4 |
| 4841 | antojo | 4 |
| 4842 | antero | 4 |
| 4843 | animación | 4 |
| 4844 | angosto | 4 |
| 4845 | andaluz | 4 |
| 4846 | análisis | 4 |
| 4847 | anales | 4 |
| 4848 | ambicionar | 4 |
| 4849 | amapola | 4 |
| 4850 | alterar | 4 |
| 4851 | altanero | 4 |
| 4852 | alpaca | 4 |
| 4853 | almohadón | 4 |
| 4854 | alegoría | 4 |
| 4855 | albañil | 4 |
| 4856 | alarmante | 4 |
| 4857 | ajo | 4 |
| 4858 | aislar | 4 |
| 4859 | airar | 4 |
| 4860 | ahumado | 4 |
| 4861 | ahorro | 4 |
| 4862 | agrio | 4 |
| 4863 | agregar | 4 |
| 4864 | aflojar | 4 |
| 4865 | afecto | 4 |
| 4866 | afectación | 4 |
| 4867 | adular | 4 |
| 4868 | adolescencia | 4 |
| 4869 | adentrar | 4 |
| 4870 | actor | 4 |
| 4871 | acompañamiento | 4 |
| 4872 | acierto | 4 |
| 4873 | aceite | 4 |
| 4874 | acecho | 4 |
| 4875 | acalorar | 4 |
| 4876 | abominable | 4 |
| 4877 | abalorio | 4 |
| 4878 | zángano | 3 |
| 4879 | xiv | 3 |
| 4880 | wamba | 3 |
| 4881 | voy | 3 |
| 4882 | viudez | 3 |
| 4883 | vistoso | 3 |
| 4884 | vislumbrar | 3 |
| 4885 | visible | 3 |
| 4886 | viril | 3 |
| 4887 | villanía | 3 |
| 4888 | vicisitud | 3 |
| 4889 | vicioso | 3 |
| 4890 | viajar | 3 |
| 4891 | vestigio | 3 |
| 4892 | vertical | 3 |
| 4893 | verter | 3 |
| 4894 | verdugo | 3 |
| 4895 | verdor | 3 |
| 4896 | veranear | 3 |
| 4897 | ventilar | 3 |
| 4898 | veleidad | 3 |
| 4899 | velador | 3 |
| 4900 | vejiga | 3 |
| 4901 | vejar | 3 |
| 4902 | veinticuatro | 3 |
| 4903 | ve | 3 |
| 4904 | varilla | 3 |
| 4905 | vaporoso | 3 |
| 4906 | vaciar | 3 |
| 4907 | utilitario | 3 |
| 4908 | urna | 3 |
| 4909 | uñir | 3 |
| 4910 | unión | 3 |
| 4911 | unidad | 3 |
| 4912 | unanimidad | 3 |
| 4913 | unánime | 3 |
| 4914 | última | 3 |
| 4915 | u | 3 |
| 4916 | turnar | 3 |
| 4917 | turba | 3 |
| 4918 | tunante | 3 |
| 4919 | trovador | 3 |
| 4920 | tristón | 3 |
| 4921 | trigo | 3 |
| 4922 | tregua | 3 |
| 4923 | trece | 3 |
| 4924 | travesaño | 3 |
| 4925 | traspasar | 3 |
| 4926 | trasnochar | 3 |
| 4927 | transparentar | 3 |
| 4928 | transformación | 3 |
| 4929 | transacción | 3 |
| 4930 | tramar | 3 |
| 4931 | trago | 3 |
| 4932 | tragedia | 3 |
| 4933 | tráfico | 3 |
| 4934 | traducir | 3 |
| 4935 | tostado | 3 |
| 4936 | tortuoso | 3 |
| 4937 | tortuga | 3 |
| 4938 | torrente | 3 |
| 4939 | torno | 3 |
| 4940 | tornillo | 3 |
| 4941 | tornasol | 3 |
| 4942 | torero | 3 |
| 4943 | toma | 3 |
| 4944 | toledo | 3 |
| 4945 | todd | 3 |
| 4946 | tocante | 3 |
| 4947 | titular | 3 |
| 4948 | tirso | 3 |
| 4949 | tiesto | 3 |
| 4950 | tibia | 3 |
| 4951 | testimonio | 3 |
| 4952 | testero | 3 |
| 4953 | tesón | 3 |
| 4954 | terremoto | 3 |
| 4955 | termasaltas | 3 |
| 4956 | teórico | 3 |
| 4957 | tensión | 3 |
| 4958 | tendero | 3 |
| 4959 | telar | 3 |
| 4960 | tardío | 3 |
| 4961 | tapaboca | 3 |
| 4962 | tañer | 3 |
| 4963 | tajar | 3 |
| 4964 | tacón | 3 |
| 4965 | tablero | 3 |
| 4966 | tabernero | 3 |
| 4967 | susurro | 3 |
| 4968 | surgir | 3 |
| 4969 | suprimir | 3 |
| 4970 | suplicante | 3 |
| 4971 | supersticiosamente | 3 |
| 4972 | suicidio | 3 |
| 4973 | sugestión | 3 |
| 4974 | sueldo | 3 |
| 4975 | subrayar | 3 |
| 4976 | sonido | 3 |
| 4977 | sondear | 3 |
| 4978 | sonámbulo | 3 |
| 4979 | solidez | 3 |
| 4980 | solicitante | 3 |
| 4981 | soldar | 3 |
| 4982 | sojuzgar | 3 |
| 4983 | socorro | 3 |
| 4984 | sobriedad | 3 |
| 4985 | situar | 3 |
| 4986 | sinodal | 3 |
| 4987 | simulacro | 3 |
| 4988 | sílaba | 3 |
| 4989 | signo | 3 |
| 4990 | sidra | 3 |
| 4991 | sevilla | 3 |
| 4992 | setenta | 3 |
| 4993 | serpear | 3 |
| 4994 | serenidad | 3 |
| 4995 | seráfico | 3 |
| 4996 | sepultar | 3 |
| 4997 | sepulcro | 3 |
| 4998 | separación | 3 |
| 4999 | sentenciar | 3 |
| 5000 | sentencia | 3 |
| 5001 | sensible | 3 |
| 5002 | senda | 3 |
| 5003 | seguía | 3 |
| 5004 | segismundo | 3 |
| 5005 | segar | 3 |
| 5006 | sectario | 3 |
| 5007 | saya | 3 |
| 5008 | savia | 3 |
| 5009 | sardina | 3 |
| 5010 | sandez | 3 |
| 5011 | saliva | 3 |
| 5012 | sagacidad | 3 |
| 5013 | sacristán | 3 |
| 5014 | sacerdocio | 3 |
| 5015 | sábado | 3 |
| 5016 | rusia | 3 |
| 5017 | ruiseñor | 3 |
| 5018 | ruinoso | 3 |
| 5019 | rugir | 3 |
| 5020 | roto | 3 |
| 5021 | rosina | 3 |
| 5022 | rosetón | 3 |
| 5023 | roque | 3 |
| 5024 | rompimiento | 3 |
| 5025 | romero | 3 |
| 5026 | románico | 3 |
| 5027 | rojizo | 3 |
| 5028 | roer | 3 |
| 5029 | rodrigo | 3 |
| 5030 | rocín | 3 |
| 5031 | risum | 3 |
| 5032 | revolucionario | 3 |
| 5033 | retraer | 3 |
| 5034 | retiro | 3 |
| 5035 | retirada | 3 |
| 5036 | reticencia | 3 |
| 5037 | resumidas | 3 |
| 5038 | restaurar | 3 |
| 5039 | resquicio | 3 |
| 5040 | respaldo | 3 |
| 5041 | resignado | 3 |
| 5042 | reseco | 3 |
| 5043 | requerir | 3 |
| 5044 | reprensible | 3 |
| 5045 | repleto | 3 |
| 5046 | repetido | 3 |
| 5047 | reparo | 3 |
| 5048 | rentar | 3 |
| 5049 | renovar | 3 |
| 5050 | renglón | 3 |
| 5051 | rendición | 3 |
| 5052 | rencoroso | 3 |
| 5053 | renan | 3 |
| 5054 | remolino | 3 |
| 5055 | remiendo | 3 |
| 5056 | remendar | 3 |
| 5057 | relacionar | 3 |
| 5058 | reglar | 3 |
| 5059 | regar | 3 |
| 5060 | regañadientes | 3 |
| 5061 | refinado | 3 |
| 5062 | reemplazar | 3 |
| 5063 | redonda | 3 |
| 5064 | redomado | 3 |
| 5065 | redactor | 3 |
| 5066 | reconciliación | 3 |
| 5067 | recompensar | 3 |
| 5068 | recluta | 3 |
| 5069 | reclamo | 3 |
| 5070 | recato | 3 |
| 5071 | recatado | 3 |
| 5072 | recargar | 3 |
| 5073 | recaer | 3 |
| 5074 | rebosar | 3 |
| 5075 | rebelde | 3 |
| 5076 | rebelar | 3 |
| 5077 | razonar | 3 |
| 5078 | razonable | 3 |
| 5079 | rayar | 3 |
| 5080 | rastro | 3 |
| 5081 | rasero | 3 |
| 5082 | rascar | 3 |
| 5083 | raquítico | 3 |
| 5084 | rana | 3 |
| 5085 | ramo | 3 |
| 5086 | raído | 3 |
| 5087 | raciocinio | 3 |
| 5088 | quinqué | 3 |
| 5089 | quincalla | 3 |
| 5090 | quieres | 3 |
| 5091 | querrá | 3 |
| 5092 | quejumbroso | 3 |
| 5093 | purgatorio | 3 |
| 5094 | pupitre | 3 |
| 5095 | puntería | 3 |
| 5096 | pulsar | 3 |
| 5097 | puf | 3 |
| 5098 | puertas | 3 |
| 5099 | proyectar | 3 |
| 5100 | providencial | 3 |
| 5101 | provechoso | 3 |
| 5102 | proscenio | 3 |
| 5103 | proporcionar | 3 |
| 5104 | propina | 3 |
| 5105 | propietario | 3 |
| 5106 | prólogo | 3 |
| 5107 | prohibición | 3 |
| 5108 | prodigio | 3 |
| 5109 | proclamar | 3 |
| 5110 | privar | 3 |
| 5111 | primor | 3 |
| 5112 | primogénito | 3 |
| 5113 | prever | 3 |
| 5114 | prevenir | 3 |
| 5115 | préstamo | 3 |
| 5116 | presentir | 3 |
| 5117 | preliminar | 3 |
| 5118 | precoz | 3 |
| 5119 | preclaro | 3 |
| 5120 | preceder | 3 |
| 5121 | praxíteles | 3 |
| 5122 | pradera | 3 |
| 5123 | practicar | 3 |
| 5124 | potencia | 3 |
| 5125 | postre | 3 |
| 5126 | posta | 3 |
| 5127 | positivismo | 3 |
| 5128 | positivamente | 3 |
| 5129 | posar | 3 |
| 5130 | pos | 3 |
| 5131 | portátil | 3 |
| 5132 | pordiosero | 3 |
| 5133 | poquito | 3 |
| 5134 | poniente | 3 |
| 5135 | pompadour | 3 |
| 5136 | pólvora | 3 |
| 5137 | polémica | 3 |
| 5138 | poetisa | 3 |
| 5139 | poderío | 3 |
| 5140 | pobrecita | 3 |
| 5141 | pluvial | 3 |
| 5142 | plumero | 3 |
| 5143 | pleno | 3 |
| 5144 | playa | 3 |
| 5145 | platea | 3 |
| 5146 | plantón | 3 |
| 5147 | plácido | 3 |
| 5148 | placa | 3 |
| 5149 | pisotear | 3 |
| 5150 | pirueta | 3 |
| 5151 | pinturas | 3 |
| 5152 | pintada | 3 |
| 5153 | petimetre | 3 |
| 5154 | pestillo | 3 |
| 5155 | pese | 3 |
| 5156 | pescuezo | 3 |
| 5157 | pesca | 3 |
| 5158 | pesadumbre | 3 |
| 5159 | perspicacia | 3 |
| 5160 | personalidad | 3 |
| 5161 | perseverancia | 3 |
| 5162 | perpendicular | 3 |
| 5163 | perlas | 3 |
| 5164 | perífrasis | 3 |
| 5165 | pergamino | 3 |
| 5166 | perenne | 3 |
| 5167 | pepita | 3 |
| 5168 | penetrante | 3 |
| 5169 | penas | 3 |
| 5170 | pelota | 3 |
| 5171 | pelado | 3 |
| 5172 | pedante | 3 |
| 5173 | pedagógico | 3 |
| 5174 | patrón | 3 |
| 5175 | patriotismo | 3 |
| 5176 | patas | 3 |
| 5177 | pasta | 3 |
| 5178 | pasmoso | 3 |
| 5179 | pasivo | 3 |
| 5180 | pase | 3 |
| 5181 | pascuas | 3 |
| 5182 | partícula | 3 |
| 5183 | paroxismo | 3 |
| 5184 | parodiar | 3 |
| 5185 | parecía | 3 |
| 5186 | paralela | 3 |
| 5187 | panurgo | 3 |
| 5188 | panteón | 3 |
| 5189 | paniaguado | 3 |
| 5190 | palpitar | 3 |
| 5191 | palpable | 3 |
| 5192 | palmera | 3 |
| 5193 | palabreja | 3 |
| 5194 | paca | 3 |
| 5195 | pabellón | 3 |
| 5196 | otras | 3 |
| 5197 | ortografía | 3 |
| 5198 | orillar | 3 |
| 5199 | originalidad | 3 |
| 5200 | oriental | 3 |
| 5201 | oratoria | 3 |
| 5202 | opio | 3 |
| 5203 | opaco | 3 |
| 5204 | ondear | 3 |
| 5205 | olvidito | 3 |
| 5206 | ojuelos | 3 |
| 5207 | ojeriza | 3 |
| 5208 | ojalá | 3 |
| 5209 | oidor | 3 |
| 5210 | oda | 3 |
| 5211 | ocio | 3 |
| 5212 | ocasionar | 3 |
| 5213 | oblicuo | 3 |
| 5214 | obediencia | 3 |
| 5215 | nuez | 3 |
| 5216 | núcleo | 3 |
| 5217 | nubes | 3 |
| 5218 | novelesco | 3 |
| 5219 | notaba | 3 |
| 5220 | nono | 3 |
| 5221 | nimiedad | 3 |
| 5222 | nilo | 3 |
| 5223 | nido | 3 |
| 5224 | nevar | 3 |
| 5225 | neutral | 3 |
| 5226 | negrura | 3 |
| 5227 | necesariamente | 3 |
| 5228 | navaja | 3 |
| 5229 | naturalmente | 3 |
| 5230 | narrativo | 3 |
| 5231 | narración | 3 |
| 5232 | nacional | 3 |
| 5233 | mutuamente | 3 |
| 5234 | mustiar | 3 |
| 5235 | muslo | 3 |
| 5236 | musical | 3 |
| 5237 | muera | 3 |
| 5238 | mueca | 3 |
| 5239 | muchísimo | 3 |
| 5240 | muchas | 3 |
| 5241 | mozalbete | 3 |
| 5242 | montico | 3 |
| 5243 | montera | 3 |
| 5244 | monstruoso | 3 |
| 5245 | monopolio | 3 |
| 5246 | molde | 3 |
| 5247 | modal | 3 |
| 5248 | mitrado | 3 |
| 5249 | misteriosamente | 3 |
| 5250 | mis | 3 |
| 5251 | miren | 3 |
| 5252 | mimo | 3 |
| 5253 | millar | 3 |
| 5254 | miga | 3 |
| 5255 | miente | 3 |
| 5256 | miedoso | 3 |
| 5257 | miasma | 3 |
| 5258 | metrópoli | 3 |
| 5259 | metafísico | 3 |
| 5260 | mercantil | 3 |
| 5261 | mente | 3 |
| 5262 | memorable | 3 |
| 5263 | mejoría | 3 |
| 5264 | mejía | 3 |
| 5265 | meditabundo | 3 |
| 5266 | mediano | 3 |
| 5267 | medalla | 3 |
| 5268 | máxima | 3 |
| 5269 | matrona | 3 |
| 5270 | matorral | 3 |
| 5271 | masón | 3 |
| 5272 | martínez | 3 |
| 5273 | martín | 3 |
| 5274 | maridar | 3 |
| 5275 | mari | 3 |
| 5276 | margen | 3 |
| 5277 | mareo | 3 |
| 5278 | marea | 3 |
| 5279 | marcos | 3 |
| 5280 | marco | 3 |
| 5281 | manolillo | 3 |
| 5282 | manjar | 3 |
| 5283 | manirroto | 3 |
| 5284 | maniquí | 3 |
| 5285 | maniqueo | 3 |
| 5286 | maniático | 3 |
| 5287 | maligno | 3 |
| 5288 | maldita | 3 |
| 5289 | magullar | 3 |
| 5290 | magnético | 3 |
| 5291 | maestría | 3 |
| 5292 | maduro | 3 |
| 5293 | madrugón | 3 |
| 5294 | madrugada | 3 |
| 5295 | madreselva | 3 |
| 5296 | macizo | 3 |
| 5297 | lunar | 3 |
| 5298 | lumbrera | 3 |
| 5299 | ludibrio | 3 |
| 5300 | lozano | 3 |
| 5301 | lola | 3 |
| 5302 | locuaz | 3 |
| 5303 | llenas | 3 |
| 5304 | llegada | 3 |
| 5305 | lívido | 3 |
| 5306 | liviandad | 3 |
| 5307 | liebre | 3 |
| 5308 | librería | 3 |
| 5309 | libación | 3 |
| 5310 | levar | 3 |
| 5311 | lealtad | 3 |
| 5312 | lavabo | 3 |
| 5313 | latido | 3 |
| 5314 | lamento | 3 |
| 5315 | ladrones | 3 |
| 5316 | ladera | 3 |
| 5317 | lacónico | 3 |
| 5318 | labrar | 3 |
| 5319 | kilómetro | 3 |
| 5320 | justamente | 3 |
| 5321 | jurado | 3 |
| 5322 | julio | 3 |
| 5323 | jubilar | 3 |
| 5324 | jubilación | 3 |
| 5325 | jovial | 3 |
| 5326 | josé | 3 |
| 5327 | job | 3 |
| 5328 | jipijapa | 3 |
| 5329 | irrupción | 3 |
| 5330 | irrevocable | 3 |
| 5331 | irreverencia | 3 |
| 5332 | irreprochable | 3 |
| 5333 | irreflexivo | 3 |
| 5334 | iris | 3 |
| 5335 | iría | 3 |
| 5336 | inventor | 3 |
| 5337 | invento | 3 |
| 5338 | invasión | 3 |
| 5339 | intrigar | 3 |
| 5340 | intratable | 3 |
| 5341 | interesado | 3 |
| 5342 | intento | 3 |
| 5343 | intempestivo | 3 |
| 5344 | intemperie | 3 |
| 5345 | insulso | 3 |
| 5346 | instrucción | 3 |
| 5347 | inquietar | 3 |
| 5348 | inquebrantable | 3 |
| 5349 | inodoro | 3 |
| 5350 | inmortalidad | 3 |
| 5351 | inmoral | 3 |
| 5352 | inflexible | 3 |
| 5353 | infinitamente | 3 |
| 5354 | infelices | 3 |
| 5355 | infames | 3 |
| 5356 | inexorable | 3 |
| 5357 | inepto | 3 |
| 5358 | indulgente | 3 |
| 5359 | indudable | 3 |
| 5360 | índole | 3 |
| 5361 | individuo | 3 |
| 5362 | indirecta | 3 |
| 5363 | indio | 3 |
| 5364 | indias | 3 |
| 5365 | independencia | 3 |
| 5366 | indecente | 3 |
| 5367 | incorrecto | 3 |
| 5368 | incompatible | 3 |
| 5369 | incomparable | 3 |
| 5370 | incómodo | 3 |
| 5371 | incipiente | 3 |
| 5372 | incentivar | 3 |
| 5373 | incansable | 3 |
| 5374 | incalificable | 3 |
| 5375 | impureza | 3 |
| 5376 | impúdico | 3 |
| 5377 | impresionable | 3 |
| 5378 | imponente | 3 |
| 5379 | impertinencia | 3 |
| 5380 | imperdonable | 3 |
| 5381 | impasible | 3 |
| 5382 | impaciente | 3 |
| 5383 | ilustración | 3 |
| 5384 | ignominioso | 3 |
| 5385 | ignominia | 3 |
| 5386 | idioma | 3 |
| 5387 | huraño | 3 |
| 5388 | humorístico | 3 |
| 5389 | humorismo | 3 |
| 5390 | humildemente | 3 |
| 5391 | huésped | 3 |
| 5392 | hotel | 3 |
| 5393 | hostia | 3 |
| 5394 | hortera | 3 |
| 5395 | hondonada | 3 |
| 5396 | honda | 3 |
| 5397 | holocausto | 3 |
| 5398 | hojuela | 3 |
| 5399 | hipótesis | 3 |
| 5400 | hipócrates | 3 |
| 5401 | hermanito | 3 |
| 5402 | hermanitas | 3 |
| 5403 | herido | 3 |
| 5404 | helecho | 3 |
| 5405 | hebilla | 3 |
| 5406 | has | 3 |
| 5407 | han | 3 |
| 5408 | hambriento | 3 |
| 5409 | halago | 3 |
| 5410 | habría | 3 |
| 5411 | habitante | 3 |
| 5412 | guijarro | 3 |
| 5413 | guía | 3 |
| 5414 | grosería | 3 |
| 5415 | grana | 3 |
| 5416 | gotera | 3 |
| 5417 | goma | 3 |
| 5418 | goberna | 3 |
| 5419 | gigante | 3 |
| 5420 | geométrico | 3 |
| 5421 | gentil | 3 |
| 5422 | genial | 3 |
| 5423 | generalizado | 3 |
| 5424 | gemir | 3 |
| 5425 | gatillo | 3 |
| 5426 | garbo | 3 |
| 5427 | garbanzo | 3 |
| 5428 | gangoso | 3 |
| 5429 | gancho | 3 |
| 5430 | galante | 3 |
| 5431 | gafa | 3 |
| 5432 | funda | 3 |
| 5433 | fulgencia | 3 |
| 5434 | frutar | 3 |
| 5435 | frisar | 3 |
| 5436 | frenesí | 3 |
| 5437 | fraternidad | 3 |
| 5438 | frasco | 3 |
| 5439 | franela | 3 |
| 5440 | fósforo | 3 |
| 5441 | fortificar | 3 |
| 5442 | formalmente | 3 |
| 5443 | forcejear | 3 |
| 5444 | fogoso | 3 |
| 5445 | flojedad | 3 |
| 5446 | flato | 3 |
| 5447 | flanquear | 3 |
| 5448 | fisonomía | 3 |
| 5449 | finito | 3 |
| 5450 | fingimiento | 3 |
| 5451 | figúrate | 3 |
| 5452 | fiero | 3 |
| 5453 | fidias | 3 |
| 5454 | feuillet | 3 |
| 5455 | ferviente | 3 |
| 5456 | feriar | 3 |
| 5457 | febril | 3 |
| 5458 | fauna | 3 |
| 5459 | fatigoso | 3 |
| 5460 | fangoso | 3 |
| 5461 | falsificar | 3 |
| 5462 | faena | 3 |
| 5463 | extremoso | 3 |
| 5464 | extravagante | 3 |
| 5465 | extenso | 3 |
| 5466 | experimentar | 3 |
| 5467 | exhibición | 3 |
| 5468 | excomunión | 3 |
| 5469 | exclusivamente | 3 |
| 5470 | exclamaba | 3 |
| 5471 | exagerado | 3 |
| 5472 | europa | 3 |
| 5473 | estucar | 3 |
| 5474 | estribillo | 3 |
| 5475 | estrellar | 3 |
| 5476 | estío | 3 |
| 5477 | estercolero | 3 |
| 5478 | estás | 3 |
| 5479 | estaría | 3 |
| 5480 | establecimiento | 3 |
| 5481 | estaban | 3 |
| 5482 | esqueleto | 3 |
| 5483 | espumar | 3 |
| 5484 | espontáneamente | 3 |
| 5485 | espiritualidad | 3 |
| 5486 | espiritista | 3 |
| 5487 | espionaje | 3 |
| 5488 | espinoso | 3 |
| 5489 | espía | 3 |
| 5490 | esperma | 3 |
| 5491 | espantoso | 3 |
| 5492 | espantada | 3 |
| 5493 | espaldar | 3 |
| 5494 | espacioso | 3 |
| 5495 | espaciar | 3 |
| 5496 | esmerar | 3 |
| 5497 | escudo | 3 |
| 5498 | escuálido | 3 |
| 5499 | escritor | 3 |
| 5500 | escrito | 3 |
| 5501 | esclavina | 3 |
| 5502 | escarlata | 3 |
| 5503 | escarcha | 3 |
| 5504 | escapatoria | 3 |
| 5505 | esbeltez | 3 |
| 5506 | epístola | 3 |
| 5507 | envejecer | 3 |
| 5508 | entró | 3 |
| 5509 | entretanto | 3 |
| 5510 | entremés | 3 |
| 5511 | ensimismar | 3 |
| 5512 | ensayo | 3 |
| 5513 | ensalada | 3 |
| 5514 | enrique | 3 |
| 5515 | ennoblecer | 3 |
| 5516 | enlutar | 3 |
| 5517 | enguantar | 3 |
| 5518 | engomar | 3 |
| 5519 | enfrascar | 3 |
| 5520 | encubridor | 3 |
| 5521 | encenagar | 3 |
| 5522 | encarar | 3 |
| 5523 | encajar | 3 |
| 5524 | empedrar | 3 |
| 5525 | emparejar | 3 |
| 5526 | empapelar | 3 |
| 5527 | eminente | 3 |
| 5528 | emigración | 3 |
| 5529 | embutido | 3 |
| 5530 | embalsamar | 3 |
| 5531 | electricidad | 3 |
| 5532 | ebrio | 3 |
| 5533 | duras | 3 |
| 5534 | dudoso | 3 |
| 5535 | dormido | 3 |
| 5536 | dogmático | 3 |
| 5537 | divisa | 3 |
| 5538 | diván | 3 |
| 5539 | distrito | 3 |
| 5540 | distante | 3 |
| 5541 | disfrazado | 3 |
| 5542 | discordia | 3 |
| 5543 | discípulo | 3 |
| 5544 | disciplinar | 3 |
| 5545 | directivo | 3 |
| 5546 | dirá | 3 |
| 5547 | dictar | 3 |
| 5548 | dicen | 3 |
| 5549 | dice | 3 |
| 5550 | dibujo | 3 |
| 5551 | diamante | 3 |
| 5552 | diagonal | 3 |
| 5553 | desván | 3 |
| 5554 | desterrar | 3 |
| 5555 | destello | 3 |
| 5556 | despilfarro | 3 |
| 5557 | desperdiciar | 3 |
| 5558 | desocupar | 3 |
| 5559 | deslumbrador | 3 |
| 5560 | descriptivo | 3 |
| 5561 | descompuesto | 3 |
| 5562 | descolgar | 3 |
| 5563 | descarnar | 3 |
| 5564 | descabellado | 3 |
| 5565 | desanimar | 3 |
| 5566 | desairado | 3 |
| 5567 | desagravio | 3 |
| 5568 | desagradable | 3 |
| 5569 | derribo | 3 |
| 5570 | depósito | 3 |
| 5571 | dependiente | 3 |
| 5572 | demonche | 3 |
| 5573 | demócrata | 3 |
| 5574 | delirar | 3 |
| 5575 | delirante | 3 |
| 5576 | deletéreo | 3 |
| 5577 | delantal | 3 |
| 5578 | déjame | 3 |
| 5579 | degenerar | 3 |
| 5580 | defensor | 3 |
| 5581 | decretar | 3 |
| 5582 | décima | 3 |
| 5583 | decían | 3 |
| 5584 | decaimiento | 3 |
| 5585 | decadencia | 3 |
| 5586 | debía | 3 |
| 5587 | curación | 3 |
| 5588 | cundir | 3 |
| 5589 | cuero | 3 |
| 5590 | cuentas | 3 |
| 5591 | cubo | 3 |
| 5592 | cubierta | 3 |
| 5593 | cuarteto | 3 |
| 5594 | cuánta | 3 |
| 5595 | cuadrar | 3 |
| 5596 | cuaderno | 3 |
| 5597 | crujiente | 3 |
| 5598 | crujía | 3 |
| 5599 | crónico | 3 |
| 5600 | cromo | 3 |
| 5601 | cristalino | 3 |
| 5602 | crees | 3 |
| 5603 | creador | 3 |
| 5604 | creación | 3 |
| 5605 | corteza | 3 |
| 5606 | cortejo | 3 |
| 5607 | corrido | 3 |
| 5608 | correspondencia | 3 |
| 5609 | corralada | 3 |
| 5610 | corpulento | 3 |
| 5611 | corporación | 3 |
| 5612 | coraza | 3 |
| 5613 | coquetear | 3 |
| 5614 | copón | 3 |
| 5615 | convocar | 3 |
| 5616 | conveniente | 3 |
| 5617 | contrahacer | 3 |
| 5618 | contorsión | 3 |
| 5619 | contestación | 3 |
| 5620 | contera | 3 |
| 5621 | contagio | 3 |
| 5622 | consumar | 3 |
| 5623 | consolador | 3 |
| 5624 | conservación | 3 |
| 5625 | consejero | 3 |
| 5626 | conformidad | 3 |
| 5627 | conferenciar | 3 |
| 5628 | conejo | 3 |
| 5629 | conducto | 3 |
| 5630 | concretar | 3 |
| 5631 | cónclave | 3 |
| 5632 | concertar | 3 |
| 5633 | concentrar | 3 |
| 5634 | concebir | 3 |
| 5635 | compungir | 3 |
| 5636 | compuesto | 3 |
| 5637 | comprimido | 3 |
| 5638 | complejo | 3 |
| 5639 | competencia | 3 |
| 5640 | comitiva | 3 |
| 5641 | comidilla | 3 |
| 5642 | comestible | 3 |
| 5643 | comarca | 3 |
| 5644 | comandante | 3 |
| 5645 | columbrar | 3 |
| 5646 | colocación | 3 |
| 5647 | colmena | 3 |
| 5648 | colgado | 3 |
| 5649 | codorniz | 3 |
| 5650 | código | 3 |
| 5651 | codiciado | 3 |
| 5652 | codazo | 3 |
| 5653 | cochera | 3 |
| 5654 | cobijar | 3 |
| 5655 | club | 3 |
| 5656 | cloaca | 3 |
| 5657 | clementina | 3 |
| 5658 | clamar | 3 |
| 5659 | civilización | 3 |
| 5660 | cirial | 3 |
| 5661 | circunspecto | 3 |
| 5662 | circunloquio | 3 |
| 5663 | cima | 3 |
| 5664 | cid | 3 |
| 5665 | chuzo | 3 |
| 5666 | chistar | 3 |
| 5667 | chisme | 3 |
| 5668 | chirrido | 3 |
| 5669 | chino | 3 |
| 5670 | charol | 3 |
| 5671 | chal | 3 |
| 5672 | cesto | 3 |
| 5673 | cesantía | 3 |
| 5674 | cerrazón | 3 |
| 5675 | cerradura | 3 |
| 5676 | cerilla | 3 |
| 5677 | cerero | 3 |
| 5678 | ceñido | 3 |
| 5679 | centinela | 3 |
| 5680 | celeste | 3 |
| 5681 | cejijunto | 3 |
| 5682 | cebolleta | 3 |
| 5683 | cavar | 3 |
| 5684 | caudillo | 3 |
| 5685 | cauce | 3 |
| 5686 | católica | 3 |
| 5687 | categórico | 3 |
| 5688 | castor | 3 |
| 5689 | casta | 3 |
| 5690 | carrillo | 3 |
| 5691 | carpintero | 3 |
| 5692 | carnero | 3 |
| 5693 | carbonera | 3 |
| 5694 | característica | 3 |
| 5695 | capullo | 3 |
| 5696 | cañada | 3 |
| 5697 | cantidad | 3 |
| 5698 | canónigos | 3 |
| 5699 | candidato | 3 |
| 5700 | candelero | 3 |
| 5701 | candelas | 3 |
| 5702 | cancel | 3 |
| 5703 | canastillo | 3 |
| 5704 | campillo | 3 |
| 5705 | campanilla | 3 |
| 5706 | camarada | 3 |
| 5707 | calvicie | 3 |
| 5708 | cáliz | 3 |
| 5709 | cajero | 3 |
| 5710 | cadete | 3 |
| 5711 | cadera | 3 |
| 5712 | cacho | 3 |
| 5713 | cabezada | 3 |
| 5714 | cábala | 3 |
| 5715 | burbuja | 3 |
| 5716 | bullanguero | 3 |
| 5717 | bujía | 3 |
| 5718 | buenos | 3 |
| 5719 | brutalidad | 3 |
| 5720 | brujo | 3 |
| 5721 | bramar | 3 |
| 5722 | borroso | 3 |
| 5723 | borrico | 3 |
| 5724 | bolo | 3 |
| 5725 | bofetón | 3 |
| 5726 | boda | 3 |
| 5727 | blusa | 3 |
| 5728 | bizarro | 3 |
| 5729 | bienestar | 3 |
| 5730 | bíblico | 3 |
| 5731 | benevolencia | 3 |
| 5732 | benemérito | 3 |
| 5733 | benéfico | 3 |
| 5734 | bendición | 3 |
| 5735 | belisario | 3 |
| 5736 | batín | 3 |
| 5737 | batería | 3 |
| 5738 | basura | 3 |
| 5739 | basto | 3 |
| 5740 | barriada | 3 |
| 5741 | barbero | 3 |
| 5742 | banquero | 3 |
| 5743 | bandido | 3 |
| 5744 | banda | 3 |
| 5745 | baladí | 3 |
| 5746 | bala | 3 |
| 5747 | badajo | 3 |
| 5748 | bactriana | 3 |
| 5749 | azote | 3 |
| 5750 | azahar | 3 |
| 5751 | avenar | 3 |
| 5752 | avena | 3 |
| 5753 | avellanar | 3 |
| 5754 | ausentar | 3 |
| 5755 | aura | 3 |
| 5756 | augusto | 3 |
| 5757 | atronar | 3 |
| 5758 | atrio | 3 |
| 5759 | atributo | 3 |
| 5760 | atragantar | 3 |
| 5761 | astuto | 3 |
| 5762 | astucia | 3 |
| 5763 | astorga | 3 |
| 5764 | asiduo | 3 |
| 5765 | asechanza | 3 |
| 5766 | ascensión | 3 |
| 5767 | artificial | 3 |
| 5768 | artesano | 3 |
| 5769 | arrinconar | 3 |
| 5770 | arreo | 3 |
| 5771 | aroma | 3 |
| 5772 | armonizar | 3 |
| 5773 | armónico | 3 |
| 5774 | armero | 3 |
| 5775 | armazón | 3 |
| 5776 | arenga | 3 |
| 5777 | arbusto | 3 |
| 5778 | aragón | 3 |
| 5779 | aquelarre | 3 |
| 5780 | apoyo | 3 |
| 5781 | apodo | 3 |
| 5782 | aplicación | 3 |
| 5783 | aplacar | 3 |
| 5784 | apestar | 3 |
| 5785 | apasionado | 3 |
| 5786 | aparatoso | 3 |
| 5787 | antipatía | 3 |
| 5788 | antigua | 3 |
| 5789 | anticipo | 3 |
| 5790 | antesala | 3 |
| 5791 | aniquilar | 3 |
| 5792 | animado | 3 |
| 5793 | angustiar | 3 |
| 5794 | anémico | 3 |
| 5795 | anemia | 3 |
| 5796 | andrajoso | 3 |
| 5797 | andaría | 3 |
| 5798 | anca | 3 |
| 5799 | anarquía | 3 |
| 5800 | anaquel | 3 |
| 5801 | analizar | 3 |
| 5802 | anacronismo | 3 |
| 5803 | anacleto | 3 |
| 5804 | amplio | 3 |
| 5805 | amonestación | 3 |
| 5806 | amigote | 3 |
| 5807 | americana | 3 |
| 5808 | amén | 3 |
| 5809 | ambicioso | 3 |
| 5810 | amanerar | 3 |
| 5811 | amadeo | 3 |
| 5812 | altozano | 3 |
| 5813 | altivo | 3 |
| 5814 | altivar | 3 |
| 5815 | alternar | 3 |
| 5816 | alteración | 3 |
| 5817 | alrededores | 3 |
| 5818 | almorzar | 3 |
| 5819 | aliviar | 3 |
| 5820 | alfonso | 3 |
| 5821 | alfombrar | 3 |
| 5822 | aleteo | 3 |
| 5823 | alertar | 3 |
| 5824 | alegar | 3 |
| 5825 | alcázar | 3 |
| 5826 | alcaraván | 3 |
| 5827 | alcantarilla | 3 |
| 5828 | albergue | 3 |
| 5829 | alarido | 3 |
| 5830 | ajustado | 3 |
| 5831 | ajuar | 3 |
| 5832 | ahorcar | 3 |
| 5833 | ahínco | 3 |
| 5834 | aguacero | 3 |
| 5835 | agravio | 3 |
| 5836 | agravar | 3 |
| 5837 | agradecido | 3 |
| 5838 | agapita | 3 |
| 5839 | agachar | 3 |
| 5840 | afortunar | 3 |
| 5841 | afligir | 3 |
| 5842 | afilado | 3 |
| 5843 | afectado | 3 |
| 5844 | adusto | 3 |
| 5845 | adquirido | 3 |
| 5846 | adonde | 3 |
| 5847 | adivinación | 3 |
| 5848 | adelantado | 3 |
| 5849 | acusación | 3 |
| 5850 | acumular | 3 |
| 5851 | acreditado | 3 |
| 5852 | acosar | 3 |
| 5853 | aclimatación | 3 |
| 5854 | achaque | 3 |
| 5855 | acendrar | 3 |
| 5856 | aceituna | 3 |
| 5857 | acatar | 3 |
| 5858 | abundancia | 3 |
| 5859 | abultado | 3 |
| 5860 | absorto | 3 |
| 5861 | ábside | 3 |
| 5862 | abrumador | 3 |
| 5863 | abordar | 3 |
| 5864 | abono | 3 |
| 5865 | abolengo | 3 |
| 5866 | zurriagar | 2 |
| 5867 | zurriágame | 2 |
| 5868 | zumbido | 2 |
| 5869 | zueco | 2 |
| 5870 | zarzamora | 2 |
| 5871 | zarandear | 2 |
| 5872 | zagal | 2 |
| 5873 | yugo | 2 |
| 5874 | york | 2 |
| 5875 | x | 2 |
| 5876 | werther | 2 |
| 5877 | vuestro | 2 |
| 5878 | vuelve | 2 |
| 5879 | votación | 2 |
| 5880 | vos | 2 |
| 5881 | voluptuosamente | 2 |
| 5882 | voluntariamente | 2 |
| 5883 | vocabulario | 2 |
| 5884 | viviente | 2 |
| 5885 | viveza | 2 |
| 5886 | visual | 2 |
| 5887 | vistazo | 2 |
| 5888 | vistas | 2 |
| 5889 | vistalegre | 2 |
| 5890 | viso | 2 |
| 5891 | virginal | 2 |
| 5892 | violeta | 2 |
| 5893 | viña | 2 |
| 5894 | villegas | 2 |
| 5895 | viii | 2 |
| 5896 | vii | 2 |
| 5897 | viga | 2 |
| 5898 | veterano | 2 |
| 5899 | vestidura | 2 |
| 5900 | vertiginoso | 2 |
| 5901 | vergonzante | 2 |
| 5902 | verdaderamente | 2 |
| 5903 | vera | 2 |
| 5904 | ventorrillo | 2 |
| 5905 | venial | 2 |
| 5906 | venía | 2 |
| 5907 | venia | 2 |
| 5908 | venciste | 2 |
| 5909 | velludo | 2 |
| 5910 | vello | 2 |
| 5911 | veintiséis | 2 |
| 5912 | vega | 2 |
| 5913 | vastísimo | 2 |
| 5914 | variar | 2 |
| 5915 | variado | 2 |
| 5916 | vaquero | 2 |
| 5917 | vanidoso | 2 |
| 5918 | vanamente | 2 |
| 5919 | vanagloriar | 2 |
| 5920 | vanagloria | 2 |
| 5921 | van | 2 |
| 5922 | valeroso | 2 |
| 5923 | valentía | 2 |
| 5924 | valdés | 2 |
| 5925 | vajilla | 2 |
| 5926 | vade | 2 |
| 5927 | vacilación | 2 |
| 5928 | urbano | 2 |
| 5929 | untar | 2 |
| 5930 | unidos | 2 |
| 5931 | uf | 2 |
| 5932 | tutear | 2 |
| 5933 | turco | 2 |
| 5934 | turbio | 2 |
| 5935 | turbado | 2 |
| 5936 | turbación | 2 |
| 5937 | tupir | 2 |
| 5938 | tupido | 2 |
| 5939 | tumbar | 2 |
| 5940 | tul | 2 |
| 5941 | tubinga | 2 |
| 5942 | tropa | 2 |
| 5943 | trochar | 2 |
| 5944 | trocar | 2 |
| 5945 | triunfador | 2 |
| 5946 | tripular | 2 |
| 5947 | trenza | 2 |
| 5948 | traviesa | 2 |
| 5949 | traviata | 2 |
| 5950 | tratamiento | 2 |
| 5951 | tratado | 2 |
| 5952 | trastienda | 2 |
| 5953 | trasplantar | 2 |
| 5954 | trapillo | 2 |
| 5955 | trapicheo | 2 |
| 5956 | transparente | 2 |
| 5957 | transfusión | 2 |
| 5958 | trama | 2 |
| 5959 | traducción | 2 |
| 5960 | trabucar | 2 |
| 5961 | tortura | 2 |
| 5962 | tortilla | 2 |
| 5963 | torso | 2 |
| 5964 | torquemada | 2 |
| 5965 | torcida | 2 |
| 5966 | topo | 2 |
| 5967 | tópico | 2 |
| 5968 | topar | 2 |
| 5969 | tonsurar | 2 |
| 5970 | tonel | 2 |
| 5971 | toalla | 2 |
| 5972 | tiznar | 2 |
| 5973 | titán | 2 |
| 5974 | tiros | 2 |
| 5975 | tirón | 2 |
| 5976 | tirantez | 2 |
| 5977 | tirante | 2 |
| 5978 | tirador | 2 |
| 5979 | tinto | 2 |
| 5980 | tintero | 2 |
| 5981 | tino | 2 |
| 5982 | tez | 2 |
| 5983 | testarudo | 2 |
| 5984 | tesorero | 2 |
| 5985 | terrado | 2 |
| 5986 | terquedad | 2 |
| 5987 | tenorios | 2 |
| 5988 | tenia | 2 |
| 5989 | tendría | 2 |
| 5990 | tendrá | 2 |
| 5991 | tendencia | 2 |
| 5992 | temple | 2 |
| 5993 | templado | 2 |
| 5994 | temperatura | 2 |
| 5995 | temeridad | 2 |
| 5996 | tarsa | 2 |
| 5997 | tarjeta | 2 |
| 5998 | tapizar | 2 |
| 5999 | tapete | 2 |
| 6000 | tangible | 2 |
| 6001 | tamaza | 2 |
| 6002 | talla | 2 |
| 6003 | talía | 2 |
| 6004 | talante | 2 |
| 6005 | tálamo | 2 |
| 6006 | taimado | 2 |
| 6007 | tachar | 2 |
| 6008 | sutilmente | 2 |
| 6009 | sutileza | 2 |
| 6010 | sustituir | 2 |
| 6011 | sustentar | 2 |
| 6012 | sustancial | 2 |
| 6013 | suscitar | 2 |
| 6014 | susceptibilidad | 2 |
| 6015 | surtidor | 2 |
| 6016 | surcar | 2 |
| 6017 | superlativo | 2 |
| 6018 | superar | 2 |
| 6019 | supeditar | 2 |
| 6020 | sumergir | 2 |
| 6021 | sufrimiento | 2 |
| 6022 | suficientemente | 2 |
| 6023 | sueco | 2 |
| 6024 | sudeste | 2 |
| 6025 | suciedad | 2 |
| 6026 | sucesivo | 2 |
| 6027 | sucedáneo | 2 |
| 6028 | subversivo | 2 |
| 6029 | subsiguiente | 2 |
| 6030 | subrepticiamente | 2 |
| 6031 | submarino | 2 |
| 6032 | subasta | 2 |
| 6033 | sr | 2 |
| 6034 | sosegar | 2 |
| 6035 | sortija | 2 |
| 6036 | sordidez | 2 |
| 6037 | soñaba | 2 |
| 6038 | sonsonete | 2 |
| 6039 | sonrosar | 2 |
| 6040 | sonante | 2 |
| 6041 | sonaja | 2 |
| 6042 | somos | 2 |
| 6043 | somero | 2 |
| 6044 | sombrilla | 2 |
| 6045 | soltura | 2 |
| 6046 | solariego | 2 |
| 6047 | solapar | 2 |
| 6048 | sois | 2 |
| 6049 | sofocado | 2 |
| 6050 | socorrer | 2 |
| 6051 | socarronería | 2 |
| 6052 | sobrio | 2 |
| 6053 | sobrevivir | 2 |
| 6054 | sobresaltar | 2 |
| 6055 | sobra | 2 |
| 6056 | sitiar | 2 |
| 6057 | sistemático | 2 |
| 6058 | sistemáticamente | 2 |
| 6059 | sirena | 2 |
| 6060 | síncope | 2 |
| 6061 | simultáneo | 2 |
| 6062 | simón | 2 |
| 6063 | similor | 2 |
| 6064 | sigue | 2 |
| 6065 | significado | 2 |
| 6066 | siglos | 2 |
| 6067 | siervo | 2 |
| 6068 | sicilia | 2 |
| 6069 | sexto | 2 |
| 6070 | setentón | 2 |
| 6071 | sesudo | 2 |
| 6072 | servidor | 2 |
| 6073 | serrar | 2 |
| 6074 | serían | 2 |
| 6075 | serenata | 2 |
| 6076 | señuelo | 2 |
| 6077 | señalado | 2 |
| 6078 | sensibilidad | 2 |
| 6079 | sensato | 2 |
| 6080 | semblante | 2 |
| 6081 | sello | 2 |
| 6082 | seguramente | 2 |
| 6083 | segundón | 2 |
| 6084 | sedentario | 2 |
| 6085 | sedar | 2 |
| 6086 | secundaria | 2 |
| 6087 | secundar | 2 |
| 6088 | secas | 2 |
| 6089 | seca | 2 |
| 6090 | sazón | 2 |
| 6091 | sauce | 2 |
| 6092 | santurrón | 2 |
| 6093 | santísimo | 2 |
| 6094 | sangría | 2 |
| 6095 | sancionar | 2 |
| 6096 | salvedad | 2 |
| 6097 | salve | 2 |
| 6098 | salvarme | 2 |
| 6099 | salva | 2 |
| 6100 | salsa | 2 |
| 6101 | salía | 2 |
| 6102 | salero | 2 |
| 6103 | sajón | 2 |
| 6104 | sacramental | 2 |
| 6105 | saborcillo | 2 |
| 6106 | rumboso | 2 |
| 6107 | rumbo | 2 |
| 6108 | ruidoso | 2 |
| 6109 | ruegos | 2 |
| 6110 | ruedo | 2 |
| 6111 | ruboroso | 2 |
| 6112 | rubí | 2 |
| 6113 | rousseau | 2 |
| 6114 | rossini | 2 |
| 6115 | rollo | 2 |
| 6116 | rodrigón | 2 |
| 6117 | rociar | 2 |
| 6118 | robustez | 2 |
| 6119 | robo | 2 |
| 6120 | rito | 2 |
| 6121 | riquísimo | 2 |
| 6122 | riñón | 2 |
| 6123 | riego | 2 |
| 6124 | ribete | 2 |
| 6125 | rezo | 2 |
| 6126 | rezagar | 2 |
| 6127 | revuelta | 2 |
| 6128 | revista | 2 |
| 6129 | revestir | 2 |
| 6130 | revés | 2 |
| 6131 | reventar | 2 |
| 6132 | retrospectivo | 2 |
| 6133 | retractar | 2 |
| 6134 | retórico | 2 |
| 6135 | retardar | 2 |
| 6136 | retar | 2 |
| 6137 | respondía | 2 |
| 6138 | respetabilidad | 2 |
| 6139 | resaltar | 2 |
| 6140 | resabio | 2 |
| 6141 | res | 2 |
| 6142 | requisito | 2 |
| 6143 | reputación | 2 |
| 6144 | republicanismo | 2 |
| 6145 | reposar | 2 |
| 6146 | reportar | 2 |
| 6147 | repletar | 2 |
| 6148 | repetición | 2 |
| 6149 | repatriación | 2 |
| 6150 | rendija | 2 |
| 6151 | remitir | 2 |
| 6152 | remilgo | 2 |
| 6153 | rematar | 2 |
| 6154 | relajar | 2 |
| 6155 | reguero | 2 |
| 6156 | regocijar | 2 |
| 6157 | regatear | 2 |
| 6158 | regata | 2 |
| 6159 | reformista | 2 |
| 6160 | reforma | 2 |
| 6161 | redoblar | 2 |
| 6162 | redivivo | 2 |
| 6163 | redil | 2 |
| 6164 | rectángulo | 2 |
| 6165 | recostar | 2 |
| 6166 | recordaba | 2 |
| 6167 | reconcentrar | 2 |
| 6168 | recoletas | 2 |
| 6169 | recolección | 2 |
| 6170 | recogimiento | 2 |
| 6171 | recodo | 2 |
| 6172 | reclutar | 2 |
| 6173 | recipiente | 2 |
| 6174 | receloso | 2 |
| 6175 | recelo | 2 |
| 6176 | recatar | 2 |
| 6177 | recargado | 2 |
| 6178 | rebuscar | 2 |
| 6179 | rebozar | 2 |
| 6180 | rebeldía | 2 |
| 6181 | rebasar | 2 |
| 6182 | reata | 2 |
| 6183 | reaparecer | 2 |
| 6184 | reanudar | 2 |
| 6185 | realmente | 2 |
| 6186 | realismo | 2 |
| 6187 | realar | 2 |
| 6188 | rayos | 2 |
| 6189 | raudal | 2 |
| 6190 | rastrero | 2 |
| 6191 | raso | 2 |
| 6192 | rasguño | 2 |
| 6193 | rápidamente | 2 |
| 6194 | rapé | 2 |
| 6195 | ramillete | 2 |
| 6196 | raer | 2 |
| 6197 | radicalmente | 2 |
| 6198 | radiante | 2 |
| 6199 | quintar | 2 |
| 6200 | química | 2 |
| 6201 | quimera | 2 |
| 6202 | quijote | 2 |
| 6203 | quiá | 2 |
| 6204 | quevedo | 2 |
| 6205 | queso | 2 |
| 6206 | purgar | 2 |
| 6207 | punzada | 2 |
| 6208 | puntapiés | 2 |
| 6209 | puntapié | 2 |
| 6210 | puntal | 2 |
| 6211 | pundonoroso | 2 |
| 6212 | pun | 2 |
| 6213 | pulverizar | 2 |
| 6214 | pulular | 2 |
| 6215 | pulgar | 2 |
| 6216 | pulgada | 2 |
| 6217 | pugnar | 2 |
| 6218 | puerro | 2 |
| 6219 | puerilidad | 2 |
| 6220 | provocación | 2 |
| 6221 | provisorato | 2 |
| 6222 | provisional | 2 |
| 6223 | provincialismo | 2 |
| 6224 | protesto | 2 |
| 6225 | protagonista | 2 |
| 6226 | prostituir | 2 |
| 6227 | prostitución | 2 |
| 6228 | prosperar | 2 |
| 6229 | prosiguió | 2 |
| 6230 | prorrumpir | 2 |
| 6231 | prórroga | 2 |
| 6232 | propiciar | 2 |
| 6233 | propagar | 2 |
| 6234 | propagandista | 2 |
| 6235 | proletario | 2 |
| 6236 | progresar | 2 |
| 6237 | profusión | 2 |
| 6238 | profesor | 2 |
| 6239 | profesión | 2 |
| 6240 | prodigioso | 2 |
| 6241 | proceso | 2 |
| 6242 | procedimiento | 2 |
| 6243 | procedente | 2 |
| 6244 | procaz | 2 |
| 6245 | privilegiado | 2 |
| 6246 | privado | 2 |
| 6247 | pringue | 2 |
| 6248 | primitiva | 2 |
| 6249 | primerizo | 2 |
| 6250 | pretérito | 2 |
| 6251 | presuntuoso | 2 |
| 6252 | preso | 2 |
| 6253 | presea | 2 |
| 6254 | prescripción | 2 |
| 6255 | prensar | 2 |
| 6256 | premioso | 2 |
| 6257 | predio | 2 |
| 6258 | precocidad | 2 |
| 6259 | precoces | 2 |
| 6260 | precipitado | 2 |
| 6261 | pp | 2 |
| 6262 | postrado | 2 |
| 6263 | posterior | 2 |
| 6264 | postergar | 2 |
| 6265 | positivar | 2 |
| 6266 | posibilidad | 2 |
| 6267 | portugués | 2 |
| 6268 | porquería | 2 |
| 6269 | porqué | 2 |
| 6270 | porcelana | 2 |
| 6271 | popularidad | 2 |
| 6272 | populacho | 2 |
| 6273 | pontificio | 2 |
| 6274 | pontifical | 2 |
| 6275 | pompa | 2 |
| 6276 | polvoriento | 2 |
| 6277 | polichinela | 2 |
| 6278 | pobres | 2 |
| 6279 | plegaria | 2 |
| 6280 | plazo | 2 |
| 6281 | platónicamente | 2 |
| 6282 | platillo | 2 |
| 6283 | plano | 2 |
| 6284 | planchar | 2 |
| 6285 | pistoletazo | 2 |
| 6286 | pisotón | 2 |
| 6287 | piropo | 2 |
| 6288 | pirámide | 2 |
| 6289 | pintado | 2 |
| 6290 | pinchazo | 2 |
| 6291 | pimiento | 2 |
| 6292 | pilón | 2 |
| 6293 | pilluelo | 2 |
| 6294 | pílades | 2 |
| 6295 | pila | 2 |
| 6296 | pienso | 2 |
| 6297 | picaresca | 2 |
| 6298 | petrica | 2 |
| 6299 | petitorio | 2 |
| 6300 | petaca | 2 |
| 6301 | pestañear | 2 |
| 6302 | pestaña | 2 |
| 6303 | pésimo | 2 |
| 6304 | pesimista | 2 |
| 6305 | pesebre | 2 |
| 6306 | pésame | 2 |
| 6307 | pervertir | 2 |
| 6308 | perspicaz | 2 |
| 6309 | personificar | 2 |
| 6310 | perol | 2 |
| 6311 | pernicioso | 2 |
| 6312 | perla | 2 |
| 6313 | período | 2 |
| 6314 | perfeccionar | 2 |
| 6315 | perdigón | 2 |
| 6316 | pérdida | 2 |
| 6317 | percha | 2 |
| 6318 | pequeñísimo | 2 |
| 6319 | peón | 2 |
| 6320 | peñón | 2 |
| 6321 | peña | 2 |
| 6322 | penúltimo | 2 |
| 6323 | pendón | 2 |
| 6324 | penacho | 2 |
| 6325 | peluca | 2 |
| 6326 | pelear | 2 |
| 6327 | pedrada | 2 |
| 6328 | pechuga | 2 |
| 6329 | pausado | 2 |
| 6330 | paúl | 2 |
| 6331 | patriótico | 2 |
| 6332 | patriota | 2 |
| 6333 | patrio | 2 |
| 6334 | patrimonio | 2 |
| 6335 | patentar | 2 |
| 6336 | pastoril | 2 |
| 6337 | pastoral | 2 |
| 6338 | pastar | 2 |
| 6339 | pasmado | 2 |
| 6340 | parsimonia | 2 |
| 6341 | parodia | 2 |
| 6342 | parejo | 2 |
| 6343 | parecíale | 2 |
| 6344 | pardiez | 2 |
| 6345 | parchar | 2 |
| 6346 | páramo | 2 |
| 6347 | paralelo | 2 |
| 6348 | paquita | 2 |
| 6349 | papanatas | 2 |
| 6350 | pantoja | 2 |
| 6351 | panegírico | 2 |
| 6352 | palomo | 2 |
| 6353 | palomar | 2 |
| 6354 | palaciego | 2 |
| 6355 | palabras | 2 |
| 6356 | pajarita | 2 |
| 6357 | pago | 2 |
| 6358 | pagadero | 2 |
| 6359 | padrenuestros | 2 |
| 6360 | oyente | 2 |
| 6361 | osa | 2 |
| 6362 | ortiga | 2 |
| 6363 | ornitólogo | 2 |
| 6364 | orla | 2 |
| 6365 | orientar | 2 |
| 6366 | orfandad | 2 |
| 6367 | ordenanza | 2 |
| 6368 | opuesto | 2 |
| 6369 | optimista | 2 |
| 6370 | opresión | 2 |
| 6371 | ondulación | 2 |
| 6372 | ominoso | 2 |
| 6373 | olvidado | 2 |
| 6374 | oloroso | 2 |
| 6375 | ojival | 2 |
| 6376 | ojeroso | 2 |
| 6377 | oficialmente | 2 |
| 6378 | ofensa | 2 |
| 6379 | ofendido | 2 |
| 6380 | ociosidad | 2 |
| 6381 | ochocientos | 2 |
| 6382 | obtener | 2 |
| 6383 | obstinado | 2 |
| 6384 | observó | 2 |
| 6385 | observatorio | 2 |
| 6386 | obscenidad | 2 |
| 6387 | obligado | 2 |
| 6388 | obispos | 2 |
| 6389 | obediente | 2 |
| 6390 | nupcial | 2 |
| 6391 | nulo | 2 |
| 6392 | notorio | 2 |
| 6393 | nombramiento | 2 |
| 6394 | ninguno | 2 |
| 6395 | nicho | 2 |
| 6396 | nevado | 2 |
| 6397 | neuralgia | 2 |
| 6398 | nebuloso | 2 |
| 6399 | neblina | 2 |
| 6400 | nauseabundo | 2 |
| 6401 | natillas | 2 |
| 6402 | narrador | 2 |
| 6403 | naipe | 2 |
| 6404 | nación | 2 |
| 6405 | músico | 2 |
| 6406 | muscular | 2 |
| 6407 | musa | 2 |
| 6408 | murió | 2 |
| 6409 | murillo | 2 |
| 6410 | muñeco | 2 |
| 6411 | municipal | 2 |
| 6412 | muerta | 2 |
| 6413 | mudéjar | 2 |
| 6414 | motín | 2 |
| 6415 | mote | 2 |
| 6416 | mostrenco | 2 |
| 6417 | mortificación | 2 |
| 6418 | mortífero | 2 |
| 6419 | morirá | 2 |
| 6420 | moreto | 2 |
| 6421 | mórbido | 2 |
| 6422 | moratín | 2 |
| 6423 | moralizar | 2 |
| 6424 | moqueta | 2 |
| 6425 | monje | 2 |
| 6426 | monedero | 2 |
| 6427 | molina | 2 |
| 6428 | molière | 2 |
| 6429 | molicie | 2 |
| 6430 | molesto | 2 |
| 6431 | molécula | 2 |
| 6432 | mole | 2 |
| 6433 | mojigato | 2 |
| 6434 | mojadura | 2 |
| 6435 | mohín | 2 |
| 6436 | mochuelo | 2 |
| 6437 | mitigar | 2 |
| 6438 | mister | 2 |
| 6439 | misioneros | 2 |
| 6440 | misionero | 2 |
| 6441 | misericordioso | 2 |
| 6442 | miserables | 2 |
| 6443 | mirado | 2 |
| 6444 | minutar | 2 |
| 6445 | minucioso | 2 |
| 6446 | minoría | 2 |
| 6447 | ministerio | 2 |
| 6448 | mínimo | 2 |
| 6449 | mínguez | 2 |
| 6450 | minerva | 2 |
| 6451 | mimoso | 2 |
| 6452 | mimosa | 2 |
| 6453 | mímico | 2 |
| 6454 | militante | 2 |
| 6455 | miliciano | 2 |
| 6456 | miles | 2 |
| 6457 | migaja | 2 |
| 6458 | midas | 2 |
| 6459 | microscopio | 2 |
| 6460 | mezclado | 2 |
| 6461 | mezcla | 2 |
| 6462 | meticuloso | 2 |
| 6463 | meritorio | 2 |
| 6464 | mercancía | 2 |
| 6465 | mequetrefe | 2 |
| 6466 | menudencia | 2 |
| 6467 | menudear | 2 |
| 6468 | mentecato | 2 |
| 6469 | mentar | 2 |
| 6470 | menoscabo | 2 |
| 6471 | menguar | 2 |
| 6472 | mendrugo | 2 |
| 6473 | melódico | 2 |
| 6474 | meléndez | 2 |
| 6475 | mefistófeles | 2 |
| 6476 | mediados | 2 |
| 6477 | medallón | 2 |
| 6478 | mechón | 2 |
| 6479 | mecer | 2 |
| 6480 | mazorca | 2 |
| 6481 | máximo | 2 |
| 6482 | matricular | 2 |
| 6483 | matilde | 2 |
| 6484 | matemático | 2 |
| 6485 | matanzas | 2 |
| 6486 | mástil | 2 |
| 6487 | marrullero | 2 |
| 6488 | maroto | 2 |
| 6489 | marino | 2 |
| 6490 | margarita | 2 |
| 6491 | marejada | 2 |
| 6492 | marcar | 2 |
| 6493 | marar | 2 |
| 6494 | maquinación | 2 |
| 6495 | maquiavelo | 2 |
| 6496 | maquiavélico | 2 |
| 6497 | maña | 2 |
| 6498 | manzano | 2 |
| 6499 | manuel | 2 |
| 6500 | manteca | 2 |
| 6501 | mansión | 2 |
| 6502 | mansedumbre | 2 |
| 6503 | manrique | 2 |
| 6504 | manotada | 2 |
| 6505 | manolé | 2 |
| 6506 | mangar | 2 |
| 6507 | mando | 2 |
| 6508 | mandamiento | 2 |
| 6509 | mampara | 2 |
| 6510 | maltratado | 2 |
| 6511 | malhumorado | 2 |
| 6512 | malhaya | 2 |
| 6513 | malgastar | 2 |
| 6514 | malagueño | 2 |
| 6515 | majestuosamente | 2 |
| 6516 | magnetismo | 2 |
| 6517 | mágico | 2 |
| 6518 | magia | 2 |
| 6519 | magdalena | 2 |
| 6520 | madurar | 2 |
| 6521 | madres | 2 |
| 6522 | machacar | 2 |
| 6523 | lutero | 2 |
| 6524 | lunes | 2 |
| 6525 | lugarteniente | 2 |
| 6526 | lucas | 2 |
| 6527 | lotería | 2 |
| 6528 | lona | 2 |
| 6529 | locuacidad | 2 |
| 6530 | llavín | 2 |
| 6531 | llanura | 2 |
| 6532 | llamativo | 2 |
| 6533 | llamada | 2 |
| 6534 | liturgia | 2 |
| 6535 | lisonjear | 2 |
| 6536 | lisonja | 2 |
| 6537 | lírico | 2 |
| 6538 | lira | 2 |
| 6539 | liquidación | 2 |
| 6540 | linaje | 2 |
| 6541 | límpido | 2 |
| 6542 | limpia | 2 |
| 6543 | limón | 2 |
| 6544 | limitar | 2 |
| 6545 | ligorio | 2 |
| 6546 | licencia | 2 |
| 6547 | librote | 2 |
| 6548 | librepensador | 2 |
| 6549 | libertar | 2 |
| 6550 | letrina | 2 |
| 6551 | letrero | 2 |
| 6552 | lesa | 2 |
| 6553 | leñar | 2 |
| 6554 | lentitud | 2 |
| 6555 | lengüeta | 2 |
| 6556 | leguas | 2 |
| 6557 | legitimidad | 2 |
| 6558 | lechoso | 2 |
| 6559 | lear | 2 |
| 6560 | leandro | 2 |
| 6561 | latón | 2 |
| 6562 | latamente | 2 |
| 6563 | lacónicamente | 2 |
| 6564 | labrador | 2 |
| 6565 | juvenil | 2 |
| 6566 | justar | 2 |
| 6567 | júpiter | 2 |
| 6568 | juguetear | 2 |
| 6569 | jueves | 2 |
| 6570 | judicial | 2 |
| 6571 | judía | 2 |
| 6572 | jubón | 2 |
| 6573 | jornada | 2 |
| 6574 | jirón | 2 |
| 6575 | jaspe | 2 |
| 6576 | jarrón | 2 |
| 6577 | jarro | 2 |
| 6578 | jarras | 2 |
| 6579 | jardinero | 2 |
| 6580 | jamón | 2 |
| 6581 | jactancioso | 2 |
| 6582 | jactancia | 2 |
| 6583 | italia | 2 |
| 6584 | isabel | 2 |
| 6585 | irritante | 2 |
| 6586 | irrisorio | 2 |
| 6587 | irresponsable | 2 |
| 6588 | irreparable | 2 |
| 6589 | irremediable | 2 |
| 6590 | involuntario | 2 |
| 6591 | invasor | 2 |
| 6592 | invariable | 2 |
| 6593 | inválido | 2 |
| 6594 | inútilmente | 2 |
| 6595 | inutilidad | 2 |
| 6596 | intuición | 2 |
| 6597 | intruso | 2 |
| 6598 | intransigencia | 2 |
| 6599 | intranquilo | 2 |
| 6600 | intolerancia | 2 |
| 6601 | intolerable | 2 |
| 6602 | intervención | 2 |
| 6603 | interrupción | 2 |
| 6604 | interrogatorio | 2 |
| 6605 | intermedio | 2 |
| 6606 | interinar | 2 |
| 6607 | interceptar | 2 |
| 6608 | inteligible | 2 |
| 6609 | integridad | 2 |
| 6610 | insultante | 2 |
| 6611 | insuficiente | 2 |
| 6612 | instruir | 2 |
| 6613 | instituciones | 2 |
| 6614 | instintivo | 2 |
| 6615 | instantáneo | 2 |
| 6616 | inspección | 2 |
| 6617 | insomnio | 2 |
| 6618 | insistente | 2 |
| 6619 | insistencia | 2 |
| 6620 | insigne | 2 |
| 6621 | inseparable | 2 |
| 6622 | insensiblemente | 2 |
| 6623 | insecto | 2 |
| 6624 | inscripción | 2 |
| 6625 | insano | 2 |
| 6626 | inquina | 2 |
| 6627 | inmemorial | 2 |
| 6628 | injerto | 2 |
| 6629 | iniquidad | 2 |
| 6630 | inimitable | 2 |
| 6631 | inicial | 2 |
| 6632 | inhibir | 2 |
| 6633 | inhabitable | 2 |
| 6634 | inglaterra | 2 |
| 6635 | ingénito | 2 |
| 6636 | ingenioso | 2 |
| 6637 | ingeniar | 2 |
| 6638 | ínfula | 2 |
| 6639 | informe | 2 |
| 6640 | inflamar | 2 |
| 6641 | infiltrar | 2 |
| 6642 | infestar | 2 |
| 6643 | infanzones | 2 |
| 6644 | infaliblemente | 2 |
| 6645 | inexperto | 2 |
| 6646 | industrial | 2 |
| 6647 | indiscutible | 2 |
| 6648 | indignidad | 2 |
| 6649 | indicio | 2 |
| 6650 | india | 2 |
| 6651 | indescriptible | 2 |
| 6652 | independiente | 2 |
| 6653 | indefinidamente | 2 |
| 6654 | indefectiblemente | 2 |
| 6655 | indecencia | 2 |
| 6656 | incurrir | 2 |
| 6657 | incruento | 2 |
| 6658 | incomodidad | 2 |
| 6659 | incólume | 2 |
| 6660 | incoherente | 2 |
| 6661 | incógnito | 2 |
| 6662 | incitante | 2 |
| 6663 | incentivo | 2 |
| 6664 | inaugural | 2 |
| 6665 | inaudito | 2 |
| 6666 | impunemente | 2 |
| 6667 | improvisado | 2 |
| 6668 | impreso | 2 |
| 6669 | imprenta | 2 |
| 6670 | importación | 2 |
| 6671 | implícito | 2 |
| 6672 | implícitamente | 2 |
| 6673 | imperturbable | 2 |
| 6674 | imparcialmente | 2 |
| 6675 | imitador | 2 |
| 6676 | imán | 2 |
| 6677 | imaginario | 2 |
| 6678 | igualar | 2 |
| 6679 | idólatra | 2 |
| 6680 | idiotas | 2 |
| 6681 | idéntico | 2 |
| 6682 | iban | 2 |
| 6683 | hurto | 2 |
| 6684 | hurtar | 2 |
| 6685 | hurtadillas | 2 |
| 6686 | humillación | 2 |
| 6687 | humedecer | 2 |
| 6688 | huida | 2 |
| 6689 | huesudo | 2 |
| 6690 | hubiera | 2 |
| 6691 | hoyo | 2 |
| 6692 | hornacina | 2 |
| 6693 | hormiga | 2 |
| 6694 | horizontal | 2 |
| 6695 | horcar | 2 |
| 6696 | hongo | 2 |
| 6697 | hombruno | 2 |
| 6698 | hojear | 2 |
| 6699 | hojalata | 2 |
| 6700 | hizo | 2 |
| 6701 | hisopo | 2 |
| 6702 | hiponax | 2 |
| 6703 | hiperbólico | 2 |
| 6704 | hiel | 2 |
| 6705 | híbrido | 2 |
| 6706 | herodes | 2 |
| 6707 | hermosísima | 2 |
| 6708 | hermosear | 2 |
| 6709 | hermosa | 2 |
| 6710 | herético | 2 |
| 6711 | hércules | 2 |
| 6712 | herbario | 2 |
| 6713 | hechizar | 2 |
| 6714 | hebdomadario | 2 |
| 6715 | hartazgo | 2 |
| 6716 | hartar | 2 |
| 6717 | harina | 2 |
| 6718 | harapo | 2 |
| 6719 | hacinar | 2 |
| 6720 | hachazo | 2 |
| 6721 | hachar | 2 |
| 6722 | habían | 2 |
| 6723 | habano | 2 |
| 6724 | gula | 2 |
| 6725 | guitarra | 2 |
| 6726 | guisa | 2 |
| 6727 | guirnalda | 2 |
| 6728 | guarnición | 2 |
| 6729 | guarda | 2 |
| 6730 | gruta | 2 |
| 6731 | grillete | 2 |
| 6732 | grillera | 2 |
| 6733 | grietar | 2 |
| 6734 | graznar | 2 |
| 6735 | gratuito | 2 |
| 6736 | grasiento | 2 |
| 6737 | grasa | 2 |
| 6738 | granizo | 2 |
| 6739 | grandioso | 2 |
| 6740 | gramática | 2 |
| 6741 | grada | 2 |
| 6742 | gracejo | 2 |
| 6743 | götinga | 2 |
| 6744 | golpear | 2 |
| 6745 | goloso | 2 |
| 6746 | gitano | 2 |
| 6747 | gigantón | 2 |
| 6748 | gigantesco | 2 |
| 6749 | gestar | 2 |
| 6750 | gertrudis | 2 |
| 6751 | geografía | 2 |
| 6752 | generalmente | 2 |
| 6753 | generalizar | 2 |
| 6754 | generalife | 2 |
| 6755 | generalidad | 2 |
| 6756 | gavilán | 2 |
| 6757 | gastrónomo | 2 |
| 6758 | gastronómico | 2 |
| 6759 | gasa | 2 |
| 6760 | garza | 2 |
| 6761 | garrote | 2 |
| 6762 | gañán | 2 |
| 6763 | galón | 2 |
| 6764 | gallego | 2 |
| 6765 | gallardía | 2 |
| 6766 | galápago | 2 |
| 6767 | galanteo | 2 |
| 6768 | furtivo | 2 |
| 6769 | fundir | 2 |
| 6770 | fundación | 2 |
| 6771 | funcionar | 2 |
| 6772 | fulano | 2 |
| 6773 | fugitivo | 2 |
| 6774 | fuero | 2 |
| 6775 | frívolo | 2 |
| 6776 | frenético | 2 |
| 6777 | fragilidad | 2 |
| 6778 | fragancia | 2 |
| 6779 | fortísimo | 2 |
| 6780 | fomento | 2 |
| 6781 | fofo | 2 |
| 6782 | floricultura | 2 |
| 6783 | florete | 2 |
| 6784 | floreciente | 2 |
| 6785 | flora | 2 |
| 6786 | flan | 2 |
| 6787 | flammarion | 2 |
| 6788 | flamante | 2 |
| 6789 | física | 2 |
| 6790 | fiscal | 2 |
| 6791 | firma | 2 |
| 6792 | finísimo | 2 |
| 6793 | filosóficamente | 2 |
| 6794 | filo | 2 |
| 6795 | filípica | 2 |
| 6796 | filigrana | 2 |
| 6797 | filar | 2 |
| 6798 | filantrópico | 2 |
| 6799 | fijeza | 2 |
| 6800 | figurémonos | 2 |
| 6801 | fígaro | 2 |
| 6802 | fieltro | 2 |
| 6803 | ficción | 2 |
| 6804 | feudal | 2 |
| 6805 | festivo | 2 |
| 6806 | fervorosamente | 2 |
| 6807 | férula | 2 |
| 6808 | ferrocarril | 2 |
| 6809 | fernando | 2 |
| 6810 | féretro | 2 |
| 6811 | fenómeno | 2 |
| 6812 | felonía | 2 |
| 6813 | felizmente | 2 |
| 6814 | felipe | 2 |
| 6815 | felino | 2 |
| 6816 | fealdad | 2 |
| 6817 | fé | 2 |
| 6818 | fausto | 2 |
| 6819 | fauces | 2 |
| 6820 | farolero | 2 |
| 6821 | faro | 2 |
| 6822 | fariseo | 2 |
| 6823 | familiarmente | 2 |
| 6824 | faldero | 2 |
| 6825 | faja | 2 |
| 6826 | facultativo | 2 |
| 6827 | facha | 2 |
| 6828 | fabuloso | 2 |
| 6829 | fa | 2 |
| 6830 | extensión | 2 |
| 6831 | extasiar | 2 |
| 6832 | explíquese | 2 |
| 6833 | explícito | 2 |
| 6834 | experimento | 2 |
| 6835 | exótico | 2 |
| 6836 | exordio | 2 |
| 6837 | exorbitante | 2 |
| 6838 | exijo | 2 |
| 6839 | execrable | 2 |
| 6840 | exclusivo | 2 |
| 6841 | excluir | 2 |
| 6842 | excitante | 2 |
| 6843 | excelencia | 2 |
| 6844 | exageradamente | 2 |
| 6845 | evidencia | 2 |
| 6846 | evaporar | 2 |
| 6847 | europeo | 2 |
| 6848 | eunuco | 2 |
| 6849 | eudoro | 2 |
| 6850 | estreno | 2 |
| 6851 | estrenar | 2 |
| 6852 | estrellado | 2 |
| 6853 | estrangular | 2 |
| 6854 | estrada | 2 |
| 6855 | estorbo | 2 |
| 6856 | estimación | 2 |
| 6857 | estima | 2 |
| 6858 | estético | 2 |
| 6859 | estertor | 2 |
| 6860 | estela | 2 |
| 6861 | estas | 2 |
| 6862 | estandarte | 2 |
| 6863 | estancar | 2 |
| 6864 | estampar | 2 |
| 6865 | estampa | 2 |
| 6866 | estamos | 2 |
| 6867 | estambre | 2 |
| 6868 | estados | 2 |
| 6869 | estadística | 2 |
| 6870 | establo | 2 |
| 6871 | esputar | 2 |
| 6872 | esponjar | 2 |
| 6873 | espirar | 2 |
| 6874 | espiga | 2 |
| 6875 | espere | 2 |
| 6876 | esperaba | 2 |
| 6877 | especulación | 2 |
| 6878 | especialista | 2 |
| 6879 | especia | 2 |
| 6880 | esparto | 2 |
| 6881 | espadachín | 2 |
| 6882 | esgrimir | 2 |
| 6883 | esgrima | 2 |
| 6884 | escultural | 2 |
| 6885 | escultura | 2 |
| 6886 | escueto | 2 |
| 6887 | escuelas | 2 |
| 6888 | escudar | 2 |
| 6889 | escritorio | 2 |
| 6890 | escote | 2 |
| 6891 | escotar | 2 |
| 6892 | escobazo | 2 |
| 6893 | escasez | 2 |
| 6894 | escasear | 2 |
| 6895 | escarnio | 2 |
| 6896 | escarceos | 2 |
| 6897 | escandalosamente | 2 |
| 6898 | escalonar | 2 |
| 6899 | escalinata | 2 |
| 6900 | esbirro | 2 |
| 6901 | esas | 2 |
| 6902 | erre | 2 |
| 6903 | eres | 2 |
| 6904 | erard | 2 |
| 6905 | equipaje | 2 |
| 6906 | episodio | 2 |
| 6907 | épico | 2 |
| 6908 | envalentonar | 2 |
| 6909 | enumeración | 2 |
| 6910 | entusiástico | 2 |
| 6911 | entumecido | 2 |
| 6912 | entumecer | 2 |
| 6913 | entrometido | 2 |
| 6914 | entristecer | 2 |
| 6915 | entrevista | 2 |
| 6916 | entrever | 2 |
| 6917 | entremeter | 2 |
| 6918 | entregarla | 2 |
| 6919 | entreacto | 2 |
| 6920 | entreabrir | 2 |
| 6921 | entreabierto | 2 |
| 6922 | entrañable | 2 |
| 6923 | entornado | 2 |
| 6924 | entallado | 2 |
| 6925 | enredo | 2 |
| 6926 | enredadera | 2 |
| 6927 | enlazar | 2 |
| 6928 | enjaular | 2 |
| 6929 | enjambrar | 2 |
| 6930 | enhorabuena | 2 |
| 6931 | engrandecer | 2 |
| 6932 | enfermizo | 2 |
| 6933 | enfático | 2 |
| 6934 | enero | 2 |
| 6935 | energúmeno | 2 |
| 6936 | enérgicamente | 2 |
| 6937 | endiosar | 2 |
| 6938 | encargado | 2 |
| 6939 | encaprichar | 2 |
| 6940 | empresario | 2 |
| 6941 | empotrar | 2 |
| 6942 | emporio | 2 |
| 6943 | empolvar | 2 |
| 6944 | empirismo | 2 |
| 6945 | empezaba | 2 |
| 6946 | empalagar | 2 |
| 6947 | empadronamiento | 2 |
| 6948 | emisario | 2 |
| 6949 | emigrar | 2 |
| 6950 | embrutecer | 2 |
| 6951 | embrollar | 2 |
| 6952 | embozadamente | 2 |
| 6953 | embocadura | 2 |
| 6954 | emancipar | 2 |
| 6955 | elevación | 2 |
| 6956 | elemental | 2 |
| 6957 | elector | 2 |
| 6958 | égida | 2 |
| 6959 | efusión | 2 |
| 6960 | educando | 2 |
| 6961 | educado | 2 |
| 6962 | editor | 2 |
| 6963 | ecbátana | 2 |
| 6964 | dureza | 2 |
| 6965 | dulzón | 2 |
| 6966 | dufour | 2 |
| 6967 | dominicales | 2 |
| 6968 | dominante | 2 |
| 6969 | domicilio | 2 |
| 6970 | domador | 2 |
| 6971 | divulgar | 2 |
| 6972 | divisar | 2 |
| 6973 | disuadir | 2 |
| 6974 | distender | 2 |
| 6975 | dispuesto | 2 |
| 6976 | dispénseme | 2 |
| 6977 | dispensa | 2 |
| 6978 | disimulan | 2 |
| 6979 | disertación | 2 |
| 6980 | disecar | 2 |
| 6981 | discrecional | 2 |
| 6982 | discordante | 2 |
| 6983 | diosa | 2 |
| 6984 | dinamita | 2 |
| 6985 | diminutivo | 2 |
| 6986 | dimensión | 2 |
| 6987 | dime | 2 |
| 6988 | diligente | 2 |
| 6989 | difuso | 2 |
| 6990 | difundir | 2 |
| 6991 | difícilmente | 2 |
| 6992 | diego | 2 |
| 6993 | dieciséis | 2 |
| 6994 | dieciocho | 2 |
| 6995 | diciembre | 2 |
| 6996 | dicharacho | 2 |
| 6997 | dicha | 2 |
| 6998 | diariamente | 2 |
| 6999 | diablillo | 2 |
| 7000 | di | 2 |
| 7001 | detenimiento | 2 |
| 7002 | desvergonzado | 2 |
| 7003 | destruir | 2 |
| 7004 | destierro | 2 |
| 7005 | destemplado | 2 |
| 7006 | desquite | 2 |
| 7007 | despreocupación | 2 |
| 7008 | desprendimiento | 2 |
| 7009 | desprender | 2 |
| 7010 | despreciable | 2 |
| 7011 | déspota | 2 |
| 7012 | desplumar | 2 |
| 7013 | desparramar | 2 |
| 7014 | desparpajo | 2 |
| 7015 | desmenuzar | 2 |
| 7016 | desmejorar | 2 |
| 7017 | desmayo | 2 |
| 7018 | desmadejar | 2 |
| 7019 | deslucir | 2 |
| 7020 | desliz | 2 |
| 7021 | deslenguado | 2 |
| 7022 | desistir | 2 |
| 7023 | designio | 2 |
| 7024 | desfachatado | 2 |
| 7025 | desentonar | 2 |
| 7026 | desengañado | 2 |
| 7027 | desenganchar | 2 |
| 7028 | desenfrenar | 2 |
| 7029 | desencajado | 2 |
| 7030 | desdicha | 2 |
| 7031 | desdeñoso | 2 |
| 7032 | descuento | 2 |
| 7033 | descreer | 2 |
| 7034 | desconsolador | 2 |
| 7035 | desconfiado | 2 |
| 7036 | descomunal | 2 |
| 7037 | descollar | 2 |
| 7038 | descifrar | 2 |
| 7039 | desceñir | 2 |
| 7040 | descaro | 2 |
| 7041 | descarnado | 2 |
| 7042 | descarar | 2 |
| 7043 | descalza | 2 |
| 7044 | desbancar | 2 |
| 7045 | desatino | 2 |
| 7046 | desarrollo | 2 |
| 7047 | desarrollar | 2 |
| 7048 | desahuciar | 2 |
| 7049 | desahogo | 2 |
| 7050 | desafinado | 2 |
| 7051 | derrumbar | 2 |
| 7052 | derredor | 2 |
| 7053 | deplorar | 2 |
| 7054 | departamento | 2 |
| 7055 | demagogo | 2 |
| 7056 | deliquio | 2 |
| 7057 | delincuente | 2 |
| 7058 | delicadísimo | 2 |
| 7059 | deleznable | 2 |
| 7060 | delator | 2 |
| 7061 | déjese | 2 |
| 7062 | déjela | 2 |
| 7063 | déjate | 2 |
| 7064 | dejadme | 2 |
| 7065 | deja | 2 |
| 7066 | degollar | 2 |
| 7067 | definitiva | 2 |
| 7068 | definido | 2 |
| 7069 | definición | 2 |
| 7070 | decreto | 2 |
| 7071 | decorosamente | 2 |
| 7072 | decidido | 2 |
| 7073 | decencia | 2 |
| 7074 | decaer | 2 |
| 7075 | decadente | 2 |
| 7076 | deben | 2 |
| 7077 | debate | 2 |
| 7078 | dardo | 2 |
| 7079 | da | 2 |
| 7080 | curtido | 2 |
| 7081 | cuñado | 2 |
| 7082 | cumplimiento | 2 |
| 7083 | cultura | 2 |
| 7084 | cultivo | 2 |
| 7085 | culminante | 2 |
| 7086 | cuidadosamente | 2 |
| 7087 | cucurucho | 2 |
| 7088 | cuba | 2 |
| 7089 | cuarta | 2 |
| 7090 | cuantía | 2 |
| 7091 | cuán | 2 |
| 7092 | cualquiera | 2 |
| 7093 | cruelmente | 2 |
| 7094 | crucifijo | 2 |
| 7095 | criticar | 2 |
| 7096 | crisóstomo | 2 |
| 7097 | cripta | 2 |
| 7098 | creíase | 2 |
| 7099 | crédulo | 2 |
| 7100 | credulidad | 2 |
| 7101 | crecimiento | 2 |
| 7102 | creciente | 2 |
| 7103 | crasitud | 2 |
| 7104 | costura | 2 |
| 7105 | cosquillas | 2 |
| 7106 | corujedos | 2 |
| 7107 | cortésmente | 2 |
| 7108 | cortaplumas | 2 |
| 7109 | cortado | 2 |
| 7110 | corroborar | 2 |
| 7111 | corresponsal | 2 |
| 7112 | cornucopia | 2 |
| 7113 | cornisa | 2 |
| 7114 | corista | 2 |
| 7115 | cordillera | 2 |
| 7116 | cordialidad | 2 |
| 7117 | coqueta | 2 |
| 7118 | copo | 2 |
| 7119 | copla | 2 |
| 7120 | copioso | 2 |
| 7121 | convenio | 2 |
| 7122 | contraventana | 2 |
| 7123 | contrastar | 2 |
| 7124 | contraer | 2 |
| 7125 | continuó | 2 |
| 7126 | contingentar | 2 |
| 7127 | contertulio | 2 |
| 7128 | contendiente | 2 |
| 7129 | contagiar | 2 |
| 7130 | consumo | 2 |
| 7131 | consulta | 2 |
| 7132 | constituir | 2 |
| 7133 | constipar | 2 |
| 7134 | constelación | 2 |
| 7135 | conste | 2 |
| 7136 | constantemente | 2 |
| 7137 | conspiración | 2 |
| 7138 | consistente | 2 |
| 7139 | consistencia | 2 |
| 7140 | conserva | 2 |
| 7141 | consentimiento | 2 |
| 7142 | consagrado | 2 |
| 7143 | consagración | 2 |
| 7144 | consabido | 2 |
| 7145 | conjeturar | 2 |
| 7146 | conjetura | 2 |
| 7147 | congreso | 2 |
| 7148 | congregar | 2 |
| 7149 | congojar | 2 |
| 7150 | congénere | 2 |
| 7151 | condescendencia | 2 |
| 7152 | concubina | 2 |
| 7153 | concreto | 2 |
| 7154 | concordia | 2 |
| 7155 | conclusión | 2 |
| 7156 | concha | 2 |
| 7157 | comunicativo | 2 |
| 7158 | comte | 2 |
| 7159 | compromisario | 2 |
| 7160 | comprobar | 2 |
| 7161 | comprende | 2 |
| 7162 | complexión | 2 |
| 7163 | completar | 2 |
| 7164 | compartir | 2 |
| 7165 | comparecer | 2 |
| 7166 | comparable | 2 |
| 7167 | compadre | 2 |
| 7168 | cómodamente | 2 |
| 7169 | cometido | 2 |
| 7170 | comensal | 2 |
| 7171 | combate | 2 |
| 7172 | comadrona | 2 |
| 7173 | columpiar | 2 |
| 7174 | coloso | 2 |
| 7175 | coloquio | 2 |
| 7176 | colón | 2 |
| 7177 | coliseo | 2 |
| 7178 | colegial | 2 |
| 7179 | coleccionador | 2 |
| 7180 | colapso | 2 |
| 7181 | colación | 2 |
| 7182 | coincidencia | 2 |
| 7183 | cohecho | 2 |
| 7184 | coetáneo | 2 |
| 7185 | codillo | 2 |
| 7186 | cocinar | 2 |
| 7187 | cobardía | 2 |
| 7188 | cliente | 2 |
| 7189 | clavel | 2 |
| 7190 | clasificar | 2 |
| 7191 | clarisas | 2 |
| 7192 | clarinete | 2 |
| 7193 | clarín | 2 |
| 7194 | clandestino | 2 |
| 7195 | clac | 2 |
| 7196 | cirino | 2 |
| 7197 | circulante | 2 |
| 7198 | circulación | 2 |
| 7199 | cinto | 2 |
| 7200 | cinismo | 2 |
| 7201 | cinegético | 2 |
| 7202 | cigarra | 2 |
| 7203 | cierre | 2 |
| 7204 | cielos | 2 |
| 7205 | ciegamente | 2 |
| 7206 | chusma | 2 |
| 7207 | chulo | 2 |
| 7208 | chito | 2 |
| 7209 | chisporrotear | 2 |
| 7210 | chiripa | 2 |
| 7211 | chiquito | 2 |
| 7212 | chinto | 2 |
| 7213 | chinesco | 2 |
| 7214 | chica | 2 |
| 7215 | chasquido | 2 |
| 7216 | chascarrillo | 2 |
| 7217 | chaquetar | 2 |
| 7218 | chaqueta | 2 |
| 7219 | césar | 2 |
| 7220 | cerril | 2 |
| 7221 | cerrados | 2 |
| 7222 | cerebral | 2 |
| 7223 | cerbatana | 2 |
| 7224 | cepillo | 2 |
| 7225 | ceñudo | 2 |
| 7226 | central | 2 |
| 7227 | céntimo | 2 |
| 7228 | censor | 2 |
| 7229 | celoso | 2 |
| 7230 | celibato | 2 |
| 7231 | cédula | 2 |
| 7232 | cebo | 2 |
| 7233 | cavador | 2 |
| 7234 | cauterio | 2 |
| 7235 | caudal | 2 |
| 7236 | catolicismo | 2 |
| 7237 | categoría | 2 |
| 7238 | catar | 2 |
| 7239 | catafalco | 2 |
| 7240 | cataclismo | 2 |
| 7241 | casual | 2 |
| 7242 | castañuelo | 2 |
| 7243 | castaña | 2 |
| 7244 | casos | 2 |
| 7245 | caserío | 2 |
| 7246 | casería | 2 |
| 7247 | carvajal | 2 |
| 7248 | carretero | 2 |
| 7249 | carnoso | 2 |
| 7250 | carnaza | 2 |
| 7251 | carita | 2 |
| 7252 | caricatura | 2 |
| 7253 | cargante | 2 |
| 7254 | cargamento | 2 |
| 7255 | cargado | 2 |
| 7256 | carecer | 2 |
| 7257 | cardo | 2 |
| 7258 | caramelo | 2 |
| 7259 | carámbano | 2 |
| 7260 | carabinar | 2 |
| 7261 | capón | 2 |
| 7262 | cañonazo | 2 |
| 7263 | cántaro | 2 |
| 7264 | cándido | 2 |
| 7265 | candelabro | 2 |
| 7266 | canal | 2 |
| 7267 | campesino | 2 |
| 7268 | campechano | 2 |
| 7269 | camarero | 2 |
| 7270 | cámara | 2 |
| 7271 | calzón | 2 |
| 7272 | calumnioso | 2 |
| 7273 | callejero | 2 |
| 7274 | califa | 2 |
| 7275 | calenturiento | 2 |
| 7276 | calderoniano | 2 |
| 7277 | calatayud | 2 |
| 7278 | cacique | 2 |
| 7279 | cachete | 2 |
| 7280 | cachazudo | 2 |
| 7281 | cacharro | 2 |
| 7282 | cabra | 2 |
| 7283 | cabellera | 2 |
| 7284 | cabe | 2 |
| 7285 | caballeroso | 2 |
| 7286 | caballerito | 2 |
| 7287 | cabal | 2 |
| 7288 | buscaba | 2 |
| 7289 | burlador | 2 |
| 7290 | buque | 2 |
| 7291 | bum | 2 |
| 7292 | bula | 2 |
| 7293 | bufanda | 2 |
| 7294 | bucólica | 2 |
| 7295 | bruscamente | 2 |
| 7296 | brindis | 2 |
| 7297 | brigadier | 2 |
| 7298 | brevedad | 2 |
| 7299 | breña | 2 |
| 7300 | bramido | 2 |
| 7301 | botonar | 2 |
| 7302 | bote | 2 |
| 7303 | botar | 2 |
| 7304 | bostezo | 2 |
| 7305 | borrego | 2 |
| 7306 | borrasca | 2 |
| 7307 | borde | 2 |
| 7308 | boquiabierto | 2 |
| 7309 | bonete | 2 |
| 7310 | bombo | 2 |
| 7311 | bomba | 2 |
| 7312 | bodega | 2 |
| 7313 | bochornoso | 2 |
| 7314 | bochorno | 2 |
| 7315 | blandir | 2 |
| 7316 | blanca | 2 |
| 7317 | biografía | 2 |
| 7318 | billete | 2 |
| 7319 | bienquistar | 2 |
| 7320 | bernesga | 2 |
| 7321 | benito | 2 |
| 7322 | benavides | 2 |
| 7323 | beatífico | 2 |
| 7324 | bazar | 2 |
| 7325 | batista | 2 |
| 7326 | batallón | 2 |
| 7327 | batacazo | 2 |
| 7328 | bastear | 2 |
| 7329 | base | 2 |
| 7330 | barroco | 2 |
| 7331 | barrenar | 2 |
| 7332 | barragana | 2 |
| 7333 | barnizar | 2 |
| 7334 | barbilindo | 2 |
| 7335 | barbaridad | 2 |
| 7336 | bandeja | 2 |
| 7337 | balduque | 2 |
| 7338 | baldar | 2 |
| 7339 | balbucear | 2 |
| 7340 | balanceo | 2 |
| 7341 | bajeza | 2 |
| 7342 | bajero | 2 |
| 7343 | bailé | 2 |
| 7344 | báculo | 2 |
| 7345 | baco | 2 |
| 7346 | babucha | 2 |
| 7347 | babilónico | 2 |
| 7348 | b | 2 |
| 7349 | azor | 2 |
| 7350 | azafranado | 2 |
| 7351 | axioma | 2 |
| 7352 | avizor | 2 |
| 7353 | averiar | 2 |
| 7354 | aventurado | 2 |
| 7355 | avaro | 2 |
| 7356 | autonomía | 2 |
| 7357 | automático | 2 |
| 7358 | auricular | 2 |
| 7359 | aunar | 2 |
| 7360 | atusar | 2 |
| 7361 | atropello | 2 |
| 7362 | atribulado | 2 |
| 7363 | atónito | 2 |
| 7364 | átomo | 2 |
| 7365 | atolondramiento | 2 |
| 7366 | atizar | 2 |
| 7367 | atestar | 2 |
| 7368 | atesorar | 2 |
| 7369 | atentado | 2 |
| 7370 | atañer | 2 |
| 7371 | atado | 2 |
| 7372 | asustadizo | 2 |
| 7373 | asfixia | 2 |
| 7374 | aserto | 2 |
| 7375 | ascua | 2 |
| 7376 | asceta | 2 |
| 7377 | asar | 2 |
| 7378 | artificio | 2 |
| 7379 | artífice | 2 |
| 7380 | articulista | 2 |
| 7381 | artesonar | 2 |
| 7382 | artesón | 2 |
| 7383 | arrugado | 2 |
| 7384 | arruga | 2 |
| 7385 | arrogancia | 2 |
| 7386 | arroba | 2 |
| 7387 | arrinconado | 2 |
| 7388 | arremolinar | 2 |
| 7389 | arrellanar | 2 |
| 7390 | arreglo | 2 |
| 7391 | aromático | 2 |
| 7392 | árnica | 2 |
| 7393 | armónica | 2 |
| 7394 | armisticio | 2 |
| 7395 | armería | 2 |
| 7396 | armatoste | 2 |
| 7397 | arisco | 2 |
| 7398 | ariscar | 2 |
| 7399 | argentino | 2 |
| 7400 | areo | 2 |
| 7401 | arenar | 2 |
| 7402 | arenal | 2 |
| 7403 | área | 2 |
| 7404 | arcadia | 2 |
| 7405 | arboricultura | 2 |
| 7406 | arboleda | 2 |
| 7407 | árbitro | 2 |
| 7408 | arañazo | 2 |
| 7409 | arabesco | 2 |
| 7410 | aquiles | 2 |
| 7411 | aquellos | 2 |
| 7412 | apurado | 2 |
| 7413 | apuesto | 2 |
| 7414 | apuesta | 2 |
| 7415 | aprisionar | 2 |
| 7416 | aprendiz | 2 |
| 7417 | aprecio | 2 |
| 7418 | apoteosis | 2 |
| 7419 | apóstata | 2 |
| 7420 | apostasía | 2 |
| 7421 | aplomo | 2 |
| 7422 | apiñado | 2 |
| 7423 | apiadar | 2 |
| 7424 | apellidar | 2 |
| 7425 | aparentemente | 2 |
| 7426 | añadía | 2 |
| 7427 | anzuelo | 2 |
| 7428 | anuncio | 2 |
| 7429 | antonomasia | 2 |
| 7430 | antonio | 2 |
| 7431 | antitético | 2 |
| 7432 | antinomia | 2 |
| 7433 | anticuar | 2 |
| 7434 | antecesor | 2 |
| 7435 | annatas | 2 |
| 7436 | aniversario | 2 |
| 7437 | aniquilamiento | 2 |
| 7438 | animador | 2 |
| 7439 | angelina | 2 |
| 7440 | angelical | 2 |
| 7441 | anfiteatro | 2 |
| 7442 | anfibio | 2 |
| 7443 | andrajo | 2 |
| 7444 | andén | 2 |
| 7445 | andamiaje | 2 |
| 7446 | anchura | 2 |
| 7447 | anatomía | 2 |
| 7448 | analogía | 2 |
| 7449 | amorosamente | 2 |
| 7450 | amoratar | 2 |
| 7451 | ambrosio | 2 |
| 7452 | ámbito | 2 |
| 7453 | ambientar | 2 |
| 7454 | amazona | 2 |
| 7455 | amargor | 2 |
| 7456 | amago | 2 |
| 7457 | amagar | 2 |
| 7458 | amador | 2 |
| 7459 | álvaro | 2 |
| 7460 | alvarín | 2 |
| 7461 | alucinación | 2 |
| 7462 | alternativamente | 2 |
| 7463 | altercar | 2 |
| 7464 | alquiler | 2 |
| 7465 | almohadillado | 2 |
| 7466 | almohadilla | 2 |
| 7467 | almidonar | 2 |
| 7468 | almacenar | 2 |
| 7469 | almacén | 2 |
| 7470 | alinear | 2 |
| 7471 | alhambra | 2 |
| 7472 | alhaja | 2 |
| 7473 | alguna | 2 |
| 7474 | alemán | 2 |
| 7475 | aleluya | 2 |
| 7476 | alejandro | 2 |
| 7477 | alejandría | 2 |
| 7478 | aleación | 2 |
| 7479 | aldabonazo | 2 |
| 7480 | aldabón | 2 |
| 7481 | alcoholismo | 2 |
| 7482 | alborotador | 2 |
| 7483 | alambre | 2 |
| 7484 | alambicado | 2 |
| 7485 | alacena | 2 |
| 7486 | ajar | 2 |
| 7487 | aislamiento | 2 |
| 7488 | ahondar | 2 |
| 7489 | aguzar | 2 |
| 7490 | agudeza | 2 |
| 7491 | agrietado | 2 |
| 7492 | agridulce | 2 |
| 7493 | agregado | 2 |
| 7494 | agitar | 2 |
| 7495 | agitado | 2 |
| 7496 | agente | 2 |
| 7497 | aforismo | 2 |
| 7498 | afligido | 2 |
| 7499 | afeminar | 2 |
| 7500 | afeminamiento | 2 |
| 7501 | afeminado | 2 |
| 7502 | afeitar | 2 |
| 7503 | afectuoso | 2 |
| 7504 | afabilidad | 2 |
| 7505 | advirtió | 2 |
| 7506 | advertencia | 2 |
| 7507 | adulación | 2 |
| 7508 | adormecer | 2 |
| 7509 | adoptar | 2 |
| 7510 | adocenado | 2 |
| 7511 | admirador | 2 |
| 7512 | administrar | 2 |
| 7513 | adentro | 2 |
| 7514 | adaptación | 2 |
| 7515 | adán | 2 |
| 7516 | actualmente | 2 |
| 7517 | actualidad | 2 |
| 7518 | activar | 2 |
| 7519 | acreditar | 2 |
| 7520 | acorde | 2 |
| 7521 | acontecer | 2 |
| 7522 | acompasar | 2 |
| 7523 | acomodo | 2 |
| 7524 | acomodar | 2 |
| 7525 | aclimatar | 2 |
| 7526 | achicar | 2 |
| 7527 | achaparrar | 2 |
| 7528 | achacoso | 2 |
| 7529 | acequia | 2 |
| 7530 | acelerar | 2 |
| 7531 | acallar | 2 |
| 7532 | aburren | 2 |
| 7533 | abstinencia | 2 |
| 7534 | absorber | 2 |
| 7535 | absorbente | 2 |
| 7536 | abroño | 2 |
| 7537 | abrió | 2 |
| 7538 | abominar | 2 |
| 7539 | abogado | 2 |
| 7540 | abdomen | 2 |
| 7541 | abdicar | 2 |
| 7542 | abarcar | 2 |
| 7543 | abanicar | 2 |
| 7544 | zurriago | 1 |
| 7545 | zurriagazo | 1 |
| 7546 | zurcir | 1 |
| 7547 | zurcido | 1 |
| 7548 | zurbarán | 1 |
| 7549 | zumarri | 1 |
| 7550 | zuavo | 1 |
| 7551 | zozobra | 1 |
| 7552 | zoológico | 1 |
| 7553 | zona | 1 |
| 7554 | zodiaco | 1 |
| 7555 | zascandil | 1 |
| 7556 | zas | 1 |
| 7557 | zarzaparrilla | 1 |
| 7558 | zarpar | 1 |
| 7559 | zarandaja | 1 |
| 7560 | zaquizamí | 1 |
| 7561 | zancadilla | 1 |
| 7562 | zambullir | 1 |
| 7563 | zamarra | 1 |
| 7564 | zamacois | 1 |
| 7565 | zafio | 1 |
| 7566 | yodo | 1 |
| 7567 | yema | 1 |
| 7568 | xxx | 1 |
| 7569 | xxviii | 1 |
| 7570 | xxvii | 1 |
| 7571 | xxvi | 1 |
| 7572 | xxv | 1 |
| 7573 | xxix | 1 |
| 7574 | xxiv | 1 |
| 7575 | xxiii | 1 |
| 7576 | xxii | 1 |
| 7577 | xxi | 1 |
| 7578 | xx | 1 |
| 7579 | xviii | 1 |
| 7580 | xvii | 1 |
| 7581 | xvi | 1 |
| 7582 | xix | 1 |
| 7583 | xiii | 1 |
| 7584 | xii | 1 |
| 7585 | xi | 1 |
| 7586 | wisseman | 1 |
| 7587 | wieland | 1 |
| 7588 | vulgarmente | 1 |
| 7589 | vuélvete | 1 |
| 7590 | vox | 1 |
| 7591 | vosotros | 1 |
| 7592 | vosotras | 1 |
| 7593 | volvía | 1 |
| 7594 | volveré | 1 |
| 7595 | voluta | 1 |
| 7596 | voluntario | 1 |
| 7597 | voluminoso | 1 |
| 7598 | vogt | 1 |
| 7599 | voces | 1 |
| 7600 | vocal | 1 |
| 7601 | vocablo | 1 |
| 7602 | vizconde | 1 |
| 7603 | vivirá | 1 |
| 7604 | vivimos | 1 |
| 7605 | vividor | 1 |
| 7606 | vive | 1 |
| 7607 | vituperar | 1 |
| 7608 | vitriolo | 1 |
| 7609 | vitrina | 1 |
| 7610 | vitando | 1 |
| 7611 | vitalidad | 1 |
| 7612 | vitalicio | 1 |
| 7613 | vislumbre | 1 |
| 7614 | visitaciones | 1 |
| 7615 | visionario | 1 |
| 7616 | visiblemente | 1 |
| 7617 | visera | 1 |
| 7618 | viseo | 1 |
| 7619 | vis | 1 |
| 7620 | viruela | 1 |
| 7621 | virilidad | 1 |
| 7622 | virchov | 1 |
| 7623 | viola | 1 |
| 7624 | vinader | 1 |
| 7625 | villavieja | 1 |
| 7626 | villancico | 1 |
| 7627 | villafranca | 1 |
| 7628 | villa | 1 |
| 7629 | vigorizar | 1 |
| 7630 | vigente | 1 |
| 7631 | vientecillo | 1 |
| 7632 | vienes | 1 |
| 7633 | viena | 1 |
| 7634 | vidrioso | 1 |
| 7635 | vidente | 1 |
| 7636 | victis | 1 |
| 7637 | vicepresidente | 1 |
| 7638 | víbora | 1 |
| 7639 | viático | 1 |
| 7640 | viable | 1 |
| 7641 | vi | 1 |
| 7642 | vestusta | 1 |
| 7643 | vestuario | 1 |
| 7644 | vestimenta | 1 |
| 7645 | vespucios | 1 |
| 7646 | vértigo | 1 |
| 7647 | vertiente | 1 |
| 7648 | vertedero | 1 |
| 7649 | versión | 1 |
| 7650 | versículo | 1 |
| 7651 | versalles | 1 |
| 7652 | veritas | 1 |
| 7653 | verificar | 1 |
| 7654 | veríamos | 1 |
| 7655 | veremundo | 1 |
| 7656 | verdulera | 1 |
| 7657 | verdoso | 1 |
| 7658 | verdinegro | 1 |
| 7659 | verbosidad | 1 |
| 7660 | verbo | 1 |
| 7661 | verbigracia | 1 |
| 7662 | veranillo | 1 |
| 7663 | veraniego | 1 |
| 7664 | veraneo | 1 |
| 7665 | veo | 1 |
| 7666 | ventrílocuo | 1 |
| 7667 | ventero | 1 |
| 7668 | ventar | 1 |
| 7669 | ventanillo | 1 |
| 7670 | venta | 1 |
| 7671 | venidero | 1 |
| 7672 | vengo | 1 |
| 7673 | vengábase | 1 |
| 7674 | venerar | 1 |
| 7675 | venerando | 1 |
| 7676 | veneciano | 1 |
| 7677 | venecia | 1 |
| 7678 | vendrás | 1 |
| 7679 | vendrán | 1 |
| 7680 | vendrá | 1 |
| 7681 | venal | 1 |
| 7682 | velón | 1 |
| 7683 | vellón | 1 |
| 7684 | veleidoso | 1 |
| 7685 | veleidades | 1 |
| 7686 | velado | 1 |
| 7687 | vejamen | 1 |
| 7688 | veintitrés | 1 |
| 7689 | veíalo | 1 |
| 7690 | veíala | 1 |
| 7691 | veía | 1 |
| 7692 | vehículo | 1 |
| 7693 | vehemencia | 1 |
| 7694 | veguellinas | 1 |
| 7695 | vegetación | 1 |
| 7696 | vegallanas | 1 |
| 7697 | vedado | 1 |
| 7698 | véase | 1 |
| 7699 | veamos | 1 |
| 7700 | vea | 1 |
| 7701 | váyase | 1 |
| 7702 | vauban | 1 |
| 7703 | vate | 1 |
| 7704 | vasto | 1 |
| 7705 | vástago | 1 |
| 7706 | vasar | 1 |
| 7707 | vas | 1 |
| 7708 | variante | 1 |
| 7709 | variación | 1 |
| 7710 | vampiro | 1 |
| 7711 | vallar | 1 |
| 7712 | valetudinario | 1 |
| 7713 | valera | 1 |
| 7714 | valdiñón | 1 |
| 7715 | vaivén | 1 |
| 7716 | vaina | 1 |
| 7717 | vae | 1 |
| 7718 | uva | 1 |
| 7719 | utrecht | 1 |
| 7720 | utensilio | 1 |
| 7721 | usurpador | 1 |
| 7722 | usura | 1 |
| 7723 | usual | 1 |
| 7724 | usado | 1 |
| 7725 | urdir | 1 |
| 7726 | urbanidad | 1 |
| 7727 | unto | 1 |
| 7728 | unos | 1 |
| 7729 | universidades | 1 |
| 7730 | unísono | 1 |
| 7731 | uniformar | 1 |
| 7732 | unido | 1 |
| 7733 | uníase | 1 |
| 7734 | unas | 1 |
| 7735 | ultratelúrica | 1 |
| 7736 | ultramontanismo | 1 |
| 7737 | ulloa | 1 |
| 7738 | ujier | 1 |
| 7739 | tuy | 1 |
| 7740 | tuvo | 1 |
| 7741 | tutor | 1 |
| 7742 | tutela | 1 |
| 7743 | tute | 1 |
| 7744 | turquía | 1 |
| 7745 | turbante | 1 |
| 7746 | turbamulta | 1 |
| 7747 | túnel | 1 |
| 7748 | tumba | 1 |
| 7749 | tugurio | 1 |
| 7750 | tufillo | 1 |
| 7751 | tuerca | 1 |
| 7752 | tuberculosis | 1 |
| 7753 | truncado | 1 |
| 7754 | trozo | 1 |
| 7755 | troya | 1 |
| 7756 | trovadores | 1 |
| 7757 | trotaconventos | 1 |
| 7758 | tropo | 1 |
| 7759 | tropezones | 1 |
| 7760 | tropel | 1 |
| 7761 | trono | 1 |
| 7762 | tronada | 1 |
| 7763 | trompetear | 1 |
| 7764 | trompa | 1 |
| 7765 | trocito | 1 |
| 7766 | triunfal | 1 |
| 7767 | tristemente | 1 |
| 7768 | triple | 1 |
| 7769 | trinchera | 1 |
| 7770 | trinchante | 1 |
| 7771 | trimestre | 1 |
| 7772 | trifoncito | 1 |
| 7773 | trifoncillo | 1 |
| 7774 | tridentino | 1 |
| 7775 | tribu | 1 |
| 7776 | triángulo | 1 |
| 7777 | trepidación | 1 |
| 7778 | trenzar | 1 |
| 7779 | trena | 1 |
| 7780 | tratable | 1 |
| 7781 | trasvolar | 1 |
| 7782 | trasunto | 1 |
| 7783 | traslucir | 1 |
| 7784 | trascender | 1 |
| 7785 | trascendencia | 1 |
| 7786 | traquetear | 1 |
| 7787 | trapacero | 1 |
| 7788 | tranvía | 1 |
| 7789 | transportar | 1 |
| 7790 | transmitir | 1 |
| 7791 | tránsito | 1 |
| 7792 | transición | 1 |
| 7793 | transformismo | 1 |
| 7794 | transcurrir | 1 |
| 7795 | tranquilícese | 1 |
| 7796 | tramposo | 1 |
| 7797 | tramo | 1 |
| 7798 | tralla | 1 |
| 7799 | tragarse | 1 |
| 7800 | tragaluz | 1 |
| 7801 | traerlos | 1 |
| 7802 | tráeme | 1 |
| 7803 | traductor | 1 |
| 7804 | tradicionalmente | 1 |
| 7805 | trabilla | 1 |
| 7806 | torvo | 1 |
| 7807 | torturar | 1 |
| 7808 | torrentes | 1 |
| 7809 | torpemente | 1 |
| 7810 | tornasolar | 1 |
| 7811 | tornar | 1 |
| 7812 | tornadizo | 1 |
| 7813 | torcuato | 1 |
| 7814 | torcedor | 1 |
| 7815 | toral | 1 |
| 7816 | toraces | 1 |
| 7817 | toque | 1 |
| 7818 | topetazo | 1 |
| 7819 | tontunas | 1 |
| 7820 | tontina | 1 |
| 7821 | tonta | 1 |
| 7822 | tonillo | 1 |
| 7823 | ton | 1 |
| 7824 | tole | 1 |
| 7825 | tocado | 1 |
| 7826 | toca | 1 |
| 7827 | tobillo | 1 |
| 7828 | tizne | 1 |
| 7829 | titulado | 1 |
| 7830 | titubear | 1 |
| 7831 | tito | 1 |
| 7832 | titilar | 1 |
| 7833 | títere | 1 |
| 7834 | tirotear | 1 |
| 7835 | tiritar | 1 |
| 7836 | tirilla | 1 |
| 7837 | tiránico | 1 |
| 7838 | tirada | 1 |
| 7839 | tira | 1 |
| 7840 | tiple | 1 |
| 7841 | tímpano | 1 |
| 7842 | tiempos | 1 |
| 7843 | tiemblan | 1 |
| 7844 | tiburón | 1 |
| 7845 | thackeray | 1 |
| 7846 | tétrico | 1 |
| 7847 | tetrarca | 1 |
| 7848 | testimoniar | 1 |
| 7849 | tesar | 1 |
| 7850 | terruño | 1 |
| 7851 | terrorista | 1 |
| 7852 | territorio | 1 |
| 7853 | terpsícore | 1 |
| 7854 | terneza | 1 |
| 7855 | termómetro | 1 |
| 7856 | términos | 1 |
| 7857 | terminantemente | 1 |
| 7858 | terminación | 1 |
| 7859 | tergiversar | 1 |
| 7860 | terceto | 1 |
| 7861 | tercero | 1 |
| 7862 | terapéutica | 1 |
| 7863 | teócrito | 1 |
| 7864 | teocrático | 1 |
| 7865 | tentáculo | 1 |
| 7866 | teniente | 1 |
| 7867 | tenían | 1 |
| 7868 | tengo | 1 |
| 7869 | tenebroso | 1 |
| 7870 | tendré | 1 |
| 7871 | tenaz | 1 |
| 7872 | templete | 1 |
| 7873 | templanza | 1 |
| 7874 | tempé | 1 |
| 7875 | temo | 1 |
| 7876 | temía | 1 |
| 7877 | temerón | 1 |
| 7878 | temblábale | 1 |
| 7879 | telescopio | 1 |
| 7880 | telegrama | 1 |
| 7881 | tejido | 1 |
| 7882 | tejer | 1 |
| 7883 | tejadillo | 1 |
| 7884 | tecnicismo | 1 |
| 7885 | tecla | 1 |
| 7886 | techar | 1 |
| 7887 | teatral | 1 |
| 7888 | taurina | 1 |
| 7889 | tasso | 1 |
| 7890 | tascar | 1 |
| 7891 | tartana | 1 |
| 7892 | tarso | 1 |
| 7893 | tarsilita | 1 |
| 7894 | tarascar | 1 |
| 7895 | taparelli | 1 |
| 7896 | tapado | 1 |
| 7897 | tapa | 1 |
| 7898 | tañido | 1 |
| 7899 | tantas | 1 |
| 7900 | tamizar | 1 |
| 7901 | tamiz | 1 |
| 7902 | tamboril | 1 |
| 7903 | tamañitos | 1 |
| 7904 | tallo | 1 |
| 7905 | tallar | 1 |
| 7906 | tallado | 1 |
| 7907 | talismán | 1 |
| 7908 | talega | 1 |
| 7909 | tajo | 1 |
| 7910 | taigeto | 1 |
| 7911 | tahúr | 1 |
| 7912 | tagarnina | 1 |
| 7913 | tafetán | 1 |
| 7914 | taconeo | 1 |
| 7915 | tácitamente | 1 |
| 7916 | tacita | 1 |
| 7917 | tacha | 1 |
| 7918 | tacaño | 1 |
| 7919 | tablilla | 1 |
| 7920 | tabicar | 1 |
| 7921 | tabernáculo | 1 |
| 7922 | suya | 1 |
| 7923 | sutilísimo | 1 |
| 7924 | sustraer | 1 |
| 7925 | sustancia | 1 |
| 7926 | suspira | 1 |
| 7927 | suspicacia | 1 |
| 7928 | suspensión | 1 |
| 7929 | susodicho | 1 |
| 7930 | suscripción | 1 |
| 7931 | supremacía | 1 |
| 7932 | suposición | 1 |
| 7933 | suponiendo | 1 |
| 7934 | suplicio | 1 |
| 7935 | superfino | 1 |
| 7936 | superficialidad | 1 |
| 7937 | superficial | 1 |
| 7938 | suntuoso | 1 |
| 7939 | suministrar | 1 |
| 7940 | sumergido | 1 |
| 7941 | sumar | 1 |
| 7942 | sulfurar | 1 |
| 7943 | suizo | 1 |
| 7944 | suicidar | 1 |
| 7945 | suicida | 1 |
| 7946 | sufrido | 1 |
| 7947 | sufre | 1 |
| 7948 | sufragio | 1 |
| 7949 | suegro | 1 |
| 7950 | suecia | 1 |
| 7951 | sudario | 1 |
| 7952 | sucursal | 1 |
| 7953 | sucumbiría | 1 |
| 7954 | sucesivamente | 1 |
| 7955 | subvencionar | 1 |
| 7956 | suburbio | 1 |
| 7957 | subterfugio | 1 |
| 7958 | subteniente | 1 |
| 7959 | subsuelo | 1 |
| 7960 | subsistir | 1 |
| 7961 | subjetivar | 1 |
| 7962 | súbito | 1 |
| 7963 | subió | 1 |
| 7964 | subido | 1 |
| 7965 | subida | 1 |
| 7966 | súbdito | 1 |
| 7967 | subalterno | 1 |
| 7968 | strauss | 1 |
| 7969 | stoa | 1 |
| 7970 | sport | 1 |
| 7971 | spirto | 1 |
| 7972 | spínolas | 1 |
| 7973 | sousa | 1 |
| 7974 | sostenido | 1 |
| 7975 | sosiego | 1 |
| 7976 | sortear | 1 |
| 7977 | sordomudo | 1 |
| 7978 | sordina | 1 |
| 7979 | sorbo | 1 |
| 7980 | sorbete | 1 |
| 7981 | soportar | 1 |
| 7982 | soportable | 1 |
| 7983 | sopar | 1 |
| 7984 | soñado | 1 |
| 7985 | sonrojar | 1 |
| 7986 | soneto | 1 |
| 7987 | sonda | 1 |
| 7988 | sonado | 1 |
| 7989 | somieda | 1 |
| 7990 | solterón | 1 |
| 7991 | soltera | 1 |
| 7992 | soliviantar | 1 |
| 7993 | solideo | 1 |
| 7994 | solidaridad | 1 |
| 7995 | solicitación | 1 |
| 7996 | solía | 1 |
| 7997 | solfear | 1 |
| 7998 | solecismo | 1 |
| 7999 | solazar | 1 |
| 8000 | solapado | 1 |
| 8001 | solamente | 1 |
| 8002 | soga | 1 |
| 8003 | sofocación | 1 |
| 8004 | sofión | 1 |
| 8005 | socorrido | 1 |
| 8006 | socialismo | 1 |
| 8007 | sociable | 1 |
| 8008 | sochantre | 1 |
| 8009 | sobrón | 1 |
| 8010 | sobrevenir | 1 |
| 8011 | sobrenadar | 1 |
| 8012 | sobremesa | 1 |
| 8013 | sobrehumano | 1 |
| 8014 | sobradamente | 1 |
| 8015 | soberanía | 1 |
| 8016 | sobar | 1 |
| 8017 | sobaco | 1 |
| 8018 | sixto | 1 |
| 8019 | sitial | 1 |
| 8020 | sistemática | 1 |
| 8021 | sisar | 1 |
| 8022 | sisa | 1 |
| 8023 | siria | 1 |
| 8024 | sinuosidad | 1 |
| 8025 | sintió | 1 |
| 8026 | sintetizar | 1 |
| 8027 | síntesis | 1 |
| 8028 | sinrazón | 1 |
| 8029 | sinónimo | 1 |
| 8030 | singularísimo | 1 |
| 8031 | sinapismo | 1 |
| 8032 | simular | 1 |
| 8033 | simplicidad | 1 |
| 8034 | simplemente | 1 |
| 8035 | símil | 1 |
| 8036 | simiente | 1 |
| 8037 | simetría | 1 |
| 8038 | simeón | 1 |
| 8039 | simbolismo | 1 |
| 8040 | simancas | 1 |
| 8041 | sima | 1 |
| 8042 | silva | 1 |
| 8043 | sillería | 1 |
| 8044 | sillar | 1 |
| 8045 | sigiloso | 1 |
| 8046 | sierpe | 1 |
| 8047 | siendo | 1 |
| 8048 | shakespeare | 1 |
| 8049 | sexta | 1 |
| 8050 | sevillano | 1 |
| 8051 | sesgar | 1 |
| 8052 | sesentón | 1 |
| 8053 | servilmente | 1 |
| 8054 | servilletero | 1 |
| 8055 | servil | 1 |
| 8056 | servicial | 1 |
| 8057 | serrallo | 1 |
| 8058 | serpiente | 1 |
| 8059 | serón | 1 |
| 8060 | sermones | 1 |
| 8061 | serie | 1 |
| 8062 | serán | 1 |
| 8063 | sepárese | 1 |
| 8064 | separado | 1 |
| 8065 | señorial | 1 |
| 8066 | sentía | 1 |
| 8067 | sentado | 1 |
| 8068 | sensualista | 1 |
| 8069 | sensualismo | 1 |
| 8070 | sensualidad | 1 |
| 8071 | sensiblería | 1 |
| 8072 | sensatamente | 1 |
| 8073 | senil | 1 |
| 8074 | sempiterno | 1 |
| 8075 | semillero | 1 |
| 8076 | semicírculo | 1 |
| 8077 | semicientífico | 1 |
| 8078 | semental | 1 |
| 8079 | sembrado | 1 |
| 8080 | selvático | 1 |
| 8081 | selva | 1 |
| 8082 | segura | 1 |
| 8083 | segadora | 1 |
| 8084 | sedoso | 1 |
| 8085 | sediento | 1 |
| 8086 | sedentarismo | 1 |
| 8087 | secundario | 1 |
| 8088 | secularización | 1 |
| 8089 | secuestrar | 1 |
| 8090 | secuestrador | 1 |
| 8091 | secuentia | 1 |
| 8092 | secretario | 1 |
| 8093 | secretaría | 1 |
| 8094 | secretamente | 1 |
| 8095 | sección | 1 |
| 8096 | secchi | 1 |
| 8097 | sebastopol | 1 |
| 8098 | sebastián | 1 |
| 8099 | sazonar | 1 |
| 8100 | sayón | 1 |
| 8101 | saturnillo | 1 |
| 8102 | saturación | 1 |
| 8103 | satírico | 1 |
| 8104 | sátira | 1 |
| 8105 | satinado | 1 |
| 8106 | satín | 1 |
| 8107 | satén | 1 |
| 8108 | satánico | 1 |
| 8109 | satán | 1 |
| 8110 | sastrería | 1 |
| 8111 | sarraceno | 1 |
| 8112 | sardou | 1 |
| 8113 | sardónico | 1 |
| 8114 | sarcástico | 1 |
| 8115 | saquear | 1 |
| 8116 | sansón | 1 |
| 8117 | sanitario | 1 |
| 8118 | sanguinolento | 1 |
| 8119 | sanguinario | 1 |
| 8120 | sanguijuela | 1 |
| 8121 | sangriento | 1 |
| 8122 | sangrientamente | 1 |
| 8123 | sandunga | 1 |
| 8124 | sandio | 1 |
| 8125 | sandalia | 1 |
| 8126 | sancti | 1 |
| 8127 | sancionado | 1 |
| 8128 | sanción | 1 |
| 8129 | sancho | 1 |
| 8130 | sálvense | 1 |
| 8131 | sálvamelo | 1 |
| 8132 | saludó | 1 |
| 8133 | saltarín | 1 |
| 8134 | salpimentar | 1 |
| 8135 | salomónico | 1 |
| 8136 | salomón | 1 |
| 8137 | salmista | 1 |
| 8138 | salió | 1 |
| 8139 | saliente | 1 |
| 8140 | salid | 1 |
| 8141 | saldar | 1 |
| 8142 | salchichón | 1 |
| 8143 | sahumar | 1 |
| 8144 | sagunto | 1 |
| 8145 | sagrario | 1 |
| 8146 | sacudido | 1 |
| 8147 | sacrosanto | 1 |
| 8148 | sacro | 1 |
| 8149 | sacrilegio | 1 |
| 8150 | sacrificándose | 1 |
| 8151 | sacramentar | 1 |
| 8152 | sacerdotisa | 1 |
| 8153 | sacerdotal | 1 |
| 8154 | sacada | 1 |
| 8155 | sabría | 1 |
| 8156 | sablazo | 1 |
| 8157 | sabihondo | 1 |
| 8158 | sabandija | 1 |
| 8159 | sabana | 1 |
| 8160 | ruso | 1 |
| 8161 | rumoroso | 1 |
| 8162 | ruleta | 1 |
| 8163 | rugido | 1 |
| 8164 | rufinita | 1 |
| 8165 | rudo | 1 |
| 8166 | rudesinda | 1 |
| 8167 | rúbrica | 1 |
| 8168 | ruborizarse | 1 |
| 8169 | rubito | 1 |
| 8170 | rozado | 1 |
| 8171 | rotundo | 1 |
| 8172 | rótulo | 1 |
| 8173 | rosendo | 1 |
| 8174 | rosal | 1 |
| 8175 | rorro | 1 |
| 8176 | roquero | 1 |
| 8177 | ropón | 1 |
| 8178 | ronzalillo | 1 |
| 8179 | ronquido | 1 |
| 8180 | ronda | 1 |
| 8181 | ron | 1 |
| 8182 | rompecabezas | 1 |
| 8183 | romo | 1 |
| 8184 | romea | 1 |
| 8185 | romancero | 1 |
| 8186 | romana | 1 |
| 8187 | rojas | 1 |
| 8188 | rogativa | 1 |
| 8189 | roedor | 1 |
| 8190 | rodríguez | 1 |
| 8191 | rococó | 1 |
| 8192 | robledo | 1 |
| 8193 | robledal | 1 |
| 8194 | rivalizar | 1 |
| 8195 | ristre | 1 |
| 8196 | riña | 1 |
| 8197 | rima | 1 |
| 8198 | riguroso | 1 |
| 8199 | rigolade | 1 |
| 8200 | rígido | 1 |
| 8201 | rigidez | 1 |
| 8202 | rifa | 1 |
| 8203 | ricacho | 1 |
| 8204 | ribera | 1 |
| 8205 | ríase | 1 |
| 8206 | rezumar | 1 |
| 8207 | rezando | 1 |
| 8208 | reyes | 1 |
| 8209 | revuelto | 1 |
| 8210 | revolucionar | 1 |
| 8211 | revolar | 1 |
| 8212 | reverso | 1 |
| 8213 | reverencia | 1 |
| 8214 | reverbero | 1 |
| 8215 | reverberar | 1 |
| 8216 | revelaciones | 1 |
| 8217 | retumbante | 1 |
| 8218 | retroceso | 1 |
| 8219 | retrato | 1 |
| 8220 | retratar | 1 |
| 8221 | retraso | 1 |
| 8222 | retractación | 1 |
| 8223 | retozar | 1 |
| 8224 | retorta | 1 |
| 8225 | retocar | 1 |
| 8226 | retintín | 1 |
| 8227 | retina | 1 |
| 8228 | resurrección | 1 |
| 8229 | resumir | 1 |
| 8230 | resultas | 1 |
| 8231 | resuelto | 1 |
| 8232 | resuello | 1 |
| 8233 | restringido | 1 |
| 8234 | restañar | 1 |
| 8235 | restablecer | 1 |
| 8236 | responso | 1 |
| 8237 | responde | 1 |
| 8238 | resplandeciente | 1 |
| 8239 | respiró | 1 |
| 8240 | respiro | 1 |
| 8241 | respectivamente | 1 |
| 8242 | respecta | 1 |
| 8243 | residir | 1 |
| 8244 | residencia | 1 |
| 8245 | reservado | 1 |
| 8246 | reseñar | 1 |
| 8247 | resentido | 1 |
| 8248 | rescatar | 1 |
| 8249 | requebrar | 1 |
| 8250 | repuso | 1 |
| 8251 | reproducir | 1 |
| 8252 | reprimir | 1 |
| 8253 | representativo | 1 |
| 8254 | representante | 1 |
| 8255 | representaba | 1 |
| 8256 | reposado | 1 |
| 8257 | repliegue | 1 |
| 8258 | replicaba | 1 |
| 8259 | repiqueteo | 1 |
| 8260 | repique | 1 |
| 8261 | repicar | 1 |
| 8262 | repertorio | 1 |
| 8263 | repercutir | 1 |
| 8264 | repechar | 1 |
| 8265 | reo | 1 |
| 8266 | renuncia | 1 |
| 8267 | rentístico | 1 |
| 8268 | renovado | 1 |
| 8269 | renovación | 1 |
| 8270 | rendimiento | 1 |
| 8271 | rendido | 1 |
| 8272 | renacimiento | 1 |
| 8273 | remolque | 1 |
| 8274 | remolón | 1 |
| 8275 | remolacha | 1 |
| 8276 | remiso | 1 |
| 8277 | remendón | 1 |
| 8278 | remedar | 1 |
| 8279 | remanso | 1 |
| 8280 | relojero | 1 |
| 8281 | rellenar | 1 |
| 8282 | relevar | 1 |
| 8283 | relator | 1 |
| 8284 | relativos | 1 |
| 8285 | relativamente | 1 |
| 8286 | relamer | 1 |
| 8287 | relajación | 1 |
| 8288 | reivindicar | 1 |
| 8289 | reivindicación | 1 |
| 8290 | reiterado | 1 |
| 8291 | reintegrar | 1 |
| 8292 | reíanse | 1 |
| 8293 | rehusar | 1 |
| 8294 | rehuir | 1 |
| 8295 | rehuía | 1 |
| 8296 | rehabilitar | 1 |
| 8297 | regularmente | 1 |
| 8298 | regresar | 1 |
| 8299 | regocijo | 1 |
| 8300 | reglamento | 1 |
| 8301 | reglamentario | 1 |
| 8302 | registrándole | 1 |
| 8303 | regeneración | 1 |
| 8304 | regateo | 1 |
| 8305 | refutar | 1 |
| 8306 | refugiábanse | 1 |
| 8307 | refrigerar | 1 |
| 8308 | refriega | 1 |
| 8309 | refrescar | 1 |
| 8310 | refrenar | 1 |
| 8311 | refrán | 1 |
| 8312 | refractar | 1 |
| 8313 | reforzar | 1 |
| 8314 | reflexivo | 1 |
| 8315 | refinamiento | 1 |
| 8316 | referente | 1 |
| 8317 | reencarnación | 1 |
| 8318 | reedificar | 1 |
| 8319 | reduplicar | 1 |
| 8320 | redundante | 1 |
| 8321 | redundancia | 1 |
| 8322 | reducto | 1 |
| 8323 | redondilla | 1 |
| 8324 | redondear | 1 |
| 8325 | redoma | 1 |
| 8326 | redoble | 1 |
| 8327 | rédito | 1 |
| 8328 | rediós | 1 |
| 8329 | redentor | 1 |
| 8330 | redención | 1 |
| 8331 | redactar | 1 |
| 8332 | recular | 1 |
| 8333 | recuerda | 1 |
| 8334 | recuento | 1 |
| 8335 | rectificaba | 1 |
| 8336 | rectangular | 1 |
| 8337 | recta | 1 |
| 8338 | recorte | 1 |
| 8339 | recortado | 1 |
| 8340 | recorrido | 1 |
| 8341 | recopilación | 1 |
| 8342 | reconvención | 1 |
| 8343 | recontar | 1 |
| 8344 | reconquista | 1 |
| 8345 | reconozco | 1 |
| 8346 | reconciliarás | 1 |
| 8347 | recompensa | 1 |
| 8348 | recoletos | 1 |
| 8349 | recogida | 1 |
| 8350 | recobraste | 1 |
| 8351 | reclinar | 1 |
| 8352 | recíproca | 1 |
| 8353 | recibimiento | 1 |
| 8354 | recelar | 1 |
| 8355 | recaudar | 1 |
| 8356 | recatadamente | 1 |
| 8357 | recalcitrante | 1 |
| 8358 | recaída | 1 |
| 8359 | rebullir | 1 |
| 8360 | rebozo | 1 |
| 8361 | rebotar | 1 |
| 8362 | reblandecer | 1 |
| 8363 | rebeca | 1 |
| 8364 | reanimar | 1 |
| 8365 | reacio | 1 |
| 8366 | re | 1 |
| 8367 | ratificar | 1 |
| 8368 | raspar | 1 |
| 8369 | rarísimo | 1 |
| 8370 | rapto | 1 |
| 8371 | rapsodia | 1 |
| 8372 | rapidísimo | 1 |
| 8373 | rapar | 1 |
| 8374 | rancio | 1 |
| 8375 | ramificación | 1 |
| 8376 | ramayana | 1 |
| 8377 | ralea | 1 |
| 8378 | raja | 1 |
| 8379 | racionalmente | 1 |
| 8380 | racionalismo | 1 |
| 8381 | racionales | 1 |
| 8382 | ración | 1 |
| 8383 | rachir | 1 |
| 8384 | rabo | 1 |
| 8385 | rabioso | 1 |
| 8386 | rábano | 1 |
| 8387 | r | 1 |
| 8388 | quizá | 1 |
| 8389 | quítese | 1 |
| 8390 | quisquilloso | 1 |
| 8391 | quisque | 1 |
| 8392 | quisicosa | 1 |
| 8393 | quise | 1 |
| 8394 | quintana | 1 |
| 8395 | quintal | 1 |
| 8396 | quinientas | 1 |
| 8397 | químico | 1 |
| 8398 | quijotesco | 1 |
| 8399 | quijotada | 1 |
| 8400 | quijada | 1 |
| 8401 | quietud | 1 |
| 8402 | quietismo | 1 |
| 8403 | quieren | 1 |
| 8404 | quiera | 1 |
| 8405 | quiénes | 1 |
| 8406 | quid | 1 |
| 8407 | querrían | 1 |
| 8408 | querría | 1 |
| 8409 | querían | 1 |
| 8410 | queremos | 1 |
| 8411 | querella | 1 |
| 8412 | quemadura | 1 |
| 8413 | quemado | 1 |
| 8414 | quema | 1 |
| 8415 | quedó | 1 |
| 8416 | queda | 1 |
| 8417 | quando | 1 |
| 8418 | pústula | 1 |
| 8419 | pusilánime | 1 |
| 8420 | purulento | 1 |
| 8421 | purificar | 1 |
| 8422 | puridad | 1 |
| 8423 | purga | 1 |
| 8424 | pupilo | 1 |
| 8425 | puños | 1 |
| 8426 | puñetazos | 1 |
| 8427 | puñados | 1 |
| 8428 | puñado | 1 |
| 8429 | punzar | 1 |
| 8430 | puntuación | 1 |
| 8431 | puntillo | 1 |
| 8432 | puntada | 1 |
| 8433 | pundonor | 1 |
| 8434 | pumarada | 1 |
| 8435 | pum | 1 |
| 8436 | pulvisés | 1 |
| 8437 | pulir | 1 |
| 8438 | pulga | 1 |
| 8439 | pujanza | 1 |
| 8440 | pugna | 1 |
| 8441 | pugilato | 1 |
| 8442 | puertos | 1 |
| 8443 | puerperio | 1 |
| 8444 | puerperal | 1 |
| 8445 | puerco | 1 |
| 8446 | pudoroso | 1 |
| 8447 | pudiente | 1 |
| 8448 | pudibundo | 1 |
| 8449 | publicidad | 1 |
| 8450 | públicamente | 1 |
| 8451 | publicación | 1 |
| 8452 | puar | 1 |
| 8453 | púa | 1 |
| 8454 | psíquico | 1 |
| 8455 | psicológicamente | 1 |
| 8456 | pseudoclásico | 1 |
| 8457 | prudentemente | 1 |
| 8458 | proyectil | 1 |
| 8459 | provocador | 1 |
| 8460 | provisto | 1 |
| 8461 | provisionalmente | 1 |
| 8462 | proverbial | 1 |
| 8463 | provenir | 1 |
| 8464 | proveer | 1 |
| 8465 | protoplasma | 1 |
| 8466 | protejo | 1 |
| 8467 | protegido | 1 |
| 8468 | prostituto | 1 |
| 8469 | prosternar | 1 |
| 8470 | próspero | 1 |
| 8471 | prosperidad | 1 |
| 8472 | prosopopeya | 1 |
| 8473 | prosélito | 1 |
| 8474 | propuesta | 1 |
| 8475 | proporcionado | 1 |
| 8476 | propongo | 1 |
| 8477 | pronunciado | 1 |
| 8478 | pronóstico | 1 |
| 8479 | pronosticar | 1 |
| 8480 | promulgar | 1 |
| 8481 | prominencia | 1 |
| 8482 | prolongado | 1 |
| 8483 | prolijo | 1 |
| 8484 | prole | 1 |
| 8485 | prohibían | 1 |
| 8486 | programar | 1 |
| 8487 | profundísima | 1 |
| 8488 | profeso | 1 |
| 8489 | proferir | 1 |
| 8490 | proeza | 1 |
| 8491 | prodigiosamente | 1 |
| 8492 | prodigalidad | 1 |
| 8493 | procedencia | 1 |
| 8494 | probo | 1 |
| 8495 | probidad | 1 |
| 8496 | probecicos | 1 |
| 8497 | pro | 1 |
| 8498 | privilegiar | 1 |
| 8499 | privación | 1 |
| 8500 | prístino | 1 |
| 8501 | prismático | 1 |
| 8502 | principado | 1 |
| 8503 | primoroso | 1 |
| 8504 | primordial | 1 |
| 8505 | primicia | 1 |
| 8506 | primeramente | 1 |
| 8507 | primar | 1 |
| 8508 | prez | 1 |
| 8509 | previo | 1 |
| 8510 | previamente | 1 |
| 8511 | prevenido | 1 |
| 8512 | prevención | 1 |
| 8513 | prevaricación | 1 |
| 8514 | prevaler | 1 |
| 8515 | prevalecer | 1 |
| 8516 | pretil | 1 |
| 8517 | pretendido | 1 |
| 8518 | presuroso | 1 |
| 8519 | presto | 1 |
| 8520 | prestigiar | 1 |
| 8521 | prestidigitador | 1 |
| 8522 | preste | 1 |
| 8523 | prestamista | 1 |
| 8524 | presión | 1 |
| 8525 | presilla | 1 |
| 8526 | presidiario | 1 |
| 8527 | presidenta | 1 |
| 8528 | presidencia | 1 |
| 8529 | presentación | 1 |
| 8530 | prescribir | 1 |
| 8531 | prescindamos | 1 |
| 8532 | presbiterio | 1 |
| 8533 | prerrogativa | 1 |
| 8534 | preñar | 1 |
| 8535 | prensado | 1 |
| 8536 | premeditado | 1 |
| 8537 | pregúntaselo | 1 |
| 8538 | preguntaron | 1 |
| 8539 | pregonero | 1 |
| 8540 | preferible | 1 |
| 8541 | preeminente | 1 |
| 8542 | predisposición | 1 |
| 8543 | precursor | 1 |
| 8544 | precisión | 1 |
| 8545 | precipitadamente | 1 |
| 8546 | precipicio | 1 |
| 8547 | preciosa | 1 |
| 8548 | preces | 1 |
| 8549 | precepto | 1 |
| 8550 | precaver | 1 |
| 8551 | prebenda | 1 |
| 8552 | pragmática | 1 |
| 8553 | poussin | 1 |
| 8554 | potro | 1 |
| 8555 | potente | 1 |
| 8556 | potentado | 1 |
| 8557 | póstumo | 1 |
| 8558 | postdata | 1 |
| 8559 | posponer | 1 |
| 8560 | posada | 1 |
| 8561 | portocarrero | 1 |
| 8562 | portezuela | 1 |
| 8563 | portería | 1 |
| 8564 | portentoso | 1 |
| 8565 | portador | 1 |
| 8566 | porrazo | 1 |
| 8567 | porra | 1 |
| 8568 | porfiado | 1 |
| 8569 | porfía | 1 |
| 8570 | porche | 1 |
| 8571 | poquísimo | 1 |
| 8572 | populoso | 1 |
| 8573 | pontificii | 1 |
| 8574 | pontificado | 1 |
| 8575 | pomposo | 1 |
| 8576 | pomares | 1 |
| 8577 | polvareda | 1 |
| 8578 | polo | 1 |
| 8579 | polea | 1 |
| 8580 | polaina | 1 |
| 8581 | polaco | 1 |
| 8582 | poetizar | 1 |
| 8583 | poe | 1 |
| 8584 | podría | 1 |
| 8585 | podrá | 1 |
| 8586 | pocas | 1 |
| 8587 | poca | 1 |
| 8588 | pobretería | 1 |
| 8589 | poblado | 1 |
| 8590 | pluralidad | 1 |
| 8591 | plomar | 1 |
| 8592 | plenamente | 1 |
| 8593 | plegadera | 1 |
| 8594 | platón | 1 |
| 8595 | platicar | 1 |
| 8596 | plasticidad | 1 |
| 8597 | plástica | 1 |
| 8598 | plantado | 1 |
| 8599 | planicie | 1 |
| 8600 | planeta | 1 |
| 8601 | plancha | 1 |
| 8602 | pizpireto | 1 |
| 8603 | pizpireta | 1 |
| 8604 | pizcar | 1 |
| 8605 | pizarro | 1 |
| 8606 | pitonisa | 1 |
| 8607 | pitar | 1 |
| 8608 | pitágoras | 1 |
| 8609 | pistilo | 1 |
| 8610 | pista | 1 |
| 8611 | pisci | 1 |
| 8612 | pisada | 1 |
| 8613 | pirata | 1 |
| 8614 | piña | 1 |
| 8615 | pinzón | 1 |
| 8616 | pinón | 1 |
| 8617 | pingüe | 1 |
| 8618 | pinar | 1 |
| 8619 | pin | 1 |
| 8620 | pimpollo | 1 |
| 8621 | píldora | 1 |
| 8622 | pigault | 1 |
| 8623 | pietista | 1 |
| 8624 | piensa | 1 |
| 8625 | picotear | 1 |
| 8626 | picota | 1 |
| 8627 | pichón | 1 |
| 8628 | picazón | 1 |
| 8629 | pican | 1 |
| 8630 | picador | 1 |
| 8631 | picado | 1 |
| 8632 | picacho | 1 |
| 8633 | piara | 1 |
| 8634 | piafar | 1 |
| 8635 | petrificar | 1 |
| 8636 | petirrojo | 1 |
| 8637 | petardo | 1 |
| 8638 | pétalo | 1 |
| 8639 | pespuntear | 1 |
| 8640 | pesetero | 1 |
| 8641 | pescaremos | 1 |
| 8642 | pescante | 1 |
| 8643 | pescador | 1 |
| 8644 | pesadez | 1 |
| 8645 | pervertido | 1 |
| 8646 | perverso | 1 |
| 8647 | perú | 1 |
| 8648 | perturbar | 1 |
| 8649 | perturbador | 1 |
| 8650 | pertinente | 1 |
| 8651 | pertinaz | 1 |
| 8652 | persuasión | 1 |
| 8653 | personificación | 1 |
| 8654 | persistir | 1 |
| 8655 | persistente | 1 |
| 8656 | persignar | 1 |
| 8657 | perseguidor | 1 |
| 8658 | perrería | 1 |
| 8659 | perpetua | 1 |
| 8660 | perorar | 1 |
| 8661 | permítame | 1 |
| 8662 | peritonitis | 1 |
| 8663 | peritar | 1 |
| 8664 | periodista | 1 |
| 8665 | periódicos | 1 |
| 8666 | perifollo | 1 |
| 8667 | pergeño | 1 |
| 8668 | pergeñar | 1 |
| 8669 | perfumería | 1 |
| 8670 | perfidia | 1 |
| 8671 | perfecta | 1 |
| 8672 | perezosos | 1 |
| 8673 | perezosamente | 1 |
| 8674 | pérez | 1 |
| 8675 | perentorio | 1 |
| 8676 | peregrinación | 1 |
| 8677 | pereda | 1 |
| 8678 | perecedero | 1 |
| 8679 | perdulario | 1 |
| 8680 | perdóneme | 1 |
| 8681 | perdonarla | 1 |
| 8682 | perdonadle | 1 |
| 8683 | perdida | 1 |
| 8684 | perceptivo | 1 |
| 8685 | peraltado | 1 |
| 8686 | pera | 1 |
| 8687 | pepinillo | 1 |
| 8688 | peonza | 1 |
| 8689 | peonar | 1 |
| 8690 | peñasco | 1 |
| 8691 | penuria | 1 |
| 8692 | penumbra | 1 |
| 8693 | pentagrama | 1 |
| 8694 | pensaban | 1 |
| 8695 | penitenciario | 1 |
| 8696 | péndulo | 1 |
| 8697 | pendencia | 1 |
| 8698 | penar | 1 |
| 8699 | peluquería | 1 |
| 8700 | pelucón | 1 |
| 8701 | peleo | 1 |
| 8702 | peldaño | 1 |
| 8703 | pelayo | 1 |
| 8704 | pelar | 1 |
| 8705 | peinador | 1 |
| 8706 | peinado | 1 |
| 8707 | pegado | 1 |
| 8708 | pegada | 1 |
| 8709 | pega | 1 |
| 8710 | pedirla | 1 |
| 8711 | pedigüeño | 1 |
| 8712 | pedestre | 1 |
| 8713 | pedestal | 1 |
| 8714 | pedantesco | 1 |
| 8715 | pedantería | 1 |
| 8716 | pechina | 1 |
| 8717 | pechar | 1 |
| 8718 | pebetero | 1 |
| 8719 | pche | 1 |
| 8720 | pavoroso | 1 |
| 8721 | paulo | 1 |
| 8722 | paulatino | 1 |
| 8723 | paulatinamente | 1 |
| 8724 | paul | 1 |
| 8725 | patronato | 1 |
| 8726 | patrocinar | 1 |
| 8727 | patris | 1 |
| 8728 | patriarca | 1 |
| 8729 | patraña | 1 |
| 8730 | patitas | 1 |
| 8731 | patíbulo | 1 |
| 8732 | patear | 1 |
| 8733 | patarata | 1 |
| 8734 | pataleo | 1 |
| 8735 | pastoreo | 1 |
| 8736 | pastora | 1 |
| 8737 | pastilla | 1 |
| 8738 | pasteur | 1 |
| 8739 | pastelero | 1 |
| 8740 | pastel | 1 |
| 8741 | pasó | 1 |
| 8742 | pásmese | 1 |
| 8743 | pasmábase | 1 |
| 8744 | paseíto | 1 |
| 8745 | pascal | 1 |
| 8746 | pasará | 1 |
| 8747 | parves | 1 |
| 8748 | parvedad | 1 |
| 8749 | particularmente | 1 |
| 8750 | parrilla | 1 |
| 8751 | parisiense | 1 |
| 8752 | parejita | 1 |
| 8753 | paredón | 1 |
| 8754 | parecen | 1 |
| 8755 | pardal | 1 |
| 8756 | parcial | 1 |
| 8757 | parca | 1 |
| 8758 | pararrayos | 1 |
| 8759 | parangón | 1 |
| 8760 | paradoja | 1 |
| 8761 | parado | 1 |
| 8762 | paquete | 1 |
| 8763 | papista | 1 |
| 8764 | papas | 1 |
| 8765 | pañales | 1 |
| 8766 | pañal | 1 |
| 8767 | panteísta | 1 |
| 8768 | pantalla | 1 |
| 8769 | panoplia | 1 |
| 8770 | panecillo | 1 |
| 8771 | pandereta | 1 |
| 8772 | pamplinas | 1 |
| 8773 | palúdico | 1 |
| 8774 | palpitación | 1 |
| 8775 | palmito | 1 |
| 8776 | palmario | 1 |
| 8777 | palmado | 1 |
| 8778 | pallavicini | 1 |
| 8779 | palio | 1 |
| 8780 | palinodia | 1 |
| 8781 | palillo | 1 |
| 8782 | pálida | 1 |
| 8783 | palas | 1 |
| 8784 | palafrén | 1 |
| 8785 | palabrota | 1 |
| 8786 | paje | 1 |
| 8787 | pajas | 1 |
| 8788 | pajarraco | 1 |
| 8789 | pájara | 1 |
| 8790 | pajar | 1 |
| 8791 | paix | 1 |
| 8792 | paginar | 1 |
| 8793 | paganismo | 1 |
| 8794 | padrinos | 1 |
| 8795 | padres | 1 |
| 8796 | padrenuestro | 1 |
| 8797 | padrazo | 1 |
| 8798 | padecimiento | 1 |
| 8799 | pactar | 1 |
| 8800 | pacos | 1 |
| 8801 | pacíficamente | 1 |
| 8802 | paciente | 1 |
| 8803 | oxígeno | 1 |
| 8804 | oxidado | 1 |
| 8805 | ovillo | 1 |
| 8806 | oveja | 1 |
| 8807 | ovalado | 1 |
| 8808 | oval | 1 |
| 8809 | ovación | 1 |
| 8810 | otrosí | 1 |
| 8811 | otros | 1 |
| 8812 | otoñada | 1 |
| 8813 | osuna | 1 |
| 8814 | ostracismo | 1 |
| 8815 | ostensiblemente | 1 |
| 8816 | oscilar | 1 |
| 8817 | osado | 1 |
| 8818 | osadía | 1 |
| 8819 | orza | 1 |
| 8820 | orto | 1 |
| 8821 | ortiz | 1 |
| 8822 | orsini | 1 |
| 8823 | orquestar | 1 |
| 8824 | oropel | 1 |
| 8825 | ornato | 1 |
| 8826 | ornamento | 1 |
| 8827 | ornamentar | 1 |
| 8828 | orientalista | 1 |
| 8829 | orgullosa | 1 |
| 8830 | orgasmo | 1 |
| 8831 | organismo | 1 |
| 8832 | organdí | 1 |
| 8833 | orejera | 1 |
| 8834 | ordenó | 1 |
| 8835 | ordenado | 1 |
| 8836 | órbita | 1 |
| 8837 | orangután | 1 |
| 8838 | oráculo | 1 |
| 8839 | opulento | 1 |
| 8840 | opulencia | 1 |
| 8841 | óptimo | 1 |
| 8842 | óptico | 1 |
| 8843 | opresor | 1 |
| 8844 | oppert | 1 |
| 8845 | opositor | 1 |
| 8846 | oportunísimo | 1 |
| 8847 | oportunamente | 1 |
| 8848 | opinaba | 1 |
| 8849 | onza | 1 |
| 8850 | omnipotencia | 1 |
| 8851 | olivo | 1 |
| 8852 | olimpo | 1 |
| 8853 | olfato | 1 |
| 8854 | olé | 1 |
| 8855 | ojiva | 1 |
| 8856 | ojazos | 1 |
| 8857 | oirá | 1 |
| 8858 | oigámoslo | 1 |
| 8859 | ofrendar | 1 |
| 8860 | ofrenda | 1 |
| 8861 | oficiar | 1 |
| 8862 | ofensiva | 1 |
| 8863 | ocupaciones | 1 |
| 8864 | ocupábase | 1 |
| 8865 | octava | 1 |
| 8866 | ochentón | 1 |
| 8867 | occidental | 1 |
| 8868 | ocasional | 1 |
| 8869 | obstante | 1 |
| 8870 | obseso | 1 |
| 8871 | observe | 1 |
| 8872 | obscuridad | 1 |
| 8873 | obreros | 1 |
| 8874 | oblongo | 1 |
| 8875 | obligatorio | 1 |
| 8876 | objetó | 1 |
| 8877 | objetivo | 1 |
| 8878 | obdulias | 1 |
| 8879 | obcecar | 1 |
| 8880 | nutrir | 1 |
| 8881 | nuncio | 1 |
| 8882 | nuevas | 1 |
| 8883 | nuestras | 1 |
| 8884 | nublar | 1 |
| 8885 | nubarrón | 1 |
| 8886 | novísimo | 1 |
| 8887 | noviazgo | 1 |
| 8888 | novenas | 1 |
| 8889 | novelista | 1 |
| 8890 | novedades | 1 |
| 8891 | notó | 1 |
| 8892 | noten | 1 |
| 8893 | notabilidad | 1 |
| 8894 | noruega | 1 |
| 8895 | normandos | 1 |
| 8896 | normal | 1 |
| 8897 | nordeste | 1 |
| 8898 | non | 1 |
| 8899 | nominar | 1 |
| 8900 | nodriza | 1 |
| 8901 | nocivo | 1 |
| 8902 | noción | 1 |
| 8903 | nocedal | 1 |
| 8904 | noblemente | 1 |
| 8905 | nivelar | 1 |
| 8906 | niños | 1 |
| 8907 | niñas | 1 |
| 8908 | ninon | 1 |
| 8909 | nínive | 1 |
| 8910 | ninfa | 1 |
| 8911 | nimbo | 1 |
| 8912 | nieto | 1 |
| 8913 | niega | 1 |
| 8914 | nevada | 1 |
| 8915 | neutro | 1 |
| 8916 | nene | 1 |
| 8917 | nemrod | 1 |
| 8918 | negligencia | 1 |
| 8919 | nefasto | 1 |
| 8920 | nefando | 1 |
| 8921 | necia | 1 |
| 8922 | necesito | 1 |
| 8923 | necesitaba | 1 |
| 8924 | necedades | 1 |
| 8925 | nay | 1 |
| 8926 | navío | 1 |
| 8927 | navegación | 1 |
| 8928 | naval | 1 |
| 8929 | náutico | 1 |
| 8930 | natividad | 1 |
| 8931 | natalicio | 1 |
| 8932 | natalia | 1 |
| 8933 | narigudo | 1 |
| 8934 | narices | 1 |
| 8935 | narciso | 1 |
| 8936 | naranjo | 1 |
| 8937 | naranjas | 1 |
| 8938 | nació | 1 |
| 8939 | naciente | 1 |
| 8940 | musgoso | 1 |
| 8941 | musgo | 1 |
| 8942 | musculoso | 1 |
| 8943 | murmuró | 1 |
| 8944 | murmuraban | 1 |
| 8945 | murmuraba | 1 |
| 8946 | muñoz | 1 |
| 8947 | muñón | 1 |
| 8948 | munificencia | 1 |
| 8949 | munda | 1 |
| 8950 | múltiple | 1 |
| 8951 | multar | 1 |
| 8952 | mullir | 1 |
| 8953 | mulato | 1 |
| 8954 | mujerzuela | 1 |
| 8955 | mujeril | 1 |
| 8956 | mugre | 1 |
| 8957 | múdese | 1 |
| 8958 | mu | 1 |
| 8959 | mr | 1 |
| 8960 | movible | 1 |
| 8961 | movedizo | 1 |
| 8962 | mostaza | 1 |
| 8963 | mosco | 1 |
| 8964 | mortuorio | 1 |
| 8965 | morro | 1 |
| 8966 | moroso | 1 |
| 8967 | morigerar | 1 |
| 8968 | morfina | 1 |
| 8969 | morería | 1 |
| 8970 | morena | 1 |
| 8971 | mordedura | 1 |
| 8972 | morcillo | 1 |
| 8973 | morcilla | 1 |
| 8974 | morboso | 1 |
| 8975 | morbidez | 1 |
| 8976 | moño | 1 |
| 8977 | moña | 1 |
| 8978 | montes | 1 |
| 8979 | montecristo | 1 |
| 8980 | monólogo | 1 |
| 8981 | monolito | 1 |
| 8982 | monocromo | 1 |
| 8983 | mónica | 1 |
| 8984 | monescillo | 1 |
| 8985 | móndame | 1 |
| 8986 | monástico | 1 |
| 8987 | monago | 1 |
| 8988 | mona | 1 |
| 8989 | momentáneo | 1 |
| 8990 | mollera | 1 |
| 8991 | moleschott | 1 |
| 8992 | moler | 1 |
| 8993 | moldura | 1 |
| 8994 | mojigata | 1 |
| 8995 | mojiganga | 1 |
| 8996 | modismo | 1 |
| 8997 | modificación | 1 |
| 8998 | mocoso | 1 |
| 8999 | mobiliario | 1 |
| 9000 | mixto | 1 |
| 9001 | mitológico | 1 |
| 9002 | místicos | 1 |
| 9003 | místicamente | 1 |
| 9004 | misterios | 1 |
| 9005 | misiva | 1 |
| 9006 | misérrimo | 1 |
| 9007 | miserere | 1 |
| 9008 | miserablemente | 1 |
| 9009 | misántropo | 1 |
| 9010 | mirón | 1 |
| 9011 | mirlar | 1 |
| 9012 | mírele | 1 |
| 9013 | mirábala | 1 |
| 9014 | míos | 1 |
| 9015 | miope | 1 |
| 9016 | minué | 1 |
| 9017 | minuciosamente | 1 |
| 9018 | miniatura | 1 |
| 9019 | mineral | 1 |
| 9020 | mimado | 1 |
| 9021 | milo | 1 |
| 9022 | militaba | 1 |
| 9023 | milano | 1 |
| 9024 | milagrosamente | 1 |
| 9025 | miguel | 1 |
| 9026 | migar | 1 |
| 9027 | mezquita | 1 |
| 9028 | mezquinar | 1 |
| 9029 | metz | 1 |
| 9030 | metropolitano | 1 |
| 9031 | metralla | 1 |
| 9032 | método | 1 |
| 9033 | metodista | 1 |
| 9034 | metida | 1 |
| 9035 | meteorológico | 1 |
| 9036 | meteorología | 1 |
| 9037 | metafóricamente | 1 |
| 9038 | meta | 1 |
| 9039 | meses | 1 |
| 9040 | mero | 1 |
| 9041 | mermar | 1 |
| 9042 | merino | 1 |
| 9043 | meridional | 1 |
| 9044 | merecimiento | 1 |
| 9045 | merecido | 1 |
| 9046 | merecidísimo | 1 |
| 9047 | mentor | 1 |
| 9048 | mentón | 1 |
| 9049 | mentís | 1 |
| 9050 | mentalmente | 1 |
| 9051 | mengua | 1 |
| 9052 | menestral | 1 |
| 9053 | meneses | 1 |
| 9054 | meneo | 1 |
| 9055 | méndez | 1 |
| 9056 | mencionar | 1 |
| 9057 | memorias | 1 |
| 9058 | memento | 1 |
| 9059 | membibres | 1 |
| 9060 | melodioso | 1 |
| 9061 | melodía | 1 |
| 9062 | melocotón | 1 |
| 9063 | melancólicamente | 1 |
| 9064 | mejorcito | 1 |
| 9065 | méjico | 1 |
| 9066 | médula | 1 |
| 9067 | medro | 1 |
| 9068 | medrados | 1 |
| 9069 | meditaba | 1 |
| 9070 | médicis | 1 |
| 9071 | medianoche | 1 |
| 9072 | medianero | 1 |
| 9073 | mechero | 1 |
| 9074 | mecha | 1 |
| 9075 | mecedor | 1 |
| 9076 | mecanismo | 1 |
| 9077 | mecánicamente | 1 |
| 9078 | mazar | 1 |
| 9079 | mayúsculo | 1 |
| 9080 | mayorazgo | 1 |
| 9081 | mayoral | 1 |
| 9082 | maudsley | 1 |
| 9083 | matrícula | 1 |
| 9084 | matizar | 1 |
| 9085 | matiella | 1 |
| 9086 | matías | 1 |
| 9087 | maternidad | 1 |
| 9088 | mateo | 1 |
| 9089 | matemáticamente | 1 |
| 9090 | matarla | 1 |
| 9091 | matadero | 1 |
| 9092 | masini | 1 |
| 9093 | martirizar | 1 |
| 9094 | marte | 1 |
| 9095 | marsilla | 1 |
| 9096 | marrón | 1 |
| 9097 | marquesina | 1 |
| 9098 | marmitón | 1 |
| 9099 | maritornes | 1 |
| 9100 | marismas | 1 |
| 9101 | mares | 1 |
| 9102 | mareantes | 1 |
| 9103 | mareado | 1 |
| 9104 | marchito | 1 |
| 9105 | marchitar | 1 |
| 9106 | maravilloso | 1 |
| 9107 | maquinilla | 1 |
| 9108 | maquinalmente | 1 |
| 9109 | maquinal | 1 |
| 9110 | mapa | 1 |
| 9111 | maño | 1 |
| 9112 | manuscribir | 1 |
| 9113 | mantillas | 1 |
| 9114 | manterola | 1 |
| 9115 | mantear | 1 |
| 9116 | manriques | 1 |
| 9117 | manoseado | 1 |
| 9118 | manolito | 1 |
| 9119 | manola | 1 |
| 9120 | manojo | 1 |
| 9121 | manir | 1 |
| 9122 | maniobra | 1 |
| 9123 | manifestó | 1 |
| 9124 | manejo | 1 |
| 9125 | mandria | 1 |
| 9126 | mandoble | 1 |
| 9127 | mandamos | 1 |
| 9128 | mandaba | 1 |
| 9129 | manar | 1 |
| 9130 | maná | 1 |
| 9131 | mampostería | 1 |
| 9132 | mamar | 1 |
| 9133 | maltrecho | 1 |
| 9134 | malquistar | 1 |
| 9135 | malla | 1 |
| 9136 | malhechor | 1 |
| 9137 | malévolo | 1 |
| 9138 | malestar | 1 |
| 9139 | malbaratar | 1 |
| 9140 | malamente | 1 |
| 9141 | malabar | 1 |
| 9142 | mala | 1 |
| 9143 | majo | 1 |
| 9144 | majar | 1 |
| 9145 | majaderos | 1 |
| 9146 | majadería | 1 |
| 9147 | maizal | 1 |
| 9148 | maitines | 1 |
| 9149 | mahoma | 1 |
| 9150 | mago | 1 |
| 9151 | magno | 1 |
| 9152 | magnífica | 1 |
| 9153 | magnanimidad | 1 |
| 9154 | magistratura | 1 |
| 9155 | magistrales | 1 |
| 9156 | madriguera | 1 |
| 9157 | madrigal | 1 |
| 9158 | madrejón | 1 |
| 9159 | madrastra | 1 |
| 9160 | madeja | 1 |
| 9161 | macizar | 1 |
| 9162 | macilento | 1 |
| 9163 | machacón | 1 |
| 9164 | maceta | 1 |
| 9165 | macabro | 1 |
| 9166 | macabeos | 1 |
| 9167 | m | 1 |
| 9168 | luzbel | 1 |
| 9169 | luys | 1 |
| 9170 | lustroso | 1 |
| 9171 | lustre | 1 |
| 9172 | lusitano | 1 |
| 9173 | luján | 1 |
| 9174 | lugarejo | 1 |
| 9175 | luengo | 1 |
| 9176 | lucubración | 1 |
| 9177 | lucro | 1 |
| 9178 | lucrecio | 1 |
| 9179 | lucrativo | 1 |
| 9180 | lucrar | 1 |
| 9181 | luciría | 1 |
| 9182 | lucifer | 1 |
| 9183 | lucido | 1 |
| 9184 | lucharía | 1 |
| 9185 | luchador | 1 |
| 9186 | lucero | 1 |
| 9187 | lucerna | 1 |
| 9188 | lucaaam | 1 |
| 9189 | lubricidad | 1 |
| 9190 | lozoya | 1 |
| 9191 | lozanía | 1 |
| 9192 | loza | 1 |
| 9193 | lovelace | 1 |
| 9194 | lot | 1 |
| 9195 | losa | 1 |
| 9196 | lonja | 1 |
| 9197 | longevidad | 1 |
| 9198 | longaniza | 1 |
| 9199 | locuras | 1 |
| 9200 | locos | 1 |
| 9201 | loca | 1 |
| 9202 | lóbrego | 1 |
| 9203 | lobezno | 1 |
| 9204 | loable | 1 |
| 9205 | llueve | 1 |
| 9206 | llovía | 1 |
| 9207 | llovería | 1 |
| 9208 | llorón | 1 |
| 9209 | lloro | 1 |
| 9210 | lloriquear | 1 |
| 9211 | llévame | 1 |
| 9212 | lleva | 1 |
| 9213 | llegaron | 1 |
| 9214 | llegará | 1 |
| 9215 | llegamos | 1 |
| 9216 | llaneza | 1 |
| 9217 | llana | 1 |
| 9218 | llamé | 1 |
| 9219 | llame | 1 |
| 9220 | llamado | 1 |
| 9221 | llamaba | 1 |
| 9222 | liviano | 1 |
| 9223 | litigante | 1 |
| 9224 | literato | 1 |
| 9225 | listillo | 1 |
| 9226 | listar | 1 |
| 9227 | listado | 1 |
| 9228 | liso | 1 |
| 9229 | líricamente | 1 |
| 9230 | liquen | 1 |
| 9231 | lío | 1 |
| 9232 | linfa | 1 |
| 9233 | lindoro | 1 |
| 9234 | limítrofe | 1 |
| 9235 | limitado | 1 |
| 9236 | limbo | 1 |
| 9237 | ligereza | 1 |
| 9238 | ligera | 1 |
| 9239 | ligadura | 1 |
| 9240 | lidiar | 1 |
| 9241 | librepensamiento | 1 |
| 9242 | libraco | 1 |
| 9243 | libra | 1 |
| 9244 | libelo | 1 |
| 9245 | levantisco | 1 |
| 9246 | levántate | 1 |
| 9247 | leva | 1 |
| 9248 | letargo | 1 |
| 9249 | letanía | 1 |
| 9250 | lesionar | 1 |
| 9251 | lesión | 1 |
| 9252 | lesbos | 1 |
| 9253 | les | 1 |
| 9254 | leproso | 1 |
| 9255 | leonor | 1 |
| 9256 | lenteja | 1 |
| 9257 | lenidad | 1 |
| 9258 | lenclós | 1 |
| 9259 | lema | 1 |
| 9260 | legislación | 1 |
| 9261 | legendario | 1 |
| 9262 | legar | 1 |
| 9263 | legalmente | 1 |
| 9264 | lechuga | 1 |
| 9265 | lebrun | 1 |
| 9266 | leal | 1 |
| 9267 | laxitud | 1 |
| 9268 | laurent | 1 |
| 9269 | latorre | 1 |
| 9270 | lastimoso | 1 |
| 9271 | lastimero | 1 |
| 9272 | lasciami | 1 |
| 9273 | larguísimo | 1 |
| 9274 | largos | 1 |
| 9275 | largamente | 1 |
| 9276 | lapsus | 1 |
| 9277 | languidecer | 1 |
| 9278 | lánguidamente | 1 |
| 9279 | landó | 1 |
| 9280 | lanchar | 1 |
| 9281 | lancha | 1 |
| 9282 | lanas | 1 |
| 9283 | lampiño | 1 |
| 9284 | lamparilla | 1 |
| 9285 | laminar | 1 |
| 9286 | lamentable | 1 |
| 9287 | lamego | 1 |
| 9288 | lamartine | 1 |
| 9289 | lagarto | 1 |
| 9290 | lagar | 1 |
| 9291 | lacrimoso | 1 |
| 9292 | labriego | 1 |
| 9293 | labranza | 1 |
| 9294 | laborioso | 1 |
| 9295 | laborar | 1 |
| 9296 | laberinto | 1 |
| 9297 | l | 1 |
| 9298 | kock | 1 |
| 9299 | justillo | 1 |
| 9300 | justificar | 1 |
| 9301 | justificable | 1 |
| 9302 | justa | 1 |
| 9303 | jurídico | 1 |
| 9304 | juremos | 1 |
| 9305 | juntura | 1 |
| 9306 | junco | 1 |
| 9307 | juguetón | 1 |
| 9308 | jugo | 1 |
| 9309 | judit | 1 |
| 9310 | jubileo | 1 |
| 9311 | joyero | 1 |
| 9312 | jovialidad | 1 |
| 9313 | jovellanos | 1 |
| 9314 | jota | 1 |
| 9315 | jorobar | 1 |
| 9316 | jornalero | 1 |
| 9317 | jornal | 1 |
| 9318 | jorge | 1 |
| 9319 | jónico | 1 |
| 9320 | jofaina | 1 |
| 9321 | jocoso | 1 |
| 9322 | jinojo | 1 |
| 9323 | jícara | 1 |
| 9324 | jesuitismo | 1 |
| 9325 | jesuítico | 1 |
| 9326 | jerusalén | 1 |
| 9327 | jerusalem | 1 |
| 9328 | jeroma | 1 |
| 9329 | jericó | 1 |
| 9330 | jerga | 1 |
| 9331 | jeremías | 1 |
| 9332 | jerárquico | 1 |
| 9333 | jehová | 1 |
| 9334 | je | 1 |
| 9335 | jazmín | 1 |
| 9336 | jardinera | 1 |
| 9337 | jarana | 1 |
| 9338 | japón | 1 |
| 9339 | jaime | 1 |
| 9340 | jaco | 1 |
| 9341 | jaccoud | 1 |
| 9342 | jacas | 1 |
| 9343 | j | 1 |
| 9344 | ix | 1 |
| 9345 | iv | 1 |
| 9346 | ítem | 1 |
| 9347 | israelita | 1 |
| 9348 | israel | 1 |
| 9349 | islote | 1 |
| 9350 | isis | 1 |
| 9351 | irritarse | 1 |
| 9352 | irritación | 1 |
| 9353 | irritabilidad | 1 |
| 9354 | irrisión | 1 |
| 9355 | irresponsabilidad | 1 |
| 9356 | irremisiblemente | 1 |
| 9357 | irregularidad | 1 |
| 9358 | irreflexivamente | 1 |
| 9359 | irradiar | 1 |
| 9360 | ironías | 1 |
| 9361 | irisar | 1 |
| 9362 | iria | 1 |
| 9363 | iremos | 1 |
| 9364 | iré | 1 |
| 9365 | irá | 1 |
| 9366 | invulnerable | 1 |
| 9367 | involucrar | 1 |
| 9368 | investigar | 1 |
| 9369 | invertir | 1 |
| 9370 | invernante | 1 |
| 9371 | invernadero | 1 |
| 9372 | invernáculo | 1 |
| 9373 | inventario | 1 |
| 9374 | invariablemente | 1 |
| 9375 | inusitado | 1 |
| 9376 | intrincado | 1 |
| 9377 | intrigante | 1 |
| 9378 | intrépido | 1 |
| 9379 | intransigente | 1 |
| 9380 | intestinal | 1 |
| 9381 | interrogar | 1 |
| 9382 | interrogante | 1 |
| 9383 | intérprete | 1 |
| 9384 | interpretación | 1 |
| 9385 | interponer | 1 |
| 9386 | interno | 1 |
| 9387 | intermitente | 1 |
| 9388 | interjección | 1 |
| 9389 | interioridad | 1 |
| 9390 | interino | 1 |
| 9391 | interinamente | 1 |
| 9392 | intentona | 1 |
| 9393 | intensamente | 1 |
| 9394 | intendente | 1 |
| 9395 | íntegro | 1 |
| 9396 | integrar | 1 |
| 9397 | integrante | 1 |
| 9398 | integral | 1 |
| 9399 | intacto | 1 |
| 9400 | insurrecto | 1 |
| 9401 | insulsez | 1 |
| 9402 | instrumentista | 1 |
| 9403 | instrumentar | 1 |
| 9404 | instruido | 1 |
| 9405 | instituto | 1 |
| 9406 | instigar | 1 |
| 9407 | instar | 1 |
| 9408 | instancia | 1 |
| 9409 | insólito | 1 |
| 9410 | insolenta | 1 |
| 9411 | insinuó | 1 |
| 9412 | insignificancia | 1 |
| 9413 | insidioso | 1 |
| 9414 | inservible | 1 |
| 9415 | insertar | 1 |
| 9416 | insensato | 1 |
| 9417 | inquisición | 1 |
| 9418 | inquirir | 1 |
| 9419 | inquilino | 1 |
| 9420 | inoportunamente | 1 |
| 9421 | inopinado | 1 |
| 9422 | inocentada | 1 |
| 9423 | innumerable | 1 |
| 9424 | innovador | 1 |
| 9425 | innovación | 1 |
| 9426 | innominado | 1 |
| 9427 | innato | 1 |
| 9428 | inmovilidad | 1 |
| 9429 | inmoralidad | 1 |
| 9430 | inmodestia | 1 |
| 9431 | inmediaciones | 1 |
| 9432 | inmaculada | 1 |
| 9433 | injurioso | 1 |
| 9434 | injerencia | 1 |
| 9435 | iniciación | 1 |
| 9436 | ingreso | 1 |
| 9437 | ingresar | 1 |
| 9438 | ingenuidad | 1 |
| 9439 | ingenuamente | 1 |
| 9440 | infructuoso | 1 |
| 9441 | infringir | 1 |
| 9442 | infraganti | 1 |
| 9443 | infracción | 1 |
| 9444 | inflexión | 1 |
| 9445 | inflamable | 1 |
| 9446 | infecundo | 1 |
| 9447 | infausto | 1 |
| 9448 | infatigable | 1 |
| 9449 | infante | 1 |
| 9450 | infamatorio | 1 |
| 9451 | inextinguible | 1 |
| 9452 | inexplicable | 1 |
| 9453 | inescrutable | 1 |
| 9454 | inequívoco | 1 |
| 9455 | ineludible | 1 |
| 9456 | industriar | 1 |
| 9457 | indumentario | 1 |
| 9458 | indómito | 1 |
| 9459 | indomable | 1 |
| 9460 | indisciplinar | 1 |
| 9461 | indirecto | 1 |
| 9462 | indino | 1 |
| 9463 | indignamente | 1 |
| 9464 | indígena | 1 |
| 9465 | indicó | 1 |
| 9466 | indicado | 1 |
| 9467 | indescifrable | 1 |
| 9468 | indemnización | 1 |
| 9469 | indefinido | 1 |
| 9470 | indefenso | 1 |
| 9471 | indeciso | 1 |
| 9472 | indecible | 1 |
| 9473 | indagar | 1 |
| 9474 | incuria | 1 |
| 9475 | incumbencia | 1 |
| 9476 | inculcar | 1 |
| 9477 | increíble | 1 |
| 9478 | incredulidad | 1 |
| 9479 | incorruptible | 1 |
| 9480 | incorregible | 1 |
| 9481 | inconveniencia | 1 |
| 9482 | incontrastable | 1 |
| 9483 | inconstancia | 1 |
| 9484 | inconsolable | 1 |
| 9485 | inconexo | 1 |
| 9486 | incompleto | 1 |
| 9487 | incompatibilidad | 1 |
| 9488 | incomparablemente | 1 |
| 9489 | incombustible | 1 |
| 9490 | incoherencia | 1 |
| 9491 | inciso | 1 |
| 9492 | incendio | 1 |
| 9493 | incendiar | 1 |
| 9494 | incauto | 1 |
| 9495 | incautar | 1 |
| 9496 | incasable | 1 |
| 9497 | incalculable | 1 |
| 9498 | inarticulado | 1 |
| 9499 | inarco | 1 |
| 9500 | inapreciable | 1 |
| 9501 | inapetencia | 1 |
| 9502 | inanimado | 1 |
| 9503 | inanición | 1 |
| 9504 | inalienable | 1 |
| 9505 | inaguantable | 1 |
| 9506 | inadvertencia | 1 |
| 9507 | inacabable | 1 |
| 9508 | in | 1 |
| 9509 | imputar | 1 |
| 9510 | impune | 1 |
| 9511 | improvisación | 1 |
| 9512 | impropiamente | 1 |
| 9513 | improperio | 1 |
| 9514 | improper | 1 |
| 9515 | ímprobo | 1 |
| 9516 | imprimir | 1 |
| 9517 | imprescindible | 1 |
| 9518 | imprentar | 1 |
| 9519 | impregnar | 1 |
| 9520 | imprecar | 1 |
| 9521 | imprecación | 1 |
| 9522 | impotente | 1 |
| 9523 | impotencia | 1 |
| 9524 | impostura | 1 |
| 9525 | imposibilidad | 1 |
| 9526 | importantísimo | 1 |
| 9527 | importador | 1 |
| 9528 | implorar | 1 |
| 9529 | impermeable | 1 |
| 9530 | impericia | 1 |
| 9531 | imperial | 1 |
| 9532 | imperceptible | 1 |
| 9533 | imperativo | 1 |
| 9534 | imperar | 1 |
| 9535 | impecable | 1 |
| 9536 | imbuir | 1 |
| 9537 | imbécil | 1 |
| 9538 | imantar | 1 |
| 9539 | imagínole | 1 |
| 9540 | imaginativo | 1 |
| 9541 | imaginaria | 1 |
| 9542 | ilusorio | 1 |
| 9543 | iluso | 1 |
| 9544 | ilusionar | 1 |
| 9545 | iluminado | 1 |
| 9546 | ilmo | 1 |
| 9547 | iliterato | 1 |
| 9548 | ilíada | 1 |
| 9549 | ilegible | 1 |
| 9550 | ilegal | 1 |
| 9551 | iii | 1 |
| 9552 | ignoraba | 1 |
| 9553 | idilio | 1 |
| 9554 | idealizar | 1 |
| 9555 | ictericia | 1 |
| 9556 | ibérico | 1 |
| 9557 | iba | 1 |
| 9558 | huyo | 1 |
| 9559 | hurgar | 1 |
| 9560 | humorado | 1 |
| 9561 | humíllate | 1 |
| 9562 | humillante | 1 |
| 9563 | humeante | 1 |
| 9564 | humanizar | 1 |
| 9565 | humanitario | 1 |
| 9566 | huiría | 1 |
| 9567 | huiré | 1 |
| 9568 | hugonotes | 1 |
| 9569 | hugo | 1 |
| 9570 | hueste | 1 |
| 9571 | huesca | 1 |
| 9572 | hubo | 1 |
| 9573 | hoz | 1 |
| 9574 | hostilidad | 1 |
| 9575 | hospitalidad | 1 |
| 9576 | hospicio | 1 |
| 9577 | hospiciano | 1 |
| 9578 | horticultura | 1 |
| 9579 | hortelano | 1 |
| 9580 | horriblemente | 1 |
| 9581 | hormigueo | 1 |
| 9582 | horchatería | 1 |
| 9583 | horchata | 1 |
| 9584 | horas | 1 |
| 9585 | horadar | 1 |
| 9586 | honroso | 1 |
| 9587 | honradamente | 1 |
| 9588 | honores | 1 |
| 9589 | honorario | 1 |
| 9590 | honni | 1 |
| 9591 | honestidad | 1 |
| 9592 | honestamente | 1 |
| 9593 | hondura | 1 |
| 9594 | hondamente | 1 |
| 9595 | homo | 1 |
| 9596 | homero | 1 |
| 9597 | hombrear | 1 |
| 9598 | hollar | 1 |
| 9599 | holgazanería | 1 |
| 9600 | holgazán | 1 |
| 9601 | holgado | 1 |
| 9602 | holgadamente | 1 |
| 9603 | holanda | 1 |
| 9604 | hocico | 1 |
| 9605 | hita | 1 |
| 9606 | histerismo | 1 |
| 9607 | histérico | 1 |
| 9608 | hipotético | 1 |
| 9609 | hipotérmico | 1 |
| 9610 | hipotecar | 1 |
| 9611 | hipopótamo | 1 |
| 9612 | hipógrifo | 1 |
| 9613 | hipódromo | 1 |
| 9614 | hiperbólicamente | 1 |
| 9615 | hinojos | 1 |
| 9616 | hinchazón | 1 |
| 9617 | hinchado | 1 |
| 9618 | hincar | 1 |
| 9619 | hijuelo | 1 |
| 9620 | hijos | 1 |
| 9621 | hijita | 1 |
| 9622 | higuera | 1 |
| 9623 | hígado | 1 |
| 9624 | hidra | 1 |
| 9625 | hidalgo | 1 |
| 9626 | hicieron | 1 |
| 9627 | heterogéneo | 1 |
| 9628 | hervir | 1 |
| 9629 | herreros | 1 |
| 9630 | herradura | 1 |
| 9631 | heroísmo | 1 |
| 9632 | heroicidad | 1 |
| 9633 | herodías | 1 |
| 9634 | heresiarca | 1 |
| 9635 | heredad | 1 |
| 9636 | herborizar | 1 |
| 9637 | heráldica | 1 |
| 9638 | hepatitis | 1 |
| 9639 | henao | 1 |
| 9640 | helada | 1 |
| 9641 | hegemonía | 1 |
| 9642 | hedor | 1 |
| 9643 | hediondo | 1 |
| 9644 | hechura | 1 |
| 9645 | hechos | 1 |
| 9646 | haraposo | 1 |
| 9647 | hará | 1 |
| 9648 | hamlet | 1 |
| 9649 | hame | 1 |
| 9650 | hamaca | 1 |
| 9651 | halagüeño | 1 |
| 9652 | hagámonos | 1 |
| 9653 | haga | 1 |
| 9654 | hacía | 1 |
| 9655 | hachón | 1 |
| 9656 | hacerse | 1 |
| 9657 | hacerla | 1 |
| 9658 | habrán | 1 |
| 9659 | habrá | 1 |
| 9660 | habló | 1 |
| 9661 | hablo | 1 |
| 9662 | hablemos | 1 |
| 9663 | hablé | 1 |
| 9664 | hable | 1 |
| 9665 | hablas | 1 |
| 9666 | hablarme | 1 |
| 9667 | hablarle | 1 |
| 9668 | habitado | 1 |
| 9669 | hábilmente | 1 |
| 9670 | habéis | 1 |
| 9671 | haba | 1 |
| 9672 | gutierre | 1 |
| 9673 | gustoso | 1 |
| 9674 | gustazo | 1 |
| 9675 | guillotinar | 1 |
| 9676 | guillotina | 1 |
| 9677 | guerrero | 1 |
| 9678 | guedeja | 1 |
| 9679 | guasa | 1 |
| 9680 | guarecer | 1 |
| 9681 | guardilla | 1 |
| 9682 | guarden | 1 |
| 9683 | guardador | 1 |
| 9684 | guapetón | 1 |
| 9685 | guadalquivir | 1 |
| 9686 | gruyer | 1 |
| 9687 | grupa | 1 |
| 9688 | grijalte | 1 |
| 9689 | grifo | 1 |
| 9690 | grieta | 1 |
| 9691 | grecia | 1 |
| 9692 | gravísimo | 1 |
| 9693 | gravemente | 1 |
| 9694 | grato | 1 |
| 9695 | gratis | 1 |
| 9696 | grata | 1 |
| 9697 | granuja | 1 |
| 9698 | granizada | 1 |
| 9699 | granear | 1 |
| 9700 | grandilocuente | 1 |
| 9701 | granar | 1 |
| 9702 | gráfico | 1 |
| 9703 | graciosamente | 1 |
| 9704 | grabado | 1 |
| 9705 | gozo | 1 |
| 9706 | gozando | 1 |
| 9707 | gotear | 1 |
| 9708 | gorjeo | 1 |
| 9709 | gorjear | 1 |
| 9710 | gordas | 1 |
| 9711 | gonzález | 1 |
| 9712 | gongorino | 1 |
| 9713 | góngora | 1 |
| 9714 | góndola | 1 |
| 9715 | golondrina | 1 |
| 9716 | gollería | 1 |
| 9717 | golfo | 1 |
| 9718 | gobernadora | 1 |
| 9719 | gloriosamente | 1 |
| 9720 | giro | 1 |
| 9721 | giraldi | 1 |
| 9722 | gira | 1 |
| 9723 | gimnástico | 1 |
| 9724 | gimnasio | 1 |
| 9725 | gimió | 1 |
| 9726 | gil | 1 |
| 9727 | gestación | 1 |
| 9728 | gerundio | 1 |
| 9729 | geológico | 1 |
| 9730 | geográfico | 1 |
| 9731 | genuinamente | 1 |
| 9732 | gentío | 1 |
| 9733 | gentileza | 1 |
| 9734 | genil | 1 |
| 9735 | generoso | 1 |
| 9736 | generosidad | 1 |
| 9737 | gayo | 1 |
| 9738 | gayarre | 1 |
| 9739 | gauthier | 1 |
| 9740 | gatito | 1 |
| 9741 | gatillar | 1 |
| 9742 | gatazo | 1 |
| 9743 | gatas | 1 |
| 9744 | gastroenteritis | 1 |
| 9745 | gástrico | 1 |
| 9746 | gaseoso | 1 |
| 9747 | garzo | 1 |
| 9748 | garden | 1 |
| 9749 | garcilaso | 1 |
| 9750 | garcía | 1 |
| 9751 | garabato | 1 |
| 9752 | ganzúa | 1 |
| 9753 | ganas | 1 |
| 9754 | ganancial | 1 |
| 9755 | gamo | 1 |
| 9756 | galope | 1 |
| 9757 | gallinero | 1 |
| 9758 | gallardete | 1 |
| 9759 | gallardamente | 1 |
| 9760 | galileo | 1 |
| 9761 | galicismo | 1 |
| 9762 | galgo | 1 |
| 9763 | galera | 1 |
| 9764 | galdós | 1 |
| 9765 | galardonar | 1 |
| 9766 | galantear | 1 |
| 9767 | gaitero | 1 |
| 9768 | gacho | 1 |
| 9769 | futura | 1 |
| 9770 | fútil | 1 |
| 9771 | furibundo | 1 |
| 9772 | fungoso | 1 |
| 9773 | funesto | 1 |
| 9774 | fundición | 1 |
| 9775 | fundamentar | 1 |
| 9776 | funcionario | 1 |
| 9777 | fumador | 1 |
| 9778 | fulminar | 1 |
| 9779 | fulminante | 1 |
| 9780 | fulgor | 1 |
| 9781 | fulanito | 1 |
| 9782 | fulanita | 1 |
| 9783 | fuguillas | 1 |
| 9784 | fuga | 1 |
| 9785 | fuese | 1 |
| 9786 | fuertemente | 1 |
| 9787 | fuer | 1 |
| 9788 | fuelle | 1 |
| 9789 | fue | 1 |
| 9790 | frutal | 1 |
| 9791 | frustrar | 1 |
| 9792 | fruncir | 1 |
| 9793 | fruela | 1 |
| 9794 | frontón | 1 |
| 9795 | frontispicio | 1 |
| 9796 | frontero | 1 |
| 9797 | frontal | 1 |
| 9798 | frondoso | 1 |
| 9799 | frivolidad | 1 |
| 9800 | frito | 1 |
| 9801 | frigorífico | 1 |
| 9802 | fríamente | 1 |
| 9803 | fría | 1 |
| 9804 | freno | 1 |
| 9805 | frenéticos | 1 |
| 9806 | frenar | 1 |
| 9807 | fraternizar | 1 |
| 9808 | fraternal | 1 |
| 9809 | frascueeeelo | 1 |
| 9810 | francklin | 1 |
| 9811 | franciscos | 1 |
| 9812 | franciscas | 1 |
| 9813 | francesa | 1 |
| 9814 | fraigerundio | 1 |
| 9815 | fr | 1 |
| 9816 | fosforera | 1 |
| 9817 | fosco | 1 |
| 9818 | forzado | 1 |
| 9819 | fortuito | 1 |
| 9820 | fortalecer | 1 |
| 9821 | foro | 1 |
| 9822 | fornos | 1 |
| 9823 | formulismo | 1 |
| 9824 | formular | 1 |
| 9825 | formado | 1 |
| 9826 | forjar | 1 |
| 9827 | forajido | 1 |
| 9828 | fontanero | 1 |
| 9829 | follar | 1 |
| 9830 | fogonazo | 1 |
| 9831 | foco | 1 |
| 9832 | fluir | 1 |
| 9833 | floricultor | 1 |
| 9834 | flórez | 1 |
| 9835 | flores | 1 |
| 9836 | florero | 1 |
| 9837 | flema | 1 |
| 9838 | fleco | 1 |
| 9839 | flammarión | 1 |
| 9840 | flamígero | 1 |
| 9841 | flagrante | 1 |
| 9842 | fisiólogo | 1 |
| 9843 | fisiológicamente | 1 |
| 9844 | fiscalía | 1 |
| 9845 | firmeza | 1 |
| 9846 | firmaba | 1 |
| 9847 | finge | 1 |
| 9848 | fineza | 1 |
| 9849 | fincar | 1 |
| 9850 | finca | 1 |
| 9851 | filtro | 1 |
| 9852 | filtración | 1 |
| 9853 | filón | 1 |
| 9854 | filius | 1 |
| 9855 | filis | 1 |
| 9856 | filete | 1 |
| 9857 | filarmónico | 1 |
| 9858 | filantropía | 1 |
| 9859 | fijamente | 1 |
| 9860 | figurilla | 1 |
| 9861 | figúrese | 1 |
| 9862 | fierabrás | 1 |
| 9863 | fielding | 1 |
| 9864 | fidelísimo | 1 |
| 9865 | fichar | 1 |
| 9866 | feudalismo | 1 |
| 9867 | fétido | 1 |
| 9868 | fervoroso | 1 |
| 9869 | fertilidad | 1 |
| 9870 | fértil | 1 |
| 9871 | feroz | 1 |
| 9872 | fermento | 1 |
| 9873 | fermentar | 1 |
| 9874 | felpudo | 1 |
| 9875 | felices | 1 |
| 9876 | feijóo | 1 |
| 9877 | federación | 1 |
| 9878 | fecundo | 1 |
| 9879 | fecundar | 1 |
| 9880 | febrero | 1 |
| 9881 | faz | 1 |
| 9882 | fatalista | 1 |
| 9883 | fastidioso | 1 |
| 9884 | fastidiar | 1 |
| 9885 | farnesios | 1 |
| 9886 | faringe | 1 |
| 9887 | faraones | 1 |
| 9888 | fantásticamente | 1 |
| 9889 | fantasear | 1 |
| 9890 | fanfarrón | 1 |
| 9891 | fanal | 1 |
| 9892 | famosísimo | 1 |
| 9893 | familiaridad | 1 |
| 9894 | faltriquera | 1 |
| 9895 | fallo | 1 |
| 9896 | fallido | 1 |
| 9897 | fallecer | 1 |
| 9898 | fallar | 1 |
| 9899 | falange | 1 |
| 9900 | faisán | 1 |
| 9901 | facistol | 1 |
| 9902 | facilidad | 1 |
| 9903 | facial | 1 |
| 9904 | fachenda | 1 |
| 9905 | fábula | 1 |
| 9906 | fabricante | 1 |
| 9907 | fabiolita | 1 |
| 9908 | f | 1 |
| 9909 | extremidad | 1 |
| 9910 | extremeño | 1 |
| 9911 | extremado | 1 |
| 9912 | extraer | 1 |
| 9913 | extenuado | 1 |
| 9914 | extendido | 1 |
| 9915 | extático | 1 |
| 9916 | expropiación | 1 |
| 9917 | exprofeso | 1 |
| 9918 | exprimir | 1 |
| 9919 | expreso | 1 |
| 9920 | expresivo | 1 |
| 9921 | expositio | 1 |
| 9922 | exportar | 1 |
| 9923 | explotación | 1 |
| 9924 | explosivo | 1 |
| 9925 | explosión | 1 |
| 9926 | explorar | 1 |
| 9927 | exploración | 1 |
| 9928 | expirar | 1 |
| 9929 | expeditar | 1 |
| 9930 | expedientar | 1 |
| 9931 | expedicionario | 1 |
| 9932 | expectación | 1 |
| 9933 | existente | 1 |
| 9934 | exíjase | 1 |
| 9935 | exiguo | 1 |
| 9936 | exhausto | 1 |
| 9937 | exhalar | 1 |
| 9938 | exentar | 1 |
| 9939 | exegético | 1 |
| 9940 | excusa | 1 |
| 9941 | excursionar | 1 |
| 9942 | exclamación | 1 |
| 9943 | excesivamente | 1 |
| 9944 | exceptuar | 1 |
| 9945 | exceder | 1 |
| 9946 | excavación | 1 |
| 9947 | evidentemente | 1 |
| 9948 | evangelii | 1 |
| 9949 | eucalipto | 1 |
| 9950 | etrusco | 1 |
| 9951 | ética | 1 |
| 9952 | eternizar | 1 |
| 9953 | estupro | 1 |
| 9954 | estupor | 1 |
| 9955 | estupendo | 1 |
| 9956 | estupefacción | 1 |
| 9957 | estudioso | 1 |
| 9958 | estudia | 1 |
| 9959 | estuche | 1 |
| 9960 | estricto | 1 |
| 9961 | estribor | 1 |
| 9962 | estrepitosos | 1 |
| 9963 | estremecimiento | 1 |
| 9964 | estrangulado | 1 |
| 9965 | estrangulación | 1 |
| 9966 | estragado | 1 |
| 9967 | estornino | 1 |
| 9968 | estorbaré | 1 |
| 9969 | estola | 1 |
| 9970 | estofa | 1 |
| 9971 | estocada | 1 |
| 9972 | estirpe | 1 |
| 9973 | estirado | 1 |
| 9974 | estimular | 1 |
| 9975 | estilita | 1 |
| 9976 | estética | 1 |
| 9977 | estereotipar | 1 |
| 9978 | esterar | 1 |
| 9979 | ester | 1 |
| 9980 | estepa | 1 |
| 9981 | esté | 1 |
| 9982 | estatuto | 1 |
| 9983 | estate | 1 |
| 9984 | estarían | 1 |
| 9985 | estará | 1 |
| 9986 | estaño | 1 |
| 9987 | estañar | 1 |
| 9988 | estanquero | 1 |
| 9989 | estanque | 1 |
| 9990 | estancamiento | 1 |
| 9991 | estancado | 1 |
| 9992 | estampilla | 1 |
| 9993 | estaciones | 1 |
| 9994 | estacar | 1 |
| 9995 | estable | 1 |
| 9996 | esquilache | 1 |
| 9997 | esquila | 1 |
| 9998 | esquela | 1 |
| 9999 | espuela | 1 |
| 10000 | esponjoso | 1 |
| 10001 | espliego | 1 |
| 10002 | espíritus | 1 |
| 10003 | espirituoso | 1 |
| 10004 | espiritualista | 1 |
| 10005 | espino | 1 |
| 10006 | espinazo | 1 |
| 10007 | espigar | 1 |
| 10008 | espesura | 1 |
| 10009 | esperaría | 1 |
| 10010 | esperará | 1 |
| 10011 | espejismo | 1 |
| 10012 | especificar | 1 |
| 10013 | especialísimo | 1 |
| 10014 | espartero | 1 |
| 10015 | española | 1 |
| 10016 | espantajo | 1 |
| 10017 | espantadizo | 1 |
| 10018 | espaldera | 1 |
| 10019 | esotérico | 1 |
| 10020 | esos | 1 |
| 10021 | esmerado | 1 |
| 10022 | escupió | 1 |
| 10023 | escultórico | 1 |
| 10024 | escultor | 1 |
| 10025 | escuadrar | 1 |
| 10026 | escrupulosidad | 1 |
| 10027 | escrupulosamente | 1 |
| 10028 | escritura | 1 |
| 10029 | escribió | 1 |
| 10030 | escríbame | 1 |
| 10031 | escriba | 1 |
| 10032 | escozor | 1 |
| 10033 | escotillón | 1 |
| 10034 | escosura | 1 |
| 10035 | escoria | 1 |
| 10036 | escondrijo | 1 |
| 10037 | escondidos | 1 |
| 10038 | escombro | 1 |
| 10039 | escolta | 1 |
| 10040 | escolástica | 1 |
| 10041 | escogido | 1 |
| 10042 | esclarecer | 1 |
| 10043 | escepticismo | 1 |
| 10044 | escénico | 1 |
| 10045 | escayola | 1 |
| 10046 | escatimar | 1 |
| 10047 | escarnecer | 1 |
| 10048 | escarmentar | 1 |
| 10049 | escapulario | 1 |
| 10050 | escandalizarse | 1 |
| 10051 | escamar | 1 |
| 10052 | escamandro | 1 |
| 10053 | escalpelo | 1 |
| 10054 | escalón | 1 |
| 10055 | escalofriar | 1 |
| 10056 | escabroso | 1 |
| 10057 | eruditamente | 1 |
| 10058 | erudición | 1 |
| 10059 | eructar | 1 |
| 10060 | erróneo | 1 |
| 10061 | errante | 1 |
| 10062 | erradamente | 1 |
| 10063 | erotismo | 1 |
| 10064 | ermitaño | 1 |
| 10065 | erizado | 1 |
| 10066 | erario | 1 |
| 10067 | equívoco | 1 |
| 10068 | equivocado | 1 |
| 10069 | equivaler | 1 |
| 10070 | equitativo | 1 |
| 10071 | equinoccio | 1 |
| 10072 | equilibrar | 1 |
| 10073 | epopeya | 1 |
| 10074 | episcopal | 1 |
| 10075 | epílogo | 1 |
| 10076 | epigramático | 1 |
| 10077 | epidemia | 1 |
| 10078 | epicuro | 1 |
| 10079 | epicureísmo | 1 |
| 10080 | epiceno | 1 |
| 10081 | envuelto | 1 |
| 10082 | envoltorio | 1 |
| 10083 | enviar | 1 |
| 10084 | enviado | 1 |
| 10085 | envejecido | 1 |
| 10086 | envanecer | 1 |
| 10087 | enumerar | 1 |
| 10088 | entusiasta | 1 |
| 10089 | entumecimiento | 1 |
| 10090 | entrometer | 1 |
| 10091 | entreverar | 1 |
| 10092 | entretenimiento | 1 |
| 10093 | entresuelo | 1 |
| 10094 | entregarme | 1 |
| 10095 | entraré | 1 |
| 10096 | entra | 1 |
| 10097 | entorpecimiento | 1 |
| 10098 | entonar | 1 |
| 10099 | entonado | 1 |
| 10100 | entomólogo | 1 |
| 10101 | entidad | 1 |
| 10102 | entibiar | 1 |
| 10103 | enterrador | 1 |
| 10104 | enterado | 1 |
| 10105 | entendimiento | 1 |
| 10106 | entendido | 1 |
| 10107 | entendedor | 1 |
| 10108 | entendámonos | 1 |
| 10109 | ente | 1 |
| 10110 | entallar | 1 |
| 10111 | ensuciar | 1 |
| 10112 | ensortijar | 1 |
| 10113 | ensoñador | 1 |
| 10114 | ensoñación | 1 |
| 10115 | ensartar | 1 |
| 10116 | ensanche | 1 |
| 10117 | enrevesado | 1 |
| 10118 | enramar | 1 |
| 10119 | enojar | 1 |
| 10120 | enmudecer | 1 |
| 10121 | enmendar | 1 |
| 10122 | enmascarar | 1 |
| 10123 | enlutado | 1 |
| 10124 | enloquecer | 1 |
| 10125 | enjuto | 1 |
| 10126 | enjambre | 1 |
| 10127 | enigma | 1 |
| 10128 | enhestar | 1 |
| 10129 | engolfar | 1 |
| 10130 | englobar | 1 |
| 10131 | engalanar | 1 |
| 10132 | enfurecer | 1 |
| 10133 | enfundar | 1 |
| 10134 | enfrenar | 1 |
| 10135 | enfilar | 1 |
| 10136 | enfermero | 1 |
| 10137 | enervar | 1 |
| 10138 | enemistad | 1 |
| 10139 | enderezar | 1 |
| 10140 | endemoniado | 1 |
| 10141 | endémico | 1 |
| 10142 | encorvada | 1 |
| 10143 | encopetar | 1 |
| 10144 | encontrado | 1 |
| 10145 | encontrábase | 1 |
| 10146 | encomienda | 1 |
| 10147 | encogimiento | 1 |
| 10148 | encogido | 1 |
| 10149 | encinta | 1 |
| 10150 | enciende | 1 |
| 10151 | encienda | 1 |
| 10152 | enchufar | 1 |
| 10153 | encharcado | 1 |
| 10154 | encerar | 1 |
| 10155 | encauzar | 1 |
| 10156 | encarnizado | 1 |
| 10157 | encarnación | 1 |
| 10158 | encarecer | 1 |
| 10159 | encarcelar | 1 |
| 10160 | encapotado | 1 |
| 10161 | encantador | 1 |
| 10162 | encantado | 1 |
| 10163 | enano | 1 |
| 10164 | enamoramiento | 1 |
| 10165 | enaltecer | 1 |
| 10166 | enajenación | 1 |
| 10167 | emulación | 1 |
| 10168 | empujón | 1 |
| 10169 | empuje | 1 |
| 10170 | emprendedor | 1 |
| 10171 | empleara | 1 |
| 10172 | emplazamiento | 1 |
| 10173 | emplasto | 1 |
| 10174 | empinar | 1 |
| 10175 | empinado | 1 |
| 10176 | empieza | 1 |
| 10177 | empezó | 1 |
| 10178 | emperifollar | 1 |
| 10179 | emperador | 1 |
| 10180 | empequeñecer | 1 |
| 10181 | empeorar | 1 |
| 10182 | empeñarse | 1 |
| 10183 | empedernir | 1 |
| 10184 | emparejarse | 1 |
| 10185 | emparedar | 1 |
| 10186 | emparedado | 1 |
| 10187 | empanar | 1 |
| 10188 | empanada | 1 |
| 10189 | empalmar | 1 |
| 10190 | empalagoso | 1 |
| 10191 | empadronar | 1 |
| 10192 | emocionar | 1 |
| 10193 | eminentemente | 1 |
| 10194 | emigró | 1 |
| 10195 | embuste | 1 |
| 10196 | embrutecimiento | 1 |
| 10197 | embrujar | 1 |
| 10198 | embrollo | 1 |
| 10199 | embrión | 1 |
| 10200 | embozado | 1 |
| 10201 | embotar | 1 |
| 10202 | emboscar | 1 |
| 10203 | embobar | 1 |
| 10204 | embellecer | 1 |
| 10205 | embeleso | 1 |
| 10206 | embebecer | 1 |
| 10207 | embarcar | 1 |
| 10208 | embajada | 1 |
| 10209 | emancipación | 1 |
| 10210 | eludir | 1 |
| 10211 | eloïm | 1 |
| 10212 | elevado | 1 |
| 10213 | elegantemente | 1 |
| 10214 | elefante | 1 |
| 10215 | elástico | 1 |
| 10216 | elaboración | 1 |
| 10217 | ejercitar | 1 |
| 10218 | ejecutor | 1 |
| 10219 | ejecutivo | 1 |
| 10220 | ejecución | 1 |
| 10221 | ego | 1 |
| 10222 | égloga | 1 |
| 10223 | egeria | 1 |
| 10224 | efusivo | 1 |
| 10225 | efluvio | 1 |
| 10226 | efímera | 1 |
| 10227 | efectivo | 1 |
| 10228 | eduardo | 1 |
| 10229 | edicto | 1 |
| 10230 | edgar | 1 |
| 10231 | ecuestre | 1 |
| 10232 | economizar | 1 |
| 10233 | economista | 1 |
| 10234 | economato | 1 |
| 10235 | eclipse | 1 |
| 10236 | échele | 1 |
| 10237 | echarla | 1 |
| 10238 | echada | 1 |
| 10239 | ebro | 1 |
| 10240 | ébano | 1 |
| 10241 | ebanista | 1 |
| 10242 | duración | 1 |
| 10243 | dupanloup | 1 |
| 10244 | dúo | 1 |
| 10245 | dumio | 1 |
| 10246 | dumas | 1 |
| 10247 | duerme | 1 |
| 10248 | dudó | 1 |
| 10249 | dúctil | 1 |
| 10250 | ducha | 1 |
| 10251 | dualista | 1 |
| 10252 | dramaturgo | 1 |
| 10253 | doy | 1 |
| 10254 | dovela | 1 |
| 10255 | dosis | 1 |
| 10256 | dorso | 1 |
| 10257 | dormitorio | 1 |
| 10258 | donoso | 1 |
| 10259 | donar | 1 |
| 10260 | dominus | 1 |
| 10261 | dómine | 1 |
| 10262 | domiciliar | 1 |
| 10263 | domesticar | 1 |
| 10264 | domar | 1 |
| 10265 | döllinger | 1 |
| 10266 | docente | 1 |
| 10267 | doblado | 1 |
| 10268 | divisible | 1 |
| 10269 | divina | 1 |
| 10270 | divertirme | 1 |
| 10271 | divertidísimo | 1 |
| 10272 | distributivo | 1 |
| 10273 | distribución | 1 |
| 10274 | distintivo | 1 |
| 10275 | distintamente | 1 |
| 10276 | distanciar | 1 |
| 10277 | displicencia | 1 |
| 10278 | disperso | 1 |
| 10279 | dispersión | 1 |
| 10280 | disparo | 1 |
| 10281 | disoluto | 1 |
| 10282 | dislocar | 1 |
| 10283 | dislocado | 1 |
| 10284 | dislate | 1 |
| 10285 | disipar | 1 |
| 10286 | disimulaba | 1 |
| 10287 | disimula | 1 |
| 10288 | disertar | 1 |
| 10289 | disculpas | 1 |
| 10290 | disculpable | 1 |
| 10291 | discretear | 1 |
| 10292 | disciplinario | 1 |
| 10293 | discernir | 1 |
| 10294 | dirían | 1 |
| 10295 | diretes | 1 |
| 10296 | diré | 1 |
| 10297 | diputación | 1 |
| 10298 | dionisíaco | 1 |
| 10299 | dintel | 1 |
| 10300 | dinastía | 1 |
| 10301 | dinamitar | 1 |
| 10302 | dimisionario | 1 |
| 10303 | diminuto | 1 |
| 10304 | dimes | 1 |
| 10305 | dilucidar | 1 |
| 10306 | dilatación | 1 |
| 10307 | díjolo | 1 |
| 10308 | dijeron | 1 |
| 10309 | dije | 1 |
| 10310 | dignificar | 1 |
| 10311 | dignatario | 1 |
| 10312 | dignamente | 1 |
| 10313 | digestivo | 1 |
| 10314 | digerir | 1 |
| 10315 | dígase | 1 |
| 10316 | díganme | 1 |
| 10317 | dígame | 1 |
| 10318 | dígalo | 1 |
| 10319 | difuntos | 1 |
| 10320 | dificilísimo | 1 |
| 10321 | diferenciar | 1 |
| 10322 | diezmo | 1 |
| 10323 | dieta | 1 |
| 10324 | diestra | 1 |
| 10325 | diecisiete | 1 |
| 10326 | dictatorial | 1 |
| 10327 | dictamen | 1 |
| 10328 | dictadura | 1 |
| 10329 | dickens | 1 |
| 10330 | dichas | 1 |
| 10331 | dicharachero | 1 |
| 10332 | dibujado | 1 |
| 10333 | días | 1 |
| 10334 | diapasón | 1 |
| 10335 | diana | 1 |
| 10336 | diáfano | 1 |
| 10337 | diácono | 1 |
| 10338 | diabluras | 1 |
| 10339 | diablos | 1 |
| 10340 | devastación | 1 |
| 10341 | devanadera | 1 |
| 10342 | deudo | 1 |
| 10343 | detonación | 1 |
| 10344 | determinación | 1 |
| 10345 | deteriorar | 1 |
| 10346 | detenidamente | 1 |
| 10347 | detalle | 1 |
| 10348 | desvivir | 1 |
| 10349 | desviar | 1 |
| 10350 | desventurado | 1 |
| 10351 | desvencijar | 1 |
| 10352 | desvelo | 1 |
| 10353 | desvelar | 1 |
| 10354 | desvarío | 1 |
| 10355 | desvanecimiento | 1 |
| 10356 | desvanecido | 1 |
| 10357 | desvalijar | 1 |
| 10358 | desuso | 1 |
| 10359 | destrucción | 1 |
| 10360 | destrozado | 1 |
| 10361 | destreza | 1 |
| 10362 | desteñir | 1 |
| 10363 | destartalado | 1 |
| 10364 | destajo | 1 |
| 10365 | desquitar | 1 |
| 10366 | despuntar | 1 |
| 10367 | desprovisto | 1 |
| 10368 | despropósito | 1 |
| 10369 | desproporcionado | 1 |
| 10370 | desprestigio | 1 |
| 10371 | despreocupado | 1 |
| 10372 | despoblar | 1 |
| 10373 | desplegar | 1 |
| 10374 | despídame | 1 |
| 10375 | desperezar | 1 |
| 10376 | desperdicio | 1 |
| 10377 | despeñar | 1 |
| 10378 | despeluznar | 1 |
| 10379 | despejado | 1 |
| 10380 | despeinar | 1 |
| 10381 | despego | 1 |
| 10382 | despear | 1 |
| 10383 | despeado | 1 |
| 10384 | despavorido | 1 |
| 10385 | desparpajar | 1 |
| 10386 | despabilar | 1 |
| 10387 | desorientar | 1 |
| 10388 | desollar | 1 |
| 10389 | desolación | 1 |
| 10390 | desocupado | 1 |
| 10391 | desmesurar | 1 |
| 10392 | desmentir | 1 |
| 10393 | desmedido | 1 |
| 10394 | desmayado | 1 |
| 10395 | desmañado | 1 |
| 10396 | desmantelar | 1 |
| 10397 | desmán | 1 |
| 10398 | desleír | 1 |
| 10399 | desidia | 1 |
| 10400 | deshora | 1 |
| 10401 | deshonesto | 1 |
| 10402 | deshojar | 1 |
| 10403 | deshilachar | 1 |
| 10404 | desheredar | 1 |
| 10405 | desgarrador | 1 |
| 10406 | desgajar | 1 |
| 10407 | desfiladero | 1 |
| 10408 | desfigurar | 1 |
| 10409 | desfigurado | 1 |
| 10410 | desfavorable | 1 |
| 10411 | deseoso | 1 |
| 10412 | desenvoltura | 1 |
| 10413 | desenterrar | 1 |
| 10414 | desentender | 1 |
| 10415 | desenlazar | 1 |
| 10416 | desenfreno | 1 |
| 10417 | desenfadar | 1 |
| 10418 | desencanto | 1 |
| 10419 | desencajar | 1 |
| 10420 | desencadenar | 1 |
| 10421 | desembolso | 1 |
| 10422 | desembarco | 1 |
| 10423 | desecho | 1 |
| 10424 | desdoro | 1 |
| 10425 | desdentado | 1 |
| 10426 | desdecir | 1 |
| 10427 | descuide | 1 |
| 10428 | descubridor | 1 |
| 10429 | descuartizar | 1 |
| 10430 | descreimiento | 1 |
| 10431 | descotado | 1 |
| 10432 | descoser | 1 |
| 10433 | descontentar | 1 |
| 10434 | desconcierto | 1 |
| 10435 | descompasar | 1 |
| 10436 | descoco | 1 |
| 10437 | descenso | 1 |
| 10438 | descendimiento | 1 |
| 10439 | descastado | 1 |
| 10440 | descarado | 1 |
| 10441 | descaminado | 1 |
| 10442 | descalzas | 1 |
| 10443 | desbordar | 1 |
| 10444 | desbordado | 1 |
| 10445 | desazonar | 1 |
| 10446 | desayuno | 1 |
| 10447 | desatinar | 1 |
| 10448 | desasosiego | 1 |
| 10449 | desasir | 1 |
| 10450 | desarróllase | 1 |
| 10451 | desarrollado | 1 |
| 10452 | desarreglo | 1 |
| 10453 | desaprobación | 1 |
| 10454 | desapasionado | 1 |
| 10455 | desaparición | 1 |
| 10456 | desapacible | 1 |
| 10457 | desanimado | 1 |
| 10458 | desandar | 1 |
| 10459 | desamparado | 1 |
| 10460 | desaliño | 1 |
| 10461 | desalentar | 1 |
| 10462 | desalar | 1 |
| 10463 | desagradecido | 1 |
| 10464 | desacierto | 1 |
| 10465 | desabrochar | 1 |
| 10466 | desabrimiento | 1 |
| 10467 | derrotado | 1 |
| 10468 | derrota | 1 |
| 10469 | derrochar | 1 |
| 10470 | derrengar | 1 |
| 10471 | derrame | 1 |
| 10472 | derramamiento | 1 |
| 10473 | derivado | 1 |
| 10474 | derivación | 1 |
| 10475 | depositario | 1 |
| 10476 | dentera | 1 |
| 10477 | dentadura | 1 |
| 10478 | denso | 1 |
| 10479 | densidad | 1 |
| 10480 | demontre | 1 |
| 10481 | demoler | 1 |
| 10482 | demodoco | 1 |
| 10483 | demanda | 1 |
| 10484 | deleitábale | 1 |
| 10485 | delegar | 1 |
| 10486 | delegación | 1 |
| 10487 | delantera | 1 |
| 10488 | dejen | 1 |
| 10489 | déjeme | 1 |
| 10490 | dejaría | 1 |
| 10491 | dejará | 1 |
| 10492 | dejando | 1 |
| 10493 | déjale | 1 |
| 10494 | déjala | 1 |
| 10495 | deísmo | 1 |
| 10496 | degollado | 1 |
| 10497 | defraudar | 1 |
| 10498 | deforme | 1 |
| 10499 | definitivo | 1 |
| 10500 | definitivamente | 1 |
| 10501 | deficiencia | 1 |
| 10502 | defensivo | 1 |
| 10503 | deducir | 1 |
| 10504 | decorar | 1 |
| 10505 | declive | 1 |
| 10506 | declamador | 1 |
| 10507 | declamación | 1 |
| 10508 | decisión | 1 |
| 10509 | decirle | 1 |
| 10510 | decimal | 1 |
| 10511 | decentemente | 1 |
| 10512 | decantar | 1 |
| 10513 | decálogo | 1 |
| 10514 | decaído | 1 |
| 10515 | débilmente | 1 |
| 10516 | debilitar | 1 |
| 10517 | debatir | 1 |
| 10518 | dativo | 1 |
| 10519 | date | 1 |
| 10520 | datar | 1 |
| 10521 | darwin | 1 |
| 10522 | darro | 1 |
| 10523 | daría | 1 |
| 10524 | danzar | 1 |
| 10525 | dante | 1 |
| 10526 | dandy | 1 |
| 10527 | dan | 1 |
| 10528 | damisela | 1 |
| 10529 | dame | 1 |
| 10530 | dalila | 1 |
| 10531 | daga | 1 |
| 10532 | dadme | 1 |
| 10533 | daba | 1 |
| 10534 | cúspide | 1 |
| 10535 | curvo | 1 |
| 10536 | cursilón | 1 |
| 10537 | curita | 1 |
| 10538 | curiosón | 1 |
| 10539 | cúpula | 1 |
| 10540 | cuota | 1 |
| 10541 | cuneta | 1 |
| 10542 | cumplidamente | 1 |
| 10543 | cumpleaños | 1 |
| 10544 | culata | 1 |
| 10545 | cuestor | 1 |
| 10546 | cuesta | 1 |
| 10547 | cuerdamente | 1 |
| 10548 | cuchufleta | 1 |
| 10549 | cucharilla | 1 |
| 10550 | cucharada | 1 |
| 10551 | cubríale | 1 |
| 10552 | cubilete | 1 |
| 10553 | cúbico | 1 |
| 10554 | cuartucho | 1 |
| 10555 | cuartilla | 1 |
| 10556 | cuajar | 1 |
| 10557 | cuadricular | 1 |
| 10558 | crusología | 1 |
| 10559 | crudeza | 1 |
| 10560 | crucifixión | 1 |
| 10561 | cromático | 1 |
| 10562 | cristos | 1 |
| 10563 | cristóbal | 1 |
| 10564 | cristiana | 1 |
| 10565 | cristalería | 1 |
| 10566 | crispado | 1 |
| 10567 | crisol | 1 |
| 10568 | crisálida | 1 |
| 10569 | crin | 1 |
| 10570 | criminalmente | 1 |
| 10571 | cría | 1 |
| 10572 | creyó | 1 |
| 10573 | creyendo | 1 |
| 10574 | crema | 1 |
| 10575 | creíale | 1 |
| 10576 | creería | 1 |
| 10577 | créanlo | 1 |
| 10578 | créame | 1 |
| 10579 | coz | 1 |
| 10580 | coyuntura | 1 |
| 10581 | covent | 1 |
| 10582 | covadonga | 1 |
| 10583 | cotorra | 1 |
| 10584 | coto | 1 |
| 10585 | cotización | 1 |
| 10586 | cotidiano | 1 |
| 10587 | cotarro | 1 |
| 10588 | cota | 1 |
| 10589 | costoso | 1 |
| 10590 | costera | 1 |
| 10591 | cosquilleo | 1 |
| 10592 | cosmético | 1 |
| 10593 | cosechero | 1 |
| 10594 | cosechar | 1 |
| 10595 | cosecha | 1 |
| 10596 | corzo | 1 |
| 10597 | corvo | 1 |
| 10598 | corva | 1 |
| 10599 | cortinilla | 1 |
| 10600 | cortes | 1 |
| 10601 | corsé | 1 |
| 10602 | corruptela | 1 |
| 10603 | corroboraba | 1 |
| 10604 | corrió | 1 |
| 10605 | corrigió | 1 |
| 10606 | correveidile | 1 |
| 10607 | correría | 1 |
| 10608 | correctamente | 1 |
| 10609 | correa | 1 |
| 10610 | corre | 1 |
| 10611 | corralón | 1 |
| 10612 | corpiño | 1 |
| 10613 | coronilla | 1 |
| 10614 | corolario | 1 |
| 10615 | corneta | 1 |
| 10616 | cornamenta | 1 |
| 10617 | corintio | 1 |
| 10618 | córdoba | 1 |
| 10619 | cordialmente | 1 |
| 10620 | cordero | 1 |
| 10621 | corcovar | 1 |
| 10622 | corchete | 1 |
| 10623 | corbatín | 1 |
| 10624 | corazoncito | 1 |
| 10625 | coral | 1 |
| 10626 | copiosamente | 1 |
| 10627 | copar | 1 |
| 10628 | coordinar | 1 |
| 10629 | convulso | 1 |
| 10630 | convivencia | 1 |
| 10631 | convídesele | 1 |
| 10632 | converso | 1 |
| 10633 | convergencia | 1 |
| 10634 | conventual | 1 |
| 10635 | convencido | 1 |
| 10636 | contumaz | 1 |
| 10637 | contrincante | 1 |
| 10638 | contrición | 1 |
| 10639 | contribuyente | 1 |
| 10640 | contribución | 1 |
| 10641 | contratar | 1 |
| 10642 | contratante | 1 |
| 10643 | contrasentido | 1 |
| 10644 | contrariar | 1 |
| 10645 | contrabandista | 1 |
| 10646 | contorsionar | 1 |
| 10647 | contoneo | 1 |
| 10648 | contestaron | 1 |
| 10649 | contestaban | 1 |
| 10650 | contestaba | 1 |
| 10651 | contentadizo | 1 |
| 10652 | contender | 1 |
| 10653 | contemplativo | 1 |
| 10654 | contarían | 1 |
| 10655 | contado | 1 |
| 10656 | consumidor | 1 |
| 10657 | consumado | 1 |
| 10658 | consultado | 1 |
| 10659 | consuetudinario | 1 |
| 10660 | construcción | 1 |
| 10661 | constituían | 1 |
| 10662 | constitución | 1 |
| 10663 | constipado | 1 |
| 10664 | consternar | 1 |
| 10665 | constantinopla | 1 |
| 10666 | consorte | 1 |
| 10667 | consonante | 1 |
| 10668 | consolidar | 1 |
| 10669 | consistorios | 1 |
| 10670 | consigo | 1 |
| 10671 | consigna | 1 |
| 10672 | conserjería | 1 |
| 10673 | consentido | 1 |
| 10674 | conocía | 1 |
| 10675 | conoce | 1 |
| 10676 | cono | 1 |
| 10677 | conmutar | 1 |
| 10678 | conmover | 1 |
| 10679 | conmiseración | 1 |
| 10680 | conmemorar | 1 |
| 10681 | conjuro | 1 |
| 10682 | conjurado | 1 |
| 10683 | conjuntar | 1 |
| 10684 | cónico | 1 |
| 10685 | congraciar | 1 |
| 10686 | congestión | 1 |
| 10687 | congeniar | 1 |
| 10688 | confusamente | 1 |
| 10689 | confortante | 1 |
| 10690 | confortable | 1 |
| 10691 | confitero | 1 |
| 10692 | confirmó | 1 |
| 10693 | confirmación | 1 |
| 10694 | confirmábase | 1 |
| 10695 | confiado | 1 |
| 10696 | conferencias | 1 |
| 10697 | confeccionar | 1 |
| 10698 | condiscípulo | 1 |
| 10699 | condimento | 1 |
| 10700 | condiciones | 1 |
| 10701 | condescendiente | 1 |
| 10702 | condensar | 1 |
| 10703 | condecoración | 1 |
| 10704 | concurrido | 1 |
| 10705 | concupiscente | 1 |
| 10706 | concupiscencia | 1 |
| 10707 | concretamente | 1 |
| 10708 | concordato | 1 |
| 10709 | concluyó | 1 |
| 10710 | concluía | 1 |
| 10711 | conciso | 1 |
| 10712 | conciliar | 1 |
| 10713 | concesión | 1 |
| 10714 | conceptuoso | 1 |
| 10715 | cóncavo | 1 |
| 10716 | comúnmente | 1 |
| 10717 | comunidad | 1 |
| 10718 | comunicación | 1 |
| 10719 | compunción | 1 |
| 10720 | compuerta | 1 |
| 10721 | comprendió | 1 |
| 10722 | comprendía | 1 |
| 10723 | compre | 1 |
| 10724 | comprador | 1 |
| 10725 | compostura | 1 |
| 10726 | componenda | 1 |
| 10727 | complicidad | 1 |
| 10728 | complemento | 1 |
| 10729 | complaciente | 1 |
| 10730 | competente | 1 |
| 10731 | compenetrar | 1 |
| 10732 | compasivo | 1 |
| 10733 | comparado | 1 |
| 10734 | compacto | 1 |
| 10735 | comisura | 1 |
| 10736 | comistrajo | 1 |
| 10737 | comisionista | 1 |
| 10738 | comisionar | 1 |
| 10739 | comisionado | 1 |
| 10740 | comisario | 1 |
| 10741 | comino | 1 |
| 10742 | cominero | 1 |
| 10743 | comilona | 1 |
| 10744 | comienzo | 1 |
| 10745 | comido | 1 |
| 10746 | cómetela | 1 |
| 10747 | comería | 1 |
| 10748 | comercial | 1 |
| 10749 | comehostias | 1 |
| 10750 | comedimiento | 1 |
| 10751 | combustión | 1 |
| 10752 | comarcano | 1 |
| 10753 | coma | 1 |
| 10754 | colosal | 1 |
| 10755 | colorín | 1 |
| 10756 | colorete | 1 |
| 10757 | colmillo | 1 |
| 10758 | collar | 1 |
| 10759 | collado | 1 |
| 10760 | colgadizo | 1 |
| 10761 | colérico | 1 |
| 10762 | colegiala | 1 |
| 10763 | colectividad | 1 |
| 10764 | colectivamente | 1 |
| 10765 | coleccionar | 1 |
| 10766 | colasa | 1 |
| 10767 | colaborar | 1 |
| 10768 | coimbra | 1 |
| 10769 | cofre | 1 |
| 10770 | coercitivo | 1 |
| 10771 | codicioso | 1 |
| 10772 | cocido | 1 |
| 10773 | cocer | 1 |
| 10774 | cobos | 1 |
| 10775 | cobertizo | 1 |
| 10776 | coadjutor | 1 |
| 10777 | climatológico | 1 |
| 10778 | clavija | 1 |
| 10779 | clavetear | 1 |
| 10780 | clave | 1 |
| 10781 | clavada | 1 |
| 10782 | cláusula | 1 |
| 10783 | claudio | 1 |
| 10784 | claraboya | 1 |
| 10785 | clandestinamente | 1 |
| 10786 | clamor | 1 |
| 10787 | civis | 1 |
| 10788 | civilizar | 1 |
| 10789 | civilizado | 1 |
| 10790 | ciutti | 1 |
| 10791 | citado | 1 |
| 10792 | cisterna | 1 |
| 10793 | ciruelo | 1 |
| 10794 | circunstancias | 1 |
| 10795 | circunstancial | 1 |
| 10796 | circunspección | 1 |
| 10797 | ciprés | 1 |
| 10798 | cinturón | 1 |
| 10799 | cínicamente | 1 |
| 10800 | cincel | 1 |
| 10801 | cimodocea | 1 |
| 10802 | cimiento | 1 |
| 10803 | cilíndrico | 1 |
| 10804 | cigüeña | 1 |
| 10805 | cigarrera | 1 |
| 10806 | cifra | 1 |
| 10807 | cierzo | 1 |
| 10808 | ciervo | 1 |
| 10809 | cierta | 1 |
| 10810 | cierra | 1 |
| 10811 | cierne | 1 |
| 10812 | cientos | 1 |
| 10813 | cicuta | 1 |
| 10814 | ciclópeo | 1 |
| 10815 | cíclope | 1 |
| 10816 | ciclón | 1 |
| 10817 | ciclo | 1 |
| 10818 | cíclades | 1 |
| 10819 | chusquin | 1 |
| 10820 | chorrito | 1 |
| 10821 | chorretada | 1 |
| 10822 | chomel | 1 |
| 10823 | chocha | 1 |
| 10824 | chitón | 1 |
| 10825 | chipre | 1 |
| 10826 | chinita | 1 |
| 10827 | china | 1 |
| 10828 | chin | 1 |
| 10829 | chiflado | 1 |
| 10830 | chevrière | 1 |
| 10831 | chasquir | 1 |
| 10832 | chasco | 1 |
| 10833 | charlatán | 1 |
| 10834 | charanga | 1 |
| 10835 | chaquetón | 1 |
| 10836 | chapa | 1 |
| 10837 | chanza | 1 |
| 10838 | chantre | 1 |
| 10839 | chantal | 1 |
| 10840 | chambra | 1 |
| 10841 | chambón | 1 |
| 10842 | chambergo | 1 |
| 10843 | chalet | 1 |
| 10844 | cetro | 1 |
| 10845 | cerviz | 1 |
| 10846 | cervantes | 1 |
| 10847 | certamen | 1 |
| 10848 | cerro | 1 |
| 10849 | ceremonial | 1 |
| 10850 | cerda | 1 |
| 10851 | cerciorar | 1 |
| 10852 | cercenar | 1 |
| 10853 | cepo | 1 |
| 10854 | centuria | 1 |
| 10855 | centímetro | 1 |
| 10856 | centésima | 1 |
| 10857 | centellear | 1 |
| 10858 | cenarás | 1 |
| 10859 | celta | 1 |
| 10860 | celonio | 1 |
| 10861 | celestinas | 1 |
| 10862 | celesta | 1 |
| 10863 | celeres | 1 |
| 10864 | celenio | 1 |
| 10865 | celar | 1 |
| 10866 | celaje | 1 |
| 10867 | ceguedad | 1 |
| 10868 | cefiso | 1 |
| 10869 | céfiro | 1 |
| 10870 | cedro | 1 |
| 10871 | cebolla | 1 |
| 10872 | cazurro | 1 |
| 10873 | cazadero | 1 |
| 10874 | cavilar | 1 |
| 10875 | caverna | 1 |
| 10876 | caveant | 1 |
| 10877 | cauto | 1 |
| 10878 | cautiverio | 1 |
| 10879 | cautivar | 1 |
| 10880 | cautelar | 1 |
| 10881 | catarro | 1 |
| 10882 | catálogo | 1 |
| 10883 | catacumbas | 1 |
| 10884 | castelar | 1 |
| 10885 | castañeteo | 1 |
| 10886 | castañar | 1 |
| 10887 | casquivano | 1 |
| 10888 | caseta | 1 |
| 10889 | caseoso | 1 |
| 10890 | cascarón | 1 |
| 10891 | cáscara | 1 |
| 10892 | casamata | 1 |
| 10893 | cartulina | 1 |
| 10894 | cartujo | 1 |
| 10895 | cartela | 1 |
| 10896 | cartel | 1 |
| 10897 | cartapacio | 1 |
| 10898 | carraspiques | 1 |
| 10899 | carraca | 1 |
| 10900 | carolina | 1 |
| 10901 | carmín | 1 |
| 10902 | caritativo | 1 |
| 10903 | caricaturar | 1 |
| 10904 | carestía | 1 |
| 10905 | cardona | 1 |
| 10906 | cardiopatía | 1 |
| 10907 | cardíaco | 1 |
| 10908 | cardan | 1 |
| 10909 | carcomido | 1 |
| 10910 | carcamal | 1 |
| 10911 | carca | 1 |
| 10912 | carbonizar | 1 |
| 10913 | carbayeda | 1 |
| 10914 | carátula | 1 |
| 10915 | carambola | 1 |
| 10916 | caramba | 1 |
| 10917 | característico | 1 |
| 10918 | caracolear | 1 |
| 10919 | capua | 1 |
| 10920 | capota | 1 |
| 10921 | capitular | 1 |
| 10922 | capitel | 1 |
| 10923 | capitanear | 1 |
| 10924 | capitalista | 1 |
| 10925 | capirote | 1 |
| 10926 | capelo | 1 |
| 10927 | capellanías | 1 |
| 10928 | capcioso | 1 |
| 10929 | capalleja | 1 |
| 10930 | capacidad | 1 |
| 10931 | caótico | 1 |
| 10932 | caos | 1 |
| 10933 | cañedo | 1 |
| 10934 | cañamón | 1 |
| 10935 | cantera | 1 |
| 10936 | cántaros | 1 |
| 10937 | cantante | 1 |
| 10938 | cantando | 1 |
| 10939 | cantábrico | 1 |
| 10940 | cansarse | 1 |
| 10941 | canonjía | 1 |
| 10942 | canonista | 1 |
| 10943 | canela | 1 |
| 10944 | candil | 1 |
| 10945 | candidatura | 1 |
| 10946 | candente | 1 |
| 10947 | candelillar | 1 |
| 10948 | candado | 1 |
| 10949 | canciones | 1 |
| 10950 | cancerbero | 1 |
| 10951 | camposanto | 1 |
| 10952 | campbell | 1 |
| 10953 | campar | 1 |
| 10954 | campanillazo | 1 |
| 10955 | campanillas | 1 |
| 10956 | campamento | 1 |
| 10957 | camisolín | 1 |
| 10958 | camisola | 1 |
| 10959 | camilla | 1 |
| 10960 | camarote | 1 |
| 10961 | camarín | 1 |
| 10962 | calzonazos | 1 |
| 10963 | calzada | 1 |
| 10964 | calza | 1 |
| 10965 | calva | 1 |
| 10966 | calumniador | 1 |
| 10967 | calomarde | 1 |
| 10968 | callo | 1 |
| 10969 | callejuela | 1 |
| 10970 | callaba | 1 |
| 10971 | calizo | 1 |
| 10972 | caliza | 1 |
| 10973 | caliginoso | 1 |
| 10974 | cálidas | 1 |
| 10975 | calibre | 1 |
| 10976 | calepino | 1 |
| 10977 | calentura | 1 |
| 10978 | calefacción | 1 |
| 10979 | caldear | 1 |
| 10980 | calculador | 1 |
| 10981 | calculaba | 1 |
| 10982 | calcetín | 1 |
| 10983 | calcetar | 1 |
| 10984 | calatravas | 1 |
| 10985 | calado | 1 |
| 10986 | calada | 1 |
| 10987 | calabozo | 1 |
| 10988 | cajista | 1 |
| 10989 | caín | 1 |
| 10990 | caída | 1 |
| 10991 | cafetera | 1 |
| 10992 | caería | 1 |
| 10993 | cadenilla | 1 |
| 10994 | cadencioso | 1 |
| 10995 | cacofónico | 1 |
| 10996 | cachivache | 1 |
| 10997 | cachaza | 1 |
| 10998 | cacerola | 1 |
| 10999 | cacería | 1 |
| 11000 | cabotaje | 1 |
| 11001 | cable | 1 |
| 11002 | cabezota | 1 |
| 11003 | cabellar | 1 |
| 11004 | cabalmente | 1 |
| 11005 | caballeriza | 1 |
| 11006 | caballería | 1 |
| 11007 | caballerete | 1 |
| 11008 | cabalístico | 1 |
| 11009 | ca | 1 |
| 11010 | byron | 1 |
| 11011 | búsquelo | 1 |
| 11012 | buscada | 1 |
| 11013 | burlándose | 1 |
| 11014 | burgués | 1 |
| 11015 | burdo | 1 |
| 11016 | bullir | 1 |
| 11017 | bullicio | 1 |
| 11018 | buitre | 1 |
| 11019 | buhonero | 1 |
| 11020 | bufos | 1 |
| 11021 | bufar | 1 |
| 11022 | buey | 1 |
| 11023 | buchner | 1 |
| 11024 | buche | 1 |
| 11025 | brooke | 1 |
| 11026 | bromista | 1 |
| 11027 | brochada | 1 |
| 11028 | brocado | 1 |
| 11029 | brioso | 1 |
| 11030 | brígida | 1 |
| 11031 | bribón | 1 |
| 11032 | brevísimo | 1 |
| 11033 | brevemente | 1 |
| 11034 | bretón | 1 |
| 11035 | brechar | 1 |
| 11036 | brea | 1 |
| 11037 | bramante | 1 |
| 11038 | braga | 1 |
| 11039 | bracear | 1 |
| 11040 | bozal | 1 |
| 11041 | boto | 1 |
| 11042 | boticario | 1 |
| 11043 | botica | 1 |
| 11044 | botarate | 1 |
| 11045 | botánica | 1 |
| 11046 | borrón | 1 |
| 11047 | borrador | 1 |
| 11048 | borona | 1 |
| 11049 | bordear | 1 |
| 11050 | bordado | 1 |
| 11051 | bonitos | 1 |
| 11052 | bombardeo | 1 |
| 11053 | bolsón | 1 |
| 11054 | bolsista | 1 |
| 11055 | bolera | 1 |
| 11056 | bogar | 1 |
| 11057 | bodegón | 1 |
| 11058 | bocacalle | 1 |
| 11059 | bobadas | 1 |
| 11060 | bobada | 1 |
| 11061 | bloqueo | 1 |
| 11062 | bloquear | 1 |
| 11063 | bloque | 1 |
| 11064 | blindar | 1 |
| 11065 | blindaje | 1 |
| 11066 | blindado | 1 |
| 11067 | blasfemo | 1 |
| 11068 | blanquear | 1 |
| 11069 | blandón | 1 |
| 11070 | blandamente | 1 |
| 11071 | bizcocho | 1 |
| 11072 | bizcochar | 1 |
| 11073 | bizcar | 1 |
| 11074 | bizantino | 1 |
| 11075 | birrete | 1 |
| 11076 | bípedo | 1 |
| 11077 | bion | 1 |
| 11078 | bilioso | 1 |
| 11079 | bílbilis | 1 |
| 11080 | bilbao | 1 |
| 11081 | bilateral | 1 |
| 11082 | bienhechor | 1 |
| 11083 | bibliófilo | 1 |
| 11084 | betún | 1 |
| 11085 | bethlehem | 1 |
| 11086 | bestial | 1 |
| 11087 | berruguete | 1 |
| 11088 | bernardo | 1 |
| 11089 | bernard | 1 |
| 11090 | bermudo | 1 |
| 11091 | berlín | 1 |
| 11092 | bengala | 1 |
| 11093 | benévolo | 1 |
| 11094 | beneplácito | 1 |
| 11095 | beneficioso | 1 |
| 11096 | benedicto | 1 |
| 11097 | belvedere | 1 |
| 11098 | belo | 1 |
| 11099 | bellaquería | 1 |
| 11100 | bellaco | 1 |
| 11101 | belem | 1 |
| 11102 | begonia | 1 |
| 11103 | becerro | 1 |
| 11104 | bebida | 1 |
| 11105 | bebedor | 1 |
| 11106 | beatería | 1 |
| 11107 | be | 1 |
| 11108 | bayonetazo | 1 |
| 11109 | bautizar | 1 |
| 11110 | battistini | 1 |
| 11111 | bastonazo | 1 |
| 11112 | bastón | 1 |
| 11113 | bastidores | 1 |
| 11114 | bastidor | 1 |
| 11115 | bastiat | 1 |
| 11116 | basquiña | 1 |
| 11117 | basilisco | 1 |
| 11118 | barroquismo | 1 |
| 11119 | barrera | 1 |
| 11120 | barbas | 1 |
| 11121 | bárbaros | 1 |
| 11122 | bárbara | 1 |
| 11123 | barbar | 1 |
| 11124 | barata | 1 |
| 11125 | barajar | 1 |
| 11126 | báquico | 1 |
| 11127 | banqueta | 1 |
| 11128 | bandolero | 1 |
| 11129 | bambolear | 1 |
| 11130 | bambalina | 1 |
| 11131 | balzac | 1 |
| 11132 | baltasar | 1 |
| 11133 | balbuciente | 1 |
| 11134 | balbuceó | 1 |
| 11135 | balaustre | 1 |
| 11136 | balaustrar | 1 |
| 11137 | balaustrada | 1 |
| 11138 | balancear | 1 |
| 11139 | bájese | 1 |
| 11140 | bajada | 1 |
| 11141 | baglivio | 1 |
| 11142 | badulaque | 1 |
| 11143 | bachiller | 1 |
| 11144 | bacantes | 1 |
| 11145 | bacalao | 1 |
| 11146 | baboso | 1 |
| 11147 | babor | 1 |
| 11148 | azuzar | 1 |
| 11149 | azulado | 1 |
| 11150 | azufre | 1 |
| 11151 | azucarero | 1 |
| 11152 | azucarado | 1 |
| 11153 | azotacalles | 1 |
| 11154 | azogar | 1 |
| 11155 | ayunar | 1 |
| 11156 | ayúdeme | 1 |
| 11157 | ayudante | 1 |
| 11158 | ayudábala | 1 |
| 11159 | axis | 1 |
| 11160 | avinagrar | 1 |
| 11161 | avinagrado | 1 |
| 11162 | averiguación | 1 |
| 11163 | aventurero | 1 |
| 11164 | aventado | 1 |
| 11165 | avenida | 1 |
| 11166 | avellanado | 1 |
| 11167 | avellana | 1 |
| 11168 | avasallar | 1 |
| 11169 | avasallador | 1 |
| 11170 | avanzada | 1 |
| 11171 | avalorar | 1 |
| 11172 | auxiliar | 1 |
| 11173 | autoridades | 1 |
| 11174 | autómata | 1 |
| 11175 | auto | 1 |
| 11176 | aúpa | 1 |
| 11177 | aumento | 1 |
| 11178 | aulló | 1 |
| 11179 | aullido | 1 |
| 11180 | audiencias | 1 |
| 11181 | atropellar | 1 |
| 11182 | atronador | 1 |
| 11183 | atril | 1 |
| 11184 | atribular | 1 |
| 11185 | atribución | 1 |
| 11186 | atrévete | 1 |
| 11187 | atravesado | 1 |
| 11188 | atracón | 1 |
| 11189 | atracción | 1 |
| 11190 | atonía | 1 |
| 11191 | aterir | 1 |
| 11192 | atenuar | 1 |
| 11193 | atenea | 1 |
| 11194 | atemorizar | 1 |
| 11195 | atávico | 1 |
| 11196 | ataúd | 1 |
| 11197 | atareado | 1 |
| 11198 | atalayar | 1 |
| 11199 | atajo | 1 |
| 11200 | atajar | 1 |
| 11201 | asueto | 1 |
| 11202 | asturias | 1 |
| 11203 | asturiano | 1 |
| 11204 | astronomía | 1 |
| 11205 | astillar | 1 |
| 11206 | aspirado | 1 |
| 11207 | aspar | 1 |
| 11208 | aspa | 1 |
| 11209 | asombrosamente | 1 |
| 11210 | asolar | 1 |
| 11211 | asociar | 1 |
| 11212 | asociación | 1 |
| 11213 | asimilar | 1 |
| 11214 | asilo | 1 |
| 11215 | asilar | 1 |
| 11216 | asignatura | 1 |
| 11217 | asia | 1 |
| 11218 | asestar | 1 |
| 11219 | asesorar | 1 |
| 11220 | asesinato | 1 |
| 11221 | asentar | 1 |
| 11222 | asegurado | 1 |
| 11223 | asedio | 1 |
| 11224 | asear | 1 |
| 11225 | ascetismo | 1 |
| 11226 | ascético | 1 |
| 11227 | asamblea | 1 |
| 11228 | as | 1 |
| 11229 | artesonado | 1 |
| 11230 | artela | 1 |
| 11231 | arruinado | 1 |
| 11232 | arroz | 1 |
| 11233 | arropar | 1 |
| 11234 | arrollar | 1 |
| 11235 | arrobar | 1 |
| 11236 | arriesgado | 1 |
| 11237 | arriero | 1 |
| 11238 | arresto | 1 |
| 11239 | arrendamiento | 1 |
| 11240 | arremetida | 1 |
| 11241 | arregla | 1 |
| 11242 | arrasar | 1 |
| 11243 | arras | 1 |
| 11244 | arraigo | 1 |
| 11245 | arrabal | 1 |
| 11246 | arquitecto | 1 |
| 11247 | arouet | 1 |
| 11248 | aromar | 1 |
| 11249 | aro | 1 |
| 11250 | armas | 1 |
| 11251 | armando | 1 |
| 11252 | armadura | 1 |
| 11253 | árido | 1 |
| 11254 | argumosa | 1 |
| 11255 | argucia | 1 |
| 11256 | argos | 1 |
| 11257 | arengar | 1 |
| 11258 | ardilla | 1 |
| 11259 | arcón | 1 |
| 11260 | arciprestazgo | 1 |
| 11261 | arcilla | 1 |
| 11262 | archivo | 1 |
| 11263 | archimonástica | 1 |
| 11264 | arcar | 1 |
| 11265 | arcadias | 1 |
| 11266 | arboricultor | 1 |
| 11267 | arbolado | 1 |
| 11268 | arbitrista | 1 |
| 11269 | arbitrar | 1 |
| 11270 | aragonesa | 1 |
| 11271 | árabe | 1 |
| 11272 | aquilatar | 1 |
| 11273 | apuntando | 1 |
| 11274 | aproximadamente | 1 |
| 11275 | apropósito | 1 |
| 11276 | aprobado | 1 |
| 11277 | aprieto | 1 |
| 11278 | apremiante | 1 |
| 11279 | apreciación | 1 |
| 11280 | apóstrofe | 1 |
| 11281 | apóstoles | 1 |
| 11282 | apostatar | 1 |
| 11283 | apostaría | 1 |
| 11284 | apostaba | 1 |
| 11285 | aposento | 1 |
| 11286 | aportar | 1 |
| 11287 | apoplético | 1 |
| 11288 | apoplejía | 1 |
| 11289 | apólogo | 1 |
| 11290 | apología | 1 |
| 11291 | apoderado | 1 |
| 11292 | apodar | 1 |
| 11293 | apocalíptico | 1 |
| 11294 | apocado | 1 |
| 11295 | aplicable | 1 |
| 11296 | aplausos | 1 |
| 11297 | aplaude | 1 |
| 11298 | apiñábase | 1 |
| 11299 | ápice | 1 |
| 11300 | apetecer | 1 |
| 11301 | aperitivo | 1 |
| 11302 | apéndice | 1 |
| 11303 | apelmazar | 1 |
| 11304 | apegar | 1 |
| 11305 | apatía | 1 |
| 11306 | apasionamiento | 1 |
| 11307 | apartamiento | 1 |
| 11308 | apartado | 1 |
| 11309 | apareció | 1 |
| 11310 | aparador | 1 |
| 11311 | apañar | 1 |
| 11312 | apalear | 1 |
| 11313 | apagó | 1 |
| 11314 | apacentar | 1 |
| 11315 | añoso | 1 |
| 11316 | años | 1 |
| 11317 | añicos | 1 |
| 11318 | anuncita | 1 |
| 11319 | anular | 1 |
| 11320 | anual | 1 |
| 11321 | antro | 1 |
| 11322 | antonelli | 1 |
| 11323 | antón | 1 |
| 11324 | antolínez | 1 |
| 11325 | antojadizo | 1 |
| 11326 | antojábasele | 1 |
| 11327 | antigüedades | 1 |
| 11328 | antiguamente | 1 |
| 11329 | antiespasmódicos | 1 |
| 11330 | anticuado | 1 |
| 11331 | anticipado | 1 |
| 11332 | antepasado | 1 |
| 11333 | antecedentes | 1 |
| 11334 | anónimos | 1 |
| 11335 | animalucho | 1 |
| 11336 | animalejo | 1 |
| 11337 | aniceto | 1 |
| 11338 | anhelante | 1 |
| 11339 | angustioso | 1 |
| 11340 | anguila | 1 |
| 11341 | angostar | 1 |
| 11342 | angola | 1 |
| 11343 | angelito | 1 |
| 11344 | angelino | 1 |
| 11345 | angélico | 1 |
| 11346 | angarillas | 1 |
| 11347 | anfibológico | 1 |
| 11348 | andrómaca | 1 |
| 11349 | anden | 1 |
| 11350 | andarín | 1 |
| 11351 | andalucía | 1 |
| 11352 | analítico | 1 |
| 11353 | amplitud | 1 |
| 11354 | ampliar | 1 |
| 11355 | amotinado | 1 |
| 11356 | amostazar | 1 |
| 11357 | amortajar | 1 |
| 11358 | amorcillo | 1 |
| 11359 | amoratado | 1 |
| 11360 | amontonado | 1 |
| 11361 | amoldar | 1 |
| 11362 | amnistiar | 1 |
| 11363 | amistoso | 1 |
| 11364 | amistades | 1 |
| 11365 | américo | 1 |
| 11366 | américas | 1 |
| 11367 | amenizar | 1 |
| 11368 | amenidad | 1 |
| 11369 | amenguar | 1 |
| 11370 | amenazador | 1 |
| 11371 | ambulante | 1 |
| 11372 | amazacotar | 1 |
| 11373 | amasijo | 1 |
| 11374 | amasar | 1 |
| 11375 | amarrar | 1 |
| 11376 | amarillez | 1 |
| 11377 | amarillear | 1 |
| 11378 | amarilla | 1 |
| 11379 | amarilis | 1 |
| 11380 | amaré | 1 |
| 11381 | amaño | 1 |
| 11382 | amansar | 1 |
| 11383 | amaneramiento | 1 |
| 11384 | amaba | 1 |
| 11385 | alvarico | 1 |
| 11386 | aluvión | 1 |
| 11387 | alumbramiento | 1 |
| 11388 | aludido | 1 |
| 11389 | alucinar | 1 |
| 11390 | alturas | 1 |
| 11391 | altivez | 1 |
| 11392 | altisonante | 1 |
| 11393 | altísimo | 1 |
| 11394 | altanería | 1 |
| 11395 | alquilar | 1 |
| 11396 | alpiste | 1 |
| 11397 | alondra | 1 |
| 11398 | almuerzo | 1 |
| 11399 | almidonado | 1 |
| 11400 | almidón | 1 |
| 11401 | almibarar | 1 |
| 11402 | almibarado | 1 |
| 11403 | almena | 1 |
| 11404 | alleluia | 1 |
| 11405 | allanar | 1 |
| 11406 | alimentación | 1 |
| 11407 | alimaña | 1 |
| 11408 | aliciente | 1 |
| 11409 | alianza | 1 |
| 11410 | alharaca | 1 |
| 11411 | alguno | 1 |
| 11412 | algunas | 1 |
| 11413 | algodones | 1 |
| 11414 | algodón | 1 |
| 11415 | alforja | 1 |
| 11416 | alfonsos | 1 |
| 11417 | alfiletero | 1 |
| 11418 | alfilerar | 1 |
| 11419 | alfiler | 1 |
| 11420 | aletear | 1 |
| 11421 | aletargar | 1 |
| 11422 | alero | 1 |
| 11423 | alemania | 1 |
| 11424 | alegremente | 1 |
| 11425 | alegórico | 1 |
| 11426 | aleccionar | 1 |
| 11427 | aleatorio | 1 |
| 11428 | aldebarán | 1 |
| 11429 | alcurnia | 1 |
| 11430 | alcubilla | 1 |
| 11431 | alcornoque | 1 |
| 11432 | alcohólico | 1 |
| 11433 | alcides | 1 |
| 11434 | alcaldesa | 1 |
| 11435 | alcaide | 1 |
| 11436 | álbum | 1 |
| 11437 | alboroto | 1 |
| 11438 | alborada | 1 |
| 11439 | albión | 1 |
| 11440 | albergar | 1 |
| 11441 | alberca | 1 |
| 11442 | albéitar | 1 |
| 11443 | albedrío | 1 |
| 11444 | albañal | 1 |
| 11445 | albaicín | 1 |
| 11446 | alarmado | 1 |
| 11447 | alarma | 1 |
| 11448 | alarcón | 1 |
| 11449 | alambrar | 1 |
| 11450 | alabado | 1 |
| 11451 | ajustábase | 1 |
| 11452 | ajenjo | 1 |
| 11453 | aislador | 1 |
| 11454 | airado | 1 |
| 11455 | ahuyentar | 1 |
| 11456 | ahumar | 1 |
| 11457 | ahorita | 1 |
| 11458 | ahogado | 1 |
| 11459 | ahíto | 1 |
| 11460 | ahitar | 1 |
| 11461 | ahincar | 1 |
| 11462 | agustinito | 1 |
| 11463 | agujerito | 1 |
| 11464 | aguijonear | 1 |
| 11465 | aguijón | 1 |
| 11466 | aguerrido | 1 |
| 11467 | aguas | 1 |
| 11468 | aguar | 1 |
| 11469 | agrónomo | 1 |
| 11470 | agrícola | 1 |
| 11471 | agriar | 1 |
| 11472 | agreste | 1 |
| 11473 | agravante | 1 |
| 11474 | agradézcaselo | 1 |
| 11475 | agradablemente | 1 |
| 11476 | agradábale | 1 |
| 11477 | agotar | 1 |
| 11478 | agorero | 1 |
| 11479 | agorar | 1 |
| 11480 | agonizar | 1 |
| 11481 | agonía | 1 |
| 11482 | agobiar | 1 |
| 11483 | aglomerar | 1 |
| 11484 | aglomeración | 1 |
| 11485 | agilidad | 1 |
| 11486 | ágil | 1 |
| 11487 | agenciar | 1 |
| 11488 | agencia | 1 |
| 11489 | agazapar | 1 |
| 11490 | agasajo | 1 |
| 11491 | agasajar | 1 |
| 11492 | agarrada | 1 |
| 11493 | afueras | 1 |
| 11494 | africano | 1 |
| 11495 | afrentar | 1 |
| 11496 | afrenta | 1 |
| 11497 | afirmó | 1 |
| 11498 | afirmativo | 1 |
| 11499 | afilar | 1 |
| 11500 | afilador | 1 |
| 11501 | afianzar | 1 |
| 11502 | aferrar | 1 |
| 11503 | afeitado | 1 |
| 11504 | afectivo | 1 |
| 11505 | afectísimo | 1 |
| 11506 | afear | 1 |
| 11507 | afanar | 1 |
| 11508 | afablemente | 1 |
| 11509 | aeroterapia | 1 |
| 11510 | aéreo | 1 |
| 11511 | adverso | 1 |
| 11512 | adulterado | 1 |
| 11513 | adulador | 1 |
| 11514 | aducir | 1 |
| 11515 | aduana | 1 |
| 11516 | adquisición | 1 |
| 11517 | adocenar | 1 |
| 11518 | adobar | 1 |
| 11519 | admitido | 1 |
| 11520 | adjunto | 1 |
| 11521 | adjetivo | 1 |
| 11522 | adiosito | 1 |
| 11523 | adición | 1 |
| 11524 | adhesión | 1 |
| 11525 | adherir | 1 |
| 11526 | aderezo | 1 |
| 11527 | adelanto | 1 |
| 11528 | adefesio | 1 |
| 11529 | adecuar | 1 |
| 11530 | adaptarse | 1 |
| 11531 | adamascado | 1 |
| 11532 | adamado | 1 |
| 11533 | acústico | 1 |
| 11534 | acusador | 1 |
| 11535 | acudió | 1 |
| 11536 | acuarela | 1 |
| 11537 | actriz | 1 |
| 11538 | acta | 1 |
| 11539 | acróbata | 1 |
| 11540 | acritud | 1 |
| 11541 | acribillar | 1 |
| 11542 | acreedor | 1 |
| 11543 | acortar | 1 |
| 11544 | acongojar | 1 |
| 11545 | acompasado | 1 |
| 11546 | acomodamiento | 1 |
| 11547 | aclamación | 1 |
| 11548 | acíbar | 1 |
| 11549 | achantar | 1 |
| 11550 | acervo | 1 |
| 11551 | acertado | 1 |
| 11552 | acerico | 1 |
| 11553 | acerado | 1 |
| 11554 | aceptó | 1 |
| 11555 | aceitar | 1 |
| 11556 | accionista | 1 |
| 11557 | accionar | 1 |
| 11558 | accesorio | 1 |
| 11559 | acatarrar | 1 |
| 11560 | acartonado | 1 |
| 11561 | acarrear | 1 |
| 11562 | acariciador | 1 |
| 11563 | acaparar | 1 |
| 11564 | acaparador | 1 |
| 11565 | acantos | 1 |
| 11566 | acantilado | 1 |
| 11567 | acampar | 1 |
| 11568 | acalorado | 1 |
| 11569 | academia | 1 |
| 11570 | abyección | 1 |
| 11571 | abur | 1 |
| 11572 | abundantemente | 1 |
| 11573 | abultar | 1 |
| 11574 | abstraer | 1 |
| 11575 | abstractar | 1 |
| 11576 | abstención | 1 |
| 11577 | abroquelado | 1 |
| 11578 | abrigado | 1 |
| 11579 | abreviatura | 1 |
| 11580 | abreviar | 1 |
| 11581 | abreviado | 1 |
| 11582 | abrasador | 1 |
| 11583 | abra | 1 |
| 11584 | aborrecido | 1 |
| 11585 | aborrecía | 1 |
| 11586 | abonado | 1 |
| 11587 | abominación | 1 |
| 11588 | abogar | 1 |
| 11589 | abofetear | 1 |
| 11590 | ablución | 1 |
| 11591 | ablativo | 1 |
| 11592 | ablandar | 1 |
| 11593 | abertura | 1 |
| 11594 | abelardo | 1 |
| 11595 | abeja | 1 |
|
|
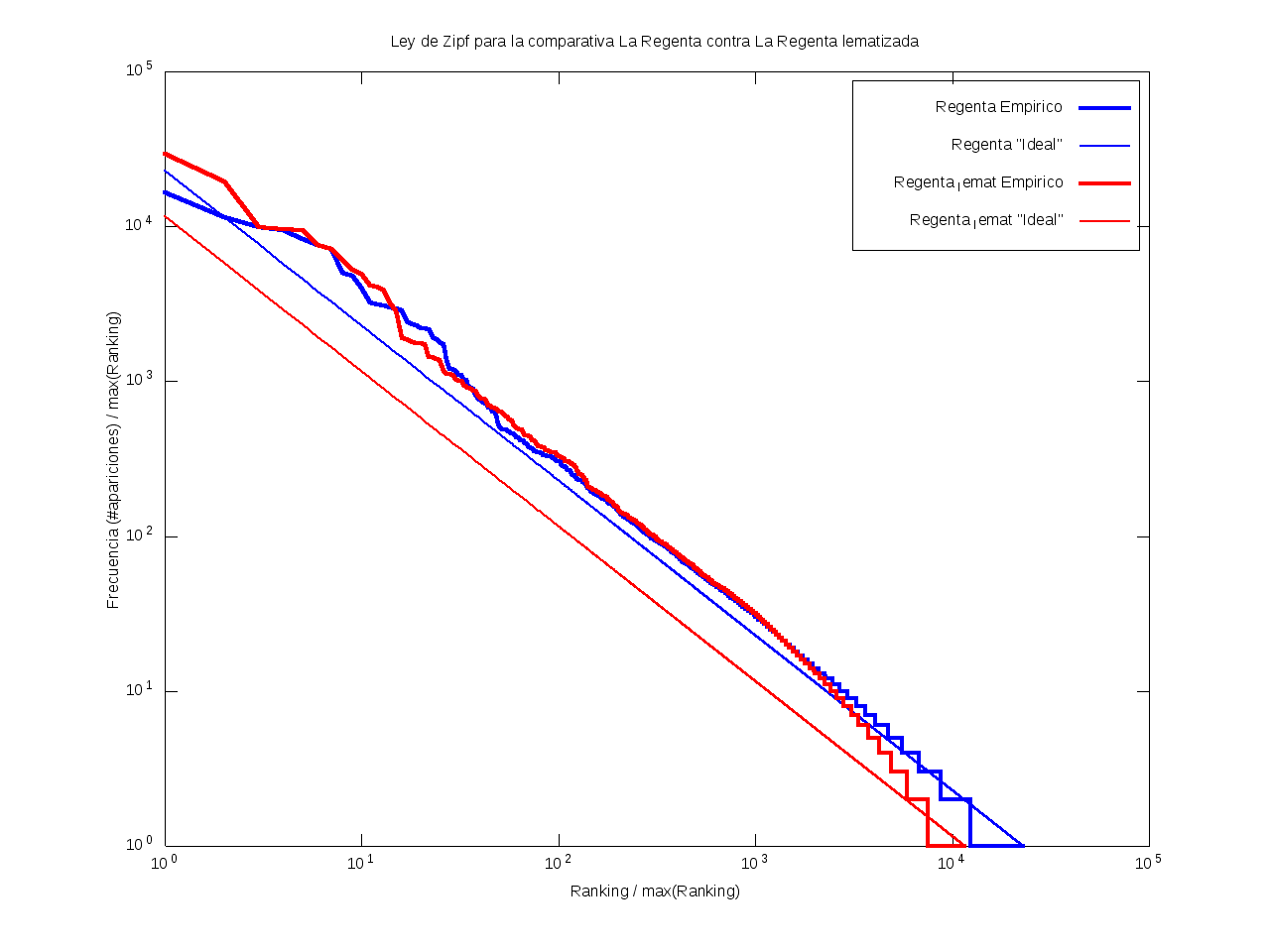
|
|
Mostrar todo
Recoger
|
Test de Dunning
El test de Dunning sirve para identificar las palabras distintivas de un texto.
En este caso lo utilizaremos para encontrar palabras distintivas de cada uno de los conjuntos que estamos comparando frente al otro.
Fórmula:
- 2 log(lambda) = 2 [ log L(p1,k1,n1)+log L(p2,k2,n2)-log L(p,k1,n1)-log L(p,k2,n2) ]
donde
L(p,k,n) = p^k * (1-p)^(n-k)
con
- ki = frecuencia (número de apariciones) de la palabra en el conjunto i.
- ni = número total de palabras del conjunto i.
- pi = probabilidad de la palabra en el conjunto i = ki/ni.
Para encontrar las palabras distintivas se enfrentará un conjunto (Regenta) (conjunto 1)
contra el otro (Regenta_lemat) (conjunto 2) y viceversa.
A continuación se muestra una lista de todas las palabras presentes en los textos,
ordenadas por su puntuación en la razón de verosimilitud, indicando de cuál de ellos son distintivas.
Haga click en la palabra para ver su definición según el diccionario de la RAE.
En este caso no tiene sentido aplicar el test de Dunning ya que los textos están en idiomas distintos.